1.Redis学习资料
虽然前面已经学习了 Redis 理论和技术点,但是如果想要持续提升自己的技术能力,还是需要不断丰富自己的知识体系。本章,给你推荐几本优秀的书籍,以及拓展知识面的其他资料。
1.1 经典书籍
在学习 Redis 时,场景的需求有三个方面:
- 日常使用操作:比如常见的命令和配置,集群搭建等
- 关键技术原理:比如 IO 模型、AOF 和 RDB 机制等
- 在实际使用时的经验教训,比如 Redis 响应变慢了怎么办?Redis 主从数据库不一致怎么办? 等等。
1.2 工具书《Redis 使用手册》
一本好的工具书可以帮助我们快速了解或查询 Redis 日常的使用命令和操作方法。《Redis 使用手册》是一本非常好用的工具书。
本书中,作者将 Redis 内容分成了三大部分,分别是“数据结构与应用”、“附加功能” 和“多功能机制”。其中,最有用的就是“数据结构与应用”的内容,因为它提供了丰富的操作命令介绍,不仅涵盖了 Redis 的 5 大数据类型的主要操作命令,还介绍了 4 种扩展数据类型的命令操作,包括 位图、地址坐标、HyperLogLog 和流。
不过,想要了解最新、最全的 Redis 命令操作,建议去官网查阅。考虑到有些读者想看中文版,在提供一个翻译版的命令参考。
《Redis 使用手册》还提供了“附加功能”部分,介绍了 Redis 数据库的管理操作和过期 key 的操作,这对我们进行 Redis 数据库运维(例如迁移数据、清空数据库、淘汰数据库等)提供了操作上的指导。
1.3 原理书:《Redis 设计与实现》
虽然《Redis 设计与实现》和《Redis 使用手册》是同一个作者写的,但是它们的侧重点不同,这本书更加关注 Redis 关键机制的实现原理。
介绍 Redis 原理的书籍很多,但是这本书讲解的非常透彻,尤其是在 Redis 底层数据结构、RDB 和 AOF 持久化机制,以及哨兵机制和切片集群的介绍上,非常容易理解,建议你可以重点学习下这部分内容。
除了文字的讲解,概述还针对一些难点问题,例如数据结构的组成、哨兵实例间的交互过程、切片集群实例的交互过程等,都使用了非常清晰的插图来表示,可以最大程度地降低学习难度。
虽然这本书的出版日期比较早(针对 Redis 3.0),但里面讲的很多原理现在依然是适用的,它可以在帮助你从入门 Redis 到精通的道路上,迈进一大步。
1.4 实战书:《Redis 开发与运维》
在实战方面,《Redis 开发与运维》是一本不错的参考书。
首先,它介绍了 Redis 的 Java 和 Python 客户端,以及 Redis 用于缓冲设计的关键技术和注意事项,这些内容在其他的书籍中不太常见,可以重点学习下。
其实,它围绕客户端、持久化、主从复制、哨兵、切片集群等几方面,着重介绍了在日常的开发运维过程中遇到的“坑”,都是经验之谈,可以帮助你提前做规避。
另外,这本书还针对 Redis 阻塞、优化内存使用、处理 bigkey 这几个经典问题,提供了解决方案,非常值得一读。你可以把目录的问题做成 QA 列表,这样,在遇到问题的时候,就可以对照这个列表,快速找出原因,并利用书中的方案去解决问题。
当然,想真正提升能力,光读书是不够的,有两条建议:
- 第一条是阅读源码。读源码其实也是一种实战锻炼,可以帮助你从代码逻辑中彻底理解 Redis 的实际运行机制,当遇到问题时,可以直接从代码层面进行定位、分析和解决问题。阅读 Redis 的源码在 GitHub 上。另外,还有一个增加了中文注释的代码库 (基于Redis 3.0 源码)。
此外,还要动手进行实践。Redis 就是一个进程,我们可以直接使用自己的电脑进行部署。只要不是性能测试,在功能测试或场景模拟上,自己电脑的环境一般都是可以胜任的。比如说,要想部署主从集群或者切片集群,模拟主库故障,完全可以在自己的电脑上起多个 Redis 实例来完成,只要它们的端口号不同就可以了。
1.5 扩展阅读方向
Redis 的很多关键功能,其实和操作系统底层的实现机制是相关的,比如说:非阻塞的网络框架、RDB 生成和 AOF 重写时设计到的 fork 和写实复制机制,等等。另外,Redis 主从集群中的哨兵机制,以及切片集群的数据分布还涉及到一些分布式系统的内容。
