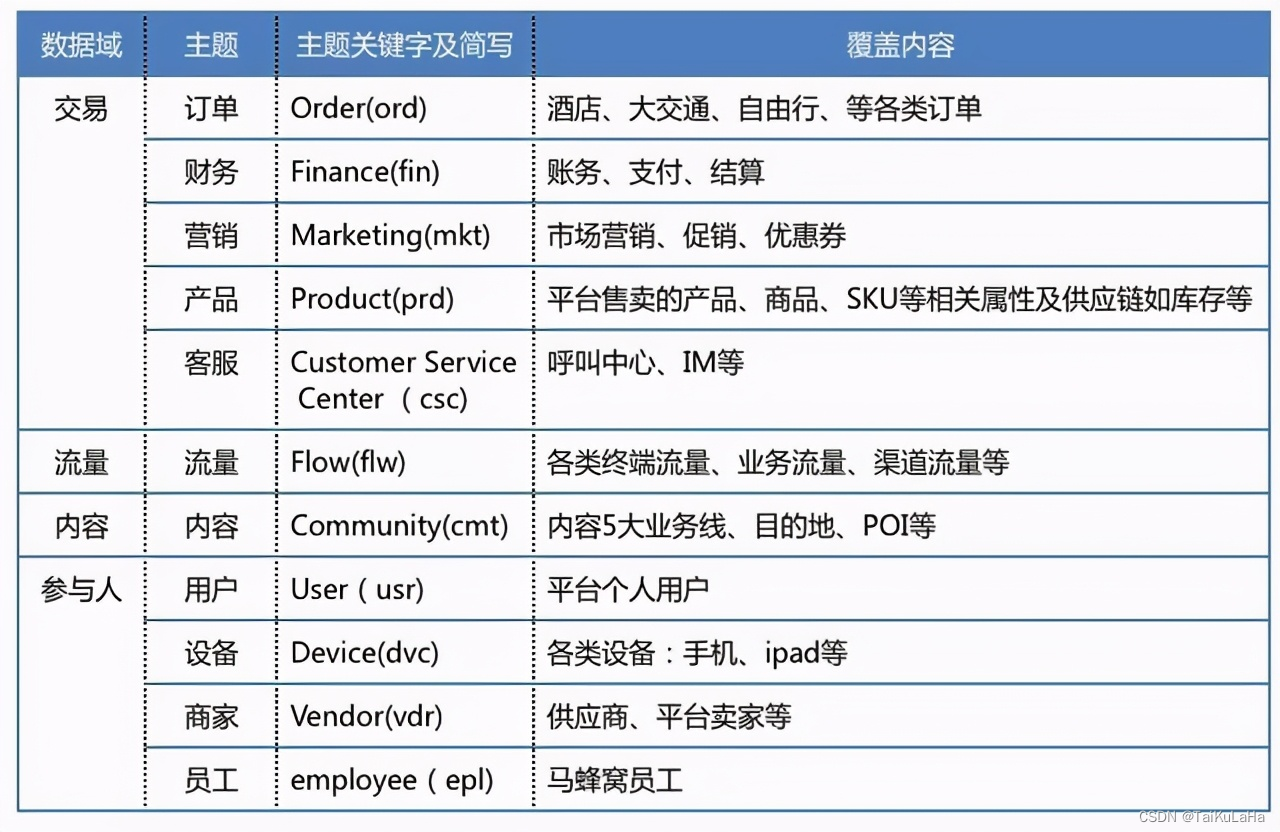
Flink部署支持三种模式:本地部署、Standalone部署、Flink on Yarn部署。
独立(Standalone)模式由Flink自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。
Flink on Yarn模式,把资源管理交给Yarn实现,计算机资源统一由Haoop Yarn管理,生产环境测试。
Yarn(yet another resource negotiator)是一个通用分布式资源管理系统和调度平台,为上层应用提供统一的资源管理和调度。在集群利用率、资源统一管理和数据共享等方面带来巨大好处.
