GPT-SoVITS是一个非常棒的少样本中文声音克隆项目,之前有一篇文章详细介绍过如何部署和训练自己的模型,并使用该模型在web界面中合成声音,可惜它自带的 api 在调用方面支持比较差,比如不能中英混合、无法按标点切分句子等,因此对原版api做了修改,详细使用说明如下。
修改后代码开源地址:github.com/jianchang51…
代码下载地址 github.com/jianchang51…
api2.py 使用示例
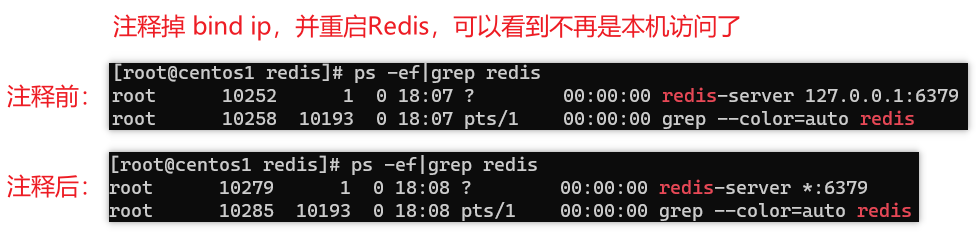
下载解压 github.com/jianchang51… ,将 api2.py 复制到GPT-SoVITS软件目录下,执行命令同自带api.py一样,只需要将名字 api.py 改成 api2.py。默认端口也是 9880,默认绑定 127.0.0.1
效果音频,听听这是谁
启动默认模型并指定默认参考音频 -dr -dt -dl
假设参考音频要使用根目录下的 123.wav ,音频文字是 “一二三四五六七。” ,音频语言是中文,那么命令如下:
.\runtime\python api2.py -dr "123.wav" -dt "一二三四五六七。" -dl "zh"

Linux下命令去掉 .\runtime 即可
如上述命令这样在启动后,指定的参考音频将作为默认配置,在api请求数据中未指定参考音频时,将使用。
启动默认模型并指定ip地址和端口 -a -p
假设要指定绑定内网ip 192.168.0.120 ,端口要使用 9001,不指定默认参考音频,那么执行如下命令:
.\runtime\python api2.py -a "127.0.0.1" -p 9001

启动自己训练好的模型 -s -g
在指定自己的模型时,必须确保同时指定参考音频。
训练好的模型可分别在软件目录下的 GPT_weights 和 SoVITS_weights 目录下寻找,以你训练时命名的模型名称开头,后跟e数字最大的那个即可。
.\runtime\python api2.py -s "SoVITS_weights/你的模型名" -g "GPT_weights/你的模型名" -dr "参考音频路径和名称" -dt "参考音频的文字内容,使用双引号括起来,确保文字内容里没有双引号" -dl zh|ja|en三者选一

强制在CPU上推理 -d cpu
默认将优先使用 CUDA 或 mps(Mac), 如果你想指定在CPU上运行,可以通过 -d cpu 指定
.\runtime\python api2.py -d cpu
注意 -d 后只能是 cpu 或 cuda 或 mps,并且只有在正确配置 cuda 后才能指定 cuda,只有Apple CPU Mac上才能指定 mps
全部按照默认运行
.\runtime\python api2.py
这种方式将使用默认模型,并且在 api 请求时必须指定参考音频、参考音频文字内容、参考音频语言代码,api 监听 9880 端口
可使用的语言代码 zh ja en
仅支持 中文、日语、英语 三种语言,对应只可使用 zh(代表中文或中英混合)、ja(代表日语或日英混合)、en(代表英语),使用 -dl 指定,如 -dl zh,-dl ja,-dl en
参考音频路径 -dr
参考音频填写以软件根目录为起点的相对目录,假如你的参考音频是直接放在软件根目录下,那么只需要填写带后缀的完整名字即可,比如 -dr 123.wav,如果是在子目录下,比如在 wavs 文件夹下,那么填写 -dr "wavs/123.wav"
参考音频的文字内容 -dt
参考音频的文字内容就是音频里的说话文字,需要正确填写标点符号,并使用英文双引号括起来。请注意,文字中不要再有英文双引号。
-dt "这里填写参考音频的文字内容,不要含有英文双引号"

