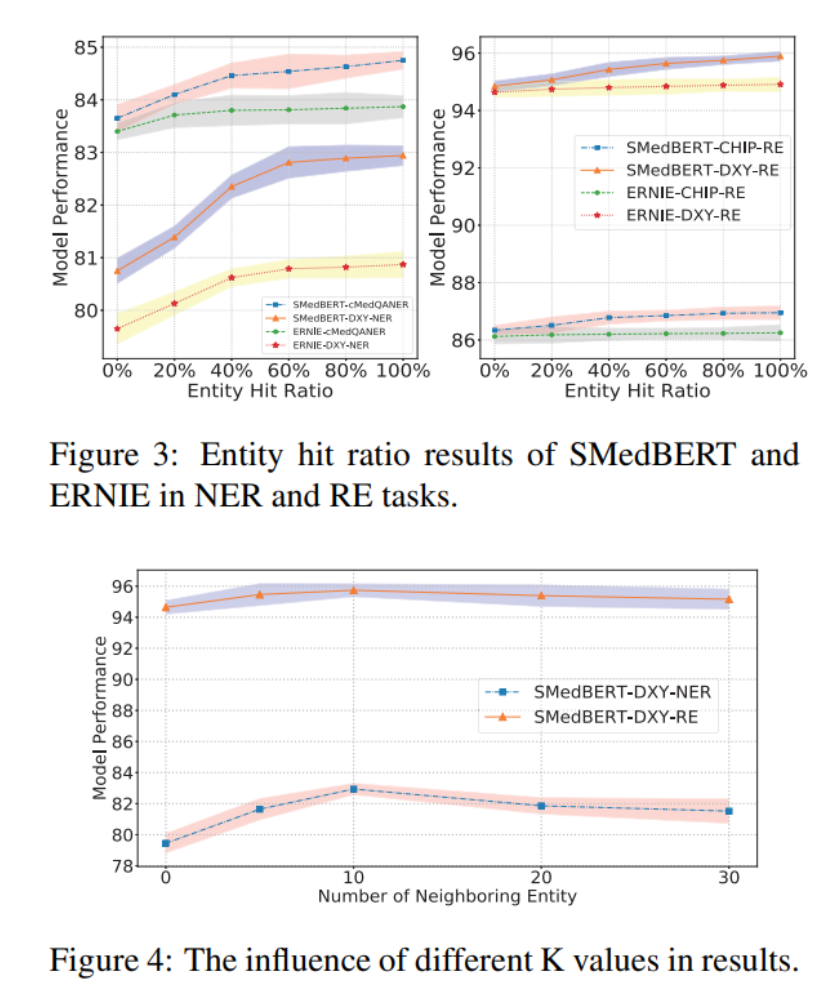
一、说明
拼写检查器项目涉及创建一个可以自动检测并纠正给定文本中的拼写错误的程序。此类项目在各种应用程序中非常有用,例如文字处理器、电子邮件客户端和网络浏览器,可确保用户生成的文本没有拼写错误。
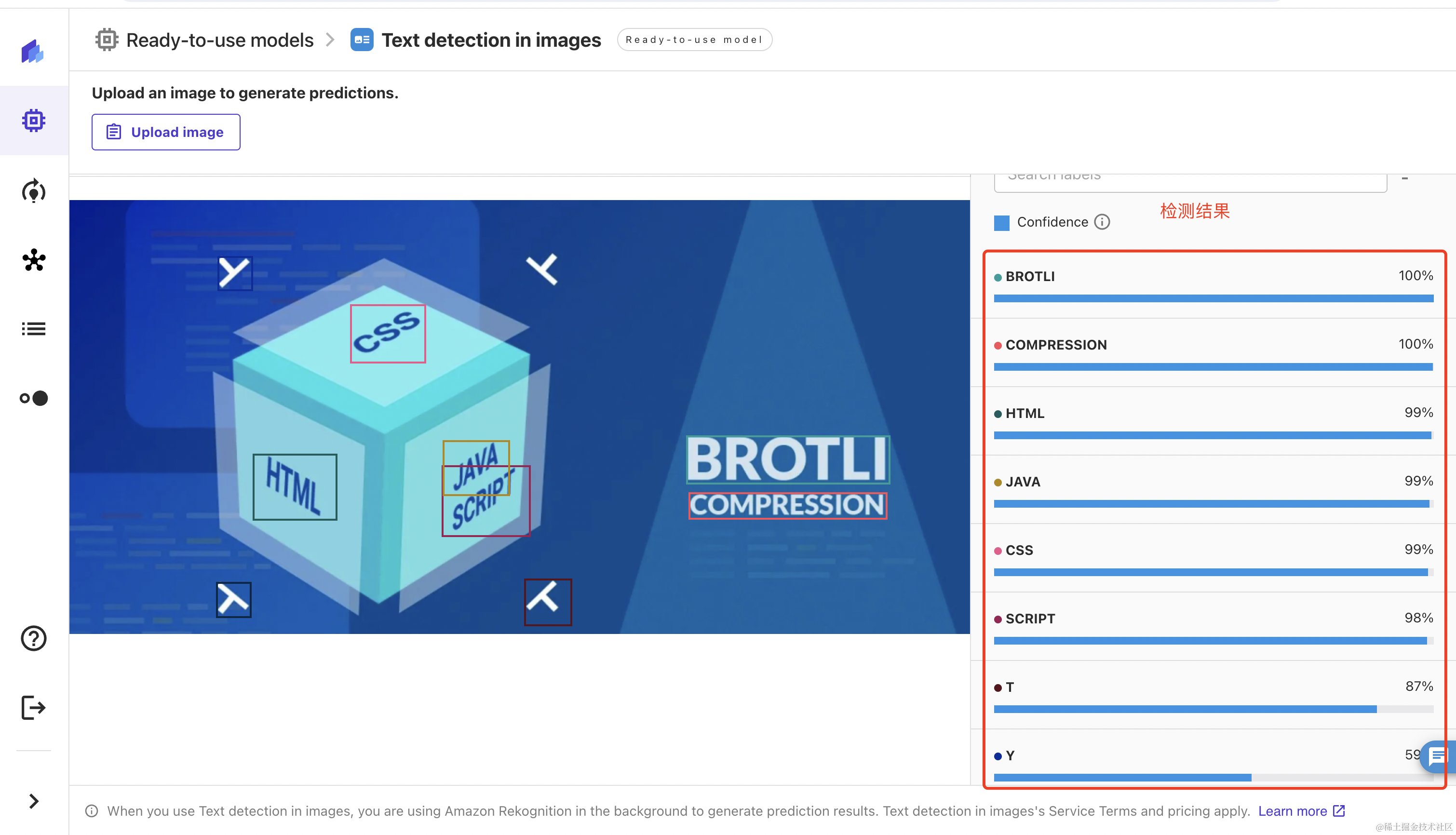
您可以找到我创建的拼写检查器应用程序: https: //spellchecker-xr26zeryecn4cugmwrvgje.streamlit.app/
二、拼写检查应用程序创建方法:
可以使用多种方法创建拼写检查器应用程序:
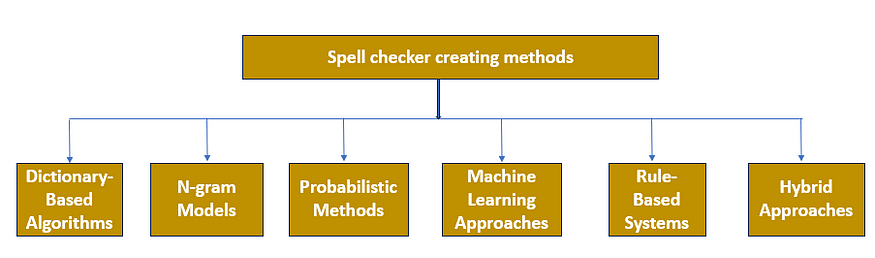
- 基于字典的算法:
- 基于查找:该算法使用预先构建的正确单词词典。它会根据字典检查输入文本中的每个单词,并针对未找到的单词提出更正建议。
- 编辑距离:该算法计算将一个单词转换为另一个单词所需的编辑(插入、删除、替换)次数。然后根据编辑距离最小的单词提出建议。在这篇文章中,我们将详细讨论这个主题。
2. N-gram 模型: N-gram 是相邻单词或字母的序列。N-gram 模型使用特定单词序列一起出现的可能性的统计分析。建议基于相邻单词组合的概率。
3. 概率方法:
- 贝叶斯方法:这些方法使用贝叶斯概率来估计句子中某个单词在给定上下文的情况下正确的可能性。
- 上下文信息:拼写检查器可以考虑单词的周围上下文来改进纠正建议。例如,一个单词的正确拼写可能取决于它周围的单词。
4. 机器学习方法:
- 监督学习:使用正确和错误拼写的标记数据集,可以训练机器学习算法来预测拼写错误单词的更正。
- 神经网络:深度学习模型,例如循环神经网络 (RNN) 或 Transformer,可用于拼写检查任务。这些模型可以捕获语言中的复杂模式和依赖性。