1 基础环境
1.1 服务器环境
操作系统环境为CentOS 8。
1)配置规划集群节点间免密访问
参考相关章节或附录的指南配置,可以有效提供部署和管理效率。
2)配置JAVA环境
参考相关章节或附录的指南配置。
3)配置HDFS存储集群
如果需要与HDFS存储集群集成,则需要提前完成配置。
参考相关章节或附录的指南配置,并且Flink规划集群或设备可网络访问。
4)配置zookeeper集群
如果需要部署Standalone模式,则需要提前完成配置。参考相关章节或附录的指南配置。
5)配置 Yarn集群
如果需要部署Flink on Yarn模式,则需要提前完成配置。参考相关章节或附录的指南配置。
1.2 Flink软件基础配置
在本实践案例中,采用的Flink软件包版本 1.14.5,Hadoop的版本为3.2,Spark软件的根目录(SPARK_HOME)为/opt/flink/flink。
源码下载可以通过官方源和国内源两种方式下载,官方源再国外,下载速度慢,国内源采用清华大学的源,速度相对较快,但只保留最新版本。
Apache官方:https://archive.apache.org/dist/flink/
清华大学:https://mirrors.tuna.tsinghua.edu.cn/apache/flink/
下载软件包:
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.12.tgz
# tar -zxvf flink-1.14.5-bin-scala_2.12.tgz解压软件包:
# tar -zxvf flink-1.14.5-bin-scala_2.12.tgz
# ln -s flink-1.14.5 flink
# ls flink/
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt2 本地模式
最简单的启动方式,其实是不搭建集群,直接本地模式启动。
2.1 配置部署
在本地模式下,不需要启动任何的进程,仅仅是使用本地线程来模拟 Flink 的进程,适用于测试开发调试等,不用更改任何配置信息,只需要保证 JDK8 安装正常即可。
1)启动命令
# /usr/local/flink/bin/start-cluster.sh2)关闭命令
# /usr/local/flink/bin/stop-cluster.sh2.2 测试验证
1)Flink启动
# /usr/local/flink/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host lake01.
Starting taskexecutor daemon on host lake012)访问验证
通过<local主机地址>:8081打开

3)jps查看
# jps
3968 Jps
1941 NameNode
3685 TaskManagerRunner
2790 NodeManager
3418 StandaloneSessionClusterEntrypoint
2159 DataNode4)执行官方用例WordCount
通过执行官方示例,可以看到flink任务运行成功
# /opt/flink/flink/bin/flink run /opt/flink/flink/examples/batch/WordCount.jar
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID d6987ed5b263fc5e297d5be1e28b465a
Program execution finished
Job with JobID d6987ed5b263fc5e297d5be1e28b465a has finished.
Job Runtime: 373 ms
Accumulator Results:
- 843a1470cb2c3e3169dfb25bcda7369d (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
……观察Flink WebUI,如下图

2.3 问题-提示无法连接Yarn服务
一、问题描述
从flink on yarn模式切换为本地模式,执行start-cluster.sh提示如下错误:
2022-10-13 20:38:05,757 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/flink/flink-1.14.5/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2022-10-13 20:38:05,946 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at **lake02/******:8032
