题目列表
3028. 边界上的蚂蚁
3029. 将单词恢复初始状态所需的最短时间 I
3030. 找出网格的区域平均强度
3031. 将单词恢复初始状态所需的最短时间 II
一、边界上的蚂蚁

这题没什么好说的,模拟就行,本质就是看前缀和有几个为0。
代码如下
class Solution {
public:
int returnToBoundaryCount(vector<int>& nums) {
int ans = 0, sum = 0;
for(auto x:nums){
sum += x;
ans += sum==0;
}
return ans;
}
};二、将单词恢复初始状态所需要的最短时间I&II


这题如果没有什么其他思路,我们直接暴力枚举也是可以直接过的(数据范围比较小),这里先写一个暴力的代码,下面会讲一个更快的方法
这题的本质其实就是判断特定长度的前后缀是否相同,这里我们直接暴力枚举一个个字符进行判断
代码如下
class Solution {
public:
int minimumTimeToInitialState(string word, int k) {
int n = word.size(), ans = 1;
for(int i = k; i < n; i += k){
bool flag = false;
for(int j = 0;j < n - i; j++){
if(word[j] != word[i+j]){
flag = true;
break;
}
}
if(flag) ans++;
else break;
}
return ans;
}
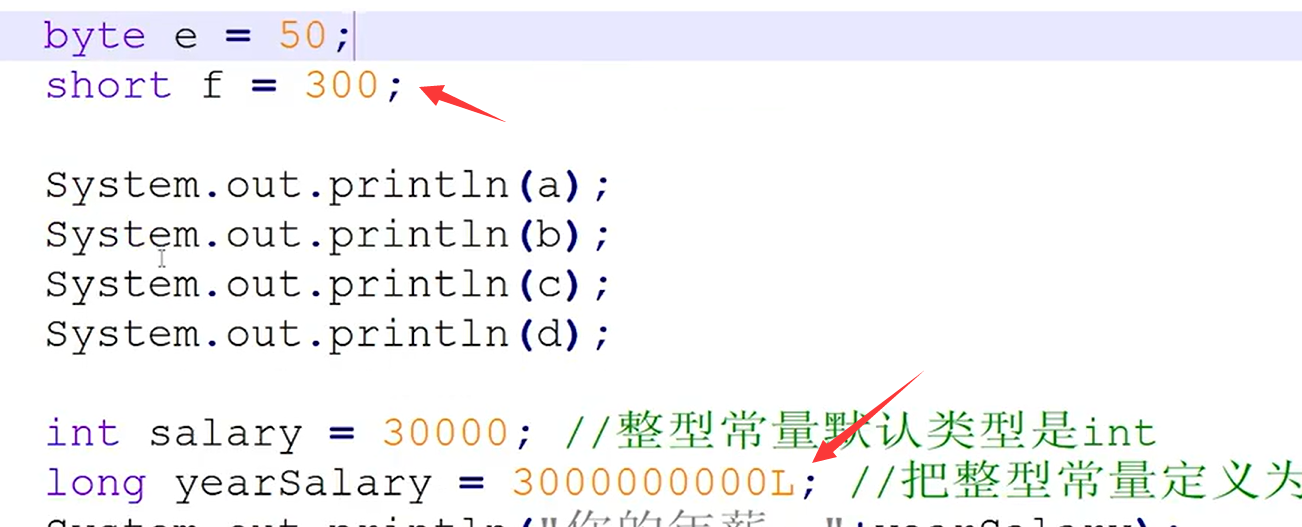
};那么如果数据范围变大(如下图),我们又该如何去做呢???(第四题)

