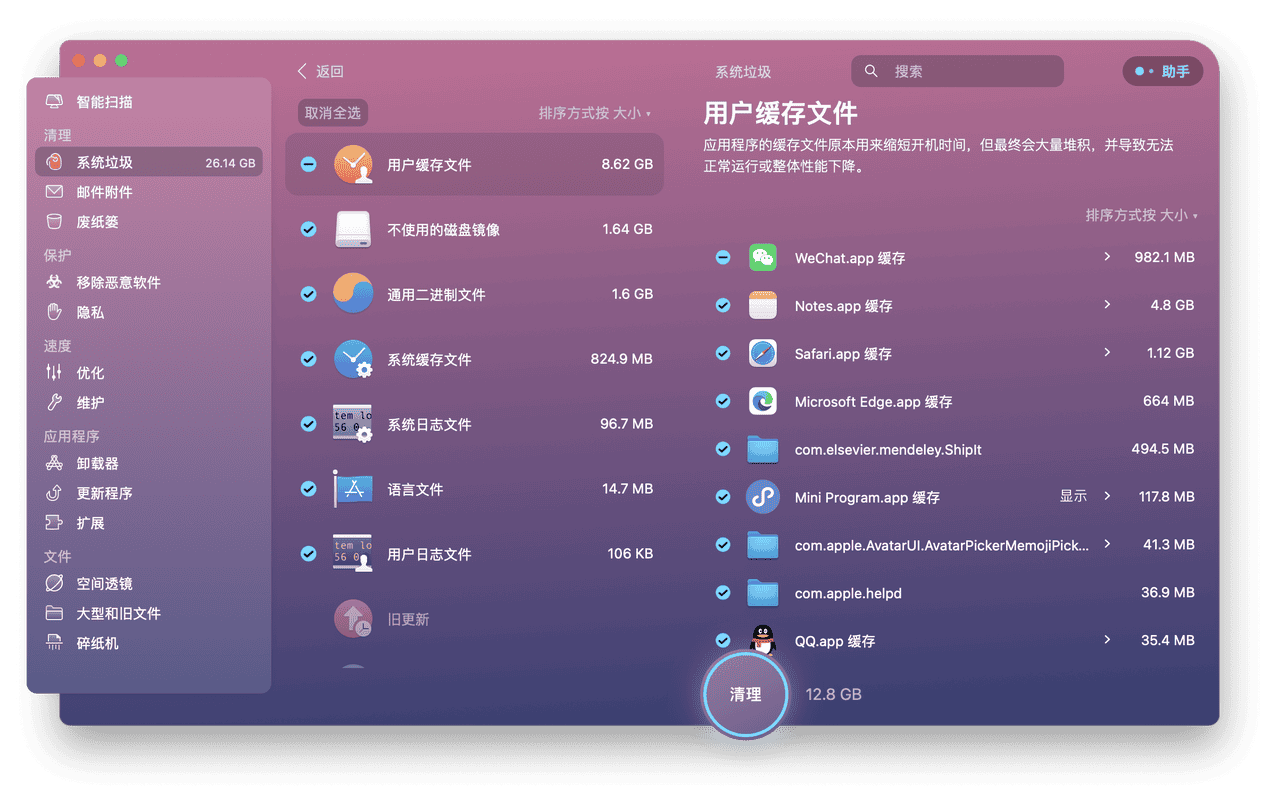
CRAG:改进传统的 RAG,增加纠正机制提升生成文本的准确性
- 提出背景
- CRAG 框架
- 轻量级检索评估器
- 大规模网络搜索
- 分解再重组算法
提出背景
论文:https://arxiv.org/abs/2401.15884
代码:https://github.com/HuskyInSalt/CRAG
大型语言模型经常因依赖内部参数知识而产生不准确或幻觉化的内容。
对于大模型的内部错误,可以引入RAG,从外部知识来源(pdf、网页等)寻找支撑证据。
虽然RAG方法通过获取外部文档来丰富生成,从而补充了LLM,但其有效性显著依赖于这些检索文档的相关性。当检索不准确时,模型受到误导。
RAG的局限性:依赖检索文档的相关性和准确性,不准确的检索结果会损害模型性能。
CRAG延续了RAG的基本框架,即通过检索器从大量知识文档中检索相关信息,并将这些信息作为输入的一部分提供给生成器,以增强生成文本的相关性和准确性。
假设我们的任务是生成一个特定历史人物的详细传记。
基于RAG的系统可能直接从预先设定的知识库中检索与查询相关的文档,并基于这些文档生成传记。
如果检索到的文档不够准确或者包含过时信息,生成的传记可能会包含错误的事实,导致整体质量下降。
解法: 纠正检索增强生成(CRAG)。
核心组件:
- 轻量级检索评估器:评估检索到的文档与输入查询的相关性,发现质量不高,信心度低,这时会触发网络搜索。
- 大规模网络搜索:作为补充策略,当静态语料库检索失败或返回次优文档时,从网络中检索更相关、更高质量的文档。
- 分解再重组算法:精炼检索到的文档,提取关键信息,过滤掉不相关内容。
流程步骤:
- 查询输入:用户输入查询,例如要求生成关于“艾萨克·牛顿”的传记。
- 检索阶段:使用CRAG框架,首先由检索器R检索出与“艾萨克·牛顿”相关的顶K篇文档。
- 检索评估:轻量级检索评估器评估这些文档的相关性得分,确定它们与查询的相关度。
- 行动触发:
- 如果文档被评估为相关(Correct),则通过知识精炼方法进一步提取关键知识条。
- 如果文档被评估为不相关(Incorrect),则丢弃这些文档,并通过网络搜索寻找更准确的补充知识源。
