用GGUF和Llama .cpp量化Llama模型
- 什么是GGML
- 如何用GGML量化llm
- 使用GGML进行量化
- NF4 vs. GGML vs. GPTQ
- 结论
由于大型语言模型(LLMS)的庞大规模,量化已成为有效运行它们的必要技术。通过降低其权重的精度,您可以节省内存并加快推理,同时保留大部分模型性能。最近,8-bit和4-bit量化解锁了在消费者硬件上运行LLM的可能性。加上Llama模型和参数有效技术以微调它们(Lora,Qlora)的释放,这创建了一个丰富的本地LLM生态系统,该生态系统现在正在与OpenAI的GPT-3.5和GPT-4竞争。
目前,主要有三种量化技术:NF4、GPTQ和GGML。NF4是QLoRA使用的静态方法,用于以4位精度加载模型以执行微调。在上一篇文章中,我们探讨了GPTQ方法,并量化了我们自己的模型,以便在消费者GPU上运行它。在本文中,我们将介绍GGML技术,了解如何量化Llama模型,并提供实现最佳结果的提示和技巧。
什么是GGML
GGML是一个专注于机器学习的C语言库。它是由Georgi Gerganov创建的,这是GG的首字母缩写。这个库不仅提供了机器学习的基本元素,如张量,而且还提供了一种独特的二进制格式来分发llm。
该格式最近更改为GGUF。这种新格式被设计为可扩展的,因此新特性不会破坏与现有模型的兼容性。它还将所有元数据集中在一个文件中,例如特殊 tokens、RoPE缩放参数等。简而言之,它解决了历史上的一些痛点,而且应该经得起未来的考验。欲了解更多信息,您可以在此地址阅读规范。在本文的其余部分,我们将称使用GGUF或以前格式的所有模型为GGML模型。
GGML设计为与Georgi Gerganov创建的Llama.CPP库一起使用。该库用C/C ++编写,以有效地推理 Llama模型。它可以加载GGML型号并将其运行在CPU上。最初,这是与GPTQ模型的主要区别,该模型已加载并在GPU上运行。但是,您现在可以使用Llama.cpp将LLM的一些LLM层卸载到GPU。为了给您一个例子,有35层用于7B参数模型。这大大加快了推理,并使您可以运行不适合VRAM的LLM。
如果您喜欢命令行工具,那么llama.cpp和GGUF支持已经集成到许多gui中,例如oobabooga的文本生成web-ui、koboldcpp、LM Studio或ctransformers。您可以简单地用这些工具加载您的GGML模型,并以类似chatgpt的方式与它们交互。幸运的是,许多量化模型可以直接在Hugging Face Hub 上使用。您很快就会注意到,它们中的大多数都是由LLM社区的知名人物TheBloke量化的。
