本文整理自 2023 年 7 月 DataFunSummit 2023 数据基础架构峰会——大规模存储架构分论坛的同名主题分享。
非常欢迎大家的到来,今天由我来分享百度智能云块存储 EC 系统的构建。块存储系统在百度智能云的产品名叫 CDS,底层 EC 系统由 Aries 承担。
今天主要介绍的内容如下,首先会比较一下各种容错方式,介绍一下我们选择 EC 容错方式的必然性;然后给大家介绍一下在块存储产品下构建 EC 引擎的挑战,并逐步展开对这些挑战进行分析和解决的方法;最后,我们介绍一下基于这个解决方案的一些优化。
1. 数据容错方式比较
首先介绍一下常见的数据容错方式。
数据容错在单机和分布式系统下,有着不同的选择。
单机情况下,比较直接的方式是选用 RAID 卡。在 BIOS 中配置,一般支持 RAID5 就够了。如果没有 RAID 卡,也可以用软 RAID,创建带有 RAID 功能的逻辑卷。
分布式的情况,比较直接的方式是采用多副本的形式,将数据复制成多份,存在不同的机器。实际上,最好将每份数据保存到不同的交换机下。另外一种方式是采用分布式纠删码的方式。这种方式其实就是分布式的 RAID。只不过,单机用奇偶校验的 RAID5 基本可以保证数据安全,而分布式系统中,由于磁盘规模庞大,纠删码的复杂度要高一些。

