文章目录
- 🚀前言
- 🚀并查集
- 🚀并查集的两个优化
- ✈️路径压缩
- ✈️按秩合并
- 🚀并查集代码模板
🚀前言
大家好啊!今天阿辉来给大家介绍一种简洁而优雅的数据结构——并查集,不知道各位是否了解它,如果你在题解区见到并查集,想必各位一定见过类似下面这样的评论


好了,阿辉也不卖关子了,开始咱们今天的学习吧!!!!
🚀并查集
并查集是一种树形数据结构,每一棵树代表一个集合,支持两种操作:
isSameSet方法:查找两个元素是否为同一集合uinionSet方法:合并两个集合
并查集与二叉树这类树形结构并不相同,二叉树的每个节点都维护着他的两个子节点,而并查集则是每个节点都指向其父节点直至根节点,而根节点指向自己,类似于下图这样的结构
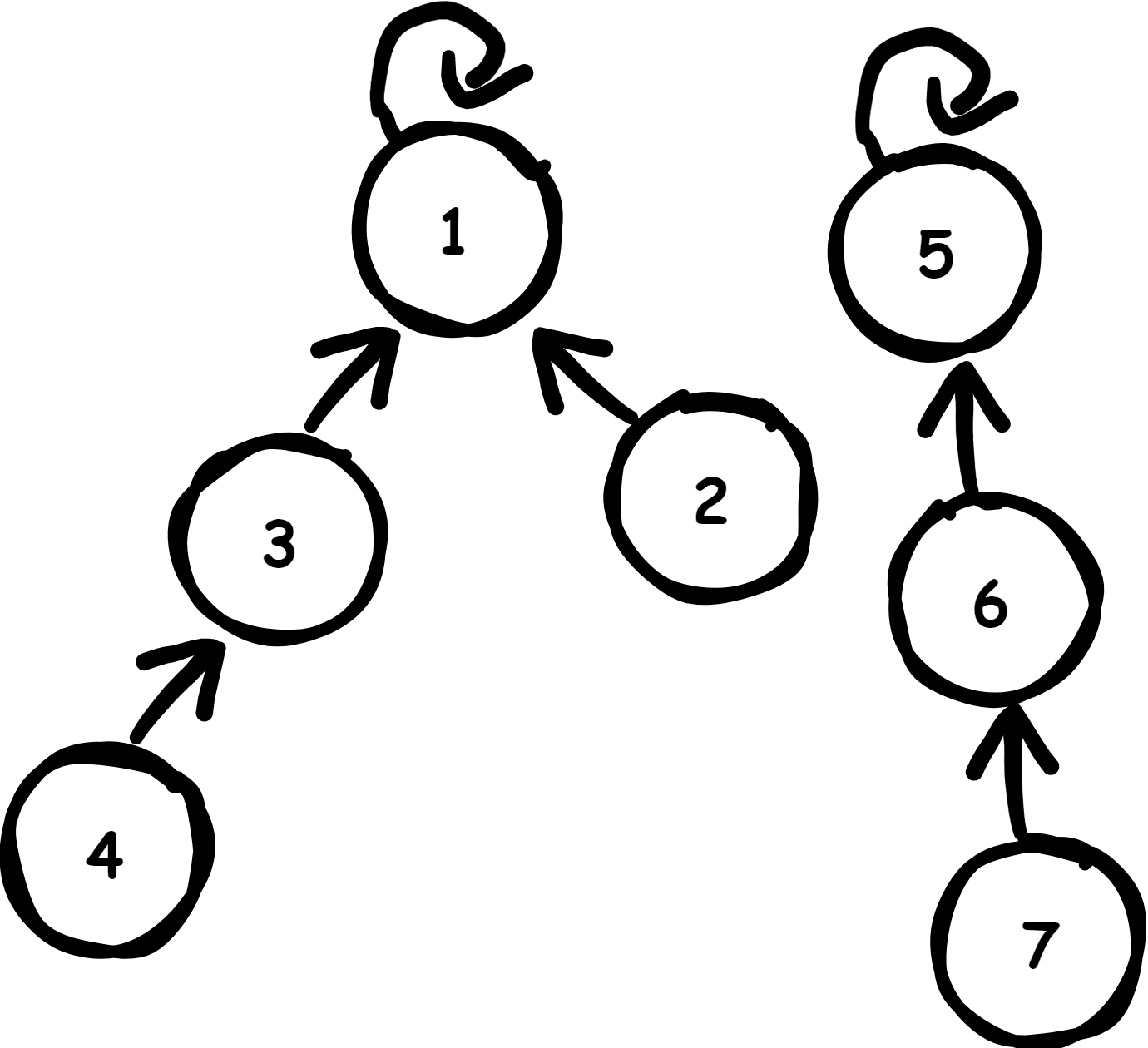
根节点1和5指向自己,他们的子节点指向其父节点,一棵树代表一个集合,对于每一棵树它的根节点又被称为代表节点,因为集合中的任意节点都能找到其根节点,判断两元素是否在同一集合就是判断量元素的根节点(代表节点)是否相同,这也就是isSameSet方法
1和5两个集合如何合并呢?
