环境:
Win10
11代i7 64G内存 500G硬盘
chatgpt-on-wechat
RWKV-Runner
问题描述:
如何把chatgpt-on-wechat 与RWKV-Runner结合打造本地微信chatgpt机器人
解决方案:
chatgpt-on-wechat项目
有4种运行程序的方式供你选择:

本地开发环境支持 MacOS、Windows、Linux 系统,需要安装 python 环境,推荐的版本在 3.7.1 ~ 3.9.X 之间,可前往 官网 下载。
提示
在命令行执行 python3 -V,如果能显示正确的版本则表示安装成功。需要注意的是,python3 只是一个指向python解释器的引用,有可能在你的系统里这个别名是 "python" 或者 "python3.8",那么在后面你就需要用 "python" 或 "python3.8" 来代替 python3 运行程序。同样的,执行 pip3 -V 来确认已经成功安装包管理软件 pip。
RWKV-Runner项目
本项目旨在消除大语言模型的使用门槛,全自动为你处理一切,你只需要一个仅仅几MB的可执行程序。此外本项目提供了与OpenAI API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端
一、本地部署chatgpt-on-wechat
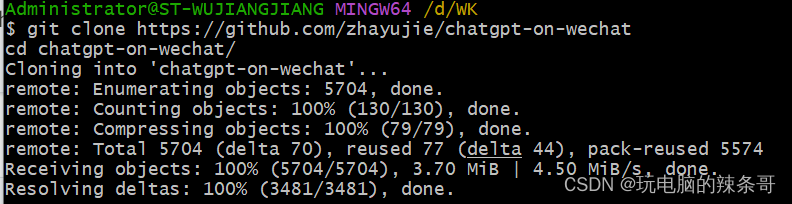
1.下载源码
在命令行使用 git 克隆项目并进入目录:
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