所以,如果你希望自己的实战能力更强,建议你读一读操作系统和分布式系统方面的经典教材,比如《操作系统导论》。这本书里对进程、线程的定义,对进程 API 、线程 API 以及对文件系统 fsync 操作、缓存和缓冲的介绍,都是和 Redis 直接相关的;再比如《大规模分布式存储系统:原理解析与架构实战》中的分布式系统章节,可以让你掌握 Redis 主从集群、切片集群涉及到的设计规范。了解了操作系统和分布式系统的基础知识,技能帮你理清容易混淆的概念,也可以帮你将一些通用的设计方法(如一致性哈希)应用到日常实践中,做到融会贯通,举一反三。
2. Redis 好用的运维工具
2.1 最基本的监控命令:INFO 命令
Redis 本身提供的 INFO 命令会返回丰富的实例运行监控信息,这个命令是 Redis 监控工具的基础。
INFO 命令在使用的时候,可以带一个 section ,这个参数的取值有好几种,相应的,INFO 命令也会返回不同类型的监控信息。我们把 INFO 命令的返回信息分成 5 大类,其中,有的类别当中有包含了不同的监控信息,如下表所示:
| 类别 | 子类别 | 对应INFO命令的section参数 |
|---|---|---|
| 实例本身配置信息 | 无 | server |
| 运行状态统计 | 客户端统计 | client |
| 运行状态统计 | 通用统计信息 | stats |
| 运行状态统计 | 数据库整体统计信息 | keyspace |
| 运行状态统计 | 不同类型命令的调用统计信息 | commandstats |
| 资源使用统计信息 | cpu使用情况 | cpu |
| 资源使用统计信息 | 内存使用情况 | memory |
| 关键功能运行状态 | RDB、AOF运行情况 | persistence |
| 关键功能运行状态 | 主从复制的运行情况 | replication |
| 关键功能运行状态 | 切片集群的运行情况 | cluster |
| 扩展模块信息 | 无 | modules |
在监控 Redis 运行状态是,INFO 命令返回的结果非常有用。如果你想了解 INFO 命令的所有参数返回的含义,可以查看 Redis 官网的介绍。这里给你几个运维时,需要重点关注的参数,及它们的重要返回结果。
首先,无论你运行的是单实例或集群,建议你重点关注一下 stats、commandstats 、cpu 和 memory 这四个参数的返回结果,这里包含了命令的执行情况(如命令的执行次数、执行时间、命令使用的 CPU 资源),内存的使用情况(比如内存的已使用量、内存的碎片率),CPU 资源使用情况等,这可以帮助我们判断实例的运行状态和资源消耗情况。
另外,当你启用 RDB 或 AOF 功能时,你要重点关注下 persistence 参数的返回结果,通过它可以看到 RDB 或 AOF 的执行情况。
如果你在使用主从集群,要重点关注下 replication 参数的返回结果,这里面包含了主从同步的实时状态。
不过 info 命令只提供了文本形式的监控结果,并没有可视化,可以使用一些第三方开源工具,将 INFO 命令返回的结果可视化。
2.2 面向 Prometheus 的 Redis-exporter 监控
Prometheus 是一套开源的系统监控报警框架。它的核心功能是从被监控的系统中拉取监控数据,结合 Grafana 工具,进行可视化展示。而且,监控数据可以保存到时序数据库中,以便运维人员进行历史查询。同时,Prometheus 会检测系统的监控指标是否超过了预设的阈值,一旦超过,Prometheus 就会出发报警。
对于系统的日常运维来说,这些功能是非常重要的。而 Prometheus 已经实现了使用这些功能的工具框架。我们只要能从被监控系统中获取到监控数据,就可以用 Prometheus 来实现运维监控。
Prometheus 正好提供了插件功能拉实现对一个系统法监控,我们把插件称为 exporter ,每一个 exporter 实际是一个采集监控数据的组件。exporter 采集的数据格式符合 Prometheus 的要求,Prometheus 获取到这些数据后,就可以进行展示和保持了。
