近日,我们开源了有道自研的RAG(Retrieval Augmented Generation) 引擎QAnything。该引擎允许用户上传PDF、图片、Word、Excel、PowerPoint等多种格式的文档,并实现类似于ChatGPT的互动问答功能,其中每个答案都能精确追溯到相应的文档段落来源。QAnything 支持纯本地部署,上传文档数量无上限,问答准确率高。
QAnything自开源以来,迅速吸引了开发者社区的广泛关注,并很快登上了GitHub trending榜单。短短一个月内,下载次数已达数万次,其中,我们的语义嵌入排序模型BCEmbedding更是达到了惊人的60万次下载。根据社区的热情反馈,我们决定分享QAnything背后的研发故事、技术路线选择以及我们的经验,希望能够为社区带来启发。
QAnything的起源
与市场上的其他Retrieval Augmented Generation (RAG) 产品相比,QAnything引擎的研发轨迹略显不同。它不是一开始就被设定为一个具体的项目目标,而是在项目进展中,通过不断的探索和实践,逐步成形的。这个过程虽然经历了一些波折,但正是这些经历,让我们在RAG领域积累了丰富的实践经验。
从文档翻译到文档问答
QAnything的研发团队最初专注于文档翻译。2022年我们启动了一个为期一年的文档翻译的升级的项目,到2023年3月份上线,效果提升显著。正好那时候ChatGPT和类似技术正在兴起,我们意识到这正是将我们现有技术扩展至文档问答的绝佳时机。因此,我们毫不犹豫地为我们的文档翻译服务增添了问答功能,该功能能够根据文档内容自动推荐问题并提供答案,于5月份正式推出。

(视频链接:https://www.bilibili.com/video/BV1fw4m1Z7QX/)
之所以能够轻松地扩展到文档问答,是因为有道在文档翻译领域的深厚积累。我们的文档翻译服务因其卓越的性能而闻名,这主要得益于两大核心技术:先进的翻译引擎和精准的文档解析/OCR技术。多年来,在翻译和OCR领域的持续探索和创新,为我们构建Retrieval Augmented Generation (RAG) 系统提供了坚实的基础。
首先,核心技术方面,我们的翻译模型基于Transformer架构,这与当前研究领域的大型语言模型(LLM)紧密相连,实质上并无显著区别。所谓LLM,就是很大的Transformer模型,就是我们天天在研究的东西。ChatGPT出来后,我们之所以能迅速掌握并扩展我们的模型,例如开发了针对教育场景的“子曰”大模型,这一切都得益于我们对Transformer模型的深入理解和应用。
接着,关于RAG系统,它不仅仅是外部数据和LLM的简单叠加。鉴于用户文档的多样性,特别是PDF文件中复杂的图文混排,仅仅提取文本往往会带来信息的失真。例如,将具有逻辑连贯性的文本分割成多个片段,或者将图表数据错误地融入文本,这些都会严重影响信息的准确性。正因如此,我们长期致力于文档解析技术的研发,能够精确地识别和分析文档中的每一部分,无论是段落、图表、公式还是其他元素,确保将用户的查询以最适合机器处理的方式进行组织和检索。
借助有道翻译庞大的用户基础,我们得以在实际应用中不断完善和优化我们的系统。日均活跃用户数达百万级别的大数据反馈,为我们提供了宝贵的实践经验,使我们能够持续提升系统性能,满足用户对高质量翻译和问答服务的需求。
从文档问答到速读
有道速读(https://read.youdao.com) 是我们算法研究员从自己的需求出发做的产品。有道翻译桌面端虽然已经上线了文档问答,但是它主要是面向大众设计的,适合通用的文档。我们经常读论文,希望有一些论文相关的更个性一点的功能。而有道翻译用户量太大了,不方便随意改动。