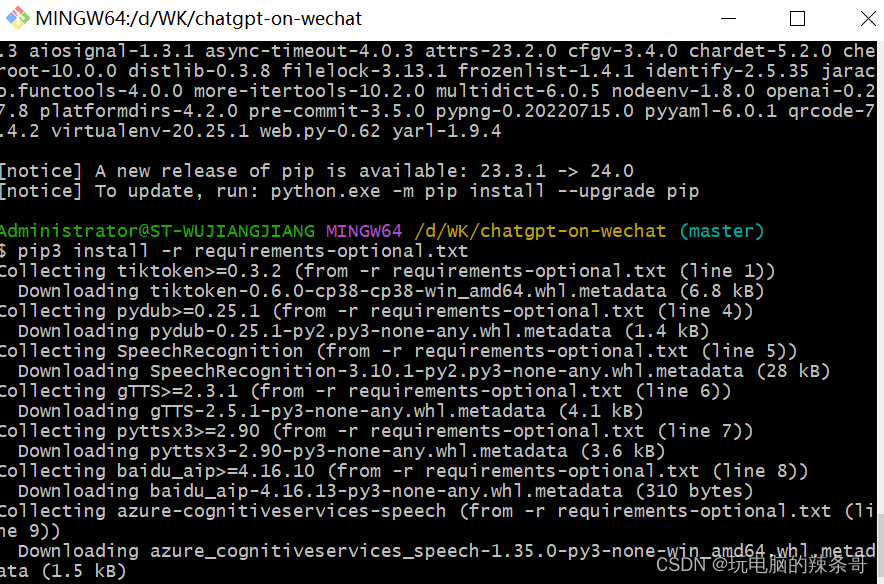
2.安装依赖
需要耐心等待一段时间
pip3 install -r requirements.txt # 必选依赖
pip3 install -r requirements-optional.txt # 可选依赖,语音、tool插件等功能需要
3.配置
复制项目中的模板文件 config-template.json,来生成最终起效果的配置文件config.json,你可以通过执行以下命令完成:
cp config-template.json config.json
然后打开 config.json 文件,添加所需配置,具体配置含义参考 配置说明。
配置说明
说明
选择不同的部署方式进行配置的形式不同,但配置项的使用是完全相同的。
Railway部署在模板页面中填写,Docker部署在 docker-compose.yml 文件中填写,Python部署则需要在 config.json 配置文件中填写。其中 docker-compose.yml 文件中的配置项使用大小写均可。
下面以 Python部署 方式为例,介绍各配置项的用法。配置文件的模板在根目录的config-template.json中,可以复制该模板创建最终生效的 config.json 文件:
cp config-template.json config.json
然后在config.json中填入配置即可,以下是对默认配置的说明,可根据需要进行自定义修改(在实际json文件中要去掉注释哦):
# config.json文件内容示例
{
