目录
项目介绍
图像分类网络构建
处理花生豆图片完成预测
项目介绍
这是一个使用图像掩膜技术和深度学习技术实现的一个花生豆分拣系统
我们有大量的花生豆图片,并以及打好了标签,可以看一下目录结构和几张具体的图片



同时我们也有几张大的图片,里面有若干花生豆,我们要做的任务就是将花生豆框住并且实现分类,可以看一下这些图片 

图像分类网络构建
这部分的内容和我上一篇博客几乎大同小异,就是把最后的分类个数和类别映射换了换,掌握了上一个项目,这部分相信也会理解的很快,这里附上网址并做简单的回顾
kaggle实战图像分类-Intel Image Classification(附源码)-CSDN博客![]() https://blog.csdn.net/weixin_62428212/article/details/136059443?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_62428212/article/details/136059443?spm=1001.2014.3001.5501
1,数据集加载
2,构建网络
3,定义超参数训练网络
这里小编使用的是resnet18这个网络,因为花生豆数据集的训练,一不小心就会过拟合,用一些更深更强的网络很容易导致过拟合,resnet18好像也有点过拟合,这里附上训练结果图片

处理花生豆图片完成预测
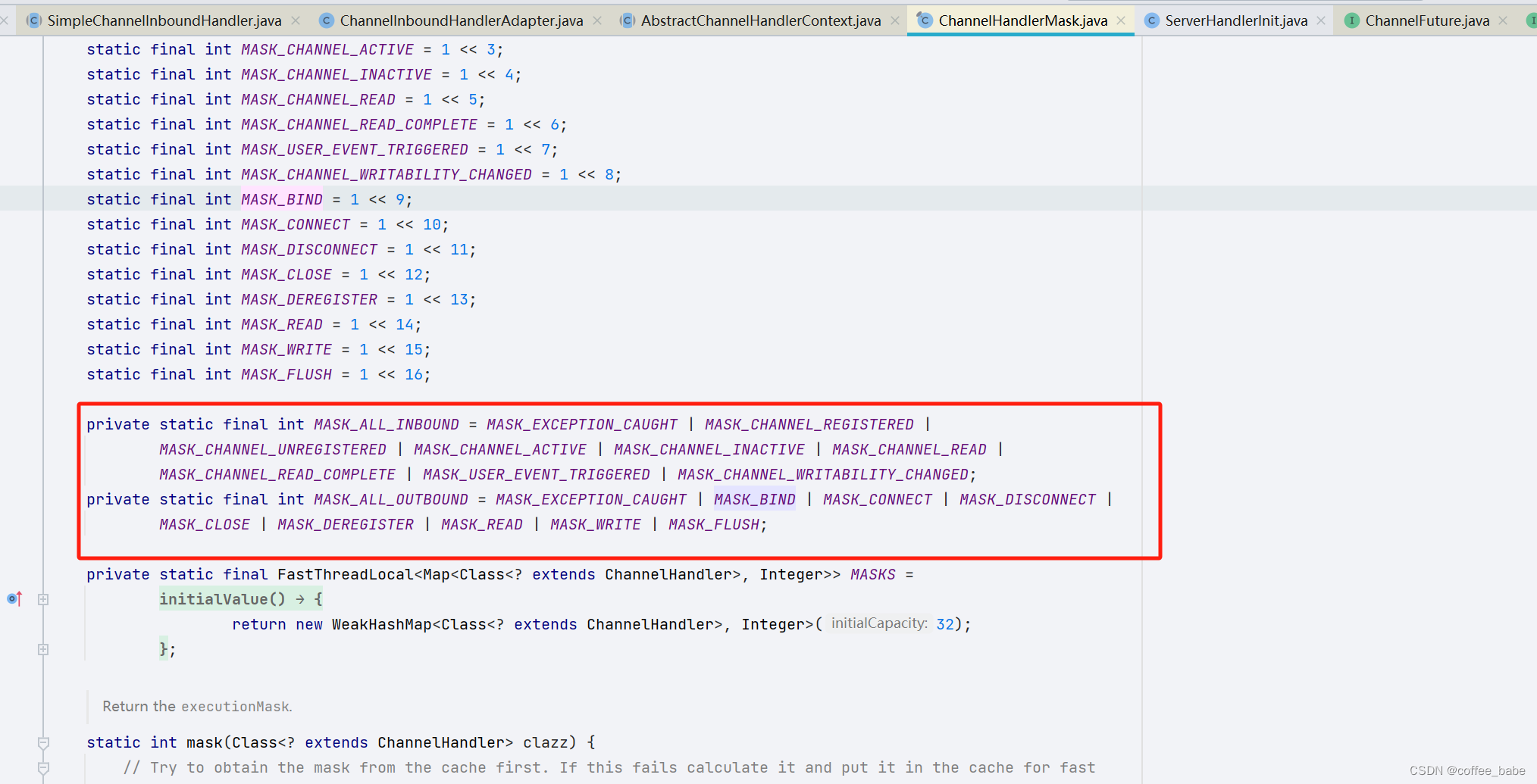
我们训练好网络后,并不能直接将网络用于预测整个花生豆的大图,因为里面有很多的花生豆,所以我们可以取出并预测,那么怎么单独取出来呢,这里用到了掩膜用以分割花生豆(一些注释写在了代码里)
首先导入相应的库和定义一下参数
# -*- coding: GB2312 -*-
import os
import cv2
import numpy as np
import torch
from PIL import Image
from utils.model import ResNet18
from torchvision import transforms
path = 'data/pic'
image_path = os.listdir(path)
classify = {0: 'baiban', 1: 'bandian', 2: 'famei', 3: 'faya', 4: 'hongpi', 5: 'qipao', 6: 'youwu', 7: 'zhengchang'}
transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()])
net = ResNet18(8)
net.load_state_dict(torch.load('model_weights/ResNet18.pth'))
min_size = 30
max_size = 400然后我们加载整个大图的文件夹并遍历处理每张图片
for i in image_path:
img = cv2.imread(os.path.join(path,i))
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) # 转HSV色彩空间
# 定义背景颜色区间(蓝色区间)
lower_blue = np.array([100, 100, 8])
upper_blue = np.array([255, 255, 255])
mask = cv2.inRange(hsv, lower_blue, upper_blue) # 创建掩膜(在上述颜色范围内(背景)为白色,不在(花生豆)则为黑色)
result = cv2.bitwise_and(img, img, mask=mask) # 根据掩膜提取图像,会将花生豆的部分变为黑色,然后提取出背景部分
result = result.astype(np.uint8)
_, binary_image = cv2.threshold(result, 1, 255, cv2.THRESH_BINARY) # 三通道二值化。背景会全为白色,花生豆部分为黑色
# 到这里我们就得到了经过掩膜过滤的图片,其中白色的为背景,黑色的为花生豆,我们可以看一下
cv2.namedWindow('HSV_Result', cv2.WINDOW_NORMAL)
cv2.resizeWindow('HSV_Result', 2840, 1000)
cv2.imshow('HSV_Result', binary_image)
cv2.waitKey(0)
cv2.destroyAllWindows()我们发现这些花生豆的背景是蓝色的,所以我们创建了一个用以区分背景和花生豆的掩膜用来分割二者,其分割完后的图片为

