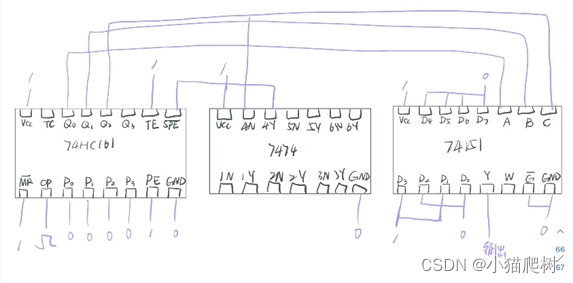
前言
本篇主要是结合手写数字例子,结合PyTorch 介绍一下Gan 实战
第一轮训练效果

第20轮训练效果,已经可以生成数字了

68 轮

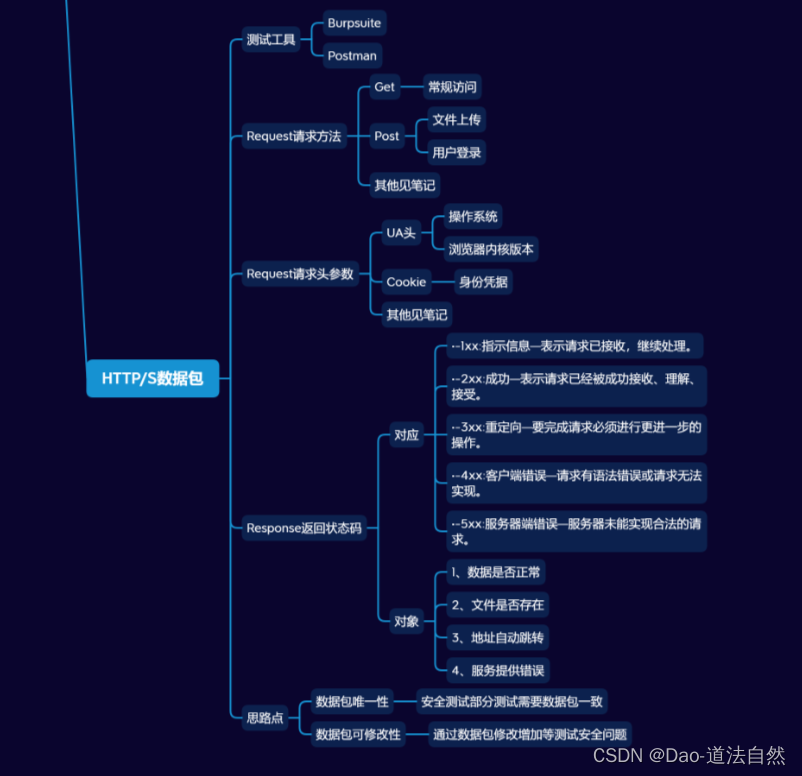
目录:
- 谷歌云服务器(Google Colab)
- 整体训练流程
- Python 代码
一 谷歌云服务器(Google Colab)
个人用的一直是联想小新笔记本,虽然非常稳定方便。但是现在跑深度学习,性能确实有点跟不上.
1.1 打开谷歌云服务器(Google Colab)
https://colab.research.google.com/
1. 2 新建笔记