"open_ai_api_key": "YOUR API KEY", # 填入上面创建的 OpenAI API KEY
"model": "gpt-3.5-turbo", # 模型名称。当use_azure_chatgpt为true时,其名称为Azure上model deployment名称
"proxy": "", # 代理客户端的ip和端口
"single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复
"single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人
"group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复
"group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"], # 开启自动回复的群名称列表
"group_chat_in_one_session": ["ChatGPT测试群"], # 支持会话上下文共享的群名称
"image_create_prefix": ["画", "看", "找"], # 开启图片回复的前缀
"conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数
"speech_recognition": false, # 是否开启语音识别
"group_speech_recognition": false, # 是否开启群组语音识别
"use_azure_chatgpt": false, # 是否使用Azure ChatGPT service代替openai ChatGPT service. 当设置为true时需要设置 open_ai_api_base,如 https://xxx.openai.azure.com/
"azure_deployment_id": "", # 采用Azure ChatGPT时,模型部署名称
"character_desc": "你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。", # 人格描述
# 订阅消息,公众号和企业微信channel中请填写,当被订阅时会自动回复,可使用特殊占位符。目前支持的占位符有{trigger_prefix},在程序中它会自动替换成bot的触发词。
"subscribe_msg": "感谢您的关注!\n这里是ChatGPT,可以自由对话。\n支持语音对话。\n支持图片输出,画字开头的消息将按要求创作图片。\n支持角色扮演和文字冒险等丰富插件。\n输入{trigger_prefix}#help 查看详细指令。"
}
配置说明:
1.个人聊天
个人聊天中,需要以 "bot"或"@bot" 为开头的内容触发机器人,对应配置项 single_chat_prefix (如果不需要以前缀触发可以填写 "single_chat_prefix": [""])
机器人回复的内容会以 "[bot] " 作为前缀, 以区分真人,对应的配置项为 single_chat_reply_prefix (如果不需要前缀可以填写 "single_chat_reply_prefix": "")
2.群组聊天
