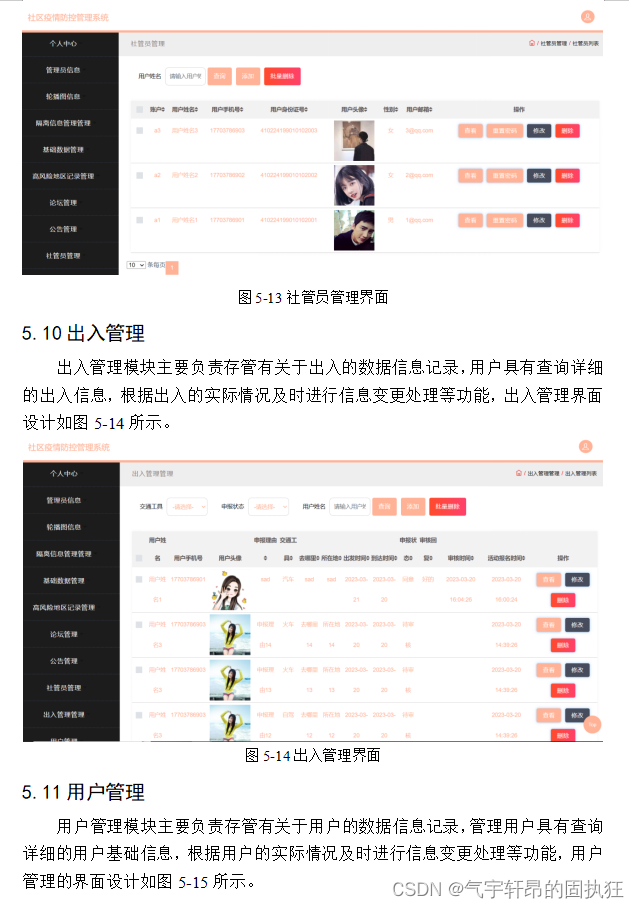
介绍
在本教程中,您将学习:
示例面部美化算法的基础知识;
如何使用 G-API 推断管道内的不同网络;
如何在视频流上运行 G-API 管道。
先决条件
此示例需要:
装有 GNU/Linux 或 Microsoft Windows 的 PC(支持 Apple macOS,但未经过测试);
OpenCV 4.2 或更高版本使用英特尔®发行版 OpenVINO™ 工具套件构建(使用英特尔® TBB 构建者优先);
OpenVINO™ Toolkit Open Model Zoo 中的以下拓扑:
face-detection-adas-0001;
facial-landmarks-35-adas-0002.
美颜算法
我们将使用现代深度学习技术和传统计算机视觉的组合来实现一个简单的面部美化算法。该算法背后的总体思想是使面部皮肤更光滑,同时保留眼睛或嘴巴对比度等面部特征。该算法使用 DNN 推理识别面部的某些部分,对找到的部分应用不同的过滤器,然后使用基本图像算法将其组合到最终结果中:
简而言之,该算法描述如下:
输入图像\(I\)被传递到非锐化掩模和双边滤波器(分别为\(U\)和\(L\));
输入图像\(I\)被传递到基于SSD的人脸检测器;
SSD 结果(\([1 \times 1 \times 200 \times 7]\) blob)被解析并转换为人脸数组;
每张脸都被传递到地标检测器;
根据为每张脸找到的地标,生成三个图像蒙版:
背景蒙版 \(b\) – 指示原始图像中的哪些区域保持原样;
面部部分蒙版 \(p\) – 识别要保留(锐化)的区域。
面膜 \(s\) – 识别要模糊的区域;
最终结果 \(O\) 是上述特征的组合,计算为 \(O = bI + pU + s*L\)。
基于一组有限的特征(每张脸只有 35 个,包括其所有部分)生成面部元素蒙版并不是一件容易的事,将在以下各节中介绍。
构建 G-API 管道
声明深度学习拓扑
此示例使用两个 DNN 检测器。每个网络接受一个输入并产生一个输出。在 G-API 中,网络是用宏 G_API_NET() 定义的:
G_API_NET(FaceDetector, <cv::GMat(cv::GMat)>, “face_detector”);
G_API_NET(LandmDetector, <cv::GMat(cv::GMat)>, “landm_detector”);
若要获取详细信息,请参阅“人脸分析管道”教程中所述的声明深度学习拓扑。
描述处理图
下面的代码为上述算法生成了一个图形:
cv::GComputation pipeline([=]()
{
cv::GMat gimgIn;//输入
cv::GMat faceOut = cv::gapi::infer<custom::FaceDetector>(gimgIn);
GArrayROI garRects = custom::GFacePostProc::on(faceOut, gimgIn, config::kConfThresh);// 后处理
cv::GArray<cv::GMat> landmOut = cv::gapi::infer<custom::LandmDetector>(garRects, gimgIn);
cv::GArray<地标> garElems;// |
cv::GArray garJaws;// |输出数组
std::tie(garElems, garJaws) = custom::GLandmPostProc::on(landmOut, garRects);// 后处理
cv::GArray garElsConts;脸部元素 //
cv::GArray garFaceConts;整张脸 //
std::tie(garElsConts, garFaceConts) = custom::GGetContours::on(garElems, garJaws);//插值
cv::GMat mskSharp = custom::GFillPolyGContours::on(gimgIn, garElsConts);// |
