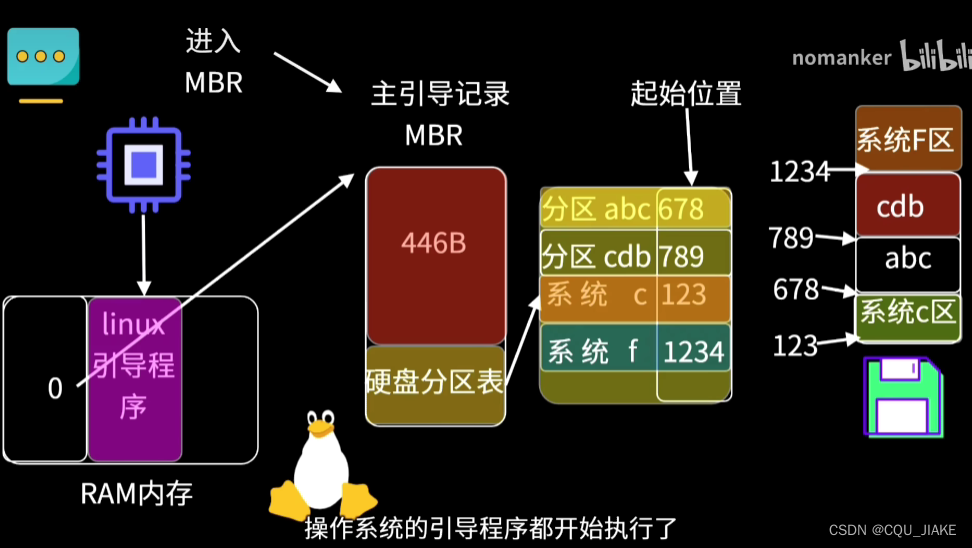
一.内容概述
- 第五节课蒙特卡洛(Mento Carlo)方法是全课程中第一次介绍 model-free 的方法,本节课的 Temporal-difference learning(TD learning)是我们要介绍的第二种 model-free 的方法。
- 基于蒙特卡洛(Mento Carlo)的方法是一种非递增(non-incremental)的方法,Temporal-difference learning(TD learning)是一种迭代式(incremental)的方法
- 第六节课的内容是本节课的铺垫
- 下节课会介绍 value function approximation 的方法,这个是基于现在我们要介绍的 TD 算法,不过这节课介绍的是基于 table 的(tabular representation),下节课会介绍基于 function 的 representation。非常经典的 deep Q learning 也会在下节课介绍。
本节课内容:
- 激励性实例(Motivating examples)
- 估计 state value 的 TD 算法:(在第四章我们使用模型计算 state value(做 state value estimation),在第五章使用蒙特卡洛计算 state value(做 state value estimation),在这章使用时序差分计算 state value(做 state value estimation),所以它们都是在做类似的事情,但是用的方法不一样。)
- 估计 action value 的 TD 算法:(Sarsa 算法):使用 TD 的思想来学习 action value,然后得到 action value 可以以此为据去更新策略,得到一个新的策略再计算它的 action value,这样不断循环下去就能够不断改进策略,直到最后找到最优的策略。
- 估计 action value 的 TD 算法:expected Sarsa (Sarsa 算法的变形)
- 估计 action value 的 TD 算法:n-step Sarsa (Sarsa 算法的变形)
- 估计最优 action value 的 TD 算法:Q-learning:直接计算 optimal action value,所以他是一个 off-policy 的算法。这就涉及到了 on-policy 和 off-policy 两个概念,在强化学习中有两个策略,一个是 behavior policy,它是用来生成经验数据的,一个是 target policy,这是我们的目标策略,我们不断改进希望这个 target policy 能够收敛到最优的策略。如果 behavior policy 和 target policy 这两个是相同的,那么它就是 on-policy,如果它们可以不同,那这个算法就是 off-policy。off-policy 的好处是,我可以用之前的别的策略所生成的数据为我所用,我可以拿过来进行学习然后得到最优的策略。
- 一个统一的观点:将这些算法进行比较
- 总结
一.激励性实例(Motivating examples)-随机问题(stochastic problems)
下面讲几个例子,讲这个例子的目的是为了建立起上节课和这节课的关系
接下来,我们将考虑一些随机问题(stochastic problems),并展示如何使用 RM 算法来解决这些问题
首先,考虑简单的均值估计问题(mean estimation problem):(之前的课程都在反复讲这个问题,我们会从不同角度介绍这个问题):mean estimation 问就是要求解一个 random variable X 的 expectation,用 w 来表示这样一个 expectation 的值,现在有的是 X 的独立同分布(iid)采样,用这些采样求 expectation。这个问题有很多算法可以求解,这里讲解 RM 算法
- 要求解 w,先把它写成一个函数 g(w)=w-E[X],求解 g(w)=0 的方程,这个方程求解出来自然可以得到它的解 w*=E[X]
- 因为我们只能获得 X 的采样 {x},w - x 是 g 的测量 g~

