说明
GlobalFunc是算网的下一代核心数据处理基础。
算网是一个分布式网络,为了能够实现真的分布式计算(加快大规模任务执行效率),以及能够在很长的时间内维护不同版本的计算方法,需要这样一个对象/服务来支撑。GlobalFunc支持通过web请求来完成计算,通常要求输入和输出都是可json序列化的;同时也支持作为一个本地对象被引入和使用。
另外一个核心点是智能化。智能化的一个前提是代理化,而不是直接调用。GlobalFunc允许使用参数化字符串来声明调用,这样每一次的操作是可以被其他算法/程序解读的。
内容
本次讨论4个主题:存储形态、基本操作、使用场景以及服务化。
1 存储形态
git项目
首先讨论GF的存储形态。传统的python包是以文件形式组织的,加上__init__.py文件指示就可以。GF本质上也是这样的,不过项目文件夹同时也是一个git项目文件夹,这意味着GF可以利用git的诸多特性:
- 1 分支。通过分支可以针对不同的项目或者探索进行微调,甚至可以支持未来由agent来进行微调实验。
- 2 比较(暂未使用)。git可以具备代码比较的能力,方便查探差异。
当前的GF可以视为一个文件夹,下面有若干子文件夹。每个子文件夹是一个独立的包,下面有若干py文件,每个文件的文件名和函数名是一致的。
如果在其他机器上拉取了该项目,那么对应的代码是一致的。当然,这仍然需要对应的环境支持才可以。所以一般来说没有必要去拉取项目,而是使用某个镜像。
除了文件形态,GF采用数据库存储,这种数据存储又是由Redis和Mongo两部分构成的。长期的持久化由Mongo完成,而零碎的取数由Redis完成。
RedisOrMongo本来的设计是为了通用的,大量的,不同程序间的数据存储服务的。为了区别不同程序的缓存,ROM约定了k(键)的命名规范,这个对于区分不同的变量非常有用。
如下,按三段命名法,k由三部分构成。总体上三段分别对应,项目、子项目、变量。或者从数据库上理解,三段分别是数据库、数据表和记录。
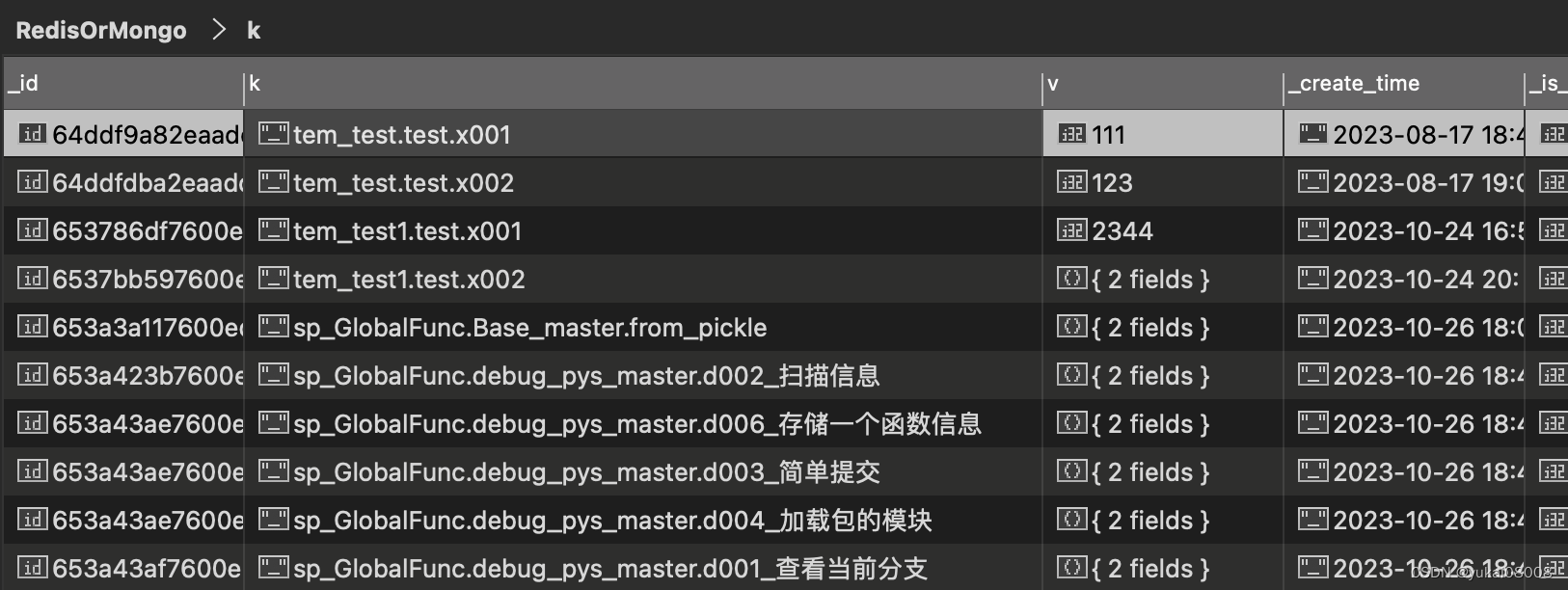
本次的存储:
- 1 tier1: sp_GlobalFunc 这个是GF的空间
- 2 tier2: Base_master 通过模块名+分支构成了第二级名称
- 3 tier2: 函数名
基于数据库的存储带来了很多便利:
- 1 首先,数据库方式允许了更智能的搜索。很多时候重复建设的根源就是在于找不到过去开发的结果。
一个有趣的实操是和chatgpt结合起来:将函数写好后,发给gpt解读,形成文本。
import os
def popen(some_cmd):
with os.popen(some_cmd) as f:
res = f.read()
return res
def popen1(some_cmd):
with os.popen(some_cmd) as f:
res = f.read()
return res.split()[0]
def get_machine_name(given_name = None):
if given_name is None :
try:
default_name = popen1('cat /etc/hostname')
except:
default_name = 'xx'
else:
default_name = given_name
return default_name
'''
你的 `popen` 函数用于执行命令并返回命令的输出,而 `popen1` 函数执行命令并返回输出的第一个单词。这些函数可以用于执行系统命令并获取输出。