cv::GMat mskSharpG = cv::gapi::gaussianBlur(mskSharp, config::kGKernelSize, // |
config::kGSigma);// |
cv::GMat mskBlur = custom::GFillPolyGContours::on(gimgIn, garFaceConts);// |
cv::GMat mskBlurG = cv::gapi::gaussianBlur(mskBlur, config::kGKernelSize, // |
config::kGSigma);// |绘制蒙版
mask() 中的第一个参数是 Blur,因为我们想从 // |
BlurG 下一步: // |
cv::GMat mskBlurFinal = mskBlurG - cv::gapi::mask(mskBlurG, mskSharpG);// |
cv::GMat mskFacesGaussed = mskBlurFinal + mskSharpG;// |
cv::GMat mskFacesWhite = cv::gapi::threshold(mskFacesGaussed, 0, 255, cv::THRESH_BINARY);// |
cv::GMat mskNoFaces = cv::gapi::bitwise_not(mskFacesWhite);// |
cv::GMat gimgBilat = custom::GBilatFilter::on(gimgIn, config::kBSize,
config::kBSigmaCol, config::kBSigmaSp);
cv::GMat gimgSharp = custom::unsharpMask(gimgIn, config::kUnshSigma,
config::kUnshStrength);
敷面膜
应该使用自定义函数 mask3C() 而不仅仅是 gapi::mask()
由于 mask() 仅提供CV_8UC1源代码(我们有CV_8U3C)
cv::GMat gimgBilatMasked = custom::mask3C(gimgBilat, mskBlurFinal);
cv::GMat gimgSharpMasked = 自定义::mask3C(gimgSharp, mskSharpG);
cv::GMat gimgInMasked = 自定义::mask3C(gimgIn, mskNoFaces);
cv::GMat gimgBeautif = gimgBilatMasked + gimgSharpMasked + gimgInMasked;
返回 cv::GComputation(cv::GIn(gimgIn), cv::GOut(gimgBeautif,
cv::gapi::copy(gimgIn),
garFaceConts,
加埃尔斯康茨,
garRects));
});
生成的图形是 G-API 的标准操作、用户定义的操作(命名空间)和 DNN 推理的混合体。通用函数允许在管道内触发推理;要推断的网络被指定为模板参数。示例代码使用两个版本:custom::cv::gapi::infer<>()cv::gapi::infer<>()
面向帧的用于检测输入帧上的人脸。
面向 ROI 列表的版本用于对人脸列表进行地标推断——此版本为每张人脸生成一系列地标。
有关此内容的详细信息,请参阅“人脸分析管道”(生成 GComputation 部分)。
G-API 中的 Unsharp 蒙版
图像 I 的非锐化掩码 U 定义为:U我
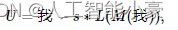
其中 M() 是中值滤波器,L() 是拉普拉斯算子,s 是强度系数。虽然 G-API 没有提供开箱即用的此函数,但它通过现有的 G-API 操作自然地表达:M()L()s
内联 cv::GMat custom::unsharpMask(const cv::GMat &src,
常量国际西格玛,
常量浮动强度)
{
cv::GMat blurred = cv::gapi::medianBlur(src, sigma);
