前言
大语言模型(LLM)自面世以来即展示了其创新能力,但 LLM 面临着幻觉等挑战。如何通过整合外部数据库的知识,检索增强生成(RAG)已成为通用和可行的解决方案。这提高了模型的准确性和可信度,特别是对于知识密集型任务,并允许持续的知识更新和特定领域信息的集成。在 RAG 过程中,通常向量数据库会是其非常重要的组件,主要体现在数据存储、高效查询等方面,它可以为 RAG 提供丰富的数据来源和输入方式,并支持高效的计算和处理,从而促进生成式 AI 的发展和应用。Amazon DocumentDB(兼容 MongoDB)现已支持向量数据库以毫秒级的响应时间存储、索引和搜索数百万个向量。向量是非结构化数据的数字表示,例如文本,由机器学习(ML)模型创建,有助于捕捉底层数据的语义含义。Amazon DocumentDB 的向量搜索可以存储来自 Amazon Bedrock、Amazon SageMaker,以及其他第三方或专有模型等的向量。
借助 Amazon DocumentDB 的向量搜索功能(Vector Search),可以轻松地为机器学习(包括生成式 AI 应用程序)设置、操作和扩展向量数据库。在一个云原生文档数据库引擎里, 实现向量和业务标量数据的统一管理,不再需要花费大量时间熟悉和管理独立的专用向量数据库引擎,以及跨数据引擎同步数据。向量搜索功能与 LLM 相结合,能够根据含义搜索数据库,从而解锁各种用例,包括语义搜索、产品推荐、个性化和聊天机器人。
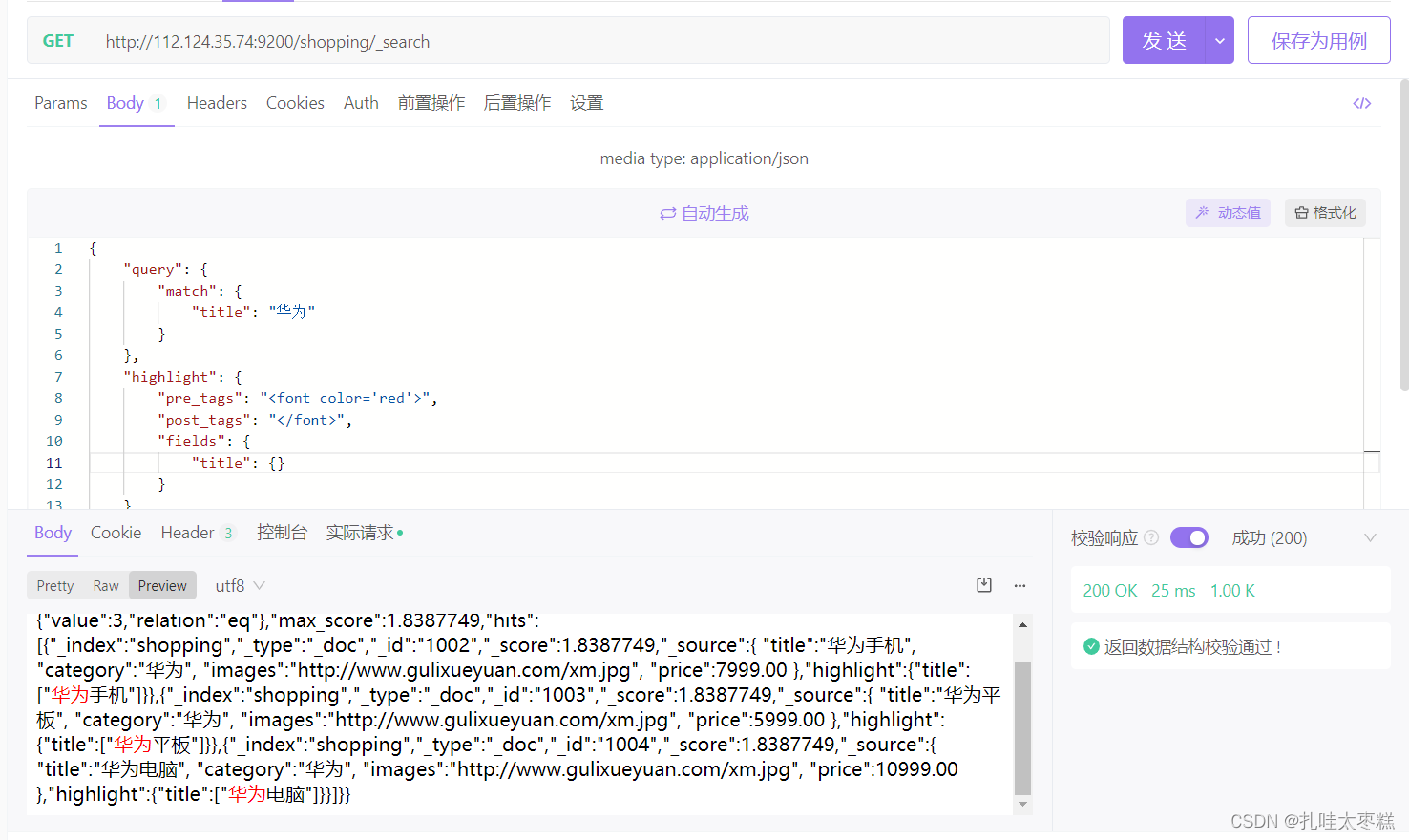
Amazon DocumentDB 的向量搜索将 JSON 文档数据库的灵活性、丰富的查询功能、全文检索与向量搜索的能力相结合。使用现有 Amazon DocumentDB 灵活的文档结构数据,结合向量数据存储、索引(最多可支持索引 2000 维,目前支持 IVFFlat 和 HNSW 索引)和搜索, 来构建机器学习和生成 AI 用例,如语义搜索体验、产品推荐、个性化、聊天机器人、欺诈检测和异常检测。Amazon DocumentDB 的向量搜索在所有可用 Amazon DocumentDB 的区域,基于 DocumentDB 5.0 实例的集群上可用。
Amazon DocumentDB 支持全文检索,可以针对文本索引字段中搜索部分或全部关键字,对大型字符串数据执行特定术语或短语的文本搜索,使用权重为索引字段分配不同的级别,并根据相关性对搜索结果进行排序。可以用于帮助客户构建知识库系统。和向量查询结合,可以实现 RAG 双路召回的功能。Amazon DocumentDB 结合向量和文本搜索可实现混合搜索,使用双路召回的方式对用户的查询进行检索,分别对查询语句和文档进行向量化和相似度计算以及基于分词的全文检索,两个查询并行执行。而针对返回的结果,再根据特定的逻辑进行合并和排序(比如加权平均、排序融合等),双壁合一得到一个最终的检索结果集合。使用混合搜索来实现双路召回的优势是,它可以克服向量检索和关键词检索各自的局限性, 获得更精准和更多样化的检索结果。
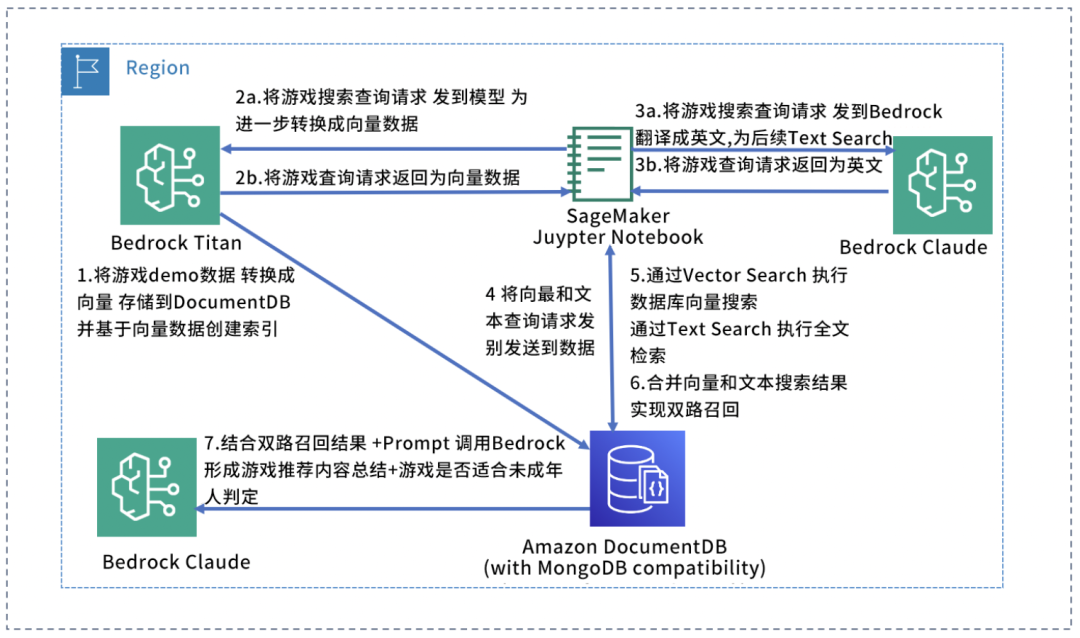