`get_machine_name` 函数用于获取机器名,默认情况下它尝试从 `/etc/hostname` 文件中读取机器名,如果失败,则返回 'xx'。如果提供了 `given_name` 参数,它将使用该参数作为机器名。
这些函数看起来能够满足获取机器名和执行系统命令的需求。如果你有任何特定问题或需要进一步的帮助,可以随时提出。
'''
因为这些文本已经全部在数据库中了,因此很方便进一步将其处理为向量,或者直接使用es进行搜索。
这样的本质是帮助使用者面对信息过载,其实也就是在推荐。泛推荐类算法将是我2024年的一个主要方向。
2 基本操作对象封装
以下讨论关于GF的基本操作。
例如查看当前分支、扫描文件变动、简单git提交、包的初始化、存储函数信息、生成函数、列出包的所有函数。
测试应用是参数化调用。
开发和执行两部分需要分开,假设GlobalFunc是一个git项目,同时也是顶级目录和函数包(有init文件)。在这个项目下有若干子文件夹,每个文件夹也是一个函数包。
开发时要切入到GlobalFunc目录下,而执行时则保持与GlobalFunc平级。
2.1 开发
对象将一些功能整合到一起
# 依赖 RedisOrMongo -> WMongo
# tier1 是sp+项目名
class GFBase:
def __init__(self, project_path = None, redis_agent_host = 'http://172.17.0.1:24021/',redis_connection_hash = None,
tier1 = None):
self.project_path = project_path
self.redis_cfg = Naive()
self.redis_cfg.redis_agent_host = redis_agent_host
self.redis_cfg.redis_connection_hash = redis_connection_hash
self.tier1 = tier1
# 查看当前分支
def _get_current_branch(self):
return get_current_branch(self.project_path)
# 扫描目录下的所有文件信息
def _get_scan_files(self):
return scan_directory(self.project_path)
# 简单提交git
def _simple_commit_git(self, commit_message = None):
git_commit_and_push(commit_message, self.project_path)
# 为包增加初始文件:针对CreateOrUpdate一个包下的函数
def _generate_init_py(self, packname = None):
package_dir = '/'.join([self.project_path, packname])
generate_init_py(package_dir)
# 保存一个文件到ROM(RedisOrMongo) some_k 就是「包.函数名」
def _save_a_file_rom(self, some_k):
# 校验,应该包含两个点
some_func = some_k
some_func_list = some_func.split('.')