5. 基于规则的系统:
- 形态分析:分析单词的结构并应用语言规则来生成建议。这对于具有复杂形态的语言特别有用。
- 基于语法的方法:根据语法规则检查输入文本,以识别并纠正潜在的拼写错误。
6. 混合方法:将多种技术(例如基于字典的方法与机器学习模型)相结合,以提高拼写检查的准确性和覆盖范围。
三、拼写检查器中的错误检查指标
A. 非单词错误 :当单词拼写错误或形成不正确时,就会发生非单词错误,从而导致字母序列与任何有效单词都不对应。
B. 真实单词错误:另一方面,真实单词错误涉及将一个单词转换为另一个有效单词的拼写错误,从而可能改变其含义。
在今天的课程中,我们将研究基于字典的编辑距离算法。
在接下来的文章中,我们将详细介绍更多算法。
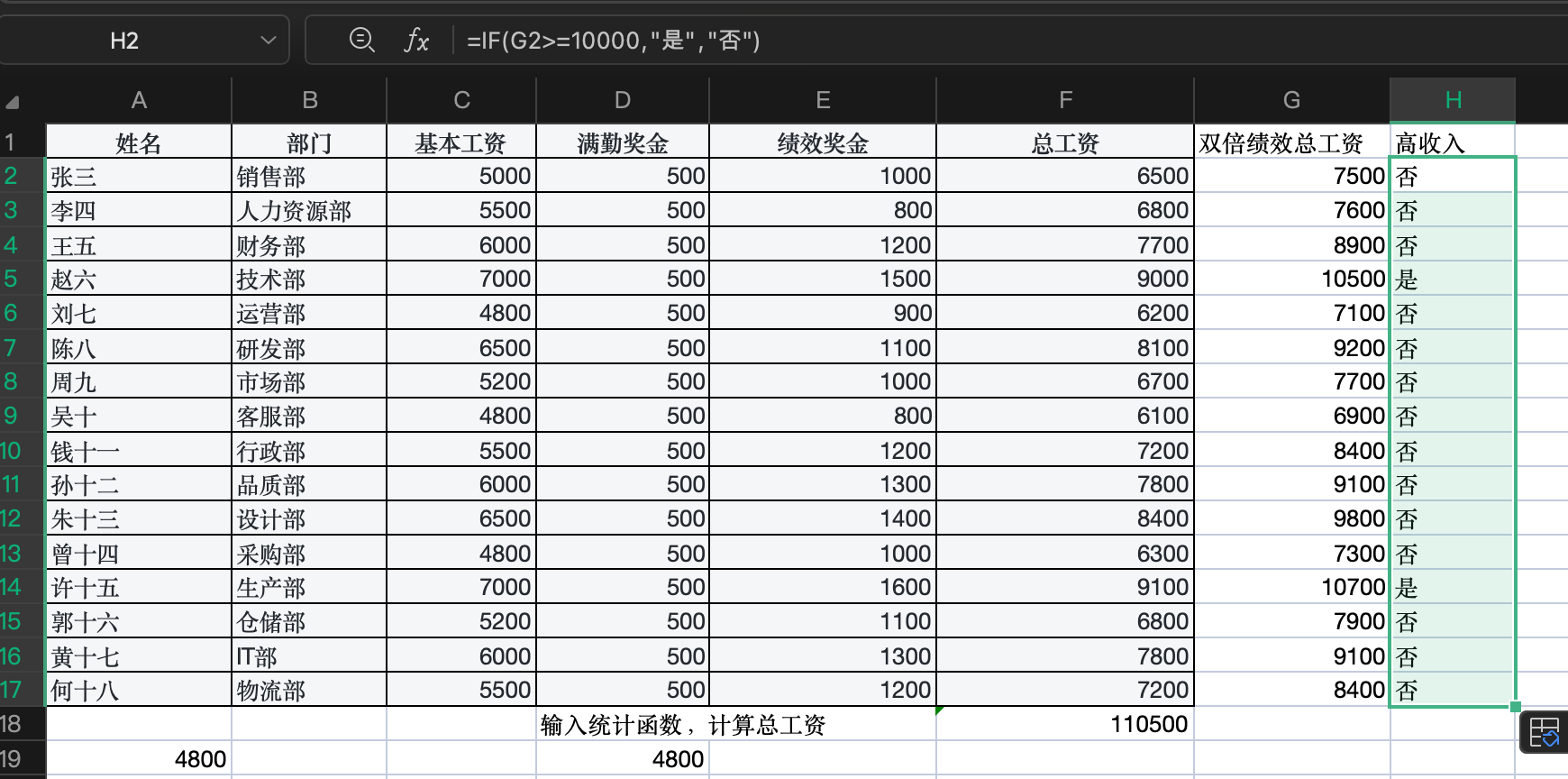
1.小写和标记化
# Function to tokenize words
def words(document):
"Convert text to lower case and tokenize the document"
return re.findall(r'\w+', document.lower()) 此函数将 big.txt 文档作为输入,将文本转换为小写,并将文档标记为单词列表。它使用正则表达式r'\w+'查找文档中的所有单词字符(字母、数字和下划线)序列。
2.读取文档中的每个单词,传入word函数,统计每个单词的个数
all_words = Counter(words(open('big.txt').read()))打开名为“big.txt”的文件并读取其内容。然后对文本文件中的每个单词调用words(document)函数。
