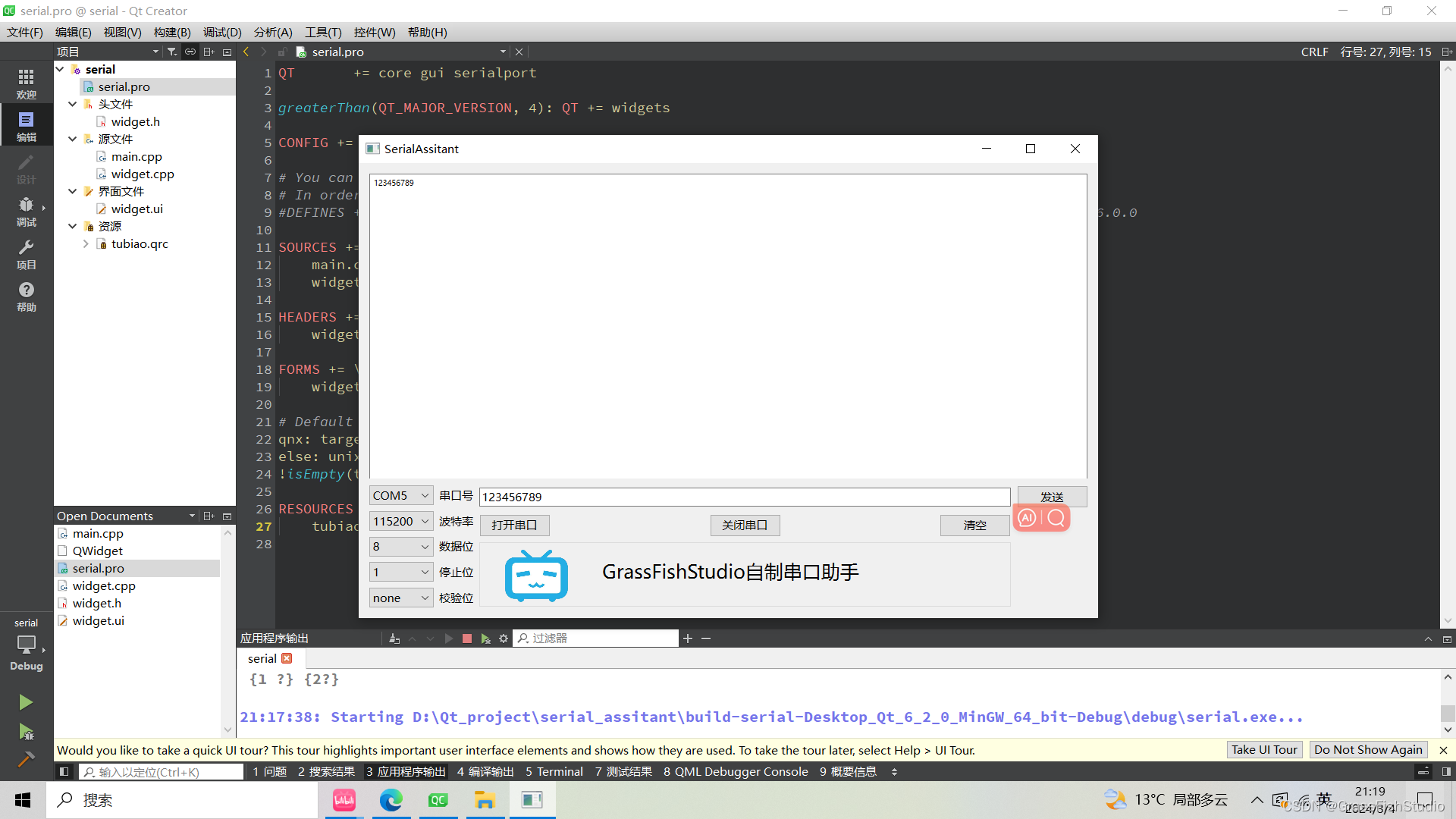
根据深度学习的基本框架,我们要做以下工作:
1,构建神经网络。
2,预处理数据。
3,用训练集训练权重。
4,用测试集进行测试。
首先我们从创建神经网络开始:
先上代码:
import torch
from torch import nn
import torch.nn.functional as F
class MyAlexNet(nn.Module):
def __init__(self):
super(MyAlexNet, self).__init__()
self.c1=nn.Conv2d(in_channels=3,out_channels=48,kernel_size=11,stride=4,padding=2)
self.ReLU=nn.ReLU()
self.c2=nn.Conv2d(in_channels=48,out_channels=128,kernel_size=5,stride=1,padding=2)
self.s2=nn.MaxPool2d(2)
self.c3=nn.Conv2d(in_channels=128,out_channels=192,kernel_size=3,stride=1,padding=1)
self.s3=nn.MaxPool2d(2)
self.c4=nn.Conv2d(in_channels=192,out_channels=192,kernel_size=3,stride=1,padding=1)
self.c5=nn.Conv2d(in_channels=192,out_channels=128,kernel_size=3,stride=1,padding=1)
self.s5=nn.MaxPool2d(kernel_size=3,stride=2)
self.flatten=nn.Flatten()
self.f6=nn.Linear(128*6*6,2048)
self.f7=nn.Linear(2048,2048)
self.f8=nn.Linear(2048,1000)
self.f9=nn.Linear(1000,2)
def forward(self,x):
x=self.ReLU(self.c1(x))
x=self.ReLU(self.c2(x))
x=self.s2(x)
x=self.ReLU(self.c3(x))
x=self.s3(x)
x=self.ReLU(self.c4(x))
x=self.ReLU(self.c5(x))
x=self.s5(x)
x=self.flatten(x)
x=self.f6(x)
x=F.dropout(x,p=0.5)
x=self.f7(x)
x=F.dropout(x,p=0.5)
x=self.f8(x)
x=F.dropout(x,p=0.5)
x=self.f9(x)
return x
if __name__ == '__main__':
x=torch.rand([1,3,224,224])
model=MyAlexNet()
y=model(x)
当然,经典神经网络的创建离不开torch.nn.Module,其中包含一系列函数,我们经常用到的是
卷积函数(torch.nn.Conv2d),我们可以在参数列表选择输入和输出的通道,卷积核大小,以及进行广播,选择跨度(padding stride)。
激活函数,包括(ReLU函数,tanh函数,sigmoid函数等),对我们输入的张量进行非线性处理。
池化函数,包括最大池化,最小池化,平均池化,注意池化层是没有参数的,只是对权重的选择(或进行均值处理)。参数表示池化窗口的大小。
