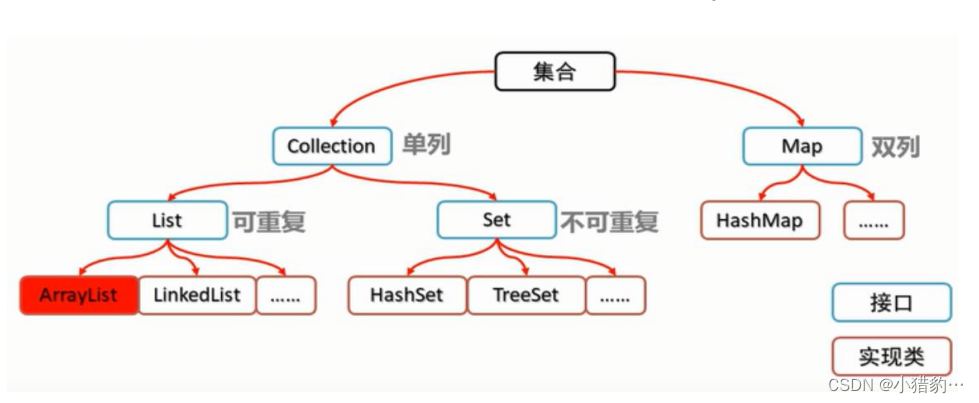
集合的概念
当我们需要保存一组一样(类型相同)的元素的时候,我们应该使用一个容器来存储,数组就是这样一个容器。
数组的特点:
数组是一组数据类型相同的元素集合;
创建数组时,必须给定长度,而且一旦创建长度不能改变;
一旦数组装满元素,就需要创建一个新的数组,将元素复制过去;
数组的局限:
如果装满了,就需要数组复制;
当我们需要从数组中删除或添加一个元素,需要移动后面的元素;
集合的作用:
在开发实践中,我们需要一些能够动态增长长度的容器来保存我们的数据,java中为了解决数据存储单一的情况,java中就提供了不同结构的集合类,可以让我们根据不同的场景进行数据存储的选择,如Java中提供了 数组实现的集合,链表实现的集合,哈希结构,树结构等。
分类
单列集合:一次放进去一个值 ( 对象 )
Collection接口:定义了单列集合共有的方法,其子接口Set和List分别定义了存储方式
List:可以有重复元素
Set:不可以有重复元素
双列集合: 键 值
集合API
集合体系概述: Java的集合框架是由很多接口、抽象类、具体类组成的,都位于java.util包中。
List 接口及实现类
概念:List继承了Collection接口,有三个实现的类,分别是:
ArrayList 数组列表
LinkedList 链表列表
Vector 数组列表 (是线程安全的)
1. ArrayList
底层有一个数组,可以动态扩展数组长度,并提供了一系列方法操作。
特点: 查询快,在中间增加 / 删除慢
注意:集合容器类中默认可以添加Object类型,但是一般建议一个集合对象只保存同一种类型,若保存多个类型后期处理时涉及类型转换问题;所以我们可以通过泛型来加以控制。
泛型:声明类型时可以自定义参数类型
ArraysList <E>
ArrayList的常用方法:
ArrayList<String> arrayList = new ArrayList();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
arrayList.add(3,"a");
arrayList.remove("a"); //根据内容删除匹配的第一个元素,返回值为boolean
arrayList.remove(1); //删除并返回指定位置的元素
arrayList.get(1); //获取指定位置的元素
arrayList.set(1,"X"); //替换并返回指定位置的元素
arrayList.clear(); //清空集合中的元素
arrayList.isEmpty(); //判断集合元素是否为空
arrayList.contains("c"); //判断是否包含指定元素
arrayList.size(); //返回集合中元素个数2. LinkedList
底层是一个链表结构,查询效率低,但增加 / 删除元素快
LinkedList中方法及功能和ArrayList中的方法大致相同,只不过LinkedList中多了关于队列和栈相关的操作方法。