2022-10-13 20:38:06,017 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-10-13 20:38:07,043 INFO org.apache.hadoop.ipc.Client [] - Retrying connect to server: **lake02/******:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
……
2022-10-13 20:38:16,052 WARN org.apache.hadoop.ipc.Client [] - Failed to connect to server: **lake02/******:8032: retries get failed due to exceeded maximum allowed retries number: 10
java.net.ConnectException: Connection refused二、问题分析
通过jps发现缺少TaskManagerRunner。
# jps
1902910 StandaloneSessionClusterEntrypoint
1861160 RunJar
1903349 SqlClient
1861350 RunJar
128746 NameNode
200744 QuorumPeerMain
1865793 Kafka
1911504 Jps发现workers和masters文件均为空
三、解决方案
恢复masters和workers的内容
# cat masters
localhost:8081
# cat workers
localhost3 Standalone模式
3.1 概述
Standalone模式是最简单的一种集群模式,不需要Yarn、mesos等资源调度平台,自带集群,资源管理由flink集群管理,开发环境测试使用。
Standalone模式是一种主从模式,主要有两个组件构成分别是JobManager(Master)和TaskManager(Slave)。
当一个应用提交执行时,Flink的各个组件是如何交互协作的:

1)App程序通过rest接口提交给Dispatcher(rest接口是跨平台,并且可以直接穿过防火墙,不需考虑拦截)。
2)Dispatcher把JobManager进程启动,把应用交给JobManager。
3)JobManager拿到应用后,向ResourceManager申请资源(slots),ResouceManager会启动对应的TaskManager进程,TaskManager空闲的slots会向ResourceManager注册。
4)ResourceManager会根据JobManager申请的资源数量,向TaskManager发出指令(这些slots由你提供给JobManager)。
5)接着,TaskManager可以直接和JobManager通信了(它们之间会有心跳包的连接),TaskManager向JobManager提供slots,JobManager向TaskManager分配在slots中执行的任务。
6)最后,在执行任务过程中,不同的TaskManager会有数据之间的交换。
3.2 配置部署
一、节点规划
本次通过虚拟机部署,采用5个节点 ,每一个节点提供一块500GB的硬盘。
| Hostname | IP | 用途 | 说明 |
| labnode01 | 192.168.80.131 | master, jobmanager | OS:centos8.0 |
| labnode02 | 192.168.80.132 | slave、taskmanager | OS:centos8.0 |
| labnode03 | 192.168.80.133 | slave、taskmanager | OS:centos8.0 |
二、修改配置文件
1)修改flink-conf.yaml配置文件:
##配置master节点ip
jobmanager.rpc.address: 192.168.1.100
##配置每个节点的可用slot,1 核CPU对应 1 slot
##the number of available CPUs per machine
taskmanager.numberOfTaskSlots: 30
##默认并行度 1 slot资源
parallelism.default: 12)修改master和work配置文件
Master文件
# cat masters
labnode01:8081workers文件
labnode02
labnode03将以上文件分发各节点对应文件夹。
三、集群启动和关闭
在master节点上执行此脚本,就可以启动集群,前提要保证master节点到slaver节点可以免密登录。
因为它的启动过程是:先在master节点启动jobmanager进程,然后ssh到各slaver节点启动taskmanager进程。
启动集群
# /usr/local/flink/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host lake02.
Starting taskexecutor daemon on host lake03.
Starting taskexecutor daemon on host lake04.
