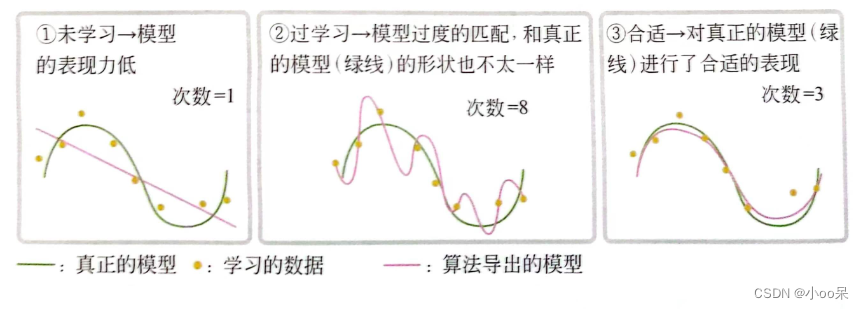
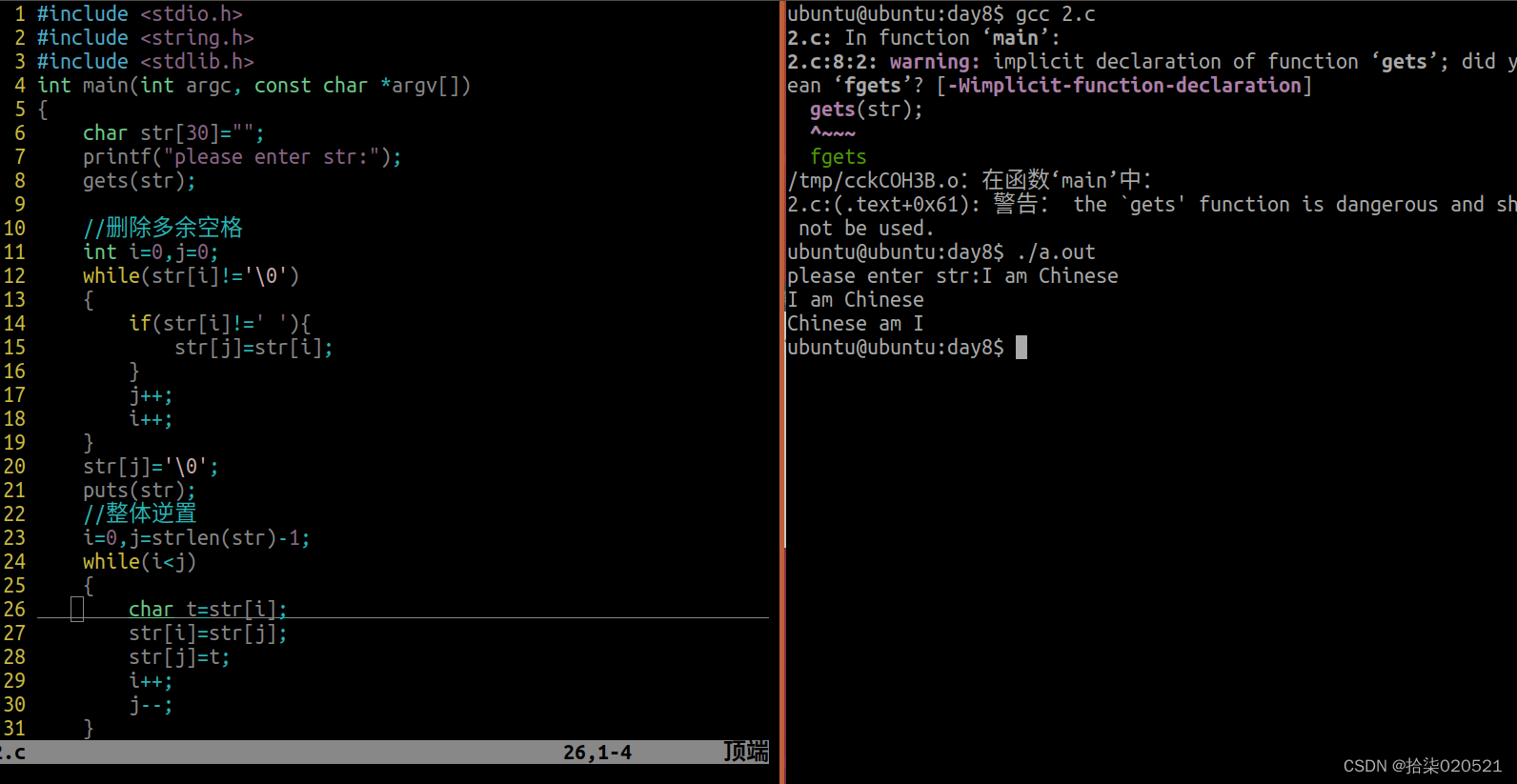
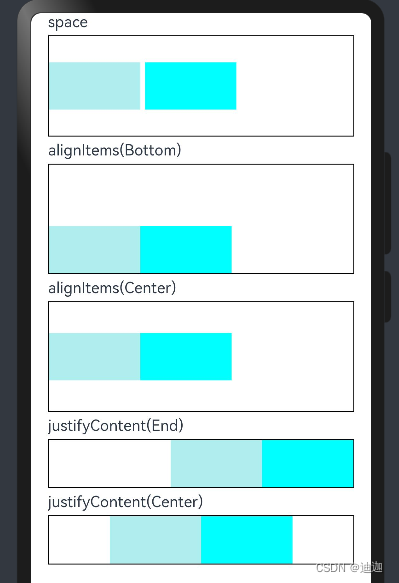
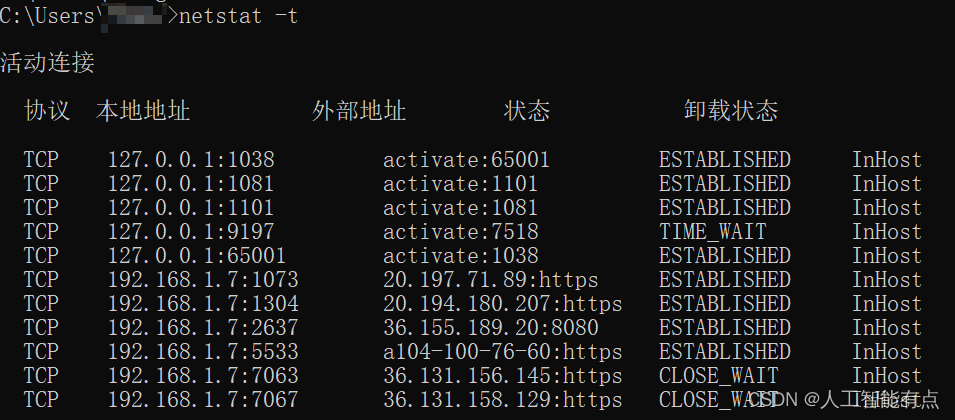
在分布式系统中,消息中间件扮演着至关重要的角色,它们负责在系统组件之间传递消息,实现解耦、异步通信和流量削峰等功能。RocketMQ与Kafka作为两款流行的消息中间件,各自拥有独特的架构设计和功能特性。本文将深入对比分析RocketMQ与Kafka在架构设计、组件构成、数据流向、扩展性、容错性和一致性等方面的差异,帮助读者更好地理解这两款消息中间件的特点和适用场景。
一、系统设计与组件构成
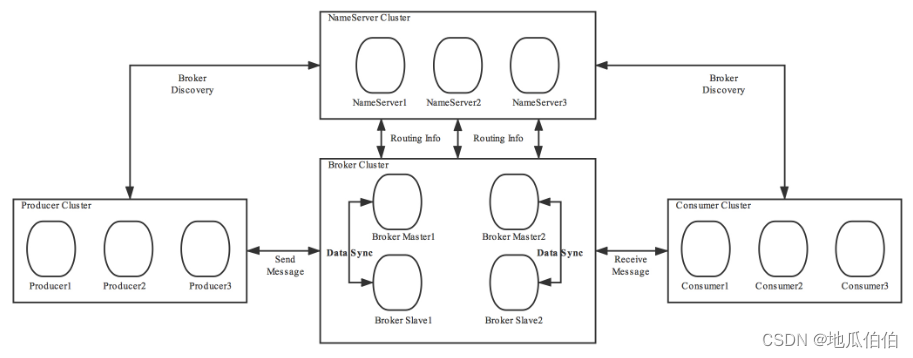
RocketMQ的系统设计更偏向于队列模型,提供了丰富的消息队列语义,如顺序消息、事务消息和定时消息等。它主要由NameServer、Broker、Producer和Consumer组成。NameServer负责服务注册与发现,Broker负责存储消息,Producer和Consumer分别负责发送和消费消息。此外,RocketMQ还支持Filter Server组件,用于支持消息过滤功能。这种设计使得RocketMQ在处理复杂业务逻辑时更加灵活。
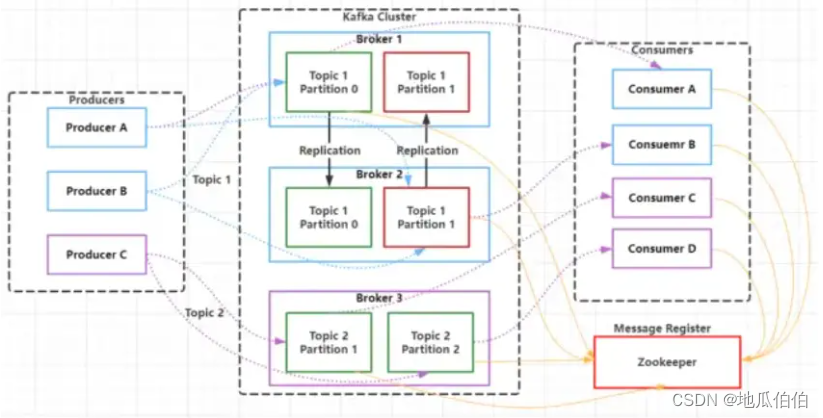
