Android下SF合成流程重学习之onMessageInvalidate
引言
虽然看了很多关于Android Graphics图形栈的文章和博客,但是都没有形成自己的知识点。每次学习了,仅仅是学习了而已,没有形成自己的知识体系,这次趁着有时间,这次必须把这个事情干透彻了!
本篇引用的代码,主要是Android R的。
并且Android下Graphics图形栈牵涉的点,太多了,这篇博客我们着重分析SF合成流程重学习之onMessageInvalidate的处理流程!
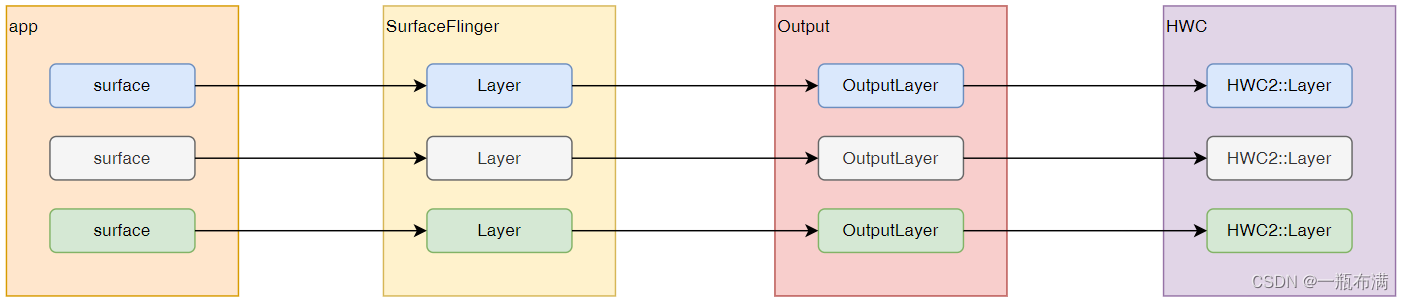
SurfaceFlinger layer之间的对应关系
先用一张图来看下各个部分之间layer的对应关系。接下来会根据这个图来解析是如何进行转换的,如下:
一. SF处理事务和处理Buffer
在SF的onMessageInvalidate主要是用来,处理事物和处理相关Buffer的,我们在下面的博客中详细分析!

1.1 onMessageInvalidate
文件: frameworks/native/services/surfaceflinger/Surfaceflinger.cpp
void SurfaceFlinger::onMessageInvalidate(nsecs_t expectedVSyncTime) {
ATRACE_CALL();
const nsecs_t frameStart = systemTime();
// expectedVSyncTime 是vsync回调带过来的时间戳,通过nextAnticipatedVSyncTimeFrom 计算得到
if (expectedVSyncTime >= frameStart) {
mExpectedPresentTime = expectedVSyncTime;
} else {
mExpectedPresentTime = mScheduler->getDispSyncExpectedPresentTime(frameStart);
}
// 存储上一帧的expectedVSyncTime
const nsecs_t lastScheduledPresentTime = mScheduledPresentTime;
mScheduledPresentTime = expectedVSyncTime;
...
// 根据上一帧的present fence判断当前这一帧是否pending
const TracedOrdinal<bool> framePending = {"PrevFramePending",
previousFramePending(graceTimeForPresentFenceMs)};
// 若framePending 或者 上一帧present fence释放的时间 > 上一帧vsync计算的时间戳 + vsync周期的一半
// 则当前帧要丢掉
DisplayStatInfo stats;
mScheduler->getDisplayStatInfo(&stats);
const nsecs_t frameMissedSlop = stats.vsyncPeriod / 2;
const nsecs_t previousPresentTime = previousFramePresentTime();
const TracedOrdinal<bool> frameMissed = {"PrevFrameMissed",
framePending ||
(previousPresentTime >= 0 &&
(lastScheduledPresentTime <
previousPresentTime - frameMissedSlop))};
// 根据合成类型判断丢帧的类型
const TracedOrdinal<bool> hwcFrameMissed = {"PrevHwcFrameMissed",
mHadDeviceComposition && frameMissed};
const TracedOrdinal<bool> gpuFrameMissed = {"PrevGpuFrameMissed",
mHadClientComposition && frameMissed};
...
