参考链接
【1】https://xiaolincoding.com/mysql/index/index_interview.html#%E6%8C%89%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%88%86%E7%B1%BB
【2】https://www.toutiao.com/article/7095749260137726476/?wid=1709192807222
【3】https://zhuanlan.zhihu.com/p/401198674
【4】https://docs.pingcode.com/ask/39637.html
【5】https://blog.csdn.net/luxiaoruo/article/details/106637231
按照四个角度来分类索引。
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
要知道什么是回表、索引覆盖、索引下推,首先大概理解B+树
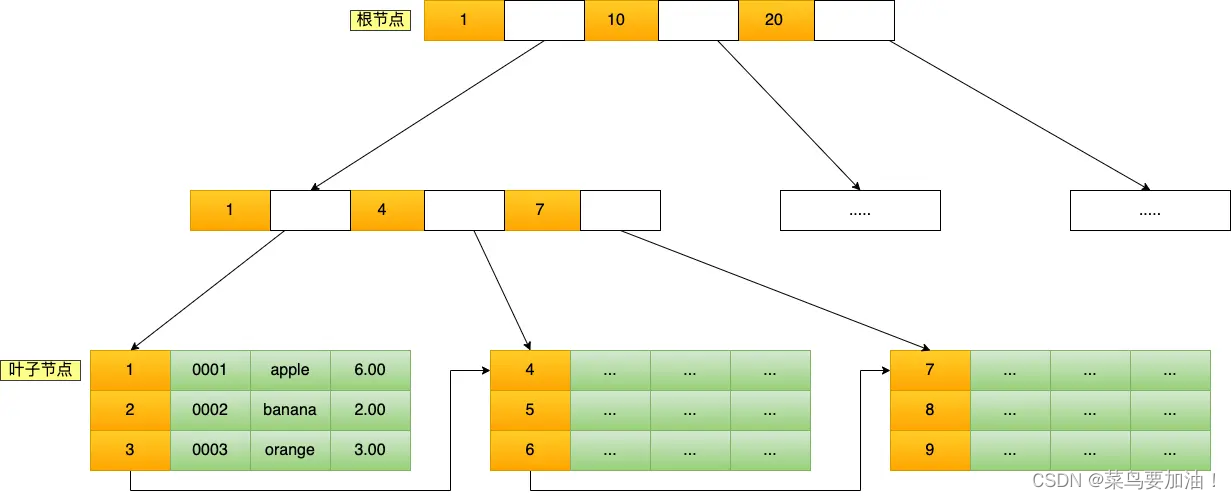
B+树
主键索引:叶子节点中存储了全部元素的索引
二级索引:叶子节点中只存储了当前索引字段和主键ID
主键索引的 B+Tree
之前在讲MVCC时提到过,再次加深印象
InnoDB主键索引【聚簇索引】的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了主键,则PK就是聚集索引;
(2)如果表没有定义主键,则第一个非空唯一索引(not NULL unique)列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
如图所示(图中叶子节点之间实际上是双向链表):
补充:【B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。】
============================================================================
主键索引的 B+Tree 和二级索引的 B+Tree 区别如下:
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
二级索引的 B+Tree
(图中叶子节点之间实际上是双向链表)

大概理解的B+树的主键索引和二级索引,就比较好理解回表、索引覆盖和索引下推了
回表
在MySQL中,回表(Index Lookups)是指在 使用二级索引(Secondary Index)进行查询时,(没有得到想要的全部结果),就需要根据该索引的键值去主键索引(Primary Index)中查找对应的数据行的过程。
写一个会回表查询的SQL:
select id, name, age from index_opt_test where name=‘cc’ ;
解析:SQL需要查询的列包括 id、name、age、使用name='cc’二级索引,但是这时候只能得到 id 和 name的值,但是age不能通过这次索引获取到。这时候只能通过 id 主键索引 获取到整行数据之后再从结果中捞出来age列的数据,这个额外的通过主键索引查找数据的过程就是回表。
回表操作可能导致额外的IO开销,影响查询性能,特别是当查询的列不包含在二级索引中。为了优化查询性能,可以使用覆盖索引(Covering Index)和索引下推(Index Condition Pushdown)技术来避免回表操作,提高查询效率。
索引覆盖。
当所有的列都能在二级索引树中查询到,就不需要再回表,这种情况就是索引覆盖。简单点来讲就是:所有不需要回表的查询操作都叫索引覆盖。
select id,name from user where name=‘shenjian’;
因为通过name='shenjian’就可以查询到id,name字段,无需回表,所以是索引覆盖。
实现索引覆盖:
- select id,name from user where name=‘shenjian’;
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name) 单列索引
)engine=innodb;
- 建立 联合索引
select id,name,sex from user where name=‘shenjian’;
create table user1 (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex) 联合索引,
)engine=innodb;
单列索升级为联合索引(name, sex)后,索引叶子节点存储了主键id,name,sex,都能够命中索引覆盖,无需回表。
下面这个查询SQL该怎么建联合索引?
select a from table where b = 1 and c = 2;
刚才在讲联合索引的时候已经说了这个知识点了,where条件有b和c的等值查询,联合索引就建成(b,c),由于select后面有a,我们就建立 (b,c,a) 的联合索引,并且可以用到覆盖索引,查询速度更快。
索引下推(ICP优化)
在需要进行 联合索引 的时候,使用ICP可以对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少存储引擎访问基础表的次数和Server访问存储引擎的次数,(减少回表次数)。
ICP 适用的一个隐含前提是二级索引必须是联合索引、且在使用索引进行扫描时只能采用最左前缀匹配原则。组合索引后面的列出现在 where 条件里,因此可以先过滤索引元组、从而减少回表读的数量。
例子:
SQL语句:(联合索引)
select id, name, sex,age from user where name=‘cc’ and sex=‘male’ and age>20;
没有开启索引下推的过程如下:
- 数据库接收到查询请求后,解析查询语句,确定需要访问的数据表为"user"表。 Server层把name推到引擎层
- 存储引擎会扫描整个"user"表,根据“最左前缀原则”,引擎层根据二级索引name找到主键, 存储引擎将满足条件的数据行返回给Server层。(回表)
- Server层再根据sex、age筛选出最终的数据。
- 最后返回给客户端
开启了索引下推后的过程如下:
- 数据库接收到查询请求后,解析查询语句,并确定需要访问的数据表。Server层会将name=‘cc’、sex=‘male’ 和 age=20 下推到存储引擎
- 存储引擎根据下推的条件,利用姓名、性别和年龄字段的索引,直接定位到符合条件的数据行。
- 符合条件的数据行将被返回给Server层。(回表)
- Server层收到数据后,将数据返回给客户端。



![[MYSQL数据库]--mysql的基础知识](https://img-blog.csdnimg.cn/direct/422eed8633604bb5bfd2efed0fa84fc5.png)