本文将展示如何采用 Amazon DocumentDB 和 Amazon Bedrock 构建游戏行业产品推荐,文中的 Demo 已经接入了目前最新发布的 Bedrock Claude 3 Sonnet 模型。Anthropic 目前的评估表明,Claude 3 模型系列在数学应用题解决(MATH)和多语言数学(MGSM)基准(目前用于大语言模型的关键基准)方面优于同类模型。另外我们使用了 Amazon Bedrock Titan 模型来生成向量,并使用 DocumentDB 将 Titan 生成的向量存储在 Amazon DocumentDB 数据库中,利用 DocumentDB Vector Search 的相似性向量搜索和 DocumentDB Text Search 全文检索功能实现 RAG 双路召回,并将 RAG 双路召回合并结果,返回给 Amazon Bedrock Claude 3 Sonnet,进行内容总结归并。
架构
环境部署
通过 Cloudformation 部署所需的资源
(区域请选择 us-east-1)
为了简化示例环境的入门体验,我们创建了 Amazon CloudFormation 基础模板来设置示例环境所需的资源。这些模板旨在部署一致的网络基础设施和客户端体验的软件包和组件,方便示例的开展。
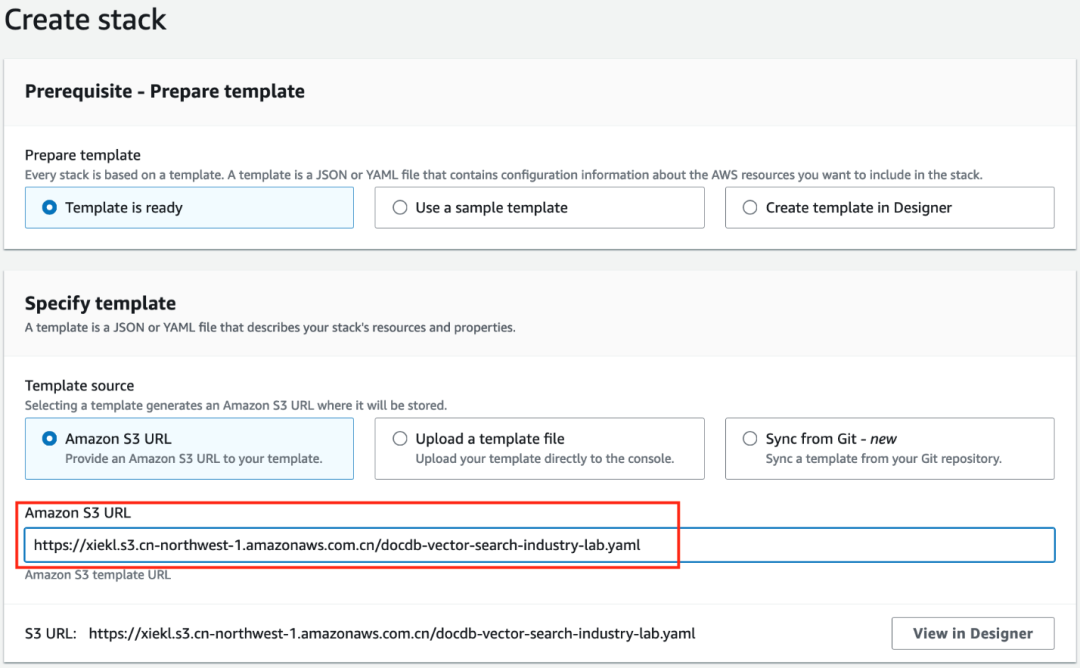
在亚马逊云科技控制台上点击 CloudFormation 页面,点击 Launch Stack(create stack)按钮来初始化您的环境。
请选择 Template source: Amazon S3 URL
请选择 Amazon S3 URL: https://xiekl.s3.cn-northwest-1.amazonaws.com.cn/docdb-vector-search-indutry-lab.yaml
在名为“Stack Name”的字段中,填入值为 docdb-vector-search-lab
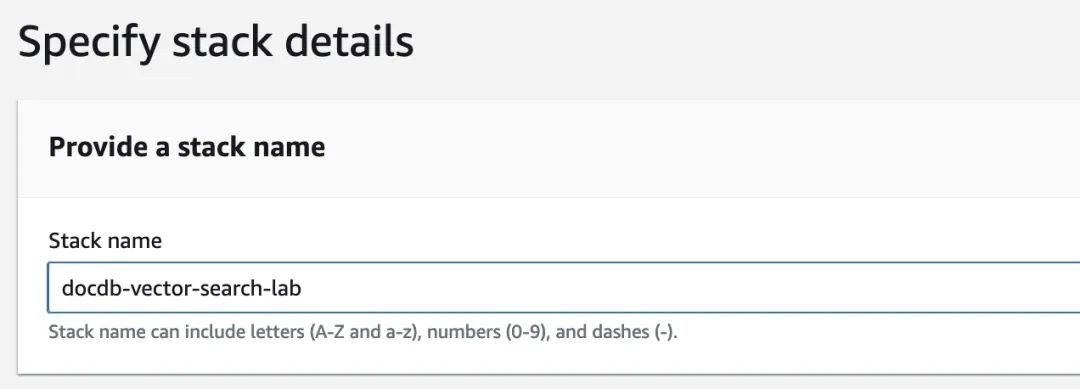
点击“下一步” ,在下一页接受默认设置,点击“下一步”。在最后一页,滚动到底部,选中确认创建 IAM 资源的复选框,然后点击“创建堆栈”
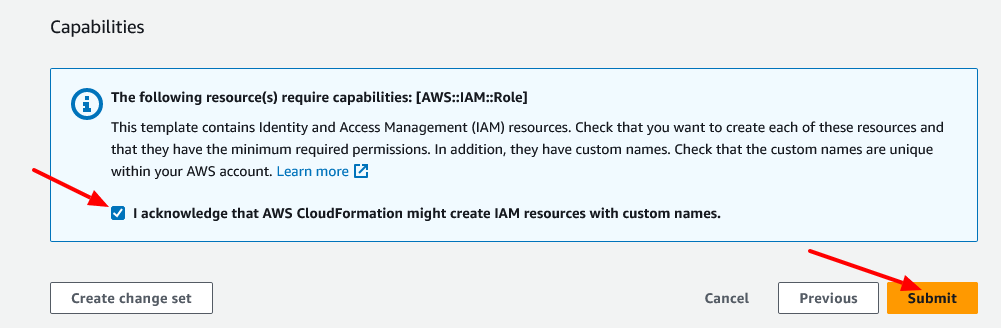
该 Stack 会创建:
一个新的 VPC、相关的子网、路由等
一个 docDB 数据库集群
一个 SageMaker Notebook 实例
支持的角色
完成这些配置大约需要十几分钟时间。您可以在主堆栈的堆栈详情页面监控状态
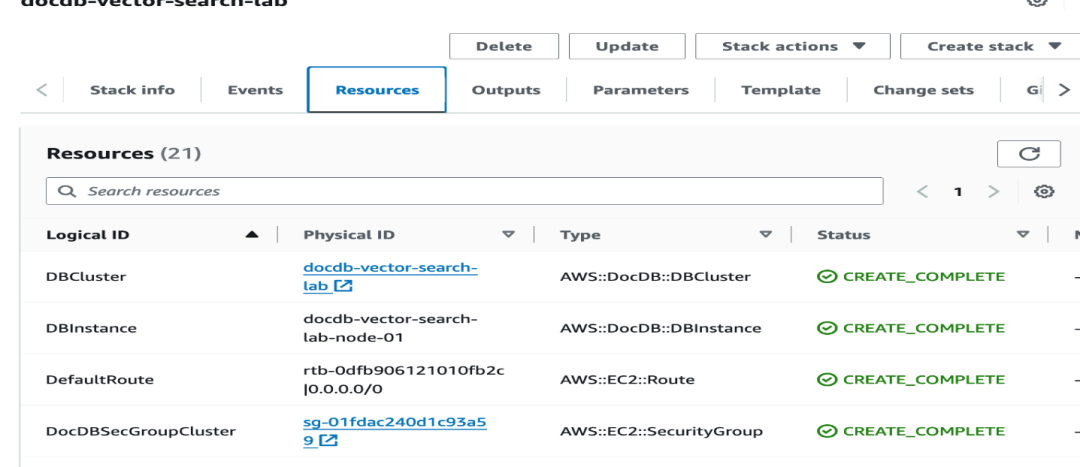
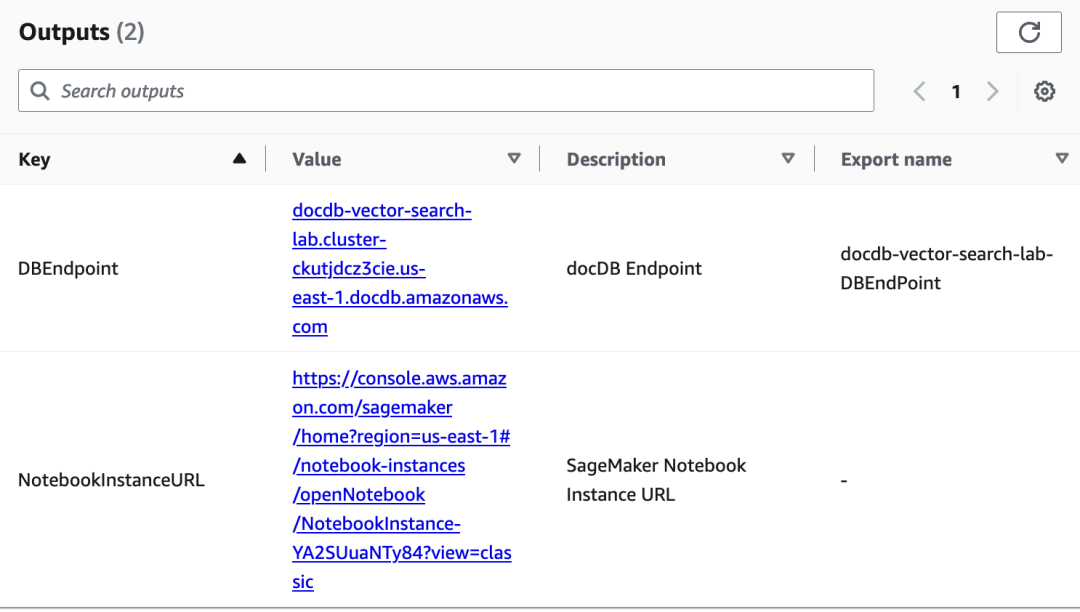
一旦状态变为 CREATE_COMPLETE,点击 Outputs 选项卡,记下 DBEndpint 和 NotebookInstanceURL 以备后用
赋予所访问的 Amazon Bedrock
大语言模型权限
访问 Amazon Bedrock Model Access 页面:https://us-east-1.console.aws.amazon.com/bedrock/home?region=us-east-1#modelaccess,选择 Manage Model Access
