目录
- 引言
- 概念
- 一、牛的学术圈I
- 二、最长连续不重复序列
- 三、数组元素的目标和
- 四、判断子序列
- 五、日志统计
- 六、统计子矩阵
引言
关于这个双指针算法,主要是用来处理枚举子区间的事,时间复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N) ,所以还是很方便的,而且枚举这类题出的还是很常见的,所以这个算法还是尤为重要的。加油!
概念
双指针算法:首先要满足单调性,二分是元素的单调性、二段性,这个指的是区间的单调性。
双指针模板:
for(int i = 0, j = 0; i < n; ++i)
{
while(j < n && check(i,j)) j++;
//该题逻辑
}
一、牛的学术圈I
标签:二分
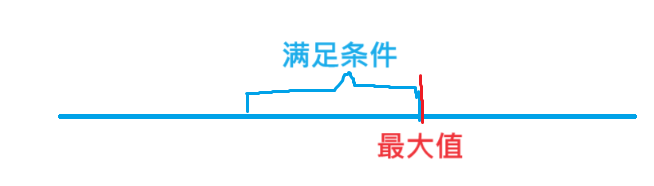
思路:像这种求最大/最小的问题,基本上都可以用二分。我们不讨论最大值,我们讨论该h指数是否能达到,然后用二分来逼近能成立的最大值,显然该题是具有二段性的,具体长如下这样。然后就是
c
h
e
c
k
check
check 函数了,因为先统计大于等于
m
i
d
mid
mid 的个数,再统计满足
a
[
i
]
+
1
=
m
i
d
a[i] + 1 = mid
a[i]+1=mid 的个数,与
l
l
l 取最小值,最后比较是否
r
e
s
≥
m
i
d
res \geq mid
res≥mid 。
题目描述:
由于对计算机科学的热爱,以及有朝一日成为 「Bessie 博士」的诱惑,奶牛 Bessie 开始攻读计算机科学博士学位。
经过一段时间的学术研究,她已经发表了 N 篇论文,并且她的第 i 篇论文得到了来自其他研究文献的 ci 次引用。
Bessie 听说学术成就可以用 h 指数来衡量。
h 指数等于使得研究员有至少 h 篇引用次数不少于 h 的论文的最大整数 h。
例如,如果一名研究员有 4 篇论文,引用次数分别为 (1,100,2,3),则 h 指数为 2,然而若引用次数为 (1,100,3,3)
则 h 指数将会是 3。
为了提升她的 h 指数,Bessie 计划写一篇综述,并引用一些她曾经写过的论文。
由于页数限制,她至多可以在这篇综述中引用 L 篇论文,并且她只能引用每篇她的论文至多一次。
请帮助 Bessie 求出在写完这篇综述后她可以达到的最大 h 指数。
注意 Bessie 的导师可能会告知她纯粹为了提升 h 指数而写综述存在违反学术道德的嫌疑;我们不建议其他学者模仿 Bessie 的行为。
输入格式
输入的第一行包含 N 和 L。
第二行包含 N 个空格分隔的整数 c1,…,cN。
输出格式
输出写完综述后 Bessie 可以达到的最大 h 指数。
数据范围
1≤N≤105,0≤ci≤105,0≤L≤105
输入样例1:
4 0
1 100 2 3
输出样例1:
2
样例1解释
Bessie 不能引用任何她曾经写过的论文。上文中提到,(1,100,2,3) 的 h 指数为 2。
输入样例2:
4 1
1 100 2 3
输出样例2:
3
如果 Bessie 引用她的第三篇论文,引用数会变为 (1,100,3,3)。上文中提到,这一引用数的 h 指数为 3。
示例代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1e5+10;
int n, m;
int a[N];
bool check(int mid) // 检查能否到mid
{
int res = 0, t = 0;
for(int i = 0; i < n; ++i)
{
if(a[i] >= mid) res++;
if(a[i] + 1 == mid) t++;
}
t = min(m, t);
res += t;
return res >= mid;
}
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n >> m;
for(int i = 0; i < n; ++i) cin >> a[i];
int l = 0, r = 1e5;
while(l < r)
{
int mid = (LL)l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
cout << r << endl;
return 0;
}
二、最长连续不重复序列
标签:双指针
思路:模板题。核心就是
[
j
,
i
]
[j,i]
[j,i] 维护的是一段有效的序列,
i
i
i 是一值往前走的,用
c
n
t
cnt
cnt 来记录每一个值出现的次数,如果重复了,那肯定是
i
i
i 和
j
j
j 所对应的元素重复了,
j
j
j 往前走即可,然后找最大值。
题目描述:
给定一个长度为 n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。
输入格式
第一行包含整数 n。
第二行包含 n 个整数(均在 0∼105 范围内),表示整数序列。
输出格式
共一行,包含一个整数,表示最长的不包含重复的数的连续区间的长度。
数据范围
1≤n≤105
输入样例:
5
1 2 2 3 5
输出样例:
3
示例代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1e5+10;