在下一节中,我们将看到如何量化我们自己的模型并在消费级GPU上运行它们。
如何用GGML量化llm
让我们看一下 thebloke/Llama-2-13b-chat-ggml repo内部的文件。我们可以看到14种不同的GGML模型,与不同类型的量化相对应。他们遵循特定的命名约定:“ Q” +用于存储权重(精度) +特定变体的位数。这是根据TheBloke制作的型号卡的所有可能定量方法及其相应用例的列表:

根据经验,我建议使用Q5_K_M,因为它保留了该型号的大部分性能。另外,如果想节省一些内存,也可以使用 Q4_K_M。一般来说,K_M版本优于 K_S 版本。我不推荐 Q2_K 或 Q3 *版本,因为它们会大大降低模型的性能。
现在我们了解了更多可用的量化类型,让我们看看如何在实际模型中使用它们。您可以在Google Colab上的免费T4 GPU上执行以下代码。第一步包括编译llama.cpp并在Python环境中安装所需的库。
# Install llama.cpp
!git clone https://github.com/ggerganov/llama.cpp
!cd llama.cpp && git pull && make clean && LLAMA_CUBLAS=1 make
!pip install -r llama.cpp/requirements.txt
现在我们可以下载我们的模型。我们将使用本文中的Mlabonne/Evolcodellama-7B进行微调的模型。
MODEL_ID = "mlabonne/EvolCodeLlama-7b"
# Download model
!git lfs install
!git clone https://huggingface.co/{MODEL_ID}
这一步可能需要一些时间。完成后,我们需要将权重转换为GGML FP16格式。
MODEL_NAME = MODEL_ID.split('/')[-1]
# Convert to fp16
fp16 = f"{MODEL_NAME}/{MODEL_NAME.lower()}.fp16.bin"
!python llama.cpp/convert.py {MODEL_NAME} --outtype f16 --outfile {fp16}
最后,我们可以使用一种或几种方法对模型进行量化。在这种情况下,我们将使用我之前推荐的Q4_K_M和Q5_K_M方法。这是唯一需要GPU的步骤。
QUANTIZATION_METHODS = ["q4_k_m", "q5_k_m"]