选中 Titan Embedding G1- Text 和 Claude 模型左侧的 checkbox,然后 save changes。
看到两个模型的 Access Status 为:Access granted

使用 Juypter Notebook
本示例采用了 Jupyter Notebook 来与 Bedrock 和 DocumentDB 数据库进行交互。Jupyter Notebook 是一个开源 Web 应用程序,您可以用它来创建和共享包含实时代码、计算、可视化和叙述文本的文档。
打开 Jupyter Notebook
1. 转到 Amazon SageMaker 控制台,列出正在运行的 notebook 实例。您应该看到一个正在运行的实例,单击打开 Jupyter 的链接
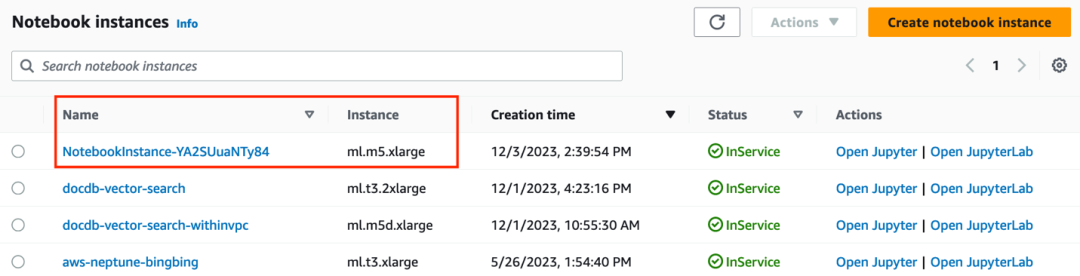
2. 点击 Open Jupyter,点击 Two-way-recall 目录
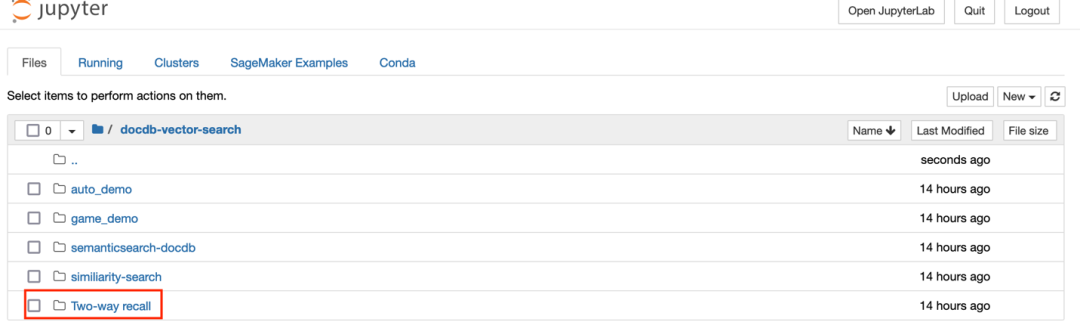
3. 点击 genai-docdb-similiarity-search-gaming.ipynb 文件以加载 Notebook 内容
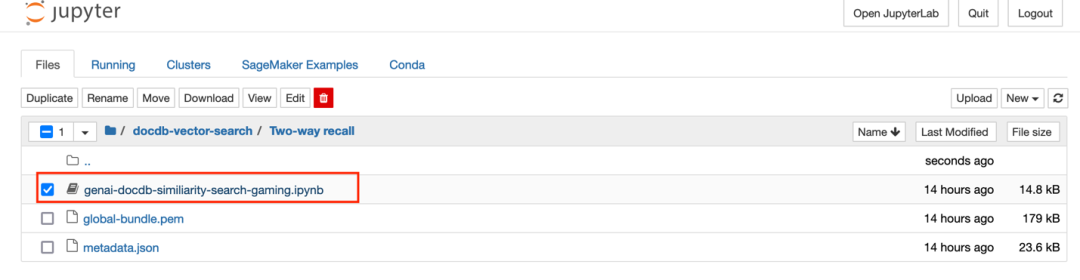
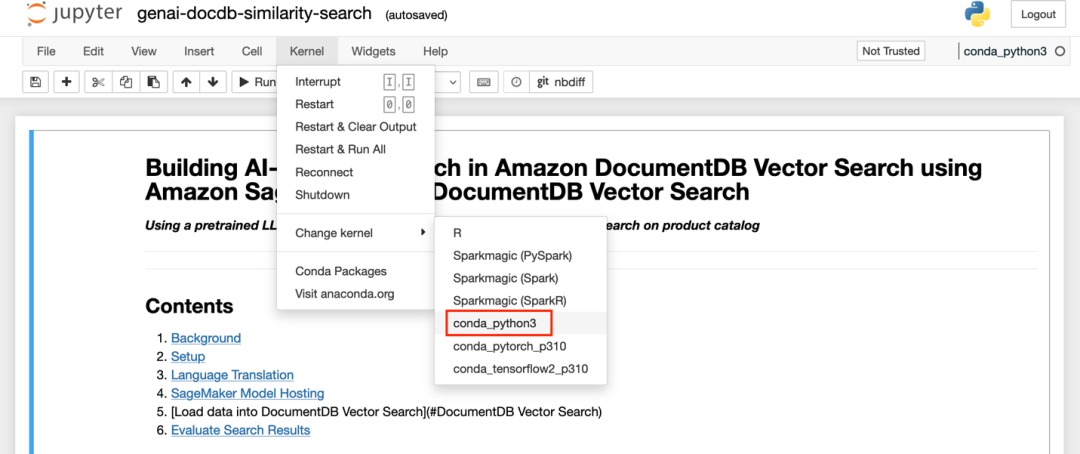
4. 在下拉菜单中选择 conda_python3 内核,然后点击 “设置内核” 。您可以在右上角查看所选的内核,如果您想更改现有的内核:
在 Notebook 中执行相似度查询
现在我们来构建游戏推荐方案:用户输入大致的游戏描述,系统能进行游戏推荐。
查找相似游戏的一个核心组件是把用户描述对应的固定长度的句子或者词进行向量化,也就是抽取“特征向量”。通常情况下这些向量是离线生成并存储起来的,以便后续查找时实现快速检索。本示例中使用了 Amazon Bedrock Titan 模型来生成向量数据。
为了实现对文本相似项目的高效搜索,我们使用 Amazon Bedrock Titan 模型生成固定长度的句子 Embedding,即“特征向量”,并使用 Amazon DocumentDB (MongoDB compatibility) 的 Vector Search 实现最近邻搜索扩展。DocumentDB Vector search 允许您存储和搜索向量空间中的点,并为这些点找到“最近邻”。使用案例包括产品推荐(基于搜索输入,匹配到最相近的产品)、图像识别和欺诈检测。
为了后续的全文检索,基于游戏英文描述做 Text Index,目前 DocumentDB 仅支持基于英文词根进行全文检索, 所以基于游戏英文描述创建索引。
本示例构建步骤为:
1)初始设置,准备环境调用 Amazon Bedrock Titan 模型;
2)将游戏 example dataset 生成特征向量;
3)把这些特征向量存储在 Amazon DocumentDB 向量数据类型中,创建向量索引。 基于游戏英文描述,创建文本索引;
4)探索一些示例查询,通过执行 DocumentDB 向量和文本搜索,实现 RAG 双路召回,合并双路召回结果,并结合 Bedrock Claude LLM 形成可视化结果。
具体步骤
安装示例所需的 python 库
