目录
一、Hive分区表
1.1 分区表的概念
1.2 分区表的创建
1.3 分区表数据加载及查询
1.3.1 静态分区
1.3.2 动态分区
1.4 分区表的本质及使用
1.5 分区表的注意事项
1.6 多重分区表
二、Hive分桶表
2.1 分桶表的概念
2.2 分桶表的创建
2.3 分桶表的数据加载
2.4 分桶表的作用
一、Hive分区表
1.1 分区表的概念
Partition分区表是hive的一种优化手段表,当Hive表数据量大,查询时通过 where子句筛选指定的分区,这样的查询效率会提高很多,避免全表扫描。
Hive支持根据指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。分区在存储层面上的表现是table表目录下以子文件夹形式存在。一个文件夹表示一个分区。子文件命名标准:分区列=分区值,Hive还支持分区下继续创建分区,所谓的多重分区。
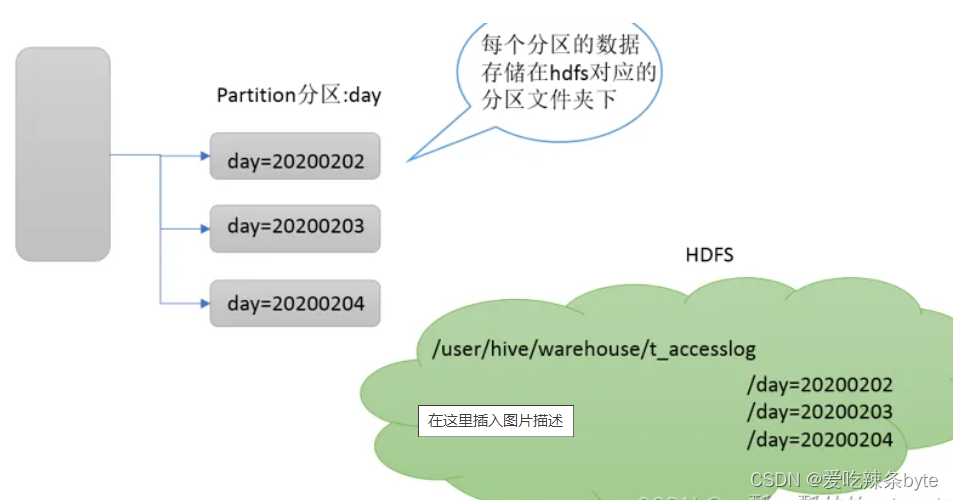
1.2 分区表的创建
- 语法
create table table_name (column1 data_type, column2 data_type)
partitioned by (partition1 data_type, partition2 data_type,….)
row format delimited fields terminated by '\t';- 示例
创建一张分区表t_all_hero_part,以role角色作为分区字段。
create table t_all_hero_part(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
)
partitioned by (role string)
row format delimited
fields terminated by "\t";ps:分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上,可以将分区字段看作表的伪列。
1.3 分区表数据加载及查询
1.3.1 静态分区
-
数据加载
静态分区指的是分区的字段值是由用户在加载数据的时候手动指定的。语法如下:
load data [local] inpath ' ' into table tablename partition(分区字段='分区值'...); 关键字Local存在表示原数据是位于本地文件系统(linux);关键字Local不存在:表示原数据是位于HDFS文件系统。
(1)假设原文件位于HDFS文件系统,则静态加载数据的操作如下:
create external table ods_log_inc
(
common struct<ar :string,ba :string,ch :string,is_new :string,md :string,mid :string,os :string,uid :string,vc
:string> comment '公共信息',
page struct<during_time :string,item :string,item_type :string,last_page_id :string,page_id
:string,source_type :string> comment '页面信息',
actions array<struct<action_id:string,item:string,item_type:string,ts:bigint>> comment '动作信息',
displays array<struct<display_type :string,item :string,item_type :string,order :string,pos_id
:string>> comment '曝光信息',
start struct<entry :string,loading_time :bigint,open_ad_id :bigint,open_ad_ms :bigint,open_ad_skip_ms
:bigint> comment '启动信息',
err struct<error_code:bigint,msg:string> comment '错误信息',
ts bigint comment '时间戳'
) comment '活动信息表'
partitioned by (dt string)
row format serde 'org.apache.hadoop.hive.serde2.jsonserde'
location '/warehouse/gmall/ods/ods_log_inc/';
#==============数据装载