这很简单只需要其中一棵树的代表节点指向另一棵树的代表节点即可,如下图:
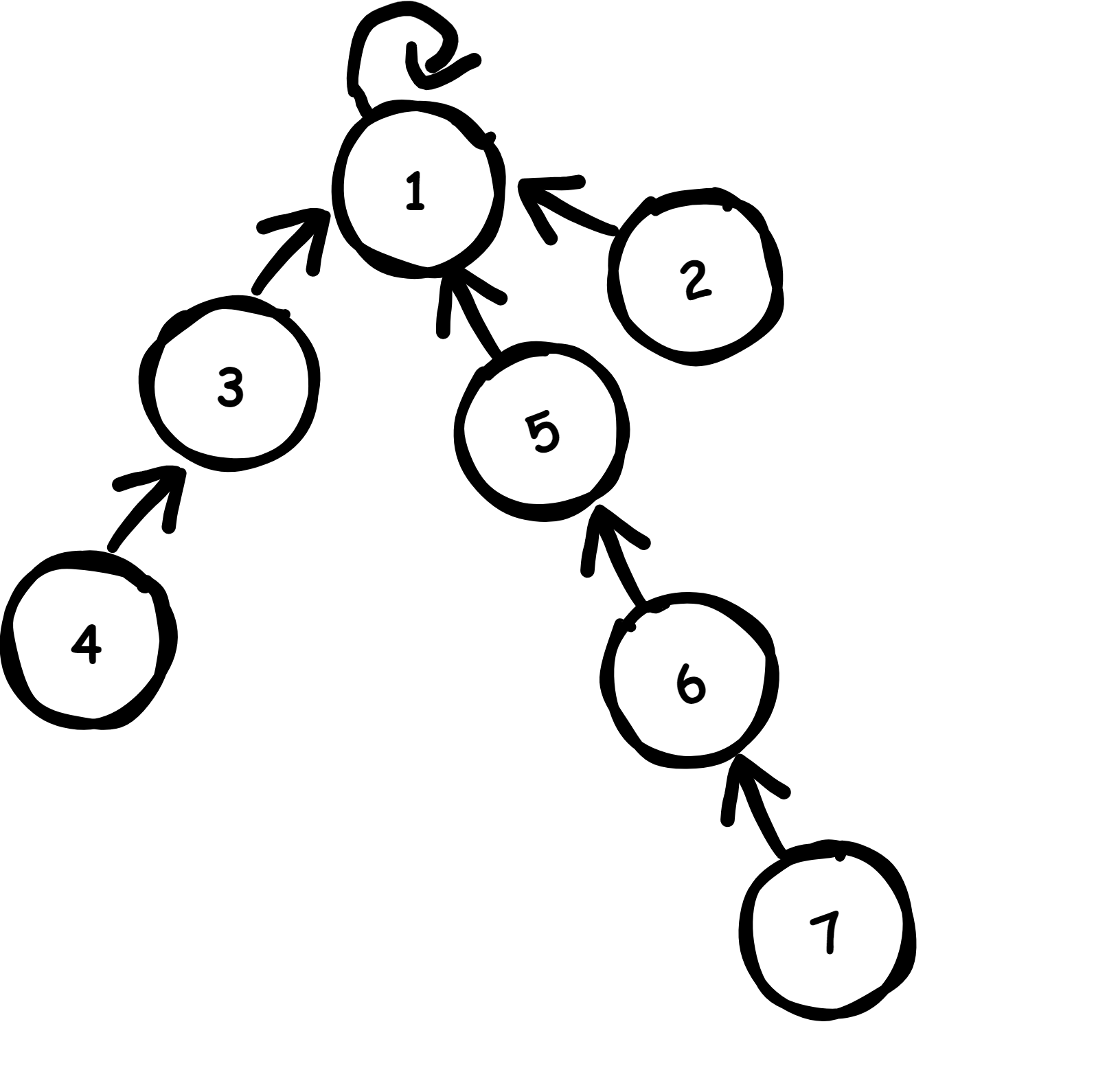
很明显,isSameSet和unionSet方法都需要一个find方法来找到元素的代表节点从而实现合并和查询功能,find方法的实现也是很容易,拿到一个节点一直往上找当自己就是父节点时,就找到代表节点了。
但并查集的厉害还未展现
并查集的厉害之处在于,它的isSameSet和unionSet方法的单次操作的均摊时间复杂度可以达到接近
O
(
1
)
O(1)
O(1),也就是说在通常情况下对于并查集的单次操作我们认为是常数时间
各位是不觉得我在开玩笑,因为很明显集合元素的增长会使得树的高度不断扩大,会导致
find方法的效率变差,没错是这样的,不过并查集的两个优化会使得find方法异常高效近乎就是常数时间
🚀并查集的两个优化
✈️路径压缩
并查集的第一个优化就是路径压缩,实际操作呢也很简单,上图
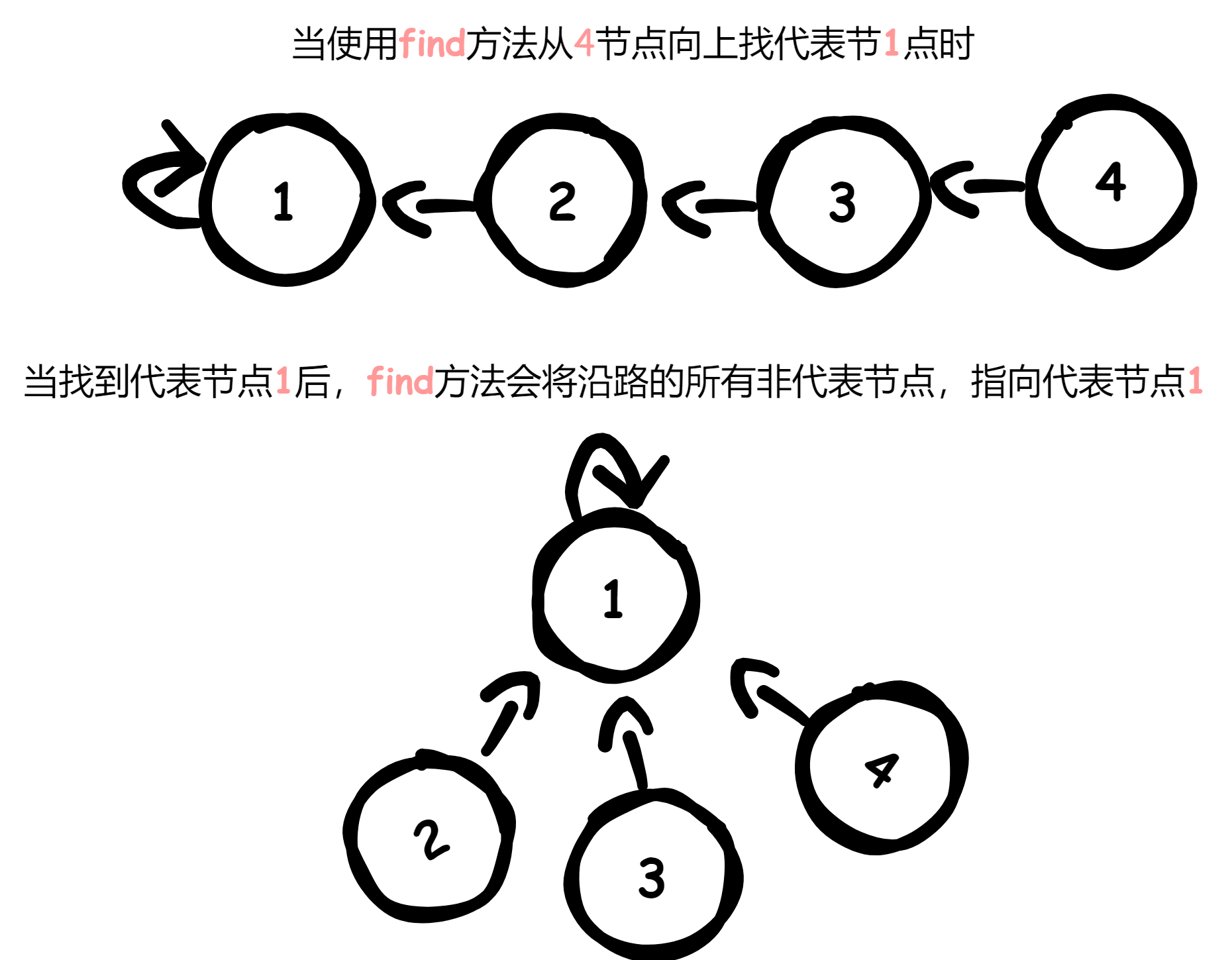
也就是上面这样高度为4的树在经历一次find后,虽然这一次遍历了4个节点但是下一次find操作剩下的节点只需要常数时间就能找到代表节点,即便一个高度为n的数如果从底部find一次,今后剩下的节点都直接指向代表节点,他们进行find操作都是常数时间,每次find操作近乎
O
(
1
)
O(1)
O(1)的时间复杂度,好吧,很遗憾阿辉不会证明,但是上面的解释相信大家能感受到并查集确实能很快
其实在各类算法竞赛中往往并查集只用到路径压缩这一种优化,就可以认为并查集的各种操作时间复杂度为
O
(
1
)
O(1)
O(1)
并查集于1964年发表,于1989年才证明其时间复杂度近乎常数时间
并查集的证明很难,各位有兴趣可以研究🧐
✈️按秩合并
