湖仓一体作为一种新兴的开放式数据管理架构,能够充分发挥数据湖的灵活性、生态丰富以及数据仓库的企业级数据分析能力,已经成为企业建设现代数据平台的热门选择。
在此前的直播中,我们分享了HashData湖仓一体方案架构设计与Hive数据同步。本次直播,我们介绍了Iceberg、Hudi的特性与支持方案,并对HashData连接组件的原理和实现流程进行了详细的讲解和演示。以下内容根据直播文字整理。
Hudi与Iceberg技术应用场景
在企业数据平台建设过程中,随着数据量的持续增加与场景的丰富,每家企业都会基于自有技术路线和需求,发展出形态各异的架构设计。
数据湖作为一种不断演进、可扩展的大数据存储、处理和分析基础设施,允许企业存储任意规模的结构化和非结构化数据。伴随着云存储(尤其是对象存储)技术逐步成熟,数据湖的解决方案也逐步向云原生靠近,数据处理方式由批处理向流式处理发展。
在这样的背景下,现代数据湖需要具备强大的流批处理能力、高效的数据更新机制、严谨的事务支持以及灵活多变的存储和计算引擎。
面对上述需求,传统的Hive+HDFS架构数据仓库存在数据修改成本高、不支持事务(ACID)、无法实现流批统一、数据分析用时长等“痛点”,无法直接用于建设数据湖。近些年,Hudi和Iceberg等先进的表格式管理技术,凭借开放的文件存储格式、丰富的事务支持以及高效的读取写入等特点,成为企业数据湖建设的主流选型。
Hudi基本术语与写入操作流程
Hudi的诞生是为了解决Hadoop体系内数据更新和增量查询的问题,在数据存储、查询等方面均具有鲜明的特性。
FileLayouts
Hudi的文件布局是其实现增量查询、数据更新等特性的基础,每个Hudi表有一个固定的目录,存放元数据(.hoodie)以及数据文件,其中数据文件以分区方式进行划分,每个分区有多个数据文件(基础文件和日志文件),这些数据文件在逻辑上被组织为文件和文件组。
- Base File:列式存储的数据文件,默认是Parquet格式。
- Log File:行存储的数据文件,为avro格式,保存的是数据的变更日志(redo log),会定期与Base File进行合并。
- File Group:同一分区下,具有相同fileId的所有BaseFiles + LogFiles集合,一个分区可以有多个文件组。
- File Slice:同一分区下,具有相同fileId以及相同instant的BaseFiles + LogFiles集合。
Timeline
可以理解为Hudi表的一个时间线,记录了Hudi表在不同时刻的操作,并保证操作的原子性。Timeline包含action、time、state三个字段。
Table Types
Hudi提供了两种表类型,分别为Copy-On-Write(COW表)和Merge-On-Read(MOR表):
- COW表:仅使用列式文件格式(如parquet)存储数据。通过在写入期间执行同步合并,简单地更新版本和重写文件,适合更新数据量较大、时效性要求不高的场景。
- MOR表:使用基于列+基于行(如avro)的文件格式的组合存储数据,更新被记录到增量文件中(基于行),然后被压缩以同步或异步地生成新版本的列式文件,适用更新数据量小、时效性要求高的场景。
Query types
Hudi支持三种查询类型,分别为Snapshot Query、Read Optimized Query、Incremental Query:
- Snapshot Query:查询最近一次Snapshot的数据,也就是最新的数据。
- Read Optimized Query:针对MOR表特有的一种查询方式,只读取BaseFile,不合并Log,因为使用的都是列式文件格式,所以效率较高。
- Incremental Query:用户需要指定一个commit time,然后Hudi会扫描文件中的记录,过滤出commit_time大于begintime的TimeLine记录及BaseFile,可以有效地提高增量数据处理能力。