current_branch = self._get_current_branch()
scan_dict = self._get_scan_files()
tier1 = self.tier1
if len(some_func_list) == 3:
print('长度为3段,正确')
tier2 = some_func_list[0] + '_' + current_branch
var_space_name = '.'.join([tier1,tier2])
var_name = some_func_list[1]
is_new = not verify_redis_var_name(var_space_name)
rom = RedisOrMongo(var_space_name, self.redis_cfg.dict(),
backend='mongo', mongo_servername='m7.24065', is_new = is_new)
# 持久化存储
# some_func_jstr = json.dumps(scan_dict[some_func]) # 不必压缩
rom.setx(var_name, scan_dict[some_func], persist=True)
# 生成一个文件到指定位置
def _gen_a_file(self,func_name = None, target_folder = None, tier1 = None, pack_name = None, branch_name ='master'):
tier1 = self.tier1 or tier1
assert all([func_name,target_folder,pack_name]), 'unc_name,target_folder,pack_name 不为空'
tier2 = '_'.join([pack_name, branch_name])
the_space_name = '.'.join([tier1,tier2])
rom = RedisOrMongo(the_space_name, self.redis_cfg.dict(),
backend='mongo', mongo_servername='m7.24065')
# 获取 meta,data : data就是代码字符
the_data = rom.getx(func_name)
target_folder1 = '/'.join([target_folder, pack_name])
os.makedirs(target_folder1, exist_ok=True)
filename = the_data['meta']['name']
filedata = the_data['data']
create_file(target_folder1, filename, filedata)
# 列出包的所有函数
def _list_file_names_without_extension(self, pack_name):
pack_path = self.project_path + pack_name
return list_file_names_without_extension(pack_path)
# 重载包
def _reload_package(self, pack_name= None):
reload_package(pack_name)
# 初始化
git_project_path = './GlobalFunc/' # 切到GlobalFunc下执行
tier1 = 'sp_GlobalFunc' # 对应rom的命名规范
redis_agent_host = 'http://公网IP:24021/' # 需要通过微服务执行
gfbase = GFBase(project_path = git_project_path,
redis_agent_host = redis_agent_host,
tier1 = tier1 )
来看具体的应用和功能代码
2.1.1 查看当前分支
通过subprocess 调用git 命令查看分支,这与具体的应用相关。目前都是master。
gfbase._get_current_branch()
# ----
import subprocess
# 获取当前分支
def get_current_branch(directory=None):
try:
# 构建 git 命令
git_command = ['git', 'rev-parse', '--abbrev-ref', 'HEAD']
if directory:
# 如果指定了目录,则将命令添加到目录中执行
git_command = ['git', '-C', directory, 'rev-parse', '--abbrev-ref', 'HEAD']
# 运行 git 命令获取当前分支
result = subprocess.check_output(git_command)
# 将结果解码为字符串并去除换行符
current_branch = result.decode('utf-8').strip()
return current_branch
except subprocess.CalledProcessError:
# 如果出现错误,例如不在 Git 仓库中,返回 None
return None
# 例子:获取当前分支(在指定的目录下执行)
# current_branch = get_current_branch(directory='/path/to/your/git/repository')
2.1.2 扫描所有文件的信息
对项目下的所有py文件进行扫描,提取元数据,并将代码保存为数据。这个操作是向数据提交函数的前提。
scan_dict = gfbase._get_scan_files()
# ----
import os
import hashlib
import time
import json
# 计算文件的 MD5 哈希值
def calculate_file_hash(file_path):
md5 = hashlib.md5()
with open(file_path, "rb") as f:
while True:
data = f.read(65536)
if not data:
break
md5.update(data)
return md5.hexdigest()
def get_line_count(file_path):
with open(file_path, "r", encoding="utf-8") as f:
return sum(1 for line in f)
def get_file_metadata(file_path):
metadata = {}
try:
stat = os.stat(file_path)
metadata["hash"] = calculate_file_hash(file_path)
# python似乎没法正确读取create_time, linux的stat命令可以显示正确时间,但是不同的系统间格式又不同,算了
# metadata["created_time"] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(stat.st_ctime))
metadata["modified_time"] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(stat.st_mtime))
metadata["line_count"] = get_line_count(file_path)
except Exception as e:
print(f"Error getting metadata for {file_path}: {str(e)}")
return metadata
def get_file_data(file_path):
data = None
try:
with open(file_path, "r") as f:
content = f.read()
# 使用 json.dumps 将文件内容序列化为 JSON 格式
data = json.dumps(content)
except Exception as e:
print(f"Error getting data for {file_path}: {str(e)}")
return data
def build_key(root= None, xfile=None,directory_path = None, base_directory = None):
relative_path = os.path.relpath(root, directory_path)
relative_path = relative_path.replace('.', '') # 将 . 替换为空字符串
if relative_path == '.':
return xfile
else:
return f"{base_directory}.{relative_path.replace(os.path.sep, '.')}.{xfile}"
def scan_directory(directory_path):
result = {}
base_directory = os.path.basename(directory_path)
# 遍历指定目录及其子目录
for root, dirs, files in os.walk(directory_path):
# 过滤以 . 开头的文件夹 和以下划线开头的文件夹
dirs[:] = [d for d in dirs if not d.startswith('.') and not d.startswith('_')]
for file in files:
if not file.startswith(".") and not file.startswith("_") and file != "__init__.py" and not file.endswith('.pkl'):
file_path = os.path.join(root, file)
key = build_key(root, file, directory_path, base_directory)
key = key.lstrip('.')
