1. 提出PointPillar的目的
在此之前对于不规则的稀疏的点云的做法普遍分为两派:
一是把点云数据量化到一个个Voxel里,常见的有VoxelNet和SECOND , 但是这种做法比较普遍的问题是由于voxel大部分是空集所以会浪费算力(SECOND利用稀疏卷积解决了它) ,但是二者都还存在高度的信息所以还需要计算三维卷积的。
一是从俯视角度将点云的数据进行处理,将高度信息通过一系列手段去除从而获得一种类似Pseudo image的方式从而去用一些经典的图像网络去处理一些任务比如,MV3D和AVOD。
本文也有点类似上面的思想二,有以下几个明显的亮点:
- 是一种结合了点试图思想(忽略非空区域)以及俯视图(量化2D平面而得到伪图片)的点云融合感知算法
- 将三维点云处理为二维伪图像,用传统CNN对伪图像进行特征提取,推理速度显著提升,是其他方法(含3维卷积)的2-4倍。
2. PointPillar网络结构
整个算法逻辑包含3个部分:数据预处理,神经网络,后处理。其中神经网络部分,原论文将其结构描述为3个部分:
PFN(Pillar Feature Net):将输入的点云转换为稀疏的伪图像的特征形式。
Backbone(2D CNN):使用 2D 的 CNN 处理伪图像特征得到高维度的特征。
Detection Head(SSD):检测和回归 3D 边界框。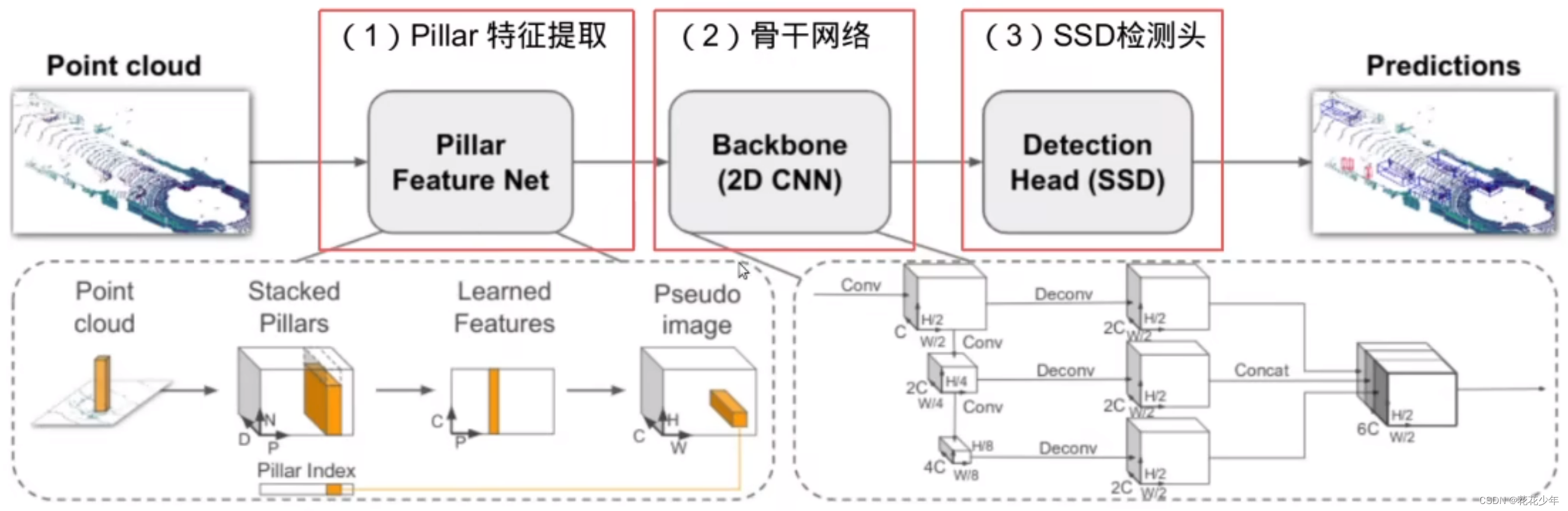
在实际部署的时候,结构拆分和论文中的稍微有些出入。主要是分成PFN(Pillar Feature Network),MFN和RPN。其中MFN是用来将PFN提取的Pillar级的点云深度特征进一步转化为伪点云图像。RPN就是Backbone,而检测头的部分功能被包含在后处理的逻辑里面。
2.1. PFN(Pillar Feature Network)模块
因为不同点云帧的点云数量是变化的,非空Pillar的数量自然也是不同的,在考虑将PFN导出为ONNX模型时,需要采用dynamic shape。
从PFN的8个输入可知,num_points表示每个Pillar包含的实际点云数量,这个轴是dynamic的。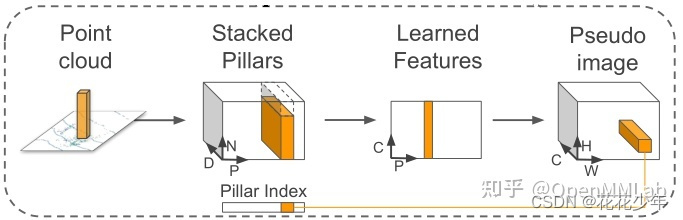
- 首先将一个样本的点云空间划分成(在 X 轴方向上点云空间的范围/pillar size,在 Y 轴方向上点云空间的范围/pillar size)pillar 网格,样本中的点根据会被包含在各个 pillar 中,没有点的 pillar 则视为空 pillar。