!pip install -U pymongo tqdm boto3 requests scikit-image游戏 demo 数据
example: [
{“url”: “游戏图片url”,
“name”: “游戏名称”,
“descriptions”: [“游戏类别:免费开玩;英雄射击;多人;第一人称射击;射击”,
“游戏介绍: xxxxxx”,
“成人内容描述: 无暴力血腥。”],
“descriptions_en”:[“Game genres: Free to Play;Battle Royale;Multiplayer;Shoote”,
“Game Introduction: xxxxxx”,
“MATURE CONTENT DESCRIPTION: No violence or gore.”],
“recommendation”: “内存: 8 GB RAM,DirectX 版本: 11,网络: 宽带互联网连接,存储空间: 需要 35 GB 可用空间”}
]
import urllib.request
import os
import json
import boto3
from multiprocessing import cpu_count
from tqdm.contrib.concurrent import process_map
filename = 'metadata.json'
with open(filename) as json_file:
results = json.load(json_file)
if not os.path.exists(filename):
print ("metadata.json file not exits")
results[0]
print(results[0])Bedrock 模型环境准备
安装 langchain:
# for bedrock model call
%pip install langchain==0.0.305 --force-reinstall创建 Bedrock Client:
#for bedrock model call
import json
import os
import sys
import boto3
bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1")准备 Bedrock Titan 模型调用,为后续生成 Embedding 数据:
# for bedrock model call
from langchain.embeddings import BedrockEmbeddings
bedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1", client=bedrock_client)准备 Bedrock LLM Claude3 模型调用,并计算 LLM 执行时间:
# calculate your LLM(Claude3) execution time
import time
def timer_llm_claude3(prompt, if_print=1):
start_time = time.time()
body = json.dumps({