value = {}
value["meta"] = get_file_metadata(file_path)
value["meta"]['name'] = file
data = get_file_data(file_path)
if data is not None:
value["data"] = data
result[key] = value
return result
# scan_dict = scan_directory('/Users/yukai/m4git/GlobalFunc/')
n [2]: scan_dict = gfbase._get_scan_files()
In [3]: scan_dict.keys()
Out[3]: dict_keys(['WMongo_V9000_012.py', 'remark.md', 'test.md', 'RedisOrMongo_v100.py', 'debug_pys.d010_参数化调用.py', 'debug_pys.d002_扫描信息.py', 'debug_pys.d008_列出某个包的所有函数.py', 'debug_pys.d006_存储一个函数信息.py',...
In [4]: scan_dict['Base.inverse_time_str.py']
Out[4]:
{'meta': {'hash': 'df80f0d4afec7ce0aa0ef00d7bc536ee',
'modified_time': '2023-10-27 15:25:39',
'line_count': 11,
'name': 'inverse_time_str.py'},
'data': '"import time\\n\\ndef inverse_time_str(time_str = None, bias_hours = 0):\\n ts = time.mktime (time.strptime(time_str,\'%Y-%m-%d %H:%M:%S\')) + bias_hours* 3600\\n return ts \\n\\n\'\'\'\\n\\u4f60\\u7684 inverse_time_str \\u51fd\\u6570\\u7528\\u4e8e\\u5c06\\u65f6\\u95f4\\u5b57\\u7b26\\u4e32\\u8f6c\\u6362\\u56de\\u65f6\\u95f4\\u6233\\uff0c\\u8003\\u8651\\u4e86\\u65f6\\u533a\\u504f\\u79fb\\u3002\\u8be5\\u51fd\\u6570\\u63a5\\u53d7\\u4e00\\u4e2a\\u65f6\\u95f4\\u5b57\\u7b26\\u4e32\\u548c\\u504f\\u79fb\\u5c0f\\u65f6\\u6570\\uff0c\\u5e76\\u8fd4\\u56de\\u4e00\\u4e2a\\u65f6\\u95f4\\u6233\\uff08\\u4ee5\\u79d2\\u4e3a\\u5355\\u4f4d\\uff09\\u3002\\n\\n\\u4f60\\u7684\\u51fd\\u6570\\u5b9e\\u73b0\\u770b\\u8d77\\u6765\\u662f\\u6b63\\u786e\\u7684\\uff0c\\u5b83\\u4f7f\\u7528\\u4e86 time.mktime \\u548c time.strptime \\u6765\\u6267\\u884c\\u5b57\\u7b26\\u4e32\\u5230\\u65f6\\u95f4\\u6233\\u7684\\u8f6c\\u6362\\u3002\\u504f\\u79fb\\u5c0f\\u65f6\\u6570\\u88ab\\u8003\\u8651\\u5728\\u5185\\uff0c\\u4ee5\\u4fbf\\u6839\\u636e\\u9700\\u8981\\u8c03\\u6574\\u65f6\\u95f4\\u6233\\u3002\\n\'\'\'"'}
2.1.3 提交git项目
当开发作为git项目时,需要进行提交。这个在本地分发或者是在分支开发时有用。
gfbase._simple_commit_git()
In [5]: gfbase._simple_commit_git()
[master cca9732] None 2024-02-13 13:53:03
3 files changed, 1 insertion(+)
create mode 100644 __pycache__/__init__.cpython-39.pyc
Enumerating objects: 16, done.
Counting objects: 100% (16/16), done.
Delta compression using up to 10 threads
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 837 bytes | 837.00 KiB/s, done.
Total 9 (delta 7), reused 0 (delta 0), pack-reused 0
To ssh://101.89.161.51:10600/home/git/GlobalFunc.git
dee7abd..cca9732 master -> master
Git操作成功完成。
import subprocess
from datetime import datetime
def git_commit_and_push(commit_message= '简单提交', git_directory='.'):
try:
current_datetime = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
full_commit_message = f"{commit_message} {current_datetime}"
# 添加所有更改
subprocess.run(['git', '-C', git_directory, 'add', '.'])
