文章目录
- MapReduce原理剖析
- MapReduce之Map阶段
- MapReduce之Reduce阶段
- WordCount分析
- 多文件WordCount分析
- 实战wordCount案例开发
MapReduce原理剖析
- MapReduce是一种分布式计算模型,主要用于搜索领域,解决海量数据的计算问题
- MapReduce由两个阶段组成:Map和Reduce
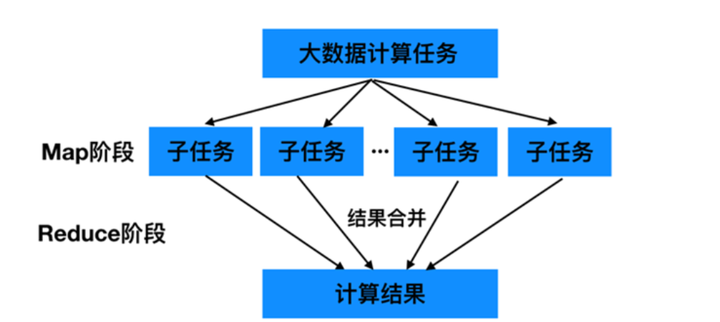
MapReduce之Map阶段
- 框架会把输入的文件夹划分为多个inputSplit,默认每个HDFS的block对应一个inputSplit。通过RecordReader类,把每个inputSplit解析程一个个<k,v>。默认每一行数据,会被解析程一个<k,v>
#比如有个文件
hello world
hello map
input split
# 第一步拆分
<0, hello world>
<12, hello map> #这里的12代表上一行的长度,也就是偏移量
<21, input split>
- 框架调用Mapper类中的map(…)函数,map函数的输入是<k1,v1>,输出是<k2,v2>,一个inputSplit对应一个Map Task
# 第二步数据会变成如下
<hello, 1>
<world, 1>
<hello, 1>
<map, 1>
<input, 1>
<split, 1>
-
框架对map输出的<k2,v2>进行分区,不同分区中的<k2,v2>由不同的Reduce Task处理,默认只有1个分区
-
框架对每个分区中的数据按照k2进行排序分组。分组值的是相同的k2的v2分成一个组
# 排序
<hello, 1>
<hello, 1>
<world, 1>
<map, 1>
<input, 1>
<split, 1>
# 分组
<hello, {1,1}>
<world, {1}>
<map, {1}>
<input, {1}>
<split, {1}>
-
在Map阶段,框架可以执行Combiner操作-可选
-
框架会把Map Task输出的<k2,v2>写入Linux的磁盘文件
至此,Map阶段执行结束
MapReduce之Reduce阶段
- 框架对多个Map Task的输出,按照不同的分区,通过网络Copy到不同的Reduce节点,这个过程称为Shuffle
- 框架对Reduce节点接收到的相同分区的<k2,v2>进行合并,排序,分组
- 框架调用Reduce类中的reduce方法,输入<k2,{v2…}>,输出<k3,v3>.一个<k2,{v2…}>调用一次reduce函数
<hello, 2>
<world, 1>
<map, 1>
<input, 1>
<split, 1>
- 框架将计算结果保存到HDFS中
hello 2
world 1
...
WordCount分析
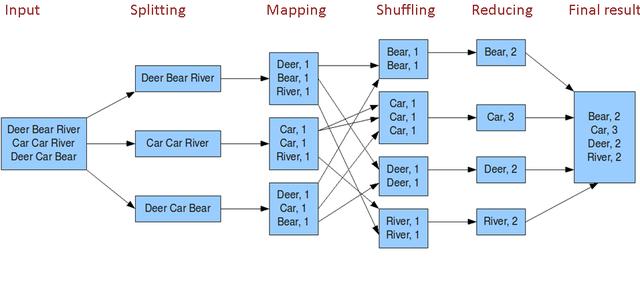
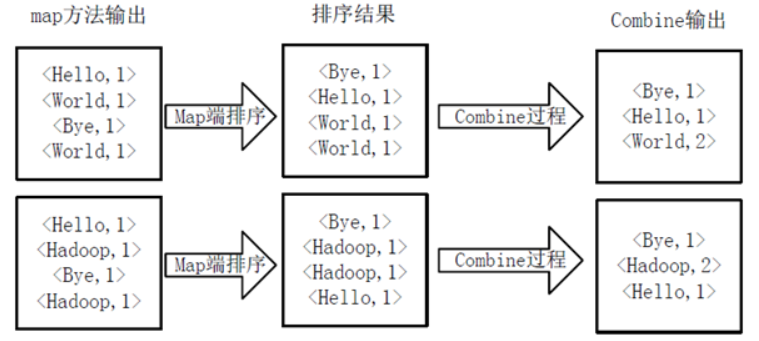
多文件WordCount分析
实战wordCount案例开发
- 开发Map阶段代码
- 开发Reduce阶段代码
- 组装job
/**
* 读取hdfs的hello.txt中每个单词出现的次数
*
* 原始文件的内容
* hello world
* hello map
* input split
*
* 最终输出
*
* hello 2
* world 1
* split 1
* map 1
* input 1
*/
public class WordCountJob {
/**
* map阶段
*/
public static class MyMapProcess extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 实现map函数
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
// k1代表每行数据的行首偏移量 v1代表每行的内容
// 对获取的数据每一行切割
String[] words = v1.toString().split(" ");
for (String word: words
) {
// 封装为<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
context.write(k2, v2);
}
}
}
/**
* reduce阶段
* 针对<k2,{v2...}>这样的数据进行累加求和,转换为<k3,v3></>
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable v2: v2s
) {
sum += v2.get();
}
context.write(k2, new LongWritable(sum));
}
}
/**
* 组装job=map+reduce
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length < 2) {
System.out.println("请输入两个目录地址");
return;
}
Configuration entries = new Configuration();
Job job = Job.getInstance(entries);
// 必须设置
job.setJarByClass(WordCountJob.class);
// 指定输入路径,可以是文件也可以是目录
FileInputFormat.setInputPaths(job, new Path("args[0]"));
// 只能指定一个不存在的目录
FileOutputFormat.setOutputPath(job, new Path("args[1]"));
// 指定map
job.setMapperClass(MyMapProcess.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// reduce指定
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
}
}
- 打包代码并上传至服务器
mvn clean package -D skipTests
- 创建测试文件
[root@hadoop01 hadoop-3.2.0]# hdfs dfs -mkdir /test
[root@hadoop01 hadoop-3.2.0]# hdfs dfs -put hello.txt /test
You have new mail in /var/spool/mail/root
[root@hadoop01 hadoop-3.2.0]# hdfs dfs -ls /test
Found 1 items
-rw-r--r-- 2 root supergroup 34 2024-03-06 16:29 /test/hello.txt
- 上传jar包到集群并运行
# 运行相关代码
[root@hadoop01 hadoop-3.2.0]# bin/hadoop jar demo-0.0.1-SNAPSHOT-jar-with-dependencies.jar com.example.hadoop.demo.mapreduce.WordCountJob /test/hello.txt /out
