文章目录
- 1、容器
- 2、Pod
- 3、工作负载
- 4、Deployment
- 5、StatefulSet
- 5、DaemonSet
- 6、Job
- 7、CronJob
1、容器
-
容器: 容器是容器镜像的运行态,通过基于标准的容器运行时运行,将应用程序从底层的主机设施中解耦。
-
容器镜像: 容器镜像是一个随时可以运行的软件包,包含运行应用程序所需的一切:代码和它需要的所有运行时、应用程序和系统库,以及一些基本设置的默认值。
-
容器环境: 在容器镜像的基础上,包括文件系统以及各种env变量、hostname、挂载的各种volume,共同组成了容器真正的运行环境。
-
容器运行时: 负责管理 Kubernetes 环境中容器的执行和生命周期,通过容器运行时接口(CRI)与Kubernetes交互。
-
容器生命周期中的回调: 需要运行时支持PostStart(异步)和PreStop(同步)回调。
-
容器更新和拉取: 建议使用容器标签或者摘要指定要更新的镜像名,并配合明确的拉取策略(IfNotPresent/Always),为了加速镜像拉取可以选择启用并行拉取以及预先拉取,同时需要通过凭据保护私有仓库的访问。
2、Pod
-
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
-
Pod 内的容器共享namespace(共享进程、网络、IPC和主机名)和文件系统卷。
-
Pod 中的容器可以在特权模式下运行,以使用原本无法访问的操作系统管理权能。
-
通常不需要直接创建 Pod,应该使用诸如 Deployment 这类工作负载资源来创建 Pod。
-
Pod的更新遵循“删除-重建”模式,Pod是一次性调度单元,重新调度、重启等都是基于删除旧的、新建新的策略;直接管理Pod时,能原地更新的只有[*].image、activeDeadlineSeconds 和tolerations,但使用工作负载时只要pod templates更新,都会重建pod。
-
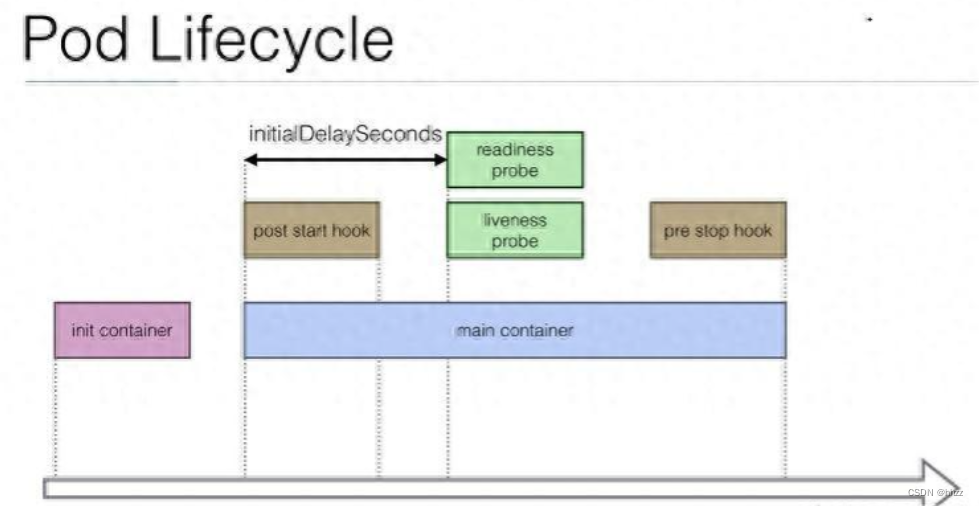
Pod生命周期
-
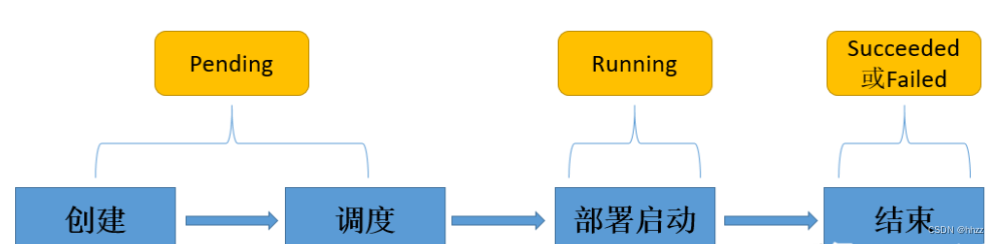
Pod有Pending、Running、Successded、Failed、Unknows五个状态,容器有Waiting、Running、Terminated状态;
-
Pod探测:StartupProbe(是否启动)、livenessProbe(是否存活)、ReadlinessProbe(是否Ready);
-
1.29版本加入Pod 就绪态的状态用于更细力度区分contaienrs ready和Pod ready;
-
Pod支持优雅停止,删除一个Pod时会先发Term信号,提示Pod内的服务开始排空请求,默认30s后,如果Pod还没终止,就发送KILL信号强制杀死Pod。
-
kubectl delete --force会触发强制删除。
-
init容器是一种在 Pod 内的应用容器启动之前运行的特殊容器,如果为一个 Pod 指定了多个 Init 容器,会在网络和数据卷初始化后按顺序逐个运行。
-
每个 Init 容器必须运行成功,下一个才能够运行,当所有的 Init 容器运行完成时, Kubernetes 才会为 Pod 初始化应用容器并像平常一样运行。
-
如果 Pod 重启,所有 Init 容器必须重新执行。因为 Init 容器可能会被重启、重试或者重新执行,所以 Init 容器的代码应该是幂等的。
-
Pod中某个资源request/limit的有效值=max(init容器某资源request/limit的最大值,应用容器某资源request/limit之和),调度和管理基于Pod有效资源值进行。
-
边车容器是一种特殊的常驻init容器,遵循init容器启动顺序,在创建Init 容器时将 restartPolicy 设置为 Always将变为边车容器,在整个 Pod 的生命周期中都处于活动状态,并且可以独立于主容器启动和停止,具有独立生命周期并支持探针来控制其生命周期。
-
临时容器可以在现有 Pod 中临时运行,以便完成用户发起的操作,例如故障排查。当由于容器崩溃或容器镜像不包含调试工具而导致 kubectl exec 无用时,临时容器对于交互式故障排查很有用。kubectl debug就是使用临时容器实现的,用于distroless镜像排查问题很有用,需要注意的是使用时需要共享进程命名空间。
-