平展函数,flatten,我们构建神经网络的时候,经常要将卷积处理之后的张量放入全链接层,为了保持维度的一致性,我们要对张量进行平展处理。将卷积处理得到的张量包含的所有权重进行平展。
全连接层:linear,对向量(一维)进行线性处理,可以按照我们的意愿得到我们希望的维度,但是需要较多的权重,一个比较好的解决办法是在卷积层的时候,将张量权重元素的输出尽量控制到一个较小的范围,但是会影响提取能力。
下面来看我们的层:
self.c1=nn.Conv2d(in_channels=3,out_channels=48,kernel_size=11,stride=4,padding=2)
self.ReLU=nn.ReLU()
self.c2=nn.Conv2d(in_channels=48,out_channels=128,kernel_size=5,stride=1,padding=2)
self.s2=nn.MaxPool2d(2)
self.c3=nn.Conv2d(in_channels=128,out_channels=192,kernel_size=3,stride=1,padding=1)
self.s3=nn.MaxPool2d(2)
self.c4=nn.Conv2d(in_channels=192,out_channels=192,kernel_size=3,stride=1,padding=1)
self.c5=nn.Conv2d(in_channels=192,out_channels=128,kernel_size=3,stride=1,padding=1)
self.s5=nn.MaxPool2d(kernel_size=3,stride=2)
self.flatten=nn.Flatten()
self.f6=nn.Linear(128*6*6,2048)
self.f7=nn.Linear(2048,2048)
self.f8=nn.Linear(2048,1000)
self.f9=nn.Linear(1000,2)我们选取神经网络层是根据相关论文。是实验表明较好的选择。
构建神经网络:
def forward(self,x):
x=self.ReLU(self.c1(x))
x=self.ReLU(self.c2(x))
x=self.s2(x)
x=self.ReLU(self.c3(x))
x=self.s3(x)
x=self.ReLU(self.c4(x))
x=self.ReLU(self.c5(x))
x=self.s5(x)
x=self.flatten(x)
x=self.f6(x)
x=F.dropout(x,p=0.5)
x=self.f7(x)
x=F.dropout(x,p=0.5)
x=self.f8(x)
x=F.dropout(x,p=0.5)
x=self.f9(x)
return x可见每经过一个卷积层,都要进行非线性处理,也就是带入激活函数中,当然,池化层不算做卷积层(很多同学因为池化层经常配合卷积层使用,错认为池化层也是卷积层)。
当我们卷积层处理完之后(最后一个池化后),将得到的张量带入flatten函数,进行平展处理。
处理之后送入全连接层,进行线性层的处理。
但是值得注意的是,在每一个全连接层处理之后,我们将得到的结果带入F.dropout函数,目的在于放弃其中部分的连接网络,因为太多的连接网络易造成过拟合。随机消失一部分有利于保留输入和标签之间的线性关系。
经过多个全连接层+网络消失的处理之后,我们得到的x就作为我们的输出。
下面我们进行验证。我们输出结果看一下:

这里我们得到是一个张量,[[0.0139,0.0212]]。我们如果需要得到其中的数据。需要用y[0][0].item()
这里用到的是两个括号。
下一步我们进行数据的预处理:

先上代码:
import os
from shutil import copy
import random
def mkdir(file):
if not os.path.exists(file):
os.makedirs(file)
#获取data文件夹下所有文件夹名(即需要分类的类名)
file_path='E:/BaiduNetdiskDownload/Kaggle猫狗大战/train'
flower_class= [cla for cla in os.listdir(file_path)]
#创建训练集train文件夹,并由类名在其目录下创建子目录
mkdir('data/train')
mkdir('data/train/cat')
mkdir('data/train/dog')
mkdir('data/val')
mkdir('data/val/cat')
mkdir('data/val/dog')
split_rate=0.1
for cla in flower_class:
cla_path=file_path+'/'+cla
#"E:\BaiduNetdiskDownload\Kaggle猫狗大战\train\train\cat.0.jpg"
images=os.listdir(cla_path)
print(cla_path)
num=len(images)
eval_index=random.sample(images,k=int(num*split_rate))
for index,image in enumerate(images):
if image in eval_index:
image_path = cla_path+'/'+image
if "cat" in image_path:
new_path = 'data/val/cat/'
else:
new_path = 'data/val/dog/'
copy(image_path,new_path)
else:
image_path=cla_path+'/'+image
if "cat" in image_path:
new_path='data/train/cat/'
else:
new_path='data/train/dog/'
copy(image_path,new_path)
print("\r[{}]processing[{}/{}]".format(cla,index+1,num),end="")
print()
print("processing done!")
首先我们要导入进行文件处理的库os。
导入进行图像文件复制的函数:from shutil import copy。
我们创建mkdir函数用来生成不存在的文件夹。
然后我们定义了我们的资源图片路径,也就是file_path。但是我们在copy的过程中,得到不同级目录之间是\符号,我们要主动进行处理,将其改为/符号。
之后对我们的资源文件进行遍历,找到其下一级目录。
这个函数指的是得到由我们的file_path文件夹下文件组成的列表。
split_rate是进行数据集划分,表示测试集占的比例。