int n;
int a[N], cnt[N];
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n;
for(int i = 0; i < n; ++i) cin >> a[i];
int res = 0;
for(int i = 0, j = 0; i < n; ++i)
{
cnt[a[i]]++;
while(j < i && cnt[a[i]] > 1) cnt[a[j++]]--;
res = max(res, i - j + 1);
}
cout << res << endl;
return 0;
}
三、数组元素的目标和
标签:哈希、双指针
思路1:就是找两个数组中和为
k
e
y
key
key 的两个下标,直接先把第一个数组按元素值存入哈希表,然后遍历第二个数组如果存在就输出即可。
思路2:由于都是升序的,
i
i
i 从最小值遍历,
j
j
j 从最大值遍历,如果值总和变小了,
i
i
i 右移,如果变大了,
j
j
j 左移,直到相等。
题目描述:
给定两个升序排序的有序数组 A 和 B,以及一个目标值 x。
数组下标从 0 开始。
请你求出满足 A[i]+B[j]=x 的数对 (i,j)。
数据保证有唯一解。
输入格式
第一行包含三个整数 n,m,x,分别表示 A 的长度,B 的长度以及目标值 x。
第二行包含 n 个整数,表示数组 A。
第三行包含 m 个整数,表示数组 B。
输出格式
共一行,包含两个整数 i 和 j。
数据范围
数组长度不超过 105。同一数组内元素各不相同。1≤数组元素≤109
输入样例:
4 5 6
1 2 4 7
3 4 6 8 9
输出样例:
1 1
示例代码1: 哈希表
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
int n, m, k;
unordered_map<int,int> mmap;
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n >> m >> k;
for(int i = 0; i < n; ++i)
{
int t; cin >> t;
mmap[t] = i;
}
for(int i = 0; i < m; ++i)
{
int t; cin >> t;
if(mmap.count(k-t))
{
cout << mmap[k-t] << " " << i << endl;
break;
}
}
return 0;
}
示例代码2: 双指针
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1e5+10;
int n, m;
LL k;
int a[N], b[N];
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n >> m >> k;
for(int i = 0; i < n; ++i) cin >> a[i];
for(int i = 0; i < m; ++i) cin >> b[i];
int i = 0, j = m - 1;
for(; i < n && j > -1; ++i)
{
while(j > -1 && a[i] + b[j] > k) j--;
if(j > -1 && (LL)a[i] + b[j] == k) break;
}
cout << i << " " << j << endl;
return 0;
}
四、判断子序列
标签:双指针、模板题
思路:双指针模板,没啥说的。
题目描述:
给定一个长度为 n 的整数序列 a1,a2,…,an 以及一个长度为 m 的整数序列 b1,b2,…,bm。
请你判断 a 序列是否为 b 序列的子序列。
子序列指序列的一部分项按原有次序排列而得的序列,例如序列 {a1,a3,a5} 是序列 {a1,a2,a3,a4,a5} 的一个子序列。
输入格式
第一行包含两个整数 n,m。
第二行包含 n 个整数,表示 a1,a2,…,an。
第三行包含 m 个整数,表示 b1,b2,…,bm。
输出格式
如果 a 序列是 b 序列的子序列,输出一行 Yes。
否则,输出 No。
数据范围
1≤n≤m≤105,109≤ai,bi≤109
输入样例:
3 5
1 3 5
1 2 3 4 5
输出样例:
Yes
示例代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1e5+10;
int n, m;
int a[N], b[N];
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n >> m;
for(int i = 0; i < n; ++i) cin >> a[i];
for(int j = 0; j < m; ++j) cin >> b[j];
int i = 0, j = 0;
while(i < n && j < m)
{
if(a[i] == b[j]) i++;
j++;
}
if(i == n) puts("Yes");
else puts("No");
return 0;
}
五、日志统计
标签:枚举、双指针
思路:一般这种题都是遍历订单,而我看这道题要按
