文章目录
- 前言
- JobGraph创建的过程
- 总结
前言
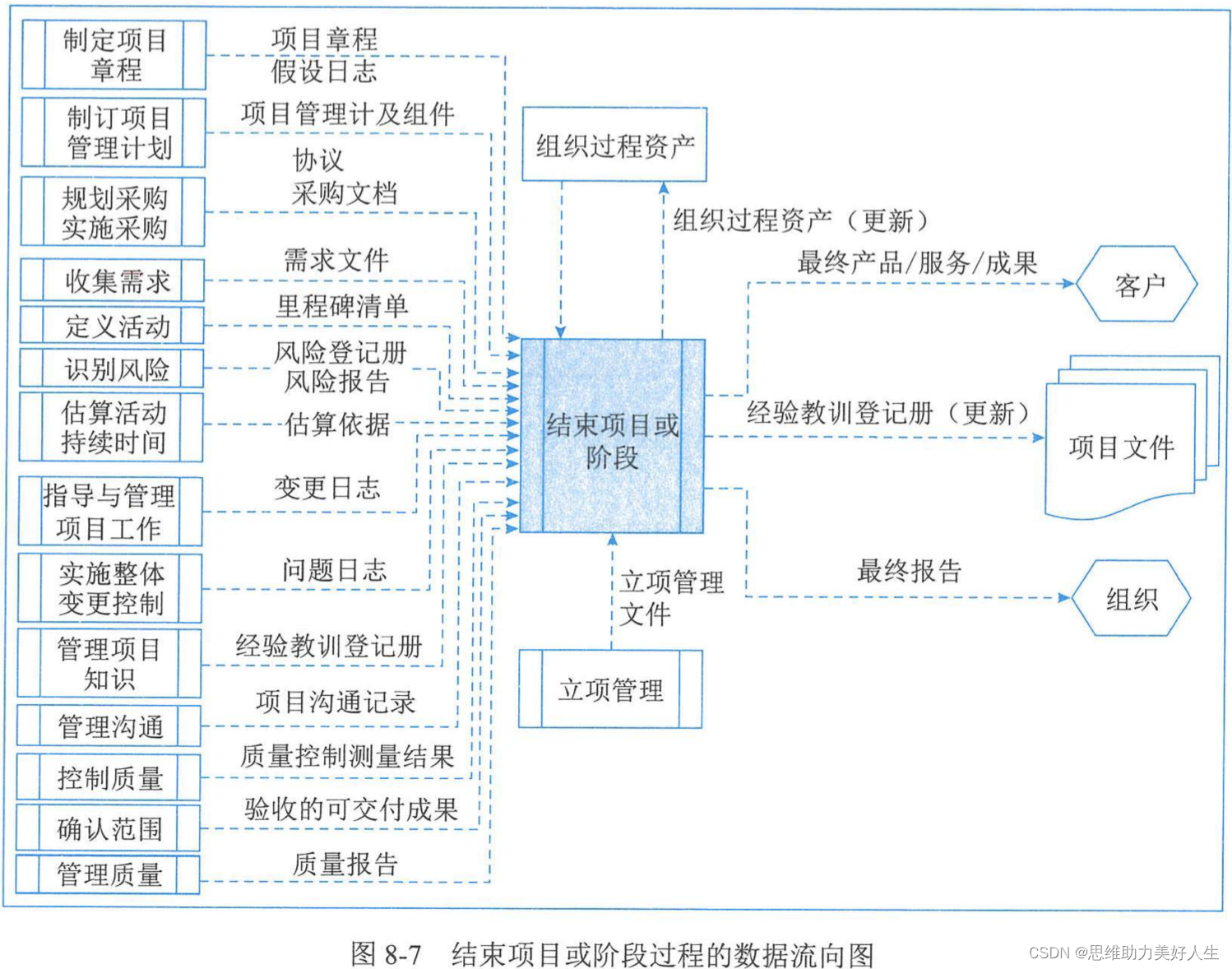
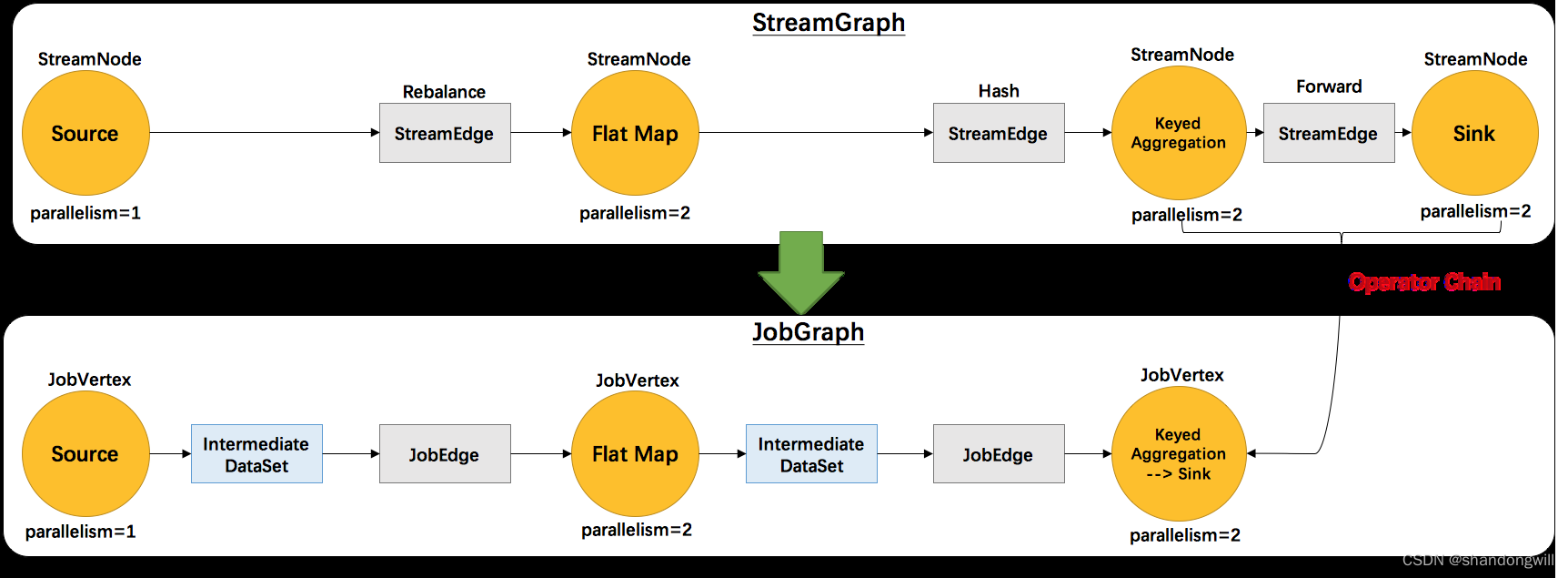
在StreamGraph构建过程中分析了StreamGraph的构建过程,在StreamGraph构建完毕之后会对StreamGraph进行优化构建JobGraph,然后再提交JobGraph。优化过程中,Flink会尝试将尽可能多的StreamNode聚合在一个JobGraph节点中,通过合并创建JobVertex,并生成JobEdge,以减少数据在不同节点之间流动所产生的序列化、反序列化、网络传输的开销。它包含的主要抽象概念有:
1、JobVertex:经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个JobVertex,即一个JobVertex 包含一个或多个 operator,JobVertex 的输入是 JobEdge,输出是IntermediateDataSet。
2、IntermediateDataSet:表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是JobVertex,consumer 是 JobEdge。
3、JobEdge:代表了job graph中的一条数据传输通道。source是IntermediateDataSet,target是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
JobGraph创建的过程
AbstractJobClusterExecutor.execute -> PipelineExecutorUtils.getJobGraph ->
PipelineTranslator.translateToJobGraph -> StreamGraphTranslator.translateToJobGraph
-> StreamGraph.getJobGraph -> StreamingJobGraphGenerator.createJobGraph
createJobGraph()函数
private JobGraph createJobGraph() {
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// 为节点生成确定性哈希,以便在提交时识别它们(如果它们没有更改)。.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
setPhysicalEdges();
markContainsSourcesOrSinks();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// 在最后完成ExecutionConfig时设置它
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
}
jobGraph.setChangelogStateBackendEnabled(streamGraph.isChangelogStateBackendEnabled());
addVertexIndexPrefixInVertexName();
setVertexDescription();
// Wait for the serialization of operator coordinators and stream config.
try {
FutureUtils.combineAll(
vertexConfigs.values().stream()
.map(
config ->
config.triggerSerializationAndReturnFuture(
serializationExecutor))
.collect(Collectors.toList()))
.get();
waitForSerializationFuturesAndUpdateJobVertices();
} catch (Exception e) {
throw new FlinkRuntimeException("Error in serialization.", e);
}
if (!streamGraph.getJobStatusHooks().isEmpty()) {
jobGraph.setJobStatusHooks(streamGraph.getJobStatusHooks());
}
return jobGraph;
}
在 StreamGraph 构建 JobGragh 的过程中,最重要的事情就是 operator 的 chain 优化,那么到底什
么样的情况的下 Operator 能chain 在一起呢?