我们做有道速读,一开始主要是面向论文阅读做的。这也是我们新技术的试验田,迭代快一点。我们看到了wordtune出了个段落摘要和对照的功能,用着特别爽,但是很贵,我们就把那个功能与RAG整合在一起,又能摘要读段落,又能问答,方便溯源。论文一般都会讲自己方法多好,我们就把其他人对这篇论文的评价信息也给整合起来了,做了论文口碑,把一篇论文的优势和局限更客观的展示出来。在内部做研发的过程中,有个研究人员希望能自动写综述,我们就在速读上加上了自动综述的功能,对每一篇论文,把前后引用的论文全部抓来,自动做问答,然后整理成报告。
有道速读可以看作是RAG在某个垂直领域的应用。因为里面的口碑、综述、文章解读等功能,都可以认为是先设置一个模版,有一堆问题(或者自动生成的),然后通过自问自答的方式,生成关键信息,最后再总结润色成文,这一切过程都是全自动的。
速读给了我们一个训练场,让我们调试应用新技术,这个过程也学到了很多,团队进步很大。当然,速读现在也不只局限于论文阅读了。
从速读到Qanything
速读主要是单篇问答(6月份刚上线时候只支持单篇,现在也支持多篇问答了,和QAnything主要区别是速读更偏重阅读的场景,QAnything偏重问答的场景,底层引擎是一样的),且只支持pdf的格式。QAnything是支持多文档问答的,不限文档格式。
做Qanything有个契机。去年7月份的时候,网易的IT集团想升级他们的客服系统,找到我们,问能否基于他们的IT文档做一个自动问答机器人,因为他们看到了我们的文档问答效果,觉得做的不错。于是我们就拿着他们的文档和历史的问答数据快速实验了一下,发现经过我们的系统后,70%的转人工的次数都可以被省下来,由AI来回答。
客服这个场景,用户的文档格式非常多样,回答问题需要综合各种文档的内容。于是我们在这个场景需求的推动下,做了多文档问答。我们给这个多文档问答系统取了一个大气的名字,叫Qanything,中文名字叫“万物皆可问”。
QAnything,也是我们的愿景。QAnything的前两个字母是Q和A,也是问答的意思,后面是anything,希望什么都可以放进去,什么东西都可以提问。
在去年8月份的时候,除了内部客户要,有道智云的外部B端客户也需要这样的多文档问答系统,还需要私有化。于是我们就做了大模型的小型化适配,做了私有化的版本,可以直接跑在游戏本上的。整个系统是完整的,可直接使用,也可以通过API调用。给了客户,卖了点钱。

(视频链接:https://www.bilibili.com/video/BV1FC411s7gQ/)
从QAanyhing到升学咨询
我们一直将qanything的体验页挂在网上,主要是为了做 有道智云 toB生意的时候给外部用户体验的,也没怎么宣传。去年9月份的时候,突然有一天,我们的精品课事业部(有道领世)的人找上门来,说希望合作QAnything。原来,他们不知道通过哪里的渠道知道了我们的QAnything,去体验了下,发现效果很好。比他们自己用langchain/lamma index+chatgpt 搭建了很久的系统,效果要好很多。
有道领世在高中升学领域深耕多年,积累了海量的升学数据资料,有几万份的文档,还有大量的数据存储在数据库里。我们的任务是通过QAnything,结合这样的积累的数据,打造出一个私人AI规划师,针对每个家长和学生,提供个性化、更加全面、专业、及时的升学规划服务。
一开始,我们把全部数据直接塞入我们QAnything系统,升学百科问答只有45%的准确率。经过一段时间的反复迭代优化,我们把确确率提升到了95%。目前系统可以解答用户关于高考政策、升学路径、学习生活以及职业规划等各种问题。未来随着不断地数据补充和更新,准确率会一直上涨。
有道AI升学规划师产品做出来后,我们都为它的体验感到惊艳。

(视频链接:https://www.bilibili.com/video/BV1Bt421b7am/)
Qanything 开源
今年1月份,我们整理了下我们的QAnything的代码和模型,将适合开源的部分开放出来了。我们做这事,希望能和社区一起,共同推动RAG技术应用的发展。最近这个月,社区给了我们很对反馈,也让我们受益良多。
QAnything架构解析