是Counter一个 Python 类,用于计算集合中元素的出现次数。在本例中,它获取 生成的单词列表words(document)并创建一个类似字典的对象,其中键是唯一单词,值是文档中每个单词的计数。
例如:
all_words=Counter({'the': 79809, 'of': 40024, 'and': 38312, 'to': 28765, 'in': 22023, 'a': 21124.....})3.生成与输入单词相距一次编辑的所有可能单词
我。splits:创建单词所有可能拆分的列表。
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]单词“THANKSGIPNG”的示例:
word='THANKSGIPNG'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
splits[('', 'THANKSGIPNG'),
('T', 'HANKSGIPNG'),
('TH', 'ANKSGIPNG'),
('THA', 'NKSGIPNG'),
('THAN', 'KSGIPNG'),
('THANK', 'SGIPNG'),
('THANKS', 'GIPNG'),
('THANKSG', 'IPNG'),
('THANKSGI', 'PNG'),
('THANKSGIP', 'NG'),
('THANKSGIPN', 'G'),
('THANKSGIPNG', '')]A. 删除:C通过从原始单词中删除一个字符来创建拆分内的单词列表。
deletes = [left + right[1:] for left, right in splits if right]对于上面的例子:
deletes = [left + right[1:] for left, right in splits if right]
deletes['HANKSGIPNG',
'TANKSGIPNG',
'THNKSGIPNG',
'THAKSGIPNG',
'THANSGIPNG',
'THANKGIPNG',
'THANKSIPNG',
'THANKSGPNG',
'THANKSGING',
'THANKSGIPG',
'THANKSGIPN']B. 插入:通过在原始单词中每个可能的位置插入每个字母,从拆分列表中创建单词列表。
inserts = [left + c + right for left, right in splits for c in alphabets]['aTHANKSGIPNG', 'bTHANKSGIPNG', 'cTHANKSGIPNG', 'dTHANKSGIPNG', 'eTHANKSGIPNG', 'fTHANKSGIPNG', 'gTHANKSGIPNG', 'hTHANKSGIPNG', .....]C. 替换:通过用每个字母替换拆分列表单词中的每个字符来创建单词列表。
replaces = [left + c + right[1:] for left, right in splits if right for c in alphabets]['aHANKSGIPNG',
'bHANKSGIPNG',
'cHANKSGIPNG',
'dHANKSGIPNG',
'eHANKSGIPNG',
'fHANKSGIPNG',
'gHANKSGIPNG',
'hHANKSGIPNG',
'iHANKSGIPNG',
'jHANKSGIPNG',
'kHANKSGIPNG',
'lHANKSGIPNG',
'mHANKSGIPNG',...
..........
..........
..........