1
1.4 选择T4GPU


1.5 点击运行按钮
可以看到当前硬件的情况

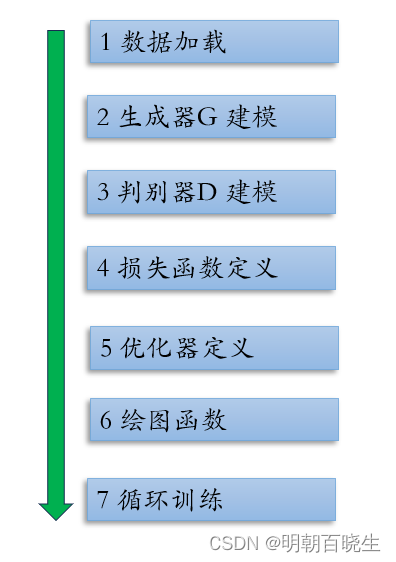
二 整体训练流程
三 PyTorch 例子
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 1 13:27:49 2024
@author: chengxf2
"""
import torch.optim as optim #优化器
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
import torch
import torch.nn as nn
#第一步加载手写数字集
def loadData():
#同时归一化数据集(-1,1)
style = transforms.Compose([
transforms.ToTensor(), #0-1 归一化0-1, channel,height,width
transforms.Normalize(mean=0.5, std=0.5) #变成了-1,1
]
)
trainData = torchvision.datasets.MNIST('data',
train=True,
transform=style,
download=True)
dataloader = torch.utils.data.DataLoader(trainData,
batch_size= 16,
shuffle=True)
imgs,_ = next(iter(dataloader))
#torch.Size([64, 1, 28, 28])
print("\n imgs shape ",imgs.shape)
return dataloader
class Generator(nn.Module):
'''
定义生成器
输入:
z 随机噪声[batch, input_size]
输出:
x: 图片 [batch, height, width, channel]
'''
def __init__(self,input_size):
super(Generator,self).__init__()
self.net = nn.Sequential(
nn.Linear(in_features = input_size , out_features =256),
nn.ReLU(),
nn.Linear(in_features = 256 , out_features =512),
nn.ReLU(),
nn.Linear(in_features = 512 , out_features =28*28),
nn.Tanh()
)
def forward(self, z):
# z 随机输入[batch, dim]
x = self.net(z)
#[batch, height, width, channel]
#print(x.shape)
x = x.view(-1,28,28,1)
return x
class Discriminator(nn.Module):
'''
定义鉴别器
输入:
x: 图片 [batch, height, width, channel]
输出:
y: 二分类图片的概率: BCELoss 计算交叉熵损失
'''
def __init__(self):
super(Discriminator,self).__init__()
#开始的维度和终止的维度,默认值分别是1和-1
self.flatten = nn.Flatten()
self.net = nn.Sequential(
nn.Linear(in_features = 28*28 , out_features =512),
nn.LeakyReLU(), #负值的时候保留梯度信息
nn.Linear(in_features = 512 , out_features =256),
nn.LeakyReLU(),
nn.Linear(in_features = 256 , out_features =1),
nn.Sigmoid()
)
def forward(self, x):
x = self.flatten(x)
#print(x.shape)
out =self.net(x)
return out
def gen_img_plot(model, epoch, test_input):
out = model(test_input).detach().cpu()
out = out.numpy()
imgs = np.squeeze(out)
fig = plt.figure(figsize=(4,4))
for i in range(out.shape[0]):
plt.subplot(4,4,i+1)
img = (imgs[i]+1)/2.0#[-1,1]
plt.imshow(img)
plt.axis('off')
plt.show()
def train():
#1 初始化参数
device ='cuda' if torch.cuda.is_available() else 'cpu'
#2 加载训练数据
dataloader = loadData()
test_input = torch.randn(16,100,device=device)
#3 超参数
maxIter = 20 #最大训练次数
input_size = 100
batchNum = 16
input_size =100
#4 初始化模型
gen = Generator(100).to(device)
dis = Discriminator().to(device)
#5 优化器,损失函数
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-4)
g_optim = torch.optim.Adam(gen.parameters(),lr=1e-4)
loss_fn = torch.nn.BCELoss()
#6 loss 变化列表
D_loss =[]
G_loss= []
for epoch in range(0,maxIter):
d_epoch_loss = 0.0
g_epoch_loss =0.0
#count = len(dataloader)
for step ,(realImgs, _) in enumerate(dataloader):
realImgs = realImgs.to(device)
random_noise = torch.randn(batchNum, input_size).to(device)
#先训练判别器
d_optim.zero_grad()
real_output = dis(realImgs)
d_real_loss = loss_fn(real_output, torch.ones_like(real_output))
d_real_loss.backward()
#不要训练生成器,所以要生成器detach
fake_img = gen(random_noise)
fake_output = dis(fake_img.detach())
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output))
d_fake_loss.backward()
d_loss = d_real_loss+d_fake_loss
d_optim.step()
#优化生成器
g_optim.zero_grad()
fake_output = dis(fake_img.detach())
g_loss = loss_fn(fake_output, torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
with torch.no_grad():
d_epoch_loss+= d_loss
g_epoch_loss+= g_loss
count = 16
with torch.no_grad():
d_epoch_loss/=count
g_epoch_loss/=count
D_loss.append(d_epoch_loss)
G_loss.append(g_epoch_loss)
gen_img_plot(gen, epoch, test_input)
print("Epoch: ",epoch)
print("-----finised-----")
if __name__ == "__main__":
train()
参考:
10.完整课程简介_哔哩哔哩_bilibili
理论【PyTorch][chapter 19][李宏毅深度学习]【无监督学习][ GAN]【理论】-CSDN博客


![[SUCTF 2019]EasyWeb --不会编程的崽](https://img-blog.csdnimg.cn/direct/3630f20ad81d493e8114f13ed0225f34.png)