2023年10月,我们发表了一篇关于TimeGPT的文章,TimeGPT是时间序列预测的第一个基础模型之一,具有零样本推理、异常检测和共形预测能力。
虽然TimeGPT是一个专有模型,只能通过API访问。但是它还是引发了对时间序列基础模型的更多研究。到了2024年2月,已经有了一个用于时间序列预测的开源基础模型:laglllama。

在原论文《Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting》中,模型作为单变量概率预测的通用基础模型提出。它是由来自不同机构的大型团队开发的,这些机构包括Morgan Stanley, ServiceNow, Université de Montréal, Mila-Quebec, 和McGill University.
在本文中,我们将探讨Lag-Llama的架构、功能以及训练方式。还会将lagllama应用于一个预测项目中,并将其与其他深度学习方法Temporal Fusion Transformer (TFT) 和DeepAR进行性能比较。
Lag-Llama
lagllama是为单变量概率预测而构建的。它使用不依赖于频率的通用方法来标记时间序列数据。这样模型可以很好地推广到不可见的频率。
它利用Transformer体系结构和分布头来解析输入令牌,并将它们映射到具有置信区间的未来预测。
1、具有滞后特征的标记
laglllama的标记策略是使用一组指定的滞后来构造序列的滞后特征。
它将从这个列表中为给定的数据集选择所有合适的频率:
季度、月、周、天、小时、秒
也就是说,如果以每日频率提供数据集,lag - llama将尝试使用每日滞后(t-1),每周滞后(t-7),每月滞后(t-30)等构建特征。
策略如下图所示。
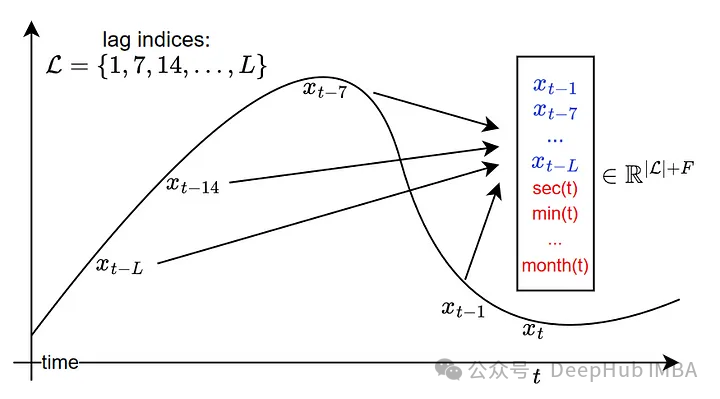
从上图中,我们还可以看到模型构建了其他静态协变量,例如秒/分、小时/天等等,直到季度/年。虽然这可以很好地推广到所有类型的时间序列,但它有一个致命的缺点:由于固定的滞后指数列表,输入令牌可能会变得非常大。
例如,查看每小时数据的每月频率需要730个时间步。这意味着除了所有静态协变量之外,输入令牌的长度至少为730。
2、Lag-Llama架构
Lag-Llama是一个基于transformer的纯解码器模型,其灵感来自大型语言模型LLaMA的体系结构。
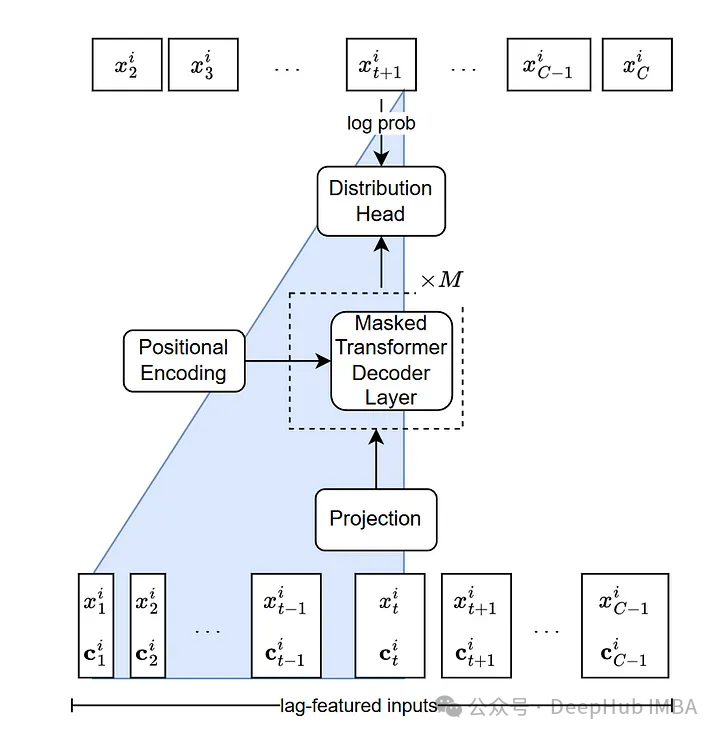
从图中可以看到输入标记是滞后时间步长和静态协变量的拼接。输入序列通过线性投影层将特征映射到解码器内部注意力模块的隐藏维度。另外就是在最后的输出,序列被发送到一个分布头负责输出一个概率分布。
在推理过程中,输入序列生成下一个时间点的分布。然后通过自回归,模型逐个生成剩余的预测序列,直到达到设置的长度。
生成预测的自回归过程有效地允许模型为其预测生成不确定性区间。但是这里的问题就是如果序列很长,自回归的方式会将错误扩大。
3、Lag-Llama分布头
Lag-Llama的分布头负责输出概率分布。这样模型就能够生成预测区间。
在模型的迭代中,最后一层使用Student 's t分布来构造不确定性区间。从理论上讲不同的分布头可以组合在一起,但是论文并没有做这样的实验,可能是想在以后在做吧。
4、Lag-Llama的训练
作为一个基础模型,Lag-Llama显然是在大量的时间序列数据语料库上训练的,因此该模型可以很好地泛化未见过的时间序列并进行零样本预测。
论文中说:Lag-Llama在来自不同领域的27个时间序列数据集上进行了训练,如能源、交通、经济等。
数据包含7965个单变量时间序列,总计约3.52亿个令牌。
所有数据集都是开源的,包括ethth, Exchange和Weather等。
Lag-Llama测试
因为代码已经开源,所以我们可以直接测试,我们首先使用Lag-Llama的零样本预测能力,并将其性能与特定数据模型(如TFT和DeepAR)进行比较。
Lag-Llama的实现是建立在GluonTS之上的,所以我们还需要安装这个库。实验使用了澳大利亚电力需求数据集,该数据集包含五个单变量时间序列,以半小时的频率跟踪能源需求。
这里有个说明:Lag-Llama目前的实现是初期阶段。并且存还在积极开发中,后面可能还会有很大的调整,因为目前还没加入微调的功能。
1、环境设置
!git clone https://github.com/time-series-foundation-models/lag-llama/
cd lag-llama
pip install -r requirements.txt --quiet
然后需要我们从HuggingFace下载模型的权重。
!huggingface-cli download time-series-foundation-models/Lag-Llama lag-llama.ckpt --local-dir /content/lag-llama
2、加载数据集