这里介绍一下分布式容错方式的实现。多副本方式容错,每个副本的数据相同,所以,一般采用分布式的一致性协议对数据进行同步,主流的协议为 Paxos 和 Raft。有的系统也会自研一些分发写的协议。最终目的是保证多份数据相同。多副本情况下,假设是 N 副本,则最多允许 N-1 份数据损坏。
纠删码则是将用户的原始数据进行切分,形成 K 个大小相等的分片,然后对这些分片进行编码,形成 M 个校验分片。校验分片的大小和数据分片相同。K+M 个分片会被分布在不同的机器上。一般情况下,纠删码允许最多 M 个分片数据损坏。最常用的纠删码是 Reed-Solomon 编码(RS 码);
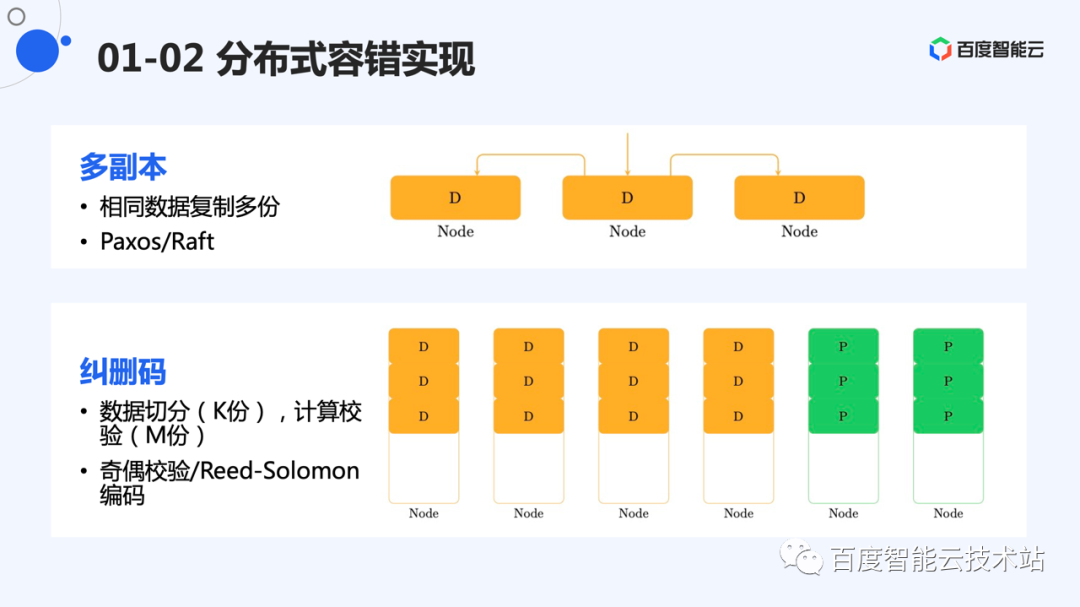
从成本考虑,3 副本将数据存储 3 份,因此是 3 倍的存储成本。而纠删码,是 K+M 的形式,K 份的数据,编码形成 M 份校验。通常情况下,M 比 K 要小。因此存储成本一般为 1.x 倍。
但是,纠删码也有自己缺点。多副本将数据无修改地复制到另外节点,不需要计算参与,数据恢复则是将数据重新复制一遍,方法比较简单。而纠删码则涉及到编码和解码,除了计算以外,编码和解码同样会带来额外的 I/O 开销。
现代 CPU 已经支持 RS 编码的硬件加速,能够提升编码/解码速度,极大减少计算压力。而 I/O 放大,则是我们重点要解决的问题。
