文章目录
- 前言
- 一、MemoryStateBackend
- 二、FSStateBackend
- 三、RocksDBStateBackend
- 四、StateBackend配置方式
- 五、状态持久化
- 六、状态重分布
- OperatorState 重分布
- KeyedState 重分布
- 七、状态过期
前言
Flink是一个流处理框架,它需要对数据流进行状态管理以支持复杂的计算逻辑。在Flink中,状态存储是指如何和在哪里存储这些状态数据。Flink提供了多种状态后端(State Backend)来实现这种存储,以满足不同的应用场景和性能需求。 StateBackend需要具备如下两种能力:
1、在计算过程中提供访问 State 的能力,开发者在编写业务逻辑中能够使用 StateBackend 的接口读写数据。
2、能够将 State 持久化到外部存储,提供容错能力。
根据使用场景的不同, Flink 内置了 3 种 StateBackend 。其体系结构如下图所示。
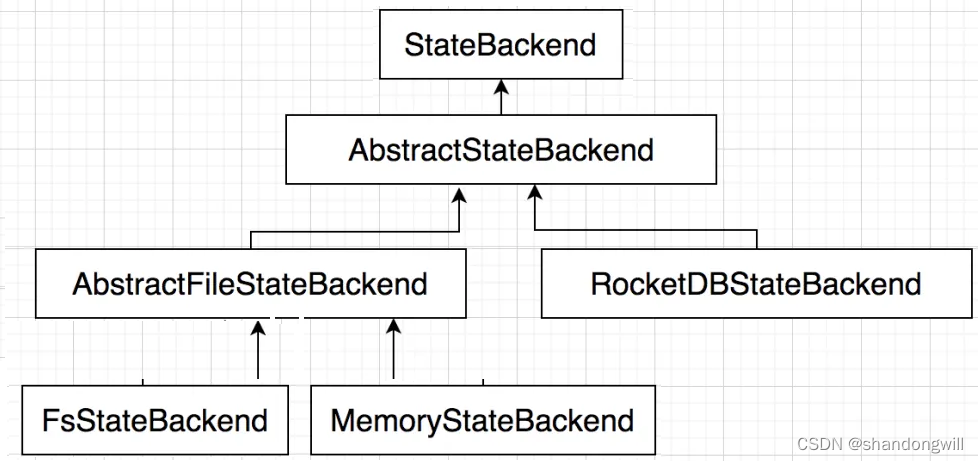
纯内存:MemoryStateBackend,适用于验证、测试,不推荐生产环境。
内存+文件:FsStateBackend,适用于长周期大规模的数据。
RocksDB:RocksDBStateBackend,适用于长周期大规模的数据。
在运行时,MemoryStateBackend 和 FsStateBackend 本地的 State 都保存在 TaskManager 的内存中,所以其底层依赖于 HeapKeyedStateBackend。HeapKeyedStateBackend 面向 Flink 引擎内部,使用者无须感知。
一、MemoryStateBackend
默认情况下,状态信息是通过MemoryStateBackend 存储在 TaskManager 的堆内存中的, KV 类型的State,窗口算子的 State 使用 HashTable 来保存数据、触发器等。执行检查点的时候,会把 State 的快照数据保存到 JobManager 进程的内存中。 MemoryStateBackend 可以使用异步的方式进行快照,(也可以同步),推荐异步,避免阻塞算子处理数据。
基于内存的 StateBackend 在生产环境下不建议使用,可以在本地开发调试测试 。
注意点如下 :
- State 存储在 JobManager 的内存中,受限于 JobManager 的内存大小。
- 每个 State 默认 5MB,可通过 MemoryStateBackend 构造函数调整。
- 每个 State 不能超过 Akka Frame 大小。
二、FSStateBackend
文件型状态存储 FSStateBackend,运行时所需的 State 数据全部保存在 TaskManager 的内存中, 执行检查点的时候,会把 State 的快照数据保存到配置的文件系统中,如使用 HDFS 的路径为 “hdfs://namenode:40010/flink/checkpoints”,使用本地文件系统的路径为:“file:///data/flink/checkpoints”。
FSStateBackend 适用于处理大状态、长窗口,或大键值状态的有状态处理任务。
缺点:
状态大小受TaskManager内存限制(默认支持5M)
优点:
状态访问速度很快
状态信息不会丢失
用于: 生产,也可存储状态数据量大的情况
三、RocksDBStateBackend
RocksDBStateBackend 跟内存型和文件型 StateBackend 不同,其使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中,不会受限于 TaskManager 的内存大小,在执行检查点的时候,再将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中,在 JobManager 内存中会存储少量的检查点元数据。RocksDB 克服了 State 受内存限制的问题,同时又能够持久化到远端文件系统中,比较适合在生产中使用。 但是 RocksDBStateBackend 相比基于内存的 StateBackcnd ,访问 State 的成本高很多,可能导致数据流的吞吐量剧烈下降,甚至可能降低为原来的 1/10。
适用场景:
最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
RocksDBStateBackend 非常适合用于高可用方案。
RocksDBStateBackend 是目前唯一支持增量检查点的后端,增量检查点非常适用于超大状态的场景。
注意点
- 总 State 大小仅限于磁盘大小,不受内存限制。
- RocksDBStateBackend 也需要配置外部文件系统,集中保存 State。
- RocksDB的 JNI API 基于byte数组,单 key 和单 Value 的大小不能超过 231 字节。
- 对于使用具有合并操作状态的应用程序,如 ListState ,随着时间可能会累积到超过 231 字节大小,这将会导致在接下来的查询中失败。
四、StateBackend配置方式
- 单任务调整
修改当前任务代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new
FsStateBackend("hdfs://namenode:9000/flink/checkpoints"));
或者new MemoryStateBackend()
或者new RocksDBStateBackend(filebackend, true);【需要添加第三方依赖】
}
- 全局调整(不建议)
修改flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