当一个 Node 耗尽资源时,Kubernetes 将首先驱逐该 Node 上运行的 BestEffort Pod,然后是 Burstable Pod,最后是 Guaranteed Pod。Guaranteed Pod:Pod内部所有容器都有设置request和limit,且值一样;Burstable Pod:Pod内部至少有一个容器设置了资源request/limit;BestEffort Pod:Pod内部容器都没有设置资源request/limit。
-
故障预算(PDB)指定应用可以容忍的副本数量(相当于应该有多少副本),可以防止非预期的Pod终止情况。
在进行滚动升级时不受 PDB 的限制,更新期间的处理方式是在对应的工作负载资源的 spec 中配置的。
Pod终止状况(PodDisruptionConditions)指示Pod终止原因。 -
在 Kubernetes 中,有两种方法可以将 Pod 和容器字段暴露给运行中的容器:
- 作为环境变量,这个是最常用的
- 作为 downwardAPI 卷中的文件
这两种暴露 Pod 和容器字段的方式统称为 Downward API。通常使用现代的开发框架,如springboot,都可以自动识别很多Pod和容器信息,具体需要参考各个框架。应用最常用的是环境变量方案获取Podname或者IP,用于设置日志文件名称或者注册中心注册,这两个信息通常默认都有(HOSTNAME和XXX_SERVICE_HOST),不需要额外注入,其他信息需要根据需要选择注入。
3、工作负载
工作负载是在 Kubernetes 上运行的应用程序。

4、Deployment
Deployment 为 Pod 和 ReplicaSet提供声明式的更新能力,帮助用户自动化的管理Pod和服务,包括Pod更新、回滚、缩放等运维操作。
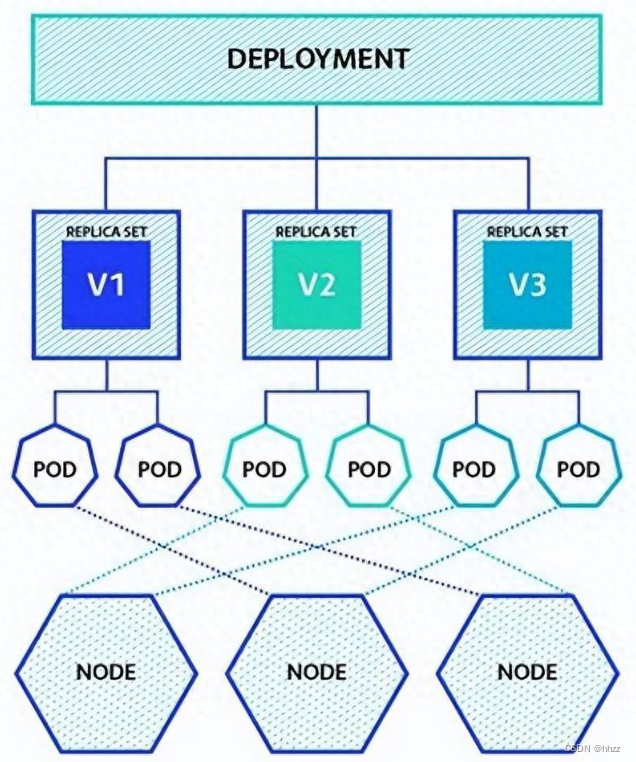
- Deployment每次更新会发起一个新的ReplicaSet,ReplicaSet部署对应Pod。
- 命名规则:Deployment的name由.metadata.name指定,ReplicaSet的name由.metadata.name-Pod-template-hash组成,Pod name查了代码发现是在ReplicaSet名称后面附加5个随机字符。
- 当 Deployment pod-template(即 .spec.template)发生改变时,例如模板的标签或容器镜像被更新,会触发Deployment 更新。pod-template-hash 标签自动添加到Deployment管理的每个 ReplicaSet 。
- 在 API 版本 apps/v1 中,Deployment 标签选择算符在创建后是不可变的,且.spec.selector 必须匹配(匹配不等于一样) .spec.template.metadata.labels,否则请求会被 API 拒绝。
- 当 Deployment 正在更新时又被更新,Deployment 会针对更新创建一个新的 ReplicaSet 并开始对其扩容,之前正在被扩容的 ReplicaSet 会被缩容,添加到旧 ReplicaSet 列表 并开始缩容。
- 如果 .spec.strategy.typeRecreate,在创建新 Pod 之前,所有现有的 Pod 会被杀死。若.spec.strategy.typeRollingUpdate时,采取滚动更新的方式更新 Pod。可以指定 maxUnavailable 和 maxSurge 来控制滚动更新过程,默认值都是25%。
- Deployment支持比例缩放,如果一个Deployment存在多个ReplicaSet在执行更新过程,那么缩放时按当前rs中的Pod数量等比例缩放,而不是一股脑都给最新的rs。
- Deployment更新前或者更新过程中,可以设置暂停更新,然后修改各种信息后,重新恢复执行,此时会自动应用最新修改后的更新。
- Deployment默认保持最新10次的ReplicaSet记录,这样可以支持回滚到最近10次修改,建议还是用git记录所有历史YAML的修改。
- Deployment状态有三种:Progressing、Complete、Failed。
- Deployment其实不支持金丝雀发布,需要额外或者更高级的控制Deployment实现金丝雀发布的能力。
5、StatefulSet