这次开源包括了模型和系统等所有必要的模块。模型方面包括ocr解析、embedding/rerank,以及大模型。系统方面包括向量数据库、mysql数据库、前端、后端等必要的模块。整个引擎的功能完整,用户可以直接下载,不需要再搭配其他的模块即可使用。系统可扩展性也非常好,只要硬盘内存足够,就可以一直建库,支持无上限的文档。
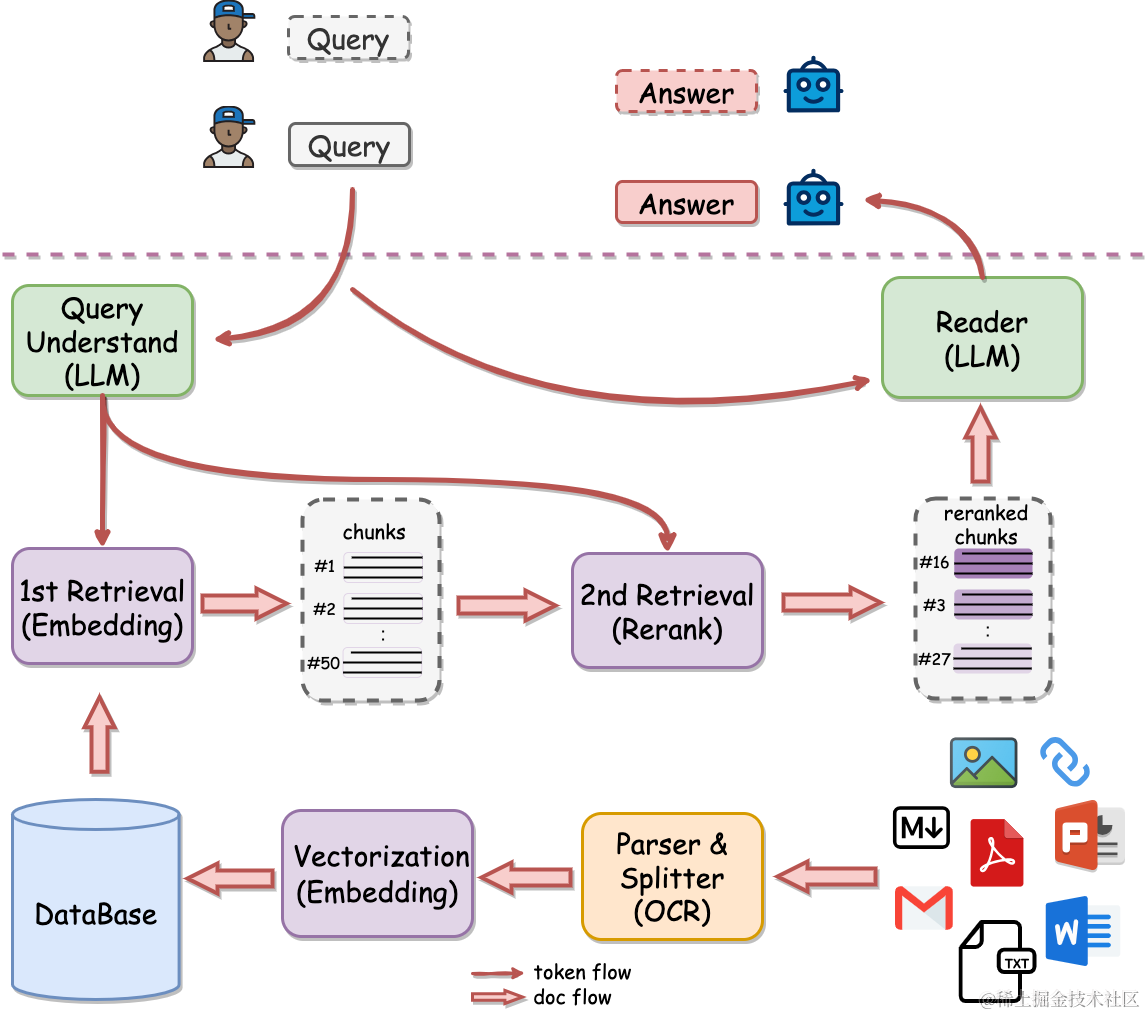
QAnything的整体架构图
系统的工作流程主要包含三个环节:
- 索引(indexing):文本索引的构建包括以下步骤:文档解析、文本分块、Embedding向量化和创建索引。先将不同格式的原始文件解析转换为纯文本,再把文本切分成较小的文本块。通过Embedding为每一个文本块生成一个向量表示,用于计算文本向量和问题向量之间的相似度。创建索引将原始文本块和Embedding向量以键值对的形式存储,以便将来进行快速和频繁的搜索。
- 检索(Retrieval):使用Embedding模型将用户输入问题转换为向量,计算问题的Embedding向量和语料库中文本块Embedding向量之间的相似度,选择相似度最高的前K个文档块作为当前问题的增强上下文信息。
- 生成(Generation):将检索得到的前K个文本块和用户问题一起送进大模型,让大模型基于给定的文本块来回答用户的问题。
Bcembedding模型
Embedding是RAG系统里面最关键的模块。为啥要自己训练embedding模型?一开始我们也是直接去尝试openai的ada embedding以及开源的embedding模型。但是我们很快发现,这样做有很大弊端。首先,在我们的业务场景下,外部的embedding效果并不如宣传的那么好。openai的embedding接口除了效果不好外,还很慢。我们后来自研了embedding,因为是放在自己服务器上,调用起来比openai接口快一百倍。其次,很多开源的embedding模型在mteb等地方刷傍刷的很高,但是那些刷榜的分值并不完全能反映真实的效果。第三,我们业务场景有很多混合语言的情况,比如库里面放的是英文的文档,用户用中文去问答。这种跨语种的能力,现有模型支持不好。第四,单纯的embedding在检索排序上天花板比较低,所以我们在embedding的基础上又做了rerank,共享同样的底座,head不一样。
为啥我们自己训练的模型会比openai的效果好?我们认为可能是通才和专才的区别。openai是通才,但是它的效果远未达到万能的地步,大家不必迷信。在我们的场景下(客服问答以及一些toB客户的场景),openai的ada2 embedding的检索准确率只有60%,而经过训练的bcembedding检索准确率可以达到95%。
我们自研的BCEmbedding,总的来讲有两个特色:
- 中英双语和跨语种能力
我们收集开源数据集(包括摘要、翻译、语义改写、问答等),来实现模型通用的基础语义表征能力。为了实现一个模型就可以实现中英双语、跨语种的检索任务,我们依赖网易有道多年积累的强大的翻译引擎,对数据进行处理,获得中英双语和跨语种数据集。实现一个模型就可以完成双语和跨语种任务。
- 多领域覆盖我们分析现有市面上常见或可能的应用场景,收集了包括:教育、医疗、法律、金融、百科、科研论文、客服(faq)、通用QA等场景的语料,使得模型可以覆盖尽可能多的应用场景。同样的依靠网易有道翻译引擎,获得多领域覆盖的中英双语和跨语种数据集。实现一个模型就可以支持多业务场景,用户可以开箱即用。
我们在训练的过程中,发现一个有意思的现象,数据标签的构建对模型的效果影响非常大。相信大家一定听过“难例挖掘”的概念,在机器学习中模型性能上不去时候,经常是因为一些例子比较难,模型训练时候见的比较少,多挖掘一些难例给模型,就能够提升模型的性能。但是在embedding训练的时候,我们发现难例挖掘反而会降低模型的性能。我们猜测原因是embedding模型本身的能力有限,不应该给过难的任务。我们想要让模型做多领域覆盖,多语种、跨语种覆盖(还要覆盖代码检索和工具检索),这已经给Embedding增加很多负担了,应该想想怎么给Embedding“减负”。