cv::GMat 拉普拉斯语 = 自定义::GLaplacian::on(模糊,CV_8U);
返回 (src - (拉普拉斯 * 强度));
}
请注意,上面截取的代码是使用 G-API 类型定义的常规 C++ 函数。用户可以编写这样的函数来简化图形构造;调用时,此函数只是将相关节点放入使用它的管道中。
自定义操作
人脸美化图正在广泛使用自定义操作。本章重点介绍最有趣的内核,有关在 G-API 中定义操作和实现内核的一般信息,请参阅 G-API 内核 API。
人脸检测器后处理
人脸检测器输出将转换为具有以下内核的人脸数组:
用矢量ROI = std::vector<cv::Rect>;
GAPI_OCV_KERNEL(GCPUFacePostProc、GFacePostProc)
{
静态 void run(const cv::Mat &inDetectResult,
const cv::Mat &inFrame,
const float faceConfThreshold,
VectorROI &outFaces)
{
常量 int kObjectSize = 7;
const int imgCols = inFrame。size().width;
const int imgRows = inFrame。size().高度;
const cv::Rect borders({0, 0}, inFrame.大小());
outFaces.clear();
const int numOfDetections = inDetectResult。尺寸[2];
const float *data = inDetectResult。ptr<浮点>();
for (int i = 0; i < numOfDetections; i++)
{
常量浮点数 faceId = data[i * kObjectSize + 0];
if (faceId < 0.f) // 表示检测结束
{
破;
}
常量浮点数 faceConfidence = data[i * kObjectSize + 2];
我们可以通过“conf”字段来减少检测
以避免探测器的错误。
if (faceConfidence > faceConfThreshold)
{
const float left = data[i * kObjectSize + 3];
const float top = data[i * kObjectSize + 4];
const float right = data[i * kObjectSize + 5];
const float bottom = data[i * kObjectSize + 6];
这些是归一化坐标,介于 0 和 1 之间;
要获得真实的像素坐标,我们应该将其乘以
图像大小分别为以下方向:
cv:😛 oint tl(toIntRounded(left * imgCols),
toIntRounded(顶部 * imgRows));
cv:😛 oint br(toIntRounded(right * imgCols),
toIntRounded(底部 * imgRows));
outFaces.push_back(cv::Rect(tl, br) & borders);
}
}
}
};
面部特征点后期处理
该算法使用OpenVINO™ Open Model Zoo的通用面部特征检测器(细节)推断面部元素(如眼睛、嘴巴和头部轮廓本身)的位置。但是,按原样检测到的地标不足以生成蒙版 - 此操作需要由闭合轮廓表示的面部感兴趣区域,因此应用一些插值来获取它们。此地标处理和插值由以下内核执行:
GAPI_OCV_KERNEL(GCPUGetContours、GGetContours)
{
static void run(const std::vector &vctPtsFaceElems, // 18个面部元素的地标
const std::vector &vctCntJaw, // 17个下颌标志
std::vector &vctElems轮廓,
std::vector &vctFaceContours)
{
size_t numFaces = vctCntJaw.size();