得到file_path文件夹下级目录,我们得到的images是由该目录下图像文件的文件名组成的列表。也就是我们希望得到的图片路径。

这段代码使用random.sample函数从images列表中随机选择num*split_rate个元素,并将这些元素存储在名为eval_index的列表中,这通常用于划分数据集,例如将图片按照一定的比例分为数据集和训练集。
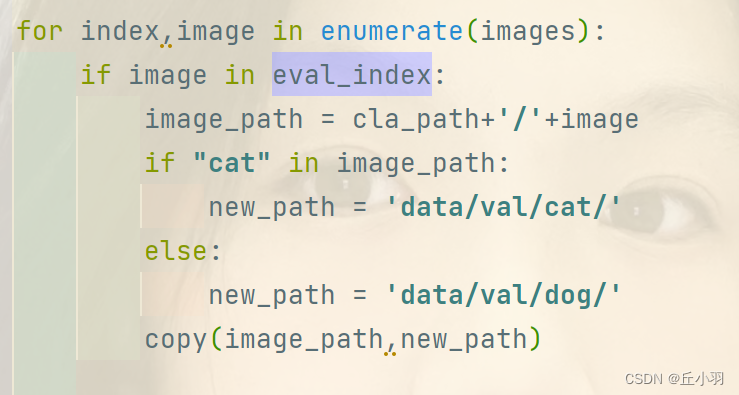
得到我们需要的图片在数据集中的路径,然后将图片内容复制到我们创建的文件夹下。
创建好数据集后,我们要对数据集进行训练:
import torch
from torch import nn
from net import MyAlexNet
import numpy as np
from torch.optim import lr_scheduler
import os
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
ROOT_TRAIN = 'C:/Users/86156/PycharmProjects/pythonProject1/cat-dog/data/train'
ROOT_TEST='C:/Users/86156/PycharmProjects/pythonProject1/cat-dog/data/val'
normalize=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
train_transform=transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize
])
val_transform=transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
#ImageFolder函数会根据文件夹的名称为每张图片分配一个类别标签,在这个训练集中,类别标签分别为0(表示cat)1(表示dog)
train_dataset=ImageFolder(ROOT_TRAIN,transform=train_transform)
val_dataset=ImageFolder(ROOT_TEST,transform=val_transform)
train_dataloader=DataLoader(train_dataset,batch_size=32,shuffle=True)
val_dataloader=DataLoader(val_dataset,batch_size=32,shuffle=True)
model=MyAlexNet()
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
lr_scheduler=lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.5)
def train(dataloader,model,loss_fn,optimizer):
loss,current,n =0.0,0.0,0.0
for batch,(x,y) in enumerate(dataloader):
image,y =x,y
output=model(image)
cur_loss=loss_fn(output,y)
_,pred=torch.max(output,axis=1)
cur_acc=torch.sum(y==pred)/output.shape[0]
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss+=cur_loss.item()
current+=cur_acc.item()
n+=1
train_loss=loss/n
train_acc=current/n
print('train_loss'+str(train_loss))
print('train_acc'+str(train_acc))
return train_loss,train_acc
def val(dataloader,model,loss_fn):
model.eval()
loss,current,n=0.0,0.0,0.0
with torch.no_grad():
for batch,(x,y) in enumerate(dataloader):
image,y =x,y
output=model(image)
cur_loss=loss_fn(output,y)
_,pred=torch.max(output,axis=1)
cur_acc=torch.sum(y==pred)/output.shape[0]
loss+=cur_loss.item()
current+=cur_acc.item()
n+=1
val_loss=loss/n
val_acc=current/n
print('val_loss'+str(val_loss))
print('val_acc'+str(val_acc))
return val_loss,val_acc
def matplot_loss(train_loss,val_loss):
plt.plot(train_loss,label='train_loss')
plt.plot(val_loss,label='val_loss')
plt.legend(loc='best')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.title("训练集和验证集loss值对比图")
plt.show()
def matplot_acc(train_loss,val_loss):
plt.plot(train_acc,label='train_acc')
plt.plot(val_acc,label='val_acc')
plt.legend(loc='best')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.title("训练集和验证集acc值对比图")
plt.show()
loss_train=[]
acc_train=[]
loss_val=[]
acc_val=[]
epoch=20
min_acc=0
for t in range(epoch):
lr_scheduler.step()
print(f"epoch{t+1}\n----------------")
train_loss,train_acc=train(train_dataloader,model,loss_fn,optimizer)
val_loss,val_acc=val(val_dataloader,model,loss_fn)
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc)
if val_acc>min_acc:
folder='save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc=val_acc
print(f"save best model,第{t+1}轮")
torch.save(model.state_dict(),'save_model/best.model.pth')
if t==epoch-1:
torch.save(model.state_dict(),'save_model/last_model.pth')
print('Done')
这段代码较长,其中一个细节处理事,进行绘图中文输出:
我们使用:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rdParams;'axes.unicode_minus']=False
表示进行中文绘制图表输出。
transforms.Compose函数是对数据预处理的操作序列,transforms.Compose函数的作用是将多个对数据处理的操作转化为一个整体的数据转化流水线,可以将多个数据处理步骤按顺序串联起来,方便对数据进行一系列的处理操作。具体处理事将图像大小缩放为224*224,将训练集进行随机垂直翻转(用于增强数据的多样性,有助于提高模型的泛化能力,防止过拟合)。之后将图像转化为张量,再对得到的张量进行归一化处理。

