前言
前面写的TCP/UDP客户端在访问服务端的时候,需要输入ip地址和端口号才可以访问, 但在现实中,我们访问一个网站是直接输入的一个域名,而不是使用的ip地址+端口号。
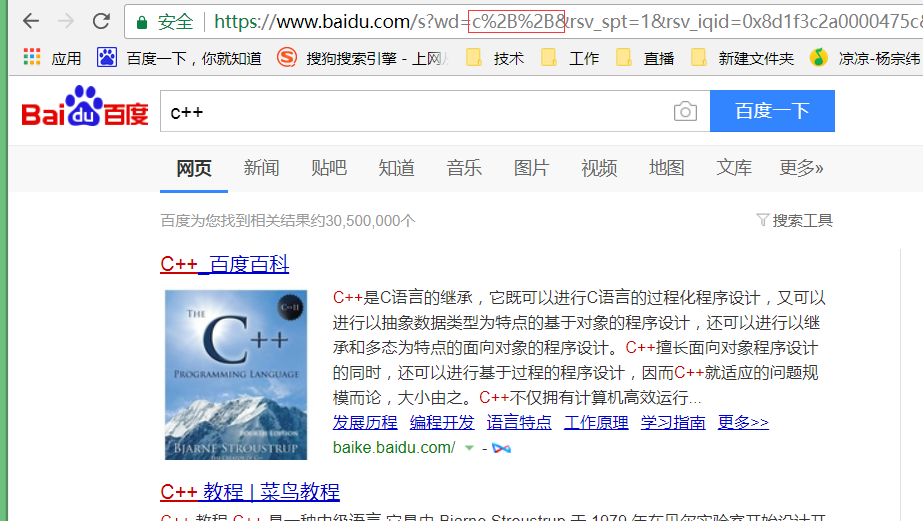
比如在访问百度 https://www.baidu.com/的时候, 是使用的域名,浏览器会把域名进行解析成为ip地址+端口号。
我们ping一下百度的域名,会得到来自百度的一个回复,然后我们可以访问这个ip地址就会得到百度的主页面。


上面在进行网络请求的时候,并没有输入端口号,在输入ip地址之后,直接进入到了百度的主页面。
![]()
把这里复制粘贴。百度一下,你就知道 其实是有一个http前缀的,我们访问其他网页,也会有http或者https前缀的。输入网址就算不输入http或https,浏览器会把这两个协议进行默认拼接。一般像这种知名的服务器会把端口号给固定下来。这种端口号是不能随意修改的。所以我们在访问百度的时候,把ip地址输入进去,可以直接访问到百度的主页面,其实就是访问的39.156.66.14:80。
认识URL
我们看到了好的文章,然后把链接(https://blog.csdn.net/weixin_73888239/category_12238116.html )复制下来分享给朋友,像这种链接就叫做URL 统一资源定位符。在全网当中,只要有这个URL,就可以访问这个网页。每一个字符串在全网当中,都是唯一的。在网络上我们所看到的一些图片,音乐,视频,直播等资源都可以用唯一的一个字符串标识,并且可以获取到,只要知道url就可以访问这些资源。
url的格式一般为下图所示

urlencode和urldecode
urlencode和urldecode是用于处理URL编码和解码的两个相关的操作,通常用于将特殊字符转换为URL安全的形式,以及将已编码的URL转换回原始形式。
urlencode 用于将字符串转换为url安全的格式,将特殊字符转换为其对应的百分比编码形式。
urldecode 用于解码已经被url编码的字符串,将百分比编码形式还原为原始字符
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
"+" 被转义成了 "%2B",urldecode就是urlencode的逆过程;
HTTP协议格式
我们平时上网的行为其实就两种
- 从服务器端拿下来资源数据 --- get方法 (可以通过 表单 的方法展示出来)表单收集用户数据(表单是要被提交的),并把用户数据推送给服务器(表单中的数据,会被转成http request的一部分)
- 把客户端的数据提交到服务器 --- post方法get方法都可以
get方法传参通过url传参,会回显输入的私密信息,不够私密
post方法通过正文提交传参,不会回显的输出信息.一般私密性是有保证的
这里的私密性不是安全性,数据只有经过加密和解密才会安全。
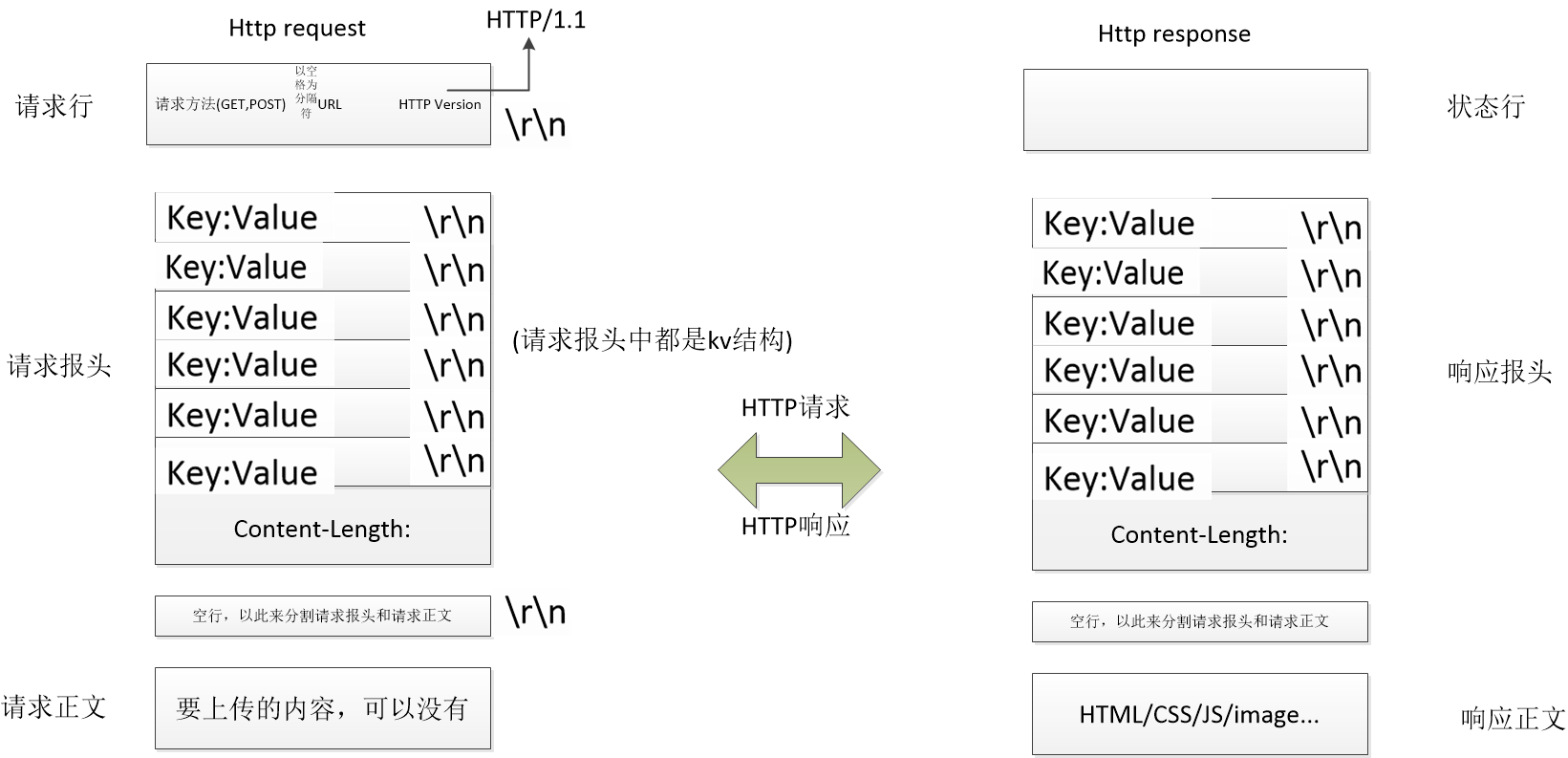
http request中,是有一个请求行,请求报头,请求正文组成,在请求行中,有请求方法(GET,POST),URL,HTTP Version组成,这三个之间以空格作为分隔符。中间部分是请求报头,都是以KV的形式存在,最后是请求正文,在请求正文和请求报头之间,存在一个空行,这是为了区分请求报头和请求正文而存在的。在读取http request的时候,按照行读取,这样就可以将报文和有效载荷成功的分离,不会读到不属于自己的数据。
在HTTP请求的时候,会先将我们所输入的域名进行解析,然后去访问该内容,客户端在与服务端建立TCP连接,通过三次握手确保双方可以进行可靠的通信。然后构建HTTP请求消息。客户端构建一个HTTP请求消息,其中包括请求行,请求报头,空行,请求正文。请求消息发送到服务器,服务器会进行处理并构建响应消息(状态行,响应报头,响应正文),然后将响应消息发送给客户端,并关闭连接。
可以使用telnet工具来完成一次http的请求和响应。
首行: [方法] + [url] + [版本]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个
Content-Length属性来标识Body的长度;
telnet www.baidu.com 80
在按ctrl + ]
回车
// http请求
GET / HTTP/1.1 // 请求行
// http响应
HTTP/1.1 200 OK // 响应状态行中存在 http的版本,状态码,状态码描述,跟请求一样,都是以空格作为分隔符
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 9508
Content-Type: text/html
Date: Thu, 29 Feb 2024 07:49:00 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Pragma: no-cache
Server: BWS/1.1
Set-Cookie: BAIDUID=BDADB3AA66EC6897715119E26C4CF88A:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=BDADB3AA66EC6897715119E26C4CF88A; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1709192940; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=BDADB3AA66EC689787381350CD38E8C2:FG=1; max-age=31536000; expires=Fri, 28-Feb-25 07:49:00 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Traceid: 1709192940051597876211264035507514709484
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
X-Xss-Protection: 1;mode=block
HTML/CSS/JS 页面。首行: [版本号] + [状态码] + [状态码解释]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个
Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
telnet是自己构建的请求。可以用费德勒这个软件进行抓包。
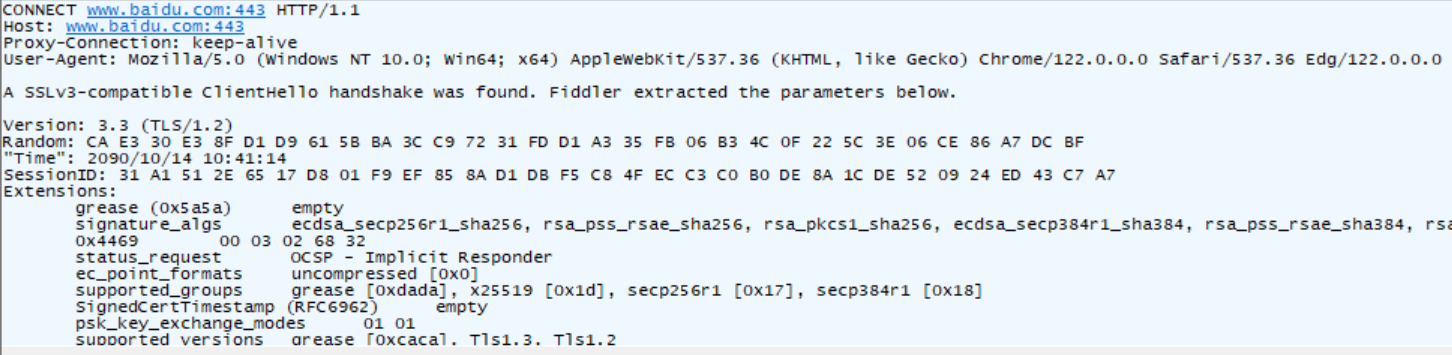
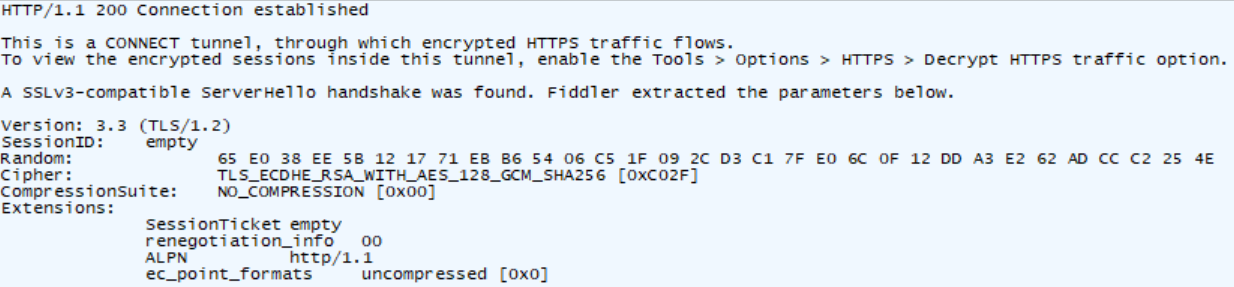
HttpDone
其实我们也可以自己写一个简单的http。
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <unistd.h>
#include "log1.hpp"
#include "Socket.hpp"
extern Log lg;
class HttpServer;
class ThreadData {
public:
ThreadData(int sockfd):_sockfd(sockfd)
{}
~ThreadData()
{}
public:
public:
HttpServer *serv;
int _sockfd;
}; // 存储线程数据
const std::string defaultip = "0.0.0.0";
class HttpServer {
public:
HttpServer(uint16_t port):_port(port),_ip(defaultip)
{}
~HttpServer()
{}
public:
void Init()
{
_listensock = sock.Socket();
lg(Info, "socket success");
sock.Bind(_listensock, _port);
lg(Info, "Bind success");
sock.Listen(_listensock);
lg(Info, "Listen success");
}
static void *ThreadRun(void *args)
{
pthread_detach(pthread_self());
ThreadData* td = static_cast<ThreadData*>(args);
char buf[1024];
while (true)
{
ssize_t n = read(td->_sockfd, buf, sizeof(buf) - 1);
if (n > 0)
{
buf[n] = 0;
std::cout << buf << std::endl;
}
}
}
bool Start()
{
while (true)
{
std::string clientip;
uint16_t clientport;
int sockfd = sock.Accept(_listensock, clientip, clientport);
lg(Info, "accept success");
ThreadData *td = new ThreadData(sockfd);
pthread_t tid;
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
private:
int _listensock;
uint16_t _port;
std::string _ip;
Sock sock;
};#include "HttpServer.hpp"
#include <memory>
int main(int argc, char *argv[])
{
if (argc != 2)
{
exit(1);
}
uint16_t port = std::stoi(argv[1]);
std::unique_ptr<HttpServer> serv(new HttpServer(port));
serv->Init();
serv->Start();
return 0;
}#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include "log1.hpp"
Log lg;
const int backlog = 10;
enum
{
SocketErr = 2,
BindErr,
ListenErr,
};
class Sock
{
public:
Sock()
{}
~Sock()
{}
int Socket()
{
_listensocket = socket(AF_INET, SOCK_STREAM, 0);
if (_listensocket < 0)
{
lg(Fatal, "socker error, %s: %d", strerror(errno), errno);
exit(SocketErr);
}
}
void Bind(int listensock, uint16_t port)
{
struct sockaddr_in serv;
bzero(&serv, sizeof(serv));
serv.sin_family = AF_INET;
serv.sin_port = htons(port);
serv.sin_addr.s_addr = INADDR_ANY;
if (bind(listensock, (const sockaddr*)&serv, sizeof(serv)) < 0)
{
lg(Fatal, "bind error, %s: %d", strerror(errno), errno);
exit(BindErr);
}
}
void Listen(int listensock)
{
if (listen(listensock, backlog) < 0)
{
lg(Fatal, "listen error, %s: %d", strerror(errno), errno);
exit(ListenErr);
}
}
int Accept(int listensock, std::string& ip, uint16_t& port)
{
struct sockaddr_in serv;
bzero(&serv, sizeof(serv));
socklen_t len = sizeof(serv);
int sockfd = accept(listensock, (struct sockaddr*)&serv, &len);
if (sockfd < 0)
{
lg(Warning, "accept error, %s: %d", strerror(errno), errno);
return -1;