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import torch
from itertools import islice
from gluonts.evaluation import make_evaluation_predictions, Evaluator
from gluonts.dataset.repository.datasets import get_dataset
from lag_llama.gluon.estimator import LagLlamaEstimator
可以直接从GluonTS加载数据集。
dataset = get_dataset("australian_electricity_demand")
backtest_dataset = dataset.test prediction_length = dataset.metadata.prediction_length
context_length = 3 * prediction_length
3、使用Lag-Llama预测
简单地初始化模型并使用LagLlamaEstimator对象。
ckpt = torch.load("lag-llama.ckpt", map_location=torch.device('cuda:0'))
estimator_args = ckpt["hyper_parameters"]["model_kwargs"]
estimator = LagLlamaEstimator( ckpt_path="lag-llama.ckpt",
prediction_length=prediction_length,
context_length=context_length,
input_size=estimator_args["input_size"],
n_layer=estimator_args["n_layer"],
n_embd_per_head=estimator_args["n_embd_per_head"],
n_head=estimator_args["n_head"],
scaling=estimator_args["scaling"],
time_feat=estimator_args["time_feat"])
lightning_module = estimator.create_lightning_module()
transformation = estimator.create_transformation()
predictor = estimator.create_predictor(transformation, lightning_module)
使用make_evaluation_predictions函数生成零样本的预测。
forecast_it, ts_it = make_evaluation_predictions(
dataset=backtest_dataset,
predictor=predictor)
这个函数返回生成器。我们需要把它们转换成列表。
forecasts = list(forecast_it)
tss = list(ts_it)
4、评估
GluonTS可以使用Evaluator对象方便地计算不同的性能指标。
evaluator = Evaluator()
agg_metrics, ts_metrics = evaluator(iter(tss), iter(forecasts))
RMSE为481.57。
我们还可以随意地将预测可视化。
plt.figure(figsize=(20, 15))
date_formater = mdates.DateFormatter('%b, %d')
plt.rcParams.update({'font.size': 15})
for idx, (forecast, ts) in islice(enumerate(zip(forecasts, tss)), 4):
ax = plt.subplot(2, 2, idx+1)
plt.plot(ts[-4 * dataset.metadata.prediction_length:].to_timestamp(), label="target")
forecast.plot( color='g')
plt.xticks(rotation=60)
ax.xaxis.set_major_formatter(date_formater)
ax.set_title(forecast.item_id)
plt.gcf().tight_layout()
plt.legend()
plt.show()
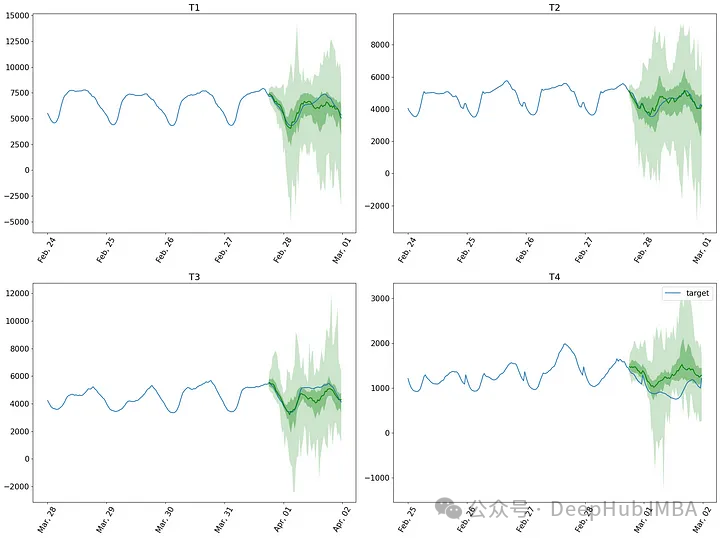
上图可以看到模型对数据做出了合理的预测,尽管它在第四个序列(图的右下角)上确实存在问题。
另外由于 Lag-Llama实现了概率预测,可以得到预测的不确定性区间。