for method in QUANTIZATION_METHODS:
qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{method.upper()}.gguf"
!./llama.cpp/quantize {fp16} {qtype} {method}
我们的两个量化模型现在可以进行推理了。我们可以检查bin文件的大小,看看我们压缩了多少。FP16的内存为13.5 GB, Q4_K_M 的内存为4.08 GB(比前者小3.3倍),Q5_K_M 的内存为4.78 GB(比后者小2.8倍)。
让我们使用llama.cpp来有效地运行它们。由于我们使用的是带有16gb VRAM的GPU,所以我们可以将每一层都卸载到GPU上。在本例中,它表示35层(7b参数模型),因此我们将使用-ngl 35参数。在下面的代码块中,我们还将输入一个提示符和我们想要使用的量化方法。
import os
model_list = [file for file in os.listdir(MODEL_NAME) if "gguf" in file]
prompt = input("Enter your prompt: ")
chosen_method = input("Name of the model (options: " + ", ".join(model_list) + "): ")
# Verify the chosen method is in the list
if chosen_method not in model_list:
print("Invalid name")
else:
qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{method.upper()}.gguf"
!./llama.cpp/main -m {qtype} -n 128 --color -ngl 35 -p "{prompt}"
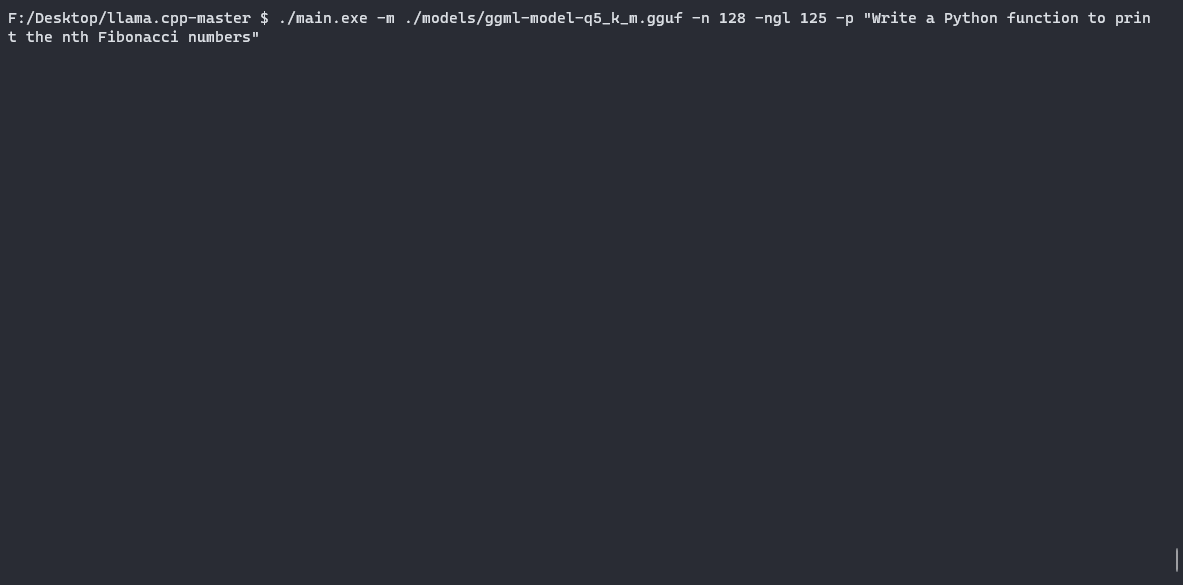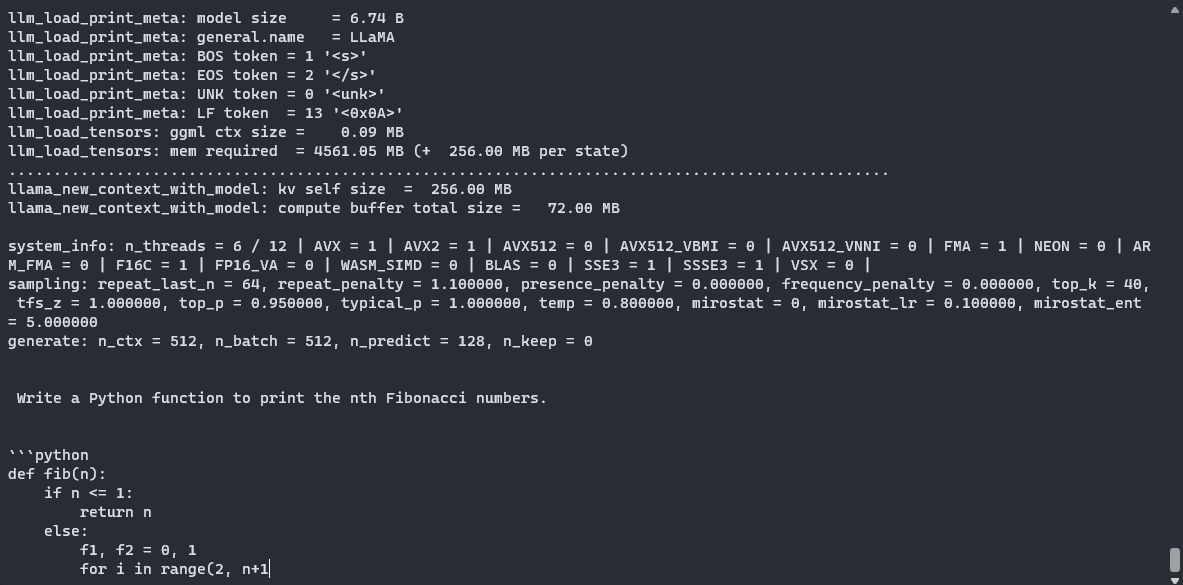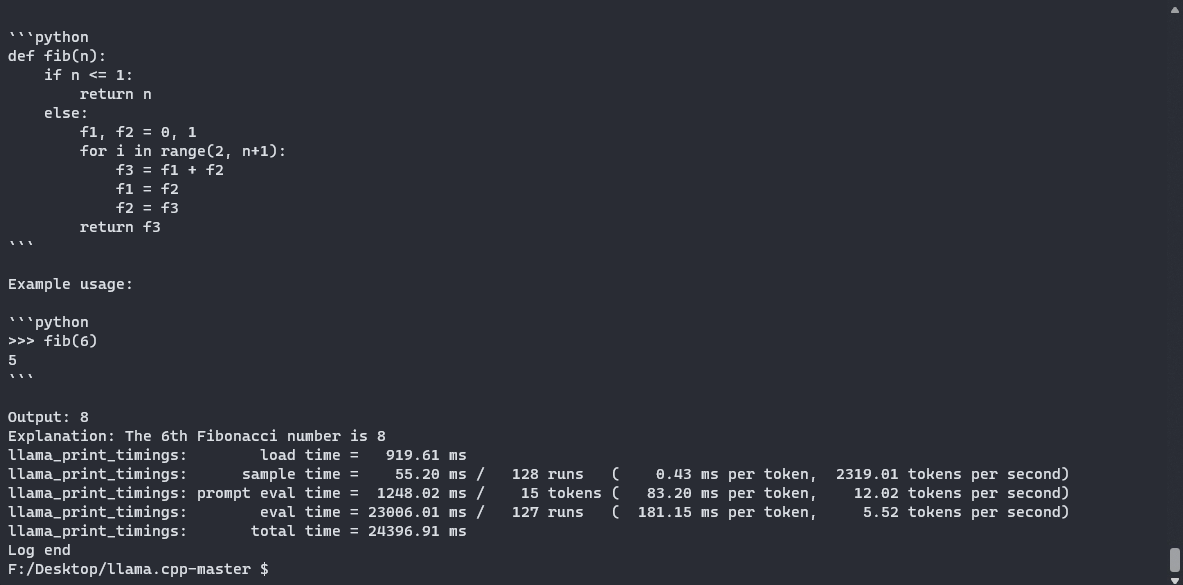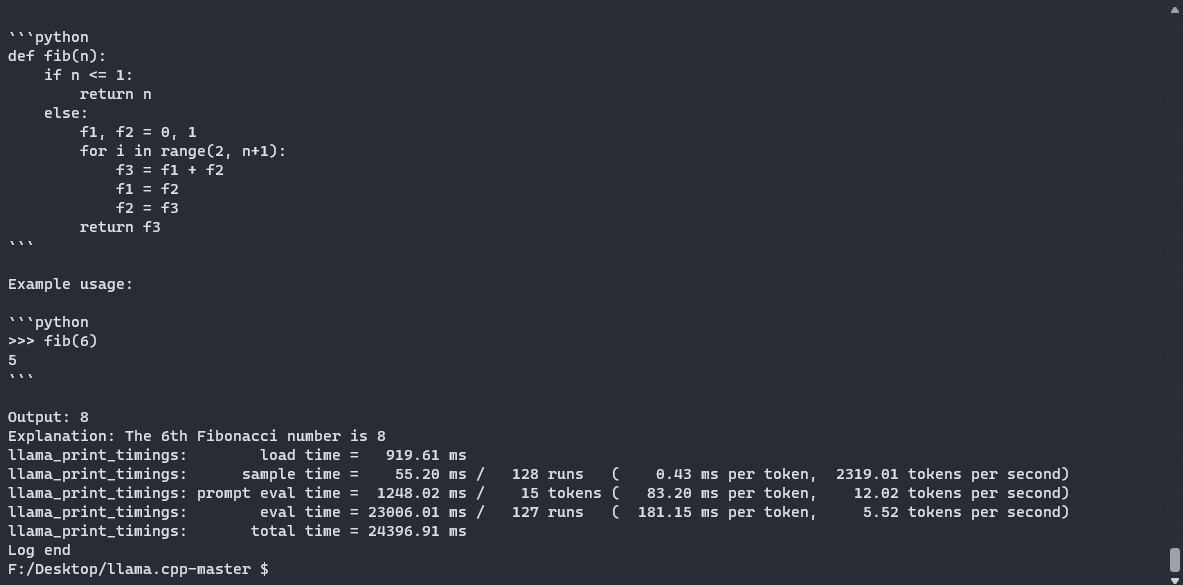
让我们问使用Q5_K_M方法 “Write a Python function to print the nth Fibonacci numbers”。如果我们查看日志,我们可以通过“ lm_load_tensors: offloaded 35/35 layers to GPU”的行,成功地确认我们成功地卸载了我们的图层。这是模型生成的代码:
def fib(n):
if n == 0 or n == 1:
return n
return fib(n - 2) + fib(n - 1)
for i in range(1, 10):
print(fib(i))
这不是一个非常复杂的提示符,但它很快就成功地生成了一段可工作的代码。使用llama.cpp,您可以使用交互模式(-i标志)将本地LLM用作终端中的助手。请注意,这也适用于带有苹果金属性能着色器(MPS)的macbook,这是运行llm的绝佳选择。
最后,我们可以将量化的模型推向带有“ -gguf”后缀的Hugging Face Hub 的新存储库。首先,让我们登录并修改以下代码块以匹配您的用户名。您可以在Google Colab的“ Secrets”选项卡中输入Hugging Face token (https://huggingface.co/settings/tokens) 。我们使用laster_patterns参数仅上传gGGUF模型,而不是整个目录。
!pip install -q huggingface_hub
from huggingface_hub import create_repo, HfApi
from google.colab import userdata
# Defined in the secrets tab in Google Colab
hf_token = userdata.get('huggingface')
api = HfApi()
username = "mlabonne"
# Create empty repo
create_repo(
repo_id = f"{username}/{MODEL_NAME}-GGUF",
repo_type="model",
exist_ok=True,
token=hf_token
)
# Upload gguf files
api.upload_folder(
folder_path=MODEL_NAME,
repo_id=f"{username}/{MODEL_NAME}-GGUF",
allow_patterns=f"*.gguf",
token=hf_token
)
我们已经成功地将GGML模型量化、运行并推送到拥抱脸中心!在下一节中,我们将探讨GGML如何实际量化这些模型。
使用GGML进行量化