相比之下,Kafka的系统设计更偏向于日志模型,强调数据的顺序性和持久性。它主要由Producer、Consumer、Broker和ZooKeeper(或KRaft)组成。Producer和Consumer分别负责发送和消费消息,Broker负责存储消息,ZooKeeper(或KRaft)负责协调管理。Kafka的Broker是无状态的,可以独立处理请求,并通过ZooKeeper(或KRaft)进行协调管理。这种设计使得Kafka在处理高吞吐量日志数据时更加高效。
二、数据流向与扩展性
在RocketMQ中,数据从Producer发送到Broker,Consumer从Broker拉取数据进行消费。RocketMQ支持消息的Tag过滤和SQL过滤,可以在Broker端进行消息过滤。此外,RocketMQ还支持事务消息和顺序消息,可以确保数据的强一致性和有序性。在扩展性方面,RocketMQ支持Broker的横向扩展,通过增加Broker节点来提高系统的吞吐量和可用性。同时,RocketMQ还支持Topic和Queue的灵活配置,可以根据业务需求进行动态调整。
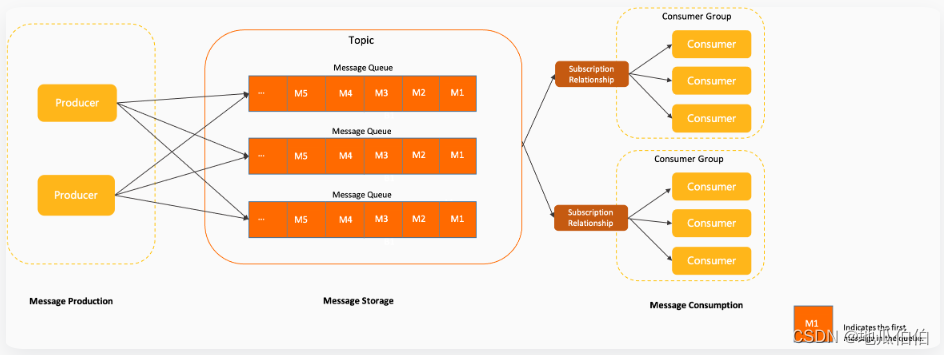
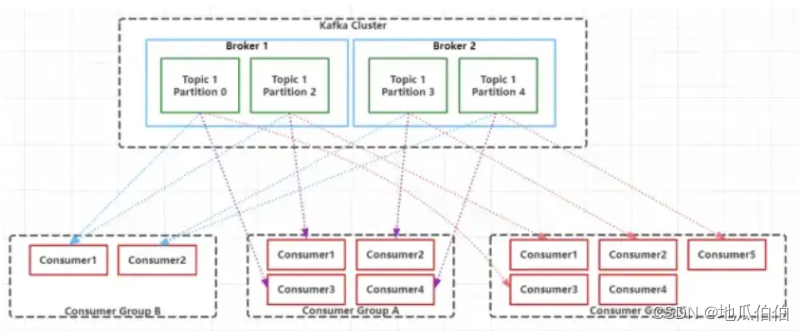
而在Kafka中,数据从Producer发送到Broker的特定Partition,Consumer从Broker的Partition拉取数据进行消费。Kafka支持按照Key进行消息分区,确保相同Key的消息发送到同一个Partition。在扩展性方面,Kafka的Broker是无状态的,可以方便地进行横向扩展,提高系统的吞吐量和可用性。同时,Kafka支持Partition的动态调整,可以通过增加Partition数量来提高系统的并行处理能力。