Writing
在Hudi数据湖框架中支持三种方式写入数据:Upsert、Insert以及Bulk-Insert。其中,Upsert为默认行为,也是Hudi的核心功能。
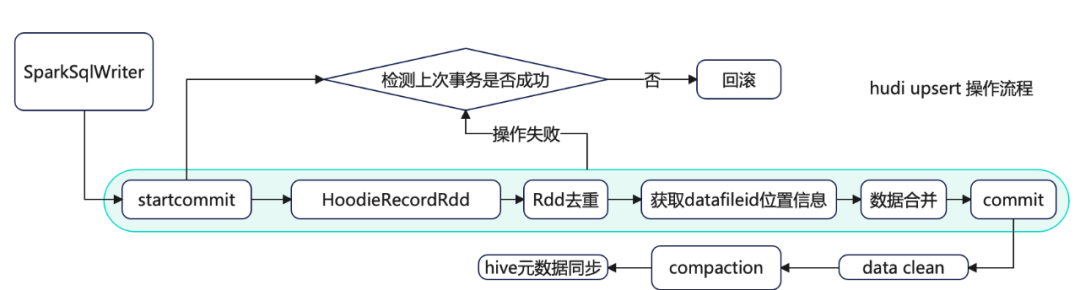
图1:Spark写入Hudi操作流程示意图
如图1所示,Spark写入Hudi,Upsert执行核心操作如下:
- 开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。
- 构造HoodieRecord Rdd对象:Hudi会根据元数据信息构造HoodieRecord Rdd对象,方便后续数据去重和数据合并。
- 数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重,避免重复数据写入Hudi表。
- 数据fileId位置信息获取:在修改记录中可以根据索引获取当前记录所属文件的fileld,因数据合并时Update操作需要知道向哪个fileid文件写入新的快照文件。
- 数据合并:在COW表模式中会重写索引命中的fileId快照文件;在MOR表模式中根据fileId追加到分区中的log文件。
- 完成提交:在元数据中生成xxxx.commit文件,只有生成commit元数据文件,查询引擎才能根据元数据查询到刚刚Upsert后的数据。
- 数据清理:用于删除旧的文件片,以及限制表空间的增长,清理操作在每次写操作之后自动被执行,同时利用缓存在TimeLine Server上的TimeLine Metadata来防止扫描整个表。
- Compaction压缩:主要是MOR模式中才会用到,会将MOR模式中的xxx.log数据合并到xxx.parquet快照文件中去。
lceberg基本术语与写入操作流程
Iceberg的官网定位是“面向海量数据分析场景的高效存储格式”,所以它没有像Hudi一样模拟业务数据库的设计模式(主键+索引)来实现数据更新,而是设计了更强大的文件组织形式来实现数据的Update操作。
Data files(数据文件)
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾,Iceberg每次更新会产生多个数据文件。
Snapshot(表快照)
快照代表一张表在某个时刻的状态,每个快照里面会列出表在某个时刻的所有Data files 列表。Data files存储在不同的Manifest files里面,Manifest files存储在一个Manifest list文件里面,而一个Manifest list文件代表一个快照。
Manifest file(清单文件)
Manifest file是一个元数据文件,它列出组成快照(Snapshot)的数据文件(Data files)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。其中,列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。Manifest file是以avro格式进行存储的,以“.avro”后缀结尾。
Manifest list(清单列表)
Manifest list也是一个元数据文件,它列出构建表快照(Snapshot)的清单。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。每行中存储了Manifest file的路径、其存储的数据文件(Data files)的分区范围,增加了几个数文件、删除了几个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