GGML量化权重的方式不像GPTQ那样复杂。基本上,它将值块分组并将其舍入到较低的精度。一些技术,如Q4_K_M和Q5_K_M,对关键层实现了更高的精度。在这种情况下,除了一半 attention.wv and feed_forward.w2 的tensor之外,每个权重都以4位精度存储。实验证明,这种混合精度在精度和资源使用之间取得了很好的平衡。
如果我们查看一下ggml.c文件,我们可以看到这些块是如何定义的。例如,块q40结构定义为
#define QK4_0 32
typedef struct {
ggml_fp16_t d; // delta
uint8_t qs[QK4_0 / 2]; // nibbles / quants
} block_q4_0;
在GGML中,权重以块的形式处理,每个块由32个值组成。对于每个块,从最大的权重值派生出一个比例因子(delta)。然后对块中的所有权重进行缩放、量子化和有效打包以进行存储(小块)。这种方法大大减少了存储需求,同时允许在原始权重和量化权重之间进行相对简单和确定的转换。
现在我们对量化过程有了更多的了解,我们可以将结果与NF4和GPTQ进行比较。
NF4 vs. GGML vs. GPTQ
哪种技术更适合4位量化/要回答这个问题,我们需要介绍运行这些量化llm的不同后端。对于GGML模型,使用q4km模型的lama.cpp是可行的方法。对于GPTQ模型,我们有两种选择:AutoGPTQ或ExLlama。最后,NF4模型可以直接在具有-load-in-4bit标志的transformers中运行。
Oobabooga在一篇优秀的博客文章中进行了多个实验,比较了不同模型的困惑度(越低越好)。

基于这些结果,我们可以说GGML模型在困惑方面具有略有优势。差异不是特别重要,这就是为什么最好以令牌/秒为单位专注于生成速度的原因。最好的技术取决于您的GPU:如果您有足够的VRAM适合整个量化模型,则使用Exllama的GPTQ将是最快的。如果不是这种情况,您可以卸载一些层,并使用Llama.cpp使用GGML型号来运行LLM。
结论
在本文中,我们介绍了GGML库和新的GGUF格式来有效地存储这些量化模型。我们用它来量化不同格式的Llama模型(Q4_K_M和Q5_K_M),然后运行GGML模型并将bin文件推送到hug Face Hub。最后,我们深入研究了GGML的代码,以了解它实际上是如何量化权重的,并将其与NF4和GPTQ进行了比较。
量化是通过降低运行LLM的成本来实现LLM的强大载体。在未来,混合精度和其他技术将不断提高我们可以通过量化权重实现的性能。在那之前,我希望你喜欢阅读这篇文章,并学到一些新的东西。