可用的命令行参数:
模型相关参数
-s SoVITS模型路径, 默认模型无需填写,自训练模型在 SoVITS_weights 目录下
-g GPT模型路径, 默认模型无需填写,自训练模型在 GPT_weights 目录下
参考音频相关参数
-dr 默认参考音频路径,如果在根目录下,直接填写带后缀名字,否则加上 路径/名字
-dt 默认参考音频文本,音频的文字内容,以英文双引号括起来
-dl 默认参考音频内容的语种, “zh"或"en"或"ja”
设备和地址相关参数
-d 推理设备, “cuda”,“cpu”,“mps” 只有配置好了cuda环境才可指定cuda,只有Apple CPU上才可指定mps
-a 绑定地址, 默认"127.0.0.1"
-p 绑定端口, 默认9880
不常用参数,新手可忽略不必设置
-fp 使用全精度
-hp 使用半精度
-hb cnhubert路径
-b bert路径
API调用示例:
调用地址url: http://你指定的ip:指定的端口,默认是 http://127.0.0.1:9880
调用时不指定参考音频
启动 api2.py 时必须指定默认参考音频,才可在调用api时不指定,否则将报错:
GET方式调用,可直接浏览器中打开:
http://127.0.0.1:9880?text=亲爱的朋友你好啊,希望你的每一天都充满快乐。&text_language=zh

POST方式调用,以json格式传参:
json
复制代码
{
"text": "先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。",
"text_language": "zh"
}

手动指定当次所使用的参考音频:
GET方式:
http://127.0.0.1:9880?refer_wav_path=wavs/5.wav&prompt_text=为什么御弟哥哥,甘愿守孤灯。&prompt_language=zh&text=亲爱的朋友你好啊,希望你的每一天都充满快乐。&text_language=zh
POST方式:
json
复制代码
{
"refer_wav_path": "wavs/5.wav",
"prompt_text": "为什么御弟哥哥,甘愿守孤灯。",
"prompt_language": "zh",
"text": "亲爱的朋友你好啊,希望你的每一天都充满快乐。",
"text_language": "zh"
}

Api调用返回信息:
成功时: 返回 wav 音频流,可直接播放或保存到 wav文件中,http 状态码 200
失败时: 返回包含错误信息的 json, http 状态码 400
css
复制代码
{"code": 400, "message": "未指定参考音频且接口无预设"}
问题:想切换模型怎么办
api2.py和官方原版api.py 一样都不支持动态模型切换,也不建议这样做,因为动态启动加载模型很慢,而且在失败时也不方便处理。
解决方法是: 一个模型起一个api服务器,绑定不同的端口,在启动 api2.py 时,指定当前服务所要使用的模型和绑定的端口。
比如起2个服务,一个使用默认模型,绑定 9880 端口,一个绑定自己训练的模型,绑定 9881 端口,命令如下
默认模型 9880 端口: http://127.0.0.1:9880
.\runtime\python api2.py -dr "5.wav" -dt "今天好开心" -dl zh
自己训练的模型: http://127.0.0.1:9881
.\runtime\python api2.py -p 9881 -s "SoVITS_weights/mymode-e200.pth" -g "GPT_weights/mymode-e200.ckpt" -dr "wavs/10.wav" -dt "御弟哥哥,为什么甘愿守孤灯" -dl zh

在视频翻译软件中使用
如下图所示,打开 菜单-设置-GPT-SoVITS ,填写api地址,以及参考音频, 填写格式为一行一个参考音频
bash
复制代码
参考音频路径带后缀名称1#参考音频1文字内容#参考音频1语言
参考音频路径带后缀名称2#参考音频2文字内容#参考音频2语言
详细说明可看上一篇文章 在其他软件中调用GPT-SoVITS将文字合成语音

小技巧
中英混合的句子如何取得更好的训练效果:
英文单词前后要留有空格,不要直接和汉字连在一起,因为英文是靠空格区分的,如果连在一起,可能无法正确识别。
此api2.py 兼容视频翻译配音软件的 GPT-SoVITS 声音合成功能
最后
为了帮助大家更好的学习人工智能,这里给大家准备了一份人工智能入门/进阶学习资料,里面的内容都是适合学习的笔记和资料,不懂编程也能听懂、看懂,所有资料朋友们如果有需要全套人工智能入门+进阶学习资源包,可以在评论区或扫.码领取哦)~
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓
第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。


😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