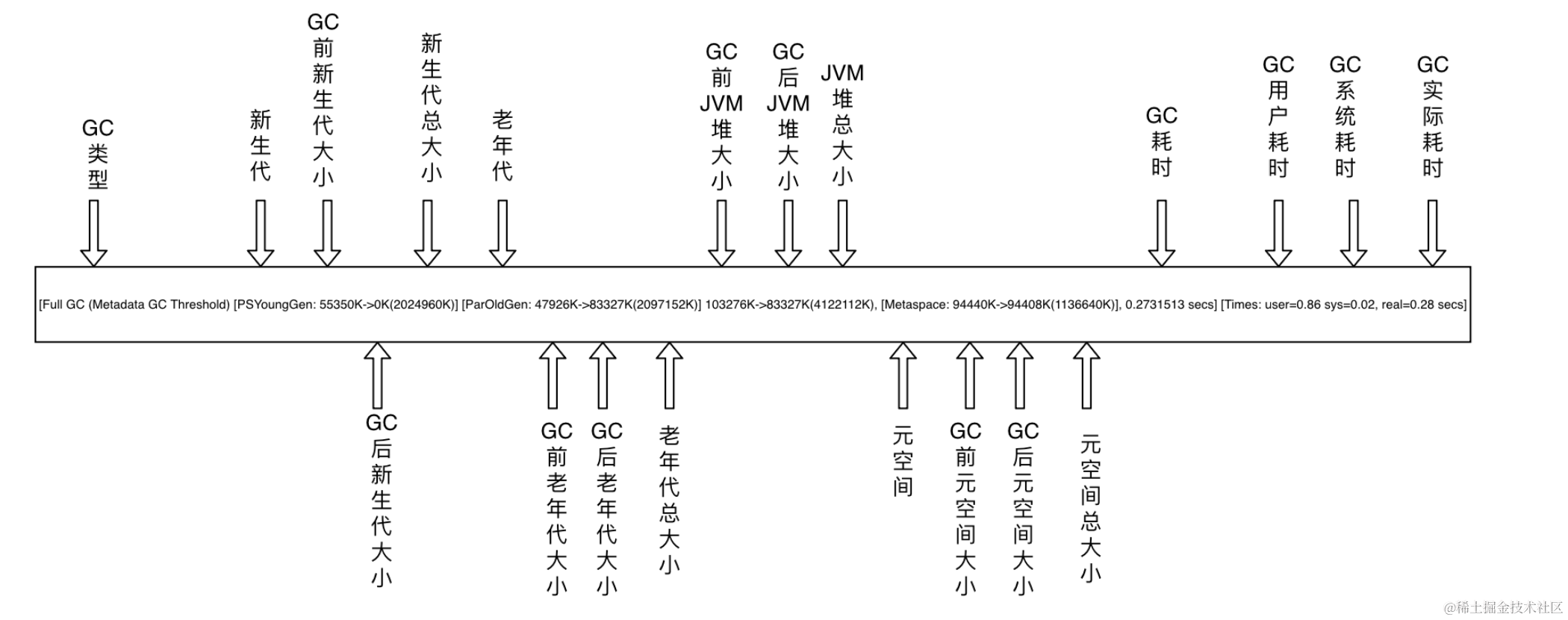
文件
文件是什么
变量是把数据保存到内存中. 如果程序重启/主机重启, 内存中的数据就会丢失.
要想能让数据被持久化存储, 就可以把数据存储到硬盘中. 也就是在 文件 中保存
在 Windows “此电脑” 中, 看到的内容都是 文件.
文件夹(目录)也是一种特殊的文件->目录文件
通过文件的后缀名, 可以看到文件的类型. 常见的文件的类型如下:
文本文件 (txt)
可执行文件 (exe, dll)
图片文件 (jpg, gif)
视频文件 (mp4, mov)
office 文件 (.ppt, docx)
…
此文章主要研究最简单的文本文件.
冯诺依曼体系结构:CPU,存储器,输入设备,输出设备
内存和硬盘的区别:
1.内存的空间更小,硬盘空间更大
2.内存访问更快,硬盘访问更慢
3.内存成本更贵,硬盘成本更便宜
4.内存的数据易失,硬盘的数据持久化存储(硬盘上存储的数据就是以文件的形式来组织的)
文件路径
一个机器上, 会存在很多文件, 为了让这些文件更方面的被组织, 往往会使用很多的 “文件夹”(也叫做目录) 来整理文件.
实际一个文件往往是放在一系列的目录结构之中的.
为了方便确定一个文件所在的位置, 使用 文件路径 来进行描述.
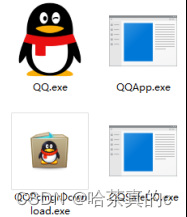
例如, 上述截图中的 QQ.exe 这个文件, 描述这个文件的位置, 就可以使用路径D:\program\qq\Bin\QQ.exe 来表示.
D: 表示 盘符. 不区分大小写.
每一个 \ 表示一级目录. 当前 QQ.exe 就是放在 “D 盘下的 program 目录下的 qq 目录下的 Bin 目录中” .