// 这部分涉及帧率切换,先是通过performSetActiveConfig 将新的帧率给到hwc,然后下一帧再更新sf这边的状态
if (mSetActiveConfigPending) {
if (framePending) {
mEventQueue->invalidate();
return;
}
// We received the present fence from the HWC, so we assume it successfully updated
// the config, hence we update SF.
mSetActiveConfigPending = false;
ON_MAIN_THREAD(setActiveConfigInternal());
}
}
// mPropagateBackpressure 可以通过adb shell setprop debug.sf.disable_backpressure x 来控制,表示系统是否允许丢帧
// 若允许丢帧则skip这次刷帧
if (framePending && mPropagateBackpressure) {
if ((hwcFrameMissed && !gpuFrameMissed) || mPropagateBackpressureClientComposition) {
signalLayerUpdate();
return;
}
}
....
bool refreshNeeded;
{
ConditionalLockGuard<std::mutex> lock(mTracingLock, mTracingEnabled);
// 主要的逻辑在这两个函数,简单理解为处理layer或者display的事务和layer的buffer
refreshNeeded = handleMessageTransaction();
refreshNeeded |= handleMessageInvalidate();
...
}
// 帧率切换,SurfaceFlinger主线程执行
ON_MAIN_THREAD(performSetActiveConfig());
...
// 若layer的事务有变化或者有新的buffer,则触发refresh
signalRefresh();
}
上述onMessageInvalidate概括来说,其主要处理的事情如下:
- 判断当前帧是否丢掉
- handleMessageTransaction 处理layer或者display事务
- handleMessageInvalidate 处理应用queue过来的Buffer
- 帧率切换
- 触发刷新流程
1.2 handleMessageTransaction
文件: frameworks/native/services/surfaceflinger/Surfaceflinger.cpp
bool SurfaceFlinger::handleMessageTransaction() {
ATRACE_CALL();
// 获取当前的mTransactionFlags,mTransactionFlags 由setTransactionFlags 赋值,比如CreateLayer时会给mTransactionFlags 赋值eTransactionNeeded
// createDisplay 时会给mTransactionFlags 赋值 eDisplayTransactionNeeded
uint32_t transactionFlags = peekTransactionFlags();
// flushTransactionQueues 会消费transactionQueue,transactionQueue 是上层通过SurfaceComposerClient 设的,然后再通过binder设置给sf这边
// setDisplayStateLocked: 处理display的事务
// setClientStateLocked: 处理layer的事务
// 这两部分事务都存放在surfaceflinger的mCurrentState 里面
bool flushedATransaction = flushTransactionQueues();
// 有新的事务则要执行handleTransaction
bool runHandleTransaction =
(transactionFlags && (transactionFlags != eTransactionFlushNeeded)) ||
flushedATransaction ||
mForceTraversal;
// 处理layer和display的事务
if (runHandleTransaction) {
handleTransaction(eTransactionMask);
} else {
getTransactionFlags(eTransactionFlushNeeded);
}
if (transactionFlushNeeded()) {
setTransactionFlags(eTransactionFlushNeeded);
}
return runHandleTransaction;
}
//来看下display和layer有哪些事务处理
文件: frameworks/native/services/surfaceflinger/Surfaceflinger.cpp
// display的事务,包括display Surface, layerStack , Projection , viewport, Size发生变化时附上eDisplayTransactionNeeded 这个flags
uint32_t SurfaceFlinger::setDisplayStateLocked(const DisplayState& s) {
const ssize_t index = mCurrentState.displays.indexOfKey(s.token);
if (index < 0) return 0;
uint32_t flags = 0;
DisplayDeviceState& state = mCurrentState.displays.editValueAt(index);
const uint32_t what = s.what;