CV_Assert(numFaces == vctPtsFaceElems.size());
CV_Assert(vctElemsContours.size() == 0ul);
CV_Assert(vctFaceContours.size() == 0ul);
vctFaceElemsContours 将存储找到的所有面部元素的轮廓
在输入图像中,即每个检测到的人脸有 4 个元素(两只眼睛、鼻子、嘴巴):
vctElemsContours.reserve(numFaces * 4);
vctFaceElemsContours 将存储输入图像中的所有面部轮廓:
vctFaceContours.reserve(numFaces);
轮廓 cntFace、cntLeftEye、cntRightEye、cntNose、cntMouth;
cntNose.reserve(4);
for (size_t i = 0ul; i < numFaces; i++)
{
面部元素轮廓
左眼:
用半椭圆(使用眼点)近似下眼轮廓并存储在 cntLeftEye 中:
cntLeftEye = getEyeEllipse(vctPtsFaceElems[i][1], vctPtsFaceElems[i][0]);
顺时针推动左眉毛:
cntLeftEye.insert(cntLeftEye.end(), {vctPtsFaceElems[i][12], vctPtsFaceElems[i][13],
vctPtsFaceElems[i][14]});
右眼:
将下眼轮廓近似为半椭圆(使用眼点)并存储在 vctRightEye 中:
cntRightEye = getEyeEllipse(vctPtsFaceElems[i][2], vctPtsFaceElems[i][3]);
顺时针推动右眉毛:
cntRightEye.insert(cntRightEye.end(), {vctPtsFaceElems[i][15], vctPtsFaceElems[i][16],
vctPtsFaceElems[i][17]});
鼻子:
顺时针存放鼻子点
cntNose.clear();
cntNose.insert(cntNose.end(), {vctPtsFaceElems[i][4], vctPtsFaceElems[i][7],
vctPtsFaceElems[i][5], vctPtsFaceElems[i][6]});
一张嘴:
用两个半椭圆(使用嘴尖)近似嘴轮廓并存储在 vctMouth 中:
cntMouth = getPatchedEllipse(vctPtsFaceElems[i][8], vctPtsFaceElems[i][9],
vctPtsFaceElems[i][10], vctPtsFaceElems[i][11]);
将所有元素存储在向量中:
vctElemsContours.insert(vctElemsContours.end(), {cntLeftEye, cntRightEye, cntNose, cntMouth});
脸部轮廓:
用半椭圆(使用下颌点)近似额头轮廓并存储在 vctFace 中:
cntFace = getForeheadEllipse(vctCntJaw[i][0], vctCntJaw[i][16], vctCntJaw[i][8]);
椭圆是顺时针绘制的,但颌骨轮廓点反之亦然,因此有必要推动
cntJaw 从结束到开始使用反向迭代器:
std::copy(vctCntJaw[i].crbegin(), vctCntJaw[i].crend(), std::back_inserter(cntFace));
将面部轮廓存储在另一个矢量中:
vctFaceContours.push_back(cntFace);
}
}
};
内核采用两个非规范化地标坐标数组,并返回元素的闭合轮廓数组和面的闭合轮廓数组;换言之,输出是第一个要锐化的图像区域轮廓阵列,第二个是另一个要平滑的图像区域轮廓。
这里和下面是一个点的向量。Contour
获得眼部轮廓
眼部轮廓通过以下功能进行估计:
内联 int custom::getLineInclinationAngleDegrees(const cv:😛 oint &ptLeft, const cv:😛 oint &ptRight)
{
const cv:😛 oint 残差 = ptRight - ptLeft;
如果 (残差。y == 0 && 残差。x == 0)
返回 0;
还
返回 toIntRounded(atan2(toDouble(residual.y)、toDouble(残差。x)) * 180.0 / CV_PI);
}
内嵌轮廓自定义::getEyeEllipse(const cv:😛 oint &ptLeft, const cv:😛 oint &ptRight)
{
轮廓 cntEyeBottom;
const cv:😛 oint ptEyeCenter((ptRight + ptLeft) / 2);
常量 int angle = getLineInclinationAngleDegrees(ptLeft, ptRight);
const int axisX = toIntRounded(cv::norm(ptRight - ptLeft) / 2.0);
根据研究,平均而言,眼睛的 Y 轴约为
X 的 1/3。
常量 int axisY = axisX / 3;
我们需要椭圆的下半部分:
静态 constexpr int kAngEyeStart = 0;
静态 constexpr int kAngEyeEnd = 180;
cv::ellipse2Poly(ptEyeCenter, cv::Size(axisX, axisY), angle, kAngEyeStart, kAngEyeEnd, config::kAngDelta,
cntEyeBottom);
返回 cntEyeBottom;
}
简而言之,此函数根据左右眼角的两个点将眼睛的底部恢复为半椭圆。实际上,用于近似眼睛区域,该函数仅基于两个点定义椭圆参数:cv::ellipse2Poly()
椭圆中心和X半轴由两个眼点计算;X
Y 半轴根据平均眼宽为其长度的 1/3 的假设计算;Y1/3
起点和终点角为 0 和 180(请参阅文档);cv::ellipse()
角度增量:在轮廓中产生多少点;
轴的倾斜角度。
使用 而不是 just in 函数是必不可少的,因为它允许根据 和 符号返回负值,因此即使在颠倒的面排列的情况下,我们也可以获得正确的角度(当然,如果我们按正确的顺序排列点)。atan2()atan()custom::getLineInclinationAngleDegrees()xy
获得额头轮廓
该功能近似于额头轮廓:
内嵌轮廓自定义::getForeheadEllipse(const cv:😛 oint &ptJawLeft,
const cv:😛 oint &ptJawRight,
const cv:😛 oint &ptJawLower)
{
轮廓 cnt额头;
下巴顶部两个点之间的点:
const cv:😛 oint ptFaceCenter((ptJawLeft + ptJawRight) / 2);
这将是椭圆的中心。
下颌与垂直线之间的角度:
const int angFace = getLineInclinationAngleDegrees(ptJawLeft, ptJawRight);
这将是椭圆的倾角
计算椭圆的半轴:
const double jawWidth = cv::norm(ptJawLeft - ptJawRight);
额头宽度等于下颌宽度,我们需要一个半轴:
常量 int axisX = toIntRounded(jawWidth / 2.0);
const double jawHeight = cv::norm(ptFaceCenter - ptJawLower);
根据研究,平均额头约为 2/3
下巴:
常量 int axisY = toIntRounded(jawHeight * 2 / 3.0);
我们需要椭圆的上部:
静态 constexpr int kAngForeheadStart = 180;
静态 constexpr int kAngForeheadEnd = 360;