Starting taskexecutor daemon on host slake05.停止集群:
# /usr/local/flink/bin/stop-cluster.sh3.3 运行验证
1)启动Flink
# /usr/local/flink/bin/start-cluster.sh2)访问flink webUI

3)执行官方用例WordCount
执行命令:
# /usr/local/flink/bin/flink run /usr/local/flink/examples/batch/WordCount.jar
……
- f27663f6191a378629eea720a988cc53 (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
……查看Flink WebUI

4 Flink On Yarn模式
4.1 概述
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。
在目前大数据生态中,国内应用最为广泛的资源管理平台是Yarn。Yarn(yet another resource negotiator)是一个通用分布式资源管理系统和调度平台,为上层应用提供统一的资源管理和调度。在集群利用率、资源统一管理和数据共享等方面带来巨大好处。
Flink on Yarn 企业生产环境运行Flink任务大多数的选择。
在强大的Yarn平台上,Flink是如何在Yarn上集成部署的,其过程是:客户端把Flink 应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的 NodeManager 申请容器。在这些容器上,Flink会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的 Slot 数量动态分配TaskManager资源。
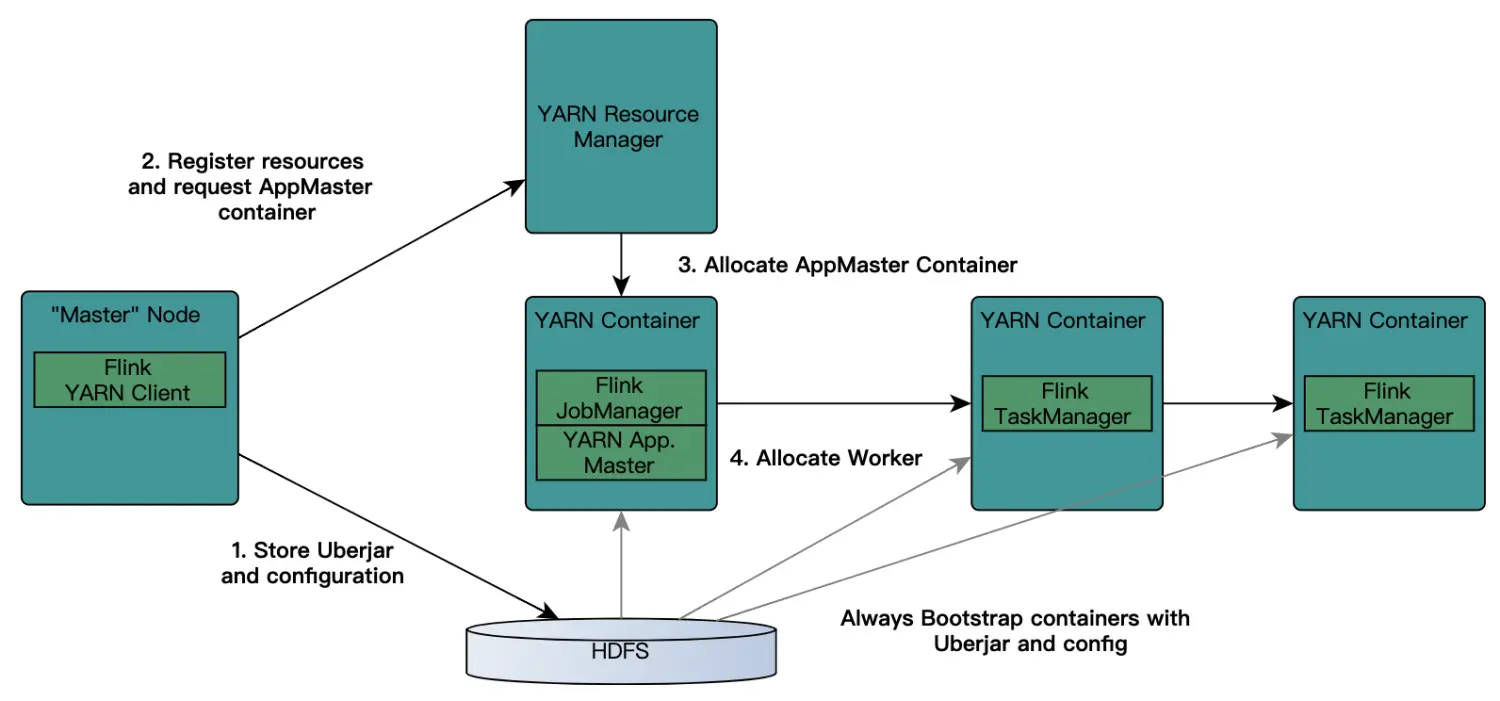
1)提交App之前,先上传Flink的Jar包和配置到HDFS,以便JobManager和TaskManager共享HDFS的数据。
2)客户端向ResourceManager提交Job,ResouceManager接到请求后,先分配container资源,然后通知NodeManager启动ApplicationMaster。
3)ApplicationMaster会加载HDFS的配置,启动对应的JobManager,然后JobManager会分析当前的作业图,将它转化成执行图(包含了所有可以并发执行的任务),从而知道当前需要的具体资源。
4)接着,JobManager会向ResourceManager申请资源,ResouceManager接到请求后,继续分配container资源,然后通知ApplictaionMaster启动更多的TaskManager(先分配好container资源,再启动TaskManager)。container在启动TaskManager时也会从HDFS加载数据。
5)最后,TaskManager启动后,会向JobManager发送心跳包。JobManager向TaskManager分配任务。
Flink提供了yarn上运行的3模式,分别为Session-Cluster,Application Mode和Per-Job-Cluster模式。
4.2 配置部署
一、节点规划
本次通过虚拟机部署,采用5个节点 ,每一个节点提供一块500GB的硬盘。
| Hostname | IP | 用途 | 说明 |
| labnode01 | 192.168.80.131 | master, jobmanager | |
| labnode02 | 192.168.80.132 | slave、taskmanager | |
| labnode03 | 192.168.80.133 | slave、taskmanager |
二、Yarn环境配置
在Yarn-site.xml中配置关闭内存校验。
Yarn-site.xml是hadoop中/etc/hadoop下的配置文件,否则flink任务可能会因为内存超标而被Yarn集群主动杀死。
<!-- Mem Check Start -->
<!-- 设置不检查虚拟内存的值,不然内存不够会报错 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- Mem Check end -->将修改后的配置文件分发到各节点,然后重启Yarn集群。
三、将Flink软件和配置文件分发到Flink集群规划节点
将Flink的配置文件conf/flink-conf.yaml恢复为初始状态。
4.3 Session-Cluster模式(yarn-session)
4.3.1 概述

Session-Cluster模式需要先启动Flink集群,向Yarn申请资源。以后提交任务都向这里提交。这个Flink集群会常驻在yarn集群中,除非手工停止。
在向Flink集群提交Job的时候, 如果资源被用完了,则新的Job不能正常提交.