Redis-exporter 就是用来监控 Redis 的,它将 INFO 命令监控到的运行状态各种统计信息提供给 Prometheus ,从而进行可视化展示和报警设置。目前,Redis-exporter 可以支持 Redis 2.0 至 6.0。
除了获取 Redis 实例的运行状态,Redis-exporter 还可以监控键值对的大小和集合数据类型数据的元素个数,这个可以在运行 Redis-exporter 时,使用 check-keys 命令选项来实现。
此外,可以开发一个 Lua 脚本,定制化采集所需的监控数据。然后,我们使用 Scrpits 命令选项,让 Redis-exporter 运行这个特定的脚本,从而可以满足业务层的多样化监控需求。
最后,在分享两个小工具:redis-stat 和 redis live。跟 Redis-exporter 相比,这两个都是轻量级的监控工具。它们分别用 Ruby 和 Python 开发,也是将 INFO 命令提供的实例运行状态信息可视化展示。虽然这两个工具更新很少,不过,如果你想自行开发 Redis 监控工具,它们都是不错的参考。
2.3 数据迁移工具 Redis-shake
有时,我们在将不同的实例间迁移数据。目前,常用的数据迁移工具是 Redis-shake。
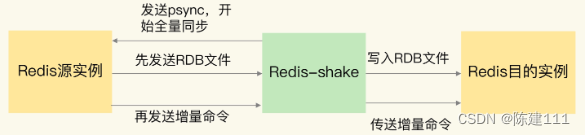
Redis-shake 的基本运行原理,是先启动 Redis-shake 进程,这个进程模拟了一个 Redis 实例,然后,Redis-shake 进程和数据迁出的源实例进行数据的全量同步。这个过程和 Redis 主从实例的全量同步是类似的。
源实例相当于主库,Redis-shake 相当于从库,源实例先把 RDB 文件传输给 Redis-shake,Redis-shake 会把 RDB 文件发送给目的实例。接着,源实例会再把增量命令发送给 Redis-shake,Redis-shake 负责把这些增量命令再同步给目的实例。
Redis-shake 的一大优势,就是支持多种类型的迁移。
首先,它既支持单个实例间的数据迁移,也支持集群到集群的数据迁移。
其次,有的 Redis 切片集群(如 Codis)使用 Proxy 接受请求操作,Redis-shake 也同样支持和 proxy 进行数据迁移。
另外,因为 Redis-shake 是阿里云团队开发的,所以除了支持开源的 Redis 版本以外,Redis-shake 还支持云下的 Redis 和云上的 Redis 实例进行迁移,可以帮助我们实现 Redis 服务上云的目标。
在数据迁移后,我们通常需要对比源实例和目的实例中的数据是否一致。如果有不一致的数据,我们需要把它们找出来,从目的实例中提出,或者是再次迁移这些不一致的数据。
这里要介绍一个数据一致性比对的工具了,Redis-full-check。
Redis-full-check 的工作原理很简单,就是对源实例和目的实例中的数据进行权利对比,从而完成数据校验。不过,为了降低数据校验的对比开销,Redis-full-check 采用了多轮比较的方法。
在第一轮校验时,Redis-full-check 会找出在源实例上的所有key,然后从源实例和目的实例中把响应的值也都查出来,进行比对。在第一次比对后,Redis-full-check 会把目的实例中和源实例中不一致的数据,记录到 sqlite 数据库中。
从第二轮校验开始,Redis-full-check 只会比较上一轮结束后记录在数据库中不一致的数据。
为了避免对实例的正常请求处理造成影响,Redis-full-check 在每一轮对比结束后,会暂停一段时间。随着 Redis-shake 增量同步的进行,源实例和目的实例中的不一致数据也会逐步减少,所以,我们的校验独臂的轮数不用很多。
等所有轮数据都比对完成后,数据库中记录的数据就是源实例和目的实例最终的差异结果。
这里有个地方需要注意下,Redis-full-check 提供了三种对比模式,我们可以通过 comparemode 参数进行设置:
- keyOutline:只比对 key 值是否相等。
- valueOutline:值对比 value 值的长度是否相等