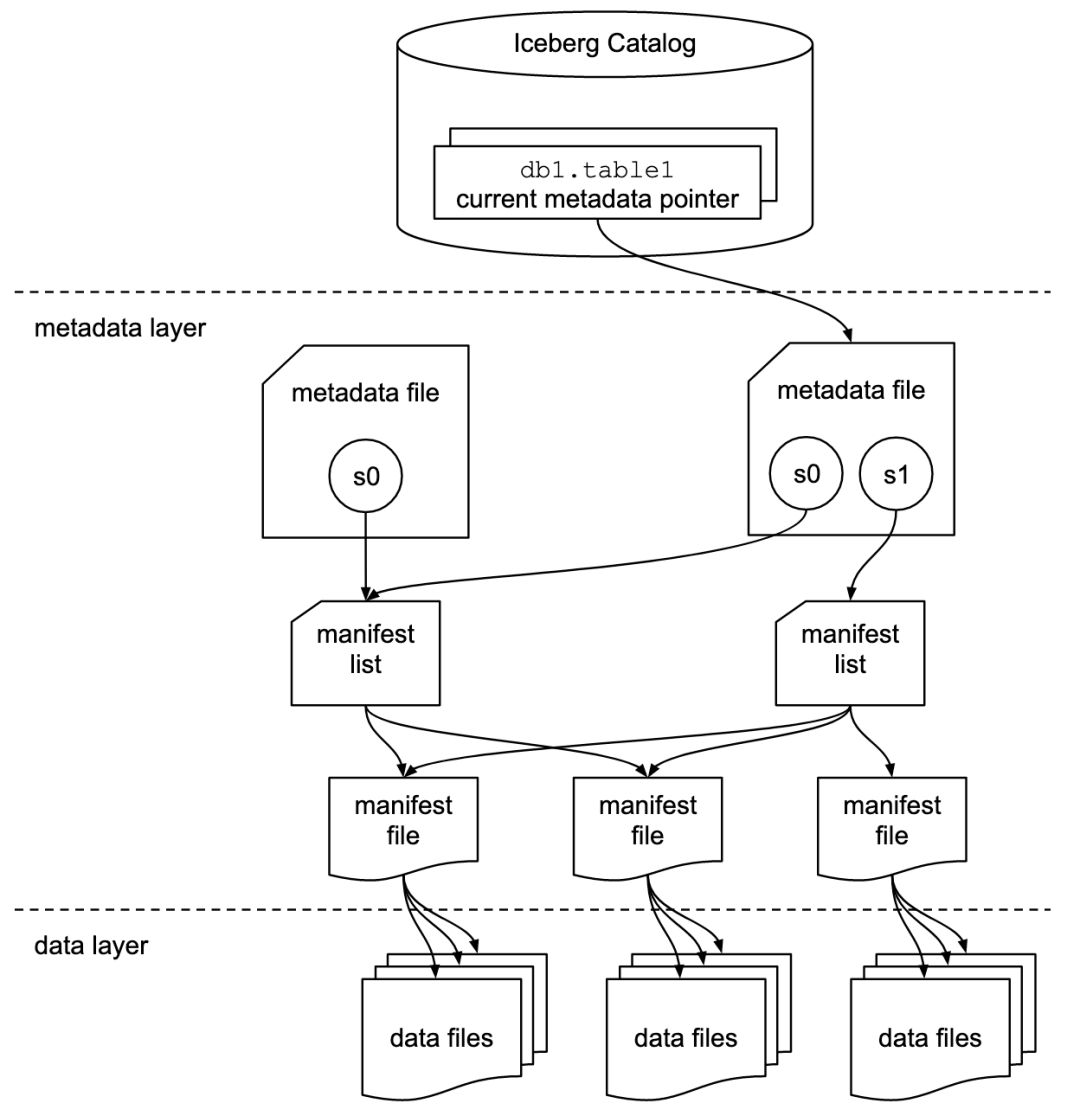
图2:Iceberg写入流程示意图
在向Iceberg写入数据时,其内部的工作流程可以概括为以下几个步骤:
- 生成FileAppender:根据所配置的文件格式,Iceberg会生成对应FileAppender,这是实际执行写文件操作的组件。
- 写入数据文件:FileAppender负责将数据写入到目标文件中。
- 收集统计信息:所有数据写完后,Iceberg会收集写入的统计信息,如记录数(record_count)、下界(lower_bound)、上界(upper_bound)、值计数(value_count)等,以上信息对后续生成Manifest file提供重要输入文件。
- 生成Manifest file:基于统计信息,Iceberg生成对应的Manifest文件,Manifest文件是Datafile的索引,保存了每个数据文件的路径等信息,Iceberg根据这些Manifest file 实现对文件的组织和管理。
- 信息回传:Executor端将生成的Manifest文件和其他相关信息传回给Driver端,完成整个写入过程。
Hashdata连接器工作原理及实现流程
数据湖中的数据通常未经组织或处理,直接分析的效率受限。HashData通过自研Hudi、Iceberg连接器,实现了与这两种架构的流畅集成。HashData目前对于Hudi、Iceberg支持Readonly表,不支持Write。

图3:HashData连接器工作原理示意图
如上图所示,HashData连接组件通过创建外部表的方式读取Hudi、Iceberg数据,进一步对湖内数据进行分析使用。
创建外部表
- 首先,需要Hudi、Iceberg存在需要读取的表。我们通过Spark、Flink等组件在Hudi、Iceberg上创建表并写入数据,且指定为Hudi、Iceberg格式。
- 在HashData DB上提交创建一张对应的可读外部表,外部表信息包含:Path、Catalog Type等信息,也就是我们前文提到的位置相关信息。
- 接下来调用Hudi、Iceberg客户端,客户端会新建连接调用Get Table,并传入外部表信息来获取Hudi、Iceberg表的元数据信息,包括表的字段数量、字段名、数据类型等。
- 根据获取到的元数据信息,在DB上mapping生成HashData的表信息。
- 至此,创建一张对应Hudi、Iceberg的外部表流程结束。
上述步骤,都是通过连接组件完成,相当于把表的Path、Catalogtype等信息打包传给连接器。连接器在获取相关表信息后再传递回来,HashData把传回的信息mapping为可读外部表。
Select表流程
- 当发起Select查询语句后,HashData会在内部发起Query For Select,通过连接器把查询的相关参数打包;然后通过External Scan 的Filter(比如SQL里的where条件)传给连接器。
- 连接器再调用Hudi、Iceberg的Scan接口,Scan方法会得到传入的参数,根据这些参数去过滤查询这次表相关的所有文件列表,并返回相关列表文件。
- 获取文件列表后,External会生成查询计划,完成查询操作和Hudi、Iceberg的元数据交互。
- HashData在获取数据后,会将文件列表打包,然后分发给每个Segment节点,Segment会获取文件列表里的一个分片,并依据这些信息读取数据。在数据返回后,整个读取数据的流程就此结束。
结语
Hudi、Iceberg作为当前主流的数据湖方案,受到广泛青睐。HashData“湖仓一体”技术方案,打通了数据仓库和数据湖,底层支持多种数据类型并存,能够真正实现数据间的相互共享,上层可以通过统一封装的接口进行访问,可同时支持实时查询和分析,为企业在数据湖架构下的数据治理与使用带来了更多的便利。