群组聊天中,群名称需配置在 group_name_white_list 中才能开启群聊自动回复。如果想对所有群聊生效,可以直接填写 "group_name_white_list": ["ALL_GROUP"]
默认只要被人 @ 就会触发机器人自动回复;另外群聊天中只要检测到以 "@bot" 开头的内容,同样会自动回复(方便自己触发),这对应配置项 group_chat_prefix
可选配置: group_name_keyword_white_list配置项支持模糊匹配群名称,group_chat_keyword配置项则支持模糊匹配群消息内容,用法与上述两个配置项相同。(Contributed by evolay)
group_chat_in_one_session:使群聊共享一个会话上下文,配置 ["ALL_GROUP"] 则作用于所有群聊
3.语音识别
添加 "speech_recognition": true 将开启语音识别,默认使用openai的whisper模型识别为文字,同时以文字回复,该参数仅支持私聊 (注意由于语音消息无法匹配前缀,一旦开启将对所有语音自动回复,支持语音触发画图);
添加 "group_speech_recognition": true 将开启群组语音识别,默认使用openai的whisper模型识别为文字,同时以文字回复,参数仅支持群聊 (会匹配group_chat_prefix和group_chat_keyword, 支持语音触发画图);
添加 "voice_reply_voice": true 将开启语音回复语音(同时作用于私聊和群聊),但是需要配置对应语音合成平台的key,由于itchat协议的限制,只能发送语音mp3文件,若使用wechaty则回复的是微信语音。
