前言
大家好我是jiantaoyab,这是我所总结作为学习的笔记第九篇,在这里分享给大家,还有一些书籍《深入理解计算机系统》《计算机组成:结构化方法》《编码:隐匿在计算机软硬件背后的语言》,这篇文章讲CPU流水线设计,可以读读这个大佬文章
我们执行一条指令,其实可以不放在一个时钟周期里面,可以直接拆分到多个时钟周期。
我们可以在一个时钟周期里面,去自增 PC 寄存器的值,也就是指令对应的内存地址。然后,我们要根据这个地址从 D 触发器里面读取指令,这个还是可以在刚才那个时钟周期内。但是对应的指令写入到指令寄存器,我们可以放在一个新的时钟周期里面。指令译码给到 ALU 之后的计算结果,要写回到寄存器,又可以放到另一个新的时钟周期。所以,执行一条计算机指令,其实可以拆分到很多个时钟周期,而不是必须使用单指令周期处理器的设计。
因为从内存里面读取指令时间很长,所以如果使用单指令周期处理器,就意味着我们的指令都要去等待一些慢速的操作。这些不同指令执行速度的差异,也正是计算机指令有指令周期、CPU 周期和时钟周期之分的原因。因此,现代我们优化 CPU 的性能时,用的 CPU 都不是单指令周期处理器,而是通过流水线、分支预测等技术,来实现在一个周期里同时执行多个指令。