目录之间的分隔符, 可以使用 \ 也可以使用 / . 一般在编写代码的时候使用 / 更方便.
\也可以表示分隔符是Windows系统所独有的,在一次更新中出现(通常都是使用 / 斜杠的方式,反斜杠\在字符串中存在转义字符的概念)
\t 表示制表符 \n表示换行…
文件路径也可以视为是文件在硬盘上的身份标识.每个文件对应的路径都是唯一的!
上述以 盘符 开头的路径, 我们也称为 绝对路径.
除了绝对路径之外, 还有一种常见的表示方式是 相对路径.
相对路径需要先指定一个基准目录, 然后以基准目录为参照点, 间接的找到目标文件
描述一个文件的位置, 使用 绝对路径 和 相对路径 都是可以的.
对于新手来说, 使用 绝对路径 更简单更好理解, 也不容易出错.
文件操作
要使用文件, 主要是通过文件来保存数据, 并且在后续把保存的数据读取出来.
但是要想读写文件, 需要先 “打开文件”, 读写完毕之后还要 “关闭文件”.
1. 打开文件
使用内建函数 open 打开一个文件.
f = open('d:/test.txt', 'r')
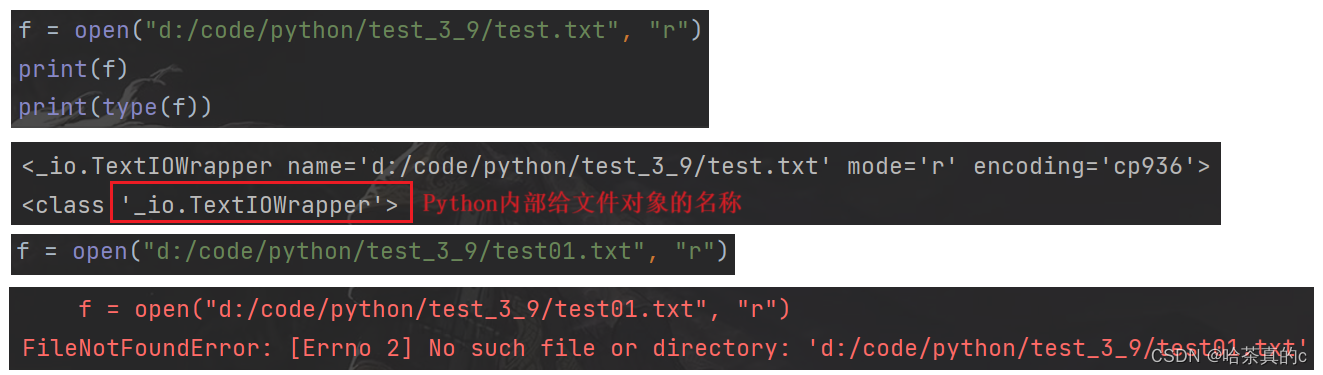
第一个参数是一个字符串, 表示要打开的文件路径
第二个参数是一个字符串, 表示打开方式. 其中 r 表示按照读方式打开. w 表示按照写方式打开. a表示追加写方式打开.
如果打开文件成功, 返回一个文件对象. 后续的读写文件操作都是围绕这个文件对象展开.
如果打开文件失败(比如路径指定的文件不存在), 就会抛出异常.
2. 关闭文件
使用 close 方法关闭已经打开的文件.
f.close()
使用完毕的文件要记得及时关闭!
打开文件,其实是在申请一定的系统资源 不再使用文件的时候,资源就应该及时释放.
“有借有还再借不难”
资源不及时释放,就可能造成文件资源泄露,进一步的导致其他部分的代码无法顺利打开文件了
正是因为一个系统的资源是有限的,因此一个程序能打开的文件个数,也是有上限的!
