一、索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构;
二、索引为什么使用B+Tree
1、索引为何不用二叉树结构
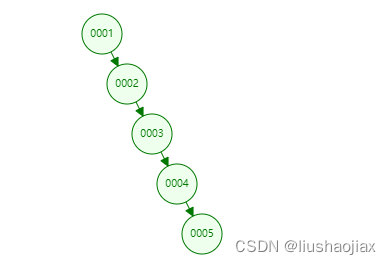
当索引字段递增时,如主键索引,二叉树会退化成一个链表,如果是数据有几百上千万,那链表就会很长,查询数据如果在链表最末尾,那就相当于全表扫描了:如图:
2、索引为何不用红黑树,红黑树可以通过左右旋转进行平衡
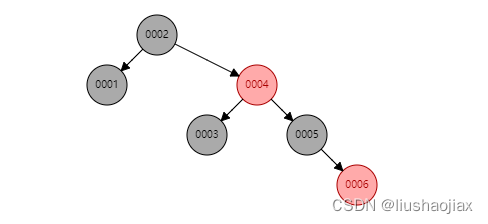
原因:考虑树的高度,假如数据有100万,索引都是递增的,那么会导致树的高度非常高,红黑树查询的顺序:如查找0005号数据,会先从根节点开始查询,比根节点数字大,查询根的右节点,之后比较0004,以此类推,每次加载根节点都是一次IO操作。
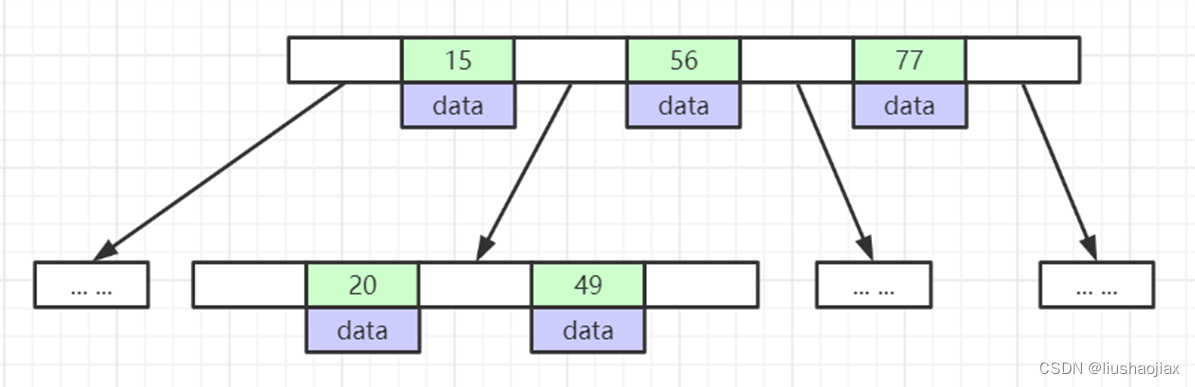
3、索引为什么不用B-Tree
B-Tree与B+Tree的区别叶节点的指针为空,不能进行范围查询,非叶子存储data数据,