}
char ipstr[64];
inet_ntop(AF_INET, &serv.sin_addr.s_addr, ipstr, sizeof(ipstr));
ip = ipstr;
port = ntohs(serv.sin_port);
return sockfd;
}
bool Connect(int listensock, const std::string &ip, const uint16_t& port)
{
struct sockaddr_in serv;
bzero(&serv, sizeof(serv));
serv.sin_family = AF_INET;
serv.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &serv.sin_addr.s_addr);
int n = connect(listensock, (const struct sockaddr*)&serv, sizeof(serv));
if (n < 0)
{
std::cerr << "connect to " << ip << ":" << port << " error" << std::endl;
return false;
}
return true;
}
void Close(int listensock)
{
close(listensock);
}
int Fd()
{
return _listensocket;
}
private:
int _listensocket;
};在运行之后,让PC端和手机端分别访问该服务端。
[Info][2024-3-1 14:2:55] socket success
[Info][2024-3-1 14:2:55] Bind success
[Info][2024-3-1 14:2:55] Listen success
[Info][2024-3-1 14:3:11] accept success
[Info][2024-3-1 14:3:11] accept success
GET / HTTP/1.1
Host: 1.117.232.232:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
[Info][2024-3-1 14:3:41] accept success
[Info][2024-3-1 14:3:41] accept success
GET / HTTP/1.1
Host: 1.117.232.232:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; U; Android 14; zh-CN; 23127PN0CC Build/UKQ1.230804.001) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/100.0.4896.58 Quark/6.9.6.501 Mobile Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7可以看到请求报头中都是kv结构的数据。其中有一个User-Agent,他代表的是浏览器的版本和用户的操作系统。
还有其他的一些数据。
在浏览器上下载软件的时候,可以直接下载PC版的安装包,用手机浏览器下载软件会直接下载手机版的安装包,这就是通过User-Agent来判断用户是用的手机端还是PC端,判断之后再给用户推送合适的内容。
其实我们可以自己构建一个http响应,当客户端连接服务端的时候,服务端会给客户端一个响应。
先写一个简单的网页当作响应正文
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>LOG IN</h1>
</body>
</html>在写一个响应状态行和响应报头,将状态行,响应报头和响应正文进行拼接。发送给浏览器,就可以得到数据了。
static std::string ReadHtmlContent(const std::string &htmlpath)
{
std::ifstream in(htmlpath);
if (!in.is_open())
{
return "404";
}
std::string line;
std::string content;
while (std::getline(in, line))
{
content += line;
}
return content;
}
static void HandlerHttp(int sockfd)
{
char buf[10240];
ssize_t n = recv(sockfd, buf, sizeof(buf) - 1, 0);
if (n > 0)
{
buf[n] = 0;
std::cout << buf;
// 构建服务端响应消息
std::string text = ReadHtmlContent("wwwroot/index.html"); // 响应正文
std::string response_line = "HTTP/1.1 200 OK\r\n"; // 响应状态行
std::string response_header = "Content-Length: "; // 响应报头
response_header += std::to_string(text.size()); // 响应报头
response_header += "\r\n";
std::string blank_line = "\r\n"; // 空行,来分割响应正文和响应报头
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
ssize_t m = send(sockfd, response.c_str(), response.size(), 0);
if (m < 0)
{
lg(Debug, "send error");
}
// Close the socket after sending the response
close(sockfd);
}
else if (n == 0)
{
// Connection closed by the client
close(sockfd);
}
else
{
// Handle the receive error
lg(Debug, "recv error");
close(sockfd);
}