通过掩膜处理完后,我们可以清晰的观察到图片里的花生豆,后面我们就可以在这幅图片上画出轮廓并分割出花生豆部分依次放入网络预测
# 过滤边框
def delet_contours(contours, delete_list):
delta = 0
for i in range(len(delete_list)):
del contours[delete_list[i] - delta]
delta = delta + 1
return contours
inverted_image = cv2.cvtColor(binary_image, cv2.COLOR_BGR2GRAY) # 转灰度图
_, binary_image = cv2.threshold(inverted_image, 1, 255, cv2.THRESH_BINARY) # 单通道二值化
contours, hierarchy = cv2.findContours(binary_image, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
contours = list(contours)
delete_list = []
for i in range(len(contours)):
# 通过框的周长去过滤边框
if (cv2.arcLength(contours[i], True) < min_size) or (cv2.arcLength(contours[i], True) > max_size):
delete_list.append(i)
contours = delet_contours(contours, delete_list)
# 遍历每一个框(取出每一个单独的花生豆进行预测)
for i in range(len(contours)):
x, y, w, h = cv2.boundingRect(contours[i])
img_pred = img[y:y+h, x:x+w, :]
img_pred = Image.fromarray(img_pred) # 将numpy数组转为PIL图像对象
img_pred = transform(img_pred) # 调整图像尺寸和转tensor格式
img_pred = torch.unsqueeze(img_pred, dim=0) # 升一个维度
pred = torch.argmax(net(img_pred), dim=1) # 拿到概率最大的分类
preds = classify[int(pred)] # 数字映射为字符串
cv2.putText(img, preds, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1, cv2.LINE_AA) # 写类别标签
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2) # 画矩形框
cv2.namedWindow('Result', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Result',2840,1000)
cv2.imshow('Result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
展示一下预测结果

小编这里发现这个方法可以预测成功中间大多数的花生豆,但是边缘处的花生豆因不会被画出轮廓故不会被放入网络预测,大体预测的效果还算可以。
源码及数据集请查看:https://github.com/jvyou/Peanut-and-bean-sorting
视频讲解请查看:https://www.bilibili.com/video/BV13F4m1g7Wp/?spm_id_from=333.999.0.0



![[超分辨率重建]ESRGAN算法训练自己的数据集过程](https://img-blog.csdnimg.cn/direct/6fa8fc39d6164d3183992b8b9806273f.png)