缺点: 如果提交的作业中有长时间执行的大作业, 占用了该Flink集群的所有资源, 则后续无法提交新的job.
所以, Session-Cluster适合那些需要频繁提交的多个小Job, 并且执行时间都不长的Job。
会话模式有两种操作模式:
- 附加模式(默认):yarn-session.sh客户端将 Flink 集群提交给 YARN,但客户端一直在运行,跟踪集群的状态。如果集群失败,客户端将显示错误。如果客户端被终止,它也会发出集群关闭的信号。
- 分离模式(-d或--detached):yarn-session.sh客户端将 Flink 集群提交给 YARN,然后客户端返回。需要再次调用客户端或 YARN 工具来停止 Flink 集群。
4.3.2 常用命令
1)yarn-session.sh参数说明
使用bin/yarn-session.sh --help 查看可用参数:
Usage:
Optional
-at,--applicationType <arg> Set a custom application type for the application on Yarn
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running Yarn session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Set to Yarn-cluster to use Yarn execution mode.
-nl,--nodeLabel <arg> Specify Yarn node label for the Yarn application
-nm,--name <arg> Set a custom name for the application on Yarn
-q,--query Display available Yarn resources (memory, cores)
-qu,--queue <arg> Specify Yarn queue.
-s,--slots <arg> Number of slots per TaskManager
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--Yarndetached If present, runs the job in detached mode (deprecated; use non-Yarn specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode2)启动命令
使用Yarn-session.sh命令申请资源初始化一个Flink集群,命令格式如下:
bin/yarn-session.sh <参数>如示例:
# /opt/flink/flink/bin/yarn-session.sh -d3)关闭Flink
停止 flink on Yarn 会话模式中的flink集群
yarn application -kill <appid>或
echo "stop" | ./bin/flink -id <appid>如示例:
# echo "stop" | /opt/flink/flink/bin/flink -id application_1661480406159_00254.3.3 运行验证
1)启动Flink
# /opt/flink/flink/bin/yarn-session.sh -d执行结果:

访问Yarn WebUI:
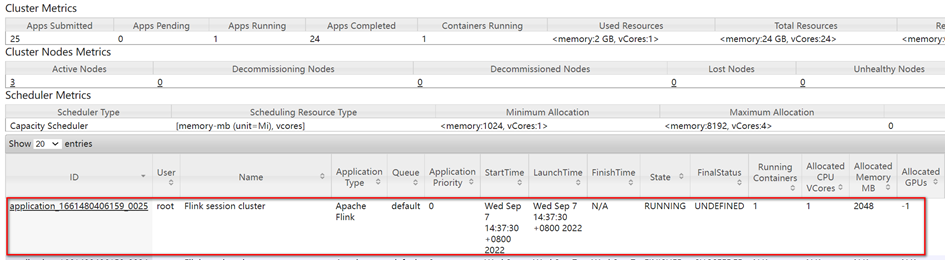
访问Flink WebUI,http://lake04:38347
2)运行官方用例WordCount
# /opt/flink/flink/bin/flink run /opt/flink/flink/examples/batch/WordCount.jar命令行执行结果:
Flink WebUI的首页:
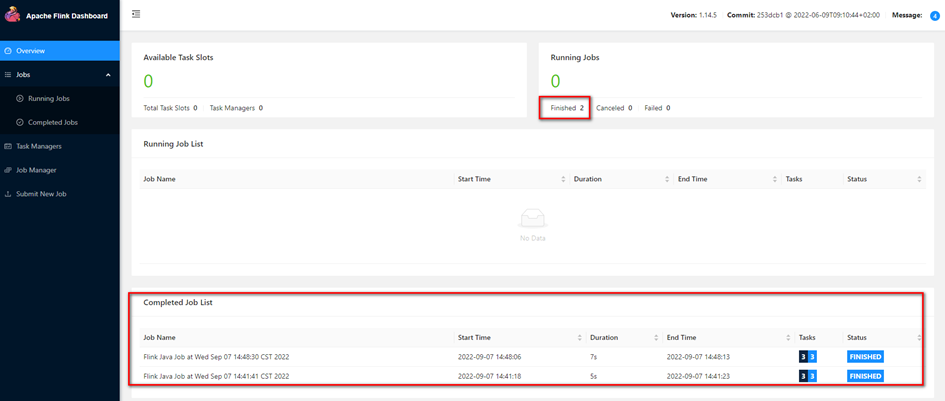
Flink WebUI中的结果:

3)关闭
执行命令关闭Flink
# echo "stop" | /opt/flink/flink/bin/flink -id application_1661480406159_00254.4 Per-Job-Cluster模式(yarn-cluster)
4.4.1 概述
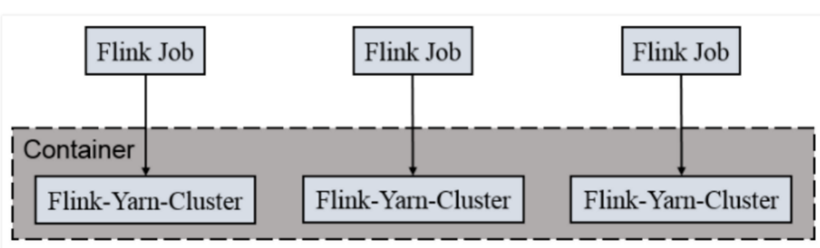
一个Job会对应一个Flink集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
4.4.2 常用命令
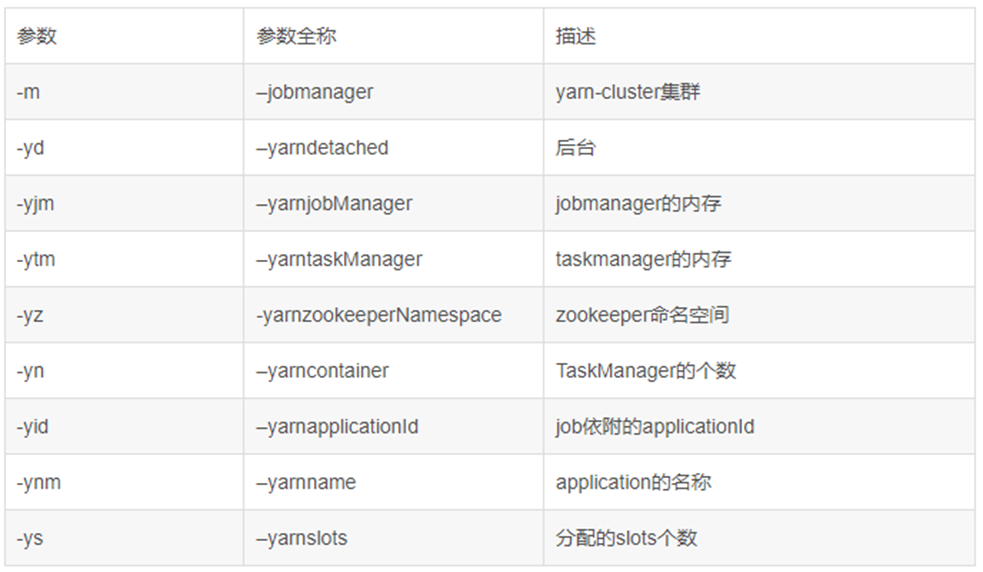
1)参数说明
flink run -m yarn-cluster --help;可用参数:
该模式下不需要先启动 yarn-session,确保 Hadoop 集群是健康的情况下直接提交 Job 命令:
bin/flink -m yarn-cluster <参数> <jar file>如示例:
# /opt/flink/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /opt/flink/flink/examples/batch/WordCount.jar4.4.3 运行验证
1)启动并执行官方用例WordCount
# /opt/flink/flink/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /opt/flink/flink/examples/batch/WordCount.jar执行结果:
访问Yarn WebUI:
4.4.4 优缺点
优点:随到随用,只有任务需要运行时才会开启flink集群;运行完就关闭释放资源,资源利用更合理;
缺点:对于小作业不太友好,
适用场景:适合大作业,长时间运行的大作业。
4.5 Application Mode
4.5.1 概述
Application Mode会在Yarn上启动集群, 应用jar包的main函数(用户类的main函数)将会在JobManager上执行. 只要应用程序执行结束, Flink集群会马上被关闭. 也可以手动停止集群.