"max_tokens": 4096,
"messages": [{"role": "user", "content": prompt}],
"anthropic_version": "bedrock-2023-05-31"
})
response = bedrock_client.invoke_model(body=body, modelId="anthropic.claude-3-sonnet-20240229-v1:0")
response_body = json.loads(response.get("body").read())
end_time = time.time()
elapsed_time = end_time - start_time
if if_print == 1:
print("----------------------------------------- OutPut -----------------------------------------")
print("Elapsed time: ", elapsed_time, "seconds")
return response_body.get("content")[0]['text']Bedrock Titan 模型调用,生成 Embedding 数据:
# for Bedrock Embedding model call
def generate_embeddings(data):
r = bedrock_embeddings.embed_query(data)
return r在这一步中,我们将获取产品描述以及生成的向量,并将这些向量存储到 DocumentDB 中,通过调用函数 generate_embeddings,调用 Amazon Bedrock Titan 生成 Embedding 数据。
建立与 DocumentDB 的数据库连接:
# Set up a connection to your Amazon DocumentDB (MongoDB compatibility) cluster and creating the database
import pymongo
client = pymongo.MongoClient(
"docdb-vector-search-*******.com:27017",
username="masteruser",
password="******",
retryWrites=False,
tls='true',
tlsCAFile='global-bundle.pem')
db = client.similarity
collection = db.games修改 docDB Cluster Endpoint为CloudFormation output docDB endpoint
修改 password=” Password1″
生成向量数据,并将向量数据存储到 docDB,创建 docDB 向量索引(IvFflat 算法;相似度:欧距;维度:1536):
import pymongo
import boto3
import json
for x in results:
description1 = ' '.join(x.get('descriptions', []))