因为Embedding模型是dual-encoder,query和passage在“离线”地语义向量提取时没有信息交互,全靠模型将query和passages“硬”编码到语义空间中,再去语义检索。而rerank的阶段,cross-encoder可以充分交互query和passage信息,潜力大的多。所以我们定了目标,embedding尽可能提高召回,rerank尽可能提高精度。
我们在Embedding模型训练中,不使用难负样例挖掘,只在Reranker中使用。以下是我们的几点看法,供参考。
- 我们在训练Embedding模型时发现,过难的负样本对模型训练有损害,训练过程中会使模型“困惑”,影响模型最终性能[19]。Embedding模型算法本身性能上限有限,很多难负样本只有细微差异,“相似”程度很高。就像让一个小学生强行去学习微积分,这种数据对Embedding训练是“有毒”的。
- 在大量的语料库中,没有人工校验的自动化难负样例挖掘,难免会“挖到正例”。语料库很大,里面经常会混有正例,利用已有Embedding模型去挖掘正例,经常会挖到正例,毒害模型训练。应该有不少调参工程师有这种惨痛经历。
- 其实所谓的“正例”和“难负样例”应该是根据你业务的定义来的。RAG场景下,之前人们认为的难负样例可能就成为了正例。比如要回答“小明喜欢吃苹果吗?”,RAG场景下召回“小明喜欢吃苹果”和“小明不喜欢吃苹果”都是符合目标的,而学术定义的语义相似这两句话又是难负样例。
所以回归我们业务目标和好检索器的“评判标准”,Embedding模型应该能尽量召回相关片段,不要将精排Reranker要干的事强压在Embedding身上,“越俎代庖”终究会害了它。
检索排序效果评测方式LlamaIndex(https://github.com/run-llama/llama_index)是一个著名的大模型应用的开源框架,在RAG社区中很受欢迎。最近,LlamaIndex博客(https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)对市面上常用的embedding和reranker模型进行RAG流程的评测,吸引广泛关注。
为了公平起见,我们复刻LlamaIndex博客评测流程,将bce-embedding-base_v1和bce-reranker-base_v1与其他Embedding和Reranker模型进行对比分析。在此,我们先明确一些情况,LlamaIndex博客(https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)的评测只使用了llama v2(https://arxiv.org/abs/2307.09288)这一篇英文论文来进行评测的,所以该评测是在纯英文、限定语种(英文)、限定领域(人工智能)场景下进行的。
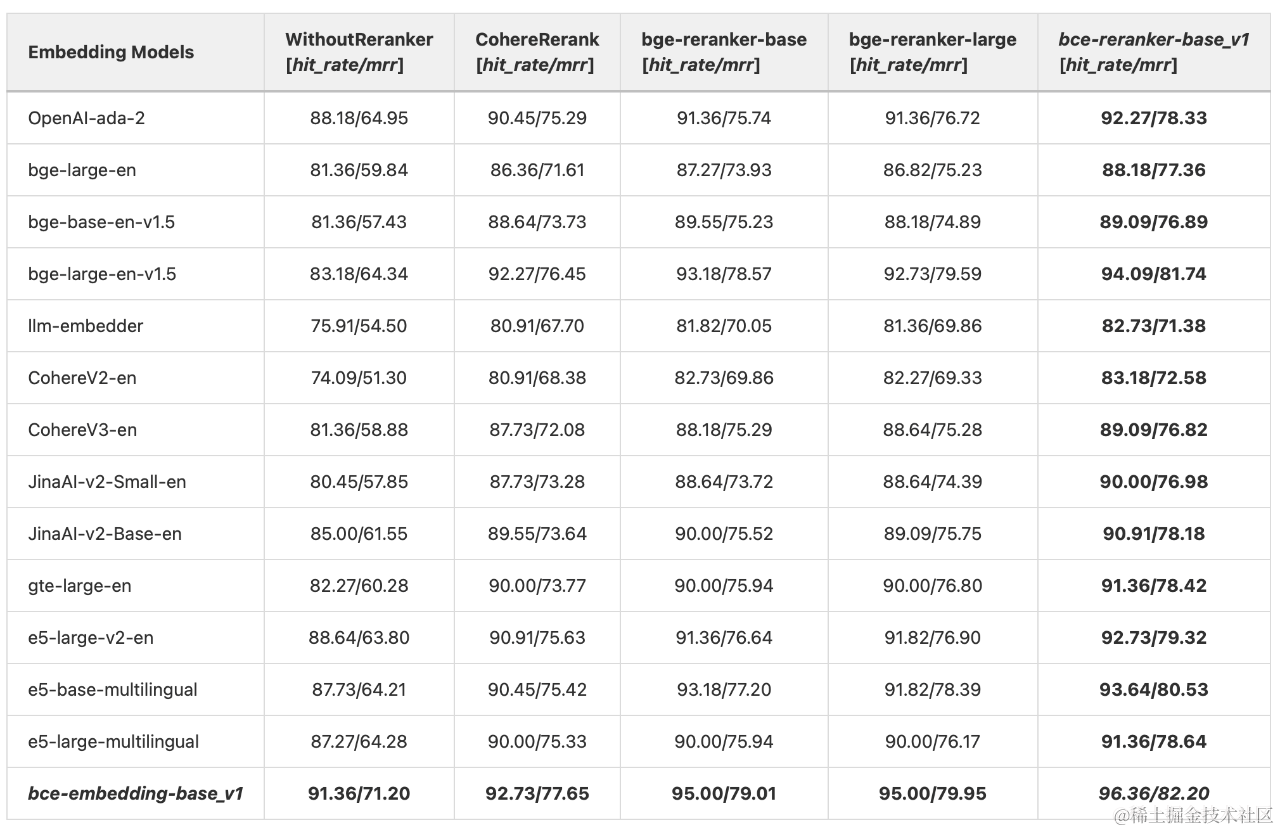
LlamaIndex博客评测复刻
如上表所示,
- 在没有Reranker模块的设置下,bce-embedding-base_v1显著优于其他常见的开源和闭源英文embedding模型。
- 在相同reranker配置下(竖排对比),bce-embedding-base_v1也都是优于其他开源、闭源embedding模型。
- 在相同的embedding配置下(横排对比),利用reranker模型可以显著提升检索效果,印证前面所述二阶段检索的优势。bce-reranker-base_v1比其他常见的开源、闭源reranker模型具备更好的精排能力。
- 综上,bce-embedding-base_v1和bce-reranker-base_v1的组合可以实现最好的效果。