与Per-Job-Cluster的区别: 就是Application Mode下, 用户的main函数式在集群中执行的
官方建议:
出于生产的需求, 我们建议使用Per-job or Application Mode,因为他们给应用提供了更好的隔离!

4.5.2 运行验证
启动
# /opt/flink/flink/bin/flink run-application -t yarn-application /opt/flink/flink/examples/batch/WordCount.jar执行结果:
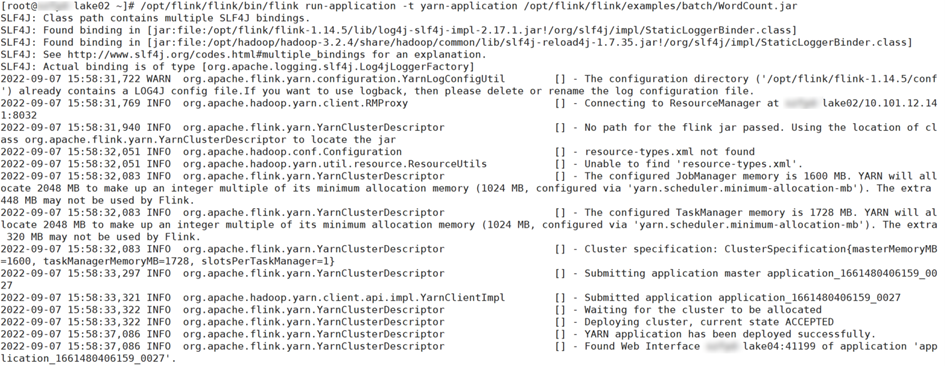
访问Yarn WebUI:
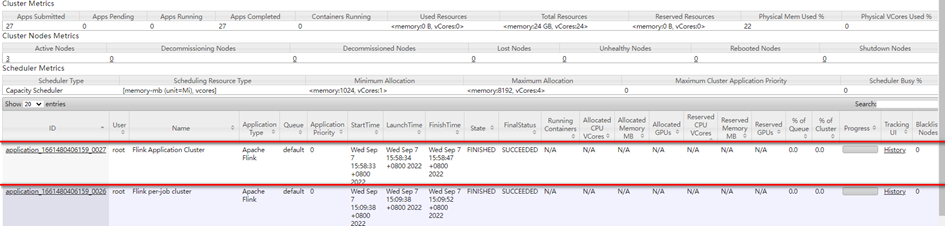
4.5.3 常见问题
任务提示 Could not allocate the required slot within slot request tim
一、错误日志
Caused by: java.util.concurrent.CompletionException: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeout
at org.apache.flink.runtime.scheduler.DefaultScheduler.lambda$assignResource$8(DefaultScheduler.java:539)
... 37 more
Caused by: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeout
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:607)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
... 35 more
Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Slot request bulk is not fulfillable! Could not allocate the required slot within slot request timeout
at org.apache.flink.runtime.jobmaster.slotpool.PhysicalSlotRequestBulkCheckerImpl.lambda$schedulePendingRequestBulkWithTimestampCheck$0(PhysicalSlotRequestBulkCheckerImpl.java:86)
... 28 more
Caused by: java.util.concurrent.TimeoutException: Timeout has occurred: 300000 ms
... 29 more解决方案
将flink的配置文件conf/flink-conf.yaml恢复为初始状态,重新启动flink的Yarn session。
问题FLINK Could not get job jar and dependencies from JAR file: JAR file does not exist:
一、问题描述
使用flink客户端将执行flink提交到Yarn,输入-yjm参数提示错误
# /opt/flink/flink/bin/flink run -m Yarn-cluster -yn 2 -yjm 1024 -ytm 1024 /opt/flink/flink/examples/batch/WordCount.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink/flink-1.14.5/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-3.2.4/share/hadoop/common/lib/slf4j-reload4j-1.7.35.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Could not get job jar and dependencies from JAR file: JAR file does not exist: -yn二、问题分析
flink1.8版本之后已弃用该参数,ResourceManager将自动启动所需的尽可能多的容器,以满足作业请求的并行性。
三、解决方案
去掉即可
Deployment took more than 60 seconds. Please check if the requested resources are
一、问题描述
日志信息如下:
INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster截图如下:

二、解决方案
配置yarn-site.xml
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>102400</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>51200</value>
</property>Flink读取Hudi表时报错lassNotFoundException: *mapred.FileInputFormat
一、问题现象:
执行“select * from t1;”报错,报错信息如下:
Flink SQL> select * from t1;
……
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.mapred.FileInputFormat二、原因分析
mapred代表的是hadoop旧API,而mapreduce代表的是hadoop新的API
三、解决办法
解决办法为复制集群的hadoop-mapreduce-client-core.jar到Flink/lib中。
读取数据表失败NoSuchMethodError: *Preconditions.checkArgument
一、问题描述
创建表格式如下
CREATE TABLE t2(