磁盘通常具有 1%~2% 的年化故障率。由于分布式系统规模都比较大,大的集群都会有千台机器,万块磁盘的规模,一定会同时出现多块磁盘同时故障。因此,一般分布式系统都采用 2 个以上的备份或者校验。一般采用 3 副本或者 RS 编码才能保证数据的可靠性。基于目前的集群规模和成本,纠删码是必然的选择。

2. 大规模块存储 EC 的技术挑战
既然选择了纠删码,下面那必须解决 EC 系统中面临的各种问题。
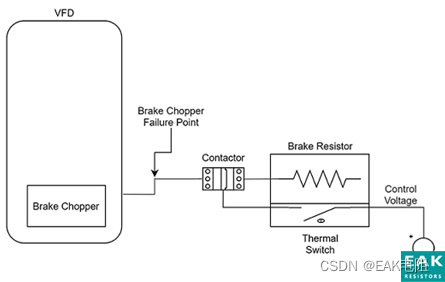
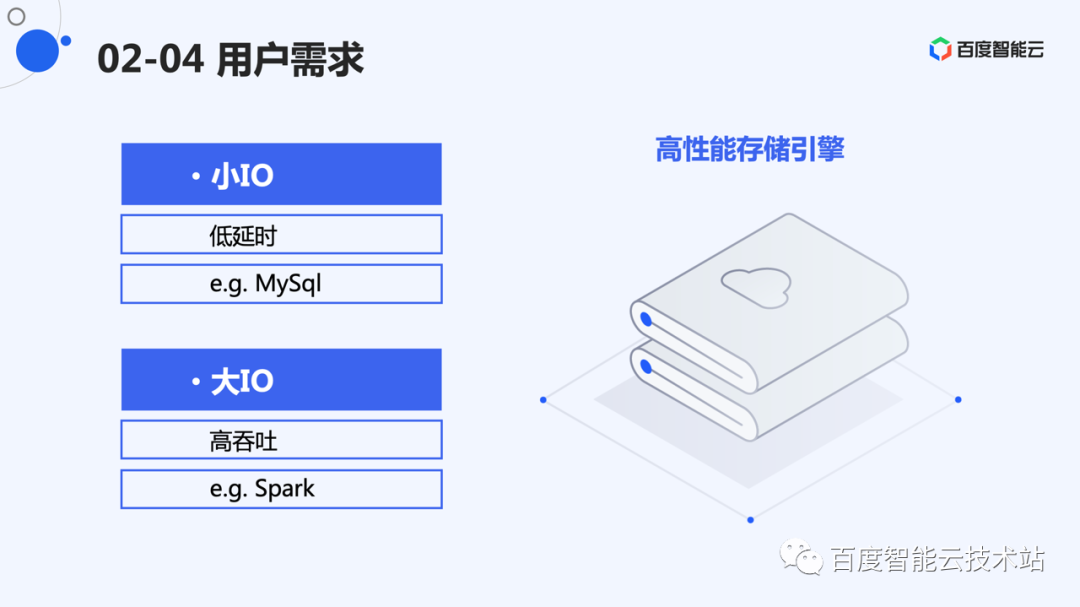
系统面临的挑战主要来自几个方面。一个是产品访问特性,块存储存储的是动态数据,用户会随时对数据进行修改。而 EC 修改代价高,原地修改需要引入额外计算和 I/O 放大。
另外就是用户下发给磁盘的数据大小不一,而小写不适合 EC。如何解决小 I/O 的 EC,是另外一个问题。
应用场景上,用户对大小写的要求是不一样的。因此,我们的设计需要一个合理的系统开销,减少资源占用,使得用户有比较好的 I/O 表现。

对比一下对象存储。它对外的接口是 put、get、delete。写入时,将一个对象的整体数据整体写入和整体删除,不涉及到重新编码的问题。因此,除了写入时产生的校验数据需要保存,没有其他写放大问题。
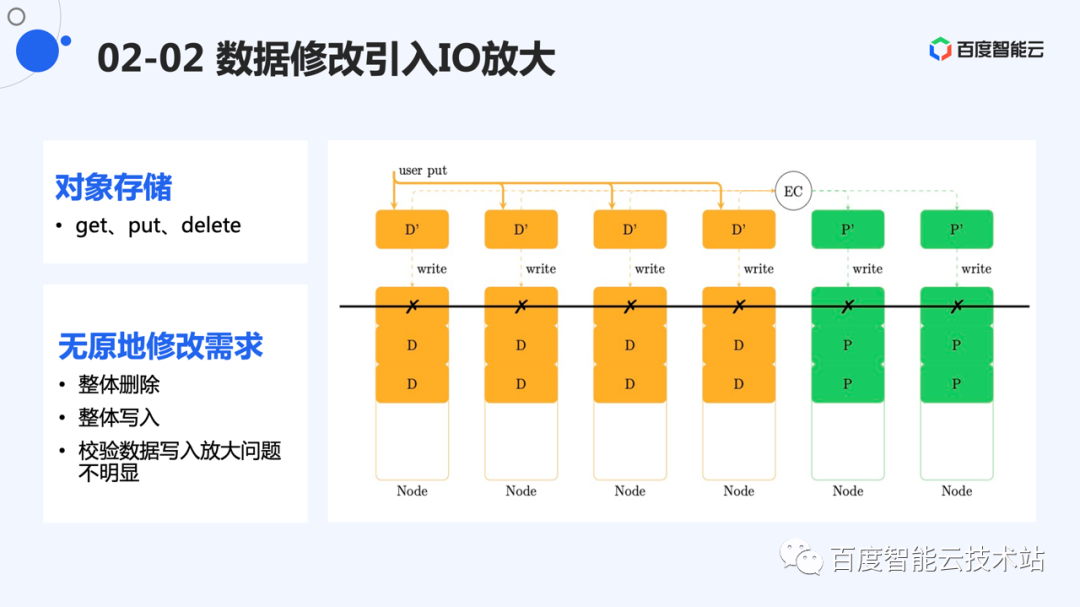
块存储,主要接口是读写和删除。与对象存储不同,这里的写绝大部分是对原有数据的修改。