多领域、多语种和跨语种RAG效果正如上所述的LlamaIndex博客(https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)评测有些局限,为了兼容更真实更广的用户使用场景,评测算法模型的 领域泛化性,双语和跨语种能力,我们按照该博客的方法构建了一个多领域(计算机科学,物理学,生物学,经济学,数学,量化金融等领域)的中英双语种和中英跨语种评测数据,CrosslingualMultiDomainsDataset(https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)。
为了使我们这个数据集质量尽可能高,我们采用OpenAI的 gpt-4-1106-preview用于数据生成。为了防止数据泄漏,评测用的英文数据我们选择了ArXiv上2023年12月30日最新的各领域英文文章;中文数据选择Semantic Scholar相应领域高质量的尽可能新的中文文章。
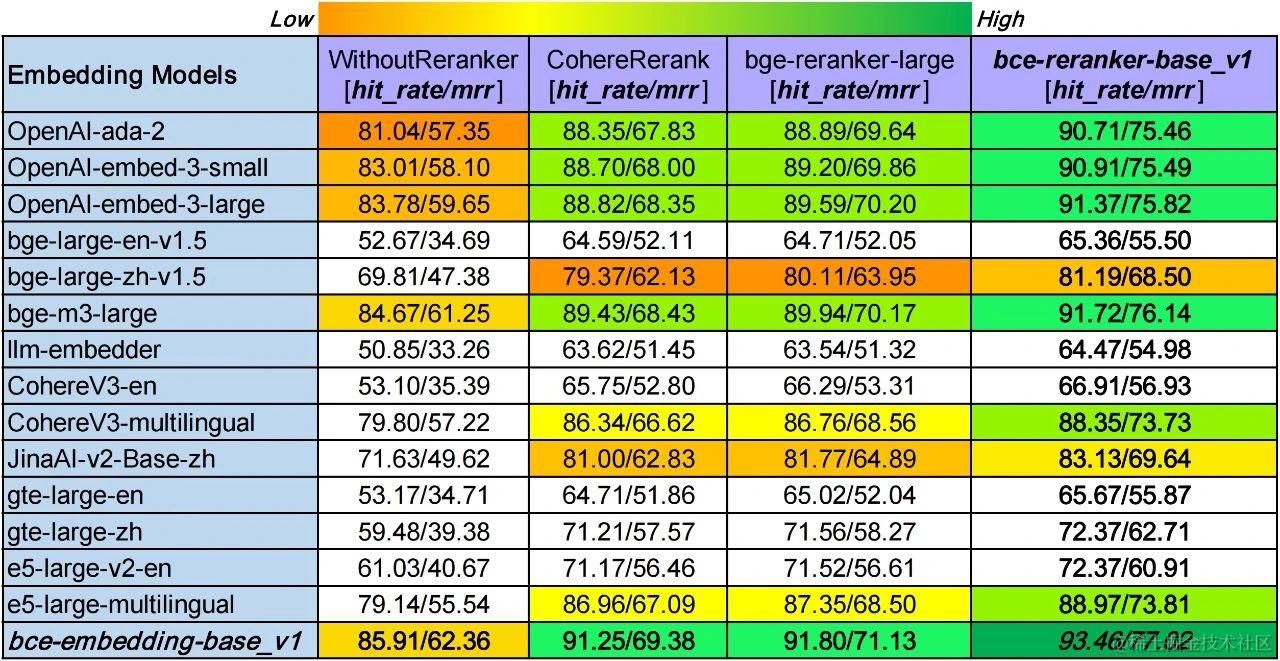 多领域、多语种和跨语种RAG评测
多领域、多语种和跨语种RAG评测
我们针对市面上最强的常用开源、闭源embedding和reranker模型,进行系统性评测分析,结果如上图所示。
-
竖排对比,bce-embedding-base_v1的表现和之前一样,具备很好的效果,语种支持和领域覆盖都很不错。最新的openai-embed-3和bge-m3表现出顽强的性能,具备良好的多语种和跨语种能力,具备良好的领域泛化性。Cohere和e5的多语种embedding模型同样表现出不错的效果。而其他单语种embedding模型表现却不尽如人意(JinaAI-v2-Base-zh和bge-large-zh-v1.5稍好一些)。
-
横排对比,reranker模块可以显著改善检索效果。其中CohereRerank和bge-reranker-large效果相当,bce-reranker-base_v1具备比前二者更好的精排能力。
-
综上,bce-embedding-base_v1和bce-reranker-base_v1的组合可以实现最好的检索效果(93.46/77.02),比其他开源闭源最好组合(bge-m3-large+bge-reranker-large, 89.94/70.17),hit rate提升3.53%,mrr提升6.85%。
Rerank的必要性
为啥需要rerank,上面数字可能还不直观。我们在开源的github上放了一张图,意思是QAnything在知识库的数据越多,准确率越高。而一般搭建的RAG,如果没有rerank这一环节,在数据输入多了以后,效果反而下降了。
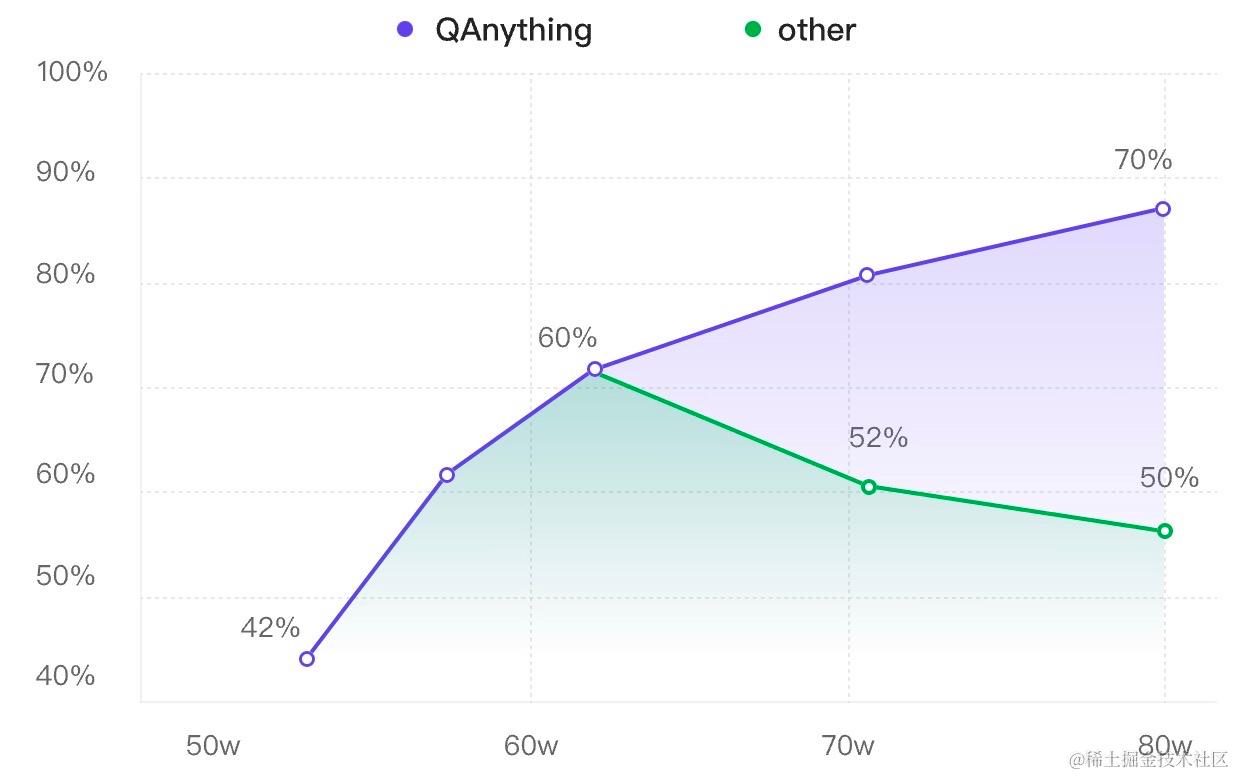
我们在做升学问答的时候,遇到一个有趣的现象:我们分批往RAG知识库中灌入数据,每加一批数据都做一次评测,观察随着数据量变大,问答效果的变化情况:
- baseline:第一批数据加入后问答正确率有42.6%,此时有一些问题没回答上来是因为确实缺少相关资料。我们继续加数据…
- 迎来上涨:第二批加了更多数据,覆盖知识范围更广。准确率提升到了60.2%,提升非常明显,看来加数据确实还是挺有用的。
- 坏消息:当加入第三批数据的时候,我们最担心的事情还是发生了。正确率急剧下降,跌了将近8个百分点。

不是所的RAG系统都能保证:数据越多,效果越好。随着数据的增多,数据之间可能会有相互干扰,导致检索退化的问题,影响问答的质量。
这个现象在最近的一篇论文:The Power of Noise: Redefining Retrieval for RAG Systems (arXiv:2401.14887v2)也有一些解释,对于RAG系统,如果喂给大模型的输入是相近容易混淆的话,对正确性的影响是最大的。
以我们遇到的一个case为例,大连医科大学怎么样?这个问题在v2版本(加入第三批数据前)是能回答对的,v3版本(加入第三批数据后)回答错了。看了一下送到LLM的文本片段,居然全部都是大连理工大学相关的信息。

主要原因是第三批加入的某些文档中恰好有 “大连理工大学xxx怎么样?” 的句子,和query “大连医科大学怎么样?” 表面上看起来确实非常像,Embedding给它打了比较高的分。