i
d
id
id 号由小到大输出,那我就遍历
i
d
id
id 号了,然后找出满足条件的输出就行了,我用
v
e
c
t
o
r
+
数组
vector+数组
vector+数组 来存,第
i
i
i 号
v
e
c
t
o
r
vector
vector 代表
i
d
id
id 号为
i
i
i 的订单时间,
v
e
c
t
o
r
vector
vector 里存的是该
i
d
id
id 的点赞时间,首先如果数量够
k
k
k 个,然后由小到大排序,遍历每
k
k
k 个时间,判断是否间隔时间在
d
d
d 以内,如果是输出即可。
题目描述:
小明维护着一个程序员论坛。现在他收集了一份”点赞”日志,日志共有 N 行。
其中每一行的格式是:
ts id 表示在 ts 时刻编号 id 的帖子收到一个”赞”。
现在小明想统计有哪些帖子曾经是”热帖”。
如果一个帖子曾在任意一个长度为 D 的时间段内收到不少于 K 个赞,小明就认为这个帖子曾是”热帖”。
具体来说,如果存在某个时刻 T 满足该帖在 [T,T+D) 这段时间内(注意是左闭右开区间)收到不少于 K 个赞,该帖就曾是”热帖”。
给定日志,请你帮助小明统计出所有曾是”热帖”的帖子编号。
输入格式
第一行包含三个整数 N,D,K。
以下 N 行每行一条日志,包含两个整数 ts 和 id。
输出格式
按从小到大的顺序输出热帖 id。
每个 id 占一行。
数据范围
1≤K≤N≤105,0≤ts,id≤105,1≤D≤10000
输入样例:
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
输出样例:
1
3
示例代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1e5+10;
int n, d, k;
vector<int> logs[N]; // 统计第i号订单的日期
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n >> d >> k;
for(int i = 0; i < n; ++i)
{
int ts, id;
cin >> ts >> id;
logs[id].push_back(ts);
}
for(int i = 0; i < N; ++i) // 遍历每一个id
{
if(logs[i].size() >= k)
{
sort(logs[i].begin(), logs[i].end()); // 给其时间排序
for(int j = 0; j + k - 1 < logs[i].size(); ++j)
{
if(logs[i][j+k-1] - logs[i][j] + 1 <= d)
{
cout << i << endl;
break;
}
}
}
}
return 0;
}
六、统计子矩阵
标签:前缀和、二分
思路:本来用前缀和直接做的话,时间复杂度在
O
(
N
4
)
O(N^4)
O(N4) ,明显超时了。由题意得元素没有负数,所以满足单调性,可以用上下界限拿前缀和处理,左右拿双指针处理,这样时间复杂度就降为了
O
(
N
3
)
O(N^3)
O(N3) 刚好能过。
题目描述:
给定一个 N×M 的矩阵 A,请你统计有多少个子矩阵 (最小 1×1,最大 N×M) 满足子矩阵中所有数的和不超过给定的整数 K?
输入格式
第一行包含三个整数 N,M 和 K。
之后 N 行每行包含 M 个整数,代表矩阵 A。
输出格式
一个整数代表答案。
数据范围对于 30% 的数据,N,M≤20,
对于 70% 的数据,N,M≤100,
对于 100% 的数据,1≤N,M≤500;0≤Aij≤1000;1≤K≤2.5×108。
输入样例:
3 4 10
1 2 3 4
5 6 7 8
9 10 11 12
输出样例:
19
样例解释
满足条件的子矩阵一共有 19,包含:
大小为 1×1 的有 10 个。大小为 1×2 的有 3 个。大小为 1×3 的有 2 个。大小为 1×4 的有 1 个。大小为 2×1 的有 3 个。
示例代码:
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 510;
int n, m, k;
int s[N][N];
int main()
{
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
cin >> n >> m >> k;
for(int i = 1; i <= n; ++i)
{
for(int j = 1; j <= m; ++j)
{
cin >> s[i][j];
s[i][j] += s[i-1][j];
}
}
LL res = 0;
for(int i = 1; i <= n; ++i)
{
for(int j = i; j <= n; ++j)
{
for(int l = 1, r = 1, sum = 0; r <= m; ++r)
{
sum += s[j][r] - s[i-1][r];
while(l <= m && sum > k) sum -= s[j][l] - s[i-1][l], l++;
res += r - l + 1;
}
}
}
cout << res << endl;
return 0;
}