对于部分数据修改,如果重新计算校验,需要将剩余数据从其余节点读到内存中,重新计算校验值,然后将校验再次写回。这里涉及到了「读-修改-写」,I/O 放大比较严重。

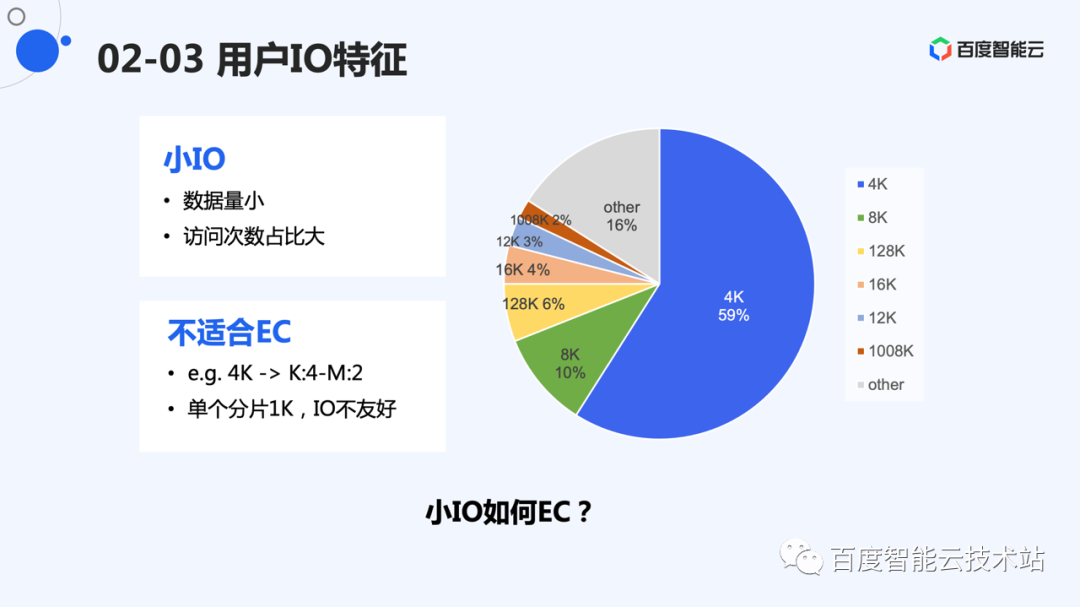
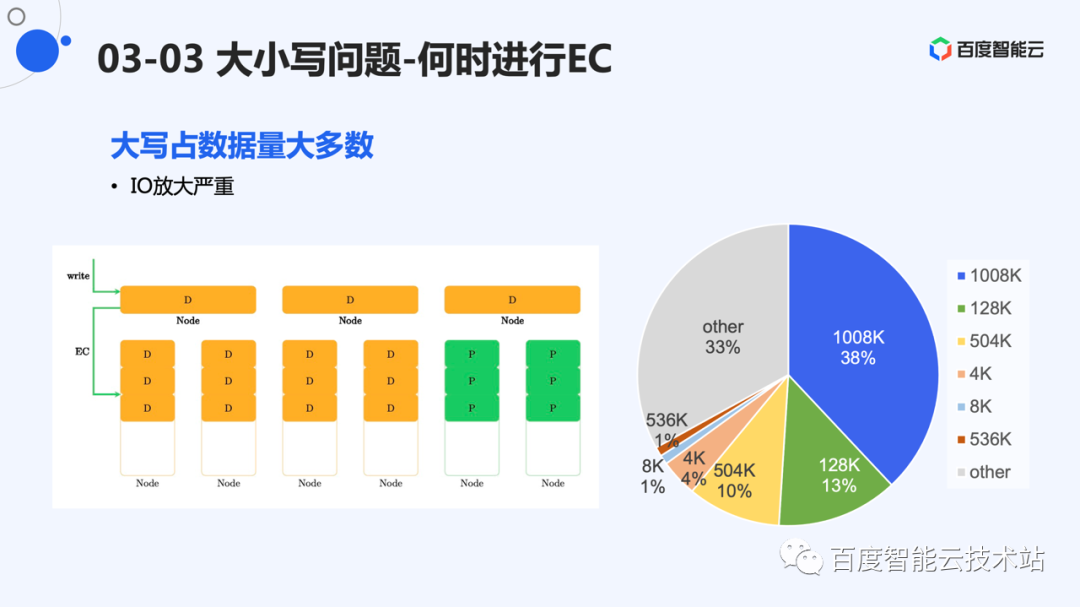
这里是线上 I/O 次数统计,小 I/O 的次数远远多于大 I/O。块存储 CDS 中,4K 大小的 I/O 占据了半数以上的写次数。但是小 I/O 不太适合 EC。
举个例子:我们如果采用 K 为 4,M 为 2 的编码,需要将分片切成 1K 大小,而一般情况下,文件系统对于 4K 倍数的 I/O 支持比较友好,1K 的 I/O size,相对来说,不是很合理的 I/O size。如果 K 值更大,会产生更细碎的分片。我们需要解决这些小 I/O 的 EC。
现代软件已经对磁盘访问有比较多的优化。当程序追求吞吐时会下发大 I/O,减少磁盘寻道时间。当程序对延时有需求时,通常会下发尽量小的 I/O,减少不必要的数据对 I/O 带宽的占用。
因此,总体看来,对于小 I/O用户需要的是小的延时,对于用户大的 I/O 用户需要的是高的吞吐。
硬件的物理带宽是有限的,提供高性能的存储引擎,系统本身占用的资源应该尽量小。对于存储引擎来说,主要就是写放大问题。
3. 百度沧海的实现方案
