一、 JVM指令集:
1. 了解Java虚拟机的指令集是什么?举例说明一些常见的指令及其作用。
Java虚拟机的指令集是一组用于执行Java程序的低级操作码。这些指令直接在Java虚拟机上执行,可以认为是Java程序的二进制表示形式。以下是一些常见的Java虚拟机指令及其作用的例子:
-
iconst系列指令:iconst_0,iconst_1, …,iconst_5: 将整数0到5推送到栈顶。- 作用:将常量整数压入栈顶。
-
aload和astore系列指令:aload_0,aload_1, …,aload_3: 将引用类型的局部变量加载到栈顶。astore_0,astore_1, …,astore_3: 将栈顶引用类型的值存储到局部变量。- 作用:加载和存储引用类型数据。
-
iload和istore系列指令:iload_0,iload_1, …,iload_3: 将整数类型的局部变量加载到栈顶。istore_0,istore_1, …,istore_3: 将栈顶整数类型的值存储到局部变量。- 作用:加载和存储整数类型数据。
-
iadd和isub等算术指令:iadd: 将栈顶两个整数相加。isub: 将栈顶两个整数相减。- 作用:执行整数加法和减法。
-
goto和if系列指令:goto: 无条件跳转到指定位置。ifeq,ifne,iflt,ifge,ifgt,ifle: 根据栈顶整数的值进行条件跳转。- 作用:实现无条件和有条件的跳转。
-
invoke系列指令:invokevirtual,invokestatic,invokespecial,invokeinterface,invokedynamic: 分别用于调用实例方法、静态方法、私有方法、接口方法和动态方法。- 作用:执行方法调用。
-
new和newarray指令:new: 创建一个新的对象。newarray: 创建一个新的基本数据类型数组。- 作用:创建对象和数组。
-
putfield和getfield指令:putfield: 将栈顶的值赋给对象的实例字段。getfield: 将对象的实例字段的值推送到栈顶。- 作用:访问对象的实例字段。
这些指令是Java虚拟机指令集中的一部分,涵盖了基本的栈操作、变量加载存储、数学运算、控制流等功能。在Java字节码中,这些指令按照字节码的格式被编码,并在Java虚拟机中执行。
二、 对象模型和内存布局:
1.描述Java对象在内存中的布局,包括对象头、实例数据和对齐等方面。
Java对象在内存中的布局主要包括对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)等三个部分。具体的布局可以因为虚拟机的不同而有所差异,以下是通用情况下的描述:
-
对象头(Header):
- 对象头用于存储对象自身的运行时数据,包括哈希码、锁状态标志、垃圾回收信息等。对象头的大小在不同的虚拟机实现中可能会有所不同,通常在32位系统上占用8字节,而在64位系统上占用12字节。
- 其中,包含:
- Mark Word(标记字): 存储对象的哈希码、锁信息等。
- Klass Pointer(类型指针): 指向对象的类元数据。
-
实例数据(Instance Data):
- 实例数据部分包含了对象的字段,即在类中声明的各种成员变量。字段的大小和对齐方式由字段的类型和虚拟机的要求决定。
- 实例数据的布局是按照在类中声明的顺序排列的,不同的虚拟机可能对字段的排列进行一些优化。
-
对齐填充(Padding):
- 由于虚拟机要求对象的起始地址必须是8字节的整数倍(在某些平台上可能是4字节的整数倍),因此可能需要对实例数据进行对齐填充,以保证整个对象的大小是8字节的倍数(或4字节的倍数)。
- 对齐填充的大小取决于实例数据部分的大小,以确保整个对象的总大小满足对齐要求。
下面是一个简单的示意图,表示一个Java对象在内存中的布局:
------------------
| 对象头(Header) |
------------------
| 实例数据(Instance Data)|
------------------
| 对齐填充(Padding) |
------------------
在不同的虚拟机和不同的场景下,对象的布局可能会有一些变化,但以上描述是一般情况下的Java对象在内存中的典型布局。要注意,具体的实现可能因为虚拟机的版本、配置和运行时环境的不同而有所调整。
2. 什么是对象的标记字(Mark Word)?
