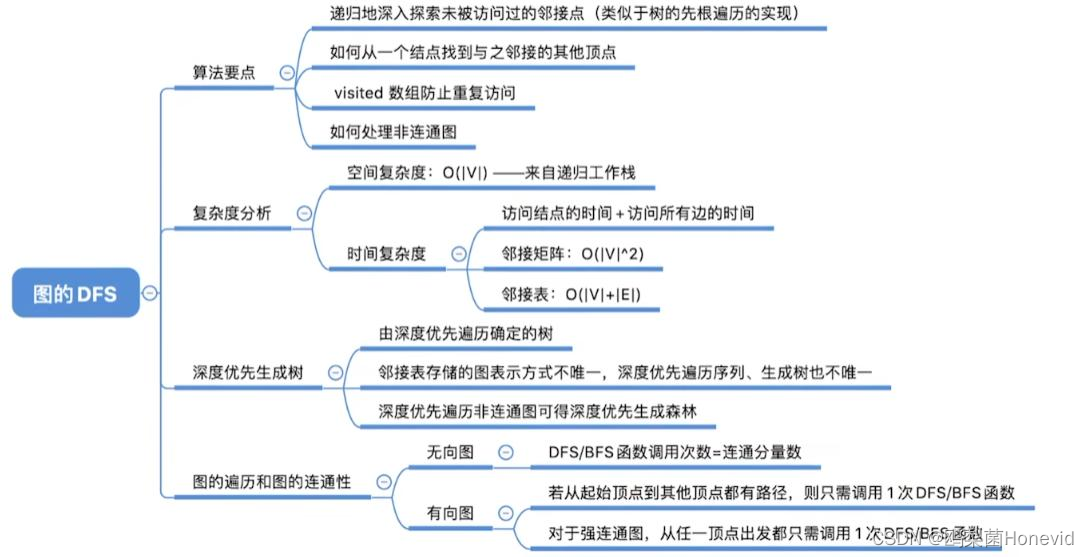
目录
一、双列集合
1、双列集合的特点
2、双列集合的常见API
3、Map的遍历方式
3.1第一种遍历方式:键找值(keySet)
3.2第二种遍历方式:键值对(entrySet)Entry:键值对对象
3.3第三种遍历方式:Lambda表达式(forEach)
二、HsahMap集合
1、HashMap的特点
2、HashMap的底层原理
3、小结
4、HashMap练习
4.1存储学生对象并遍历
4.2Map集合案例-统计投票人数
三、LinkedHashMap
编辑
四、TreeMap
1、练习TreeMap基本应用
2、练习统计个数
3、小结
编辑
五、原码解析
1、HashMap的底层原理(一)
1.1源码中的类型介绍
1.2HashMap中的每一个元素是什么?
2、HashMap的底层原理(二)
2.1看源码前的准备工作
2.2创建对象、第一种情况:添加元素(添加第一个元素,即数组位置为null)底层原理
2.3第二种情况:添加其他元素(数组位置不为null)底层原理
编辑
2.4为什么hashcode值要与数组长度-1做一次“与”运算?【★】
2.5 第三种情况:添加元素(数组位置不为null,键重复,元素覆盖)
3、TreeMap中的底层源码(一)
3.1为什么这里的默认颜色为BLACK?
3.2TreeMap中每一个节点的内部属性
3.3TreeMap类中的成员变量以及构造器
3.4面试小问题
六、可变参数
1、普通示例
2、数组使用示例
3、JDK5-可变参数
4、可变参数小细节
5、小结
七、Collections
编辑1、addAll() 批量添加元素
2、shuffle() 打乱List集合元素的顺序
3、其它方法
八、综合练习
1、自动点名器
2、自动点名器2(概率——随机面)
3、自动点名器3(不会重复且会循环点名——辅助列表)
4、自动点名器4(权重)
2、Map集合案例——省和市
一、双列集合
1、双列集合的特点

在Map中定义了双列集合所有的共性方法:
2、双列集合的常见API

示例代码
添加元素:put()
//1.创建Map集合的对象
Map<String,String> m = new HashMap<>();
//2.添加元素
//put方法的细节:
//添加/覆盖
//在添加数据的时候。如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回null
//在添加数据的时候,如果键是存在的,那么把原有的键值对对象覆盖,会把被覆盖的值进行返回。
m.put("郭靖","黄蓉");
m.put("韦小宝","沐剑屏");
m.put("杨过","小龙女");
//String value = m.put("韦小宝", "双儿");
//System.out.println(value);put小细节:
- 在添加数据的时候。如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回null
- 在添加数据的时候,如果键是存在的,那么把原有的键值对对象覆盖,会把被覆盖的值进行返回。
删除元素:删除元素,返回删除值 remove()
//删除
String reuslt = m.remove("郭靖");
System.out.println(reuslt);清空元素:clear()
//清空
m.clear();判断是否包含:containsKey()
//判断是否包含
boolean keyResult = m.containsKey("郭靖");
System.out.println(keyResult);
boolean valueResult = m.containsKey("小龙女");
System.out.println(valueResult);判空判断:isEmpty()
boolean result = m.isEmpty();
System.out.println(result);长度:size()
//长度
int size = m.size();
System.out.println(size);3、Map的遍历方式
3.1第一种遍历方式:键找值(keySet)
public class A02_MapDemo2 {
public static void main(String[] args) {
//Map集合的第一种遍历方式
//1.创建Map集合的对象
Map<String,String> map = new HashMap<>();
//2.添加元素
map.put("伊志平","小空女");
map.put("郭靖","穆念慈");
map.put("来来来","哈哈哈");
//3.通过键找值
//3.1获取所有的键,把这些键放到一个单列集合当中
Set<String> keys = map.keySet();
//3.2遍历单列结合,得到每一个键
for(String key:keys){
//System.out.println(key);
//3.3利用Map结合中的键获取对应的值 get
String value = map.get(key);
System.out.println(key +" = "+value);
}
}
}
课堂练习:
//三个课堂练习
//
//练习一:利用键找值的方式遍历map集合,要求: 装着键的单列集合使用增强for的形式进行遍历
//练习二:利用键找值的方式遍历map集合,要求: 装着键的单列集合使用迭代器的形式进行遍历
//练习三:利用键找值的方式遍历map集合,要求: 装着键的单列集合使用lambda表达式的形式进行遍历//2.迭代器
Iterator<String> it = keys.iterator();
while(it.hasNext()){
String str = it.next();
System.out.println(str);
}
//3.forEach遍历
keys.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
//Lambda表达式改进
keys.forEach( s-> System.out.println(s));3.2第二种遍历方式:键值对(entrySet)
Entry:键值对对象
public class A03_MapDemo3 {
public static void main(String[] args) {
//Map集合的第二种遍历方式
//三个课堂练习
//1.创建Map集合的对象
Map<String, String> map = new HashMap<>();
//2.添加元素
//键:任务的外号
//值:人物的名字
map.put("标枪选手", "马超");
map.put("人物挂件", "明世隐");
map.put("驯龙骑士", "你好");
//3.Map集合的第二种遍历方式
//通过键值对对象进行遍历
//3.1通过一个方法获取所有的键值对对象,返回一个Set集合
Set<Map.Entry<String, String>> entries = map.entrySet();
//3.2遍历entries这个集合,去得到里面的每一个键值对象
for (Map.Entry<String, String> entry : entries) {
//3.3利用entry调用get方法获取键和值
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
}
}
课堂练习:
//三个课堂练习
//通过键值对对象进行遍历map集合,要求: 装着键值对对象的单列集合使用增强for的形式进行遍历
//通过键值对对象进行遍历map集合,要求: 装着键值对对象的单列集合使用迭代器的形式进行遍历
//通过键值对对象进行遍历map集合,要求: 装着键值对对象的单列集合使用lambda的形式进行遍历
//2.迭代器
System.out.println("===========================");
Iterator<Map.Entry<String,String>> it= entries.iterator();
while(it.hasNext()){
Map.Entry<String,String> str = it.next();
System.out.println(str.getKey()+"="+str.getValue());
}
//3.forEach遍历
entries.forEach(new Consumer<Map.Entry<String, String>>() {
@Override
public void accept(Map.Entry<String, String> stringStringEntry) {
System.out.println(stringStringEntry.getKey()+"="+stringStringEntry.getValue());
}
});
//4.Lambda表达式
entries.forEach(stringStringEntry ->
System.out.println(stringStringEntry.getKey()+"="+stringStringEntry.getValue()));
}3.3第三种遍历方式:Lambda表达式(forEach)