vector = generate_embeddings(description1)
record = { "name": x.get('name'),
"descriptions": description1,
"descriptions_en": ' '.join(x.get('descriptions_en', [])),
"recommendation":x.get('recommendation'),
"url": x.get('url'),
"descriptions_embeddings": vector}
rec_id1 = collection.insert_one(record)
collection.create_index ([("descriptions_embeddings","vector")], vectorOptions={
"lists": 1,
"similarity": "euclidean",
"dimensions": 1536})基于游戏英文描述字段,创建文本索引:
#DocumentDB Text Search
collection.create_index({"descriptions_en": "text"})执行 DocumentDB 向量和文本搜索,生成 RAG 双路召回,合并召回结果(游戏推荐结果),同时会形成 Prompt 调用 Bedrock Claude 模型来完成推荐内容总结归并,并判断游戏是否适合未成年人:
from skimage import io
import matplotlib.pyplot as plt
import requests
from langchain.prompts import PromptTemplate
multi_var_prompt = PromptTemplate(
input_variables=["instructions"],
template="""
Human:
你是一个优秀的游戏推荐员,需要你进行游戏的总结推荐
<Objective>
- 带上游戏名称和游戏类别
- 附上游戏介绍,需要进行优化总结
- 指出玩该游戏需要的主机配置
- 判断是否适合未成年人玩
</Objective>
<instructions>
{instructions}
</instructions>
你的目标是根据<Objective>里的目标,列出<instructions>里的游戏名称,游戏类别,游戏介绍,用户的主机配置并判断该游戏是否适合未成年人,不需要有其他无关的文字内容
Assistant:""")
def similarity_search(search_text):
en_response= timer_llm_claude3("你是一位翻译人员,将以下翻译成英文,不要多余的话术,只要翻译即可,翻译后的内容需要去掉game这个单词:"+search_text)
print(en_response)
data = {"inputs": search_text}
res1 = generate_embeddings(data['inputs'])向量搜索,返回相似度最接近的两个产品:
#Vector Search (向量搜索 返回相似度最接近的两个产品)