if (what & DisplayState::eSurfaceChanged) {
if (IInterface::asBinder(state.surface) != IInterface::asBinder(s.surface)) {
state.surface = s.surface;
flags |= eDisplayTransactionNeeded;
}
}
if (what & DisplayState::eLayerStackChanged) {
if (state.layerStack != s.layerStack) {
state.layerStack = s.layerStack;
flags |= eDisplayTransactionNeeded;
}
}
if (what & DisplayState::eDisplayProjectionChanged) {
if (state.orientation != s.orientation) {
state.orientation = s.orientation;
flags |= eDisplayTransactionNeeded;
}
if (state.frame != s.frame) {
state.frame = s.frame;
flags |= eDisplayTransactionNeeded;
}
if (state.viewport != s.viewport) {
state.viewport = s.viewport;
flags |= eDisplayTransactionNeeded;
}
}
if (what & DisplayState::eDisplaySizeChanged) {
if (state.width != s.width) {
state.width = s.width;
flags |= eDisplayTransactionNeeded;
}
if (state.height != s.height) {
state.height = s.height;
flags |= eDisplayTransactionNeeded;
}
}
return flags;
}
文件: frameworks/native/services/surfaceflinger/Surfaceflinger.cpp
// layer的事务,包括ePositionChanged, eLayerChanged, eAlphaChanged 等等,跟上层的surface设置一样,同样的事务同步给layer
uint32_t SurfaceFlinger::setClientStateLocked(
const ComposerState& composerState, int64_t desiredPresentTime, int64_t postTime,
bool privileged,
std::unordered_set<ListenerCallbacks, ListenerCallbacksHash>& listenerCallbacks) {
...
sp<Layer> layer = nullptr;
if (s.surface) {
layer = fromHandleLocked(s.surface).promote();
...
if (what & layer_state_t::eDeferTransaction_legacy) {
layer->pushPendingState();
}
// Only set by BLAST adapter layers
if (what & layer_state_t::eProducerDisconnect) {
layer->onDisconnect();
}
if (what & layer_state_t::ePositionChanged) {
if (layer->setPosition(s.x, s.y)) {
flags |= eTraversalNeeded;
}
}
...
}
通过setDisplayStateLocked 和 setClientStateLocked 获取了display和layer的事务变化的flag,并且setClientStateLocked还将layer与surface进行了事务的同步。
文件: frameworks/native/services/surfaceflinger/Surfaceflinger.cpp
void SurfaceFlinger::handleTransactionLocked(uint32_t transactionFlags)
{
...
if ((transactionFlags & eTraversalNeeded) || mForceTraversal) {
mForceTraversal = false;
// 遍历mCurrentState 里面的layer,对有事务变化的layer进行处理,doTransaction 主要的处理逻辑是对sync ponit的处理,
// sync ponit用于延迟显示的一些layer,根据FrameNumber进行同步,如果当前帧数达到了设定值,latchBuffer就可以消费这个layer
mCurrentState.traverse([&](Layer* layer) {
uint32_t trFlags = layer->getTransactionFlags(eTransactionNeeded);
if (!trFlags) return;
const uint32_t flags = layer->doTransaction(0);
if (flags & Layer::eVisibleRegion)
mVisibleRegionsDirty = true;
if (flags & Layer::eInputInfoChanged) {
mInputInfoChanged = true;
}
});
}
// 处理 display的 事务逻辑
if (transactionFlags & eDisplayTransactionNeeded) {
processDisplayChangesLocked();
processDisplayHotplugEventsLocked();
}
...