如果按照B-树的结构,一个页是16kB,如果数据大小就是8kB的话,那么一个页能存的数据就只有2个索引了,这样一样会导致树的深度变高,此外,索引的每个节点的数据都不重复
叶子节点也没指向下一个节点,在范围查询中,性能就会很差,因此B+树在此基础上做了优化
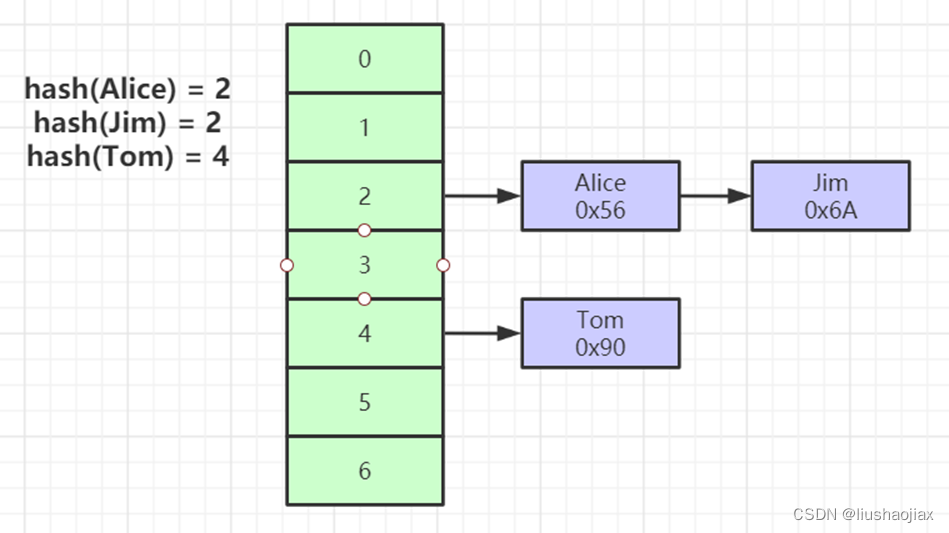
4、Hash结构
对索引的key进行一次hash计算就可以定位出数据存储的位置;
很多时候Hash索引要比B+ 树索引更高效;
仅能满足 “=”,“IN”,不支持范围查询;
hash冲突问题;
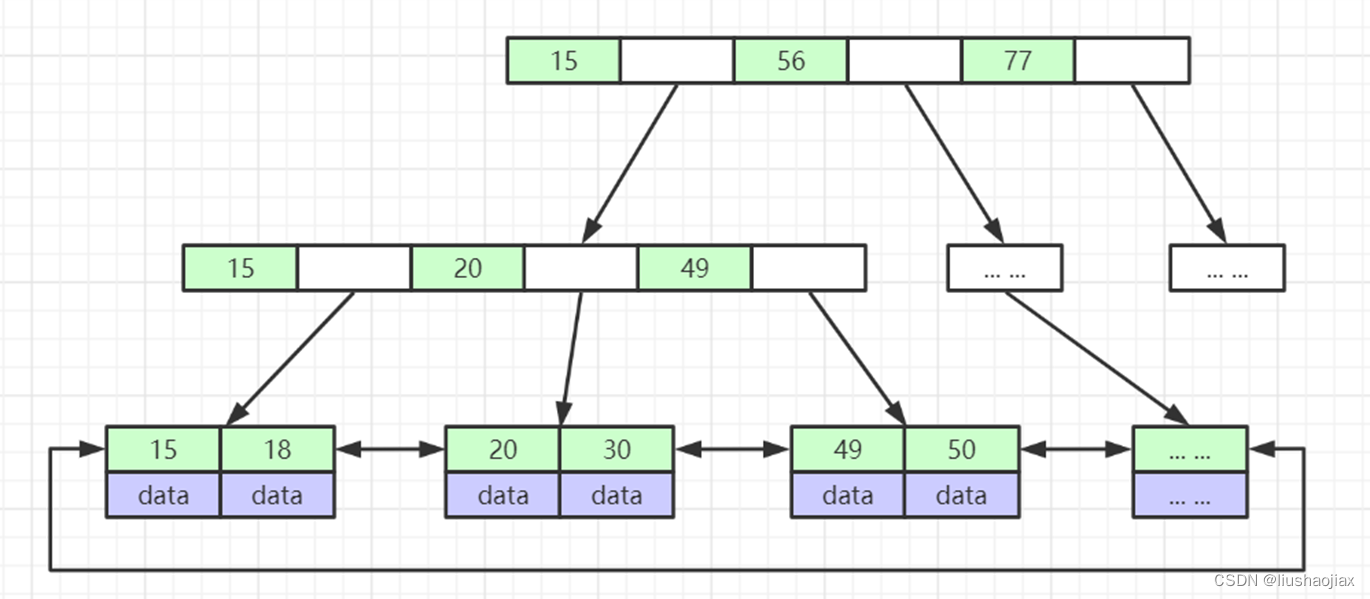
5、B+Tree(B-Tree变种)
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引;
叶子节点包含所有索引字段;
叶子节点用指针连接,提高区间访问的性能;
三、索引分类
物理存储分类:
聚簇索引(主键索引):数据和索引存储在同一位置,叶子节点包含行数据。
二级索引(辅助索引):非叶子节点包含索引和指针,需要回表查询行数据。
字段特性分类:
主键索引:主键索引是一种特殊的唯一索引,不允许有空值。