4.其他配置
model: 模型名称,目前支持 gpt-3.5-turbo, text-davinci-003, gpt-4, gpt-4-32k (其中gpt-4 api暂未完全开放,申请通过后可使用)
temperature,frequency_penalty,presence_penalty: Chat API接口参数,详情参考OpenAI官方文档。
proxy:由于目前 openai 接口国内无法访问,需配置代理客户端的地址,详情参考 #351
对于图像生成,在满足个人或群组触发条件外,还需要额外的关键词前缀来触发,对应配置 image_create_prefix
关于OpenAI对话及图片接口的参数配置(内容自由度、回复字数限制、图片大小等),可以参考 对话接口 和 图像接口 文档,在config.py中检查哪些参数在本项目中是可配置的。
conversation_max_tokens:表示能够记忆的上下文最大字数(一问一答为一组对话,如果累积的对话字数超出限制,就会优先移除最早的一组对话)
rate_limit_chatgpt,rate_limit_dalle:每分钟最高问答速率、画图速率,超速后排队按序处理。
clear_memory_commands: 对话内指令,主动清空前文记忆,字符串数组可自定义指令别名。
hot_reload: 程序退出后,暂存微信扫码状态,默认关闭。
character_desc 配置中保存着你对机器人说的一段话,他会记住这段话并作为他的设定,你可以为他定制任何人格 (关于会话上下文的更多内容参考该 issue)