// SurfaceFlinger维持mCurrentState 和 mDrawingState 两个状态,是个大的结构体,mCurrentState 可以理解为下一帧的
// layer和display的状态, mDrawingState 可以理解为当前帧的状态,commitTransaction 将 mCurrentState 更新到这一帧的状态
commitTransaction();
}
handleMessageTransaction主要的作用是处理display和layer的事物,将上层的surface和底层的layer属性做个同步,涉及到很多的细节以后遇到具体场景来分析,最后将mCurrentState 赋给 mDrawingState 更新到当前这一帧的状态。
1.3 handleMessageInvalidate
我们接着继续往下看,累啊,学习,搞起来~
文件:frameworks/native/services/surfaceflinger/Surfaceflinger.cpp
bool SurfaceFlinger::handleMessageInvalidate() {
ATRACE_CALL();
// 处理queue过来的Buffer
bool refreshNeeded = handlePageFlip();
if (mVisibleRegionsDirty) {
// 如果可见区域有变化,则重新计算layer的范围
computeLayerBounds();
}
//判断需要刷新的layer是否属于当前Output
for (auto& layer : mLayersPendingRefresh) {
Region visibleReg;
visibleReg.set(layer->getScreenBounds());
invalidateLayerStack(layer, visibleReg);
}
mLayersPendingRefresh.clear();
return refreshNeeded;
}
bool SurfaceFlinger::handlePageFlip()
{
...
// 遍历 mDrawingState里面的layer,判断该layer是否可在当前vsync内显示,如果queueBuffer带过来的时间戳大于Vsync的时间戳,则表示该layer不能在当前vsync内显示
// 能够显示的layer放到mLayersWithQueuedFrames 里面
mDrawingState.traverse([&](Layer* layer) {
if (layer->hasReadyFrame()) {
frameQueued = true;
if (layer->shouldPresentNow(expectedPresentTime)) {
mLayersWithQueuedFrames.push_back(layer);
} else {
ATRACE_NAME("!layer->shouldPresentNow()");
layer->useEmptyDamage();
}
} else {
layer->useEmptyDamage();
}
});
...
// 遍历mLayersWithQueuedFrames 里面的layer,执行latchBuffer,在latchBuffer里面消费Buffer
// 成功消费的layer放到mLayersPendingRefresh 里面
for (auto& layer : mLayersWithQueuedFrames) {
if (layer->latchBuffer(visibleRegions, latchTime, expectedPresentTime)) {
mLayersPendingRefresh.push_back(layer);
}
layer->useSurfaceDamage();
if (layer->isBufferLatched()) {
newDataLatched = true;
}
...
// 当有需要消费Buffer的layer则返回true
return !mLayersWithQueuedFrames.empty() && newDataLatched;
文件: frameworks/native/services/surfaceflinger/BufferLayer.cpp
bool BufferLayer::latchBuffer(bool& recomputeVisibleRegions, nsecs_t latchTime,
nsecs_t expectedPresentTime) {
...
// 执行顺序BufferQueueLayer-> updateTexImage ==> BufferLayerConsumer-> updateTexImage,具体逻辑在
// BufferLayerConsumer 里面
status_t err = updateTexImage(recomputeVisibleRegions, latchTime, expectedPresentTime);
// 更新mBufferInfo里的buffer,这个变量是在BufferQueueLayer里面维护
err = updateActiveBuffer();
if (err != NO_ERROR) {
return false;
}
//更新mBufferInfo的FrameNumber
err = updateFrameNumber(latchTime);
if (err != NO_ERROR) {
return false;
}
// 更新到mBufferInfo
gatherBufferInfo();
...
}
文件: frameworks/native/services/surfaceflinger/BufferLayerConsumer.cpp
status_t BufferLayerConsumer::updateTexImage(BufferRejecter* rejecter, nsecs_t expectedPresentTime,
bool* autoRefresh, bool* queuedBuffer,
uint64_t maxFrameNumber) {
...
BufferItem item;
// acquireBuffer:消费queue过来的Buffer,放到item里面
status_t err = acquireBufferLocked(&item, expectedPresentTime, maxFrameNumber);
...