单指令周期处理器
一条 CPU 指令的执行,是由取得指令(Fetch)- 指令译码(Decode)- 执行指令(Execute)组成,很自然地,我们希望能确保让这样一整条指令的执行,在一个时钟周期内完成,采用这种设计思路的处理器,就叫作单指令周期处理器。
也就是说这单指令周期处理器下,在一个时钟周期内,处理器正好能处理一条指令
但是,时钟周期是固定的,但是指令的电路复杂程度是不同的,所以实际一条指令执行的时间是不同的,随着门电路层数的增加,由于门延迟的存在,位数多、计算复杂的指令需要的执行时间会更长
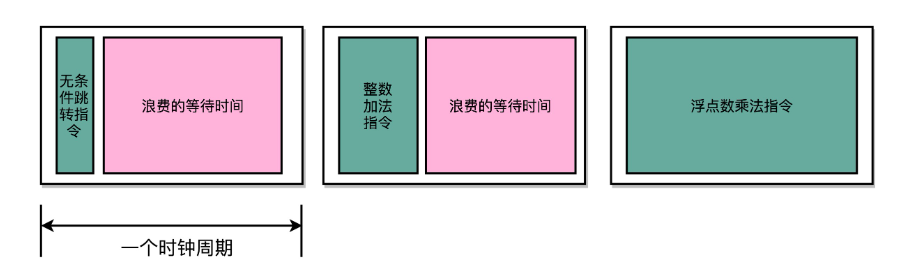
不同指令的执行时间不同,但是我们需要让所有指令都在一个时钟周期内完成,那就只好把时钟周期和执行时间最长的那个指令设成一样,就像和几个朋友去吃饭,吃饭的时间是取决于最慢的那个朋友
所以,在单指令周期处理器里面,无论是执行一条用不到 ALU 的无条件跳转指令,还是一条计算起来电路特别复杂的浮点数乘法运算,我们都等要等满一个时钟周期。在这个情况下,虽然 CPI 能够保持在 1,但是我们的时钟频率却没法太高。因为太高的话,有些复杂指令没有办法在一个时钟周期内运行完成。那么在下一个时钟周期到来,开始执行下一条指令的时候,前一条指令的执行结果可能还没有写入到寄存器里面。那下一条指令读取的数据就是不准确的,就会出现错误。