示例代码:
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class A04_MapDemo4 {
public static void main(String[] args) {
//Map集合的第三种遍历方式
//1.创建Map集合的对象
Map<String, String> map = new HashMap<>();
//2.添加元素
map.put("鲁迅","这句话是我说的");
map.put("曹操","不可能绝对不可能");
map.put("刘备","接着奏乐接着舞");
//3.利用lambda表达式进行遍历
//底层:
//forEach其实就是利用第二种方式进行遍历,依次得到每一个键和值
//再调用accept方法
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key+"="+value);
}
});
System.out.println("---------------------------------");
//Lambda表达式
map.forEach((String key, String value)-> {
System.out.println(key+"="+value);
}
);
//Lambda简化
map.forEach(( key, value)-> System.out.println(key+"="+value));
}
}
二、HsahMap集合

1、HashMap的特点

2、HashMap的底层原理
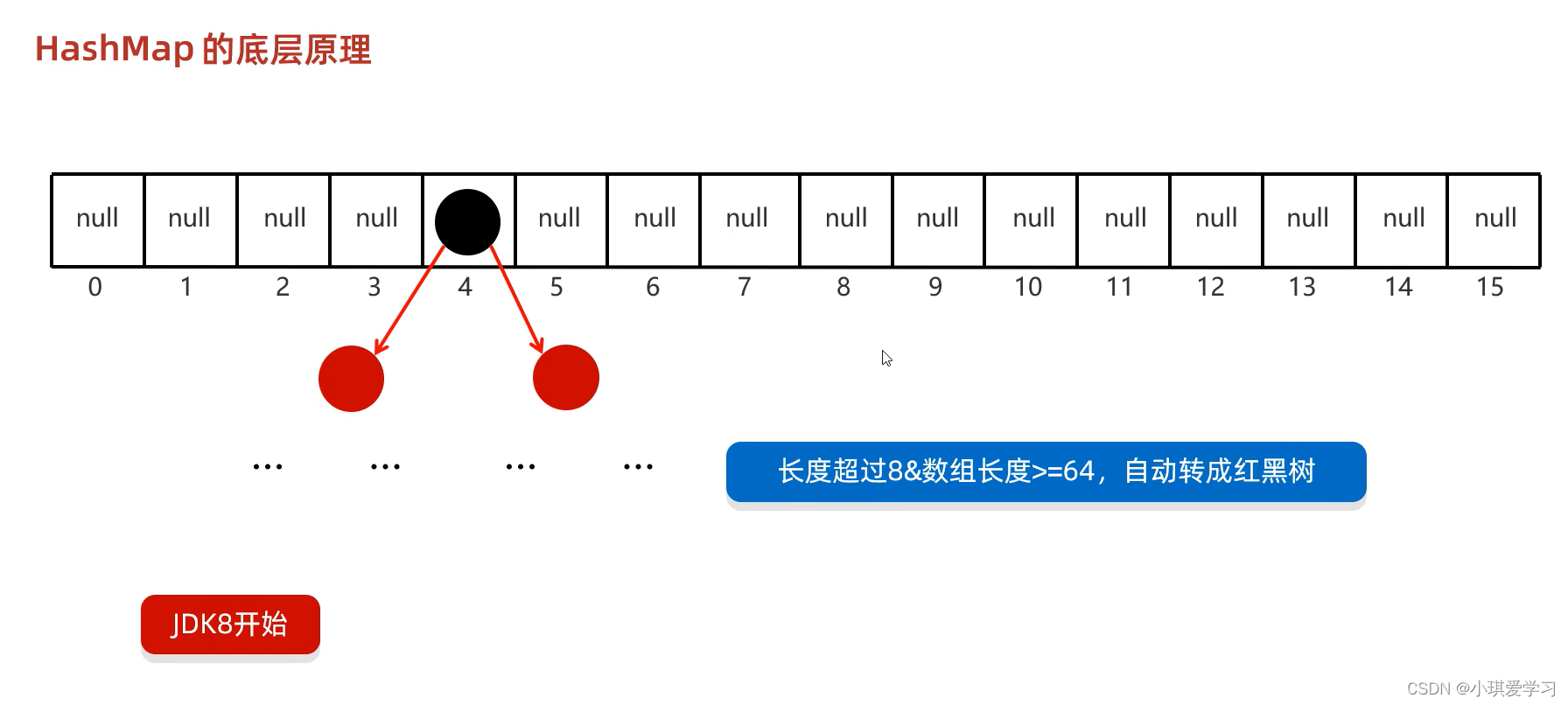
- HashMap首先还是会创建一个默认长度为16,默认加载因子为0.75的数组;
- 然后再利用put方式,就可以添加数据了,put方法的底层会先创建一个Entry对象,Entry对象里面记录的就是要添加的键和值,然后利用键来计算哈希值,跟值无关,然后再计算出元素在数组中应存储的位置的索引,如果该位置为null,直接添加,如果该位置不为null,它会调用equals方法比较键的属性值,如果键的值相同,那么元素就会被覆盖;如果比较完后不一样,则会添加新的Entry对象;
- JDK8,如果计算出来的索引相同,且键不一致,那么就会直接挂在当前值的下面;
- 此外,当链表长度超过8,且数组长度大于等于64的时候,链表就会自动转成红黑树
3、小结

