文章目录
- 1 词法分析
- 2 语法分析
- 3 遍历语法分析树
- 3.1 Listener
- 3.2 Visitor
- 4 总结
1 词法分析
词法分析就是对给定的字符串进行分割,提取出其中的单词。
在antlr4中,词法规则的名称的首字母需要大写,右侧必须是终结符,通常将词法规则的名称全部大写。
例如,要匹配C语言中的变量名,就需要知道C语言中的变量名的规范:
- 变量只能由字母、数字、下划线组成
- 变量名的第一个字符必须是字母或者下划线,不能是数字
于是,变量名的词法规则就可以是:
VARNAME: [a-zA-Z_]+[a-zA-Z_0-9]*;
antlr4提供关键字fragment用于定义词法片段,可以把比较常用的正则表达式的一部分定义为片段进行复用,它本身并不会生成任何标记,但是能够提高可读性。
fragment DIGIT : [0-9]
fragment ALPHABET: [a-zA-Z]
UNDERLINE: '_';
VARNAME: (ALPHABET|UNDERLINE)+(ALPHABET|UNDERLINE|DIGIT)*
首先分别定义字母和数字的fragment,然后定义下划线的词法规则,再结合字母、数字、下划线定义变量名的词法规则。
2 语法分析
词法分析得到单词流后,就可以通过语法分析生成语法分析树。
语法规则的民成的首字母需要小写,以区分词法规则,通常将语法规则的名称全部小写。
例如,要匹配一个赋值表达式,就需要知道赋值表达式由哪些部分构成。
赋值表达式通常由四部分构成:
- 等号左侧,左侧通常是变量名,但是也可能在定义变量时进行初始化,不过也可能赋值给指针
- 等号
- 等号右侧,右侧可能是常量,也可能是函数调用
- 表达式结尾的分号
这里为了简化处理,只实现以下的赋值语句:
- 等号左侧只是变量名
- 等号右侧只有整数常量
语法规则就是:
ASSIGN: '=';
SEMI: ';';
NUMBER: DIGIT+;
assign_expr: VARNAME ASSIGN NUMBER SEMI;
3 遍历语法分析树
在编写antlr4的语法规则文件时,可以在其中加入特定语言的动作,例如,需要在访问到某个规则的时候输出得到的字符串,就可以直接将该逻辑写在语法规则文件中,但是这种方式会使得语法规则文件和解析程序耦合,不同语言需要不同的节点访问逻辑,因此,编写完成语法规则文件后,通常生成对应语言的解析程序。利用该解析程序可以实现对语法分析树的遍历。
下一步就是对语法分析树进行遍历,为了方便对,antlr4提供了两种遍历语法分析树的模式:
- Listener
- Visitor
在使用antlr4工具生成对应语言的程序时,可以通过-listener和-visitor选项生成对应的遍历语法分析树的代码,-listener是默认选项,也就是默认得到Listener类型的遍历器。
在说明Listener和Visitor之前需要了解下语法分析树的结构和相关类型,以下的{GrammarName}表示语法名称,也就是grammar语句中的名称,{RuleName}表示语法文件中的规则名称,也就是冒号前面的单词。
antlr4为我们生成的解析器{GrammarName}Parser继承自antlr4.Parser,{GrammarName}Parser中会对每条规则定义一个类,类继承自antlr4.ParserRuleContext,例如,如果规则名是expr,就会创建一个类:class ExprContext(ParserRuleContext),同时对每条规则也会创建一个对应的方法,用于返回对应的类对象,例如,如果规则名是expr,那么方法就是def expr(self),该方法会返回ExprContext的对象。在创建{GrammarName}Parser对象时需要传递antlr4.TokenStream作为参数,antlr4.TokenStream可以理解为词法分析的单词流,解析器就是对单词流进行分析。
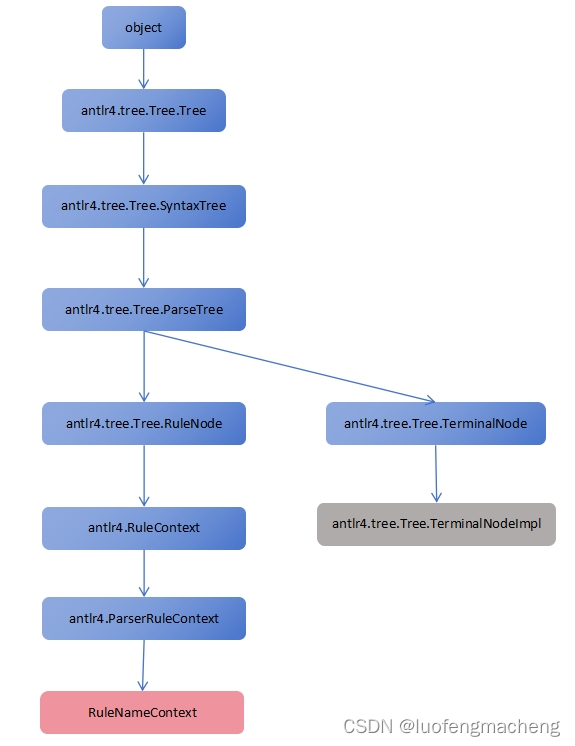
在创建{GrammarName}Parser解析器对象后,就可以通过第一条规则的规则名作为方法名得到语法分析树的根节点,接下来就可以通过Listener或者Visitor机制遍历该语法分析树。语法分析树的每个节点对应一条规则,都是继承自antlr4.ParserRuleContext的对象,而叶子节点则是词法分析的单词,类型是TerminalNodeImpl。
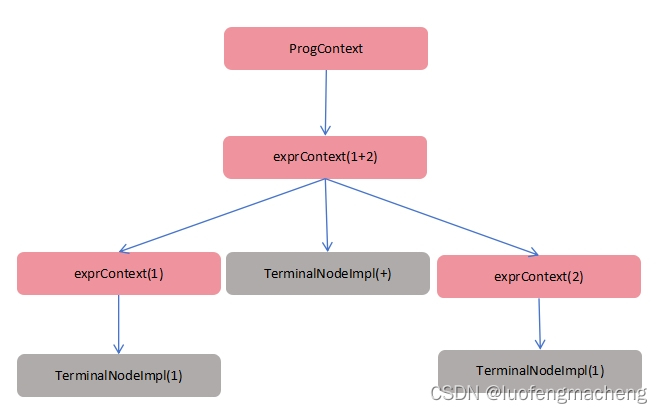
因此,在实际的开发者解析语法分析树的主函数代码通常是:
# 使用输入的字符串创建输入流,然后将输入流给到词法分析器
# 使用词法分析器就得到TokenStream对象
input_stream = InputStream("10+1+1+2\n")