针对以上问题,我们看一下百度沧海的解决方案。
这里我们重新看一下修改,I/O 放大的主要原因是需要对原有存量数据进行修改操作,如果不做特殊优化,这些操作需要将原有数据读出来,用于计算新的校验。
CDS 的选择是构建一个索引层,索引指向 EC 后的数据,数据的修改不在原地进行。
这里给了个例子,用户第一次写的数据,EC 并且存储后,建立了一个索引指向这块数据。后续在中间的修改将作为一个新数据进行 EC 并且存储。然后构建新的索引指向新的数据,之前的索引分裂成 2 部分。
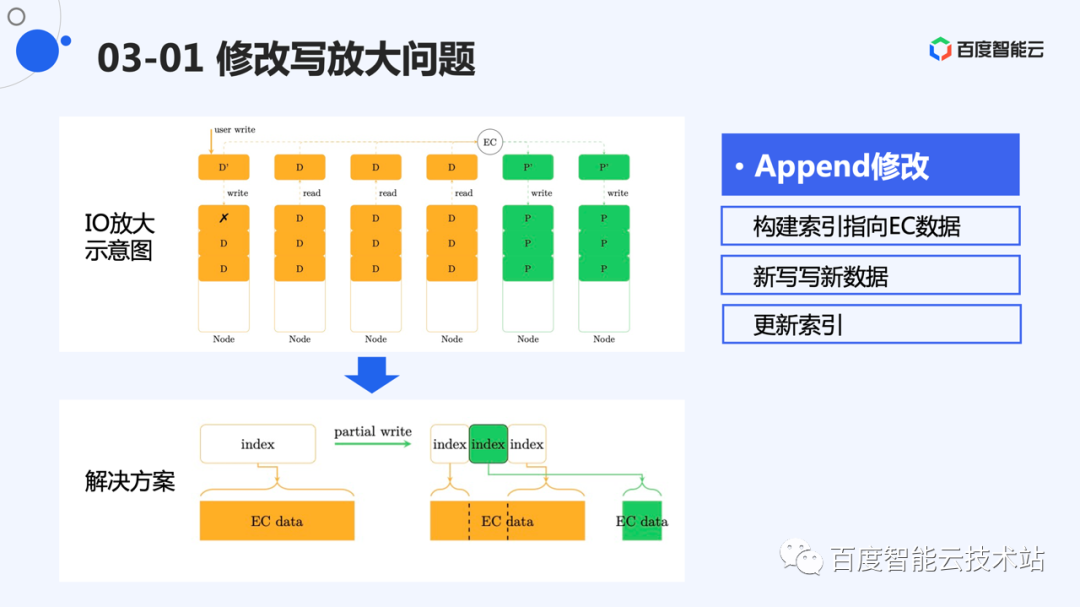
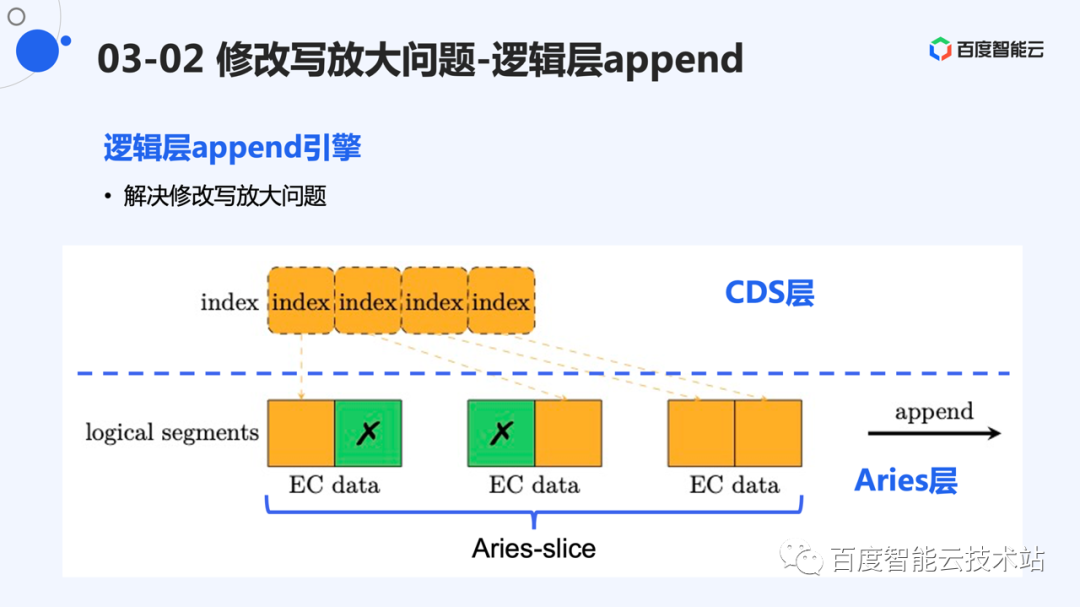
这样做后,我们实际上建立了一个基于 EC 数据的 Append 引擎。EC 后的数据,对应的就是 Append 引擎中的 segment。所有的修改采用追加写的形式,等同于 append 引擎的单路追加写。
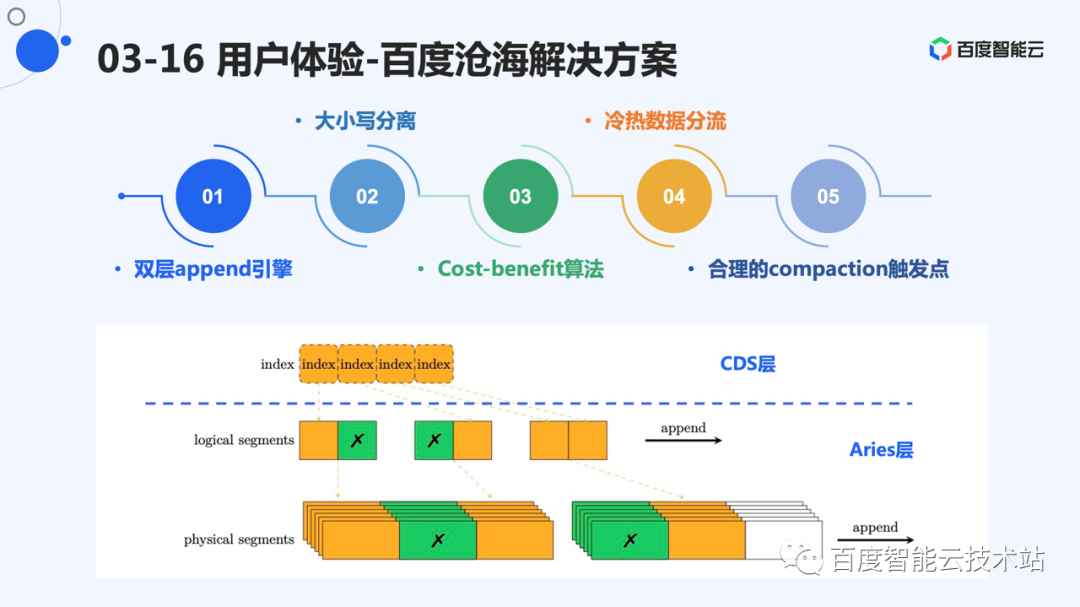
实际上,CDS 并未从头开始设计一个 EC 系统,而是采用了公司内成熟的 EC 系统 Aries 作为底层储存介质,Aries 是百度沧海提供的特别优秀的 EC 系统和数据底座。写入 Aries 的数据将作为一个 slice 存储,而一个 slice 可以对应到逻辑层的一个 segment。