注意:state.backend的值可以是下面几种:jobmanager(MemoryStateBackend),
filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
五、状态持久化
StateBackend 中的数据最终需要持久化到第三方存储中,确保集群故障或者作业故障能够恢复。 HeapSnapshotStrategy 策略对应于 HeapKeyedStateBackend,RocksDBStateBackend 的持久化策略有两种:全量持久化策略(RocksFullSnapshotStrategy)和 增量持久化策略 (RocksIncementalSnapshotStrategy)。
1、全量持久化策略
全盘持久化,也就是说每次把全量的 Slate 写人到状态存储中 (如 HDFS)。内存型、文件型、 RocksDB 类型的 StatcBackend 支持全量持久化策略。 在执行持久化策略的时候,使用异步机制,每个算子启动 1 个独立的线程,将自身的状态写入分布式存储中。在做持久化的过程中,状态可能会被持续修改,基于内存的状态后端使用 CopyOnWriteStateTable 来保证线程安全,RocksDBStateBackend 则使用 RocksDB 的快照机制,使用快照来保证线程安全。
2、增量持久化策略
增量持久化就是每次持久化增量的 State,只有 RocksDBStateBackend 支持增量持久化。Flink 增量式的检查点以 RocksDB 为基础, RocksDB 是一个基于 LSM-Tree 的 KV 存储。新的数据保存在内存中, 称为 memtable。如果 Key 相同,后到的数据将覆盖之前的数据,一旦 memtable 写满了,RocksDB 就会将数据压缩并写入磁盘。memtable 的数据持久化到磁盘后,就变成了不可变的 sstable。
因为 sstable 是不可变的,Flink 对比前一个检查点创建和删除的 RocksDB sstable 文件就可以计算出状态有哪些发生改变。
为了确保 sstable 是不可变的,Flink 会在 RocksDB 触发刷新操作,强制将 memtable 刷新到磁盘上 。在 Flink 执行检查点时,会将新的 sstable 持久化到 HDFS 中,同时保留引用。这个过程中 Flink 并不会持久化本地所有的 sstable,因为本地的一部分历史 sstable 在之前的检查点中已经持久化到存储中了,只需增加对 sstable 文件的引用次数就可以。 RocksDB 会在后台合并 sstable 并删除其中重复的数据。然后在 RocksDB 删除原来的 sstable,替换成新合成的 sstable.。新的 sstable 包含了被删除的 sstable中的信息,通过合并历史的 sstable 会合并成一个新的 sstable,并删除这些历史sstable。可以减少检查点的历史文件,避免大量小文件的产生。
六、状态重分布
在实际的生产环绕中,作业预先设置的并行度很多时候并不合理,太多则浪费资源,太少则资源不足,可能导致数据积压延迟变大或者处理时间太长,所以在运维过程中,需要根据作业的运行监控数据调整其并行度。调整并行度的关键是处理 State。回想一下前文中的内容,State 位于算子内,改变了并行度,则意味着算子个数改变了,需要将 State 重新分配给算子。下面从 OperatorState 和 KeyedState 两种 State 角度,介绍如何将 State 重新分配给算子。
OperatorState 重分布
1、ListState
并行度在改变的时候,会将并发上的每个 List 都取出,然后把这些 List 合并到一个新的 List,根据元素的个数均匀分配给新的 Task。
2、UnionListState
比 ListState 更加灵活, 把划分的方式交给用户去做,当改变并发的时候,会将原来的 List 拼接起来,然后不做划分,直接交给用户。
3、BroadcastState
操作 BroadcastState 的 UDF 需要保证不可变性,所以各个算子的同一个 BroadcastState 完全一样。在改变并发的时候,把这些数据分发到新的 Task 即可。
KeyedState 重分布
基于 Key-Group ,每个 Key 隶属于唯一的 Key-Group。Key Group 分配给 Task 实例,每个 Task 至少有 一个 Key-Group 。 Key-Group 数量取决于最大并行度 (MaxParallism) 。 KeyedStream 并发的上限是 Key-Group 的数量,等于最大并行度。
七、状态过期
1、DataStream 中状态过期
可以对 每一个 State 设置 清理策略 StateTtlConfig,可以设置的内容如下:
过期时间:超过多长时间未访问,视为 State 过期,类似于缓存。
过期时间更新策略:创建和写时更新、读取和写时更新。
State 可见性:未清理可用,超时则不可用。
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
2、Flink SQL 中状态过期
Flink SQL 在流 Join、聚合类的场景中,使用了 State,如果 State 不定时清理。 则可能会导致 State 过多,内存溢出。 为了稳妥起见,最好为每个 FLink SQL 作业提供 State 清理的策略。如果定时清理 State,则存在可能因为 State 被清理而导致计算结果不完全准确的风险。FLink 的 Table API 和 SQL 接口中提供了参数设置选项,能够让使用者在精确和资源消耗做折中。
StreamQueryConfig qConfig = ...
//设置过期时间为 min = 12 小时 ,max = 24 小时
qConfig.withIdleStateRetentionTime(Time.hours(12),Time.hours(24));