StatefulSet 是用来管理有状态应用的工作负载 API 对象,可以管理某 Pod 集合的部署和扩缩,并为这些 Pod 提供持久存储和持久标识符,包括:
- 稳定的、唯一的网络标识符
- 稳定的、持久的存储
- 有序的、优雅的部署和扩缩
- 有序的、自动的滚动更新
重点能力如下:
- 序号:对于具有 N 个副本的 StatefulSet,该 StatefulSet 中的每个 Pod 将被分配一个整数序号,该序号在此 StatefulSet 中是唯一的。默认情况下,这些 Pod 将被赋予从 0 到 N-1 的序号。
- 主机标识:StatefulSet 中的每个 Pod 根据 StatefulSet 的名称和 Pod 的序号派生出它的主机名,格式为 ( S t a t e f u l S e t 名称 ) − (StatefulSet 名称)- (StatefulSet名称)−(序号)。
- 网络标识:需要创建Headless服务以便为 Pod 提供网络标识,格式为 ( p o d n a m e ) . (podname). (podname).(servicename).$(namespace).svc.cluster.local。
- 持久存储:对于 StatefulSet 中定义的 VolumeClaimTemplate,每个 Pod 接收到一个 PersistentVolumeClaim。 当 Pod 或者 StatefulSet 被删除时,与 PersistentVolumeClaims 相关联的 PersistentVolume 并不会被删除,要删除它必须通过手动方式来完成。
- 部署的顺序性:对于包含 N 个副本的StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为 0…N-1。当删除 Pod 时,它们是逆序终止的,顺序为 N-1…0。在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。在一个 Pod 终止之前,所有的继任者必须完全关闭。
- 滚动更新:StatefulSet 控制器会删除和重建 StatefulSet 中的每个 Pod,按照与 Pod 终止相同的顺序(从最大序号到最小序号)进行,每次更新一个 Pod。
- 滚动更新的异常处置:如果更新后 Pod 模板配置进入无法运行或就绪的状态StatefulSet 将停止回滚并等待。恢复模板后,StatefulSet 继续等待损坏状态的 Pod 准备就绪(永远不会发生),此时必须删除 StatefulSet 尝试使用错误的配置来运行的 Pod, StatefulSet 才会开始使用被还原的模板来重新创建 Pod(已知问题kubernetes/issues/67250)。
- 来自 volumeClaimTemplate 的 PVC 默认策略是在 Pod 被删除时不受影响,依然保留。
5、DaemonSet
DaemonSet 与 Deployment 非常类似,但DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时,也会为他们新增一个 Pod,当有节点从集群移除时,这些 Pod 也会被回收,删除 DaemonSet 将会删除它创建的所有 Pod。
- DaemonSet 比较适合运维工具的部署,例如监控、日志采集等组件。
- DaemonSet 遵循 .spec.template.spec.nodeSelector 和 .spec.template.spec.affinity 限制,只在满足节点亲和性的节点上部署 Pod。 如果没有指定,则 DaemonSet Controller 将在所有节点上创建 Pod。
- 调度起评估符合条件的节点时,原本在 .spec.template.spec.affinity.nodeAffinity 字段上指定的节点亲和性将由 DaemonSet 控制器进行考虑,但在创建的 Pod 上会被替换为与符合条件的节点名称匹配的节点亲和性。
- DaemonSet 控制器会自动将一组容忍度添加到 DaemonSet Pod,以实现可以被调度到不健康或还不准备接受 Pod 的节点上,包括不健康、没Ready、不可达、不可调度以及资源使用原理的节点。
- DaemonSet 默认更新策略是滚动更新。
6、Job
Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。
- Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。
