一、数据模型简介
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。 一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。Doris的key列是建表语句中指定的列,建表语句中的关键字'unique key'或'aggregate key'或'duplicate key'后面的列就是 Key 列,除了 Key 列剩下的就是 Value 列。
Doris 的数据模型主要分为3类:
- Aggregate
- Unique
- Duplicate
下面我们分别介绍。
二、明细模型【Duplicate】
建表
CREATE TABLE order_info (
order_date date NOT NULL COMMENT '下单日期',
order_id int(11) NOT NULL COMMENT '订单id',
buy_num tinyint(4) NULL COMMENT '购买件数',
user_id int(11) NULL COMMENT '[-1223371, 1223371]',
create_time datetime NULL COMMENT '创建时间',
update_time datetime NULL COMMENT '更新时间'
) ENGINE=OLAP
DUPLICATE KEY(order_date, order_id)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(order_id) BUCKETS 2
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
通过Flink Sql自带的datagen生成测试数据:
CREATE TABLE order_info_source (
order_date DATE,
order_id INT,
buy_num INT,
user_id INT,
create_time TIMESTAMP(3),
update_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.order_id.min' = '99999',
'fields.order_id.max' = '10001',
'fields.user_id.min' = '10001',
'fields.user_id.max' = '90001',
'fields.buy_num.min' = '1',
'fields.buy_num.max' = '200',
'number-of-rows' = '10000'
)
datagen参数
'rows-per-second' = '1000' : 每秒发送1000条数据
'fields.order_id.min' = '99999': order_id最小值为99999
'fields.order_id.max' = '10001': order_id最大值为10001
'fields.user_id.min' = '10001': user_id最小值为10001
'fields.user_id.max' = '90001': user_id最大值为90001
'fields.buy_num.min' = '1': buy_num最小值为1
'fields.buy_num.max' = '200': buy_num最大值为200
'number-of-rows' = '10000': 共发送10000条数据, 不设置的话会无限量发送数据
参考文档:DataGen | Apache FlinkDataGen SQL Connector # Scan Source: Bounded Scan Source: UnBoundedThe DataGen connector allows for creating tables based on in-memory data generation. This is useful when developing queries locally without access to external systems such as Kafka. Tables can include Computed Column syntax which allows for flexible record generation.The DataGen connector is built-in, no additional dependencies are required.Usage # By default, a DataGen table will create an unbounded number of rows with a random value for each column.![]() https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/datagen/
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/datagen/
注册Sink 表
CREATE TABLE order_info_sink (
order_date DATE,
order_id INT,
buy_num INT,
user_id INT,
create_time TIMESTAMP(3),
update_time TIMESTAMP(3)
)
WITH (
'connector' = 'doris',
'fenodes' = '192.168.56.XXX:8030',
'table.identifier' = 'test.order_info_example',
'username' = 'test123',
'password' = 'passwd123',
'sink.label-prefix' = 'sink_doris_label_8'
)
写入Sink 表
insert into order_info_sink select * from order_info_source
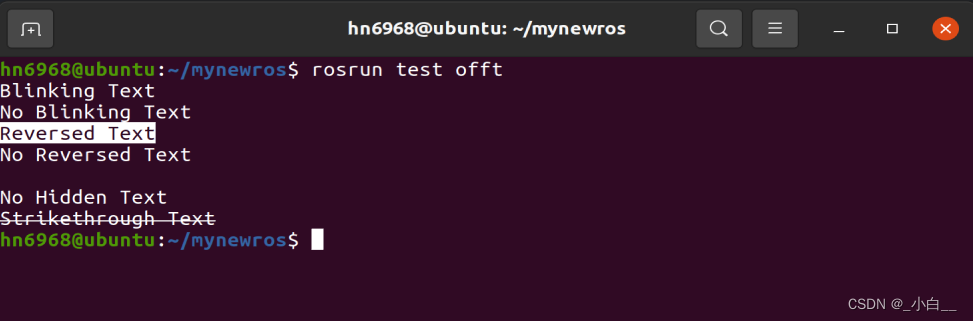
通过mysql客户端查看Doris Sink表数据
mysql> select * from test.order_info_example limit 10;
+------------+----------+---------+---------+---------------------+---------------------+
| order_date | order_id | buy_num | user_id | create_time | update_time |
+------------+----------+---------+---------+---------------------+---------------------+
| 2024-02-22 | 30007 | 10 | 10560 | 2024-02-22 07:42:21 | 2024-02-22 07:42:21 |