4、HashMap练习
4.1存储学生对象并遍历

import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class A05_HashMapDemo1 {
public static void main(String[] args) {
/*
需求: 创建一个HashMap集合,键是学生对象(student),值是籍贤(String)。
存储三个键值对元素,并遍历
要求:同姓名,同年龄认为是同一个学生
梭心点:
HashMap的键位置如果存傲的是自定义对象,需要重写hashCode和equals方法。
*/
//1.创建HashMap的对象
HashMap<Student, String> hm = new HashMap<>();
//2.创建HashMap的对象
Student s1 = new Student("zhangsan", 23);
Student s2 = new Student("lisi", 24);
Student s3 = new Student("wangwu", 25);
Student s4 = new Student("wangwu", 25);
//3.添加元素
hm.put(s1, "江苏");
hm.put(s2, "浙江");
hm.put(s3, "福建");
hm.put(s4, "山东");
//4.遍历集合
Set<Student> keys = hm.keySet();
for (Student key : keys) {
String value = hm.get(key);
System.out.println(key + "=" + value);
}
System.out.println("----------------------------");
Set<Map.Entry<Student, String>> entries = hm.entrySet();
for (Map.Entry<Student, String> entry : entries) {
Student key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
}
System.out.println("----------------------------");
hm.forEach(( student, s) -> System.out.println(student+"="+s));
}
}
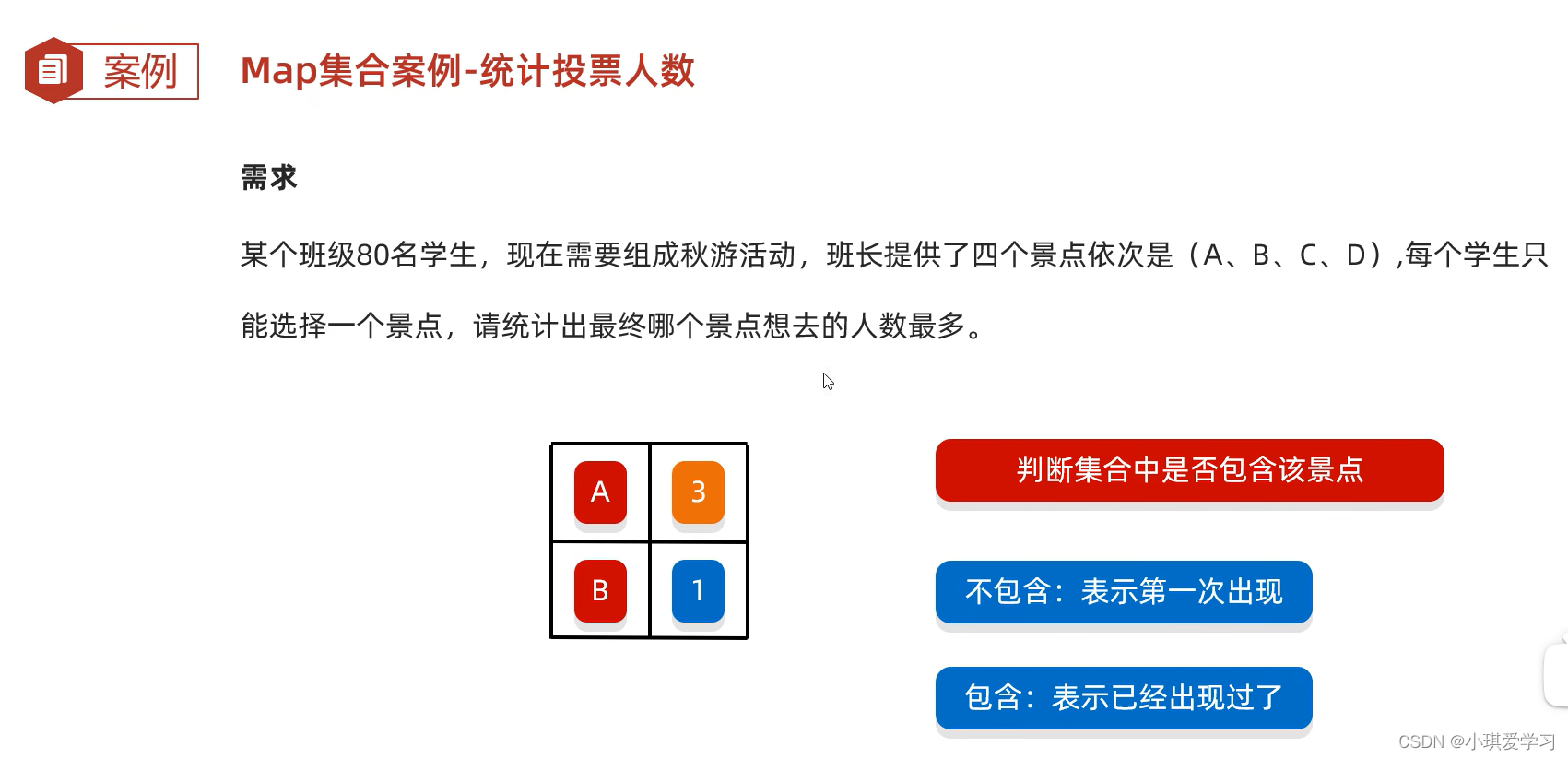
4.2Map集合案例-统计投票人数
package com.yaqi.a01mymap;
import java.util.*;
public class A06_HashMapDemo2 {
public static void main(String[] args) {
/*
某个班级80名学生。现在需要组成秋游活动。
班长提供了四个景点依次是《A、B、C、D) ,
每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多
*/
//1.需要先让同学们投票
//定义一个数组,存储4个景点