}
运行之后就会出现刚才写的页面,也可以在页面中添加a标签,进行链接跳转。
http的方法
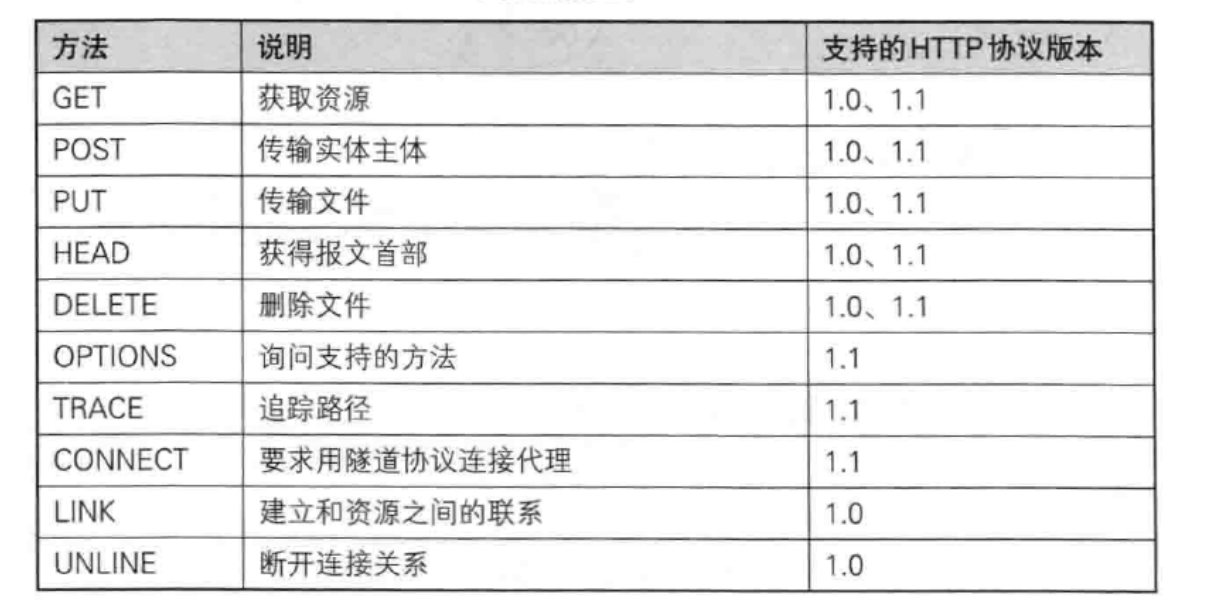
上面的请求都是get方法,我们最常用的是get和post方法。其他的方法了解一下即可。
如何把数据提交给服务器呢?我们登录账号的时候,会有一个登录页面,这个登录页面其实就是一个表单,通过表单将数据提交给服务器。
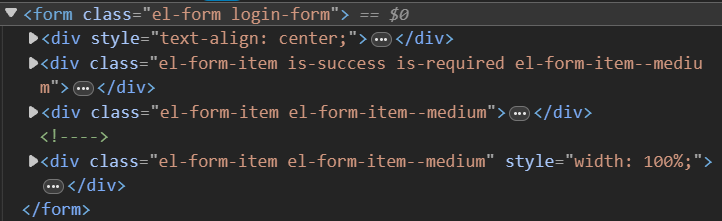
这是随便找的一个登录页面的页面代码。如果上面写的http需要数据,也可以写一个表单页面,然后将数据提交给服务器。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>LOG IN</h1>
<form action="" method="get">
name: <input type="text" name="name" value=""><br>
password: <input type="password" name="name" value=""><br>
<input type="submit" value="提交">
</form>
</body>
</html>
表单很丑陋,哈哈,这不是我们该考虑的问题。
在我们输入name和pwd之后,看浏览器中的url,
![]()
使用get方法将参数交给服务器,是通过url提交的,将参数拼接到了url的后面,来完成请求。
![]()
我们的服务端也会收到这个url。
将form中的method换成post方法之后,在将表单提交。,url中不会出现输入的name和pwd。
![]()

在写的服务端中查看浏览器的请求,可以看到使用的是post方法和数据。
可能会有人说,get方法会把数据显示到url上,不安全;post不会显示,相对安全。其实不是这样,数据只有在经过加密之后,才会变得安全。get方法只能说是不够私密,post方法私密一些。
http的状态码
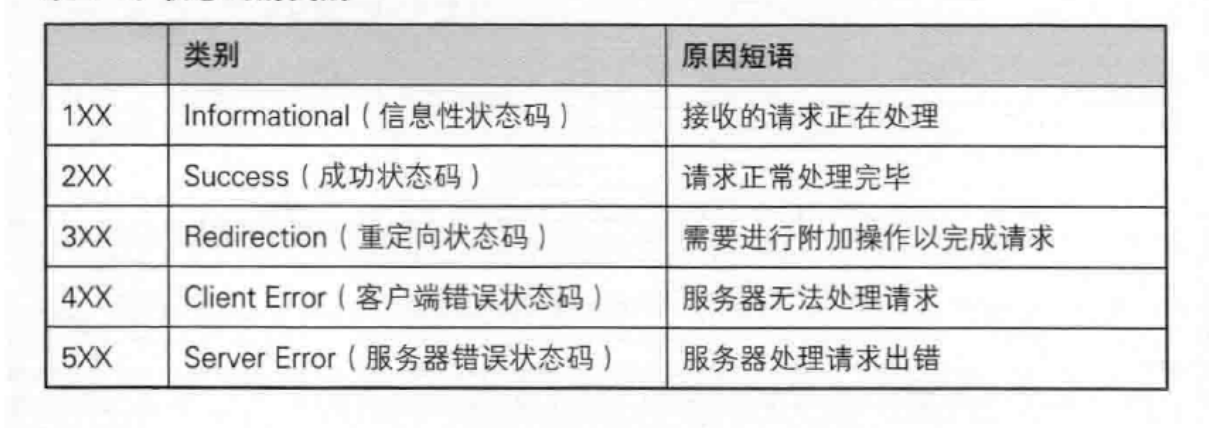
前面写的简易http代码中,浏览器发送请求后,服务端会进行响应,响应中的状态码写的是200,代表服务端响应成功。
我们在访问京东的时候,将url写为 www.jd.com/a/b/c就会出现找不到的情况。这就是404(Not Found)。

最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
重定向
浏览器向服务端发送一个请求,服务端对浏览器做出响应,但是浏览器中输入的url是不应该在被使用的url,应该使用新的地址向服务端发送请求。所以在使用老地址发送请求的时候,服务端做出的响应报头中,会存在一个location: 新地址 的kv结构,然后浏览器使用这个新地址,在对服务端发送请求。
重定向就是服务器指导浏览器访问新地址。
std::string response_line = "HTTP/1.1 302 Found\r\n"; // 响应状态行
std::string response_header = "Content-Length: "; // 响应报头
response_header += std::to_string(text.size()); // 响应报头
response_header += "\r\n";
response_header += "Location: https://www.jd.com\r\n";
std::string blank_line = "\r\n"; // 空行,来分割响应正文和响应报头
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
ssize_t m = send(sockfd, response.c_str(), response.size(), 0);
if (m < 0)
{
lg(Debug, "send error");
}
close(sockfd);
将响应状态行进行修改,将响应报头中添加上location:地址 字段,就可以完成重定向了。在访问服务端,就会跳转到jd的页面了。
![]()
临时重定向(Temporary Redirect):
- 使用状态码 302 Found 或 307 Temporary Redirect 表示。
- 表示请求的资源暂时被移动到了其他位置。
- 客户端在接收到这样的状态码时,应该继续使用原始的 URL 进行请求。
- 临时重定向是暂时性的,客户端以后可能会继续使用原始 URL,因为重定向只是暂时的。
永久重定向 (Permanent Redirect):
- 使用状态码 301 Moved Permanently 或 308 Permanent Redirect 表示。
- 表示请求的资源已经永久地移到了其他位置。
- 客户端在接收到这样的状态码时,应该更新其链接并使用新的 URL 进行以后的请求。
- 永久重定向是持久性的,客户端应该更新其链接,以便将来的请求直接发送到新的 URL 上。
http常见的header
- Content-Type: 数据类型(text/html等)
<img src="C:\Users\Lenovo\Pictures\1708049137066.jpg" alt="src error">

在运行之后,图片加载不出来,浏览器没有解释出来,这是因为格式的 问题,要在响应报头上添加上Content-Type:数据类型 这个kv结构。因为我们写的http有点简陋,仅仅添加上这个报头也不能响应,浏览器先发送请求请求的是html的页面,然后再次请求,请求的才是图片,如果把Content-Type改成图片就不能显示页面了,图片也显示不出来,所以可以添加上一个函数,用来判断请求的是什么类型。
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能
- connection:keep-alive---长连接
一次连接可以被多个请求-响应复用, 在HTTP/1.1中,默认情况下是启用了长连接的。
9. connection:close---短连接
每个请求-响应都需要建立一个新的连接,通常用于HTTP/1.0中每个连接只处理一个请求,处理完毕后即关闭连接,不保持持续的连接状态。
会话Cookie
在浏览器上登录b站,关掉浏览器,再次打开浏览器看b站,是不需要在进行登录。
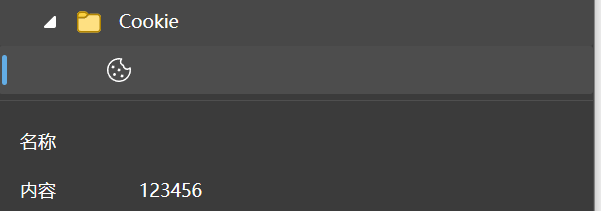