- 假设样本中包含的非空 pillar 数量为 P,同时限制每个 pillar 中的点的最大数量为 N,如果一个 pillar 中点的数量不及 N,则用 0 补全,若超过 N,则从 pillar 内的点中采样出 N 个点来。并对 pillar 中的每个点进行编码,其中每个点的表示会包括点的坐标,反射强度,pillar 的几何中心,点与 pillar 几何中心的相对位置,将每个点的表示的长度记为 D。这样我们的一个点云样本就可以用一个(P,N,D)的张量来表示。
- 得到点云的 pillar 表示的张量后,我们对其进行处理提取特征,通过使用简化版的 PointNet 中的 SA 模块来处理每个 pillar。即先对每个 pillar 中的点使用多层 MLP 来使得每个点的维度从 D 变成 C,这样张量变成了(P,N,C),然后对每个 pillar 中的点使用 Max Pooling,得到每个 pillar 的特征向量,也使得张量中的 N 的维度消失,得到了(P,C)维度的特征图。
- 最后将(P,C)的特征根据 pillar 的位置展开成伪图像特征,将 P 展开为(H,W)。这样我们就获得了类似图像的(C,H,W)形式的特征表示。
总结:shape变化,(P,N,D)->(P,N,C)->(P,C)->(C,H,W)
2.2. PFN的输入
PFN有8个输入:
pillar_x:包含Pillar化后的点云x坐标,shape为(1,1,P,100);
pillar_y:包含Pillar化后的点云y坐标,shape为(1,1,P,100);
pillar_z:包含Pillar化后的点云z坐标,shape为(1,1,P,100);
pillar_i:包含Pillar化后的点云强度值,shape为(1,1,P,100);
num_points:保存每个Pillar包含的实际点云数量,shape为(1,P);
x_sub_shaped:保存Pillar的中心x坐标,shape为(1,1,P,100);
y_sub_shaped:保存Pillar的中心y坐标,shape为(1,1,P,100);
mask:pillar点云掩码,shape为(1,1,P,100);
2.3. PFN的输出
PFN的输出shape为(1,64,pillar_num,1),pillar_num表示非空pillar的数量,是dynamic shape。因为不同点云帧的点云数量是变化的,非空Pillar的数量自然也是不同的。
参考文献
点云深度学习-PointPillar_哔哩哔哩_bilibili
点云检测算法之PointPillar深度解读-CSDN博客
PointPillars: Fast Encoders for Object Detection from Point Clouds