load data inpath '/origin_data/gmall/log/topic_log/2020-06-15' into table ods_log_inc partition(dt='2020-06-15');
(2)假设原文件位于本地的linux系统,则静态加载数据的操作如下:
create table t_order (
oid int ,
uid int ,
otime string,
oamount int
)
comment '订单表'
partitioned by (dt string)
row format delimited fields terminated by ",";
#=========数据加载
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order partition(dt ='2024-02-14');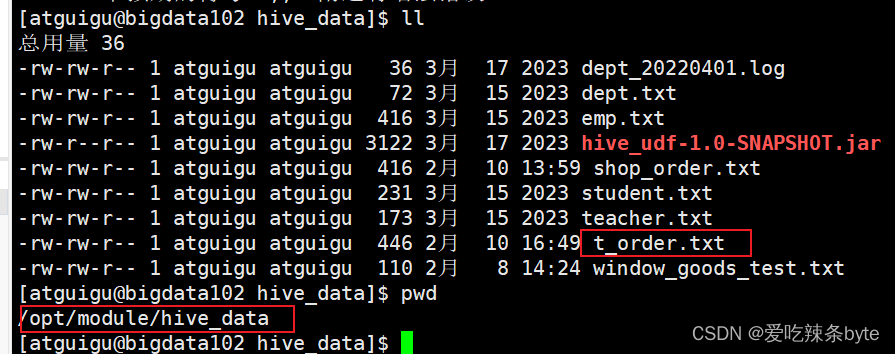 ps:分区表加载数据时,必须指定分区
ps:分区表加载数据时,必须指定分区
-
数据查询
select * from t_order where dt='2024-02-14';1.3.2 动态分区
所谓动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insert+select。
hive是批处理系统,提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
启用hive动态分区,需要设置两个参数:
# 表示开启动态分区功能能(默认true)
set hive.exec.dynamic.partition=true;
#设置为非严格模式nonstrict
set hive.exec.dynamic.partition.mode=nonstrict;
-----动态分区的模式,分为nonstick非严格模式和strict严格模式。,hive动态分区默认是strict,该模式要求至少有一个分区为静态分区 ,nonstrict 模式表示允许所有的分区字段都可以使用动态分区
Hive对其创建的动态分区数量实施限制,总结而言:每个节点默认限制100个动态分区,所有节点的总(默认)限制为1000个动态分区,相关参数如下:
#在每个执行MR的节点上,最大可以创建多少个动态分区,默认值为100
hive.exec.max.dynamic.partitions.pernode=100;
ps:该参数需要根据业务数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数
需要设置成大于365,如果使用默认值100,则会报错。
#在所有执行 MR 的节点上,最大一共可以创建多少个动态分区,默认1000
hive.exec.max.dynamic.partitions=1000;
#整个MR Job 中,最大可以创建多少个HDFS 文件,默认100000
hive.exec.max.created.files=100000;ps:实际生产环境中,动态分区数量的阈值可以根据业务数据情况进行调整。
# 创建一张新的分区表t_all_hero_part_dynamic
create table t_all_hero_part_dynamic(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
# 需求:将t_all_hero表中的数据按照角色(role_main 字段),插入到目标表t_all_hero_part_dynamic的相应分区中。
insert into table t_all_hero_part_dynamic partition(role)
select tmp.*,tmp.role_main from t_all_hero as tmp;
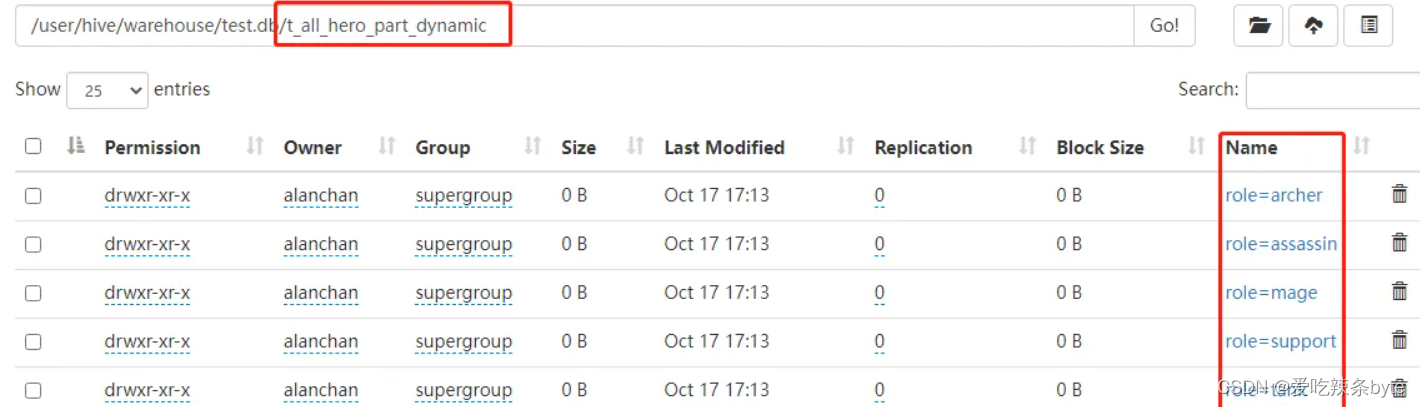
#查看目标表的的分区情况
show partitions t_all_hero_part_dynamic;
#查看分区表结构
desc formatted t_all_hero_part_dynamic;动态分区插入时,分区值是根据查询返回字段位置自动推断的。上述代码中,推断出原表t_all_hero中的字段role_main是 目标表t_all_hero_part_dynamic 的动态分区字段
1.4 分区表的本质及使用
- 建表时根据业务场景设置合适的分区字段。比如日期、地域、类别等;
- 查询的时候尽量先使用where进行分区过滤,查询指定分区的数据,避免全表扫描。
1.5 分区表的注意事项