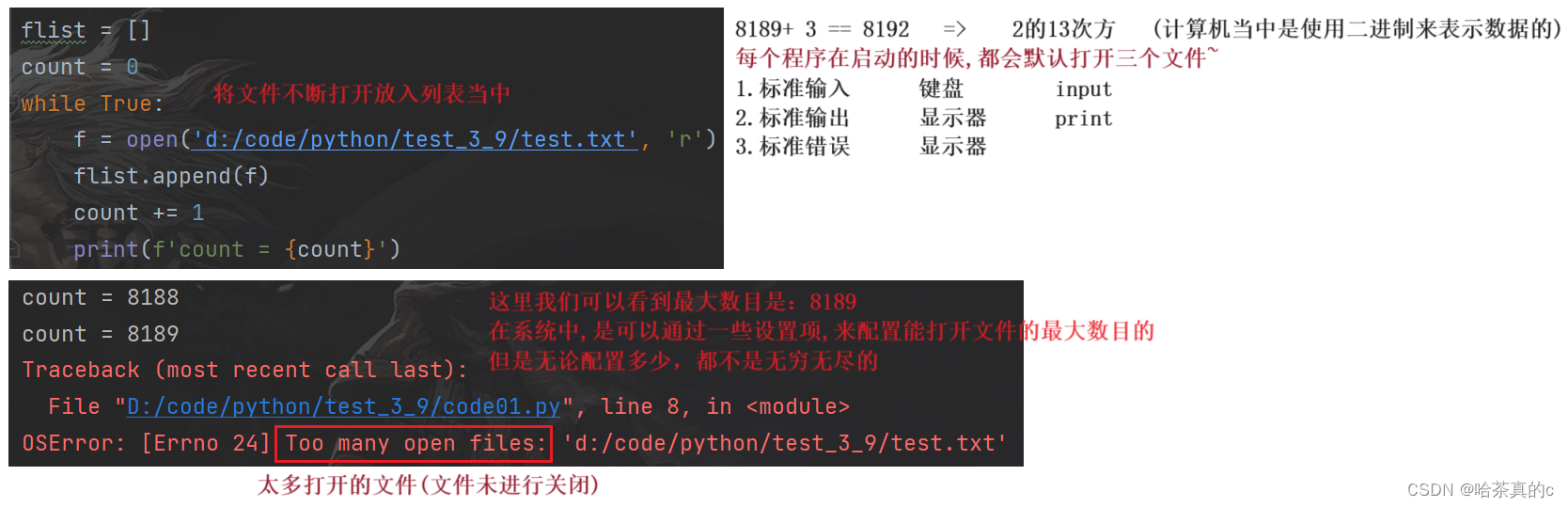
文件资源泄露是一个挺重要的问题,不会第一时间暴露出来,而是在角落里冷不丁偷袭一下(突然服务器报警告,崩溃瘫痪)
Python有一个重要的机制,垃圾回收机制(GC),自动的把不使用的变量进行释放
虽然 Python给了我们一个后手,让我们一定程度的避免上述问题,但是也不能完全依赖自动释放机制
因为自动释放不一定及时,因此还是要尽量手动释放万无一失
3. 写文件
文件打开之后, 就可以写文件了.
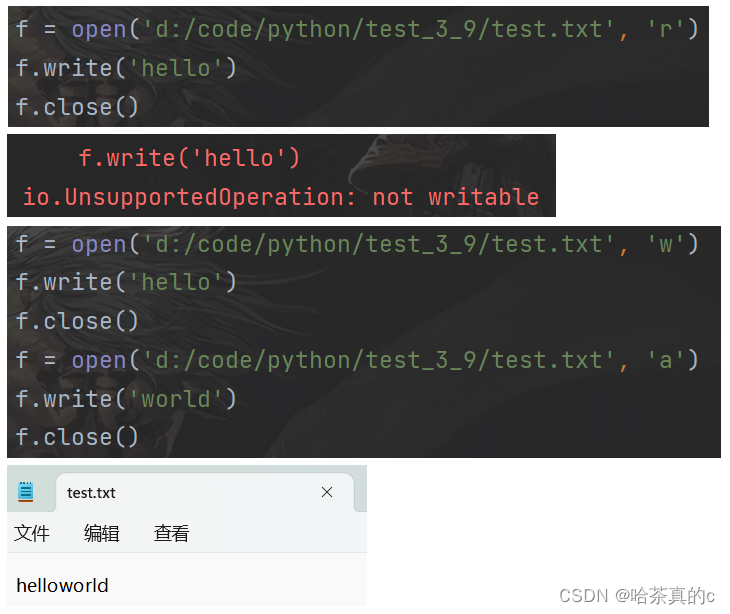
写文件, 要使用写方式打开, open 第二个参数设为 ‘w’
使用 write 方法写入文件
f = open('d:/code/python/test_3_9/test.txt', 'w')
f.write('hello')
f.close()
用记事本打开文件, 即可看到文件修改后的内容.
如果是使用 ‘r’ 方式打开文件, 则写入时会抛出异常.
使用 ‘w’ 一旦打开文件成功, 就会清空文件原有的数据.
使用 ‘a’ 实现 “追加写”, 此时原有内容不变, 写入的内容会存在于之前文件内容的末尾.
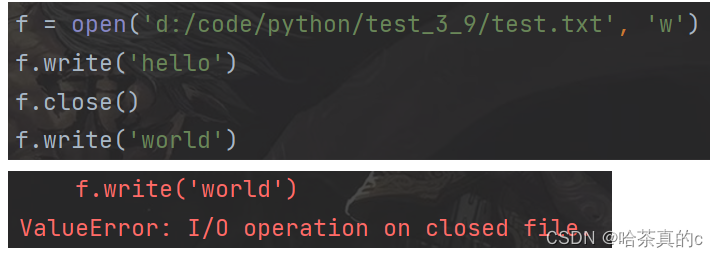
针对已经关闭的文件对象进行写操作, 也会抛出异常
4. 读文件
读文件内容需要使用 ‘r’ 的方式打开文件
使用 read 方法完成读操作. 参数表示 “读取几个字符”
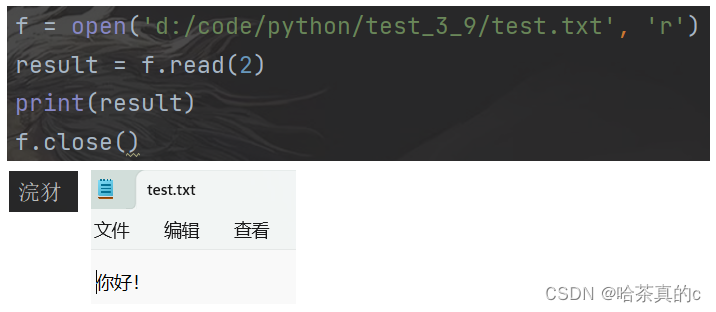
计算机表示中文的时候, 会采取一定的编码方式, 我们称为 “字符集”
所谓 “编码方式” , 本质上就是使用数字表示汉字.