lexer = exprLexer(input_stream)
token_stream = CommonTokenStream(lexer)
# 使用TokenStream对象创建antlr4为我们生成的解析器对象
parser = exprParser(token_stream)
# prog就是g4语法规则文件的第一条规则
# 因此,调用解析器的prog方法得到语法分析树的根节点
# 在其他程序中也需要使用第一条规则的规则名进行调用
tree = parser.prog()
# 此处使用Listenser的方式遍历得到的语法分析树
listener = Listener()
walker = ParseTreeWalker()
walker.walk(listener, tree)
3.1 Listener
Listener的基本思想是给树的节点定义回调函数,当访问语法分析树时自动调用定义的回调函数,实现树的自动访问。
在使用antlr4工具生成对应语言的程序时,会默认生成{GrammarName}Listener.py的代码文件(这里以python为例)。
在{GrammarName}Listener.py的文件中会生成一个继承自antlr4.tree.Tree.ParseTreeListener的{GrammarName}Listener类,该类中会每条规则定义了两个方法:
- enter{RuleName}()方法:例如,规则名为expr,则方法名为enterExpr,参数为
{GrammarName}Parser.ExprContext - exit{RuleName}()方法:例如,规则名为expr,则方法名为exitExpr,参数为
{GrammarName}Parser.ExprContext
看方法名可以知道,enterExpr()就是在访问到expr这个规则的子树时调用的方法,函数的参数就是子树的树根,exitExpr()就是在访问完expr这个子树时调用的方法,函数的参数就是子树的树根。
一般情况下,开发者不会去修改antlr4生成的Listener文件,而是重新继承{GrammarName}Listener,然后在其中重写enter/exit方法。
在enter/exit方法中,参数是当前遍历的节点,因此,可以使用继承自antlr4.ParserRuleContext的方法访问当前节点的属性和数据:
- getChild(i):获取第i个子节点
- getChildren():获取所有孩子节点
- getChildCount():获取孩子节点的个数
- getText():获取节点的字符串,通常只会在叶子节点才会调用,中间节点调用得到的就是本条规则匹配的字符串
- getParent():获取父节点,只有叶子节点才能调用
- depth():获取当前节点在树中的深度
由于参数是当前节点,并且没有返回值,无法将当前节点的处理后得到的数据往上传递,因此,如果在遍历语法分析树时需要进行数据的传递,需要使用额外的数据结构,例如第一篇文章中的计算器程序,在得到当前节点计算的值后将数据保存到字典中,在处理上层节点时再从字典中读取。
对于Listener,需要使用antlr4.tree.Tree.ParseTreeWalker进行遍历,首先创建一个ParseTreeWalker的对象,然后调用对象的walk()函数遍历,函数的参数是ParseTreeListener和ParseTree,在每个节点类型的ParserRuleContext的派生类{RuleName}Context中,都会有定义两个函数enterRule和exitRule,在调用walk()时其实就会用深度优先遍历的方式遍历每个节点,然后在开始遍历孩子节点前执行enterRule,在遍历完成孩子节点后执行exitRule:
class ParseTreeWalker(object):
DEFAULT = None
def walk(self, listener:ParseTreeListener, t:ParseTree):
"""
对树执行深度优先遍历,
在遍历当前节点的孩子节点之前,先判断当前节点是否是叶子节点,这里分为错误节点和正确的叶子节点,
分别调用listener的visitErrorNode和visitTerminal,因此,可以在我们自己的Listener中
增加visitErrorNode和visitTerminal,用于处理叶子节点
在遍历孩子节点之前,先执行enterRule,在遍历完所有孩子节点后执行exitRule
"""
if isinstance(t, ErrorNode):
listener.visitErrorNode(t)
return