- 这么看的话\alpha_k的取值也是权衡历史值和当前采样,所以也有一种“记忆”的味道在里面
- 每次考虑了期望值和结果采样值的差距进行考虑
第二,考虑一个稍微复杂一点的例子:

第三,考虑一个更复杂的例子:
下面这个式子的变量符号都是有目的使用的,R代表 reward,γ 代表 discounted rate,v 就是 state value,X 就是对应 state value 的 state。
- 这样就可以求出来 action value 了
- 可以model-free的方式求action value的期望!

快速总结:
- 上述三个例子越来越复杂。
- 它们都可以用 RM 算法求解。
- 我们将看到 TD 算法也有类似的表达式。
二.估计 state value 的 TD 算法(TD learning of state values)
先学习如何用 TD 算法求解一个给定的策略 π 的 state value,之所以求解 state value,是因为求解出来了 state value 就相当于作了 policy evaluation,之后和 policy improvement 相结合,就可以去找最优的策略
请注意
- TD 学习算法通常指的是一大类 RL 算法。今天这节课讲的所有的算法都是 TD 算法,包括 Q learning
- TD 学习算法也指下面即将介绍的一种用于估计状态值(state value)的特定算法,下面即将讲的 TD 算法是最经典的 TD 算法,就是来估计 state value 的,有一个非常明确的表达式,这时候它是指一个特定的算法。
算法所需的数据/经验:TD 算法是基于数据,不基于模型实现强化学习的,算法使用的数据/经验(data/experience)如下:

- 之前不理解为什么v_t(s_t)不写成v_k(s_t),原来一组{s_t,r_t+1,s_t+1}刚好用来更新一次v,所以两个不同意义的下标k和t其实是同步的。
下面 TD 算法就是要用这些数据来估计 π 对应的 state value,下面正式的给出 TD 算法,包含两个式子:

- 最下面两点的翻译:1)在时间t,只有访问状态st的值被更新,而未访问状态s≠st的值保持不变;2)当上下文清楚时,将省略公式(2)中的更新
- 实际上我们平时看 TD 算法的时候,看不到第二个式子,因为第二个式子隐含掉了,虽然忽略掉了,但是从数学上来讲,是有这样一个式子存在的
下面详细介绍第一个式子:

下面详细介绍上面式子中的两项:

为啥v的下标不用k呢?v下标里的t和s的下标不是同一个t吧
- 针对某一组数据的吧,同一时刻只能访问一个状态,所以下标一样
- 这里的t是指的某一时刻的各个变量的值,t+1就代表下一个时刻的值,即我们更新之后的值,没什么问题啊
- v的脚标t代表迭代,s的脚标t代表位置
- 是把时间步当成迭代步
- 是同一个t,表示t时刻所在的状态

s 的下标和v的下标都是用t表示,但是意义不同吧?v的下标t表示时间,s的下标表示第t个状态
- 我感觉都是表示时间,st+1和st可能根本就不是同一个状态
- 我个人认为在t时刻,v迭代到了第t次,visit的状态s也达到了第t个
- 感觉两个t是一样的,因为s每变一步,只更新一次v
误差期望为啥是0呢
- 因为这就是自己减自己,贝尔曼公式嘛
V pi 是最优价值吗?
- v_pi 是在给定策略pi下的state value. 定义记不清可以复习第二课
- v_pi是对当前策略pi的评估,用来改进策略
TD误差(TD error)可以解释为创新(innovation),当前我对 vπ 有一个估计,这个估计可能是不准确的,然后来了一个新的数据/经验(data/experience),然后把这个数据/经验(data/experience)和我的估计联系到一起,就计算出来了 error,这个 error 的存在说明当前的估计是不准确的,可以用这个 error 来改进我当前的估计,这意味着新的从经验中获得的信息(st, rt+1, st+1)。
下面介绍 TD 算法的一些其他性质:
- (3)中的TD算法仅估计给定的一个策略的状态值(state value),所以刚才介绍的 TD 算法只是估计 state value,只是来做 policy evaluation 这样的事情。
- 它不估计动作值(action value)。
- 它不寻求最优策略(optimal policies)。
- 稍后,马上会介绍一系列 TD 算法,他们能够估计 action value,并且和 policy improvement 的步骤结合,就能搜索最优策略。
- 尽管如此,(3)中的TD算法是理解的基础核心思想。
问:这种 TD 算法在数学上有什么作用?
答:它求解给定策略 π 的贝尔曼方程。
在介绍贝尔曼公式的时候我们已经给出了算法,给出了 closed-form solution 和 iterative solution,在那时候介绍的算法是依赖于模型的,现在是没有模型的。
因此,TD 算法是在没有模型的情况下求解贝尔曼公式。下面要做的就是证明这句话:
首先,引入一个新的贝尔曼公式