而类似大连医科大学师资介绍这样的片段相关性就稍微低了些。LLM输入token有限制,前面两个最相关但是实际并不能回答query问题的片段就已经占满了token的窗口,只能把他俩送进LLM里。结果可想而知,啥都不知道。
文本片段与query的相似性和文本片段是否包含query的答案(相关性)是两回事。RAG中一个非常重要的矛盾点在于检索召回的片段比较多,但是LLM输入token是有限制,所以必须把能回答query问题的片段(和问题最相关)给LLM。 Embedding 可以给出一个得分,但是这个得分描述的更多的是相似性。Embedding本质上是一个双编码器,两个文本在模型内部没有任何信息交互。只在最后计算两个向量的余弦相似度时才进行唯一一次交互。所以Embedding检索只能把最相似的文本片段给你,没有能力来判断候选文本和query之间的相关性。但是相似又不等于相关。
如下图所示,从某种程度上,Embedding其实就是在算两个文本块中相似字符的个数占比,它分不清query中的重点是大连医科大学,在它看来每个字符的重要性都是一样的。感兴趣的话可以计算一下下图中红字部分的占比,和最后余弦相似度的得分基本是吻合的。
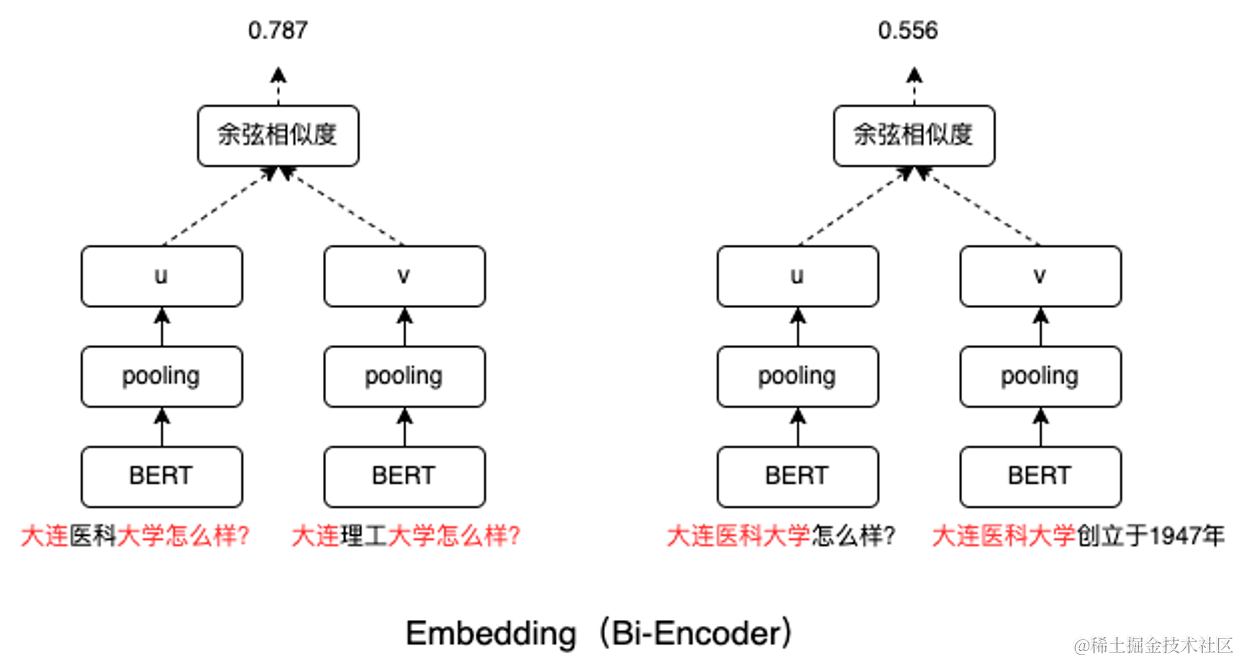
Rerank本质是一个Cross-Encoder的模型。Cross-Encoder能让两个文本片段一开始就在BERT模型各层中通过self-attention进行交互。它能够用self-attention判断出来这query中的重点在于大连医科大学,而不是怎么样?。所以,如下图所示,大连医科大学怎么样?这个query和大连医科大学创建于1947年…更相关。
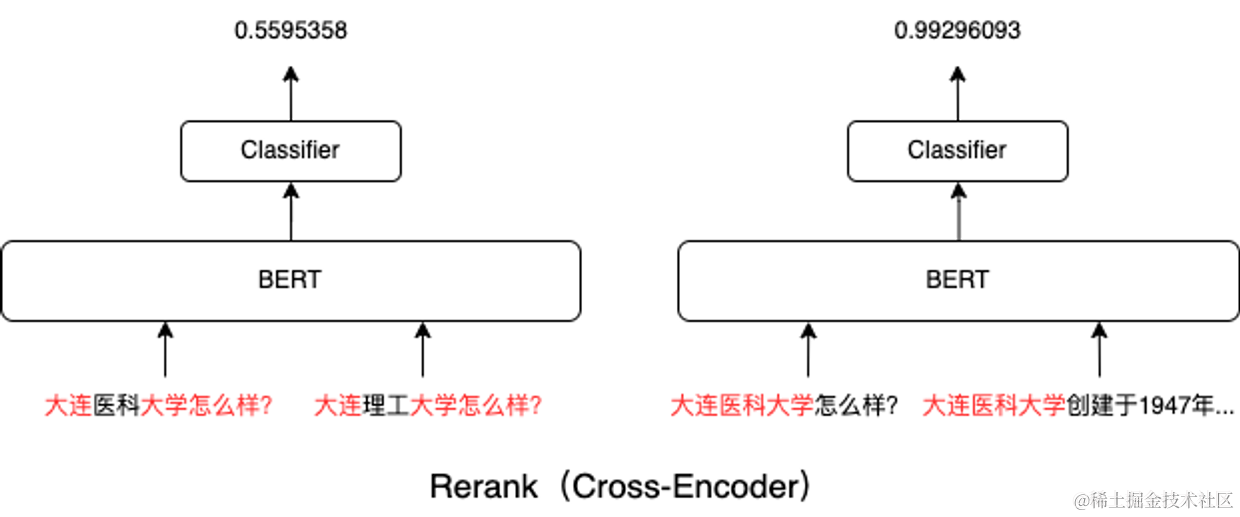
加上两阶段检索后,重新跑一下实验:
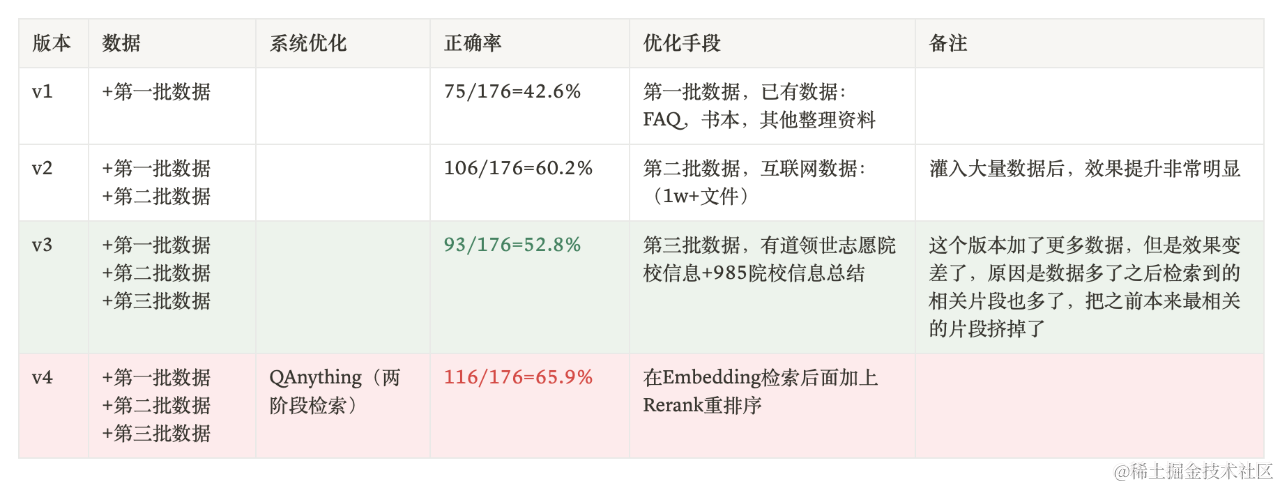
在数据不变的情况,两阶段检索问答准确率从52.8%提升到65.9%,这个结果再次证明了一阶段检索中存在数据互相干扰的情况。两阶段检索可以最大化的挖掘出数据的潜力,我们继续加数据,效果能够稳定提升。如下图所示,两阶段检索最大的意义不是在某一个实验上面提升了10个点。它最大的意义在于让“数据越多,效果越好”变成了现实。 在实际使用中,因为rerank比embedding慢得多,所以一般用两阶段检索。速度慢不是cross-encoder的模型比bi-encoder的模型速度慢。关键在于,bi-encoder可以离线计算海量文本块的向量化表示,把它们暂存在向量数据库中,在问答检索的时候只需要计算一个query的向量化表示就可以了。拿着query的向量表示去库里找最相似的文本即可。但是cross-encoder需要实时计算两个文本块的相关度,如果候选文本有几万条,每一条都需要和query一起送进BERT模型中算一遍,需要实时算几万次。这个成本是非常巨大的。所以,我们可以把检索过程分为两个阶段:召回(粗排)和重排:
- 第一个阶段的目标是尽可能多的召回相似的文本片段,这个阶段的文本得分排序不是特别靠谱,所以候选的topK可以设置大一些,比如topK=100;
- 第二个阶段的目标是对100个粗排的候选文本片段进行重新排序,用cross-encoder计算100个候选文本和query的相关度得分;
两阶段检索结合可以兼顾效果和效率。
LLM模型微调
我们的开源项目QAnything引入了一款7B参数规模的大型语言模型Qwen-7B-QAnything,该模型是在Qwen-7B基础上,通过使用我们团队精心构建的中英文高质量指令数据进行微调得到的。随着开源大型语言模型(LLM)基座模型的能力不断增强,我们通过在这些优秀的基座模型上进行后续训练,包括继续预训练、指令微调(SFT)和偏好对齐等工作,以更有效地满足RAG应用对大模型的特定需求,从而实现高性价比的模型优化。
为什么要微调?