流水线设计
把CPU执行更加细分,执行的过程,其实还包含从寄存器或者内存中读取数据,通过 ALU 进行运算,把结果写回到寄存器或者内存中。
CPU 的指令执行过程,其实也是由各个电路模块组成的。我们在取指令的时候,需要一个译码器把数据从内存里面取出来,写入到寄存器中;在指令译码的时候,我们需要另外一个译码器,把指令解析成对应的控制信号、内存地址和数据;到了指令执行的时候,我们需要的则是一个完成计算工作的 ALU。这些都是一个一个独立的组合逻辑电路。
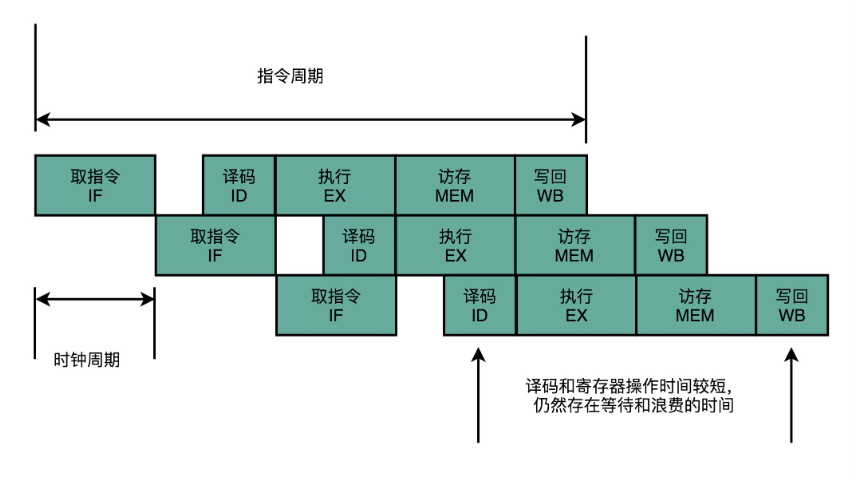
这样一来,我们就不用把时钟周期设置成整条指令执行的时间,而是拆分成完成这样的一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段,这里面每一个独立的步骤,我们就称之为流水线阶段或者流水线级(Pipeline Stage)
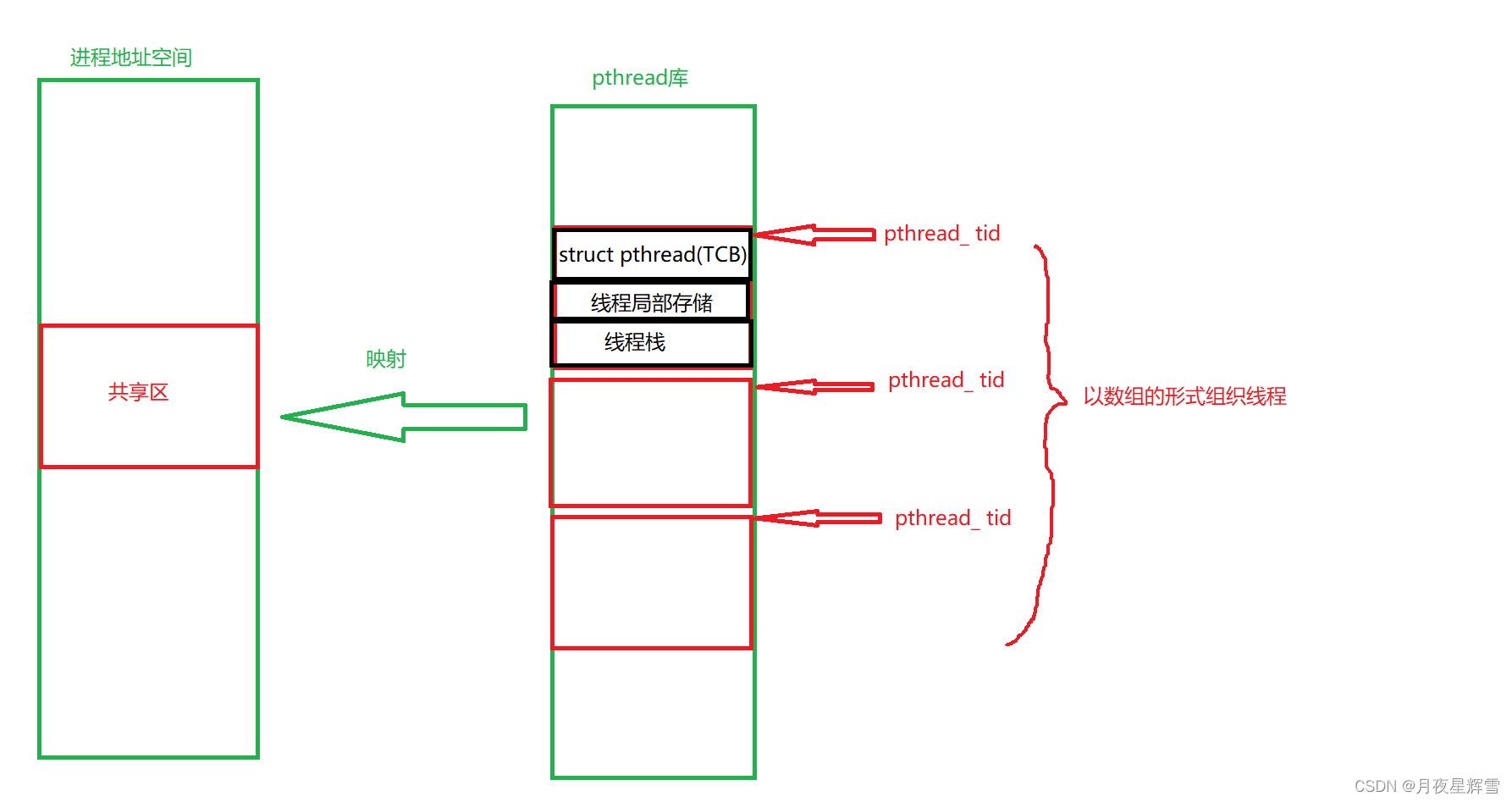
一个流水级占用一个时钟周期