- FullValue:对比 key 值、value 长度、value 值是否相等。
2.4 集群管理工具 CacheCloud
CacheCloud 是面向 Redis 运维管理的云平台,它实现了主从集群、哨兵集群和 Redis Cluster 的自动部署和管理,用户可以直接在平台的管理界面上进行操作。
针对常见的集群运维需求,CacheCloud 提供了 5 个运维操作:
- 下线实例:关闭实例及实例相关的监控任务。
- 上线实例:重新启动已经下线的实例,并进行监控。
- 添加从节点:在主从集群中给主节点添加一个从节点。
- 故障切换:手动完成 Redis Cluster 主从节点的故障转移。
- 配置管理:用户提交配置修改的工单后,管理员进行审核,并完成配置修改。
当然,作为运维管理平台,CacheCloud 除了提供运行操作外,还提供了丰富的监控信息。
CacheCloud 不仅会收集 INFO 命令提供的实例实时运行状态信息,进行可视化展示,而且还会把实例运行状态信息保存下来,例如内存使用情况、客户端连接数、键值对数据量。这些一来,当 Redis 运行发生问题时,运维人员可以查询保存的历史记录,并结合当时的运行状态信息进行分析。
如果你希望有一个统一平台,把 Redis 实例管理相关的任务集中托管起来,CacheCloud 是一个不错的工具。
3. Redis的使用规范小建议
3.1 键值对使用规范
关于键值对的使用规范,主要有两方面:
- key 的命名规范,只有命名规范,才能提供可读性强、可维护性好的 key,方便日常管理。
- value 的设计规范,包括避免 bigkey、选择高效率序列化方法和压缩方法、使用证书对象、共享池、数据类型选择。
规范一:key 的命名规范
一个 Redis 实例默认可以支持 16 个数据库,我们可以把不同的业务数据分散保存到不同的数据中。但是客户端在使用不同数据库时,需要使用 SELECT 命令进行数据库切换,相当于增加了一次额外的操作。
我们可以通过合理命名 key,减少这个操作。具体的做法是,把业务名作为前缀,然后用冒号分割,再加上具体的业务数据名。这样一来,我们可以通过 key 的前缀区分不同的业务数据,就不用在多个数据库间来回切换了。
比如说,如果我们要统计网页的独立访客量,就可以用下面的代码设置 key,这就表示,这个数据对应的业务 unique (独立访客量),而且对应的页面编号是 1024。
uv:page:1024
这里有个地方需要注意下。key 本身是字符串,底层的数据结构是 SDS。SDS 结构中会包括字符串长度、分配空间大小等元数据信息。从 Redis 3.2 版本开始,当 key 字符串的长度增加时,SDS 中的元数据也会占用更多内存空间。
所以,我们在设置 key 的名称时,要注意控制 key 的长度。否则,如果 key 很长的话,就会消耗较多内存空间,而且,SDS 元数据也会额外消耗一定的内存空间。
SDS 结构中的字符串长度和元数据大小的对应关系:
| 字符串大小(字节) | SDS结构元数据大小(字节) |
|---|---|
1 ~ 2^5 - 1 | 1 |
2^5 ~ 2^8 -1 | 3 |
2^8 ~ 2^16 -1 | 5 |
2^16 ~ 2^32 -1 | 9 |
2^32 ~ 2^64 -1 | 17 |
为了减少 key 占用的内存空间,给你一个小建议:对于业务或数据名,可以使用相应的英文单词的首字母表示,(比如 user 用 u 表示,message 用 m),或者是用缩写表示(例如 unique 是石头人使用 uv)。
规范二:避免使用 bigkey
Redis 是使用单线程读写数据,bigkey 的读写操作会阻塞,降低 Reids 的处理效率。所以,在应用 Redis 时,关于 value 的设计规范,非常重要的一点就是避免 bigkey。
bigkey 通常由两种情况。
- 情况一: 键值对的值大小本身就很大,例如 value 为 1MB 的 String 类型数据。为了避免 String 类型的 bigkey,在业务层,我们要尽量把 String 类型的数据大小控制在 10 KB 以下。
- 情况二:键值对的值是集合类型,集合元素个数非常多,例如包含 100 万个元素的 Hash 集合类型数据。为了避免集合类型的 bigkey,我给你的设计规范建议是,尽量把集合类型的元素个数控制在 1 万以下。
