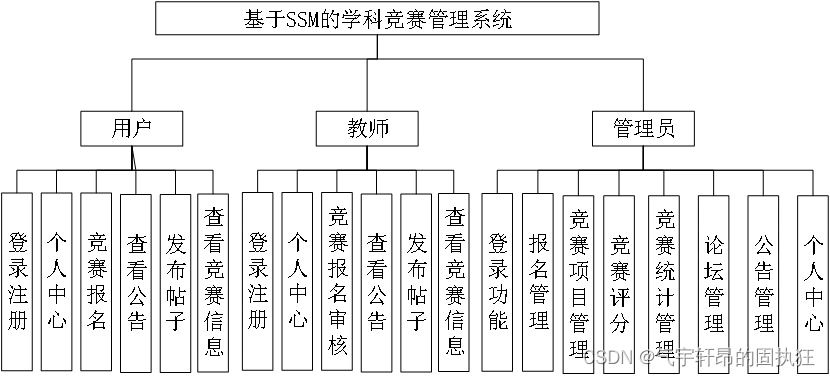
摘要
知识蒸馏从教师网络转移到学生网络,目的是大大提高学生网络的性能。以往的方法主要是通过提出特征变换和同级特征之间的损失函数来提高有效性。对师生网络连接路径交叉层次的影响因素进行了不同程度的研究,揭示了其重要性。在知识蒸馏中首次提出了跨阶段连接路径。我们新的审查机制有效,结构简单。我们最终设计的嵌套和紧凑的框架需要可以忽略不计的计算开销,并且在各种任务上由于其他方法。我们将我们的方法应用于分类、对象检测和实例分割任务。
介绍
知识蒸馏在文献[9]中首次提出。这个过程是在一个更大的网络(也就是教师)的监督下训练一个小网络(也就是学生)。在[9]中,知识是从教师里提炼出来的logit,这意味着学生同时受到ground truth和教师logit的监督。近年来,人们一直在努力提高蒸馏效率。FitNet[25]通过中间特征提取知识。AT[38]进一步优化了FitNet,利用特征的注意图传递知识。PKT[23]将教师的知识建模为概率分布,而CRD[28]使用对比目标来转移知识。所有这些解决方案都集中在变换和损失函数上。
我们的新发现:本文从教师与学生之间的联系路径这一新的视角来解决这一具有挑战性的问题。为了简单地理解我们的想法,我们首先提示之前的工作是如何处理这些路径的。如图1(a)-©所示,前面的方法都只是使用同一层次的信息来引导学生。例如,在监督学生的第四阶段输出时,总是使用教师的第四阶段信息。这个程序看起来很直观,很容易构造。

但有趣的是,我们发现它实际上是整个知识蒸馏框架的瓶颈——结构的快速更新惊人地提高了许多任务的整个系统性能。
我们研究了之前在知识蒸馏中被忽视的连接路径设计的重要性,并提出了一个新的有效框架。关键的改进是使用教师网络中的底层特征来监督学生的深层特征,这大大提高了整体性能。
我们进一步分析了网络结构,发现学生高水平阶段从教师的低水平特征中学习有用信息的能力很大。这个过程类似于人类的学习曲线,小孩子只能理解教授的一小部分知识。在成长的过程中,越来越多来自过去岁月的知识可能会逐渐被理解并记忆为经验。
我们的知识回顾架构
基于这些发现,我们提出利用教师的多层次信息来指导学生网络的一层信息。我们的新框架如图1(d)所示,我们称之为“知识回顾”。回顾机制是使用以前的(较浅的)特性来指导当前的特性。这意味着学生必须经常检查以前学过的知识,以获得新的理解和“旧知识”的背景。在我们人类的学习中,将不同阶段的知识联系起来是一种常见的做法。
然而,如何从教师提供的多层次信息中提取有用的信息并将其传递给学生是一个开放和具有挑战的问题。为了解决这些问题,我们提出了一个残差学习框架,使学习过程稳定高效。此外,**设计了一种新的基于注意力的融合(ABF)模块和层次上下文丢失(HCL)功能来提高性能。**我们提出的框架使学生网络大大提高了学习的有效性。
主要贡献
1、我们提出了一种新的知识蒸馏回顾机制,利用教师的多层次信息来指导学生网络的一层学习。
2、为了更好地实现回顾机制的学习过程,我们提出了残差学习框架。
3、为了进一步完善知识回顾机制,我们提出了基于注意力的融合(ABF)模块和层次上下文损失(HCL)函数
我们的方法
我们首先形式化了知识蒸馏提炼过程和回顾机制。然后,我们提出了一个新的框架,并引入了基于注意力的融合模块和分层上下文损失函数。
回顾机制