如果我们把一个指令拆分成“取指令 - 指令译码 - 执行指令”这样三个部分,那这就是一个三级的流水线。如果我们进一步把“执行指令”拆分成“ALU 计算(指令执行)- 内存访问 - 数据写回”,那么它就会变成一个五级的流水线,这样我们不需要确保最复杂的那条指令在时钟周期里面执行完成,而只要保障一个最复杂的流水线级的操作,在一个时钟周期内完成就好了。
流水线的优势
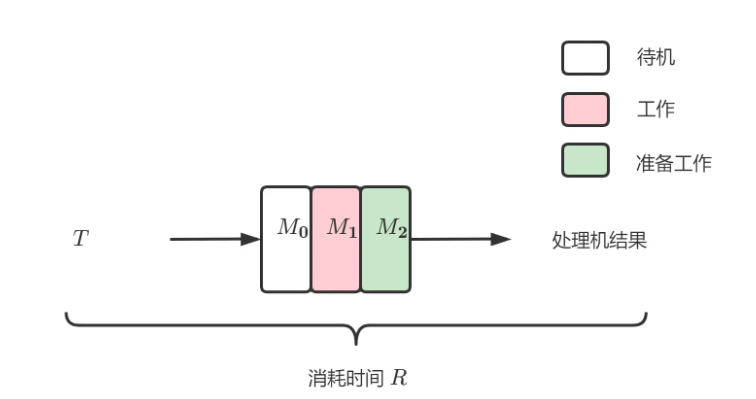
每时每刻这个系统中只有一个子系统在工作。如果用甘特图表示,这个系统处理N个任务的流程就是下图的样子
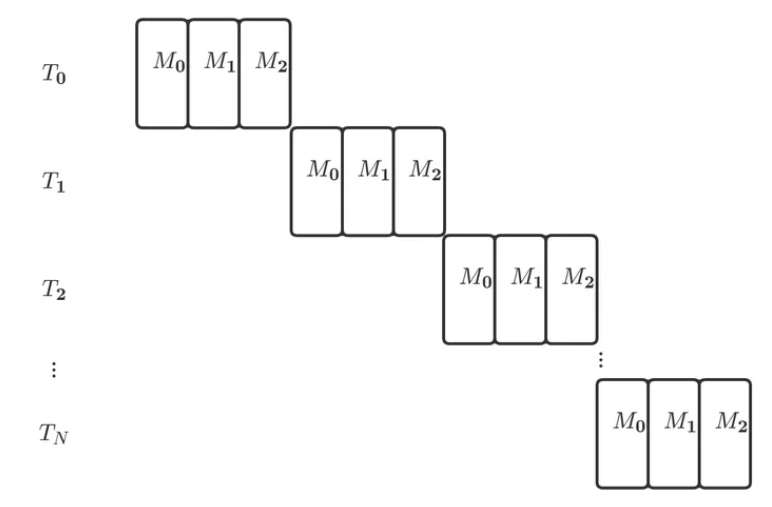
流水线设计
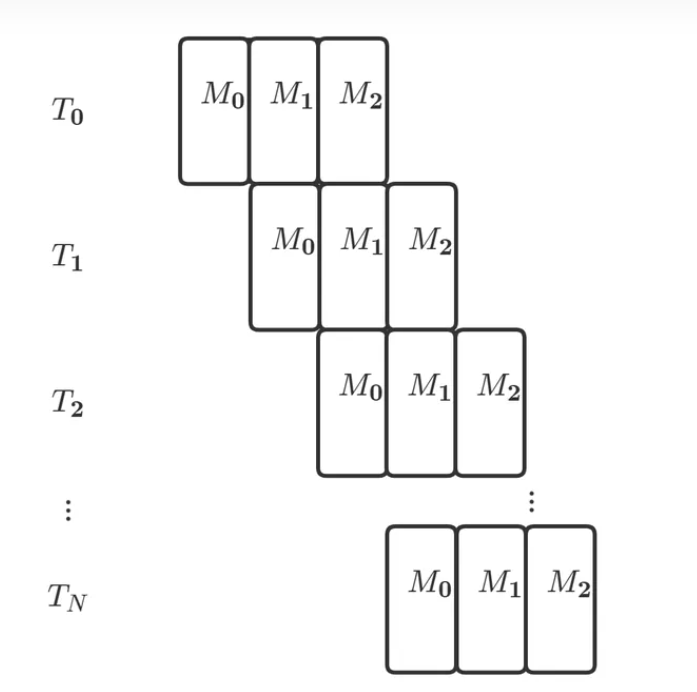
举个例子
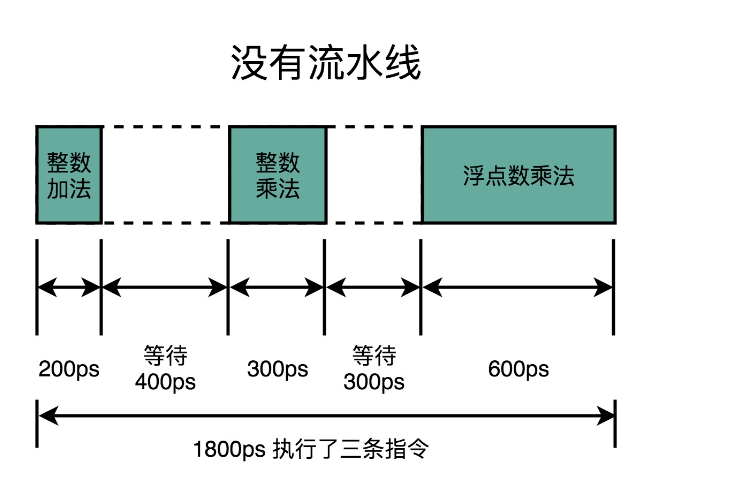
假如顺序执行这样三条指令
- 一条整数的加法,需要 200ps。
- 一条整数的乘法,需要 300ps。
- 一条浮点数的乘法,需要 600ps。
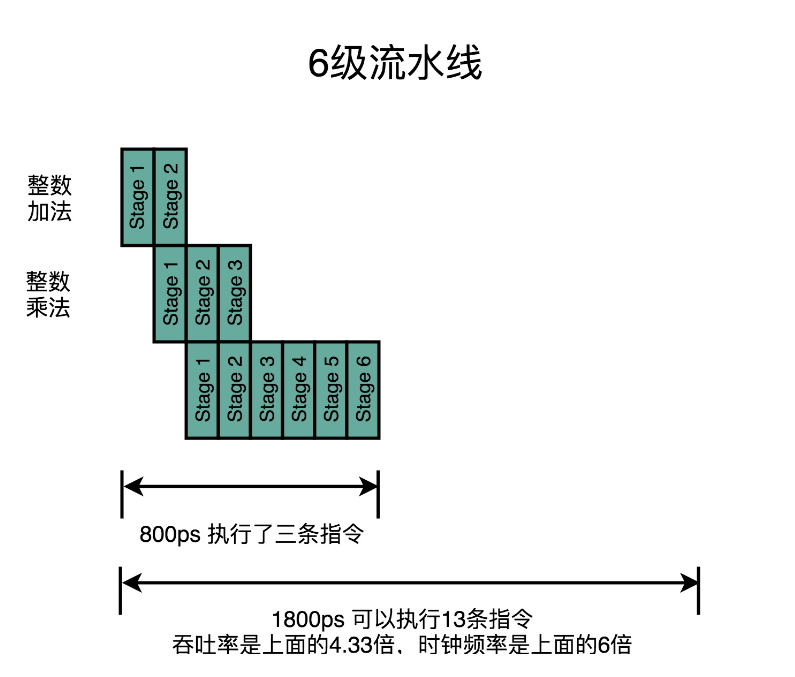
那拆分成更多的流水线不就好了,拆分成100级?