RAG技术结合了知识检索与生成模型,通过从外部知识源检索信息,并将这些信息与用户问题整合成完整的Prompt输入到大模型中,以便根据这些参考信息回答问题。然而,当面对含有专业术语或通俗缩写的开放性问题时,直接使用开源Chat模型可能会导致模型回答不准确。 此外,为了最大化利用大模型的上下文窗口,RAG应用倾向于保留尽可能多的检索信息,这可能会使得模型的注意力分散,降低其遵循指令的能力,进而引发回答中的重复内容、关键信息丢失等问题。为了提高大模型在参考信息不足时的诚实度,加入与用户问题关联度低的负样本进行微调训练变得必要。
在选择基座模型时,我们寻找能够支持中英文、至少具备4K上下文窗口的模型,且能在单块GPU上部署,优先考虑7B以下参数规模的模型以便于未来在消费级硬件上部署。Qwen-7B,一个阿里云研发的70亿参数的通用大模型,以其在多个基准测试中的卓越表现成为我们的选择。该模型通过在超过2.4万亿tokens的数据上预训练,包含了丰富的中英文、多语言、编程、数学等领域数据,确保了广泛的覆盖面。考虑到7B参数规模的限制,我们在指令微调时采用了结构化指令模板,以增强模型在实际应用中的指令遵循能力。
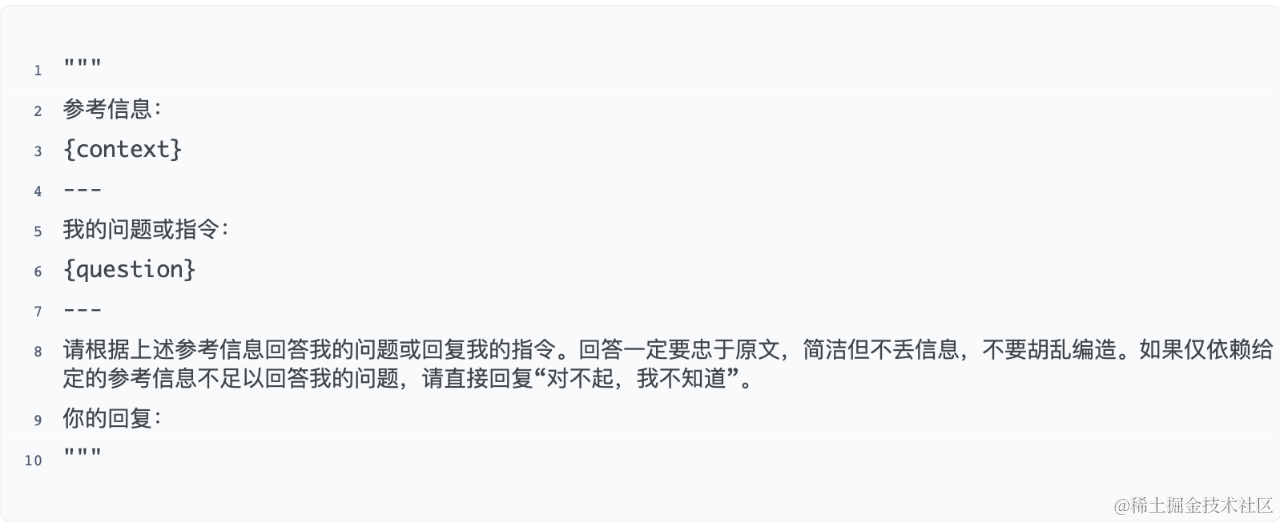
QAnything的prompt
如何微调?
-
指令微调数据构造我们为Qwen-7B-QAnything模型构造了丰富的指令微调数据集,涵盖了多种类型的数据,包括基于参考信息的结构化问答数据(单文档/多文档的事实问答、多文档的归纳总结/推理类问答、信息抽取)、多轮对话查询重写、段落摘要、开放域问答、中英文翻译以及跨学科问答等。
-
指令微调模型训练
尽管与大模型的预训练相比,指令微调成本较低,但在微调数据不完整或比例不平衡的初期探索阶段,采用全参数微调的代价依然较高。为了尽可能降低实验成本并快速验证微调效果,我们首先采用LoRA方法进行微调探索,待实验条件稳定后,再转向全参数微调。我们的LoRA微调配置如下:使用8张A40显卡的单机环境,初始学习率设为3e-5,每张卡的批量大小为2,采用16步的梯度累积,同时利用bfloat16精度训练以避免溢出并增强稳定性。此外,我们采用QLoRA + DeepSpeed Zero2 + FlashAttention配置以节约训练所需的显存。QLoRA通过4比特量化技术压缩预训练语言模型,使用NormalFloat4数据类型存储基模型权重,冻结基模型参数,并以低秩适配器(LoRA参数)形式添加少量可训练参数。在微调阶段,QLoRA将权重从NormalFloat4数据类型反量化为bfloat16进行前向和后向传播,仅更新bfloat16格式的LoRA参数权重梯度。与LoRA原论文不同,针对指令微调数据规模达到百万级别的情况,我们在所有线性层添加低秩适配器,并发现增加lora_rank和lora_alpha参数能显著提升微调效果。因此,我们为Qwen-7B模型微调采取了特定的LoRA参数配置,以实现最佳效果。

-
指令微调模型问答效果评估
我们参考了这篇文章:Benchmarking Large Language Models in Retrieval-Augmented Generation,使用开源 Benchmark 的事实型文档问答测试集,对微调过后的LLM做质量评估。中、英文测试集分别包含300条,Context Noise Ratio (0~0.8)表示LLM 输入Context中不相关噪声片段的比例。回答准确率指标结果说明:Qwen-7B-Chat (QwenLM 2023)表示论文中的结果,Qwen-7B-Chat表示使用开源Chat模型和结构化指令模版的结果,Qwen-7B-QAnything 表示QAnything开源项目微调模型的结果。模型评估时使用了top_p采样。结果表明 Qwen-7B-QAnything对检索外部知识源包含不相关信息的鲁棒性更好。
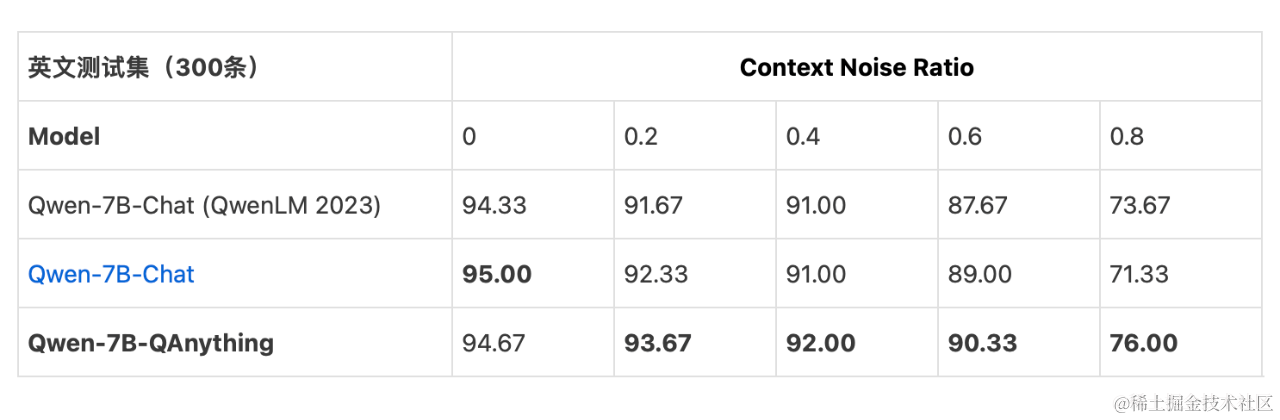
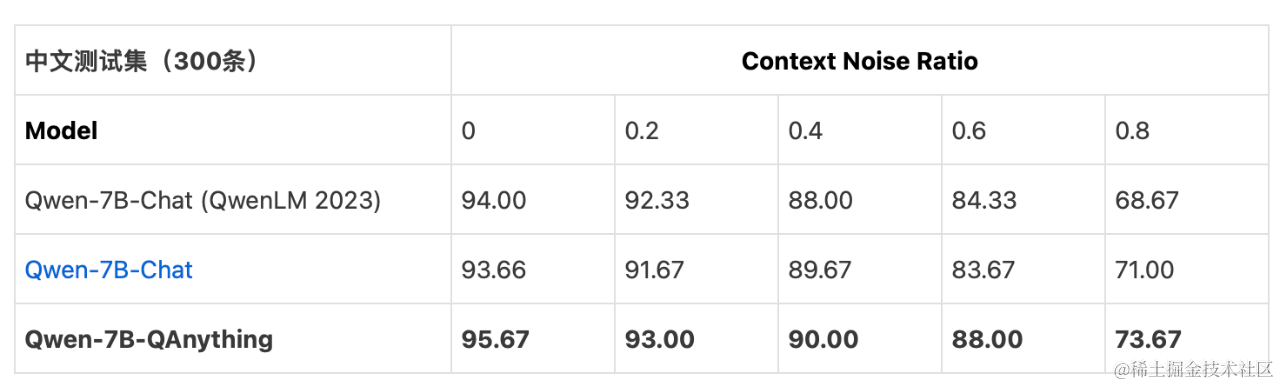
公开数据集的benchmark的评测结果
此外,团队内部针对业务场景构造700条问答对作为评测集,覆盖多种文档类型和问题,其中相关参考信息由BCE Embedding和Rerank模型检索重排序得到,参考答案由 GPT4 生成,结合人工修正得到。结合 Ragas 评测框架实现对 LLM 的自动化评测。评测指标采用 [answer_correctness],通过计算LLM回答内容 answer 和参考答案的 factual correctness 和 semantic similarity 加权和得到,其中 factual correctness(权重系数0.75)利用 GPT4 根据 answer 和参考答案生成TP/FN/FP表述计算得分,semantic similarity(权重系数0.25)利用 BCE Embedding 计算 answer 和参考答案的语义相似度。以下是评测结果及部分示例。