TD 算法从本质上讲是求解公式(5)这样一个 equation
第二,使用 RM 算法求解公式(5)这样的贝尔曼公式。之后我们会看到,推导出的 RM 算法与刚才介绍的 TD 算法非常类似,通过这个可以知道,TD 算法就是求解贝尔曼公式的一个 RM 算法

因此,求解贝尔曼公式(5)的 RM 算法是公式(6):

(6) 中的 RM 算法有两个假设值得特别注意。这个式子和刚才我们介绍的 TD 算法非常类似,但是有两个小的不同点:

- 在这个公式中我们要反复得到 r 和 s' 的采样,当前时刻从 s 出发跳到 s',下一时刻还得从 s 出发跳到 s',要反复采样。这个和 TD 算法中使用 episode 这种时序的顺序的访问是不一样的
- 上面式子用蓝色标记出来了,在计算 v_k+1 的时候,要用到 v_π(sk'),也就是 sk' 真实的状态值 v_π,但是 v_π 是不知道的。
下面解决这两个不同点:
为了消除 RM 算法中的两个假设,我们可以对其进行修改。
- 要解决第一个问题就是要把一组采样 {(s, r, s')} 替换成一组序列 {(st, rt+1, st+1)} ,简而言之就是不是从 s 出发得到 r 然后得到 s',然后再从 s 出发得到 r 然后得到 s',而是得到一个 trajectory,如果这个 trajectory 恰巧访问到了 s,就去更新一下 s,如果不访问到 s,那么 s 对应的估计值就保持不动,这样就可以用一个序列对所有 s 的 v 都进行更新。
- 另一个修改是,因为我们事先不知道 v_π(s'),这是我们要求的,可以把这个 v_π(s') 替换成 v_k(s_k'),也就是替换成 s' 这个状态它的估计值 vk。即用对它的估计值来代替 v_π(s')。(问题:在 v_π 的时候能够收敛,现在给了一个 v_k 是不准确的,还能确保收敛吗?答案是肯定的)

以上是用 RM 算法求解贝尔曼公式的一个思路,当然这个思路相对直观一些,下面会给出它的严格收敛性的分析
TD 算法严格的收敛结果是下面一个定理:

强调:
- 这个定理说的是,状态值 state value v_t(s) 会收敛到真实的状态值 v_t(s),所以 TD 算法本质上还是在做一个 policy evaluation 的事情,而且是针对给定的一个策略 π。(该定理说明,对于给定的策略 π,TD 算法可以找到策略 π 的状态值)。那么我们怎么样去改进这个策略找到最优的策略呢,因为强化学习的最终目的是找到最优策略,之后我们会介绍,我们需要把 policy evaluation 和 policy improvement 两个相结合才可以)
- 对任意一个 s,它的和 αt(s) 都应该趋于无穷,即每个状态 s 都应该被访问很多次。当每一个状态被访问的时候对应的 αt(s) 就是一个正数,当当前的 trajectory 是访问其他的状态,那么这个状态没被访问的时候对应的 αt(s) 就是 0,所以 αt(s) 求和等于无穷意味着它实际上被访问了很多次
- 学习率 α 通常被选为一个小常数。在这种情况下,条件 (α 2 t (s) < ∞ 看图片)已经失效,即这个条件不成立,但是在实际当中为什么这么做呢,因为实际中是比较复杂的,我们希望很久之后我所得到的这些经验仍然能够派上用场,相反如果 αt 最后趋向于 0 了,那很久之后的经验就没用了,所以我们只是把它设置成一个很小的数,但是不让它收敛到完全是 0。当 α 为常数时,仍然可以证明算法在期望意义上收敛。