subscribe_msg:订阅消息,公众号和企业微信channel中请填写,当被订阅时会自动回复, 可使用特殊占位符。目前支持的占位符有{trigger_prefix},在程序中它会自动替换成bot的触发词。
注意
全量配置可在 config.py 中查看,但该文件仅做配置的说明,直接修改是无效的,config.json 文件才是最终生效的配置文件。
如果启动程序失败并报错 JSONDecodeError,就是 config.json 中配置文件的json格式错误,报错中一般会提示哪一行出现问题。也可以去 在线JSON校验 网站进行验证,同时需要注意 openai_key 的安全。
4.运行
一切准备就绪,可以启动程序了,直接在项目目录使用cmd下执行:
python3 app.py

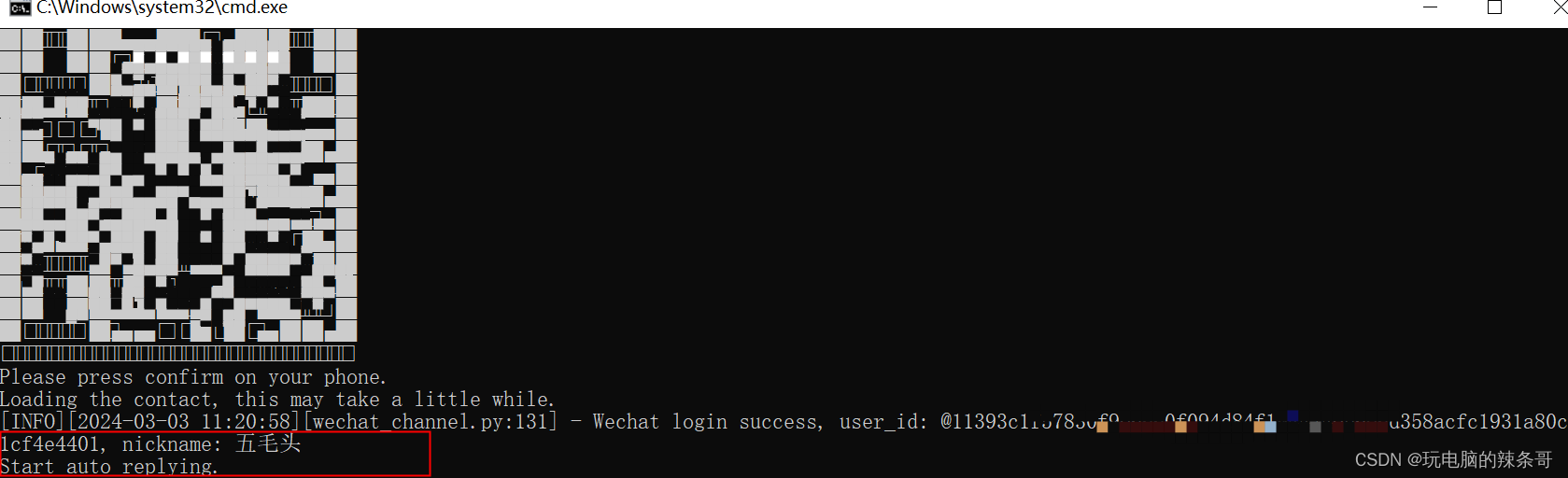
扫描输出的二维码即可完成登录。如果你使用的是 pycharm 等IDE,就更方便了,点击运行按钮就可以直接运行。
 成功运行之后日志中会输出 “Start auto replying”,这表示你用于扫码登录的账号已经变身为机器人了
成功运行之后日志中会输出 “Start auto replying”,这表示你用于扫码登录的账号已经变身为机器人了
二、部署本地RWKV-Runner CPU尝鲜版
1.下载RWKV-Runner.exe程序
 2.主页面
2.主页面
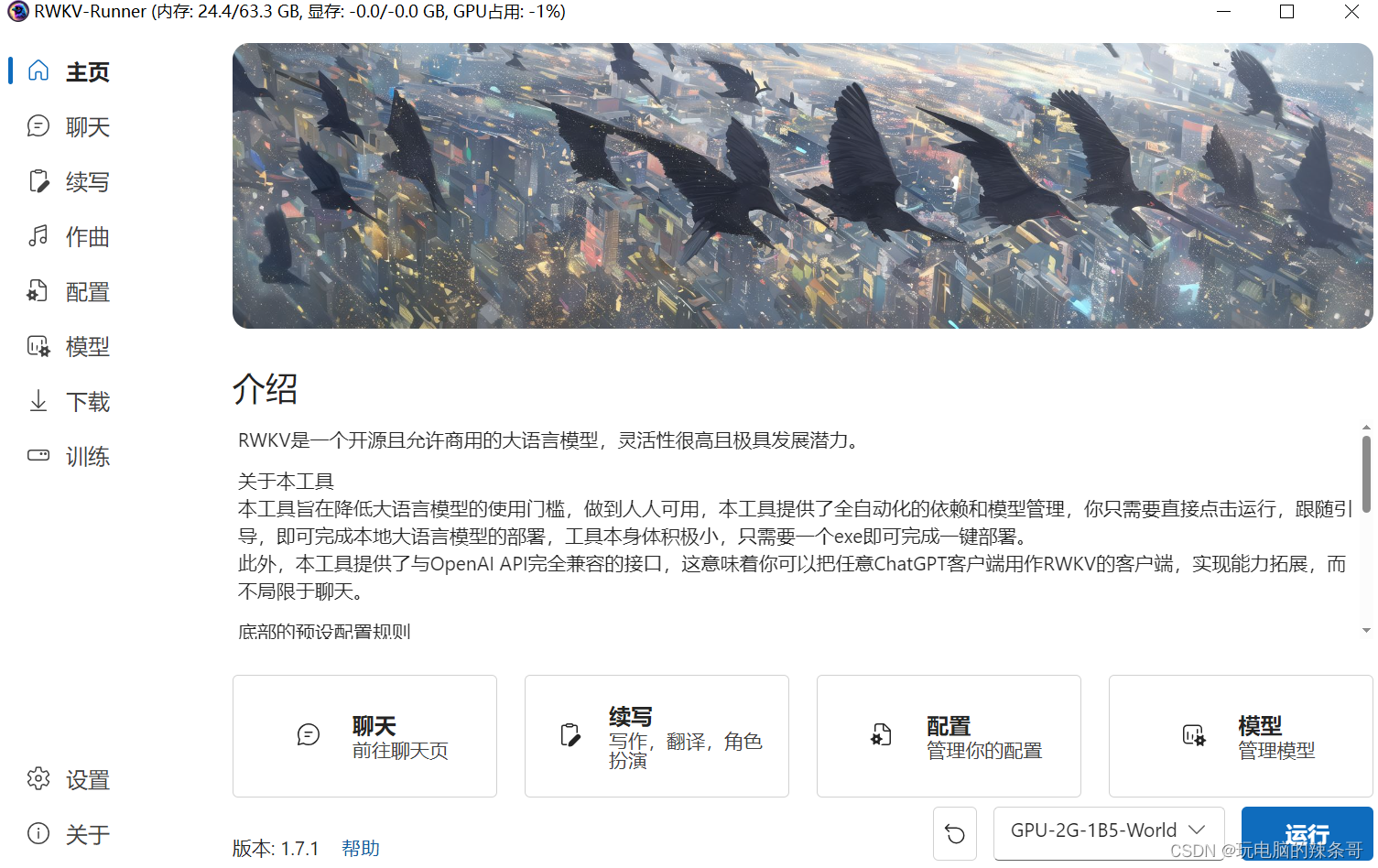
3.下载对应模型,在线下载很慢,可能需要科学
 4.如网盘下载模型放如models文件夹内,我下了1B5这个