# 提交更改
subprocess.run(['git', '-C', git_directory, 'commit', '-m', full_commit_message])
# 推送到远程仓库
subprocess.run(['git', '-C', git_directory, 'push'])
print("Git操作成功完成。")
except subprocess.CalledProcessError as e:
print("Git操作失败:", e)
2.1.4 刷新一个包的初始化文件
在增加了函数之后,这几乎是一定要执行的。增加函数 -> 刷新包初始化文件 -> git 提交,这是一个固定流程。
gfbase._generate_init_py('Base')
以下自动为包增加了这行语句,从而导入新开发的函数
...
from .test1_save_test import test1_save_test
import os
def generate_init_py(package_dir):
if not os.path.exists(package_dir):
print(f"Package directory '{package_dir}' not found.")
return
with open(os.path.join(package_dir, "__init__.py"), "w") as init_py:
for filename in os.listdir(package_dir):
if filename.endswith(".py") and not filename.startswith("_") and not filename.startswith("."):
module_name = filename[:-3] # Remove the .py extension
init_py.write(f"from .{module_name} import {module_name}\n")
2.1.5 尝试存储一个函数
除了以文件方式增加持久化的方式之外,还需要将函数持久化到数据库。
Base.test1_save_test.py
def test1_save_test():
print('test1_save_test')
gfbase._save_a_file_rom('Base.test1_save_test.py')
In [7]: gfbase._save_a_file_rom('Base.test1_save_test.py')
长度为3段,正确
【Loading cur_w】from pickle
1.当前使用的MongeAgent:http://公网IP:24011/
2.Tier1:NameSpace, Tier2:RedisSpace
3.ConnectionHash:6552982f4bcd003477c5e2170250ccce
4.FilterDict:{'_is_enable': 1}
5.Limits:10000
6.Sort:
7.Skip:0
约定空间名称以sp_开头,节点以node_开头,临时变量以tem_开头
【提供节点与子图的元数据记录】
【Loading cur_w】from pickle
【Loading cur_w】from pickle
ok sp_GlobalFunc.Base_master 存在,可以使用
description
2.1.6 读取并生成一个函数 - 需要伴随一个包的初始化文件
这个功能的应用场景是在某个新的位置,重现(可能是部分)包函数。
target_folder = '~/Desktop/test_func'
gfbase._gen_a_file(func_name='from_pickle',target_folder=target_folder,pack_name='Base')
【提供节点与子图的元数据记录】
【Loading cur_w】from pickle
【Loading cur_w】from pickle
ok sp_GlobalFunc.Base_master 存在,可以使用
description
文件 'from_pickle.py' 已成功创建于路径 '~/Desktop/test_func/Base'
import os
def create_file(path, filename, content):
# 组合完整的文件路径
file_path = os.path.join(path, filename)
try:
# 打开文件以写入内容
with open(file_path, 'w') as file:
file.write(content)
print(f"文件 '{filename}' 已成功创建于路径 '{path}'")
except Exception as e:
print(f"创建文件时出现错误:{e}")
2.1.7 列出包的所有函数
通过扫描文件夹下文件列表的方式列出所有函数。
gfbase._list_file_names_without_extension('Base')
{'Naive',
'WMongo',
'__init__',
'clear_digits',
'color_print',
'cols2s',
'create_folder',
'flat_dict',
...
import os
def list_file_names_without_extension(directory):
return set(os.path.splitext(file)[0] for file in os.listdir(directory) if os.path.isfile(os.path.join(directory, file)))
2.1.8 重载一个包
在调试时可以更新然后重载
gfbase._reload_package('Base')
成功重新加载模块: Base
import subprocess
import importlib.util
def reload_package(package_name):
try:
# 检查包是否已经被导入
spec = importlib.util.find_spec(package_name)
if spec is None:
# 如果包未导入,先尝试导入它
print(f"警告:未找到包 '{package_name}',尝试导入...")
exec(f"import {package_name}")
# 构造重新加载模块的命令
reload_command = f'python -c "import importlib; import {package_name}; importlib.reload({package_name}); print(\'成功重新加载模块: {package_name}\')"'
# 使用 subprocess 调用命令
subprocess.run(reload_command, shell=True)
except subprocess.CalledProcessError as e:
print("重新加载模块失败:", e)
2.2 执行
需要切换到GlobalFunc的同级目录执行
2.2.1 位置参数调用
这种方式将逐渐被弃用。位置参数主要是方便,但是在函数复杂时并不方便。另外,既然采用间接方式调用,那么以关键字参数显然更加清晰。
import subprocess
import importlib.util
def reload_package(package_name):
try:
# 检查包是否已经被导入
spec = importlib.util.find_spec(package_name)
if spec is None:
# 如果包未导入,先尝试导入它
print(f"警告:未找到包 '{package_name}',尝试导入...")