对象的标记字(Mark Word)是Java对象头中的一部分,用于存储对象的运行时信息。在Java虚拟机的内存模型中,每个对象都有一个对象头,其中的标记字包含了对象的一些元信息,如锁信息、垃圾回收状态等。
标记字的具体结构和含义可能会因虚拟机的实现而有所不同,但通常包含以下信息:
-
哈希码(HashCode):
- 用于支持
hashCode()方法。在对象被创建时,如果没有重写hashCode()方法,标记字中的哈希码将默认由对象的地址计算得到。
- 用于支持
-
锁信息(Lock Information):
- 用于支持对象的同步机制。在多线程环境中,Java对象可能会被多个线程同时访问,因此需要进行加锁以确保数据的一致性。标记字中的锁信息包括了对象的锁状态、锁持有的线程等信息。
-
垃圾回收信息:
- 用于支持垃圾回收。标记字中的垃圾回收信息包括了对象的存活状态、分代信息等。这些信息有助于垃圾回收器判断对象是否可被回收。
-
偏向锁标志(Biased Lock Flag):
- 用于标识对象是否处于偏向锁状态。在Java虚拟机中,偏向锁是一种提高同步性能的机制。当对象被某个线程锁定时,可以使用偏向锁来减少获取锁的开销。
标记字的具体位数和结构可能因虚拟机的不同而异。在64位虚拟机中,通常使用64位来存储标记字。在32位虚拟机中,标记字的大小可能是32位。
对象的标记字是Java虚拟机管理对象的关键信息之一,它在支持同步、垃圾回收等方面发挥着重要的作用。标记字的设计可以根据不同的虚拟机实现和需求有所差异。
三、 栈和本地方法栈:
1. 解释栈的结构,栈帧的组成,以及方法调用时栈的变化。
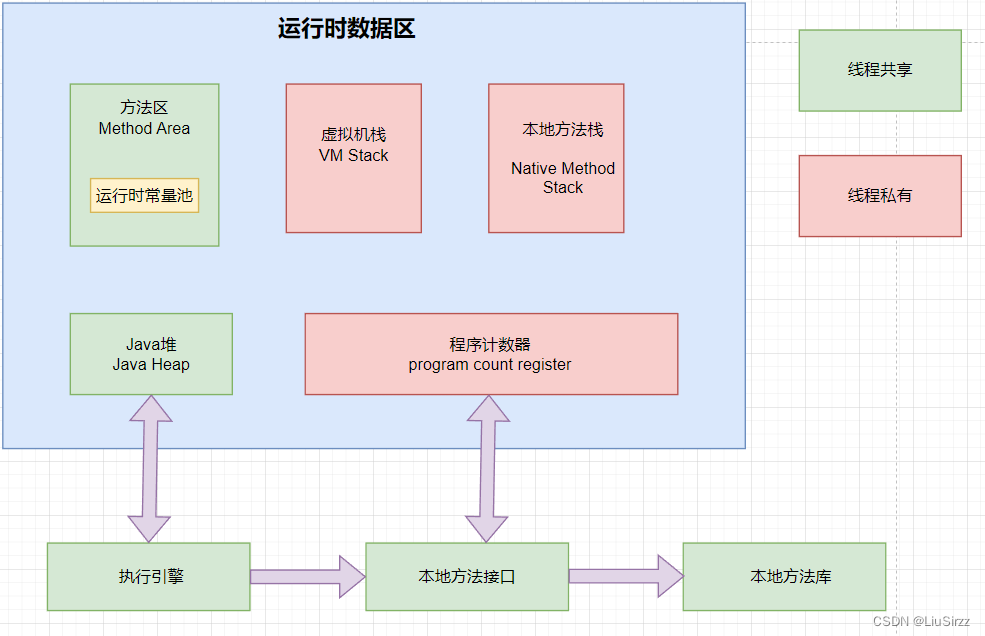
栈(Stack)是Java虚拟机用来执行方法调用的数据结构,每个线程都有自己的栈。栈是一个后进先出(LIFO)的数据结构,用于存储方法的局部变量、操作数栈、动态链接、方法出口等信息。在Java虚拟机中,栈的结构主要由栈帧构成。
栈帧(Stack Frame)的组成:
栈帧是用于支持方法调用和执行的数据结构,每个方法调用都会创建一个对应的栈帧。栈帧的组成通常包括以下几个部分:
-
局部变量表(Local Variable Table):
- 用于存储方法中的局部变量,包括方法参数和在方法体内部定义的局部变量。局部变量表中的槽位可以存放基本数据类型和对象引用。
-
操作数栈(Operand Stack):
- 用于存储方法执行过程中的操作数。在方法调用时,参数从局部变量表传递到操作数栈,方法执行时,操作数栈用于存储临时数据和中间结果。
-
动态链接(Dynamic Linking):
- 指向运行时常量池的方法引用,包括类和方法的信息。动态链接支持方法调用时的动态绑定。
-
方法返回地址(Return Address):
- 指向方法调用结束后需要返回的地址。在Java虚拟机中,方法的返回地址通常是指向方法调用指令的下一条指令。
-
帧数据(Frame Data):
- 用于存储一些附加的信息,例如异常处理表(Exception Table)等。
方法调用时栈的变化:
-
方法调用过程:
- 当一个方法被调用时,Java虚拟机会创建一个新的栈帧并推入栈顶,该栈帧包含了方法的局部变量表、操作数栈等信息。
- 方法参数被传递到局部变量表中,方法的操作数栈被清空。
-
方法执行过程:
- 在方法执行过程中,局部变量表和操作数栈用于存储和计算方法中的数据。
- 操作数栈用于存放中间结果、方法调用的参数和返回值。
-
方法返回过程:
- 当方法执行完成时,返回地址和方法的返回值等信息从栈帧中弹出,控制权返回给调用方法。
- 调用方法的栈帧被弹出,控制权回到调用方法的栈帧。
-
递归调用:
- 在递归调用中,每次方法调用都会创建一个新的栈帧,形成一个栈帧的链条。这些栈帧在栈中依次排列,每个栈帧负责一个方法的执行。
栈的结构和栈帧的组成是支持Java方法调用和执行的关键。在方法调用过程中,栈帧的入栈和出栈使得方法的执行能够进行,同时局部变量表和操作数栈的使用保证了方法执行时的数据存储和计算。
2. 本地方法栈和虚拟机栈有何异同?
本地方法栈(Native Method Stack)和虚拟机栈(Java Virtual Machine Stack)都是Java虚拟机在运行时使用的栈结构,但它们分别用于支持不同类型的方法调用。
本地方法栈(Native Method Stack):
-
作用:
- 本地方法栈用于支持Java虚拟机使用本地方法(Native Method),即用其他语言(通常是C或C++)编写的方法。
-
存储内容:
- 存储的是本地方法的调用和执行信息。本地方法是通过Java Native Interface(JNI)调用的,其实现是由其他语言编写的。
-
内存管理:
- 本地方法栈与虚拟机栈的管理方式相似,都是通过栈帧来管理方法调用的信息。但本地方法栈的管理通常由本地方法库负责,而不是由Java虚拟机直接管理。
-
可能性:
- 并非所有的Java虚拟机实现都提供本地方法栈,某些虚拟机将本地方法栈和虚拟机栈合二为一。
虚拟机栈(Java Virtual Machine Stack):
-
作用:
- 虚拟机栈用于支持Java方法的调用和执行。
-
存储内容:
- 存储的是Java方法的调用和执行信息,包括局部变量表、操作数栈、动态链接等。
-
内存管理:
- 虚拟机栈由Java虚拟机直接进行管理,它的栈帧中包含了方法的执行信息,并且可以在方法调用时动态地分配和释放栈帧。
-
异常处理:
- 虚拟机栈中还包含了用于异常处理的信息,当方法出现异常时,虚拟机会在虚拟机栈中找到对应的异常处理器进行处理。
异同点总结:
-
调用对象:
- 本地方法栈用于调用本地方法,而虚拟机栈用于调用Java方法。
-
存储内容:
- 本地方法栈存储本地方法的调用和执行信息,虚拟机栈存储Java方法的调用和执行信息。
-
内存管理:
- 本地方法栈的内存管理通常由本地方法库负责,虚拟机栈由Java虚拟机直接进行管理。
-
异常处理:
- 虚拟机栈中包含了用于异常处理的信息,而本地方法栈可能不包含这样的信息。
本地方法栈和虚拟机栈都是为了支持方法调用和执行而设计的,但它们服务于不同类型的方法,具有不同的内存管理机制。
四、 深入分析类加载机制:
1.类加载过程中,具体每个阶段发生了什么?