我们知道, 计算机只能表示二进制数据. 要想表示英文字母, 或者汉字, 或者其他文字符号, 就都要通过编码.
最简单的字符编码就是 ascii. 使用一个简单的整数就可以表示英文字母和阿拉伯数字.
但是要想表示汉字, 就需要一个更大的码表. 一般常用的汉字编码方式, 主要是 GBK 和 UTF-8
必须要保证文件本身的编码方式, 和 Python 代码中读取文件使用的编码方式匹配, 才能避免出现上述问题.
Python3 中默认打开文件的字符集跟随系统, 而 Windows 简体中文版的字符集采用了 GBK,
所以如果文件本身是 GBK 的编码, 直接就能正确处理.
如果文件本身是其他编码(比如 UTF-8), 那么直接打开就可能出现上述问题
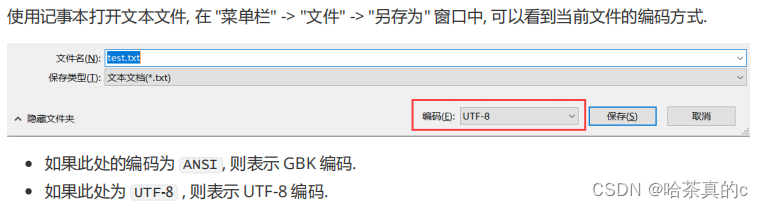
此时修改打开文件的代码, 给 open 方法加上 encoding 参数, 显式的指定为和文本相同的字符集, 问题即可解决.

如果文件是多行文本, 可以使用 for 循环一次读取一行
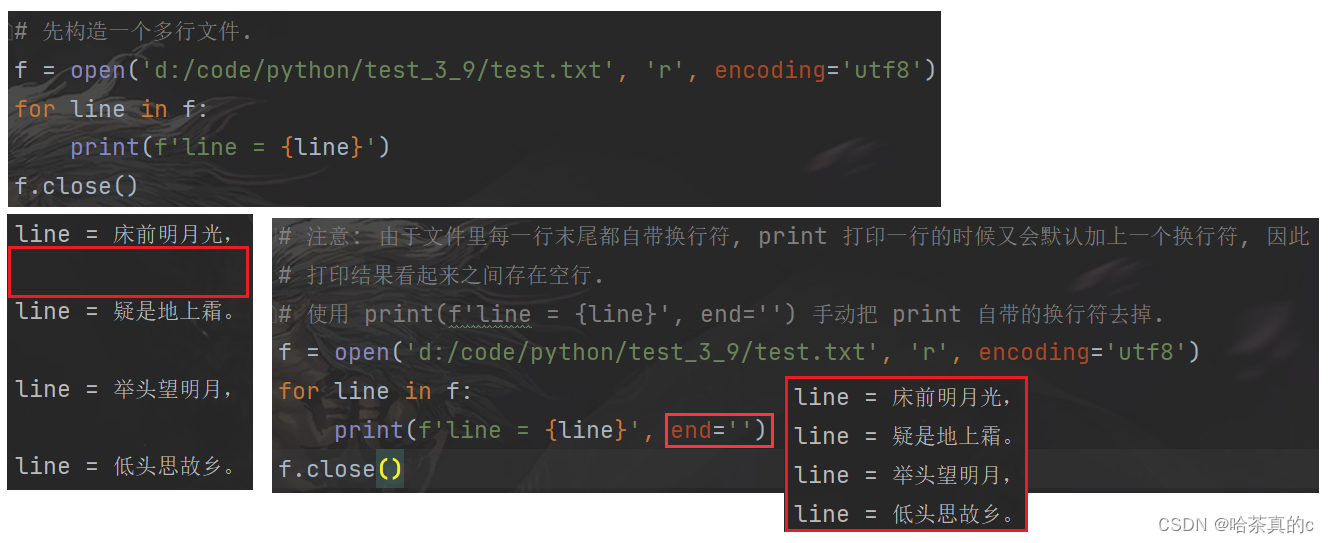
使用 readlines 直接把文件整个内容读取出来, 返回一个列表. 每个元素即为一行.