唯一索引:唯一索引保证每一列的值不相同。
普通索引:普通索引不附加任何限制条件,用于提高查询效率。
前缀索引:前缀索引是普通索引的一种,只基于字段的前缀进行索引。
字段个数分类:
单列索引:基于表中单个字段创建的索引。
联合索引:基于表中多个字段组合创建的索引。
四、InnoDB索引实现(聚集)
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?(mysql会自己维护主键索引,使用整型的自增主键减少索引维护,如果不创建就会寻找唯一索引,如果没有就会自己维护rowid)
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
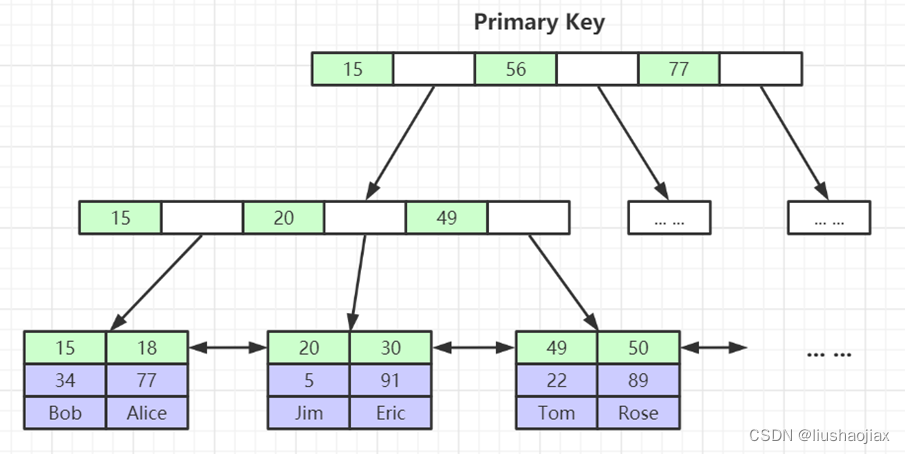

五、索引最左前缀原理
联合索引的底层存储结构长什么样?
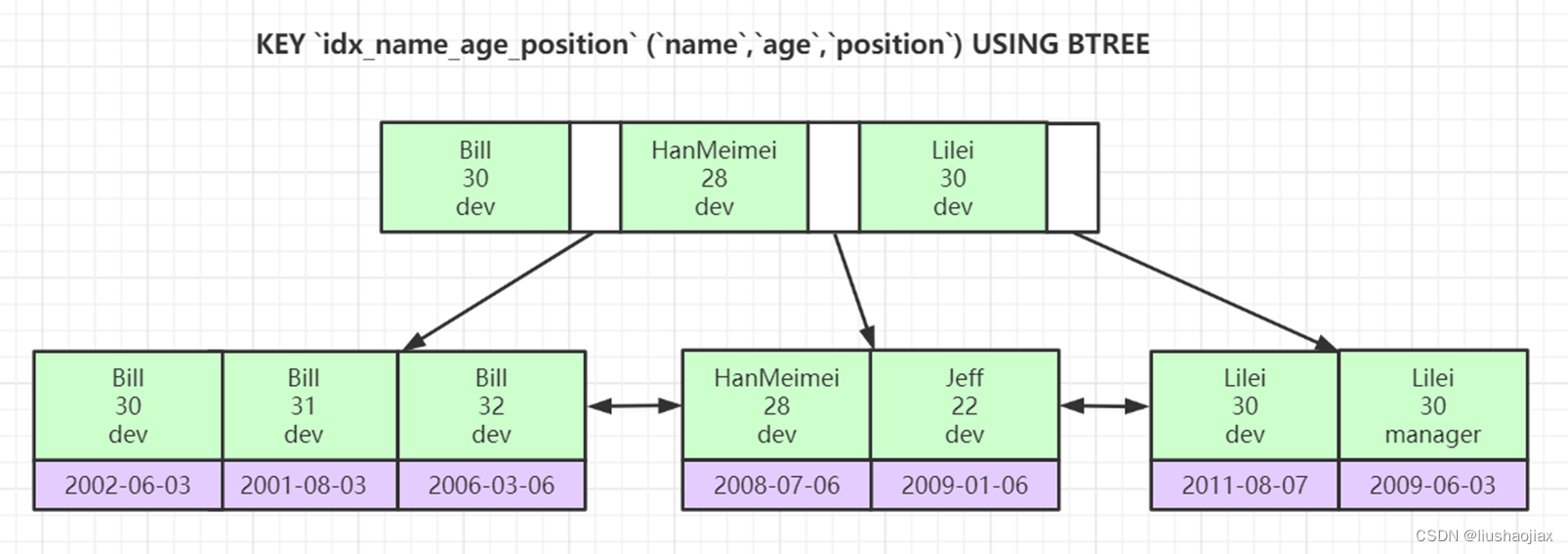
如图:我们可以看见联合索引创建就是根据第一字段进行创建的,索引如果查询不遵循最左前缀就会匹配不到;
索索引索引最左前缀原理引最左前缀原理