3. Vector
和ArrayList一样,底层也是数组实现,不同的是Vector的方法默认加了锁,线程是安全的。
List接口集合迭代
List集合遍历方式有四种:
1. for循环遍历 2. 增强for循环遍历
//List集合遍历方式1:for循环
for (int i = 0; i < arrayList.size(); i++) {
if ("a".equals(arrayList.get(i))){
arrayList.remove("a");//允许修改集合元素
i--; // 要注意索引的变化与元素位置的移动
}
}
System.out.println(arrayList);
System.out.println("----------------");
//List集合遍历方式2:增强for循环
for (String s:arrayList) {
System.out.println(s); //不能修改集合元素
}3. 迭代器遍历 (Iterator)
//List集合遍历方式3:使用迭代器遍历
//获得集合对象的迭代器对象
Iterator<String> it = arrayList.iterator();
while(it.hasNext()){
String s = it.next();//获取下一个院系
if (s.equals("a")) {
it.remove(); //使用迭代器对象删除元素
}
}
System.out.println(arrayList);4. ListIterator迭代器:
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
arrayList.add("d");
/*
ListIterator迭代器只能对List接口下的实现遍历
ListIterator(index)可以从指定位置开始向前向后遍历
*/
ListIterator<String> listIterator= arrayList.listIterator(arrayList.size());
while(listIterator.hasPrevious()){
System.out.println(listIterator.previous());//逆序遍历
}
}Set接口
Set接口也继承了Collection接口,Set中所储存的元素是不重复的,但是是无序的,Set中的元素没有索引。
Set接口的实现类
● HashSet
1. HashSet类中的元素不能重复
public static void main(String[] args) {
HashSet set =new HashSet<>();
set.add("a");
set.add("a");
set.add("b");
set.add("c"); //元素是不重复的
System.out.println(set);
}
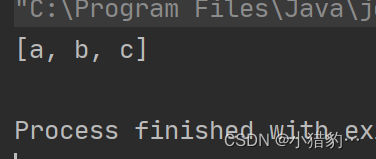
2. HashSet类中的元素是无序的
public static void main(String[] args) {
HashSet set =new HashSet<>();
set.add("c");
set.add("s");
set.add("x");
set.add("d"); //元素是无序的
System.out.println(set);
set.remove("s");//没有索引,只能根据内容遍历
set.iterator();//没有索引,要用迭代器遍历
}
HashSet在添加元素时,是如何判断元素重复的? * 重点 *
在底层会先调用hashCode(),注意,Object中的hashCode()返回的是对象的地址,此时并不会调用;此时调用的是类中重写的hashCode(),返回的是根据内容计算的哈希值,遍历时,会用哈希值先比较是否相等,会提高比较的效率;但哈希值会存在问题:内容不同,哈希值相同;这种情况下再调equals比较内容,这样既保证效率又确保安全。
例:
这是错误写法,此时默认调用的是Object类中hashCode( ),返回对象地址
import java.util.HashSet;
import java.util.Objects;
public class Student {
private String name ;
private String num;
public Student(String name, String num) {
this.name = name;
this.num = num;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", num='" + num + '\'' +
'}';
}
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
Student s1 = new Student("小王1","10001");
Student s2 = new Student("小王2","10002");
Student s3 = new Student("小王3","10003");
Student s4 = new Student("小王1","10001");
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
System.out.println(set);
}
}
正确写法应该是,在Student类中重写hashCode()和equals()
package Demo;
import java.util.HashSet;
import java.util.Objects;
public class Student {
private String name ;
private String num;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return num.equals(student.num);
}
@Override
public int hashCode() {
return Objects.hash(num);
}
public Student(String name, String num) {
this.name = name;
this.num = num;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", num='" + num + '\'' +
'}';
}
public static void main(String[] args) {
HashSet<Student> set = new HashSet<>();
Student s1 = new Student("小王1","10001");
Student s2 = new Student("小王2","10002");
Student s3 = new Student("小王3","10003");
Student s4 = new Student("小王1","10001");
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
System.out.println(set);
}
}
这样就能避免重复了(此图是s1,s4重复,但只输出s1)

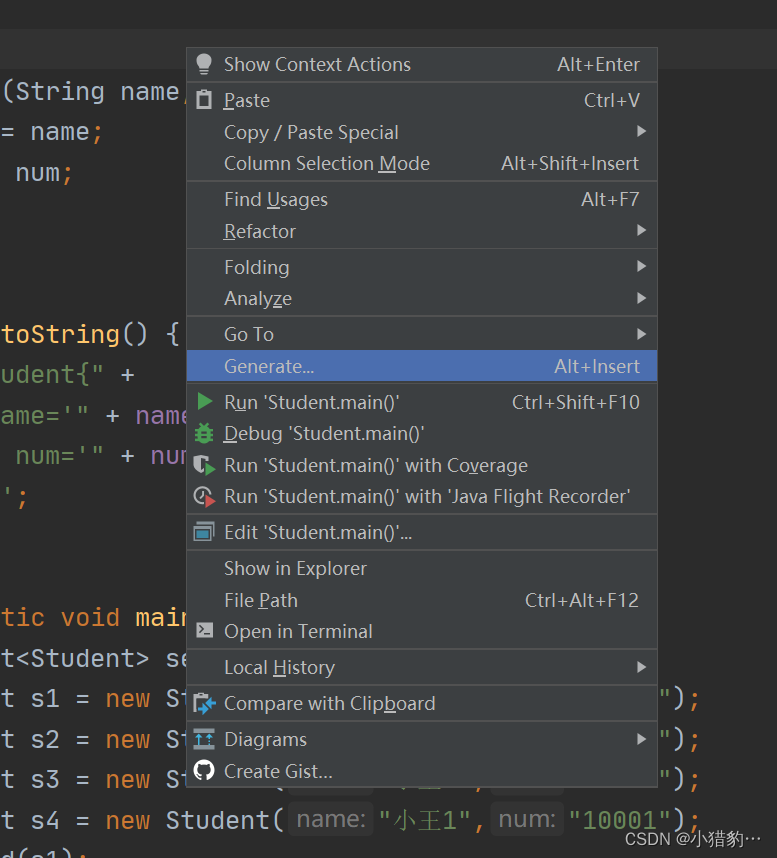
补充:如何快速生成hashCode()和equals()的重写方法?
右键选择Generate,选择equals()and hashCode(),选择重写的属性。



● TreeSet
......敬请期待^_^