exec(f"import {package_name}")
# 构造重新加载模块的命令
reload_command = f'python -c "import importlib; import {package_name}; importlib.reload({package_name}); print(\'成功重新加载模块: {package_name}\')"'
# 使用 subprocess 调用命令
subprocess.run(reload_command, shell=True)
except subprocess.CalledProcessError as e:
print("重新加载模块失败:", e)
# 用于GlobalFunc参数化获取函数 func_name like
def get_func_by_para(some_func_pack, full_func_name):
pack,funcname = full_func_name.split('.')
the_pack = getattr(some_func_pack,pack)
the_func = getattr(the_pack, funcname)
return the_func
# 在包的父目录执行,把GlobalFunc当成总包 | 在编辑的时候,我们会沉入到内部操作,在应用时则要挂在最外层
# import GlobalFunc as funcs
# the_func = get_func_by_para(funcs, 'Base.to_pickle')
class GFGo:
def __init__(self):
pass
# 执行 pack_func ~ Base.to_pickle
@staticmethod
def _exe_func_args(global_func = None, pack_func = None, args = None):
exe_func = get_func_by_para(global_func, pack_func)
return exe_func(*args)
@staticmethod
def _exe_func_kwargs(global_func = None, pack_func = None, kwargs = None):
exe_func = get_func_by_para(global_func, pack_func)
return exe_func(**kwargs)
# 重载包
@staticmethod
def _reload_package(package_name):
reload_package(package_name)
gfgo = GFGo()
以下执行一个函数,将一个数据 'a’存储为pickle, 文件名为‘a_data.pkl’
import GlobalFunc as funcs
pack_func = 'Base.to_pickle'
args1 = ['a', 'a_data', './']
gfgo._exe_func_args(global_func =funcs,pack_func= pack_func, args = args1)
In [4]: import GlobalFunc as funcs
...: pack_func = 'Base.to_pickle'
...: args1 = ['a', 'a_data', './']
...: gfgo._exe_func_args(global_func =funcs,pack_func= pack_func, args = args1)
...:
data save to pickle: ./a_data.pkl
2.2.2 关键字参数调用
这是未来的主流(规范):约定GlobalFunc函数的参数都以关键字参数
有一个工程是逐步将以前用位置参数的函数全部进行改造。
原函数
import pickle
def to_pickle(data, file_name, path='./'):
output = open(path+file_name+'.pkl', 'wb')
pickle.dump(data, output)
output.close()
print('data save to pickle: ', path+file_name+'.pkl')
改造后
import pickle
def to_pickle(data = None, file_name = None, path='./'):
output = open(path+file_name+'.pkl', 'wb')
pickle.dump(data, output)
output.close()
print('data save to pickle: ', path+file_name+'.pkl')
重新调用
# 重载包
In [10]: gfgo._reload_package('GlobalFunc')
...:
成功重新加载模块: GlobalFunc
In [11]: pack_func = 'Base.to_pickle'
...: kwargs1 = {'data':'a',
...: 'file_name':'a_data',
...: 'path':'./'}
In [12]: gfgo._exe_func_kwargs(global_func =funcs,pack_func= pack_func, kwargs = kwargs1)
data save to pickle: ./a_data.pkl
将这个函数也刷新到数据库,重新切回gfbase
gfbase._save_a_file_rom('Base.to_pickle.py')
到这里,基础功能就算告一段落。
3 场景及操作对象封装
先只讨论一种场景,就是镜像场景。
镜像场景是指使用docker容器开发,完成后封装为镜像使用。由于镜像是连同对应的开发环境一并封装的,开箱即用,所以是一个更成熟的方式。
简单来说,就是打开一个容器,将GlobalFunc文件夹拷贝进去,然后将操作对象,例如GFBase或者GFGo拷贝进去,就可以使用了。
源镜像(registry.cn-hangzhou.aliyuncs.com/andy08008/pytorch_jupyter:v205)是我之前维护的一个常用镜像,镜像装有gpu版 pytorch1.x,并安装了一些其他有用的包。
现在基于源镜像构建,目标是myregistry.domain.com:24052/worker.andy.globalfunc:v101
3.1 建立新容器
docker run -it registry.cn-hangzhou.aliyuncs.com/andy08008/pytorch_jupyter:v205 bash
3.2 拷贝GlobalFunc包
在算网机上先执行拉取git pull,更新GlobalFunc项目
注意m7.24065.pkl mymeta.pkl两个数据库连接文件要根据不同的情况刷新一下。
在宿主机执行
docker cp /opt/GlobalFunc df5a340570ab:/workspace/
此时
root@df5a340570ab:/workspace# ls
funcs_apifunc_database_model1_6810f9d37e89e5e1f33e1b8f4defa22e.so GlobalFunc test.ipynb
3.3 拷贝GFGo对象
这里只考虑执行的情况
import subprocess
import importlib.util
def reload_package(package_name):
try:
# 检查包是否已经被导入
spec = importlib.util.find_spec(package_name)
if spec is None:
# 如果包未导入,先尝试导入它
print(f"警告:未找到包 '{package_name}',尝试导入...")