当然,这些建议知识为了尽量避免 bigkey,如果业务层的 String 类型数据确实很大,我们还可以通过数据压缩来减少数据大小;如果集合类型的元素的确很多,我们可以将一个大集合拆分成多个小集合来保存。
Redis 的 4 种集合类型 List、Hash、Set 和 Sorted Set,在集合元素个数小于一定的阈值时,会使用内存紧凑型的底层数据结构进行保存,从而节省内存。例如,假设 Hash 集合的 hash-max-ziplist-entries 配置项是 1000,如果 Haash 集合元素不超过 1000 个,就会使用 ziplist。
紧凑型数据结构虽然可以节省内存,但是会在一定程度上导致数据的读写性能下降。所以,如果业务应用更加需要保持高性能访问,而不是节省内存的话,在不会导致 bigkey 的前提下,就不用刻意控制集合元素个数了。
规范三:使用高效序列化方法和压缩方法
为了节省内存,除了采用紧凑型数据结构外,还可以使用高效的序列化方法和压缩方法,来减少 value 的大小。
Redis 中的字符串都是使用二进制安全的字节数组来保存的,所以,我们可以把业务数据序列化成二进制数据写入 Redis 中。
但是,不同的序列化方法,在序列化速度和数据序列化后的占用内存空间这两个方面,效果是不一样的。比如,protostuff 和 kryo 这两种序列化方法,就要比 Java 内置的序列化方法(java-build-in-serializer)效率更高。
此外,业务应用优势会使用字符串形式的 XML 和 JSON 格式保存数据。这样做的好处是,可读性好,便于调试,不同的开发语言都支持这两种格式的解析。
缺点在于, XML 和 JSON 格式的数据占用的内存空间大。为了避免数据占用过大的内存空间,我建议使用压缩工具(例如 snappy 或 gzip),把数据压缩后再写入 Redis。
规范四:使用证书对象共享池
证书是常用的数据类型,Redis 内部维护了 0 到 9999 这 1 万个整数对象,并把这些整数作为一个共享池使用。换句话说,如果一个键值对中有 0 到 9999 范围的整数,Redis 就不会专门为这个键值对专门创建整数对象了,而是会复用共享池中的整数对象。 这样一来,可以节省内存空间。
基于这个特点,我建议你,在满足业务数据需求的前提下,能用整数时就尽量使用整数。
不能使用整数对象共享池的情况:
- 第一种情况是,如果 Redis 中设置了 maxmemory ,而且启动了 LRU 策略(allkeys-lru 或 volatile-lru 策略),那么整数对象共享池就无法使用了。这是因为,LRU 策略需要统计每个键值对的使用时间,如果不同的键值对都共享一个整数对象,LRU 策略就无法进行统计了。
- 第二种情况,如果集合类型数据采用 ziplist 编码,而集合元素是整数,这个时候,也不能使用共享池。因为 ziplist 是紧凑内存结构,判断整数对象的共享情况效率低。
3.2 数据保存规范
规范一:使用 Redis 保存热数据
一般来说,在实际应用 Redis 时,我们会更多地把它作为缓存保存热数据,这样既可以利用 Redis 的高性能特性,还可以把宝贵的内存资源用在服务热数据上。
规范二:不同业务数据库分实例存储
虽然,我们可以使用 key 的前缀把不同业务的数据区分开,但是,如果所有业务的数据量都很大,而且访问特性也不一样,这些操作就会相互干扰。
假如数据采集业务使用 Redis 保存数据时,以写操作为主,而用户统计业务使用 Redis 时,是以读为主,如果这两个业务数据混合在一起保存,读写操作相互干扰,肯定会导致业务响应变慢。
我建议把不同的业务数据放到不同的 Redis 实例中。这样,既可以避免单实例的内存使用量过大,也避免不同业务的操作相互干扰。
规范三:在数据保存时,要设置过期时间
Redis 的内存资源非常宝贵,Redis 通常是用来保存热数据的,而热数据一般都有使用的时效性。
所以,在保存数据时,建议你根据业务使用数据的时长,设置数据的过期时间。不然的话,这些数据会一直占用内存,如果数据持续增多,就可能达到机器的内存上线,造成内存溢出。