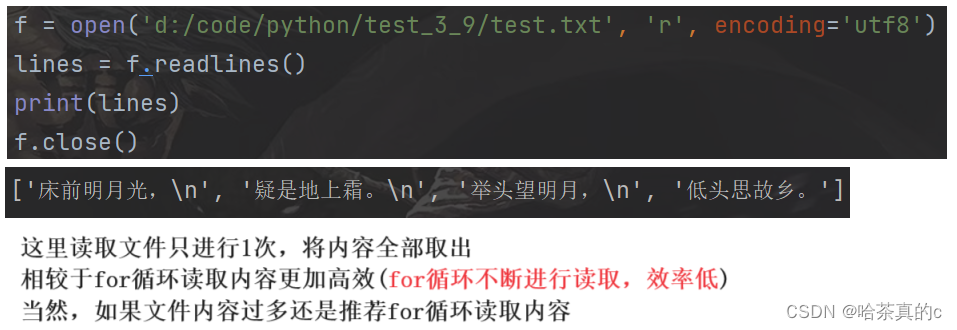
使用上下文管理器
打开文件之后, 是容易忘记关闭的. Python 提供了 上下文管理器 , 来帮助程序猿自动关闭文件.
使用 with 语句打开文件. 当 with 内部的代码块执行完毕后, 就会自动调用关闭方法.

> 不同语言针对文件自动关闭的处理方法:
> C++ ---> 智能指针
> Java ---> try with Resources
> Golang ---> defer
使用库
库 就是是别人已经写好了的代码, 可以让我们直接拿来用.
荀子曰: “君子性非异也,善假于物也”
一个编程语言能不能流行起来, 一方面取决于语法是否简单方便容易学习, 一方面取决于生态是否完备.
所谓的 “生态” 指的就是语言是否有足够丰富的库, 来应对各种各样的场景.
实际开发中, 也并非所有的代码都自己手写, 而是要充分利用现成的库, 简化开发过程.
按照库的来源, 可以大致分成两大类
标准库: Python 自带的库. 只要安装了 Python 就可以直接使用.
第三方库: 其他人实现的库. 要想使用, 需要额外安装.
咱们自己也可以实现 “第三方库” 发布出去, 交给别人来使用
标准库
认识标准库
Python 自身内置了非常丰富的库.
在 Python 官方文档上可以看到这些库的内容.
官方文档
简单来说, 主要是这些部分:
内置函数 (如 print, input 等)
内置类型 (针对 int, str, bool, list, dict 等类型内置的操作).
文本处理
时间日期
数学计算
文件目录
数据存储 (操作数据库, 数据序列化等).
加密解密
操作系统相关
并发编程相关 (多进程, 多线程, 协程, 异步等).
网络编程相关
多媒体相关 (音频处理, 视频处理等)
图形化界面相关
…
我们不需要把这些库的内容都背下来, 只要大概知道里面有啥, 需要用的时候能够找到即可.
使用 import 导入模块
使用 import 可以导入标准库的一个 模块
import [模块名]
所谓 “模块” , 其实就是一个单独的 .py 文件.
使用 import 语句可以把这个外部的 .py 文件导入到当前 .py 文件中, 并执行其中的代码.
习题
代码示例: 日期计算
1. 输入任意的两个日期, 计算两个日期之间隔了多少天.
使用 import 语句导入标准库的 datetime 模块
使用 datetime.datetime 构造两个日期. 参数使用 年, 月, 日 这样的格式.
两个日期对象相减, 即可得到日期的差值.
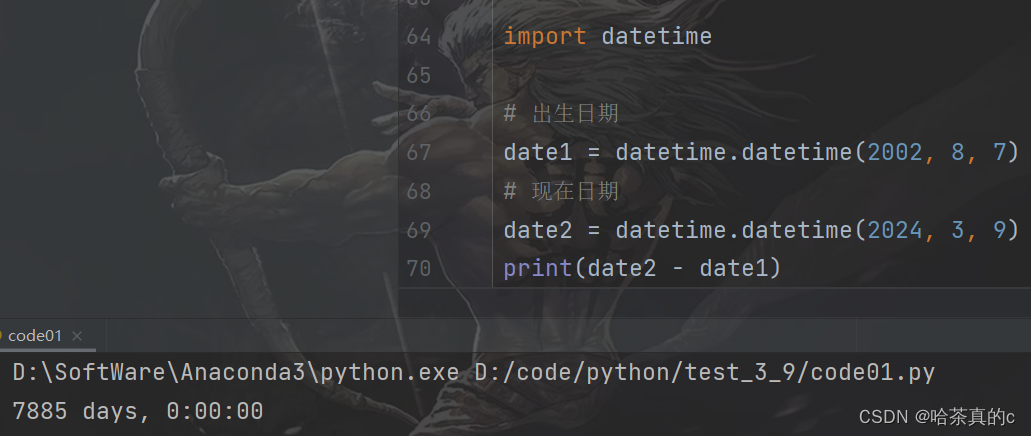
可以看到博主已经活了7000多天了,快来算算你的日子吧!
代码示例: 字符串操作
字符串是 Python 的内置类型, 字符串的很多方法不需要导入额外的模块, 即可直接使用.
2. 剑指offer 58:翻转单词顺序
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。
例如输入字符串"I am a student. “,则输出"student. a am I”。
# 分为以下三步操作:
# 使用 str 的 split 方法进行字符串切分, 指定 空格 为分隔符. 返回结果是一个列表.
# 使用列表的 reverse 方法进行逆序.
# 使用 str 的 join 方法进行字符串拼接. 把列表中的内容进行合并.
def reverseWords(s):
tokens = s.split()
tokens.reverse()
return ' '.join(tokens)
print(reverseWords('I am a student.'))