elif isinstance(t, TerminalNode):
listener.visitTerminal(t)
return
self.enterRule(listener, t)
for child in t.getChildren():
self.walk(listener, child)
self.exitRule(listener, t)
def enterRule(self, listener:ParseTreeListener, r:RuleNode):
"""
执行当前节点的enterRule
"""
ctx = r.getRuleContext()
listener.enterEveryRule(ctx)
ctx.enterRule(listener)
def exitRule(self, listener:ParseTreeListener, r:RuleNode):
"""
执行当前节点的exitRule
"""
ctx = r.getRuleContext()
ctx.exitRule(listener)
listener.exitEveryRule(ctx)
可以看到,使用这种方式的好处是,开发者只需要编写遍历节点的回调函数,即可自动实现树的遍历,但是没办法控制遍历过程以及实现值的传递。
3.2 Visitor
将g4文件使用命令antlr4 -Dlanguage=Python3 -visitor -no-listener expr.g4就可以得到只有Visitor的代码,生成的代码与Listener的区别就是有一个exprVisitor.py的文件。
exprVisitor.py中是默认生成的vistor:exprVisitor,exprVisitor继承自antlr4.tree.Tree.ParseTreeVisitor。exprVisitor中对于每条规则会生成一个visitor{RuleName}()方法,参数还是{RuleName}Context。
与Listener有所不同,Visitor模式下{RuleName}Context中没有定义enter/exit方法,而是定义了accept(ParseTreeVisitor)方法:
def accept(self, visitor:ParseTreeVisitor):
if hasattr( visitor, "visitProg" ):
return visitor.visitProg(self)
else:
return visitor.visitChildren(self)
在accept(ParseTreeVisitor)中,如果ParseTreeVisitor中有visit{RuleName}方法,就会调用visit{RuleName},否则,就会访问孩子节点。
class ParseTreeVisitor(object):
# 提供给外部调用的函数
# 参数就是树的根节点
def visit(self, tree):
# 调用的就是节点的accept()函数
return tree.accept(self)
# 访问孩子节点
def visitChildren(self, node):
result = self.defaultResult()
n = node.getChildCount()
for i in range(n):
if not self.shouldVisitNextChild(node, result):
return result
c = node.getChild(i)
childResult = c.accept(self)
result = self.aggregateResult(result, childResult)
return result
def visitTerminal(self, node):
return self.defaultResult()
def visitErrorNode(self, node):
return self.defaultResult()
def defaultResult(self):
return None
def aggregateResult(self, aggregate, nextResult):
return nextResult
def shouldVisitNextChild(self, node, currentResult):
return True
开发者需要基于exprVisitor创建自己的Visitor,重写里面的visitor{RuleName}()方法,在主逻辑中就可以调用Visitor.visit()访问语法分析树:
# 使用输入的字符串创建输入流,然后将输入流给到词法分析器
# 使用词法分析器就得到TokenStream对象
input_stream = InputStream("10+1+1+2\n")