// 1、下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
downStreamVertex.getInEdges().size() == 1;
// 2、上下游节点都在同一个 slot group 中
upStreamVertex.isSameSlotSharingGroup(downStreamVertex);
// 3、前后算子不为空
!(downStreamOperator == null || upStreamOperator == null);
// 4、上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source 默认
是 HEAD)
!upStreamOperator.getChainingStrategy() == ChainingStrategy.NEVER;
// 5、下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter 等默认是
ALWAYS)
!downStreamOperator.getChainingStrategy() != ChainingStrategy.ALWAYS;
// 6、两个节点间物理分区逻辑是 ForwardPartitioner
(edge.getPartitioner() instanceof ForwardPartitioner);
// 7、两个算子间的shuffle方式不等于批处理模式
edge.getShuffleMode() != ShuffleMode.BATCH;
// 8、上下游的并行度一致
upStreamVertex.getParallelism() == downStreamVertex.getParallelism();
// 9、用户没有禁用 chain
streamGraph.isChainingEnabled();
构造边
private void connect(Integer headOfChain, StreamEdge edge, NonChainedOutput output) {
physicalEdgesInOrder.add(edge);
Integer downStreamVertexID = edge.getTargetId();
JobVertex headVertex = jobVertices.get(headOfChain);
JobVertex downStreamVertex = jobVertices.get(downStreamVertexID);
StreamConfig downStreamConfig = new StreamConfig(downStreamVertex.getConfiguration());
downStreamConfig.setNumberOfNetworkInputs(downStreamConfig.getNumberOfNetworkInputs() + 1);
StreamPartitioner<?> partitioner = output.getPartitioner();
ResultPartitionType resultPartitionType = output.getPartitionType();
if (resultPartitionType == ResultPartitionType.HYBRID_FULL
|| resultPartitionType == ResultPartitionType.HYBRID_SELECTIVE) {
hasHybridResultPartition = true;
}
checkBufferTimeout(resultPartitionType, edge);
JobEdge jobEdge;
if (partitioner.isPointwise()) {
jobEdge =
downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.POINTWISE,
resultPartitionType,
opIntermediateOutputs.get(edge.getSourceId()).get(edge).getDataSetId(),
partitioner.isBroadcast());
} else {
jobEdge =
downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.ALL_TO_ALL,
resultPartitionType,
opIntermediateOutputs.get(edge.getSourceId()).get(edge).getDataSetId(),
partitioner.isBroadcast());
}
// set strategy name so that web interface can show it.
jobEdge.setShipStrategyName(partitioner.toString());
jobEdge.setForward(partitioner instanceof ForwardPartitioner);
jobEdge.setDownstreamSubtaskStateMapper(partitioner.getDownstreamSubtaskStateMapper());
jobEdge.setUpstreamSubtaskStateMapper(partitioner.getUpstreamSubtaskStateMapper());
if (LOG.isDebugEnabled()) {
LOG.debug(
"CONNECTED: {} - {} -> {}",
partitioner.getClass().getSimpleName(),
headOfChain,
downStreamVertexID);
}
}
总结
1、在StreamGraph构建完毕之后会开始构建JobGraph,然后再提交JobGraph。
2、StreamingJobGraphGenerator.createJobGraph()是构建JobGraph的核心实现,实现中首先会广度优先遍历StreamGraph,为其中的每个StreamNode生成一个Hash值,如果用户设置了operator的uid,那么就根据uid来生成Hash值,否则系统会自己为每个StreamNode生成一个Hash值。如果用户自己为operator提供了Hash值,也会拿来用。生成Hash值的作用主要应用在从checkpoint中的数据恢复
3、在生成Hash值之后,会调用setChaining()方法,创建operator chain、构建JobGraph顶点JobVertex、边JobEdge、中间结果集IntermediateDataSet的核心方法。
1)、创建StreamNode chain(operator chain)
从source开始,处理出边StreamEdge和target节点(edge的下游节点),递归的向下处理StreamEdge上和target StreamNode,直到找到那条过渡边,即不能再进行chain的那条边为止。那么这中间的StreamNode可以作为一个chain。这种递归向下的方式使得程序先chain完StreamGraph后面的节点,再处理头结点,类似于后序递归遍历。
2)、创建顶点JobVertex
顶点的创建在创建StreamNode chain的过程中,当已经完成了一个StreamNode chain的创建,在处理这个chain的头结点时会创建顶点JobVertex,顶点的JobVertexID根据头结点的Hash值而决定。同时JobVertex持有了chain上的所有operatorID。因为是后续遍历,所有JobVertex的创建过程是从后往前进行创建,即从sink端到source端
3)、创建边JobEdge和IntermediateDataSet
JobEdge的创建是在完成一个StreamNode chain,在处理头结点并创建完顶点JobVertex之后、根据头结点和过渡边进行connect操作时进行的,连接的是当前的JobVertex和下游的JobVertex,因为JobVertex的创建是由下至上的。
根据头结点和边从jobVertices中找到对应的JobGraph的上下游顶点JobVertex,获取过渡边的分区器,创建对应的中间结果集IntermediateDataSet和JobEdge。IntermediateDataSet由上游的顶点JobVertex创建,上游顶点JobVertex作为它的生产者producer,IntermediateDataSet作为上游顶点的输出。JobEdge中持有了中间结果集IntermediateDataSet和下游的顶点JobVertex的引用, JobEdge作为中间结果集IntermediateDataSet的消费者,JobEdge作为下游顶点JobVertex的input。整个过程就是
上游JobVertex——>IntermediateDataSet——>JobEdge——>下游JobVertex
4、接下来就是为顶点设置共享solt组、设置checkpoint配置等操作了,最后返回JobGraph,JobGraph的构建就完毕了