String[] arr = {"A", "B", "C", "D"};
//利用随机数模拟80个同学的投票,并把票数的结果存储起来
ArrayList<String> list = new ArrayList<>();
Random r = new Random();
for (int i = 0; i < 80; i++) {
int index = r.nextInt(arr.length);
list.add(arr[index]);
}
//2.如果要统计的东西比较多,不方便使用计数器思想
//我们可以定义map集合,利用集合进行统计。
HashMap<String, Integer> hm = new HashMap<>();
for (String name : list) {
//判断当前景点在Map集合当中是否存在
if (hm.containsKey(name)) {
//存在
//先获取当前景点已经被投票的次数
int count = hm.get(name);
//表示当前景点又被投了一次
count++;
//把新的次数再次添加到集合当中
hm.put(name, count);
} else {
//不存在
hm.put(name, 1);
}
}
System.out.println(hm);
//3.求最大值
int max = 0;
Set<Map .Entry<String,Integer>> entries = hm.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
int count = entry.getValue();
if(count>max){
max = count;
}
}
System.out.println(max);
//4.判断哪个景点的次数跟最大值一样,如果一样打印出来
for (Map.Entry<String, Integer> entry : entries) {
int count = entry.getValue();
if(count==max){
System.out.println(entry.getKey());
}
}
}
}
三、LinkedHashMap
代码:
import java.util.LinkedHashMap;
public class A01_LinkedHashMapDemo1 {
public static void main(String[] args) {
/*
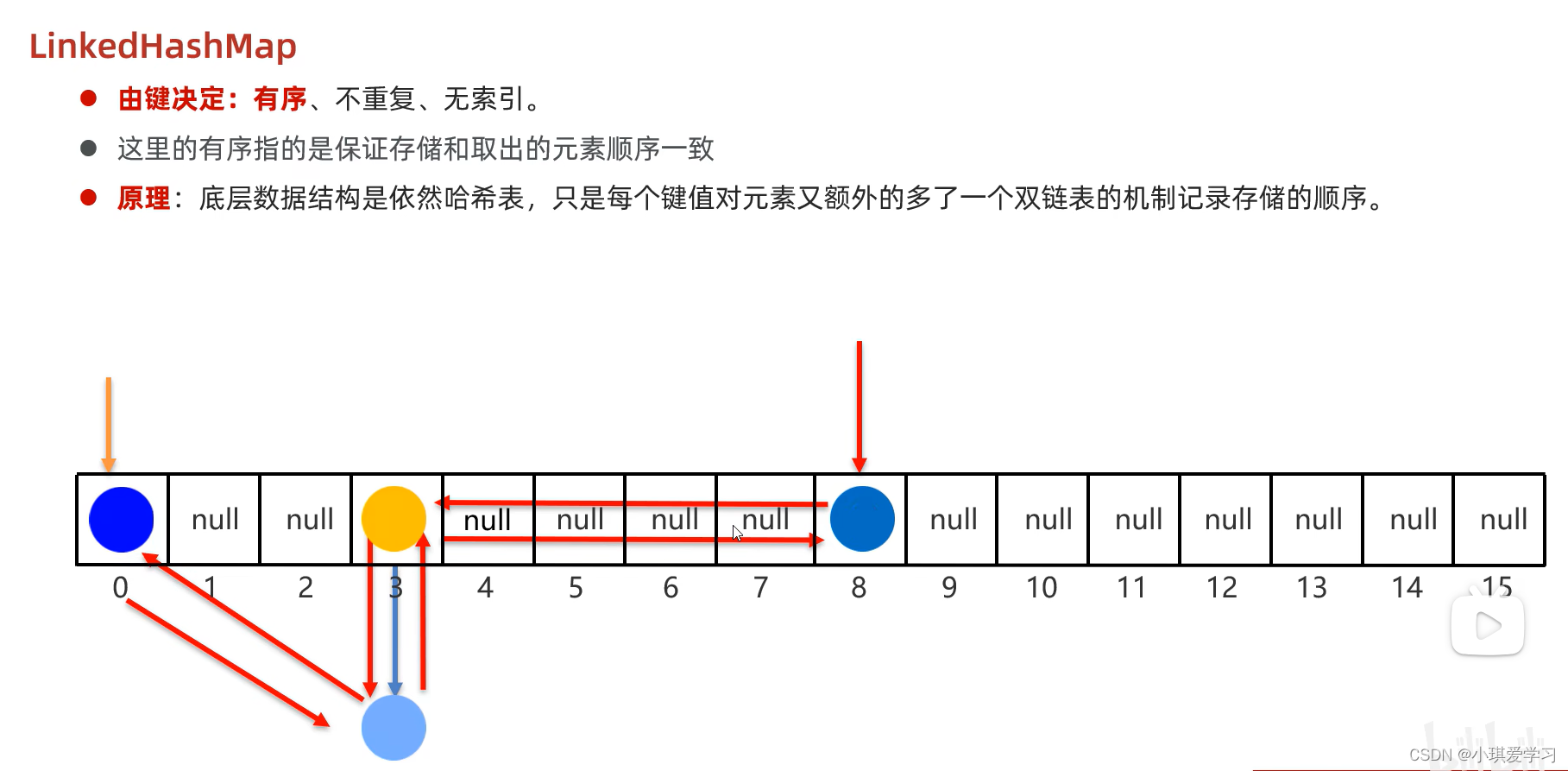
LinkedHashMap:
由键决定:
有序、不重复、无素引。
有序:
保证存储和取出的顺序一致
原理:
底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。
*/
//1.创建集合
LinkedHashMap<String,Integer> lhm = new LinkedHashMap<>();
//2.添加元素
lhm.put("c",789);
lhm.put("b",456);
lhm.put("a",123);
lhm.put("a",111);
//3.打印集合
System.out.println(lhm);
}
}