// 更新BufferLayerConsumer 状态,都是从queueBuffer设置而来
err = updateAndReleaseLocked(item, &mPendingRelease);
...
}
status_t BufferLayerConsumer::acquireBufferLocked(BufferItem* item, nsecs_t presentWhen,
uint64_t maxFrameNumber) {
status_t err = ConsumerBase::acquireBufferLocked(item, presentWhen, maxFrameNumber);
...
if (item->mGraphicBuffer != nullptr) {
std::lock_guard<std::mutex> lock(mImagesMutex);
if (mImages[item->mSlot] == nullptr || mImages[item->mSlot]->graphicBuffer() == nullptr ||
mImages[item->mSlot]->graphicBuffer()->getId() != item->mGraphicBuffer->getId()) {
// 将acquire出来的Buffer做成EGLImage,为了后面GPU合成
mImages[item->mSlot] = std::make_shared<Image>(item->mGraphicBuffer, mRE);
}
}
return NO_ERROR;
}
文件: frameworks/native/libs/gui/ConsumerBase.cpp
status_t ConsumerBase::acquireBufferLocked(BufferItem *item,
nsecs_t presentWhen, uint64_t maxFrameNumber) {
...
// 实现在BufferQueueConsumer的 acquireBuffer
status_t err = mConsumer->acquireBuffer(item, presentWhen, maxFrameNumber);
if (err != NO_ERROR) {
return err;
}
if (item->mGraphicBuffer != nullptr) {
if (mSlots[item->mSlot].mGraphicBuffer != nullptr) {
freeBufferLocked(item->mSlot);
}
//更新Bufferslot里面的GraphicsBuffer,这个Buffer的owner是GPU在处理
mSlots[item->mSlot].mGraphicBuffer = item->mGraphicBuffer;
}
// 更新Bufferslot里面的frameNumber和fence,与queueBuffer设置保持一致,这里的fence为acquireFence
mSlots[item->mSlot].mFrameNumber = item->mFrameNumber;
mSlots[item->mSlot].mFence = item->mFence;
CB_LOGV("acquireBufferLocked: -> slot=%d/%" PRIu64,
item->mSlot, item->mFrameNumber);
return OK;
}
文件: frameworks/native/libs/gui/BufferQueueConsumer.cpp
//跳过一些特殊情况代码细节,把主线code拎出来分析
status_t BufferQueueConsumer::acquireBuffer(BufferItem* outBuffer,
nsecs_t expectedPresent, uint64_t maxFrameNumber) {
...
// queueBuffer时入的队列
BufferQueueCore::Fifo::iterator front(mCore->mQueue.begin());
...
// 拿到queueBuffer对应的slot和BufferItem
slot = front->mSlot;
*outBuffer = *front;
...
if (!outBuffer->mIsStale) {
mSlots[slot].mAcquireCalled = true;
// Don't decrease the queue count if the BufferItem wasn't
// previously in the queue. This happens in shared buffer mode when
// the queue is empty and the BufferItem is created above.
if (mCore->mQueue.empty()) {
mSlots[slot].mBufferState.acquireNotInQueue();
} else {
// 更新状态为acquire
mSlots[slot].mBufferState.acquire();
}
// queueBuffer入队,acquireBuffer出队
mCore->mQueue.erase(front);
...
}
handleMessageInvalidate主要作用是执行 latchBuffer 去 acquire 应用queue过来的Buffer,然后拿到queueBuffer时设的Bufferslot一些状态属性给到BufferQueueLayer的mBufferInfo,同时还把这个Buffer做成EGLImage为后面的GPU合成做准备,期间都是数据之间的传递,所以说SurfaceFlinger并未真正触碰Buffer的内容。

写在最后
好了今天的博客Android下SF合成流程重学习之onMessageInvalidate就到这里了。总之,青山不改绿水长流先到这里了。如果本博客对你有所帮助,麻烦关注或者点个赞,如果觉得很烂也可以踩一脚!谢谢各位了!!