4.如网盘下载模型放如models文件夹内,我下了1B5这个

5.开始也可以直接点主页右下角运行,然后按提示操作,会自动下载对应所缺的东西(python等等一些东西)
 6.cpu运行会提示改配置里这
6.cpu运行会提示改配置里这
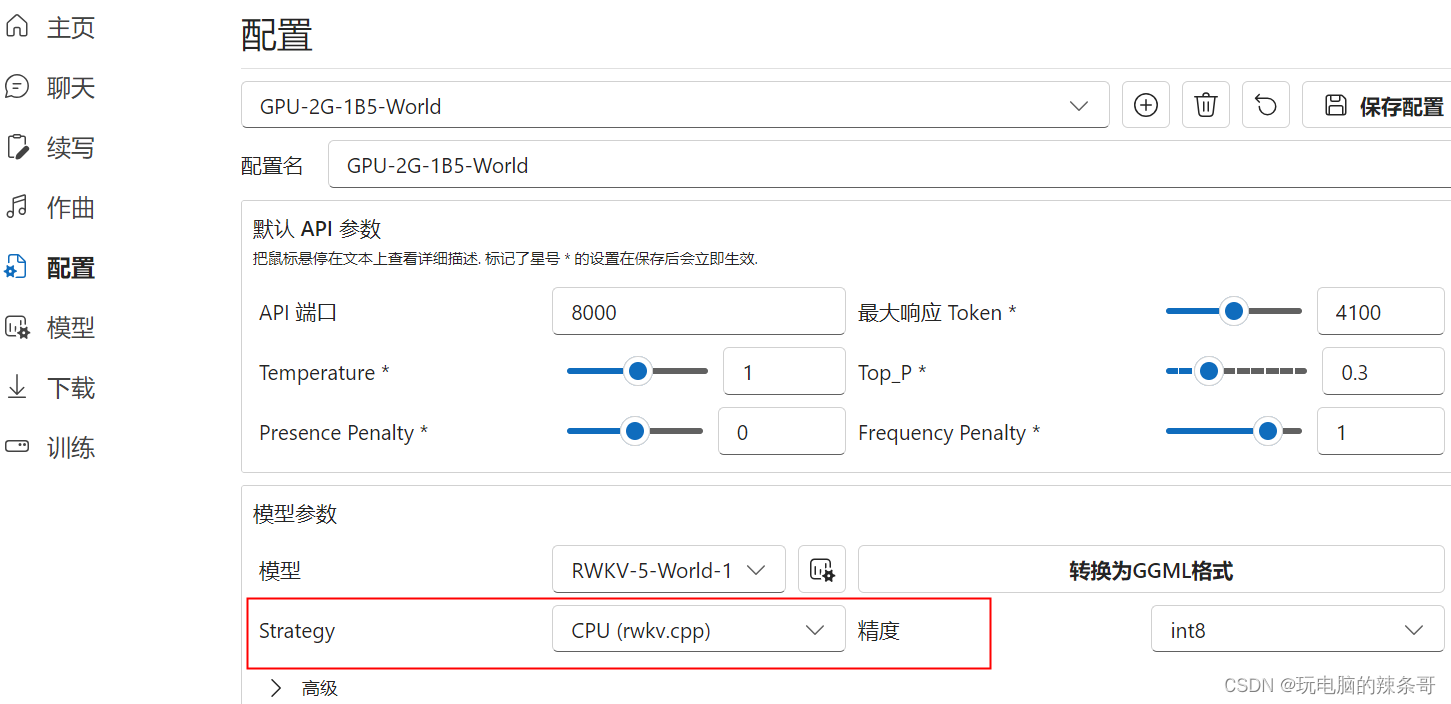
7.最后点运行

运行成功

测试对话
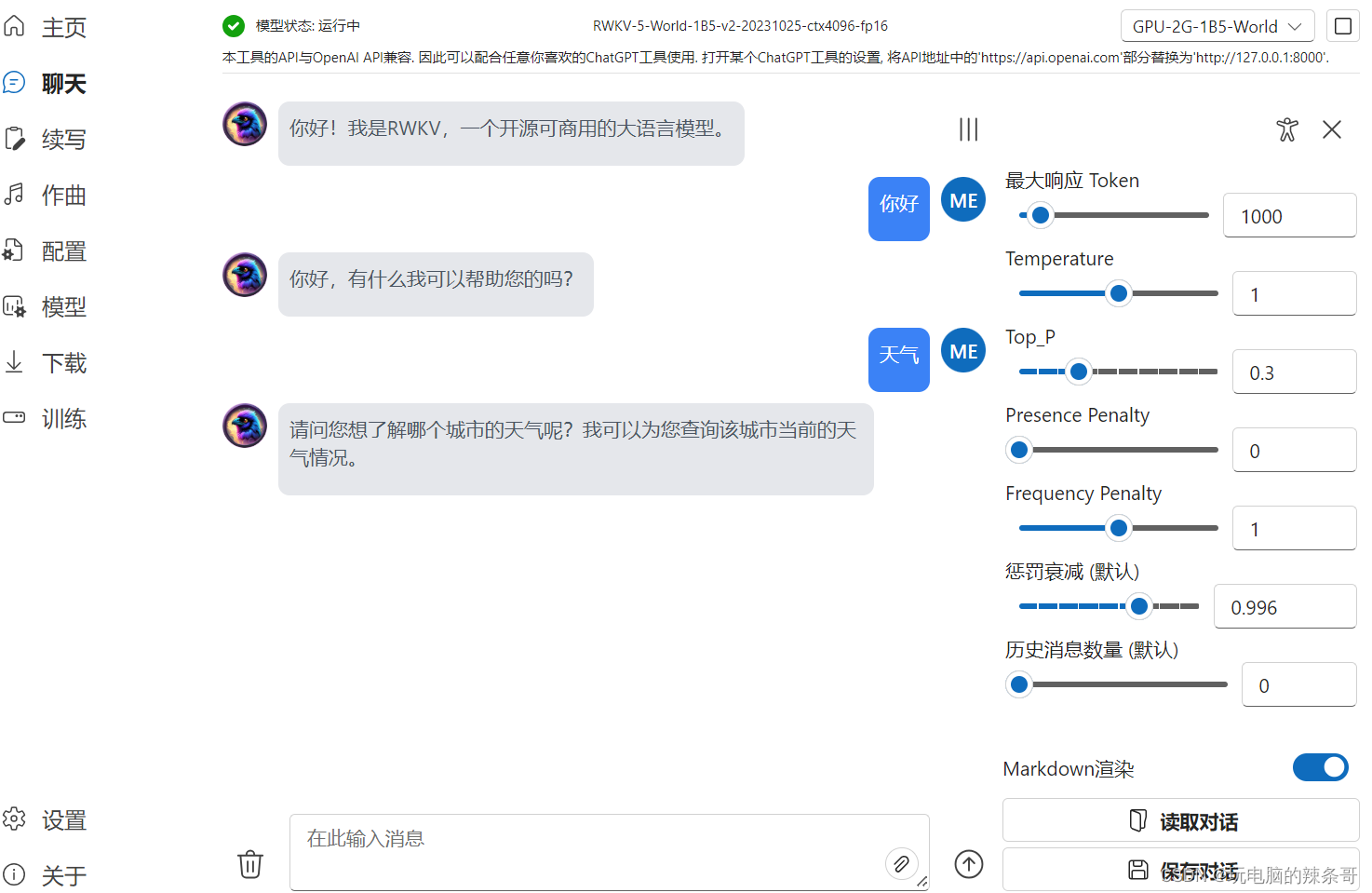
8.定义一下key
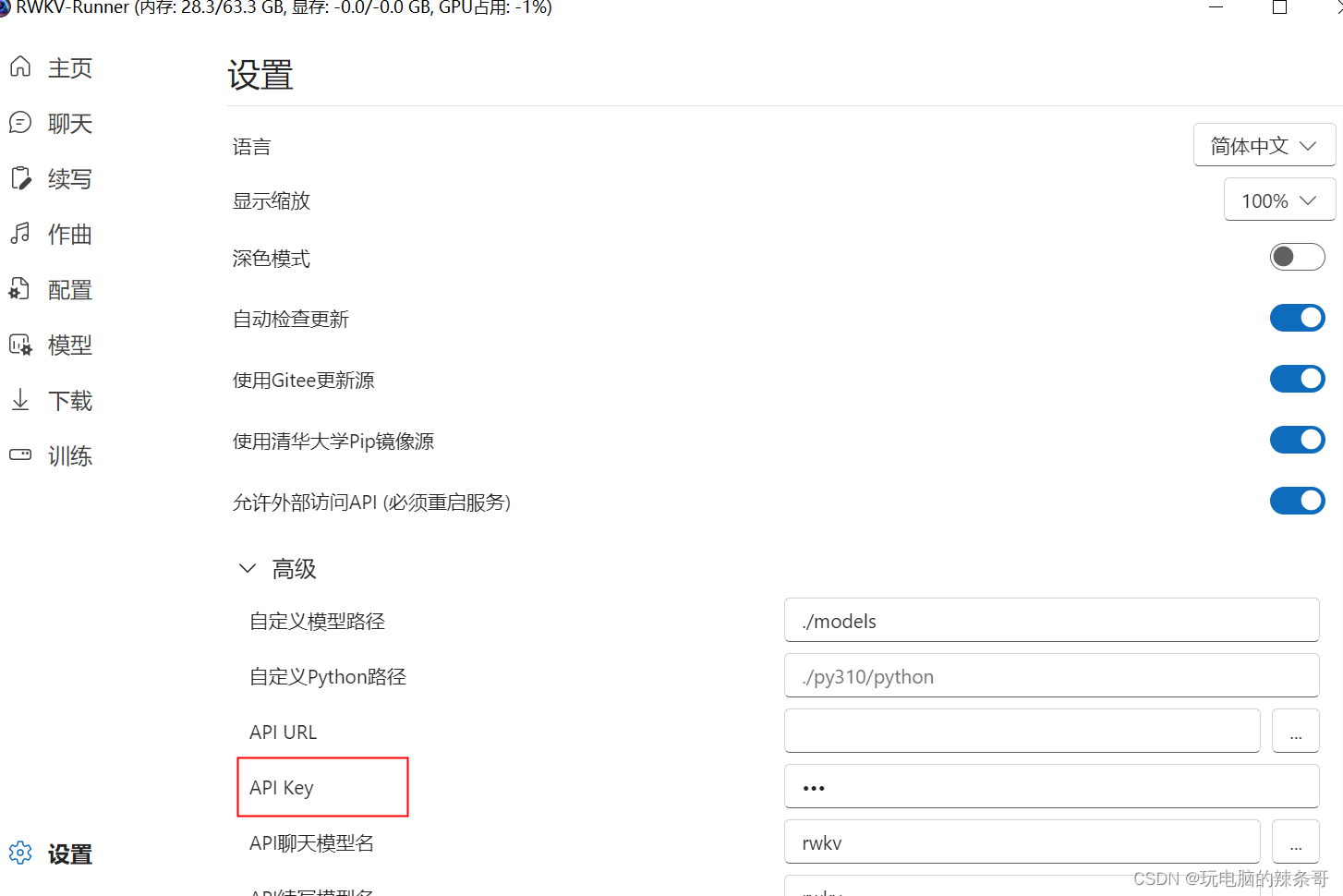 9.测试本地api服务是否正常
9.测试本地api服务是否正常
浏览器输入本地API
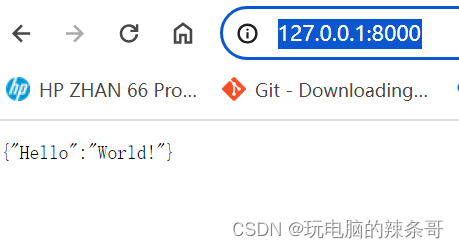
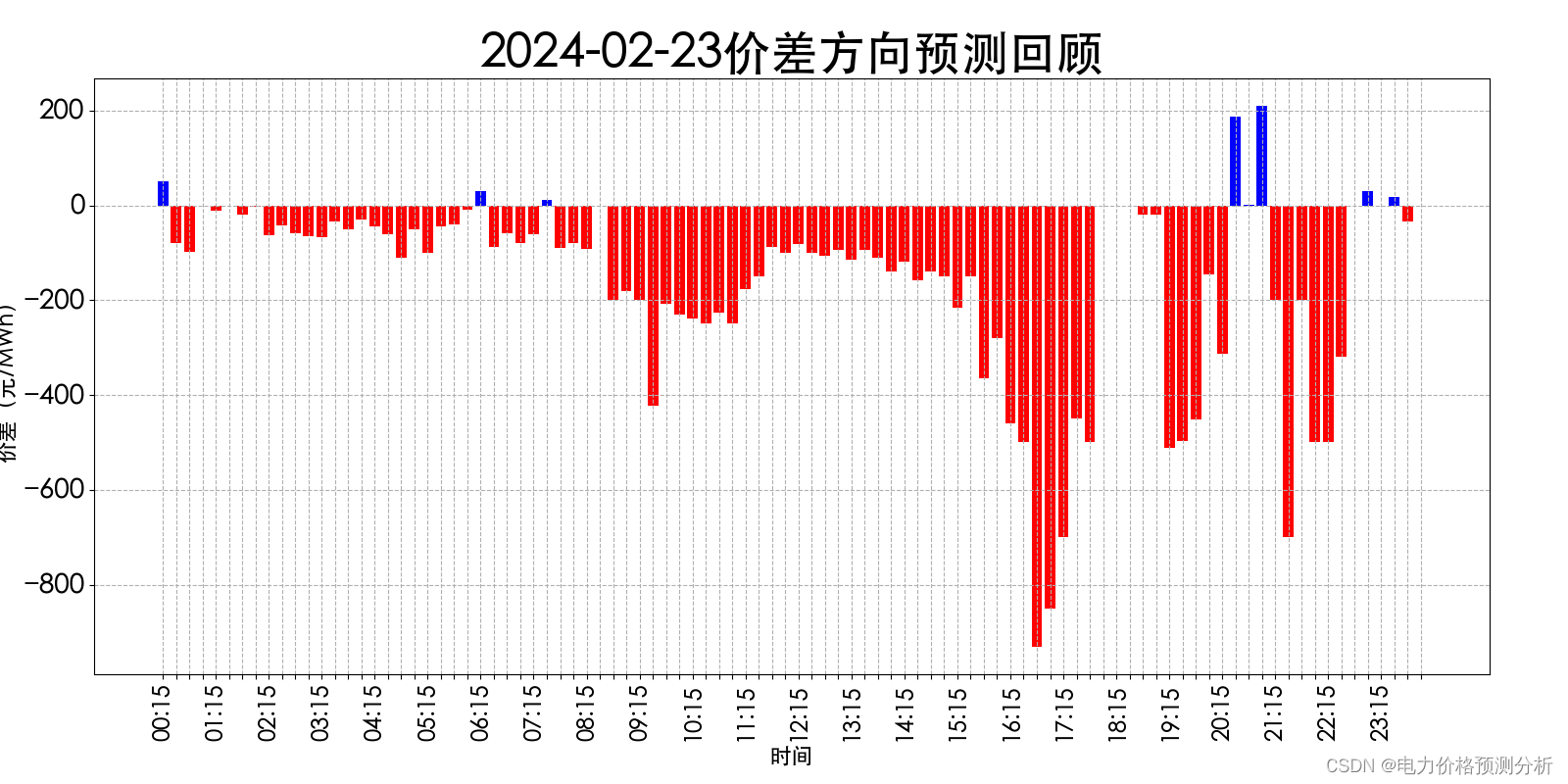
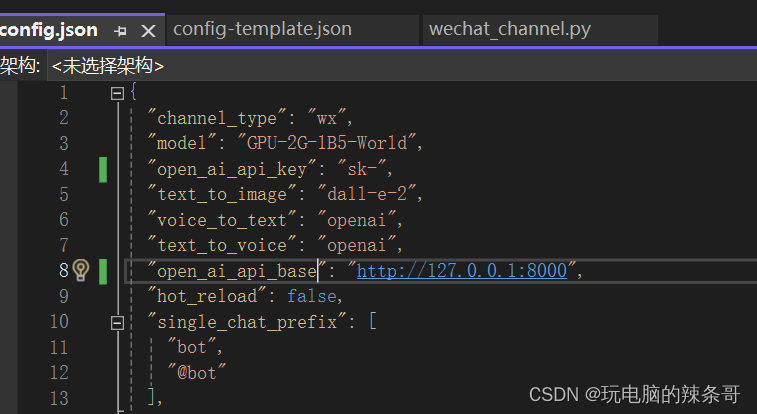
三、chatgpt-on-wechat 与RWKV-Runner结合
更改chatgpt-on-wechat配置文件,参数如下,api填本地RWKV-Runner,报错重启项目
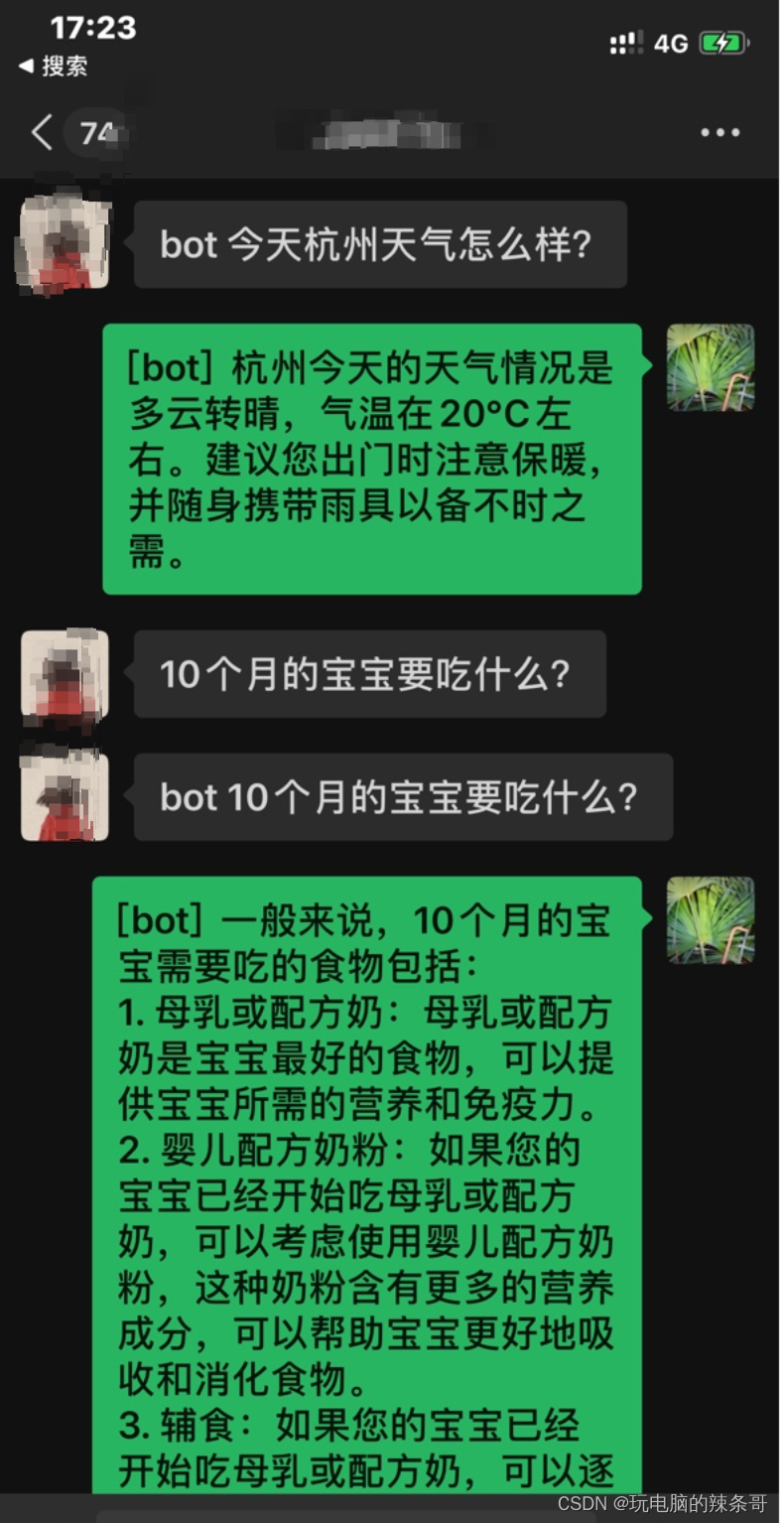
四、测试使用
让你的好友给你发消息 或在群聊@你 都会触发自动回复,效果如下图:


![【洛谷 P8682】[蓝桥杯 2019 省 B] 等差数列 题解(数学+排序+辗转相除法)](https://img-blog.csdnimg.cn/direct/1e7d14a3279041388777583541e4c7fe.png)