四、TreeMap

1、练习TreeMap基本应用

示例代码:(Integer、Double 默认情况下都是按照升序排列的)
(String 按照字母在ASCII码表中对应的数字升序排列 abcdefg…)
TreeMap集合: 基本应用
需求1:
键:整数表示id
值: 字符串表示商晶名称
要求1: 按照id的升序排列
要求2: 按照id的降序排列

TreeMap集合: 基本应用 需求2: 键:学生对象 值: 籍贯 要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人。
import java.util.TreeMap;
public class A02_TreeMapDemo2 {
public static void main(String[] args) {
/*
TreeMap集合: 基本应用
需求2:
键:学生对象
值: 籍贯
要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人。
*/
//1.创建集合
TreeMap<Student,String> tm = new TreeMap<>();
//2.创建三个学生对象
Student s1 = new Student("zhangsan",23);
Student s2=new Student("lisi",24);
Student s3 = new Student("wnagwu",25);
//3.添加元素
tm.put(s1,"武汉");
tm.put(s2,"天津");
tm.put(s3,"北京");
//4.打印集合
System.out.println(tm);
}
}
2、练习统计个数
需求:
字符串“aababcabcdabcde”
请统计宁符串中每一个字符出现的次数,并按照以下格式输出
输出结果:
a(5) b (4) c (3) d (2) e(1)
新的统计思想: 利用map集合进行统计
如果题目中没有要求对结果进行排序,默认使用HashmMap
如果题目中要求对结果进行排序,请使用TreeMap
键:表示要统计的内容
值:表示次数
import java.util.StringJoiner;
import java.util.TreeMap;
public class A03_TreeMapDemo3 {
public static void main(String[] args) {
/*
需求:
字符串“aababcabcdabcde”
请统计宁符串中每一个字符出现的次数,并按照以下格式输出
输出结果:
a(5) b (4) c (3) d (2) e(1)
新的统计思想: 利用map集合进行统计
如果题目中没有要求对结果进行排序,默认使用HashmMap
如果题目中要求对结果进行排序,请使用TreeMap
键:表示要统计的内容
值:表示次数
*/
//1.定义字符串
String s = "aababcabcdabcde";
//2.创建集合
TreeMap<Character,Integer> tm = new TreeMap<>();
//3.遍历字符串得到里面的每一个字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
//拿着c到集合中判断是否存在
//存在,表示当前字符又出现了一次
//不存在,表示当前字符是第一次出现
if(tm.containsKey(c)){
//存在
//先把已经出现的次数拿出来
int count = tm.get(c);
//当前字符又出现了一次
count++;
//把自增之后的结果再添加到集合当中
tm.put(c,count);
}else{
//不存在
tm.put(c,1);
}
}
//4.打印集合
//a(5) b(4) c(3) d(2) e(1)
//System.out.println(tm);
//字符串拼接
//StringBuilder sb = new StringBuilder();
//tm.forEach(( key, value)-> sb.append(key).append("(").append(")");
StringJoiner sj = new StringJoiner("","","");
tm.forEach(( key, value)-> sj.add(key+"").add("(").add(value+"").add(")"));
System.out.println(sj);
}
}
遍历集合,并按照指定的格式进行拼接
- StringBuilder
- StringJoiner
//4.打印集合
//a(5) b(4) c(3) d(2) e(1)
//System.out.println(tm);
//字符串拼接
//StringBuilder sb = new StringBuilder();
//tm.forEach(( key, value)-> sb.append(key).append("(").append(")");
StringJoiner sj = new StringJoiner("","","");
tm.forEach(( key, value)-> sj.add(key+"").add("(").add(value+"").add(")"));
System.out.println(sj);3、小结

五、原码解析
1、HashMap的底层原理(一)
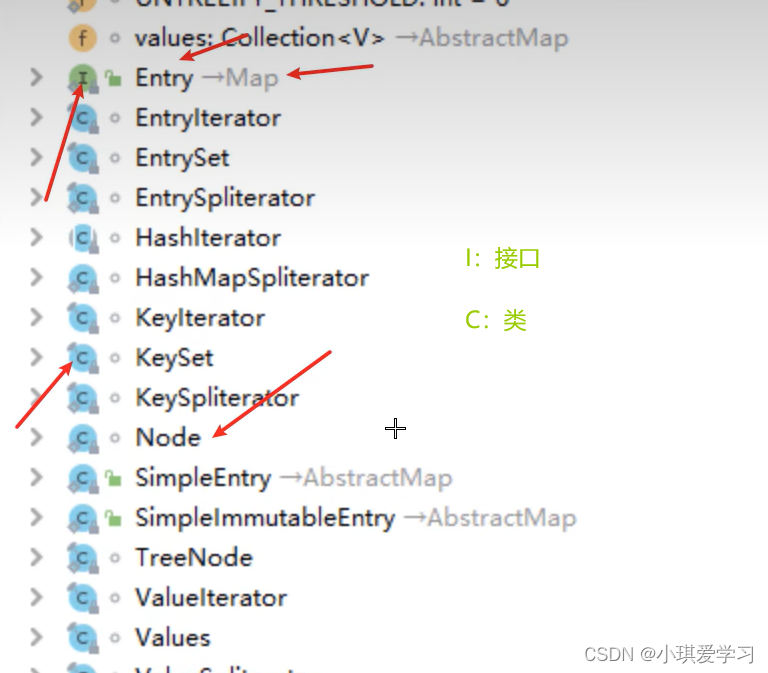
1.1源码中的类型介绍

⬆:表示该方式是父类或者接口中的方法,后面就标记了父类或接口的名称,我们可以理解为这个方法是重写的父类里面的方法;
➡:继承于Xxxx哪个类
f:表示这是HashMap的属性
I:接口
C:类
1.2HashMap中的每一个元素是什么?
在HashMap中每一个元素其实都是一个Node对象:
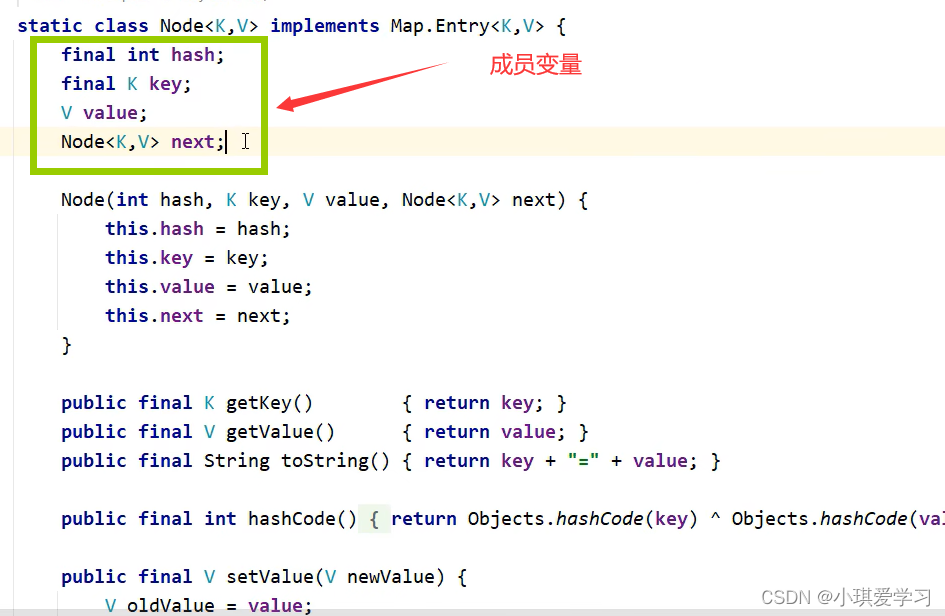
next:表示记录下一个节点的地址值
红黑树:红黑树中的节点为TreeNode

哈希表数组名为Table,默认长度为16

扩容因子:

最大容量:

2、HashMap的底层原理(二)
2.1看源码前的准备工作


数组(table)中的键值对对象是分情况讨论的:
- 数组下面挂的是链表
- 数组下面挂的是红黑树
2.2创建对象、第一种情况:添加元素(添加第一个元素,即数组位置为null)底层原理
刚开始用空参构造创建对象时,底层什么都没有,table也不存在,就是个null
当使用put方法,添加元素后,这个时候数组才存在

put方法:

putVal方法:



扩容机制:
2.3第二种情况:添加其他元素(数组位置不为null)底层原理


2.4为什么hashcode值要与数组长度-1做一次“与”运算?【★】
答:为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间。一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)”, 并且 采用二进制位操作 &,相对于%能够提高运算效率。
总结: a % b 操作等于 a & ( b - 1 ) (前提是b等于2的n次幂)
2.5 第三种情况:添加元素(数组位置不为null,键重复,元素覆盖)

步骤可见2.4
3、TreeMap中的底层源码(一)
TreeMap的底层为红黑树
3.1为什么这里的默认颜色为BLACK?
提高代码的阅读性,红黑树内部还存在调整过程,统一调整成红色。
3.2TreeMap中每一个节点的内部属性

3.3TreeMap类中的成员变量以及构造器

1.TreeMap中每一个节点的内部属性
K key; //键
V value; //值
Entry<K,V> left; //左子节点
Entry<K,V> right; //右子节点
Entry<K,V> parent; //父节点
boolean color; //节点的颜色
2.TreeMap类中中要知道的一些成员变量
public class TreeMap<K,V>{
//比较器对象
private final Comparator<? super K> comparator;//根节点
private transient Entry<K,V> root;//集合的长度
private transient int size = 0;
3.空参构造
//空参构造就是没有传递比较器对象
public TreeMap() {
comparator = null;
}
4.带参构造
//带参构造就是传递了比较器对象。
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
put:添加元素
5.添加元素
public V put(K key, V value) {
return put(key, value, true);
}参数一:键
参数二:值
参数三:当键重复的时候,是否需要覆盖值
true:覆盖
false:不覆盖
private V put(K key, V value, boolean replaceOld) {
//获取根节点的地址值,赋值给局部变量t
Entry<K,V> t = root;
//判断根节点是否为null
//如果为null,表示当前是第一次添加,会把当前要添加的元素,当做根节点
//如果不为null,表示当前不是第一次添加,跳过这个判断继续执行下面的代码
if (t == null) {
//方法的底层,会创建一个Entry对象,把他当做根节点
addEntryToEmptyMap(key, value);
//表示此时没有覆盖任何的元素
return null;
}
//表示两个元素的键比较之后的结果
int cmp;
//表示当前要添加节点的父节点
Entry<K,V> parent;
//表示当前的比较规则
//如果我们是采取默认的自然排序,那么此时comparator记录的是null,cpr记录的也是null
//如果我们是采取比较去排序方式,那么此时comparator记录的是就是比较器
Comparator<? super K> cpr = comparator;
//表示判断当前是否有比较器对象
//如果传递了比较器对象,就执行if里面的代码,此时以比较器的规则为准
//如果没有传递比较器对象,就执行else里面的代码,此时以自然排序的规则为准
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else {
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
} else {
//把键进行强转,强转成Comparable类型的
//要求:键必须要实现Comparable接口,如果没有实现这个接口
//此时在强转的时候,就会报错。
Comparable<? super K> k = (Comparable<? super K>) key;
do {
//把根节点当做当前节点的父节点
parent = t;
//调用compareTo方法,比较根节点和当前要添加节点的大小关系
cmp = k.compareTo(t.key);
if (cmp < 0)
//如果比较的结果为负数
//那么继续到根节点的左边去找
t = t.left;
else if (cmp > 0)
//如果比较的结果为正数
//那么继续到根节点的右边去找
t = t.right;
else {
//如果比较的结果为0,会覆盖
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
}
//就会把当前节点按照指定的规则进行添加
addEntry(key, value, parent, cmp < 0);
return null;
}
private void addEntry(K key, V value, Entry<K, V> parent, boolean addToLeft) {
Entry<K,V> e = new Entry<>(key, value, parent);
if (addToLeft)
parent.left = e;
else
parent.right = e;
//添加完毕之后,需要按照红黑树的规则进行调整
fixAfterInsertion(e);
size++;
modCount++;
}
红黑树规则:
private void fixAfterInsertion(Entry<K,V> x) {
//因为红黑树的节点默认就是红色的
x.color = RED;
//按照红黑规则进行调整
//parentOf:获取x的父节点
//parentOf(parentOf(x)):获取x的爷爷节点
//leftOf:获取左子节点
while (x != null && x != root && x.parent.color == RED) {
//判断当前节点的父节点是爷爷节点的左子节点还是右子节点
//目的:为了获取当前节点的叔叔节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
//表示当前节点的父节点是爷爷节点的左子节点
//那么下面就可以用rightOf获取到当前节点的叔叔节点
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
//叔叔节点为红色的处理方案
//把父节点设置为黑色
setColor(parentOf(x), BLACK);
//把叔叔节点设置为黑色
setColor(y, BLACK);
//把爷爷节点设置为红色
setColor(parentOf(parentOf(x)), RED);
//把爷爷节点设置为当前节点
x = parentOf(parentOf(x));
} else {
//叔叔节点为黑色的处理方案
//表示判断当前节点是否为父节点的右子节点
if (x == rightOf(parentOf(x))) {
//表示当前节点是父节点的右子节点
x = parentOf(x);
//左旋
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
//表示当前节点的父节点是爷爷节点的右子节点
//那么下面就可以用leftOf获取到当前节点的叔叔节点
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
//把根节点设置为黑色
root.color = BLACK;
}
3.4面试小问题
6.课堂思考问题:
6.1TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
此时是不需要重写的。hashCode和equals方法与HashMap的键有关!
6.2HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。
既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?
不需要的。
因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的
6.3TreeMap和HashMap谁的效率更高?
如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高
但是这种情况出现的几率非常的少。
一般而言,还是HashMap的效率要更高。
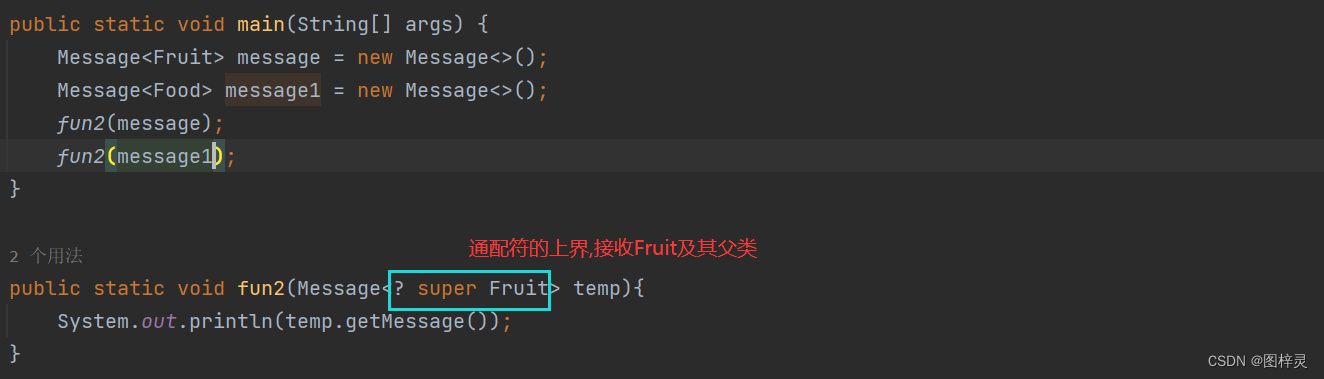
6.4你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?
此时putIfAbsent本身不重要。
传递一个思想:
代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。
那么该逻辑一定会有B面。
习惯:
boolean类型的变量控制,一般只有AB两面,因为boolean只有两个值
int类型的变量控制,一般至少有三面,因为int可以取多个值。
6.5三种双列集合,以后如何选择?
HashMap LinkedHashMap TreeMap
默认:HashMap(效率最高)
如果要保证存取有序:LinkedHashMap
如果要进行排序:TreeMap
六、可变参数

