目录
一、概述
1.1 prometheus简介
1.2 prometheus特点
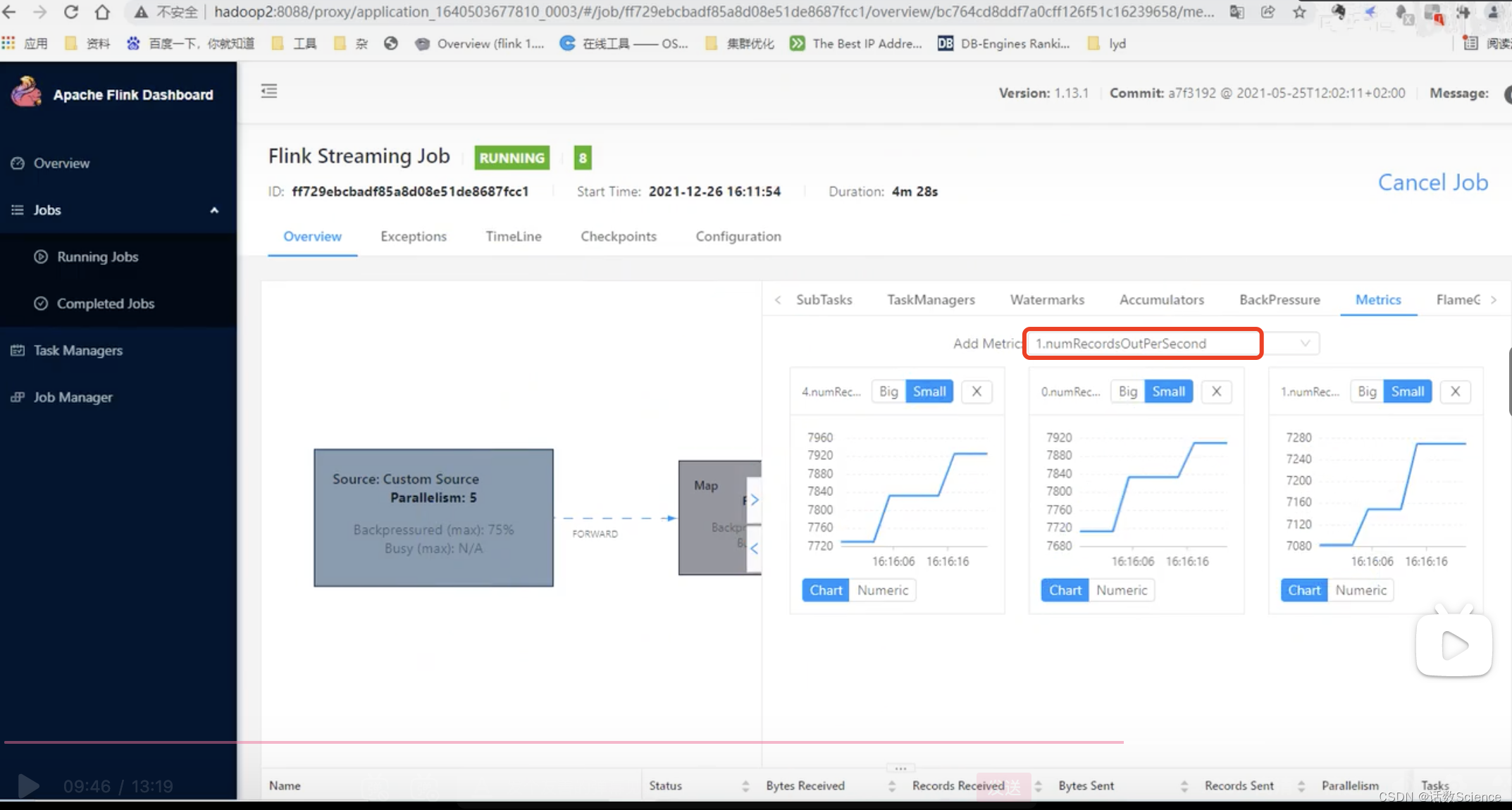
1.3 prometheus架构图
1.4 prometheus组件介绍
1、Prometheus Server
2、Client Library
3、pushgateway
4、Exporters
5、Service Discovery
6、Alertmanager
7、grafana
1.5 Prometheus 数据流向
1.6 Prometheus监控什么
1.7 Zabbix和Prometheus区别
二、prometheus工作原理
2.1 prometheus工作模式
2.2 prometheus工作流程
一、概述
1.1 prometheus简介
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。

文档地址
prometheus官网文档地址:Overview | Prometheus
prometheus中文文档地址:第1节:Prometheus 简介 - Prometheus 中文文档
1.2 prometheus特点
- 多维度数据模型,时间序列数据由metrics名称和键值对来组成,数据库:Prometheus外置的远端存储通常会用:InfluxDB、openTsDB等
- 灵活的查询语言(PromQL),可以对采集的metrics指标进行加法,乘法,连接等操作;
- 可以直接在本地部署,不依赖其他分布式存储;
- 通过基于HTTP上的拉取方式采集时序数据;
- 可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
- 可通过服务发现或者静态配置来发现目标服务对象(targets)。
- 有多种可视化图像界面,如Grafana等。
- 高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
1.3 prometheus架构图
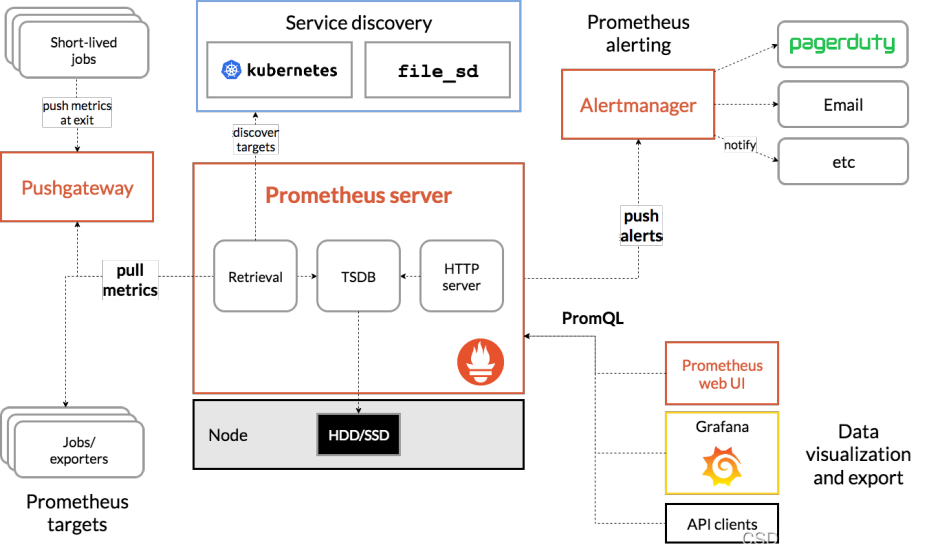
从上图可发现,Prometheus整个生态圈组成主要包括prometheus server,Exporter,pushgateway,alertmanager,grafana,Web ui界面,Prometheus server由三个部分组成,Retrieval,Storage,PromQL
- Retrieval负责在活跃的target主机上抓取监控指标数据
- Storage存储主要是把采集到的数据存储到磁盘中
- PromQL是Prometheus提供的查询语言模块。
1.4 prometheus组件介绍
1、Prometheus Server
Prometheus Server用于收集和存储时间序列数据。Prometheus server:服务核心组件,采用pull方式收集监控数据,通过http协议传输。并存储时间序列数据。Prometheus server 由三个部分组成:Retrival,Storage,PromQL
- Retrieval:负责在活跃的target 主机上抓取监控指标数据。
- Storage:存储,主要是把采集到的数据存储到磁盘中。默认为15天(可修改)。
- PromQL:是Prometheus提供的查询语言模块。
2、Client Library
客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
3、pushgateway
pushgatewy类似一个中转站,各个目标主机可上报数据到pushgatewy,然后prometheus server统一从pushgateway拉取数据。可以理解成目标主机可以上报短期任务的数据到Pushgateway,然后Prometheus server 统一从Pushgateway拉取数据。
4、Exporters
prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter
5、Service Discovery
Service Discovery:服务发现,用于动态发现待监控的Target,Prometheus支持多种服务发现机制:文件、DNS、Consul、Kubernetes等等。
服务发现可通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮询这些Target 获取监控数据。该组件目前由Prometheus Server内建支持
6、Alertmanager
Alertmanager:是一个独立的告警模块,从Prometheus server端接收到“告警通知”后,会进行去重、分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件、钉钉、企业微信等。
- Prometheus Server 仅负责生成告警指示,具体的告警行为由另一个独立的应用程序AlertManager负责;
- 告警指示由 Prometheus Server基于用户提供的告警规则周期性计算生成,Alertmanager 接收到Prometheus Server发来的告警指示后,基于用户定义的告警路由向告警接收人发送告警信息。
7、grafana
Grafana:是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。其官方库中具有丰富的仪表盘插件。
1.5 Prometheus 数据流向
① Prometheus server 定期从配置好的 jobs 或者 exporters 中拉取 metrics,或者接收来自 Pushgateway 发送过来的metrics,或者从其它的Prometheus server中拉取 metrics。
② Prometheus server在本地存储收集到的 metrics,并运行定义好的 alerts.rules,记录新的时间序列或者向Alert manager推送警报。
③ Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
④ 在图形界面中,可视化采集数据。
1.6 Prometheus监控什么
| 级别 | 监控什么 | exporter |
| 网络 | 网络协议:http、dns、tcp、icmp; 网路硬件:路由器、交换机等 | BlockBox Exporter;SNMP Exporter |
| 主机 | 资源用量 | node exporter |
| 容器 | 资源用量 | cadvisor |
| 应用(包括Library) | 延迟、错误,QPS,内部状态 | 代码集中集成Prometheus Client |
| 中间件状态 | 资源用量,以及服务状态 | 代码集中集成Prometheus Client |
| 编排工具 | 集群资源用量,调度等 | Kubernetes Components |
1.7 Zabbix和Prometheus区别
| 对比项 | Prometheus | zabbix | Prometheus优势 | zabbix优势 |
| 配置 | 配置文件 | 图形化+文件 | 更好的支持自动化配置 | 学习成本低 |
| 管理 | 二进制文件启动 | LNMP+编译 | 轻量级server ,便于迁移和维护 | 一 |
| client | 丰富的client库 | zabbix_agent自定义脚本 | 各种中间件、应用提供专业的exporter,监控项更全面 | 支持自定义监控项,对监控开发者的要求较高 |
| 数据存储方式 | TSDB | MySQL | 监控数据以时间为维度统计情况较多,时序数据库更适用于监控数据的存储,按时间索引性能更高 | MySQL比较常用,学习成本低 |
| 数据处理 | PromQL | MySQL | PromQL计算函数丰富,统计维度广 | MySQL比较常用,学习成本低 |
| 二次开发 | 丰富的SDK | API | 提供了Go、JAVA/Scala、Python等SDK二次开发更方便 | API适配较为常用,学习成本低 |