exec(f"import {package_name}")
# 构造重新加载模块的命令
reload_command = f'python -c "import importlib; import {package_name}; importlib.reload({package_name}); print(\'成功重新加载模块: {package_name}\')"'
# 使用 subprocess 调用命令
subprocess.run(reload_command, shell=True)
except subprocess.CalledProcessError as e:
print("重新加载模块失败:", e)
# 用于GlobalFunc参数化获取函数 func_name like
def get_func_by_para(some_func_pack, full_func_name):
pack,funcname = full_func_name.split('.')
the_pack = getattr(some_func_pack,pack)
the_func = getattr(the_pack, funcname)
return the_func
# 在包的父目录执行,把GlobalFunc当成总包 | 在编辑的时候,我们会沉入到内部操作,在应用时则要挂在最外层
# import GlobalFunc as funcs
# the_func = get_func_by_para(funcs, 'Base.to_pickle')
class GFGo:
def __init__(self):
pass
# 执行 pack_func ~ Base.to_pickle
@staticmethod
def _exe_func_args(global_func = None, pack_func = None, args = None):
exe_func = get_func_by_para(global_func, pack_func)
return exe_func(*args)
@staticmethod
def _exe_func_kwargs(global_func = None, pack_func = None, kwargs = None):
exe_func = get_func_by_para(global_func, pack_func)
return exe_func(**kwargs)
# 重载包
@staticmethod
def _reload_package(package_name):
reload_package(package_name)
3.4 提交保存
docker commit df5a340570ab myregistry.domain.com:24052/worker.andy.globalfunc:v101
docker push myregistry.domain.com:24052/worker.andy.globalfunc:v101
小插曲
自建的docker 镜像仓库需要使用证书到期了,因此要重新刷新一下。
制作一个10年的证书
openssl req \
-newkey rsa:4096 -nodes -sha256 -keyout /home/certs/domain.key \
-addext "subjectAltName = DNS:myregistry.domain.com" \
-x509 -days 3650 -out /home/certs/domain.crt
制作好证书后进行分发和授信。
# 1)安装工具包
apt-get install -y ca-certificates
# 2)复制ca.crt
cp /home/certs/domain.crt /usr/local/share/ca-certificates/domain.crt
# 3)更新被信任的CA证书
update-ca-certificates
# 4)重启本地dockerd(此步骤是必须的,否则依然报错x509: certificate signed by unknown authority)
systemctl daemon-reload
systemctl restart docker
要注意的是,镜像仓库的服务由于要存储镜像,需要较大的空间,因此项目的启动位置会存放在存储空间较大的位置。
3.5 调用执行
启动容器
docker run -it --rm myregistry.domain.com:24052/worker.andy.globalfunc:v101 bash
执行命令
from GFGo import GFGo
import GlobalFunc as funcs
gfgo = GFGo()
pack_func = 'Base.to_pickle'
kwargs1 = {'data':'a',
'file_name':'a_data',
'path':'./'}
gfgo._exe_func_kwargs(global_func =funcs,pack_func= pack_func, kwargs = kwargs1)
data save to pickle: ./a_data.pkl
4 服务化
GlobalFunc有两种使用方式:本地模式和API模式,其中本地模式也就是普通的包调用模式,而API模式是本次要讨论的模式。
由于每个GlobalFunc的容器都会有资源限制,且由于计算资源的分布式化,未来其容器(分身)将会呈现随机化的态势。
GlobalFunc本身是为了提供无差别的函数服务,所以端口将采取分配一个地址段的方式,而不是按照规则指定。端口区间采用26000~27000。
一个容器将由所在的宿主机、镜像版本、内存上限、显存上限以及端口号决定。例如: m7_v101_30G_0G_26000表示在m7上运行的容器,采用v101版本,最大内存为30G,最大显存0G(无显卡),占用端口26000.