代码:
1、普通示例
public static class ArgsDemo1 {
public static void main(String[] args) {
/*
假如需要定义一个方法求和,该方法可以灵活的完成如下需求:
计算2个数据的和
计算3个数据的和
计算4个数据的和
计算n个数据的和
*/
System.out.println(getSum(10,20));
System.out.println(getSum(10,20,30));
System.out.println(getSum(10,20,30,40));
}
//计算2个数据的和
public static int getSum(int a, int b) {
return a + b;
}
//计算3个数据的和
public static int getSum(int a, int b, int c) {
return a + b + c;
}
//计算4个数据的和
public static int getSum(int a, int b, int c, int d) {
return a + b + c + d;
}
}
}
2、数组使用示例
public class ArgsDemo2 {
public static void main(String[] args) {
//计算n个数据的和
int[] arr = {1,2,3,4,5,6,7,8,9,10};
int sum = getSum(arr);
System.out.println(sum);
}
public static int getSum(int[] arr) {
int sum = 0;
for (int i : arr) {
sum = sum + i;
}
return sum;
}3、JDK5-可变参数
public class ArgsDemo3 {
public static void main(String[] args) {
//JDK5
//可变参数
//方法形参的个数是可以发生变化的,0 1 2 3 ...
//格式:属性类型...名字
//int...args
int sum = getSum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
System.out.println(sum);
}
//底层:
//可变参数底层就是一个数组
//只不过不需要我们自己创建了,Java会帮我们创建好
public static int getSum(int...args){
//System.out.println(args);//[I@119d7047
int sum = 0;
for (int i : args) {
sum = sum + i;
}
return sum;
}
}
4、可变参数小细节
public class ArgsDemo4 {
public static void main(String[] args) {
//可变参数的小细节:
//1.在方法的形参中最多只能写一个可变参数
//可变参数,理解为一个大胖子,有多少吃多少
//2.在方法的形参当中,如果出了可变参数以外,还有其他的形参,那么可变参数要写在最后
getSum(1,2,3,4,5,6,7,8,9,10);
}
public static int getSum( int a,int...args) {
return 0;
}
}5、小结

七、Collections

1、addAll() 批量添加元素
import java.util.ArrayList;
import java.util.Collections;
public class CollectionsDemo1 {
public static void main(String[] args) {
/*
public static <T> boolean addAll(Collection<T> c, T... elements) 批量添加元素
public static void shuffle(List<?> list) 打乱List集合元素的顺序
*/
//addAll 批量添加元素
//1.创建集合对象
ArrayList<String> list = new ArrayList<>();
//2.批量添加元素
Collections.addAll(list,"abc","bcd","qwer","df","asdf","zxcv","1234","qwer");
//3.打印集合
System.out.println(list);
}
}
2、shuffle() 打乱List集合元素的顺序
//shuffle 打乱
Collections.shuffle(list);
System.out.println(list);
3、其它方法
package com.yaqi.a07mycollections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class CollectionsDemo2 {
public static void main(String[] args) {
/*
public static <T> void sort(List<T> list) 排序
public static <T> void sort(List<T> list, Comparator<T> c) 根据指定的规则进行排序
public static <T> int binarySearch (List<T> list, T key) 以二分查找法查找元素
public static <T> void copy(List<T> dest, List<T> src) 拷贝集合中的元素
public static <T> int fill (List<T> list, T obj) 使用指定的元素填充集合
public static <T> void max/min(Collection<T> coll) 根据默认的自然排序获取最大/小值
public static <T> void swap(List<?> list, int i, int j) 交换集合中指定位置的元素
*/
System.out.println("-------------sort默认规则--------------------------");
//默认规则,需要重写Comparable接口compareTo方法。Integer已经实现,按照从小打大的顺序排列
//如果是自定义对象,需要自己指定规则
ArrayList<Integer> list1 = new ArrayList<>();
Collections.addAll(list1, 10, 1, 2, 4, 8, 5, 9, 6, 7, 3);
Collections.sort(list1);
System.out.println(list1);
System.out.println("-------------sort自己指定规则规则--------------------------");
Collections.sort(list1, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println(list1);
Collections.sort(list1, (o1, o2) -> o2 - o1);
System.out.println(list1);
System.out.println("-------------binarySearch--------------------------");
//需要元素有序
ArrayList<Integer> list2 = new ArrayList<>();
Collections.addAll(list2, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
System.out.println(Collections.binarySearch(list2, 9));
System.out.println(Collections.binarySearch(list2, 1));
System.out.println(Collections.binarySearch(list2, 20));
System.out.println("-------------copy--------------------------");
//把list3中的元素拷贝到list4中
//会覆盖原来的元素
//注意点:如果list3的长度 > list4的长度,方法会报错
ArrayList<Integer> list3 = new ArrayList<>();
ArrayList<Integer> list4 = new ArrayList<>();
Collections.addAll(list3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Collections.addAll(list4, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0);
Collections.copy(list4, list3);
System.out.println(list3);
System.out.println(list4);
System.out.println("-------------fill--------------------------");
//把集合中现有的所有数据,都修改为指定数据
ArrayList<Integer> list5 = new ArrayList<>();
Collections.addAll(list5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Collections.fill(list5, 100);
System.out.println(list5);
System.out.println("-------------max/min--------------------------");
//求最大值或者最小值
ArrayList<Integer> list6 = new ArrayList<>();
Collections.addAll(list6, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
System.out.println(Collections.max(list6));
System.out.println(Collections.min(list6));
System.out.println("-------------max/min指定规则--------------------------");
// String中默认是按照字母的abcdefg顺序进行排列的
// 现在我要求最长的字符串
// 默认的规则无法满足,可以自己指定规则
// 求指定规则的最大值或者最小值
ArrayList<String> list7 = new ArrayList<>();
Collections.addAll(list7, "a","aa","aaa","aaaa");
System.out.println(Collections.max(list7, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();
}
}));
System.out.println("-------------swap--------------------------");
ArrayList<Integer> list8 = new ArrayList<>();
Collections.addAll(list8, 1, 2, 3);
Collections.swap(list8,0,2);
System.out.println(list8);
}
}
八、综合练习
1、自动点名器
班级里有N个学生,学生属性:姓名,年龄,性别。
实现随机点名器。import java.util.ArrayList;
import java.util.Collections;
public class Test1 {
public static void main(String[] args) {
/* 班级里有N个学生,学生属性:姓名,年龄,性别。
实现随机点名器。*/
//1.定义集合
ArrayList<String> list = new ArrayList<>();
//2.添加数据
Collections.addAll(list,"范闲","范建","范统","杜子腾","杜琦燕","宋合泛","侯笼藤","朱益群","朱穆朗玛峰","袁明媛");
//3.随机点名
/* Random r = new Random();
int index = r.nextInt(list.size());
String name = list.get(index);
System.out.println(name);*/
//打乱
Collections.shuffle(list);
String name = list.get(0);
System.out.println(name);
}
}
2、自动点名器2(概率——随机面)