给定输入图像X和学生网络S,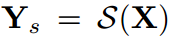 表示学生的输出logit。S可以分成不同的部分(S1,S2,…Sn,Sc),Sc是分类器,S1,…,Sn是被下采样层分割的不同阶段。因此,产生输出Ys的过程可以表示为:
表示学生的输出logit。S可以分成不同的部分(S1,S2,…Sn,Sc),Sc是分类器,S1,…,Sn是被下采样层分割的不同阶段。因此,产生输出Ys的过程可以表示为:
KaTeX parse error: Can't use function '$' in math mode at position 12: Y_s = S_c $̲\circ$ ....$\ci…
我们将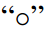 称为函数嵌套,其中
称为函数嵌套,其中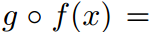
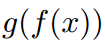 。
。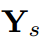 为学生的输出,中间特征为
为学生的输出,中间特征为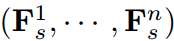 。第i个特征计算为:
。第i个特征计算为:
KaTeX parse error: Can't use function '$' in math mode at position 14: F_s^i = S_i $̲\circ$ ....$\ci…
对于教师网络T,过程几乎相同,我们省略了细节。根据前面的符号,单层知识蒸馏可以表示为:
L
S
K
D
=
D
(
M
s
i
(
F
s
i
)
,
M
t
i
(
F
t
i
)
)
L_{SKD} = D(M_s^i(F_s^i),M_t^i(F_t^i))
LSKD=D(Msi(Fsi),Mti(Fti))
其中M是将特征转化为注意图[38]或因素[14]的目标表示的转换,D是距离函数用于衡量学生和教师之间的差距。类似的,多层知识蒸馏写为:
L
M
K
D
=
∑
i
∈
I
D
(
M
s
i
)
L_{MKD} = \sum_{i \in I}D(M_s^i)
LMKD=i∈I∑D(Msi)
I存储特征层来传递知识。
我们的评审机制是使用以前的特性来指导当前的特性。带评审机制的单层知识蒸馏形式化为:
L
S
K
D
R
=
∑
j
=
1
i
D
(
M
S
i
,
j
(
F
s
i
)
,
M
t
j
,
i
(
F
t
j
)
)
L_{SKD_R} = \sum _{j=1}^i D(M_S^{i,j}(F_s^i),M_t^{j,i}(F_t^j))
LSKDR=j=1∑iD(MSi,j(Fsi),Mtj,i(Ftj))
虽然乍一看,它与多层知识蒸馏有一些相似之处,但实际上是根本不同的。在这里,学生的特征被固定为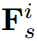 ,我们用老师的前i层特征来引导
,我们用老师的前i层特征来引导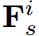 。审查机制和多层蒸馏是互补的概念。将评审机制与多层知识蒸馏相结合,损失函数变为:
。审查机制和多层蒸馏是互补的概念。将评审机制与多层知识蒸馏相结合,损失函数变为:
L
M
K
D
R
=
∑
i
∈
I
(
∑
j
=
1
i
)
D