query = {"vectorSearch" : {"vector" : res1, "path": "descriptions_embeddings", "similarity": "euclidean", "k": 2}}
projection = {
"_id":0,
"name":1,
"recommendation":1,
"url":1,
"descriptions":1,
"descriptions_en":1,
"descriptions_embeddings": 1}
r = collection.aggregate([{'$search': query},{"$project": projection}])基于游戏英文描述进行文本搜索,按返回 Score 进行排序:
#Text Search (基于游戏英文描述进行文本搜索, 按返回Score进行排序)
tsr = collection.find({"$text": {"$search": en_response}}, {"score": {"$meta": "textScore"}}).sort({"score": {"$meta": "textScore"}})
urls = []
plt.rcParams["figure.figsize"] = [7.50, 3.50]
plt.rcParams["figure.autolayout"] = True合并 RAG 双路召回结果:
# merge two-way recall result (合并RAG双路召回结果)
merged_list = []
for doc in tsr:
merged_list.append(doc)
for doc in r:
merged_list.append(doc)
unique_set = set()
result = []
for item in merged_list:
dict_str = str(item['name'])
print(dict_str)
if dict_str not in unique_set and len(result)<2:
unique_set.add(dict_str)
result.append(item)
for x in result:
# print(x)
# Pass in values to the input variables
prompt = multi_var_prompt.format(instructions="游戏名称:"+x["name"] + ".\n游戏描述:" +x["descriptions"] +".\n主机配置建议:"+ x["recommendation"])
response= timer_llm_claude3(prompt)
print(response)
url = x["url"].split('?')[0]
urldata = requests.get(url).content
a = io.imread(url)
plt.imshow(a)
plt.axis('off')
plt.show()现在我们调用上面的函数进行一些搜索。比如输入多人射击游戏:
similarity_search(“多人射击游戏”)
以下是根据上述向量和文本搜索,生成 RAG 双路召回,合并双路召回结果,结合 LLM 形成的游戏推荐内容:
——————OutPut ——————
Elapsed time: 4.0840065479278564 seconds
游戏名称:虚拟射击游戏 1
游戏类别:免费开玩、英雄射击、多人、第一人称射击、射击
游戏介绍:虚拟射击游戏 1 是一款免费的大逃杀英雄射击游戏,玩家可控制各种拥有独特技能的传奇角色,体验战术小队玩法和创新游戏元素,在边境之地与其他玩家展开激烈对决。游戏提供丰富的角色选择、深度的战术玩法和革新元素,带来全新的大逃杀竞技体验。
主机配置:
– 内存:8 GB RAM
– DirectX 版本:11
– 网络:宽带互联网连接
– 存储空间:需要 35GB 可用空间
适合年龄:由于游戏没有暴力血腥内容,适合未成年人玩。

——————OutPut ——————
Elapsed time:3.8321468830108643
游戏名称:虚拟射击游戏 2
游戏类别:第一人称射击;射击;多人;竞技;动作;电竞
优化总结:
虚拟射击游戏 2 是一款优秀的竞技类第一人称射击游戏,提供了逼真的渲染效果、先进的网络系统、强大的社区创意工坊工具等。游戏包含全球及区域排行榜、升级后的地图、动态烟雾弹等新元素,为玩家带来革命性的游戏体验。此外,游戏还拥有全新设计的声画效果,令画面声音更加震撼。
主机配置:
内存:8 GB RAM
显卡:1 GB 或以上
DirectX 版本:11
存储空间:需要 85 GB 可用空间
不适合未成年人:
虚拟射击游戏 2 包含强烈的暴力和血腥内容,因此不太适合未成年人游玩。

总结
将 Amazon DocumentDB 和 Amazon Bedrock 无缝集成,在同一个 Amazon DocumentDB 云原生文档数据库引擎中,将向量和业务标量数据统一存储,将向量搜索和文本搜索无缝集成,能够快速构建 RAG 双路召回,为优化基于 LLM 产品目录相似性搜索体验提供了高效的解决方案。企业可以提高相似性搜索、个性化推荐和欺诈检测的准确性和速度,由此进一步提高用户满意度和提供更加个性化的体验。
本篇作者

刘冰冰
亚马逊云科技数据库解决方案架构师,负责基于亚马逊云科技的数据库解决方案的咨询与架构设计,同时致力于大数据方面的研究和推广。在加入亚马逊云科技之前曾在 Oracle 工作多年,在数据库云规划、设计运维调优、DR 解决方案、大数据和数仓以及企业应用等方面有丰富的经验。

周宇翔
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构的咨询和设计,在 Edge,Serverless 等方向具有丰富的实践经验。目前专注于游戏行业。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!







![[Electron]中的BrowserView](https://img-blog.csdnimg.cn/direct/3dee076419304dff9e328c5e11bfcce7.png)
![[服务器]RTSP服务与ffmpeg推送-简单搭建-Windows与Linux](https://img-blog.csdnimg.cn/img_convert/52a97ddc940b5922702ff38fc58aabbf.png)