类加载是Java虚拟机将类的二进制数据加载到内存中,并转换为可以被虚拟机直接使用的数据结构的过程。类加载过程主要包括以下阶段:
-
加载(Loading)阶段:
- 加载阶段是类加载的第一阶段。在加载阶段,虚拟机需要完成以下任务:
- 通过类的全限定名获取类的二进制数据流。
- 将二进制数据流转换成方法区的数据结构。
- 在内存中生成一个代表该类的
java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
- 加载阶段是类加载的第一阶段。在加载阶段,虚拟机需要完成以下任务:
-
连接(Linking)阶段:
- 连接阶段包括三个子阶段:验证、准备和解析。
- 验证(Verification): 确保加载的类是符合Java虚拟机规范的,不会对虚拟机造成危害。
- 准备(Preparation): 为类的静态变量分配内存并设置默认初始值,这些变量所使用的内存都在方法区中分配。
- 解析(Resolution): 将符号引用解析为直接引用。符号引用是一组符号来描述被引用的目标,直接引用可以是直接指向目标的指针、相对偏移量或一个能间接定位到目标的句柄。
- 连接阶段包括三个子阶段:验证、准备和解析。
-
初始化(Initialization)阶段:
- 在初始化阶段,虚拟机执行类的初始化语句。这是类加载过程的最后一步,它包括:
- 执行类的初始化方法(
<clinit>),该方法是由编译器自动收集类中的所有类变量的赋值动作和静态代码块(static {})中的语句合并产生的。 - 如果一个类在初始化时发现它的父类还没有被初始化,则需要先触发其父类的初始化。
- 执行类的初始化方法(
- 在初始化阶段,虚拟机执行类的初始化语句。这是类加载过程的最后一步,它包括:
需要注意的是,不是所有类的加载阶段都经历完整的连接和初始化。比如,接口中定义的变量默认是public static final的,它们在接口的连接阶段就会被初始化为常量值,并不需要等到初始化阶段。而类变量则会在初始化阶段才被赋值。
2、如果要实现一个自定义类加载器,你会怎么做?
实现自定义类加载器通常需要继承ClassLoader类,并重写其中的findClass方法。以下是实现自定义类加载器的一般步骤:
-
继承ClassLoader类:
- 创建一个新的类,继承自
ClassLoader。
public class CustomClassLoader extends ClassLoader { // 实现自定义类加载器的方法 } - 创建一个新的类,继承自
-
重写findClass方法:
- 在自定义类加载器中,需要重写
findClass方法。这个方法负责加载类的二进制字节码并转换为Class对象。
@Override protected Class<?> findClass(String className) throws ClassNotFoundException { // 实现加载类的逻辑,将二进制数据转换为Class对象 byte[] classData = loadClassData(className); if (classData == null< - 在自定义类加载器中,需要重写