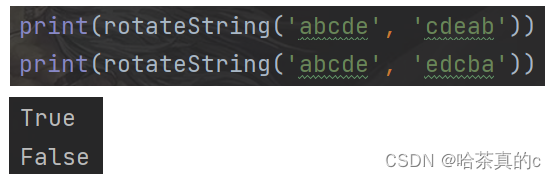
3. leetcode 796:旋转字符串
# 给定两个字符串, s 和 goal。如果在若干次旋转操作之后,s 能变成 goal ,那么返回 true 。
# s 的 旋转操作 就是将 s 最左边的字符移动到最右边。
# 例如, 若 s = 'abcde',在旋转一次之后结果就是'bcdea' 。
# 使用 len 求字符串的长度. 如果长度不相同, 则一定不能旋转得到.
# 将 s 和 自己 进行拼接, 然后直接使用 in 方法来判定 goal 是否是 s + s 的子串.
def rotateString(s, goal):
if len(s) != len(goal):
return False
return goal in (s + s)
4. leetcode 2255, 统计是给定字符串前缀的字符串数目
给你一个字符串数组 words 和一个字符串 s,其中 words[i] 和 s 只包含小写英文字母,请你返回 words 中是字符串s前缀的字符串数目.
一个字符串的 前缀 是出现在字符串开头的子字符串。子字符串 是一个字符串中的连续一段字符序列。
依次遍历 words 中的字符串,直接使用字符串的 startswith 方法即可判定当前字符串是否是 s 的前缀.
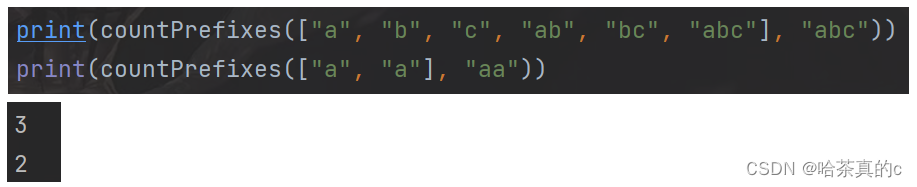
def countPrefixes(words, s):
res = 0 # 符合要求字符串个数
for word in words:
if s.startswith(word):
res += 1
return res
关于字符串的更多操作, 参考官方文档
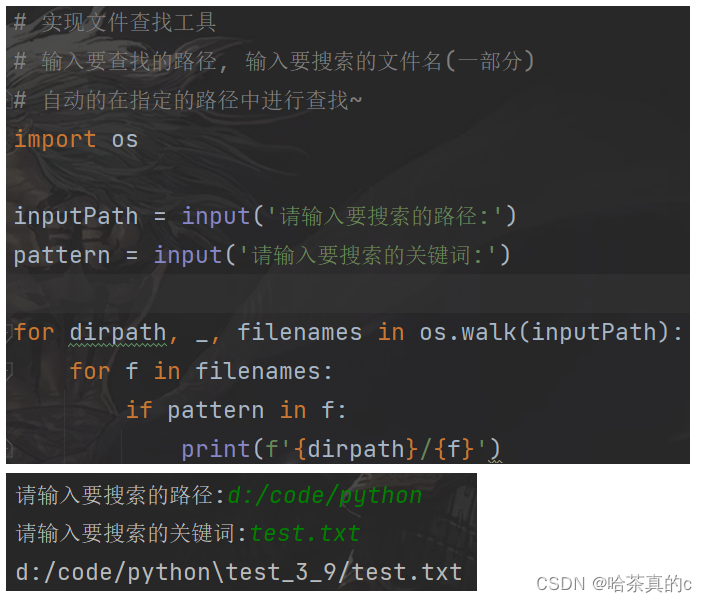
5. 代码示例: 文件查找工具
指定一个待搜索路径, 同时指定一个待搜索的关键字.
在待搜索路径中查找是否文件名中包含这个关键字.
使用 os.walk 即可实现目录的递归遍历.
os.walk 返回一个三元组, 分别是 当前路径 , 当前路径下包含的目录名 (多个), 当前路径下包含的文件名 (多个)
关于 os 模块的更多操作, 参考官方文档
第三方库
认识第三方库
第三方库就是别人已经实现好了的库, 我们可以拿过来直接使用.
虽然标准库已经很强大了, 但是终究是有限的. 而第三方库可以视为是集合了全世界 Python 程序猿的智
慧, 可以说是几乎无穷无尽.
问题来了, 当我们遇到一个需求场景的时候, 如何知道, 该使用哪个第三方库呢?
就需要用到下面几个网站了:
当我们确定了该使用哪个第三方库之后, 就可以使用 pip 来安装第三方库了.
使用 pip
pip 是 Python 内置的 包管理器.
所谓 包管理器 就类似于我们平时使用的手机 app 应用商店一样.
第三方库有很多, 是不同的人, 不同的组织实现的.
为了方便大家整理, Python 官方提供了一个网站PyPI来收集第三方库.
PyPI网站链接,
其他大佬写好的第三方库也会申请上传到 PyPI 上.
这个时候就可以方便的使用 pip 工具来下载 PyPI 上的库了.
pip 在我们安装 Python 的时候就已经内置了. 无需额外安装.