lexer = exprLexer(input_stream)
token_stream = CommonTokenStream(lexer)
# 使用TokenStream对象创建antlr4为我们生成的解析器对象
parser = exprParser(token_stream)
# prog就是g4语法规则文件的第一条规则
# 因此,调用解析器的prog方法得到语法分析树的根节点
# 在其他程序中也需要使用第一条规则的规则名进行调用
tree = parser.prog()
# 创建Visitor,并调用visit访问tree
visitor = Visitor()
print(visitor.visit(tree))
下面是一个简易的计算器程序的Visitor,visitExpr就是访问表达式,如果这个表达式只有一个孩子节点,说明它的孩子节点应该是个叶子节点,也就是经过词法分析匹配得到的操作数,则直接返回该操作数即可,如果这个表达式有3个节点,说明当前子树是个需要计算的表达式,访问第1个孩子,获取操作符左边的值,访问第3个孩子,获取操作符右边的值,然后根据第2个孩子的值进行对应的计算并返回。最后,在主逻辑中打印visitor.visit(tree)就可以得到表达式最终的结果。
class Visitor(exprVisitor):
def visitProg(self, ctx:exprParser.ProgContext):
if ctx.getChildCount() == 2:
return self.visit(ctx.getChild(0))
return self.visitChildren(ctx)
def visitExpr(self, ctx:exprParser.ExprContext):
if ctx.getChildCount() == 1:
return ctx.getChild(0).getText()
elif ctx.getChildCount() == 3:
left = self.visit(ctx.getChild(0))
right = self.visit(ctx.getChild(2))
if ctx.getChild(1).getText() == "+":
return int(left) + int(right)
elif ctx.getChild(1).getText() == "-":
return int(left) - int(right)
elif ctx.getChild(1).getText() == "*":
return int(left) * int(right)
elif ctx.getChild(1).getText() == "/":
return int(left) / int(right)
return self.visitChildren(ctx)
可以看到跟Listener的区别在于,使用Visitor的方式可以自己控制是否访问子树,并且可以得到子树的值。
4 总结
- 定义好词法和语法规则,就可以对提供的输入串进行词法分析和语法分析,得到语法分析树
- 语法分析树的非叶子节点的类型是
{RuleName}Context,叶子节点的类型为TerminalNodeImpl,然后使用解析器的第一条规则名作为函数得到树的根节点 - antlr4提供了Listener和Visitor两种机制遍历语法分析树
- Listener中生成的
{RuleName}Context中会增加enterRule()和exitRule()方法,它们分别调用listener中定义的enter{RuleName}和exit{RuleName}方法,ParseTreeWalker.walk(ParseTreeListener, ParseTree)使用深度优先搜索遍历树的根节点,在遍历当前节点的孩子节点之前会调用当前节点的enterRule()方法,在遍历完当前节点的孩子节点后会调用当前节点的exitRule()方法,从而来调用listener中定义的enter{RuleName}和exit{RuleName}方法。这种方式适合不需要传递值的场景,例如,语法检查 - Visitor中生成的
{RuleName}Context中会增加accept(ParseTreeVisitor),在使用ParseTreeVisitor.visit(ParseTree)遍历语法分析树时,就会访问根节点的accept方法,从而访问Visitor中的visit{RuleName}方法,开发人员在重写visit{RuleName}方法时可以使用visit方法得到子树的值,这种方式适合需要在子树和父节点传递值的场景