- 如果评估结果是模糊的(Ambiguous),则结合相关和不相关的处理策略,试图从现有文档中提取有价值的信息,同时寻找外部补充。
- 生成阶段:根据精炼后的知识或补充的外部知识,生成器G生成详细的传记。
比如有一个查询:“艾萨克·牛顿是如何发现万有引力的?”
- 检索:系统从预设的知识库或互联网中检索相关文档。
- 评估:检索评估器分析文档的相关性。
- 行动触发:根据评估结果,可能触发不同的行动。
- 知识精炼/网络搜索:如果文档被评估为相关,系统将提取关键信息;如果不相关,系统将通过网络搜索找到更准确的信息。
- 生成:最终,系统基于精炼或补充的知识生成准确的回答。
CRAG 框架

通过对检索文档进行评估,CRAG将结果分为三类:正确、不正确和模糊,然后对应地进行知识纠正或搜索。
如果评估为正确,CRAG会通过分解和重组过程精炼知识;如果评估为不正确或模糊,CRAG可能会进行网络搜索以寻找更准确的信息。
轻量级检索评估器
轻量级检索评估器是CRAG中用来评估检索到的文档相关性的组件。它的实现通常依赖于以下步骤和技术:
- 模型选择:选择一个预训练的语言模型,如T5-large,因其能够以较小的计算代价提供有效的性能。
- 微调:使用标注过的数据集对模型进行微调,以便它能够对给定的查询和文档对进行相关性评分。
- 评分:对于每个检索到的文档,模型会生成一个相关性得分,该得分表示文档与查询的匹配程度。
- 阈值设定:设定阈值来判断文档是否足够相关,以便后续是否使用该文档进行生成或采取其他策略。
大规模网络搜索
当检索到的文档不相关或质量不高时,CRAG会采用网络搜索来找到更好的信息源。这个过程包括:
- 查询重写:将用户的查询重写为更适合网络搜索引擎的关键词。
- 搜索执行:使用商业或开源的网络搜索API执行搜索查询,收集搜索结果。
- 选择和过滤:从搜索结果中选择相关的文档,并过滤掉不相关的内容。
分解再重组算法
这是CRAG中用于优化检索文档内容的技术,具体包括:
- 分解:将检索到的文档分解为更细粒度的知识片段,例如句子或段落。
- 评分和筛选:使用检索评估器对每个知识片段进行评分,并筛选掉得分低的不相关片段。
- 重组:将得分高的相关片段重新组合,形成一个更加凝练和准确的知识基础,用于生成阶段。