当我们拆分成很多的流水线的时候,成本就转移到了流水线的级别,每一级流水线对应的输出,都要放到流水线寄存器(Pipeline Register)里面,然后在下一个时钟周期,交给下一个流水线级去处理。所以,每增加一级的流水线,就要多一级写入到流水线寄存器的操作。虽然流水线寄存器非常快但是,如果我们不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加,最后会得不偿失
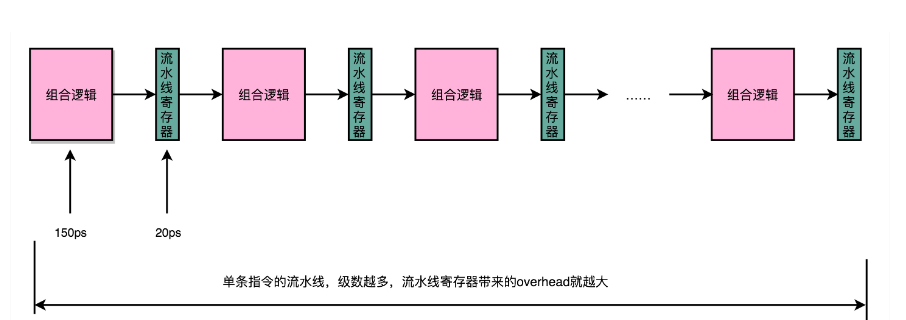
冒险和分支预测
上面说的流水线技术带来的性能提升,是一个理想情况。在实际的程序执行中,并不一定能够做得到。
假如代码改为
int a = 10 + 5; // 指令 1
int b = a * 2; // 指令 2
float c = b * 1.0f; // 指令 3
我们会发现,指令 2,不能在指令 1 的第一个 Stage 执行完成之后进行。因为指令 2,依赖指令 1 的计算结果。同样的,指令 3 也要依赖指令 2 的计算结果。这样,即使我们采用了流水线技术,这三条指令执行完成的时间,也是 200 + 300 + 600 = 1100 ps,而不是之前说的 800ps。
这个依赖问题,就是我们在计算机组成里面所说的冒险(Hazard)问题。这里我们只列举了在数据层面的依赖,也就是数据冒险。在实际应用中,还会有结构冒险、控制冒险等其他的依赖问题。
流水线越长,这个冒险的问题就越难一解决。这是因为,同一时间同时在运行的指令太多了。如果我们只有 3 级流水线,我们可以把后面没有依赖关系的指令放到前面来执行。这个就是乱序执行的技术
比方说,我们可以扩展一下上面的 3 行代码,再加上几行代码。
int a = 10 + 5; // 指令 1
int b = a * 2; // 指令 2
float c = b * 1.0f; // 指令 3
int x = 10 + 5; // 指令 4
int y = a * 2; // 指令 5
float z = b * 1.0f; // 指令 6
int o = 10 + 5; // 指令 7
int p = a * 2; // 指令 8
float q = b * 1.0f; // 指令 9
我们可以不先执行 1、2、3 这三条指令,而是在流水线里,先执行 1、4、7 三条指令。这三条指令之间是没有依赖关系的。然后再执行 2、5、8 以及 3、6、9。这样,我们又能够充分利用 CPU 的计算能力了。




![代码理解 pseudo_labeled = outputs.max(1)[1]](https://img-blog.csdnimg.cn/direct/b50f1163689a4f14a700f2e3d51f8f85.png)