我们前面提到了需要处理用户小写 EC 的问题。可以采用的一个方案是建立一个三副本的存储层,用来缓存用户 I/O。当用户写满一定规模的数据时(比如:1GB),将这些数据 EC 后进行存储。
这样的好处是所有写数据混在一起进行存储,分片的切分可以根据 EC 规模进行选择,可以做到分片对 I/O 友好。其中,EC 层基本可以假设分片是固定大小的。
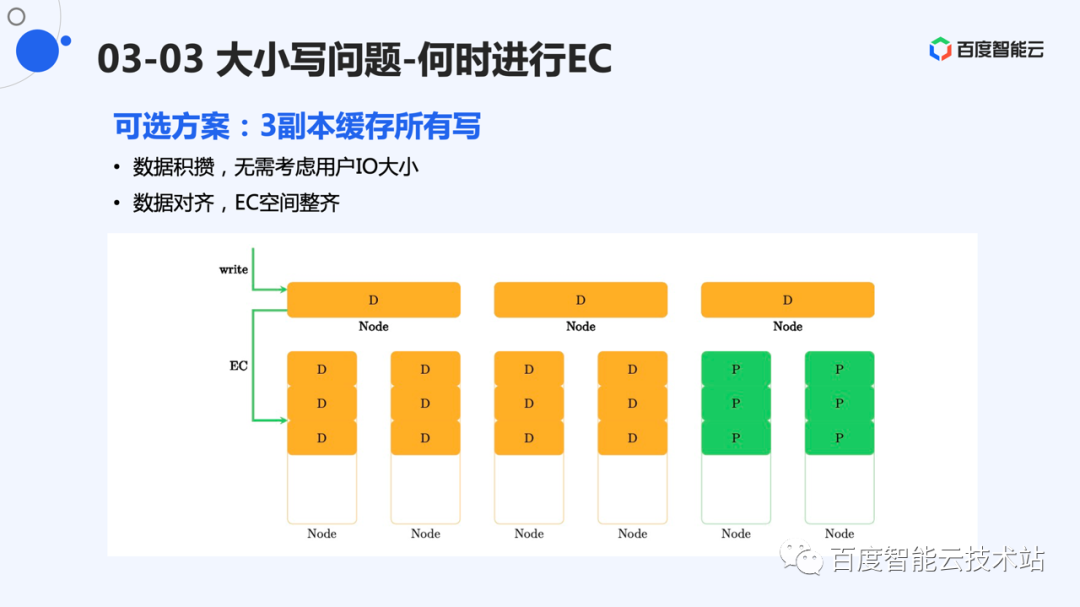
但是,这么做的缺点也很明显。数据会被先写到 3 副本层,再写到 EC 层。一定会有多于 4 倍的 I/O 放大。我们也统计了线上数据的写入量,数据量占据比较多的是大 I/O。这些大 I/O 对 EC 相对比较友好,可以采用直接 EC 的方式进行。
百度沧海的方案是将大写和小写进行分别处理。大写直接进行 EC,小写采用 3 副本形式存储。
这样做的好处是,大写的数据不经过 3 副本层,规避了缓存带来的绝大多数 I/O 放大。3 副本主要存储小 I/O,因为占比小,所以对成本的压力增长不是很大,I/O 放大也不是很严重。
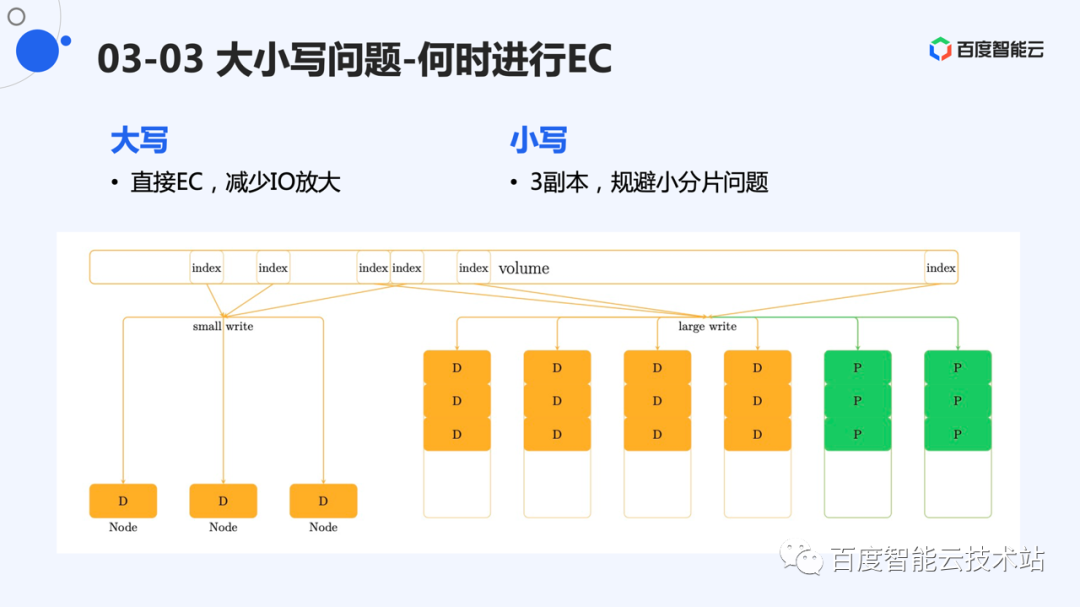
系统实现时,预留了 10% 作为 3 副本存储空间。3 副本也采用 append 引擎进行存储。数据 compaction 时,直接将数据存储到 EC 层。