服务会分为两部分,服务端与客户端。
服务仅接受和返回json字符串,客户端完成格式转换。
所以服务端承担的功能相对简单,而客户端则需要处理相对复杂的翻译功能。另外,服务端所执行的必然是有返回的函数操作,而不能是本地文件操作。例如使用to_pickle,文件将会存在服务端的文件系统。
服务端采用tornado搭建,一方面其格式非常简单,另一方面效率非常高。
安装了tornado包之后,只需要两个文件就可以启动server了。
文件1: server_funcs.py
过去,我会把服务需要的函数放在这里,现在的话,理论上可以不需要,因为所有的依赖函数都会在GlobalFunc包中。
不过从设计的角度,我认为仍然应该保留这个文件(即使是空的)。因为未来有可能有一些服务的配置,以及一些固定的数据库连接可以放在这里。这样会比较便于管理,避免反复建立数据库连接。
文件2: server.py
在当前容器中,必然存在GFGo.py和GlobalFunc, 在server.py中引入他们。同时也存在,即使是空的server_funcs.py。
from server_funcs import *
from GFGo import GFGo
import GlobalFunc as funcs
一个启动示例
from server_funcs import *
from GFGo import GFGo
import GlobalFunc as funcs
import tornado.httpserver # http服务器
import tornado.ioloop # ?
import tornado.options # 指定服务端口和路径解析
import tornado.web # web模块
from tornado.options import define, options
import os.path # 获取和生成template文件路径
app_list = []
IndexHandler_path = r'/'
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.write('【GET】This is Website for Internal API System')
self.write('Please Refer to API document')
print('Get got a request test')
# print(buffer_dict)
def post(self):
request_body = self.request.body
print('Trying Decode Json')
some_dict = json.loads(request_body)
print(some_dict)
msg_dict = {}
msg_dict['info'] = '【POST】This is Website for Internal API System'
msg_dict['input_dict'] = some_dict
self.write(json.dumps(msg_dict))
print('Post got a request test')
IndexHandler_tuple = (IndexHandler_path,IndexHandler)
app_list.append(IndexHandler_tuple)
if __name__ == '__main__':
#
tornado.options.parse_command_line()
apps = tornado.web.Application(app_list, **settings)
http_server = tornado.httpserver.HTTPServer(apps)
define('port', default=8000, help='run on the given port', type=int)
http_server.listen(options.port)
# 单核
# 多核打开注释
# 0 是全部核
# http_server.start(num_processes=10) # tornado将按照cpu核数来fork进程
# ---启动
tornado.ioloop.IOLoop.instance().start()
启动服务
python3 server.py
本地调用
import requests as req
In [4]: req.get('http://127.0.0.1:8000/').text
Out[4]: '【GET】This is Website for Internal API SystemPlease Refer to API document'
In [7]: req.post('http://127.0.0.1:8000/',json = {}).json()
Out[7]: {'info': '【POST】This is Website for Internal API System', 'input_dict': {}}
参数化调用一个函数
函数用于将时间字符串转为时间戳(在统一时间轴之下,已经不再需要用这个函数)
import time
def inverse_time_str(time_str = None, bias_hours = 0):
ts = time.mktime (time.strptime(time_str,'%Y-%m-%d %H:%M:%S')) + bias_hours* 3600
return ts
'''
你的 inverse_time_str 函数用于将时间字符串转换回时间戳,考虑了时区偏移。该函数接受一个时间字符串和偏移小时数,并返回一个时间戳(以秒为单位)。
你的函数实现看起来是正确的,它使用了 time.mktime 和 time.strptime 来执行字符串到时间戳的转换。偏移小时数被考虑在内,以便根据需要调整时间戳。
'''
假设我们知道一个时间字符串,并希望知道其东八区时间的时间戳,那么发送请求
import requests as req
pack_func = 'Base.inverse_time_str'
kwargs = {'time_str':'2024-02-15 11:11:11',
'bias_hours':-8}
req.post('http://127.0.0.1:8000/gfgo/',json = {'pack_func':pack_func,'kwargs':kwargs}).json()
1707966671
服务端:大约花了0.53ms来完成
[I 240215 08:31:48 web:2239] 200 POST /gfgo/ (127.0.0.1) 0.53ms

到这里,GlobalFunc的基础部分,也就是连通性部分已经完成。之后将可以基于这个基础进行下一步的开发,GF将会成为下一代CalNet的逻辑执行基础。
其他
原来在开发算网(CalNet)的时候,总是假设机器处在局域网中,但是实际上并不是。而且由于CalNet是基于微服务搭建的,网络配置应该作为一项独立的配置独立出来。在外网去调用微服务时,由于数据库操作代理服务默认使用了内网地址,在很多参数传递时又偷懒了,所以连接起来非常不方便。
Next,重新设计操作微服务的对象,通过分离配置、操作引导等方式改进体验。