uuid VARCHAR(20),
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://10.101.12.140:9000/datas/flink-hudi/test0907/t1',
'table.type' = 'MERGE_ON_READ',
'read.tasks' = '1',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210316134557',
'read.streaming.check-interval' = '4'
);
INSERT INTO t2 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');执行成功,然后执行表内容查询
select * from t2;报出如下错误:
Flink SQL> select * from t2;
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputForm
Flink SQL>二、原因分析
mapred代表的是hadoop旧API,而mapreduce代表的是hadoop新的API
三、解决办法
解决办法为复制集群的hive-exec-3.1.3.jar到各节点的flink/lib中。(注意hive-exec和hadoop版本的匹配)
启动失败NoSuchMethodError: *Preconditions.checkArgument
一、错误描述
通过bin/yarn-session.sh -d启动yarn-session失败,报错信息如下:
The program finished with the following exception:
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.lang.reflect.InvocationTargetException
at org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl.getClient(RpcClientFactoryPBImpl.java:81)
at org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC.getProxy(HadoopYarnProtoRPC.java:48)
……
... 21 more
Caused by: java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
……
at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.<init>(ApplicationClientProtocolPBClientImpl.java:209)
... 26 more二、错误原因
Preconditions是guava下的工具类,hudi的源码依赖了不同的项目,这些项目使用了不同的guava版本,所报错误是由于运行时guava版本过旧,没有相应的方法。
三、解决方案
在HADOOP_HOME下查询hadoop使用的guava版本,将其拷贝到FLINK_HOME/lib下:
# find ./ -name guava*
./share/hadoop/common/lib/guava-27.0-jre.jar
./share/hadoop/hdfs/lib/guava-27.0-jre.jar将文件复制到所有yarn集群的FLINK_HOME/lib下。
重新执行bin/yarn-session.sh -d,成功。
通过yarn启动flink失败-连接yarn失败
通过yarn模式启动flink,报出如下异常,关键信息如下:
# /usr/local/flink/bin/yarn-session.sh -d
….
2022-10-27 11:04:30,332 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at /0.0.0.0:8032
…
2022-10-27 11:04:41,153 WARN org.apache.hadoop.ipc.Client [] - Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 9 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-10-27 11:04:41,153 WARN org.apache.hadoop.ipc.Client [] - Failed to connect to server: 0.0.0.0/0.0.0.0:8032: retries get failed due to exceeded maximum allowed retries number: 10
java.net.ConnectException: Connection refused
……原因分析:
1)检查是否启动hadoop集群, 如果没有启动, 是无法连接到hadoop的yarn。
2)flink运行于yarn上,flink要能找到hadoop配置,因为要连接到yarn的resourcemanager和hdfs。
如果正常启动还无法连接yarn, 可以查看一下hadoop的环境变量是否配置好。
在本实例中,时因为无法获取HADOOP_CONF_DIR的配置信息导致问题发生。
二、解决方案
设置HADOOP_CONF_DIR环境变量,并使之生效。
# cat /etc/profile | grep HADOOP_CONF_DIR
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# source /etc/profile然后重新启动flink。
BTW:如果已经设置HADOOP_CONF_DIR环境变量,可能由于某种原因HADOOP_CONF_DIR环境变量没有生效,这个原因有很多。
5 参考资料
[01] https://blog.csdn.net/Vector97/article/details/117398947
[02] https://www.jianshu.com/p/8c9c897ea72a