三、容错性与一致性
RocketMQ采用主从复制机制来提高容错性。当Master出现故障时,Slave可以自动升级为Master继续提供服务。同时支持Dledger多副本机制,进一步提高系统的容错性。在一致性方面,RocketMQ通过主从复制和顺序消息机制保证数据的一致性和有序性。此外,RocketMQ还支持消息的幂等性处理,避免重复消费导致的数据不一致问题。
Kafka则通过ISR机制保证数据的可靠性和一致性。当Leader出现故障时,Follower可以通过选举成为新的Leader继续提供服务。Kafka还支持多副本存储和Min.ISR配置,确保数据的可靠性和容错性。在一致性方面,Kafka通过ISR机制和分区顺序性保证数据的一致性和有序性。同时支持Exactly-Once语义,确保分布式环境下的消息幂等性。此外,Kafka还通过日志压缩功能减少存储空间占用并提高查询效率。
四、总结与展望
通过对RocketMQ与Kafka在架构设计、组件构成、数据流向、扩展性、容错性和一致性等方面的深入对比分析,我们可以发现这两款消息中间件各有千秋。RocketMQ更适合需要丰富队列语义和灵活消费模式的场景;而Kafka则更适合强调数据顺序性、持久性和高吞吐量的日志处理场景。在实际应用中,我们需要根据具体业务需求和系统特点进行选择和配置。
随着分布式系统的不断发展,消息中间件的作用将越来越重要。未来,我们可以期待RocketMQ与Kafka在性能优化、功能增强和生态扩展等方面取得更多的突破和创新,为分布式系统的发展注入新的活力。