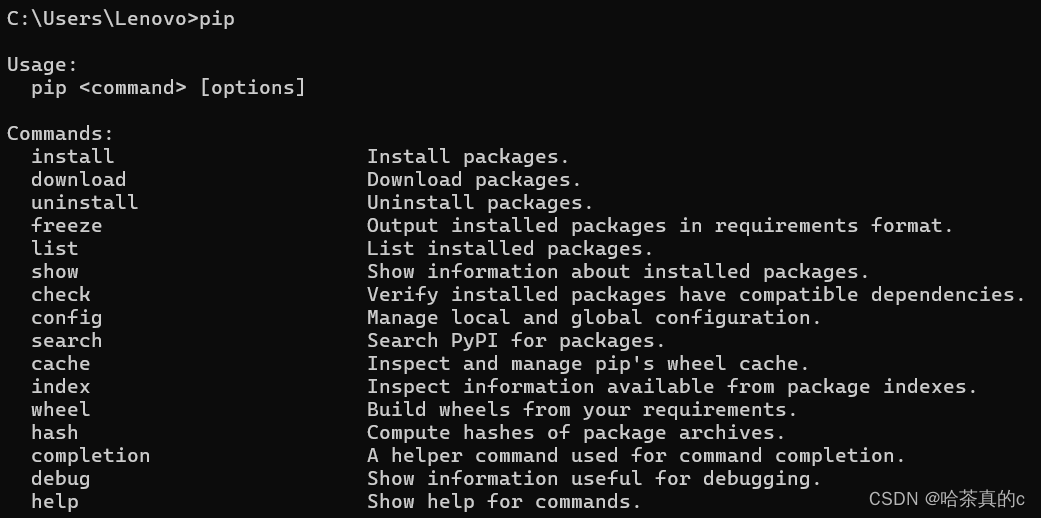
pip 是一个可执行程序, 就在 Python 的安装目录中.
打开 cmd, 直接输入 pip. 如果显示以下帮助信息, 说明 pip 已经准备就绪.
如果最开始在安装 Python 的时候勾选了
那么 pip 就是默认可用的.

如果提示:
‘pip’ 不是内部或外部命令,也不是可运行的程序
或批处理文件。
则说明没有正确的把 pip 加入到 PATH 中, 可以手动把 pip 所在的路径加入到 PATH 环境变量中.
(参考简书链接)
或者卸载重装 Python, 记得勾上上述选项, 也许是更简单的办法.
使用以下命令, 即可安装第三方库
pip install [库名]
注意: 这个命令需要从网络上下载, 使用时要保证网络畅通.
安装成功后, 即可使用 import 导入相关模块, 即可进行使用.
注意: 如果使用 pip 安装完第三方库之后, 在 PyCharm 中仍然提示找不到对应的模块, 则检查 Settings -> Project -> Python Interpreter , 看当前 Python 解释器设置的是否正确. (如果一个机器上安装了多个版本的 Python, 容易出现这种情况).
6. 代码示例: 生成二维码
(1) 通过搜索引擎, 确定使用哪个库
得到情报qrcode 这个库, 可以用来生成二维码
(2) 查看 qrcode 文档
在 PyPI 上搜索 qrcode
点击则进入 qrcode 的详情页.
文档开头描述了如何安装 qrcode

页面中央位置描述了 qrcode 库的使用方法

(3) 使用 pip 安装
pip install qrcode[pil]
注意: pip 安装的时候可能会有警告, 提示使用的 pip 版本太低. 这个警告我们不必处理, 不影响我们正常使用.
(4) 编写代码
按照文档给出的示例, 模仿一段代码.
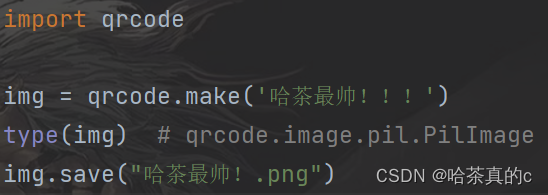

使用微信或者其他工具扫码, 即可看到二维码内容.
所谓二维码, 本质上就是使用黑白点阵表示一个字符串.
我们日常使用的二维码内部一般是一个 URL, 扫码后会自动跳转到对应的地址, 从而打开一个网页.
7. 代码示例: 操作 excel
读取 excel 可以使用 xlrd 模块. 文档地址: https://xlrd.readthedocs.io/en/latest/
修改 excel 可以使用 xlwt 模块. 文档地址: https://xlwt.readthedocs.io/en/latest/
此处以 xlrd 为例, 演示 excel 的基本操作.
需求 有如下 excel 表格 D:\code\python\test_3_9\学生成绩.xlsx
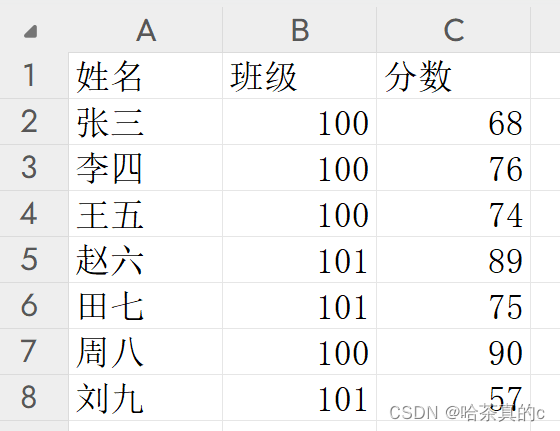
求 100 班的同学的平均分.