(
M
s
i
,
j
(
F
s
i
)
,
M
t
j
,
i
(
F
t
j
)
)
L_{MKD_R} = \sum _{i \in I}(\sum _{j=1}^i)D(M_s^{i,j}(F_s^i),M_t^{j,i}(F_t^j))
LMKDR=i∈I∑(j=1∑i)D(Msi,j(Fsi),Mtj,i(Ftj))
在我们的实验中,在训练过程中,简单地将损失与原始损失单独相加推理结果与原始模型完全相同。所以我们的方法在测试时完全没有成本。使用因子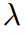 平衡蒸馏损失和原始损失。以分类任务为例,将整个损失函数定义为:
平衡蒸馏损失和原始损失。以分类任务为例,将整个损失函数定义为:
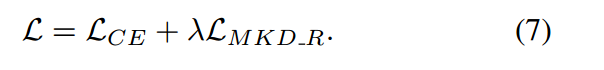
在我们提出的审查机制中,我们只使用教师的浅层特征来监督学生的较深特征。我们发现,相反的做法带来了边际效益,反而浪费了大量的资源。直观的解释是,更深层、更抽象的特征对于早期学习来说太复杂了。
残差学习框架
根据之前的工作,我们首先设计了一个简单的框架,如图2(a)所示。变换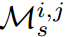 简单地由卷积层和最近的插值层组成,将学生的第i个特征 转移到匹配教师的第j个特征的大小。我们不变换教师特征
简单地由卷积层和最近的插值层组成,将学生的第i个特征 转移到匹配教师的第j个特征的大小。我们不变换教师特征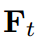 。学生特征被变换成与教师特征相同的大小。
。学生特征被变换成与教师特征相同的大小。
图2(b)显示了将该思想直接应用于多层蒸馏,并蒸馏了所有阶段的特征。然而,由于层之间存在巨大的信息差异这种策略并不是最优的。因此,它产生了一个复杂的过程,其中使用了所有功能。例如,有n个阶段的网络需要计算n(n+1)/2对损失函数的特征,这使得学习过程非常繁琐,耗费大量的资源。
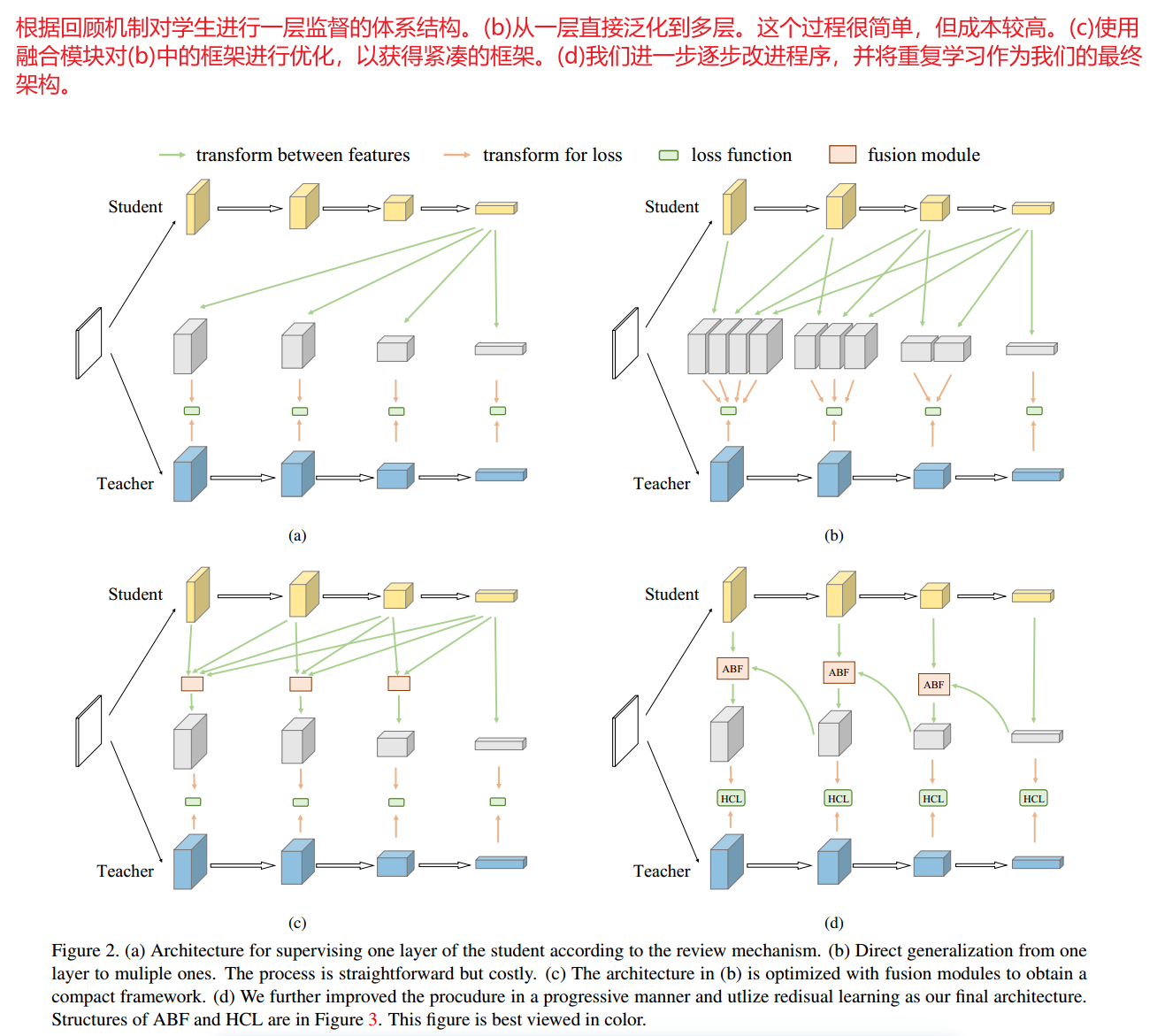
为了使过程更加可行和优雅,我们将图2(b)的等式(6)重新描述为
L
M
K
D
R
=
∑
i
=
1
n
(
∑
j
=
1
i
D
(
F
s
i
,
F
t
j
)
)
L_{MKD_R} = \sum_{i=1}^n(\sum_{j=1}^iD(F_s^i,F_t^j))
LMKDR=i=1∑n(j=1∑iD(Fsi,Ftj))
为了简单起见,省略了特征的变换。现在我们交换i和j的两个求和的顺序
L
M
K
D
R
=
∑
j
=
1
n
(
∑
i
=
j
n
D
(
F
s
i
,
F
t
j
)
)
L_{MKD_R} = \sum_{j=1}^n(\sum_{i=j}^nD(F_s^i,F_t^j))
LMKDR=j=1∑n(i=j∑nD(Fsi,Ftj))
当j固定时,等式9累加教师特征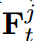 与学生特征
与学生特征 之间的距离。通过特征融合[40,16],我们将距离的总和近似为融合特征的距离。它会导致
之间的距离。通过特征融合[40,16],我们将距离的总和近似为融合特征的距离。它会导致
∑
i
=
j
n
D
(
F
s
i
,
F
t
i
)
≈
D
(
U
(
F
s
j
,
.