本地部署
QAnything开源项目为本地部署的大型语言模型(LLM)提供了三种推理框架后端选项:FasterTransformer、vLLM和Huggingface Transformers。这些选项满足了不同用户对于部署LLM的需求,实现了在高性能与通用性之间的平衡。
FasterTransformer (https://github.com/NVIDIA/FasterTransformer) 是由NVIDIA开源的一个高性能LLM推理框架,专为NVIDIA GPU优化。它的优点在于支持大型模型的INT8-Weight-Only推理,能在保持模型精度的同时减少推理延时和GPU显存使用,提高了在相同GPU配置下的多并发吞吐性能。FasterTransformer的模型权重转换与具体GPU型号无关,提供了一定的部署灵活性,但需要GPU具备一定的计算能力(FP16推理支持计算能力7.0及以上,INT8-Weight-Only支持7.5及以上)。此外,FasterTransformer作为Triton Inference Server的后端 (https://github.com/triton-inference-server/fastertransformer_backend) 实施LLM推理,支持Linux/Windows 11 WSL2部署。NVIDIA还基于FasterTransformer和TensorRT开发了新的推理框架TensorRT-LLM (https://github.com/NVIDIA/TensorRT-LLM),进一步提高了推理性能,但这也意味着与NVIDIA GPU的绑定更紧密,牺牲了一定的灵活性和通用性。
vLLM (https://github.com/vllm-project/vllm) 是由UC Berkeley LMSYS团队开发的另一款高性能LLM推理框架,其利用PagedAttention技术优化KV Cache管理,并结合并行采样和连续批处理请求调度管理,支持NVIDIA和AMD GPU,提高了系统吞吐性能。通过Huggingface Transformers训练的模型可以轻松部署为Python服务,展现出良好的系统灵活性。vLLM通过AWQ和GPTQ等算法支持INT4-Weight-Only推理,节省显存同时减少推理延时,但可能会轻微影响模型精度和生成质量。QAnything利用FastChat (https://github.com/lm-sys/FastChat)提供的接口使用vLLM后端,提供了兼容OpenAI API的调用接口,默认采用bfloat16推理,对GPU和算力有一定要求。
Huggingface Transformers (https://github.com/huggingface/transformers)是由Huggingface团队开发的一个通用性强、灵活性高的Transformer模型库,与PyTorch等深度学习框架配合,支持模型训练和Python服务部署。虽然在多数情况下,其推理性能可能不及FasterTransformer和vLLM,但它兼容不同算力等级的GPU。QAnything通过复用FastChat(https://github.com/lm-sys/FastChat)提供的接口使用Huggingface Transformers后端,实现了兼容OpenAI API的调用,采用load_in_8bit配置加载模型以节省显存,同时使用bfloat16进行推理。
关于开源
自从「QAnything」项目开放源代码以来,受到了开发社区的热烈欢迎和广泛认可。截至2024年2月29日,项目在GitHub上已经积累近5000个星标,这反映出了其流行度和用户对其价值的高度评价。
欢迎点击下面的链接下载试用:
QAnything github: https://github.com/netease-youdao/QAnything
QAnything gitee: https://gitee.com/netease-youdao/QAnything
欢迎大家在GitHub上为「QAnything」加星助力,方便收到新版本更新的通知!