cv::ellipse2Poly(ptFaceCenter, cv::Size(axisX, axisY), angFace, kAngForeheadStart, kAngForeheadEnd,
config::kAngDelta, cntForehead);
返回 cntForehead;
}
由于我们在检测到的地标中只有下颌点,因此我们必须根据下颌的三个点获得一个半椭圆:最左边、最右边和最低的一点。假设下颌宽度等于前额宽度,后者使用左右点计算。说到Y轴,我们没有点可以直接得到,而是假设额头高度大约是下颌高度的2/3,可以从脸部中心(左右点之间的中间)和下颌最低点算出来。Y2/3
绘图蒙版
当我们拥有所需的所有轮廓时,我们就可以绘制面具:
cv::GMat mskSharp = custom::GFillPolyGContours::on(gimgIn, garElsConts);// |
cv::GMat mskSharpG = cv::gapi::gaussianBlur(mskSharp, config::kGKernelSize, // |
config::kGSigma);// |
cv::GMat mskBlur = custom::GFillPolyGContours::on(gimgIn, garFaceConts);// |
cv::GMat mskBlurG = cv::gapi::gaussianBlur(mskBlur, config::kGKernelSize, // |
config::kGSigma);// |绘制蒙版
mask() 中的第一个参数是 Blur,因为我们想从 // |
BlurG 下一步: // |
cv::GMat mskBlurFinal = mskBlurG - cv::gapi::mask(mskBlurG, mskSharpG);// |
cv::GMat mskFacesGaussed = mskBlurFinal + mskSharpG;// |
cv::GMat mskFacesWhite = cv::gapi::threshold(mskFacesGaussed, 0, 255, cv::THRESH_BINARY);// |
cv::GMat mskNoFaces = cv::gapi::bitwise_not(mskFacesWhite);// |
获得口罩的步骤是:
“夏普”掩码计算:
填充应锐化的轮廓;
模糊它以获得“锐利”蒙版(mskSharpG);
“双边”掩码计算:
充分填充所有面部轮廓;
模糊它;
减去与“尖锐”掩模相交的区域,得到“双边”掩码(mskBlurFinal);
背景掩码计算:
添加两个先前的蒙版
将结果的所有非零像素设置为 255(由cv::gapi::threshold())
还原输出 (by ) 以获取背景蒙版 ()。cv::gapi::bitwise_notmskNoFaces
配置和运行管道
一旦图形完全表达出来,我们最终就可以编译它并在真实数据上运行。G-API 图编译是 G-API 框架真正了解要使用的内核和网络的阶段。此配置通过 G-API 编译参数进行。
DNN 参数
此示例使用 OpenVINO™ 工具套件推理引擎后端进行 DL 推理,其配置方式如下:
auto faceParams = cv::gapi::ie::P arams<custom::FaceDetector>
{
/*std::string*/ faceXmlPath,
/*std::string*/ faceBinPath,
/*std::string*/ faceDevice
};
auto landmParams = cv::gapi::ie::P arams<custom::LandmDetector>
{
/*std::string*/ landmXmlPath,
/*std::string*/ landmBinPath,
/*std::string*/ landmDevice
};
每个对象都与其模板参数中指定的网络相关。我们应该将在本教程早期定义的网络类型传递到那里。cv::gapi::ie::Params<>G_API_NET()
然后,网络参数被包装在:cv::gapi::NetworkPackage