| 2024-02-22 | 30125 | 16 | 17591 | 2024-02-22 07:42:26 | 2024-02-22 07:42:26 |
| 2024-02-22 | 30176 | 17 | 10871 | 2024-02-22 07:42:24 | 2024-02-22 07:42:24 |
| 2024-02-22 | 30479 | 16 | 19847 | 2024-02-22 07:42:25 | 2024-02-22 07:42:25 |
| 2024-02-22 | 30128 | 16 | 19807 | 2024-02-22 07:42:24 | 2024-02-22 07:42:24 |
| 2024-02-22 | 30039 | 13 | 18237 | 2024-02-22 07:42:28 | 2024-02-22 07:42:28 |
| 2024-02-22 | 30060 | 10 | 18309 | 2024-02-22 07:42:24 | 2024-02-22 07:42:24 |
| 2024-02-22 | 30246 | 18 | 10855 | 2024-02-22 07:42:24 | 2024-02-22 07:42:24 |
| 2024-02-22 | 30288 | 19 | 12347 | 2024-02-22 07:42:26 | 2024-02-22 07:42:26 |
| 2024-02-22 | 30449 | 17 | 11488 | 2024-02-22 07:42:23 | 2024-02-22 07:42:23 |
+------------+----------+---------+---------+---------------------+---------------------+
10 rows in set (0.05 sec)
三、Unique模型
当用户有数据更新需求时,可以选择使用Unique数据模型。Unique模型能够保证Key的唯一性,当用户更新一条数据时,新写入的数据会覆盖具有相同key的旧数据。
Unique模型提供了两种实现方式:
- 读时合并(merge-on-read)。在读时合并实现中,用户在进行数据写入时不会触发任何数据去重相关的操作,所有数据去重的操作都在查询或者compaction时进行。因此,读时合并的写入性能较好,查询性能较差,同时内存消耗也较高。
- 写时合并(merge-on-write)。在1.2版本中,我们引入了写时合并实现,该实现会在数据写入阶段完成所有数据去重的工作,因此能够提供非常好的查询性能。
Unique建表
CREATE TABLE IF NOT EXISTS example_db.example_tbl_unique
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username)。
写时合并
CREATE TABLE IF NOT EXISTS example_db.example_tbl_unique_merge_on_write
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);【注意】
- Unique表的实现方式只能在建表时确定,无法通过schema change进行修改。
- 旧的Merge-on-read的实现无法无缝升级到Merge-on-write的实现(数据组织方式完全不同),如果需要改为使用写时合并的实现版本,需要手动执行
insert into unique-mow-table select * from source table.
四、聚合模型【Aggregate】
CREATE DATABASE IF NOT EXISTS example_db;
CREATE TABLE IF NOT EXISTS example_db.example_tbl_agg1
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age ... 等称为 Key,而设置了 AggregationType 的称为 Value。
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。 AggregationType 目前有以下几种聚合方式和agg_state:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
- REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于null值,不做替换。
- HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。
- BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。
数据导入
insert into example_db.example_tbl_agg1 values
(10000,"2017-10-01","北京",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","北京",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","北京",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","上海",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","广州",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","深圳",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","深圳",35,0,"2017-10-03 10:20:22",11,6,6);查询数据

五、数据模型的选择建议
因为数据模型在建表时就已经u企鹅人,且无法修改。所以,选择一个何时的数据模型非常重要。
- Aggregate模型可以通过预聚合,极大的降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表查询场景。但是该模型对count(*)查询不是很友好。同时因为固定了Value列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
- Unique模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用RollUp等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐使用1.2版本加入的写时合并实现。
- Duplicate适合任意维度的ad-hoc查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有的列)。