规范四:控制 Redis 实例的容量
Redis 单实例的内存大小都不要太大,建议你设置在 2~6GB。这样一来,无论是 RDB 快照,还是主从集群进行数据同步,都能很快完成,不会阻塞正常请求的处理。
3.3 命令使用规范
规范一:线上禁用部分命令
Redis 是单线程处理请求操作,所以一些涉及大量操作、耗时长的命令,会验证阻塞主线程,导致其他请求无法得到正常处理,这类命令主要有 3 种:
- KEYS,按照键值对的 key 内容进行匹配,返回符合匹配条件的键值对,该命令需要对全局哈希表进行全表扫描,严重阻塞 Redis 主线程。
- FLUSHALL,删除 Redis 实例上的所有数据,如果数据量很大,会严重阻塞 Redis 主线程。
- FLUSHDB,删除当前数据库中的数据,如果数据量很大,同样会阻塞 Redis 主线程。
具体做法是,管理员用 rename-command 命令在配置文件中对这些命令进行重命名,让客户端 无法使用这些命令。
当然,你还可以使用其他命令代替这三个命令:
- 对 KEYS 来说,可以使用 SCAN 代替 KEYS 命令,分批返回符合条件的键值对,避免造成主线程阻塞。
- 对于 FLUSHALL、FLUSHDB,可以加上 ASYNC 选项,让这两个命令使用后台线程异步删除数据,避免造成主线程阻塞。
规范二:慎用 MONITOR 命令
Redis 的 MONITOR 命令在执行后,会持续输出检测到的各个命令操作。我们通常会用 MONITOR 命令返回的结果,检测命令的执行情况。
但是,MONITOR 会把监控到的内容持续写入输出缓冲区,如果线上命令的操作很多,输出缓冲区很快就会溢出了,这就会对 Redis 性能造成影响,甚至引起服务崩溃。
除非十分需要监测某些命令(如,Redis 性能突然变慢,我们想看下客户端执行了哪些命令),可以偶尔在短时间内使用下 MONITOR。
规范三:慎用全量操作命令
对于集合类型的数据来说,一般不加你使用权利操作的命令(如 Hash 类型的 HGETALL、Set 类型的 SMEMBERS)。这些操作会对 Hash 和 Set 类型的底层结构进行全量扫描,如果集合类型数据较多的话,就会阻塞主线程。
如果想要获得集合类型的全量数据,我给你三个小建议。
- 第一个建议是,使用 SSCAN、HSCAN 命令分批次返回集合中的数据,减少主线程的阻塞。
- 第二个建议是,你可以化整为零,把一个大的 Hash 集合拆分成多个小的 Hash 集合。这个操作对应到业务层,就是对业务数据进行拆分,按照时间、地域、用户 ID 等属性把一个大集合的业务数据拆分成多个小集合数据。例如,当你统计用户的访问情况时,就可以按照天的粒度,把每天的数据作为一个 Hash 集合。
- 最后一个建议是,如果集合类型保存的是业务数据的多个属性,而每次查询时,也需要返回这些属性,那么,你可以使用 String 类型,将这些属性序列化后保存,每次直接返回 String 数据就行,不用在对集合类型做全量扫描了。
Redis的使用规范小结
| 规范类别 | 规范内容 |
|---|---|
| 强制 | 禁用 KEYS、FLUSHALL、FLUSHDB |
| 推荐 | 事业业务名做key的前缀,并使用缩写形式 |
| 推荐 | 控制key的长度 |
| 推荐 | 使用高效序列化方法和压缩方法 |
| 推荐 | 使用整数对象共享池 |
| 推荐 | 不同业务数据保存到不同的实例 |
| 推荐 | 数据保存时设置过期时间 |
| 推荐 | 慎用 MONITOR 命令 |
| 推荐 | 慎用全量操作命令 |
| 建议 | 控制String类型数据的大小不超过 10KB |
| 建议 | 控制集合类型的元素个数不超过1万个 |
| 建议 | 使用 Redis 保存热数据 |
| 建议 | 把Redis实例的容量控制在2~6GB |
- 强制类的规范:如果不按照规范内容来执行,就会给 Redis 的应用带来极大的负面影响,例如性能受损。
- 推荐类的规范:这个规范的内容能有效提升性能、节省内存空间,或是增加开发和运维的便捷性,你可以直接应用到实践中。
- 建议类的规范:这类规范内容和实际业务应用相关,只是从经验给你一个建议,你需要结合自己的业务场景参考使用。