相信各位看到这个按秩合并很懵,没关系我一开始懵
“按秩合并”是一种优化并查集性能的技术。在这里,“秩”可以理解为树的“高度”或“深度”,代表集合的某种“大小”指标。按秩合并的基本思想是总是将较小的树连接到较大的树上,这样可以避免树变得过高,从而减少查找时的路径长度
很官方的话,总感觉不像人说的,其实秩就可以理解为,一个集合中的元素个数,当两个集合合并时,元素个数少的要挂在元素多的集合下,一般情况下元素多的集合的这棵树也相对较高,为了尽量降低树的高度,所以要按秩合并(不如小挂大是吧!)
🚀并查集代码模板
以数组实现并查集,最经典的用法,附上牛客并查集模板测试链接
//MAXN根据题目的数据量进行更改
#define MAXN 101
//用father数组实现每个元素的父节点,比如题目数据量是100,就开101大小的空间
//数组下表与数组元素属于天然的<int,int>的映射表
int father[MAXN];
//size数组里面存着每个集合的元素个数,由代表节点映射
int size[MAXN];
//build方法相当于对并查集初始化
void build(int n){
for(int i = 0;i < n;++i){
father[i] = i;//一开始每个元素的父节点是自己
size[i] = 1;//每个集合都只有一个元素
}
}
//find方法,找集合的代表节点
//一个三目运算很优雅,懒人专用
//int find(int x){
//return father[x] = x != father[x] ? find(father[x]) : x;
//}
int find(int x){
if(x != father[x]){//如果父节点不是自己就调递归
//找到代表节点后返回到上一级递归时,先把当前节点的父节点直接改成代表节点