自动网络 = cv::gapi::networks(faceParams, landmParams);
有关“人脸分析管道”(配置管道部分)中的更多详细信息。
内核软件包
在此示例中,我们使用了大量自定义内核,此外,我们还使用 Fluid 后端来优化 G-API 标准内核的内存(如果适用)。生成的内核包如下所示:
auto customKernels = cv::gapi::kernels<custom::GCPUBilateralFilter,
custom::GCPULaplacian,
custom::GCPUFillPolyGContours,
自定义::GCPUPolyLines,
custom::GCPURectangle,
自定义::GCPUFacePostProc,
自定义::GCPULandmPostProc,
自定义::GCPUGetContours>();
自动内核 = cv::gapi::combine(cv::gapi::core::fluid::kernels(),
customKernels);
编译流式处理管道
G-API 优化了在“流”模式下编译时视频流的执行。
cv::GStreamingCompiled stream = pipeline.compileStreaming(cv::compile_args(内核、网络));
有关此内容的详细信息,请参阅“人脸分析管道”(配置管道部分)。
运行流式处理管道
为了运行 G-API 流式处理管道,我们只需要指定输入视频源,调用 ,然后获取管道处理结果:cv::GStreamingCompiled::start()
if (parser.has(“输入”))
{
流。setSource(cv::gapi::wip::make_src<cv::gapi::wip::GCaptureSource>(parser.get<cv::String>(“输入”)));
}
auto out_vector = cv::gout(imgBeautif, imgShow, vctFaceConts,
vctElsConts、vctRects);
流。开始();
avg.start();
而 (流。运行())
{
if (!stream.try_pull(std::move(out_vector)))
{
使用 try_pull() 获取数据。
如果没有数据,请让 UI 刷新(并处理按键)
if (cv::waitKey(1) >= 0) 中断;
否则继续;
}
帧++;
如有必要,绘制面框和地标:
if (flgLandmarks == true)
{
cv::p olylines(imgShow, vctFaceConts, config::kClosedLine,
config::kClrYellow);
cv::p olylines(imgShow, vctElsConts, config::kClosedLine,
config::kClrYellow);
}
if (flgBoxes == 真)
for (自动整形:vctRects)
cv::rectangle(imgShow, rect, config::kClrGreen);
cv::imshow(config::kWinInput, imgShow);
cv::imshow(config::kWinFaceBeautification, imgBeautif);
}
一旦结果准备就绪并可以从管道中提取,我们就会将其显示在屏幕上并处理 GUI 事件。
有关详细信息,请参阅“人脸分析管道”教程中的“运行管道”部分。
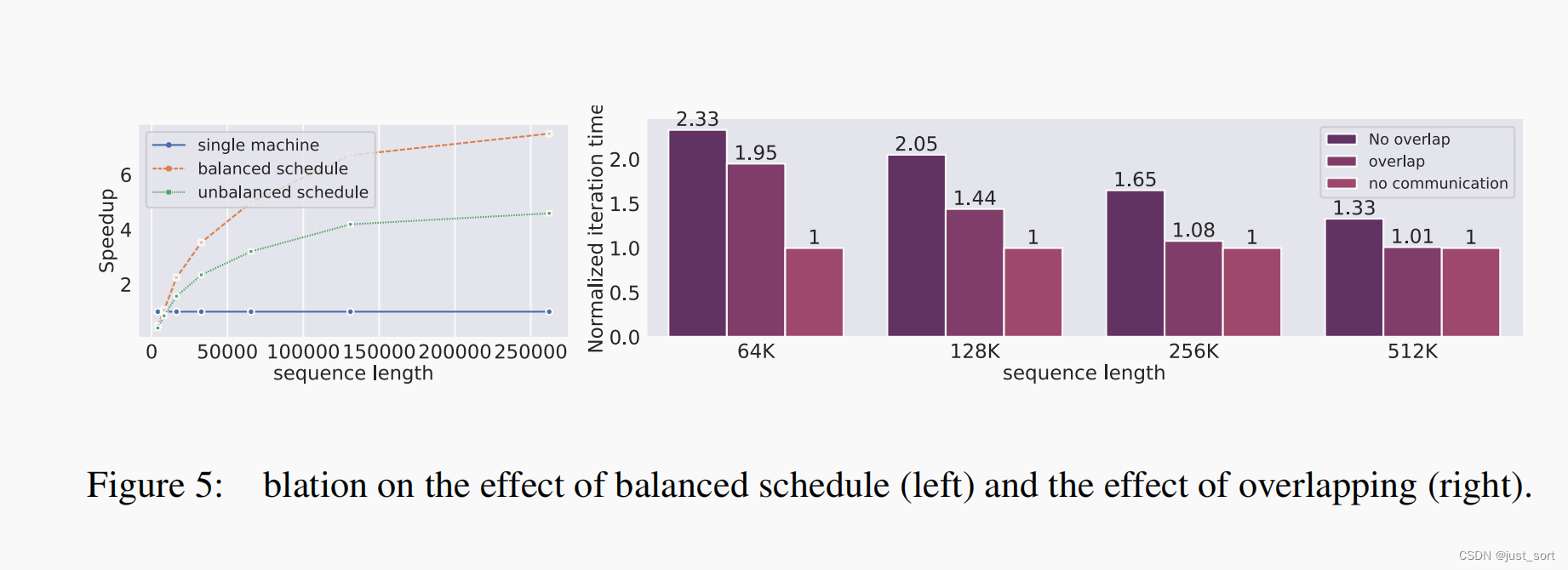
结论
本教程有两个目标:展示 OpenCV 4.2 中引入的 G-API 全新功能的使用,并给出对示例人脸美化算法的基本了解。
算法应用结果:

面部美化示例
在测试机器(Intel® Core™ i7-8700)上,G-API优化的视频流水线比其串行(非流水线)版本高出2.7倍,这意味着对于这样一个不平凡的图形,适当的流水线可以带来近3倍的性能提升。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