| 对云环境的支持 | 原生支持容器监控 | 更适合物理机监控 | 自动发现容器,更好的适配k8s | 一 |
| 告警方式 | 可按照标签分组,收敛 | 在次数上收敛 | 告警收敛方式更多样化 | 一 |
对比分析:从系统成熟度上看,Zabbix是老牌的监控系统:Zabbix是在1998年就出现的,系统功能比较稳定,成熟度较高。而Prometheus是最近几年才诞生的,虽然功能还在不断迭代更新,但站在巨人的肩膀之上,在架构设计上借鉴了很多老牌监控系统的经验;从数据存储方面来看,Zabbix采用关系数据库保存,这极大限制了Zabbix采集的性能,而Prometheus自研一套高性能的时序数据库,在V3版本可以达到每秒千万级别的数据存储,通过对接第三方时序数据库扩展历史数据的存储;从配置复杂度上看,Prometheus只有一个核心server组件,一条命令便可以启动,相比而言,其他系统配置相对麻烦,从社区活跃度上看,目前Zabbix比较活跃,但基本都是国内的公司参与,Prometheus在这方面占据绝对优势,社区活跃度虽然不如,但是受到CNCF的支持,后期的发展值得期待;从容器支持角度看,由于Zabbix出现得比较早,当时容器还没有诞生,自然对容器的支持也比较差。而Prometheus的动态发现机制,不仅可以支持swarm原生集群,还支持Kubernetes容器集群的监控,是目前容器监控最好解决方案。
总结:如果监控的是物理机,没话说就选 Zabbix,Zabbix在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势,甚至环境变动不会很频繁的情况下,Zabbix 也会比 Prometheus 好使;但如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,否则还是选择 Prometheus 吧,毕竟人家就是干这个的。Prometheus开始成为主导及容器监控方面的标配,并且在未来可见的时间内被广泛应用。如果是刚刚要上监控系统的话,不用犹豫了Prometheus + grafana+ alertManger 没错。
二、prometheus工作原理
2.1 prometheus工作模式
1. Prometheus Server 基于服务发现(Service Discovery)机制或静态配置获取要监视的目标(Target),并通过每个目标上的指标 exporter来采集(Scrape)指标数据;
2. Prometheus Server 内置了一个基于文件的时间序列存储来持久存储指标数据,用户可使用PromQL接口来检索数据,也能够按需将告警需求发往Altermanager完成告警内容发送;
3. 一些短期运行的作业的生命周期过短,难以有效地将必要的指标数据供给到Server端,它们一般会采用推送(Push)方式输出指标数据,Prometheus借助于Pushgateway 接收这些推送的数据,进而由server端进行抓取
2.2 prometheus工作流程

① Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中;还可通过一些组件自带的exporter采集相应组件的数据;
② Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
③Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager;
④ Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
⑤ Prometheus 自带的web ui界面提供PromQL查询语言,可查询监控数据
⑥Grafana可接入prometheus数据源,把监控数据以图形化形式展示出
参考文章:
prometheus和zabbix的对比_prometheus zabbix-CSDN博客
Promethues原理详解_prometheus工作原理-CSDN博客