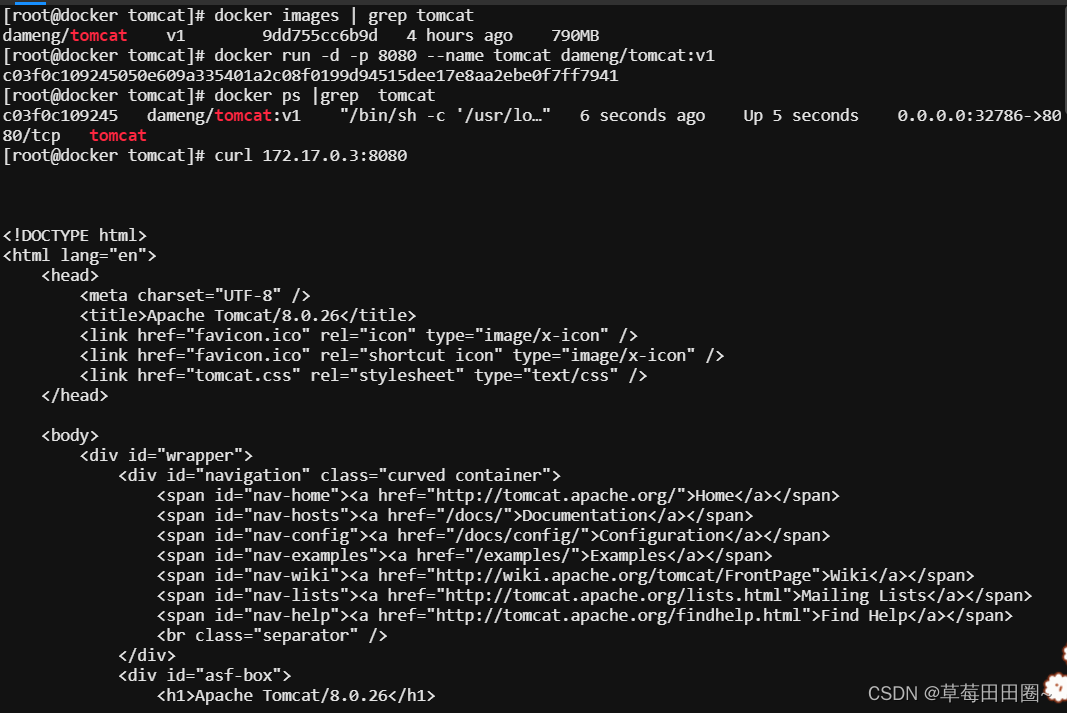
跑批是串行进行的,同时伴随着在线业务,整个跑批过程中只卡在SQL(6hqva0h4awrxh)执行环节上,相关等待事件为gc current grant 2-way,其他环节及在线业务都不受影响,主机整体资源较为空闲。最后通过重建问题SQL涉及对象的索引解决。
故障时间段的awr、ash性能报告和数据库hanganalyze全局dump信息:

如截图所示并没有出现异常指标及全局的性能问题,种种迹象表明数据库整体负载较为正常。问题只出现在单个SQL的执行上。

从systemdump 该会话的信息可以看出并没有任何会话堵塞,历史的等待一直为gc current grant 2-way。读取的对象是4号数据文件919380块,其中4号数据文件正是undotbs,说明会话进程读取数据块前镜像,大量DML操作在同一个对象上发生。
说明
gc current grant 2-way:这个等待事件说明当前实例向主节点申请了一个current块,而且这个申请已经被主节点响应,其中并没有出现超时。但是,这个被申请的数据块不包含在任何实例的数据库缓冲区中,它是需要申请实例从数据文件读取出来的,当current grant 2-way的等待事件很多,并且消耗了很多等待时间的话,可能的原因如下:
原因1:网络带宽
原因2:应用程序的角度来讲,导致大量current/cr grant 2-way等待事件的原因如下:
2.1:某些SQL语句的执行计划出现了问题
2.2:数据库缓冲区被设置过小,这导致很多数据被频繁地写入数据文件
2.3:检查点过于频繁。例如:fast_start_mttr_target设置的过短
其中原因1通过osw系统监控被排除,2.2和2.3可能性也不大。剩下2.1,我们看一下问题SQL语句:
update bs_account_jnls_tax
set status = '04'
where status = '00'
and acc_date = to_date('2024-02-10', 'yyyy-mm-dd')
and trans_jnls_no in
(select distinct trans_jnls_no
from jn_batch_result
where batch_no in ('75110058', '75110068')
and acc_date = to_date('2024-02-10', 'yyyy-mm-dd'))
一条简单的update语句使用非绑定变量,以下为内存中的执行计划: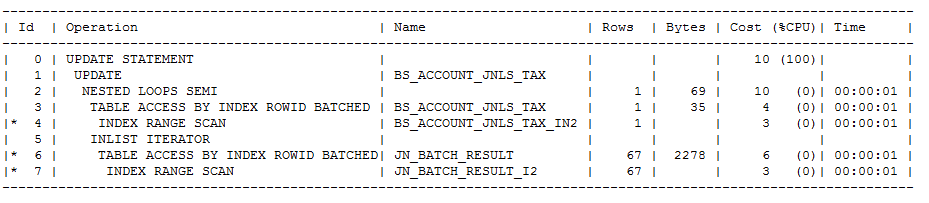
由于使用非绑定变量,CBO计算存在误差,实际和看到的执行计划存在不一致的现象。(实际的执行计划需要通过10053单独跟踪验证),这也验证了为什么通过重建索引改变执行计划来解决问题。
总结
通过上述分析判断,最主要的问题还是SQL语句本身未使用绑定变量导致执行计划不稳定,执行效率低所导致。
解决方法:
1. 规范开发SQL语句编写统一使用绑定变量
2. 评估bs_account_jnls_tax表大小,keep到buffer cache内存中,或问题SQL前先执行select count(*) from trans_jnls_no/ bs_account_jnls_tax
3. 如果建议1应用短时间内无法变更,再次出现故障时可以尝试从shared pool中手动刷出去执行计划重新生成新的,方法如下:
查询对应sql的address和hash value
select s.SQL_TEXT, s.ADDRESS || ‘,’ || s.HASH_VALUE from v$sqlarea s where sql_id = ‘10kq6nc2rfrf0’;
exec sys.dbms_shared_pool.purge(‘0000000141AE1310,91708864’,‘c’);
注:0000000141AE1310,91708864为s.ADDRESS || ‘,’ || s.HASH_VALUE的值