这是服务器发送到用户浏览器并保存在本地的一小块数据。浏览器会存储cookie并在下次向同意服务器再发起请求时,携带并发送到服务器上的。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登陆状态。Cookie使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
将http请求中添加上了set-cookie结构,就会产出cookie文件,里面保存的就是账号密码,这也就是为什么我们登录网站的时候,一段时间内再次访问同样网站的时候,浏览器和服务器相互配合,服务器自动的去认证cookie,就不需要重复登录了。
static void HandlerHttp(int sockfd)
{
char buf[10240];
ssize_t n = recv(sockfd, buf, sizeof(buf) - 1, 0);
if (n > 0)
{
buf[n] = 0;
std::cout << buf;
// 构建服务端响应消息
std::string text = ReadHtmlContent("wwwroot/index.html"); // 响应正文
std::string response_line = "HTTP/1.0 200 OK\r\n"; // 响应状态行
// std::string response_line = "HTTP/1.1 302 Found\r\n"; // 响应状态行
std::string response_header = "Content-Length: "; // 响应报头
response_header += std::to_string(text.size()); // 响应报头
response_header += "\r\n";
response_header += "Set-Cookie: ";
response_header += "123456";
response_header += "\r\n";
// response_header += "Location: https://www.jd.com\r\n";
std::string blank_line = "\r\n"; // 空行,来分割响应正文和响应报头
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
ssize_t m = send(sockfd, response.c_str(), response.size(), 0);
if (m < 0)
{
lg(Debug, "send error");
}
// Close the socket after sending the response
close(sockfd);
}
else if (n == 0)
{
// Connection closed by the client
close(sockfd);
}
else
{
// Handle the receive error
lg(Debug, "recv error");
close(sockfd);
}
}
cookie固然方便,但也有一些问题
- cookie被盗取的问题
- 个人信息泄露的问题
当浏览器发起请求的时候,会把cookie发送过去,然后服务端进行认证,认证成功之和,服务端会为我们创建一个session文件,这个文件里会记录下来用户登录相关的内容,形成session文件,还会生成一个全服务器内唯一的一个session ID,这个ID是一种序列号,以session ID为session文件进行命名,将session ID返回给用户,用户的Cookie中存储的就是这个session ID,往后,浏览器再次发送请求,Cookie中存的就是session ID,服务端进行查找就行了。假如说我访问的是B站,B站的用户非常多,服务端如何管理这个session ID呢? 先描述,在组织,session文件中有用户自己的属性,还有sessionID,所以只要以某种数据结构的形式把这些文件或ID连接起来,就能以增删查改的形式进行管理了。
如果黑客把用户发送的请求给截取了,那么黑客就会拿到Cookie了,黑客就可以通过Cookie访问用户的账号了,但是Cookie中存储的是session ID,个人信息是不会泄露的。各大网站都有技术人员,这种情况肯定会有解决方法。
https
HTTPS也是⼀个应⽤层协议.是在HTTP协议的基础上引⼊了⼀个加密层.HTTP协议内容都是按照⽂本的⽅式明⽂传输的.这就导致在传输过程中出现⼀些被篡改的情况.
http是以明文的形式传输,不加密,不提供对数据完整性的保障,容易受到中间人攻击。HTTPS是在HTTP的基础上添加了安全曾(SSL),用于对数据加密解密。通过SSL协议,确保数据在传输过程中不被窃取或篡改。应用层中http经过SSL加密解密后,到传输层,传输层并不知道该数据是经过加密的,只有应用层才会知道。
加密解密
加密就是把明⽂(要传输的信息)进⾏⼀系列变换,⽣成密⽂解密就是把密⽂再进⾏⼀系列变换,还原成明⽂在这个加密和解密的过程中,往往需要⼀个或者多个中间的数据,辅助进⾏这个过程,这样的数据称为密钥。假如7 ^ 5 = 010, 这个7就是名文,这个 010就是密文,中间的这个5就是密钥。5 ^ 010 = 7,这样就可以得到明文。
加密解密到如今已经发展成⼀个独⽴的学科:密码学.⽽密码学的奠基⼈,也正是计算机科学的祖师爷之⼀艾伦·⻨席森·图灵

因为http的内容是明⽂传输的,明⽂数据会经过路由器、wifi热点、通信服务运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双⽅察觉,这就是中间⼈攻击 ,所以我们才需要对信息进⾏加密.不⽌运营商可以劫持,其他的⿊客也可以⽤类似的⼿段进⾏劫持,来窃取⽤⼾隐私信息,或者篡改内容.
在互联网中,明文传输是一件非常危险的事情,HTTPS就是在HTTP的基础上进行了加密,进一步的来保证用户的信息安全。
常见的加密方式
对称加密
采⽤单钥密码系统的加密⽅法,同⼀个密钥可以同时⽤作信息的加密和解密,这种加密⽅法称为对
称加密,也称为单密钥加密,特征:加密和解密所⽤的密钥是相同的。
常⻅对称加密算法(了解):DES、3DES、AES、TDEA、Blowfish、RC2等
特点:算法公开、计算量⼩、加密速度快、加密效率⾼
对称加密其实就是通过同⼀个"密钥",把明⽂加密成密⽂,并且也能把密⽂解密成明⽂.