- 分区表不是建表的必要语法规则,是一种优化手段表,可选;
- 分区字段不能是表中已有的字段,不能重复;
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值可以手动指定(静态分区),也可以根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,支持更细粒度的目录划分
1.6 多重分区表
Hive支持多个分区字段:partitioned by (partition1 data_type, partition2 data_type,….);多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。
例如创建一张三分区表,按省份、市、县分区
# 创建分区表
create table t_user_province_city_county (
id int,
name string,
age int
)
partitioned by (province string, city string,county string)
row format delimited fields terminated by ",";
#加载数据到三级分区表中
load data local inpath '文件路径' into table t_user_province_city_county partition(province='hubei',city='xiangyang',county='gucheng');
二、Hive分桶表
2.1 分桶表的概念
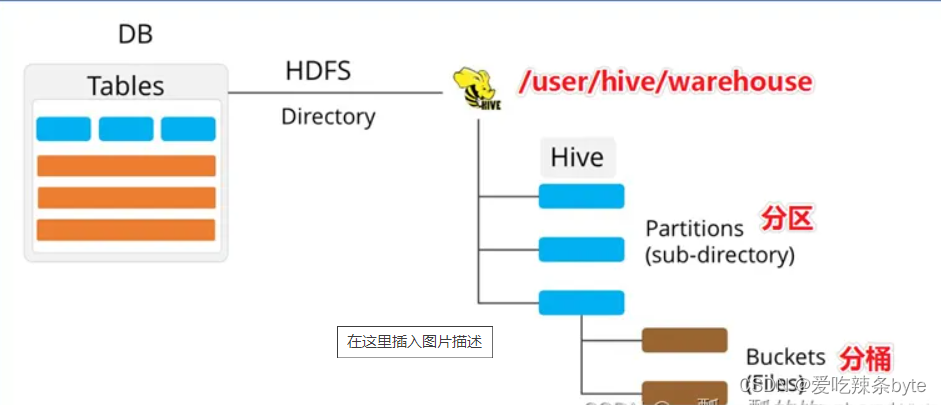
Bucket分桶表是hive的一种优化手段表。分桶是指数据表中某字段的值,经过hash计算规则将数据分为指定的若干小文件。 Bucket分桶表在hdfs中表现为同一个表目录下的数据根据hash散列之后变成多个文件。分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)。
分桶默认规则是:分桶编号Bucket number = hash_function(分桶字段) % 桶数量。桶编号相同的数据会被分到同一个桶当中。
ps:hash_function函数取决于分桶字段的数据类型,如果是int类型,hash_function(int) == int;
如果是其他数据类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。


2.2 分桶表的创建
- 语法
--分桶表建表语句
create [external] table [db_name.]table_name[(col_name data_type, ...)]
clustered by (col_name) #--根据col_name字段分桶
into n buckets #--分为n桶
row format delimited fields terminated by '\t';- 示例
--创建分桶表,分为4桶
create table stu_buck(
id int,
name string
)
clustered by(id)
into 4 buckets
--创建分桶表,分为4桶,还可以指定分桶内的数据排序规则,根据id倒叙排序
create table stu_buck(
id int,
name string
)
clustered by(id) sorted by (id desc)
into 4 buckets
--查看表结构
desc formatted stu_buck;
ps:分桶的字段必须是表中已经存在的字段。
2.3 分桶表的数据加载
load data inpath '/student.txt' into table stu_buck;
2.4 分桶表的作用
- 基于分桶字段查询时,减少全表扫描;
- join时可以提高MR程序效率,减少笛卡尔积数量;
对于join操作两个表有一个相同的列,如果对这两个表都进行了分桶操作。那么将保存相同列值的桶进行JOIN操作就可以,这种join方式也称作SMB(Sort Merge Bucket join)
三、总结
- 分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)
- 分区本质是划分hdfs目录,分桶本质是划分数据本身
- 分区字段不能是表中已经存在的字段,分桶的字段必须是表中已经存在的字段
参考文章:
https://blog.51cto.com/alanchan2win/6453477
HiveQL常用查询语句——排序、分桶、分桶抽样子句记录_hive 按分桶查询吗-CSDN博客