这种设计,当 3 副本层空间紧张时,数据仍然会被进行 EC 存储,能够在用户都是小 I/O 的极端情况下,仍然有不错的成本表现。

内部交流时,经常会被问到数据是否会从 EC 层转移到 3 副本层。如果是同种介质,我们假设访问延时没有变化。因此,不将 3 副本层作为缓存层。

大 I/O 并不是固定大小,系统选择将大 I/O 直接 EC 的情况下,对于底层 EC 的存储引擎有新的要求。它必须能够处理不同大小的分片。
设计难点是,释放的空间如何被回收利用。图中给了个例子,当数据比空洞大时,无法将数据放入;当数据比空洞小时,造成空间浪费。因此,下层存储应该采用能够很好适应变长分片的引擎。
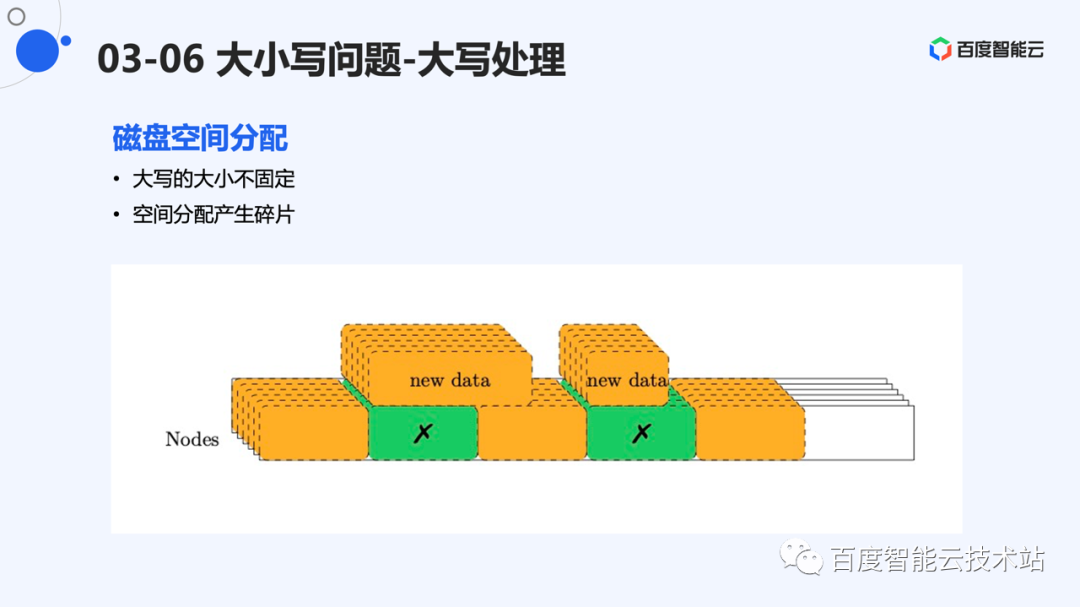
EC 存储引擎层仍然采用 append 写的方式。新数据 append 写,紧密排列在存储系统的后端。这样,新数据的空间分配变的简单。
相对于原地写,append 写无论是对于 ssd 还是 hdd,性能都更好,这也为高性能存储打下了基础。
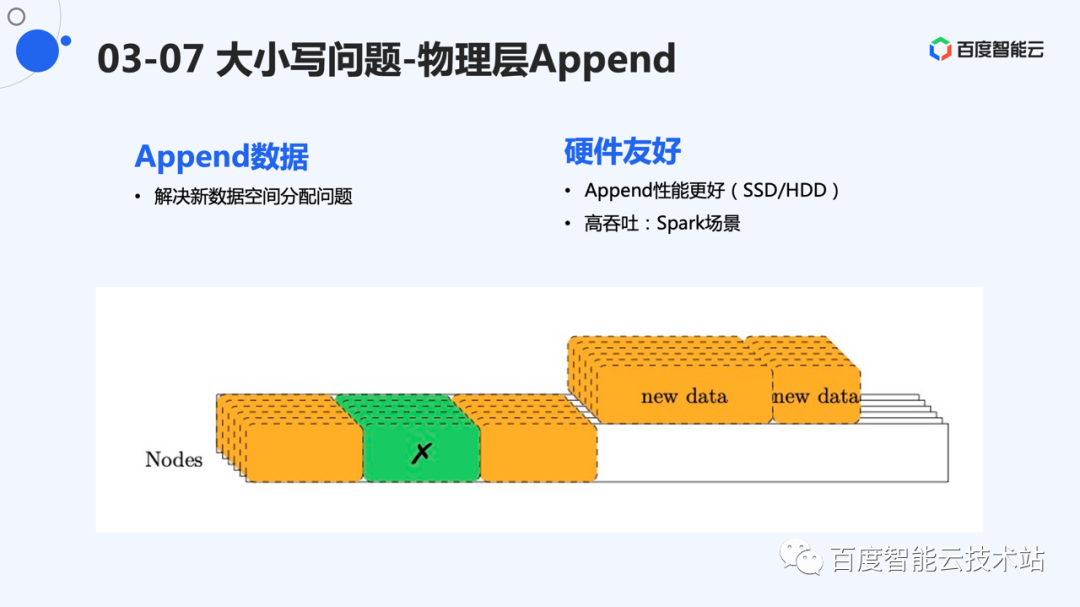
因此,总体架构是一个双层 append 架构。第一层有一个逻辑的 append 引擎,每个 EC 数据对应一个逻辑 segment。下层物理层存储 EC 的分片,也采用 append 的方式,数据只进行追加写。