非对称加密
需要两个密钥来进行加密和解密。 一个是公钥,一个是私钥。公钥和私钥是配对的,最大的缺点就是运算速度非常慢,比对称加密要慢很多。
明文 由 公钥A 加密变成密文, 密文由公钥B进行解密变成明文,也可以反着来,通过私钥对明文加密变成密文,通过公钥对密文进行解密,变成明文。
常⻅⾮对称加密算法(了解):RSA,DSA,ECDSA
特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,⽽使得加密解密速度没有对
称加密解密的速度快
数据摘要 && 数据指纹
数字指纹(数据摘要),其基本原理是利⽤单向散列函数(Hash函数)对信息进⾏运算,⽣成⼀串固定⻓度
的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被窜改。
摘要常⻅算法:有MD5、SHA1、SHA256、SHA512等,算法把⽆限的映射成有限,因此可能会有碰撞(两个不同的信息,算出的摘要相同,但是概率⾮常低)
摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推
原信息,通常⽤来进⾏数据对⽐
HTTPS加密方案
方案一 - 只使用对称加密
如果通信双⽅都各⾃持有同⼀个密钥X,且没有别⼈知道,这两⽅的通信安全当然是可以被保证的(除⾮密钥被破解)
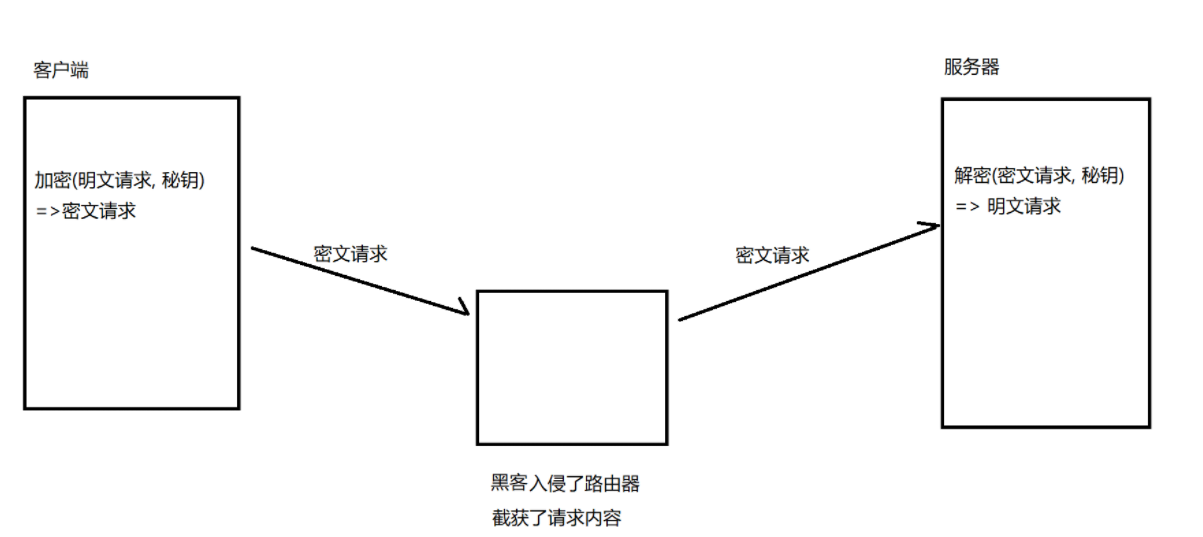
客户端向服务端发送密钥的时候,服务器能获取密钥,黑客也能获取这个密钥,那么可以让密钥进行加密,在发送给服务端,但是服务端并不知道对加密内容解密的密钥是什么,所以还是要先发送密钥,那么黑客还是可以直接获取密钥。这就导致了是先有鸡还是先有蛋的问题。
所以方案一是不可取的。
方案二 - 只使用非对称加密
非对称加密有两个密钥,一个公钥,一个私钥。客户端向服务端发送请求的时候,服务端会把公钥发送给客户端,此后客户端在向服务端发送数据的时候,数据会进行加密,只有私钥能解,只有服务器有这个私钥。黑客就算获得了公钥,没有私钥,也不能将被公钥加密过的数据解密。当服务端接受到客户端的信息后,要向客户端发起响应,这个响应是被私钥加密过的,黑客是有公钥的,所以黑客可以将服务端发送给客户端的数据给解密。
所以方案二只能保证单方向的数据安全性,此方案也不可取。
方案三 - 双方都是用非对称加密
服务端拥有公钥S与对应的私钥S',客⼾端拥有公钥C与对应的私钥C', 客户端和服务端交换公钥。客⼾端给服务端发信息:先⽤S对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥S'服务端给客⼾端发信息:先⽤C对数据加密,在发送,只能由客⼾端解密,因为只有客⼾端有私钥C'。这样貌似能行,双方协商完毕就可以保证安全性了。但是他的效率非常低。安全性问题还存在。
方案四 - ⾮对称加密+对称加密
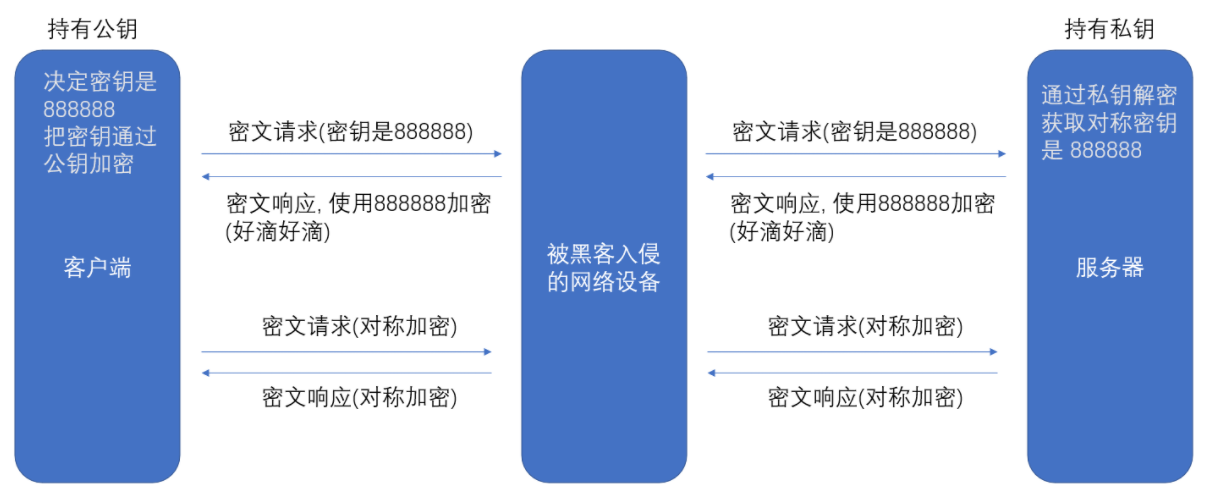
客户端先拿到服务端发送的公钥S, 然后客户端自己形成一个对称密钥C, 由公钥S和密钥C一起加密成XXX,然后发送给服务端, XXX在和私钥S` 解密成 C,此时服务端就有了对称密钥。这样就保证了数据安全,效率问题也有保证了。这个方案还是存在问题。
虽然上⾯已经⽐较接近答案了,但是依旧有安全问题
⽅案2,⽅案3,⽅案四都存在⼀个问题,如果最开始,中间⼈就已经开始攻击了呢?
中间人攻击 - 针对上面的场景
Man-in-the-MiddleAttack,简称“MITM攻击"
确实,在⽅案2/3/4中,客⼾端获取到公钥S之后,对客⼾端形成的对称秘钥X⽤服务端给客⼾端的公钥S进⾏加密,中间⼈即使窃取到了数据,此时中间⼈确实⽆法解出客⼾端形成的密钥X,因为只有服务器有私钥S'但是中间⼈的攻击,如果在最开始握⼿协商的时候就进⾏了,那就不⼀定了,假设hacker已经成功成为中间⼈ 。
- 服务器具有⾮对称加密算法的公钥S,私钥S'
- 中间⼈具有⾮对称加密算法的公钥M,私钥M'
- 客⼾端向服务器发起请求,服务器明⽂传送公钥S给客⼾端
- 中间⼈劫持数据报⽂,提取公钥S并保存好,然后将被劫持报⽂中的公钥S替换成为⾃⼰的公钥M,
并将伪造报⽂发给客⼾端 - 客⼾端收到报⽂,提取公钥M(⾃⼰当然不知道公钥被更换过了),⾃⼰形成对称秘钥X,⽤公钥M加
密X,形成报⽂发送给服务器 - 中间⼈劫持后,直接⽤⾃⼰的私钥M'进⾏解密,得到通信秘钥X,再⽤曾经保存的服务端公钥S加
密后,将报⽂推送给服务器 - 服务器拿到报⽂,⽤⾃⼰的私钥S'解密,得到通信秘钥X
- 双⽅开始采⽤X进⾏对称加密,进⾏通信。但是⼀切都在中间⼈的掌握中,劫持数据,进⾏窃听甚
⾄修改,都是可以的
上⾯的攻击⽅案,同样适⽤于⽅案2,⽅案3
问题本质出在哪⾥了呢?客⼾端⽆法确定收到的含有公钥的数据报⽂,就是⽬标服务器发送过来的!