.
.
.
,
F
s
n
)
,
F
t
j
)
\sum_{i=j}^nD(F_s^i,F_t^i) \approx D(U(F_s^j,....,F_s^n),F_t^j)
i=j∑nD(Fsi,Fti)≈D(U(Fsj,....,Fsn),Ftj)
其中U是融合特征的模块。图2©说明了这种近似,其中结构现在更有效了。但为了提高计算效率,可以进一步优化融合计算,如图2(d)所示。 的融合由
的融合由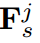 和
和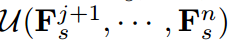 组合计算,其中融合操作递归定义为
组合计算,其中融合操作递归定义为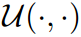 ,应用于连续的特征映射。将
,应用于连续的特征映射。将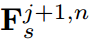 记为特征从
记为特征从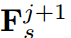 到
到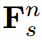 的融合,损失记为:
的融合,损失记为:
L
M
K
D
R
=
D
(
F
s
n
,
F
t
n
)
+
∑
j
=
n
−
1
1
D
(
U
(
F
s
i
,
F
s
j
+
1
,
n
)
,
F
t
j
)
L_{MKD_R} = D(F_s^n,F_t^n) + \sum_{j=n-1}^1 D(U(F_s^i,F_s^{j+1,n}),F_t^j)
LMKDR=D(Fsn,Ftn)+j=n−1∑1D(U(Fsi,Fsj+1,n),Ftj)
在这里我们从n-1循环到1来使用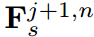 ,详细结构如图2(d)所示,其中ABF和HCL分别是为此结构设计的融合模块和损失函数。图2(d)中的结构很简洁,利用残差学习的概念简化了提炼过程。例如,将第四阶段的学生特征与第三阶段的学生特征聚合起来,以模仿第三阶段的教师特征。因此,第四阶段的学生特征学习了第三阶段的学生与教师之间特征的残差。残差信息很可能是教师产生高质量教学结果的关键因素。
,详细结构如图2(d)所示,其中ABF和HCL分别是为此结构设计的融合模块和损失函数。图2(d)中的结构很简洁,利用残差学习的概念简化了提炼过程。例如,将第四阶段的学生特征与第三阶段的学生特征聚合起来,以模仿第三阶段的教师特征。因此,第四阶段的学生特征学习了第三阶段的学生与教师之间特征的残差。残差信息很可能是教师产生高质量教学结果的关键因素。
这种残差学习过程比直接让学生的高阶特征从教师的低阶特征中学习更稳定有效。利用残差学习框架,学生的高级特征可以更好地逐步提取有用信息。此外,使用等式(11),我们消除了求和并将总复杂度降低到n对距离。
ABF和HCL
图2(d)中有两个关键组件。它们分别是基于注意的融合(ABF)和层次上下文丢失(HCL)。我们在这里解释一下。
ABF模块利用[30,12]的洞察力,如图3(a)所示。高级特征首先被调整为低级特征相同的形状。然后将来自不同层次的两个特征连接在一起,生成两个H×W注意图。这些特征图分别与两个特征相乘。最后,添加这两个特征以生成最终输出。
ABF模块可以根据输入特征生成不同的注意图。因此,两个特征映射可以动态聚合。由于两种特征图来自不同的网络阶段,其信息具有多样性,因此自适应和优于直接和。低级和高级特征可能关注不同的分区。注意图可以更合理地聚集它们。
HCL的详细情况如图3(b)所示。通常,我们使用L2距离作为两个特征映射之间的损失函数。L2距离对于同一层特征之间的信息传递是有效的。但在我们的框架中,不同层次的信息被聚集在一起,向老师学习。微小的全局L2距离不足以传递符合能级的信息。
受[41]的启发,我们提出了HCL,利用空间金字塔池,将知识转移到不同层次的上下文信息中。这样,信息可以更好地提炼成不同的抽象层次。结构非常简单:我们首先使用空间金字塔也从特征中提取不同层次的知识,然后分别用L2距离进行蒸馏。尽管结构简单,但HCL适合我们的框架。



![BUUCTF:[MRCTF2020]ezmisc](https://img-blog.csdnimg.cn/direct/54ca5247aacd47d3ac878540b42ab044.png)