2024-03-06 16:40:27,922 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/192.168.52.100:8032
2024-03-06 16:40:28,962 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2024-03-06 16:40:29,005 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1709626488940_0001
2024-03-06 16:40:29,749 INFO input.FileInputFormat: Total input files to process : 1
2024-03-06 16:40:29,943 INFO mapreduce.JobSubmitter: number of splits:1
2024-03-06 16:40:30,036 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2024-03-06 16:40:30,328 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1709626488940_0001
2024-03-06 16:40:30,329 INFO mapreduce.JobSubmitter: Executing with tokens: []
2024-03-06 16:40:30,588 INFO conf.Configuration: resource-types.xml not found
2024-03-06 16:40:30,588 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2024-03-06 16:40:31,089 INFO impl.YarnClientImpl: Submitted application application_1709626488940_0001
2024-03-06 16:40:31,147 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1709626488940_0001/
2024-03-06 16:40:31,147 INFO mapreduce.Job: Running job: job_1709626488940_0001
2024-03-06 16:40:43,417 INFO mapreduce.Job: Job job_1709626488940_0001 running in uber mode : false
2024-03-06 16:40:43,419 INFO mapreduce.Job: map 0% reduce 0%
2024-03-06 16:40:50,638 INFO mapreduce.Job: map 100% reduce 0%
2024-03-06 16:40:57,779 INFO mapreduce.Job: map 100% reduce 100%
2024-03-06 16:40:57,824 INFO mapreduce.Job: Job job_1709626488940_0001 completed successfully
2024-03-06 16:40:57,948 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=100
FILE: Number of bytes written=442629
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=134
HDFS: Number of bytes written=38
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5635
Total time spent by all reduces in occupied slots (ms)=4035
Total time spent by all map tasks (ms)=5635
Total time spent by all reduce tasks (ms)=4035
Total vcore-milliseconds taken by all map tasks=5635
Total vcore-milliseconds taken by all reduce tasks=4035
Total megabyte-milliseconds taken by all map tasks=5770240
Total megabyte-milliseconds taken by all reduce tasks=4131840
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=82
Map output materialized bytes=100
Input split bytes=100
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=100
Reduce input records=6
Reduce output records=5
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=159
CPU time spent (ms)=1880
Physical memory (bytes) snapshot=306229248
Virtual memory (bytes) snapshot=5044473856
Total committed heap usage (bytes)=141049856
Peak Map Physical memory (bytes)=201551872
Peak Map Virtual memory (bytes)=2517729280
Peak Reduce Physical memory (bytes)=104677376
Peak Reduce Virtual memory (bytes)=2526744576
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=34
File Output Format Counters
Bytes Written=38
You have new mail in /var/spool/mail/root
# 查看是否有输出
[root@hadoop01 hadoop-3.2.0]# hdfs dfs -ls /out
Found 2 items
-rw-r--r-- 2 root supergroup 0 2024-03-06 16:40 /out/_SUCCESS
-rw-r--r-- 2 root supergroup 38 2024-03-06 16:40 /out/part-r-00000
You have new mail in /var/spool/mail/root
# 查看文件内容
[root@hadoop01 hadoop-3.2.0]# hdfs dfs -cat /out/part-r-00000
hello 2
input 1
map 1
split 1
world 1