CA证书
在访问网站的时候,可能会有这样的情况,网站的安全证书已经过期,是否选择相信之类的情况。其实就是CA证书到期了。
服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就⾏了,证书就如⾝份证,证明服务端公钥的权威性。
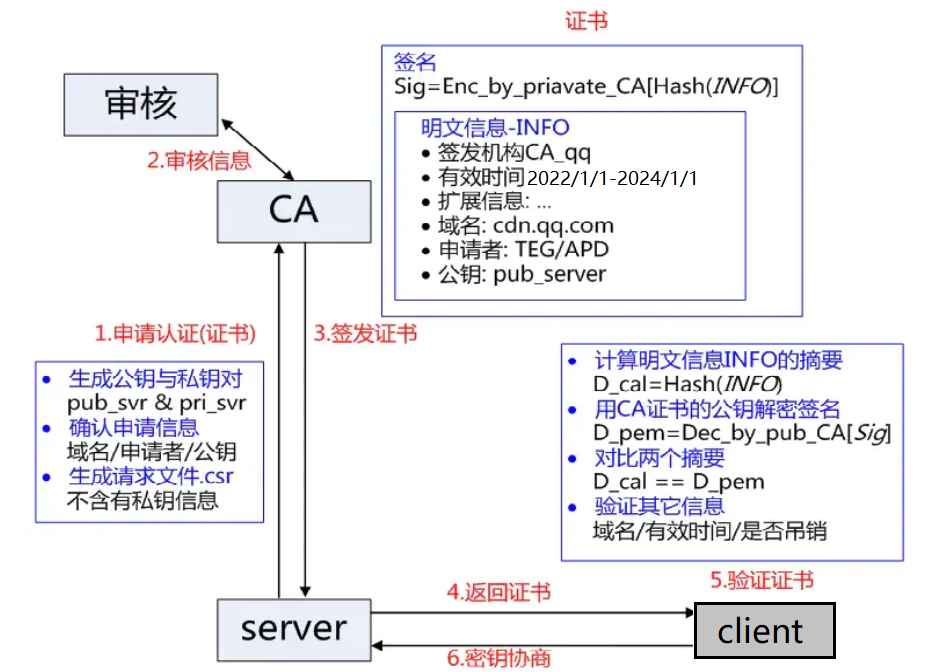
这个证书可以理解为是一个结构化的字符串,里面包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
- ……
需要注意的是:申请证书的时候,需要在特定平台⽣成查,会同时⽣成⼀对⼉密钥对⼉,即公钥和私
钥。这对密钥对⼉就是⽤来在⽹络通信中进⾏明⽂加密以及数字签名的。其中公钥会随着CSR⽂件,⼀起发给CA进⾏权威认证,私钥服务端⾃⼰保留,⽤来后续进⾏通信(其实主要就是⽤来交换对称秘钥)
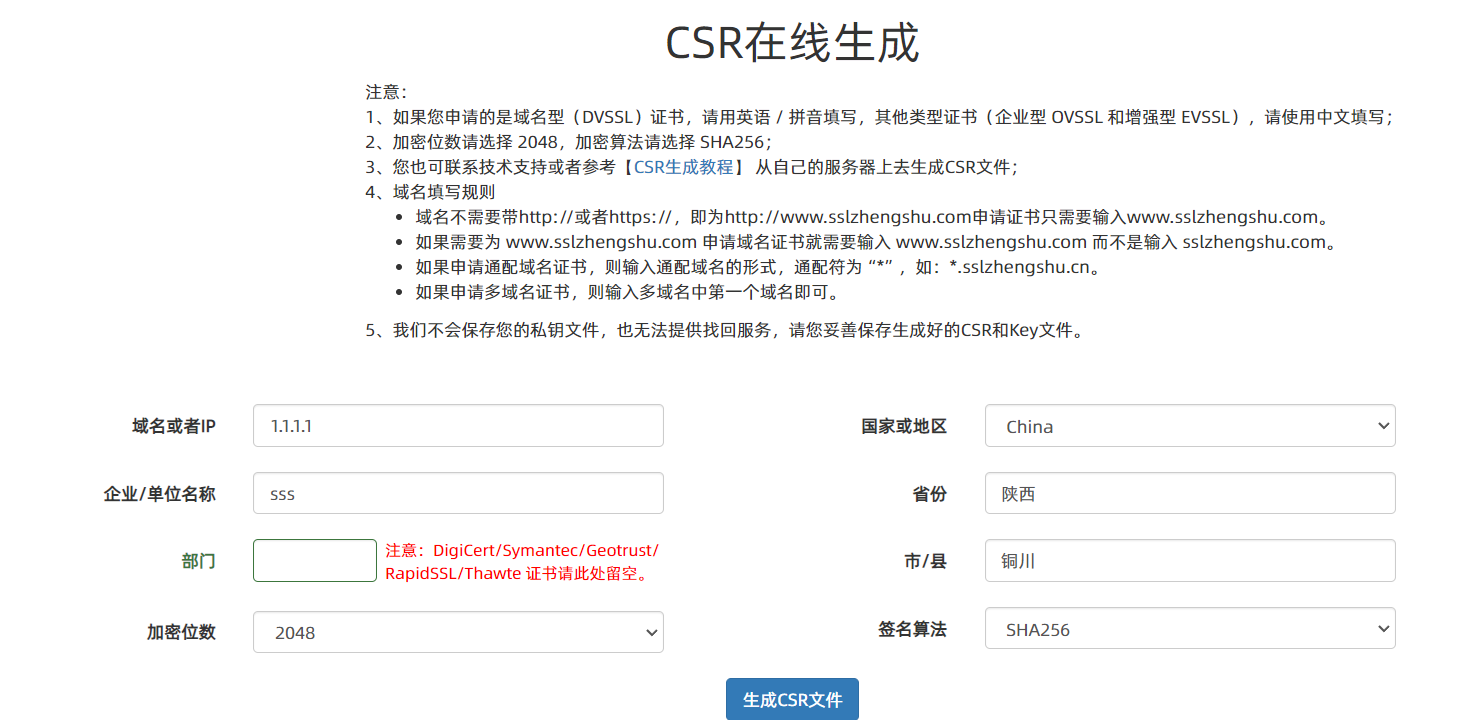
可以使用在线生成CSR和密钥形成CSR之后,后续就是向CA进⾏申请认证,不过⼀般认证过程很繁琐,⽹络各种提供证书申请的服务商,⼀般真的需要,直接找平台解决就⾏
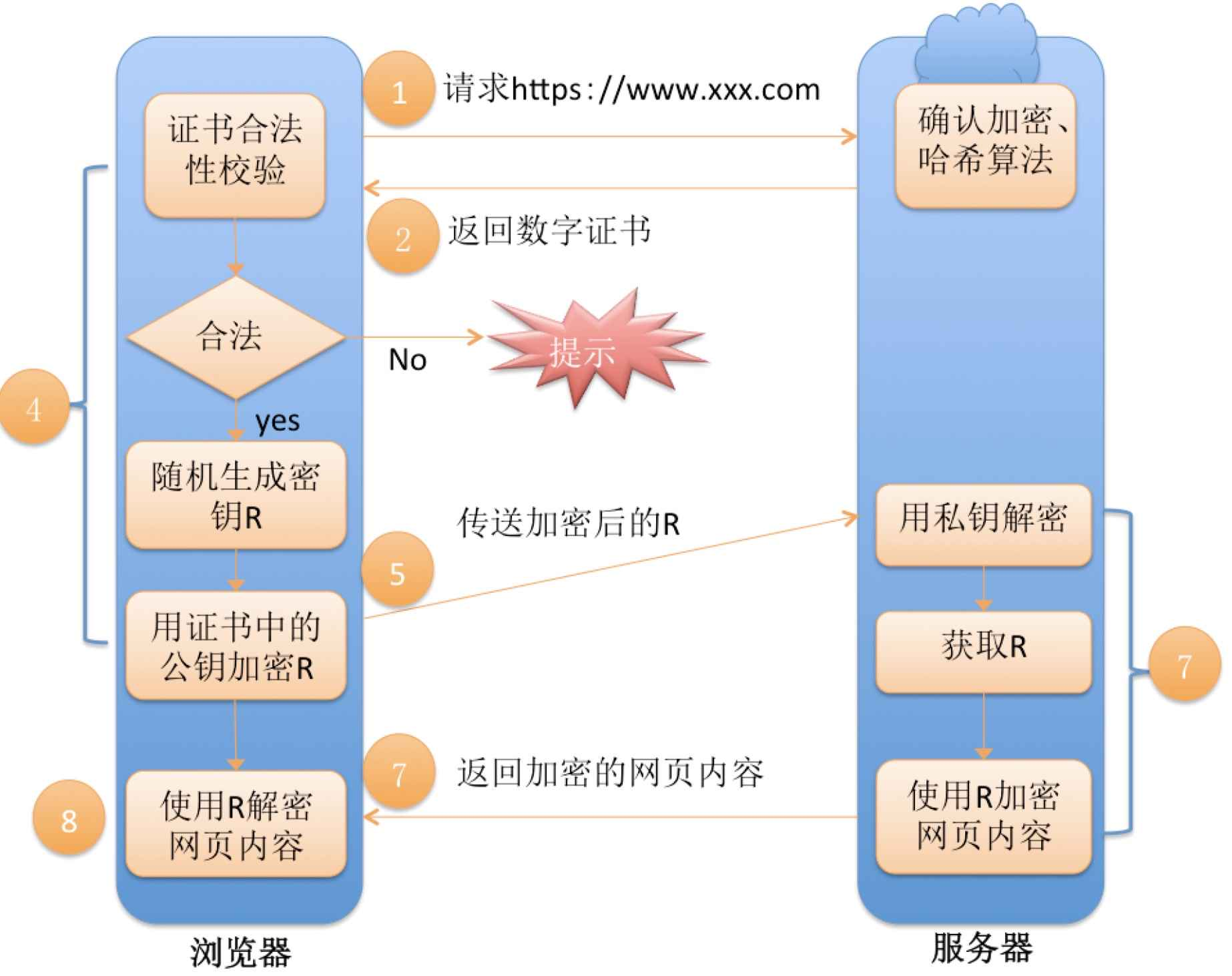
方案五 - 非对称加密 + 对称加密 + 证书认证
在客⼾端和服务器刚⼀建⽴连接的时候,服务器给客⼾端返回⼀个证书,证书包含了之前服务端的公钥,也包含了⽹站的⾝份信息.