很显然,这题是关于字符串匹配的相关问题,很容易就能想到KMP算法,但是KMP的常规用法是用来求模式串在其他文本串中是否存在及其所匹配的子串的起始下标的,而这题只有一个字符串,且所求也不同,看着根本就没有任何关系,但是真的是这样吗?
(如果对KMP算法不了解,建议先去看一下这一篇文章:如何更好地理解和掌握 KMP 算法? - 知乎)
我们来想想kmp中有什么是只跟一个字符串有关系的?很显然是next数组,那么next数组的含义是什么?next[i] 表示以 i 为结尾的字符串的前缀和后缀的最大匹配字符串的长度。
比如 ababcabab的next数组为 0 0 1 2 1 1 2 3 4
在之前我就说过这题本质其实就是判断特定长度的前后缀是否相同,在结合next数组的含义,是不是已经有点感觉了?
但是还不够,根据目前的对next数组的理解,我们只能得到该字符串的前后缀最长匹配字符串的长度,但是这个不一定满足题目要求,所以我们需要枚举从大到小所有满足字符串前后缀匹配的长度,从而找到最小的操作次数,如何做?
如果我们想要得到次大的满足字符串前后缀匹配字符串的长度,该长度的字符串必然包含在最大长度的前后缀匹配的字符串中,举个例子,比如 ababcabab 这个字符串,next.back()=4,即 abab 这个字符串,那么次大的满足前后缀匹配的字符串必然在 abab 之中,即 ab,也就是 abab 这个字符串的最大前后缀匹配的字符串长度,所以次大的前后缀匹配字符长度为2,同理,我们能得到从大到小所有满足字符串前后缀匹配字符串的长度
代码如下
class Solution {
public:
int minimumTimeToInitialState(string word, int k) {
//kmp求next数组
int n = word.size();
int next[n];next[0]=0;
for(int i=1,j=0;i<n;i++){
while(j&&word[i]!=word[j])
j=next[j-1];
if(word[i]==word[j])
j++;
next[i]=j;
}
//从大到小枚举所有的前后缀匹配的字符串长度
int res=next[n-1];
while(res&&(n-res)%k!=0)
res = next[res-1];
if(res) return (n-res)/k;
else return (n+k-1)/k;
}
};这里介绍另一种算法----z函数(又叫扩展kmp)----是之前暴力做法的优化
之前暴力做法浪费时间的地方在于每次判断前后缀是否匹配,都需要从头开始,但实际上前面匹配的信息能帮助我们跳过一些没有必要的比较
它的大体思路和kmp的思路是一样的,都是用空间去换取时间,用额外的空间去记录一些有用的信息,从而减少无用比较的次数,优化时间复杂度,有兴趣的可以去了解一下。
代码如下
class Solution {
public:
int minimumTimeToInitialState(string word, int k) {
int n = word.size();
vector<int> z(n);
int left = 0, right = 0;
for(int i = 1; i < n; i++){
if(i <= right)
z[i] = min(z[i-left], right-i+1);
while(i+z[i] < n && word[z[i]]==word[i+z[i]]){
left = i;
right = z[i]+i;
z[i]++;
}
if(i%k==0&&z[i]==n-i)
return i/k;
}
return (n+k-1)/k;
}
};三、找出网格的区域平均强度

读懂题目意思,直接模拟即可
代码如下
class Solution {
public:
vector<vector<int>> resultGrid(vector<vector<int>>& image, int threshold) {
int n = image.size(), m = image[0].size();
vector<vector<int>> dp(n+1,vector<int>(m+1));
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
dp[i+1][j+1] = dp[i][j+1] + dp[i+1][j] + image[i][j] - dp[i][j];
}
}
vector<vector<int>> v(n,vector<int>(m));
auto t = v;
for(int i = 0; i < n-2; i++){
for(int j = 0; j < m-2; j++){
bool ok = false;
for(int k = i; k <= i+2; k++)
if(abs(image[k][j]-image[k][j+1])>threshold || abs(image[k][j+1]-image[k][j+2])>threshold)
ok = true;
for(int k = j; k <= j+2; k++)
if(abs(image[i][k]-image[i+1][k])>threshold || abs(image[i+1][k]-image[i+2][k])>threshold)
ok = true;
if(ok) continue;
int sum = (dp[i+3][j+3] - dp[i+3][j] - dp[i][j+3] + dp[i][j])/9;
for(int x = i; x <= i+2; x++){
for(int y = j; y <= j+2; y++){
t[x][y]++;
v[x][y]+=sum;
}
}
}
}
for(int i = 0; i < n; i++){
for(int j = 0; j < m; j++){
if(t[i][j]) v[i][j]/=t[i][j];
else v[i][j]=image[i][j];
}
}
return v;
}
};