'THANKSGIPNv',
'THANKSGIPNw',
'THANKSGIPNx',
'THANKSGIPNy',
'THANKSGIPNz']]D. transposes:此行通过转置(交换)分割列表单词中的相邻字符来创建单词列表。
transposes = [left + right[1] + right[0] + right[2:] for left, right in splits if len(right) > 1]['HTANKSGIPNG',
'TAHNKSGIPNG',
'THNAKSGIPNG',
'THAKNSGIPNG',
'THANSKGIPNG',
'THANKGSIPNG',
'THANKSIGPNG',
'THANKSGPING',
'THANKSGINPG',
'THANKSGIPGN']二. 合并删除、插入、替换和传输以获得所有可能的单词
合并完成后,我们需要获取该集合,因为我们不希望重复任何单词。
set(deletes + inserts + replaces + transposes)因此我们的最终函数是:
def edits_one(word):
"Create all edits that are one edit away from `word`."
alphabets = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [left + right[1:] for left, right in splits if right]
inserts = [left + c + right for left, right in splits for c in alphabets]
replaces = [left + c + right[1:] for left, right in splits if right for c in alphabets]
transposes = [left + right[1] + right[0] + right[2:] for left, right in splits if len(right) > 1]
return set(deletes + inserts + replaces + transposes)4.生成距输入单词两次编辑的所有可能编辑
def edits_two(word):
# Generate all possible edits one edit away from the original word
one_edit_away = edits_one(word)
# Generate all possible edits two edits away by applying edits_one to each one-edit-away edit
two_edits_away = (e2 for e1 in one_edit_away for e2 in edits_one(e1))
return two_edits_away 它需要一个单词,找到所有可能的一次编辑修正 ( one_edit_away),然后通过应用到每个一次编辑修正来生成两次编辑修正 ( two_edits_away) 。edits_one
5. 创建一组新的已知单词
我们获取一组单词 ( words) 并检查每个单词是否出现在全局all_words计数器中。存在的单词all_words被添加到一个名为known_words
def known(words):
known_words = set()
for word in words:
if word in all_words:
known_words.add(word)
return known_words6. 检查该单词是否存在于创建的known_words列表、一个编辑列表或两个编辑列表中
我们创建更正,以检查单词本身是否已知,或者是否存在经过一两次编辑后的已知更正。如果没有找到更正,那么我们将原始单词包含在结果中
def possible_corrections(word):
corrections = known([word]) or known(edits_one(word)) or known(edits_two(word))
corrections = corrections or [word]
return corrections7. 求给定单词的概率
我们计算给定单词的概率。我们通过将单词出现的次数(由 计数all_words[word])除以标记总数(N)来做到这一点。
def prob(word, N=sum(all_words.values())):
return all_words[word] / N8. 在可能的校正集中找到最高概率的元素
更正存储输入单词的一组可能的拼写更正,例如:“THANKSGIPNG”。我们使用该max函数来查找可能的校正集中概率最高的元素。
注意:该key参数指定比较应基于函数计算的概率prob。
def spell_check(word):
corrections = possible_corrections(word)
most_probable = max(corrections, key=prob)
return "Did you mean {}?".format(most_probable) if most_probable != word else "Correct spelling."
如果最可能的更正与原始单词不同,它会返回一个字符串,使用将该单词format插入most_probable字符串的方法来建议正确的拼写。如果更正与原始单词相同,则返回一个字符串,表明拼写正确。
9. 输入用户的单词并使用单词和拼写检查功能进行分析
首先,我们使用该函数将用户输入标记为单词列表words。然后,我们使用该函数为输入文本中的每个标记生成拼写建议spell_check。
然后,我们将显示拼写检查结果的降价标题。
这将显示令牌、其索引以及我们使用 Streamlit 应用程序中的pell_check 获得的建议更正。
def main():
st.title("Aneesha's Spell Checker App")
st.text("Happy to have you here!")
user_input = st.text_area("Enter your text for spell checking:", "")
if st.button("Check Spelling"):
tokens = words(user_input)
suggestions = [spell_check(token) for token in tokens]
st.markdown("### Spell Check Results:")
for i, (token, suggestion) in enumerate(zip(tokens, suggestions)):
st.text(f"{i + 1}. {token}: {suggestion}")四、后记
本文首先介绍拼写检查方法,然后简单介绍一些用法。对于工作人员来说,虽然可能不从事具体技术,但是抛砖引玉可以获得启发,再说行业发展趋势还是需要了解的。
检查部署的此应用程序:https://spellchecker-xr26zeryecn4cugmwrvgje.streamlit.app/
欲了解更多此类内容,请订阅!



![[ai笔记5] 个人AI资讯助手实战](https://img-blog.csdnimg.cn/img_convert/8bfa0cfae898d570a0bb14623661c8e1.png)