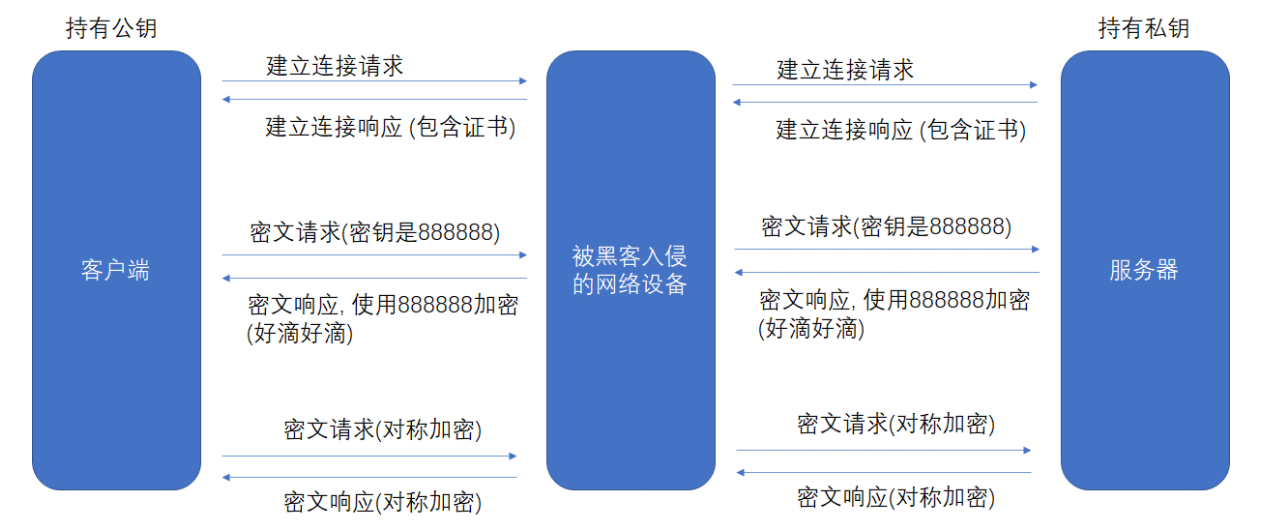
客⼾端进⾏认证
当客⼾端获取到这个证书之后,会对证书进⾏校验(防⽌证书是伪造的).
判定证书的有效期是否过期
判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构).
验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到⼀个hash值(称为数据摘要),设为hash1.然后计算整个证书的hash值,设为hash2.对⽐hash1和hash2是否相等.如果相等,则说明证书是没有被篡改过的。
中间⼈有没有可能篡改该证书?
1. 中间⼈篡改了证书的明⽂
2. 由于他没有CA机构的私钥,所以⽆法hash之后⽤私钥加密形成签名,那么也就没法办法对篡改后
的证书形成匹配的签名
3. 如果强⾏篡改,客⼾端收到该证书后会发现明⽂和签名解密后的值不⼀致,则说明证书已被篡改,
证书不可信,从⽽终⽌向服务器传输信息,防⽌信息泄露给中间⼈
中间⼈整个掉包证书?
1. 因为中间⼈没有CA私钥,所以⽆法制作假的证书(为什么?)
2. 所以中间⼈只能向CA申请真证书,然后⽤⾃⼰申请的证书进⾏掉包
3. 这个确实能做到证书的整体掉包,但是别忘记,证书明⽂中包含了域名等服务端认证信息,如果整
体掉包,客⼾端依旧能够识别出来。
4. 永远记住:中间⼈没有CA私钥,所以对任何证书都⽆法进⾏合法修改,包括⾃⼰的
完成流程