5、与TFT和DeepAR相比
我们在数据集上训练TFT和DeepAR模型,看看它们是否能表现得更好。
为了节省时间,我们将训练设置为5个epoch。
from gluonts.torch import TemporalFusionTransformerEstimator, DeepAREstimator
tft_estimator = TemporalFusionTransformerEstimator(
prediction_length=prediction_length,
context_length=context_length,
freq="30min",
trainer_kwargs={"max_epochs": 5})
deepar_estimator = DeepAREstimator(
prediction_length=prediction_length,
context_length=context_length,
freq="30min",
trainer_kwargs={"max_epochs": 5})
训练过程。
tft_predictor = tft_estimator.train(dataset.train)
deepar_predictor = deepar_estimator.train(dataset.train)
训练完成后,生成预测并计算RMSE。
tft_forecast_it, tft_ts_it = make_evaluation_predictions(
dataset=backtest_dataset,
predictor=tft_predictor)
deepar_forecast_it, deepar_ts_it = make_evaluation_predictions(
dataset=backtest_dataset,
predictor=deepar_predictor)
tft_forecasts = list(tft_forecast_it)
tft_tss = list(tft_ts_it)
deepar_forecasts = list(deepar_forecast_it)
deepar_tss = list(deepar_ts_it)
# Get evaluation metrics
tft_agg_metrics, tft_ts_metrics = evaluator(iter(tft_tss), iter(tft_forecasts))
deepar_agg_metrics, deepar_ts_metrics = evaluator(iter(deepar_tss), iter(deepar_forecasts))
下表突出显示了性能最好的模型。
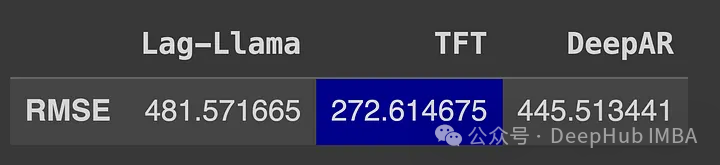
可以看到TFT是目前表现最好的模型,DeepAR的表现也优于laglama。
虽然laglllama的表现似乎不尽如人意,但该模型没有经过微调,而且零样本测本身就比较困难。
有趣的是,只训练了5个epoch这两个模型都取得了比Lag-Llama更好的结果。虽然样本预测可以节省时间,但训练五个epoch在时间和计算能力方面的要求应该不是很苛刻。所以目前可能零样本学习方面还需要很大的提升。
总结
在尝试了TimeGPT和Lag-Llama之后,Lag-Llama算是构建开源预测模型的第一步,但与TimeGPT相比,它在功能方面存在不足。
TimeGPT可以处理多变量时间序列、不规则时间戳,并实现共形预测,与使用laglama等固定分布相比,这是一种更稳健的量化不确定性的方式。
laglllama是一个开源的基础模型,只用于单变量概率预测,并且我觉得它训练的数据有点少了。我相信在不久的将来会看到更多的开源预测模型出现。他们的表现可能会得到改善,这代表了该领域的一个重大转变。
最后论文地址:
Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting by K. Rasul, A. Ashok, A. Williams, H. Ghonia, R. Bhagwatkar, A. Khorasani, M. Bayazi, G. Adamopoulos, R. Riachi, N. Hassen, M. Bilos, S. Garg, A. Schneider, N. Chapados, A. Drouin, V. Zantedeschi, Y. Nevmyvaka, I. Rish
https://avoid.overfit.cn/post/8a9120d3cf074c1ba0de0a7a247993c9
作者:Marco Peixeiro
![[office] excel2016怎么求最大值和最小值 #职场发展#知识分享](https://img-blog.csdnimg.cn/img_convert/b2e30ad30245887ba39845b64fdd2c67.jpeg)