father[x] = find(father[x]);
}
return father[x];//然后返回当前节点的父节点父节点
}
bool isSameSet(int x,int y){
return find(x) == find(y);//代表节点相同则在同一集合,否则不在
}
void unionSet(int x,int y){
int fx = find(x);//x所在集合代表节点
int fy = find(y);//y所在集合代表节点
//小挂大
if(size[fx] < size[fy]){
father[fx] = fy;
size[fy] += size[fx];//同时更新新集合元素个数
}else{
father[fy] = fx;
size[fx] += size[fy];//同时更新新集合元素个数
}
}
一般在刷题的过程中,并查集的使用往往只需要路径压缩这一优化即可,更简洁并查集模板附上洛谷并查集模板测试链接
#define MAXN 100
int find[MAXN];
void build(int n){
for(int i = 0;i < n;++i){
father[i] = i;
}
}
int find(int x){
return father[x] = father[x] != x ? find(father[x]) : x;
}
bool isSameSet(int x,int y){
return find(x) == find(y);
}
void unionSet(int x,int y){
father[find(x)] = find(y);//没有小挂大了,谁挂谁无所谓
}
虽然很少用到小挂大,但是size并不是用不到,并查集可以给每个集合加上标签,就像size表示大小,还可以根据需要给不同的集合加上标签