虽然 excel 自身支持很强大的功能, 也可以求和, 求平均值. 但是如果是稍微复杂的需求, 操作起来可能就没那么方便了.
- 安装 xlrd
pip install xlrd==1.2.0

注意: 此处要指定版本号安装. 如果不指定版本号, 则安装最新版. 最新版里删除了对 xlsx 格式文件的支持.
- 编写代码
使用 open_workbook 方法打开一个 excel 文件.
使用 xlsx.sheet_by_index(0) 获取到 0 号标签页.
使用 table.nrows 获取到表格的行数.
使用 table.cell_value(row, col) 获取到表格中 row, col 位置的元素值.
import xlrd
# 1. 打开 xlsx 文件
xlsx = xlrd.open_workbook('D:/code/python/test_3_9/学生成绩.xlsx')
# 2. 获取 0 号标签页. (当前只有一个标签页)
table = xlsx.sheet_by_index(0)
# 3. 获取总行数
nrows = table.nrows
# 4. 遍历数据
count = 0
total = 0
for i in range(1, nrows):
# 使用 cell_value(row, col) 获取到指定坐标单元格的值.
classId = table.cell_value(i, 1)
if classId == 100:
total += table.cell_value(i, 2)
count += 1
print(f'平均分: {total / count}')
计算结果:平均分: 77.0
9. 代码示例: “程序猿鼓励师”
监听键盘按键, 每按键100下, 就自动播放一个音频, 鼓励一下辛苦搬砖的自己.
- 安装第三方依赖
pynput 用于监听键盘按键. 注意版本不要用最新.
playsound 用于播放音频.
pip install pynput==1.6.8
pip install playsound==1.2.2
2) 准备音频文件
此处准备了一个 她说.mp3 放到和 py 代码同级目录中.
3) 编写代码
使用 from import 的格式直接导入模块中的指定对象/函数.
使用 keyboard.Listener 监听键盘按键. 其中 on_release 会在释放按键时被调用.
使用 listener.start 启动监听器. 为了防止程序直接退出, 使用 listener.join 让程序等待用户按键.
使用 count 计数, 每隔 10 次, 调用 playsound 播放音频文件.
from pynput import keyboard
from playsound import playsound
count = 0
def on_release(key):
print(key)
global count
count += 1
if count % 10 == 0:
playsound('ding.mp3')
listener = keyboard.Listener(
on_release=on_release)
listener.start()
listener.join()
运行程序, 即可感受到效果.
4) 改进代码
上述代码在执行过程中, 会感觉到播放音频会导致按键卡顿. 可以使用多线程解决这个问题.
关于多线程的知识, 在此处不详细介绍.
使用 threading.Thread 引入多线程类.
使用 Thread 的构造函数来构造一个线程. target 表示线程要执行的任务, args 表示 target中要调用函数的参数.
使用 Thread.start() 启动线程.
from pynput import keyboard
from playsound import playsound
from threading import Thread
count = 0
def on_release(key):
print(key)
global count
count += 1
if count % 10 == 0:
t = Thread(target=playsound, args=('ding.mp3',))
t.start()
#playsound('ding.mp3')
listener = keyboard.Listener(
on_release=on_release)
listener.start()
listener.join()
from pynput import keyboard
from playsound import playsound
from threading import Thread
soundList = ['shesai.mp3']
# 记录当前用户按了多少次键盘
count = 0
def onRelease(key):
"""
这个函数, 就是在用户释放键盘按键的时候, 就会被调用到.
这个函数不是咱们自己主动调用的, 而是把这个函数交给了 Listener ,
由 Listener 在用户释放按键的时候自动调用.
像这样的不是咱们自己主动调用, 而是交给别人, 在合适的时机进行调用, 这样的函数, 叫做 "回调函数" (callback function)
:param key: 用户按下了哪个键
"""
print(key)
global count
count += 1
if count % 20 == 0:
# 播放音频!
# 生成随机数
# i = random.randint(0, len(soundList) - 1)
# 此处的播放音频, 消耗时间比较多, 可能会引起输入的卡顿(不流畅)
# 可以创建一个线程, 在线程里播放音频!!
# playsound(soundList[i])
t = Thread(target=playsound, args=(soundList[0], ))
t.start()
# 当我们创建好 Listener 之后, 用户的键盘按键动作就会被捕获到.
# 还希望在捕获到之后能够执行一段代码.
listener = keyboard.Listener(on_release=onRelease)
listener.start()
listener.join()
# 编写一段代码, 感受一下这个程序的效果
# 播放音频可能出现卡顿
# 再次感受下代码的效果, 此时感觉就流畅了吧, 现在就非常流畅了~~~
# 现在是把频率降低到 20 下播放一次, 感觉是不是好点啦?