这一段函数是从我们的设定路径中加载我们的图像,并对其进行数据操作(我们在上面已经定义过)。ImageFolder函数会根据文件夹的名称为每一张图片分配一个类别标签,在这个训练集中,我们一共生成两个类别标签。(分别是0和1,对应cat和dog)。我们得到的是一个二维张量。

创建一个用于加载数据集的数据加载器,batch_size表示每个批次的样本数量。shuffle表示每个epoch开始时是否对数据进行随机重排序,数据加载器可以帮助有效的加载数据并组织成批次,以便于模型训练与验证。

表示计算的损失是交叉熵损失。

SGD是随机梯度下降算法的优化器,是深度学习中最常用的优化器之一,通过不断的迭代更新模型的权重使损失函数逐渐收敛到最小值,从而提高模型的准确性,第一个参数表示优化的是整个模型中所有的权重,第二个参数表示优化率是0.01,第三个参数表示动量,是随机梯度下降算法实现的一个必要因素,模拟物理模型中的动量,动量小比较容易根据之前优化路线进行前进,受到先验优化影响较大,比较易于我们跳出鞍点,动量大易于我们在最优解附近进行精致的收敛,当然二者的优势也是另一方的劣势,所以我们需要尽量在优势和劣势之间平衡,取值范围是0到1。
lr——scheduler是用于动态调整学习率的工具,在训练神经网络中非常有用,可以帮助模型收敛并获得更好的性能,称之为学习率调度器。常见的学习率调度策略包括学习率衰减,学习率周期性变化等,我们使用的StepLR是指学习率衰减,step_size指的是按照给定的步骤进行衰减,也就是每隔十轮进行衰减一次,衰减因子是gamma,表示每次调整使得学习率*gamma。
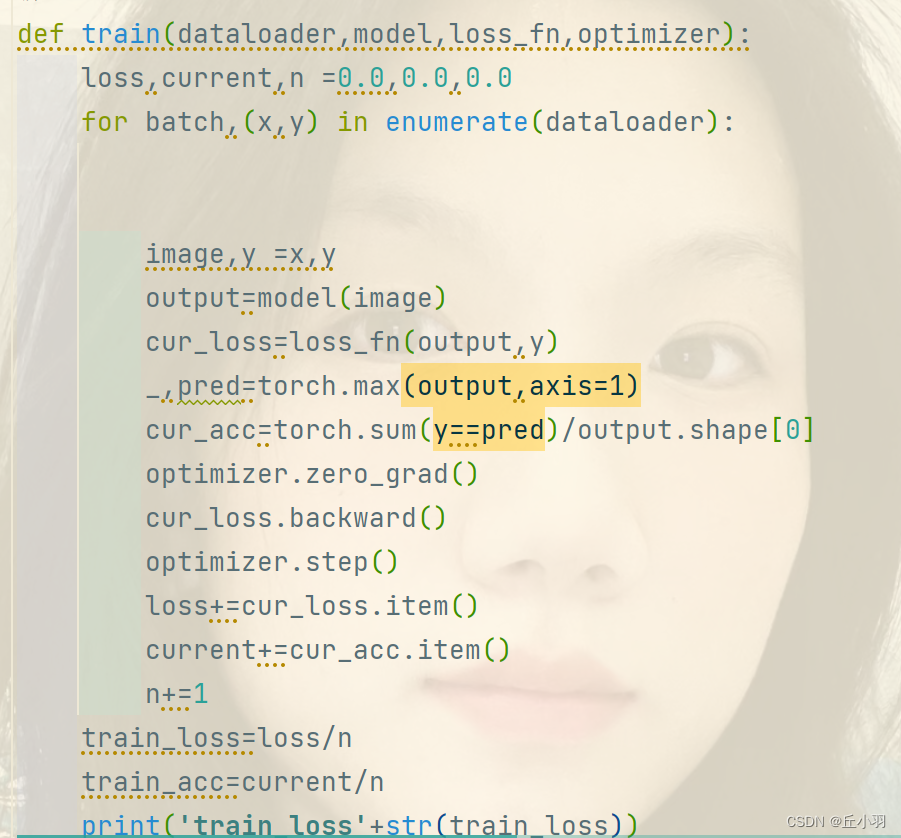
接下来我们进行一轮训练:批次是我们选择用于训练的样本数量。
_,pred=torch.max(output,axis=1):torch.max函数返回的是参数列表的最大值及其对应的索引。axis表示按照第一个维度进行搜索。
而后进行经典的梯度归零,反向传播,优化。
这里还是要强调一下batch_size的内涵,batch_size表示在训练过程中每个批次中包含的样本数量。在神经网络的训练过程中,通常将大量的数据按若干个批次进行训练。每个批次中包含的样本数量就是batch_size。
那么这段代码中批次的数量就是len(dataloader)/batch_size。