- 挂起 Job 的操作会删除 Job 的所有活跃 Pod(可能执行了部分),直到 Job 被再次恢复执行(重新调度新的Pod再次执行)。
- 删除 Job 的操作会清除所创建的全部 Pod。
- Job Spec中通常不设置Labels和Selctor,RestartPolicy 只能设置为 Never 或 OnFailure 之一。spec.completions 和 spec.parallelism代表完成数和并行数,默认都是1,可以根据任务需要的完成数和并行度分别设置。
- 容器失败:当Pod中的容器运行失败时,当RestartPolicy=OnFailure会重启容器,当RestartPolicy=Never不会重启容器,会直接将Pod状态修改为Failed。
- Pod失败:Job会重新调度一个新的Pod运行,所以程序需要处理幂等问题。
- Pod失败回退策略:.spec.backoffLimit 设置 Job 失败之前Pod的重试次数,默认6,回退重试时间将会按指数增长 (从 10 秒、20 秒到 40 秒)最多至 6 分钟。
- Pod失败次数统计方法:第一种是Pod状态为Failed,但对于RestartPolicy=OnFailure会重启容器的Pod,容器失败次数也会当做Pod失败次数。当失败次数超过.spec.backoffLimit 时会将Job状态设置为Failed。
- .spec.podFailurePolicy 字段支持配置 Pod 失效策略,该策略可以根据容器退出码和 Pod 状况来处理 Pod 失效。
- Job 完成时(不论成功或失败)不会再创建新的 Pod,不过已有的 Pod 通常也不会被删除。 保留这些 Pod 使得你可以查看已完成的 Pod 的日志输出,以便检查错误、警告或者其它诊断性输出。 Job 完成时 Job 对象也一样被保留下来,这样你就可以查看它的状态。 在查看了 Job 状态之后删除老的 Job 的操作留给了用户自己。
- 自动清理已完成 Job (状态为 Complete 或 Failed)的一种方式是使用由 TTL 控制器所提供的 TTL 机制。 通过设置 Job 的 .spec.ttlSecondsAfterFinished 字段,可以让该控制器清理掉已结束的资源。
- 可以为 Job 的 .spec.activeDeadlineSeconds 设置一个秒数值,该值适用于 Job 的整个生命期,无论 Job 创建了多少个 Pod,一旦 Job 运行时间达到 activeDeadlineSeconds 秒,其所有运行中的 Pod 都会被终止,并且 Job 的状态更新为 type: Failed 及 reason: DeadlineExceeded。
7、CronJob
CronJob 创建基于时隔重复调度的 Job。CronJob 用于执行排期操作,例如备份、生成报告等。 一个 CronJob 对象就像 Unix 系统上的 crontab(cron table)文件中的一行。 它用 Cron 格式进行编写,并周期性地在给定的调度时间执行 Job。
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周六)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
- CronJob 创建基于时隔重复调度的 Job,Job负责Pod生成和调度执行。
- CronJob 用于执行排期操作,例如备份、生成报告等。一个 CronJob 对象就像 Unix 系统上的 crontab(cron table)文件中的一行。 它用 Cron 格式进行编写[分 时 日 月 周],并周期性地在给定的调度时间执行 Job。
- CronJob支持时区设置,默认为本地时区。
- 修改CronJob只对后续创建的Job有效。
- 并发调度策略支持三种:{“Allow”:“允许并发”,“Forbid”:“不允许”,“Replace”:“调度覆盖”},默认Allow。
- 建议设置spec.startingDeadlineSeconds,表示统计错过调度次数的开始时间,默认从最后一次调度时间开始统计错过调度次数(超过100不再调度)。
- CronJob Spec中是jobTemplate,其他控制器都是template(代表Pod template),且Job和CronJob控制器都无需定义Labels和Selector,控制器自动添加并确保匹配。

人生真的不在于起点,而在于持续性。