import java.util.ArrayList;
import java.util.Collections;
import java.util.Random;
public class Test2 {
public static void main(String[] args) {
/* 班级里有N个学生
要求:
70%的概率随机到男生
30%的概率随机到女生
"范闲","范建","范统","杜子腾","宋合泛","侯笼藤","朱益群","朱穆朗玛峰",
"杜琦燕","袁明媛","李猜","田蜜蜜",
*/
//1.创建集合
ArrayList<Integer> list = new ArrayList<>();
//2.添加数据
Collections.addAll(list,1,1,1,1,1,1,1);
Collections.addAll(list,0,0,0);
//3.打乱集合中的数据
Collections.shuffle(list);
//4.从list集合中随机抽取0或者1
Random r = new Random();
int index = r.nextInt(list.size());
int number = list.get(index);
System.out.println(number);
//5.创建两个集合分别存储男生和女生的名字
ArrayList<String> boyList = new ArrayList<>();
ArrayList<String> girlList = new ArrayList<>();
Collections.addAll(boyList,"范闲","范建","范统","杜子腾","宋合泛","侯笼藤","朱益群","朱穆朗玛峰");
Collections.addAll(girlList,"杜琦燕","袁明媛","李猜","田蜜蜜");
//6.判断此时是从boyList里面抽取还是从girlList里面抽取
if(number == 1){
//boyList
int boyIndex = r.nextInt(boyList.size());
String name = boyList.get(boyIndex);
System.out.println(name);
}else{
//girlList
int girlIndex = r.nextInt(girlList.size());
String name = girlList.get(girlIndex);
System.out.println(name);
}
}
}
3、自动点名器3(不会重复且会循环点名——辅助列表)

package com.yaqi.a08test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Random;
public class Test3 {
public static void main(String[] args) {
/* 班级里有5个学生
要求:
被点到的学生不会再被点到。
但是如果班级中所有的学生都点完了,需要重新开启第二轮点名。*/
//1.定义集合
ArrayList<String> list1 = new ArrayList<>();
//2.添加数据
Collections.addAll(list1, "范闲", "范建", "范统", "杜子腾", "杜琦燕", "宋合泛", "侯笼藤", "朱益群", "朱穆朗玛峰", "袁明媛");
//创建一个临时的集合,用来存已经被点到学生的名字
ArrayList<String> list2 = new ArrayList<>();
//外循环:表示轮数
for (int i = 1; i <= 10; i++) {
System.out.println("=========第" + i + "轮点名开始了======================");
//3.获取集合的长度
int count = list1.size();
//4.随机点名
Random r = new Random();
//内循环:每一轮中随机循环抽取的过程
for (int j = 0; j < count; j++) {
int index = r.nextInt(list1.size());
String name = list1.remove(index);
list2.add(name);
System.out.println(name);
}
//此时表示一轮点名结束
//list1 空了 list2 10个学生的名字
list1.addAll(list2);
list2.clear();
}
}
}
4、自动点名器4(权重)
微服务技术
2、Map集合案例——省和市
需求
定义一个Map集合,键用表示省份名称province,值表示市city,但是市会有多个。
添加完毕后,遍历结果格式如下:
江苏省 = 南京市,扬州市,苏州市,无锡市,常州市
湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市
河北省 = 石家庄市,唐山市,邢台市,保定市,张家口市import java.util.*;
public class Test4 {
public static void main(String[] args) {
/* 需求
定义一个Map集合,键用表示省份名称province,值表示市city,但是市会有多个。
添加完毕后,遍历结果格式如下:
江苏省 = 南京市,扬州市,苏州市,无锡市,常州市
湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市
河北省 = 石家庄市,唐山市,邢台市,保定市,张家口市*/
//1.创建Map集合
HashMap<String, ArrayList<String>> hm = new HashMap<>();
//2.创建单列集合存储市
ArrayList<String> city1 = new ArrayList<>();
city1.add("南京市");
city1.add("扬州市");
city1.add("苏州市");
city1.add("无锡市");
city1.add("常州市");
ArrayList<String> city2 = new ArrayList<>();
city2.add("武汉市");
city2.add("孝感市");
city2.add("十堰市");
city2.add("宜昌市");
city2.add("鄂州市");
ArrayList<String> city3 = new ArrayList<>();
city3.add("石家庄市");
city3.add("唐山市");
city3.add("邢台市");
city3.add("保定市");
city3.add("张家口市");
//3.把省份和多个市添加到map集合
hm.put("江苏省",city1);
hm.put("湖北省",city2);
hm.put("河北省",city3);
Set<Map.Entry<String, ArrayList<String>>> entries = hm.entrySet();
for (Map.Entry<String, ArrayList<String>> entry : entries) {
//entry依次表示每一个键值对对象
String key = entry.getKey();
ArrayList<String> value = entry.getValue();
StringJoiner sj = new StringJoiner(", ","","");
for (String city : value) {
sj.add(city);
}
System.out.println(key + " = " + sj);
}
}
}