指的是将模型中所有权重的参数保存到给定的.pth文件中。
下面进行我们的最后一个部分:
进行测试,先上代码:
import torch
from net import MyAlexNet
from torch.autograd import variable
from torchvision import datasets,transforms
from torchvision.transforms import ToPILImage
from torchvision.datasets import ImageFolder
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
ROOT_TRAIN = 'C:/Users/86156/PycharmProjects/pythonProject1/cat-dog/data/train'
ROOT_TEST='C:/Users/86156/PycharmProjects/pythonProject1/cat-dog/data/val'
normalize=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
train_transform=transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
normalize
])
val_transform=transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize
])
train_dataset=ImageFolder(ROOT_TRAIN,transform=train_transform)
val_dataset=ImageFolder(ROOT_TEST,transform=val_transform)
train_dataloader=DataLoader(train_dataset,batch_size=32,shuffle=True)
val_dataloader=DataLoader(val_dataset,batch_size=32,shuffle=True)
model=MyAlexNet()
model.load_state_dict(torch.load("C:/Users/86156/PycharmProjects/pythonProject1/cat-dog/save_model/best.model.pth"))
classes=[
"cat",
"dog",
]
show=ToPILImage()
model.eval()
for i in range(50):
x,y = val_dataset[i][0],val_dataset[i][1]
show(x).show()
x=torch.tensor(torch.unsqueeze(x,dim=0).float(),requires_grad=True)
x=torch.tensor(x)
with torch.no_grad():
pred=model(x)
print(pred)
predicted,actual=classes[torch.argmax(pred[0])],classes[y]
print(f'predicted:"{predicted}",Actual:"{actual}"')
我们如何载入数据和对数据进行处理方法同训练过程。
但是不同的是,我们直接加载训练过的权重。

也就是我们之前保存的pth文件。
我们使用ToPILImage函数用于将我们经过处理得到的张量转化为图像形式。

我们的val_dataset张量的0维度是一个3的通道的图片张量,1维是标签,是在ImageFolder中生成的分类。
然后我们在处理的时候将图像张量使用unsqueeze函数扩充一个0维度。再转化为浮点型张量,之所以转化为浮点型是因为有很多关于张量处理的操作(如梯度自动求导)只在浮点型张量的情况下才能实现。
with no grad表示的是不进行张量的计算。
但是有一个问题是我们在输出图片的时候,输出的是明显被处理过的图片,我们想要输出原图的话,只需要把val_transform=transforms.Compose中的参数normalize函数去掉就行了。(这个函数对图像进行归一化处理,很显然,我们的图像之所以输出不正常是归一化处理造成的。因为ImageToTensor函数和ToTensor函数互为逆函数)。