我们通过两层架构解决了修改放大,大小写如何 EC 的问题。但是,仍然需要进一步提高系统性能,提升用户体验。

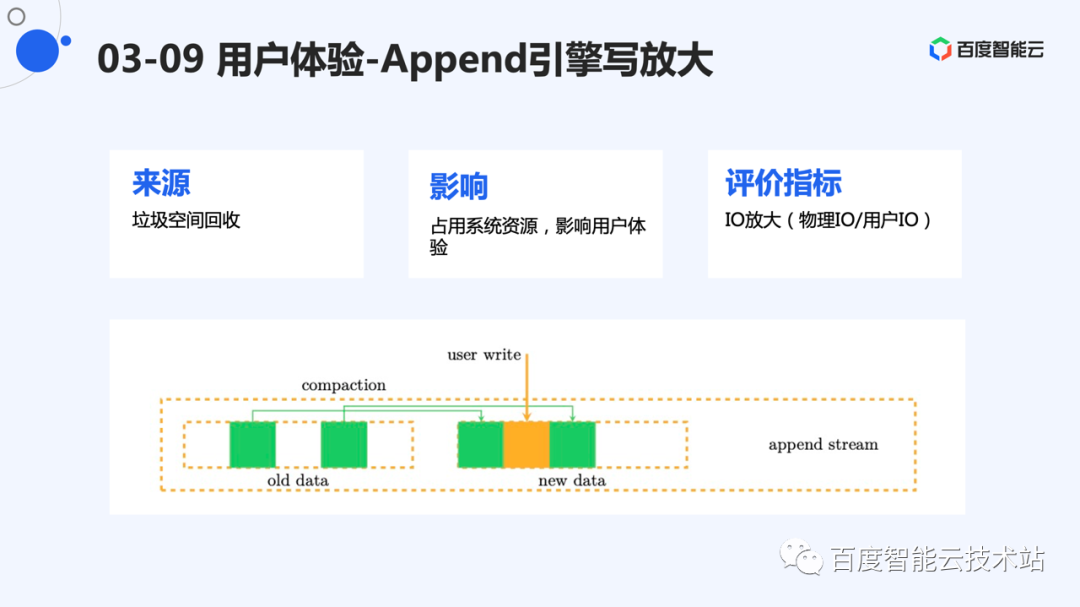
目前采用 2 层 append 引擎的方式构建系统。Append 的性能必然会对系统产生比较大的影响。存储系统,一般的瓶颈都是 I/O。Append 引擎天然存在写放大,主要来源为 compaction。
由于系统总带宽固定,如果 compaction 占用的带宽过大,留给用户使用的带宽就会降低,影响用户体验。
Append 引擎的一个重要评价指标,就是 I/O 放大,即系统总的物理 I/O 除以用户的 I/O。
要实现比较低的 I/O 放大,我们需要了解用户数据的访问特征。根据用户数据的访问特征,进行有效优化。
一般来说,用户的数据访问都存在热点情况。即最近写过的数据,被再次写的概率更大,也符合齐夫分布的特征。
齐夫分布,如公式所示,r 为访问频率的排名。C 和 ⍺ 为常数。即排名越往后,访问频率越低。对这个公式同时取对数的情况下,是一个下降的直线。我们也对线上数据的写频率进行了统计。除了长尾外,前半部分排名的数据,基本符合齐夫分布。
如果按照访问时间进行统计,那么 1 天内有写的热数据,只占总数据的 5% 左右。

既然数据有冷热,那么当我们选择 segment 进行 compaction,就可以利用数据的这种访问特点进行。
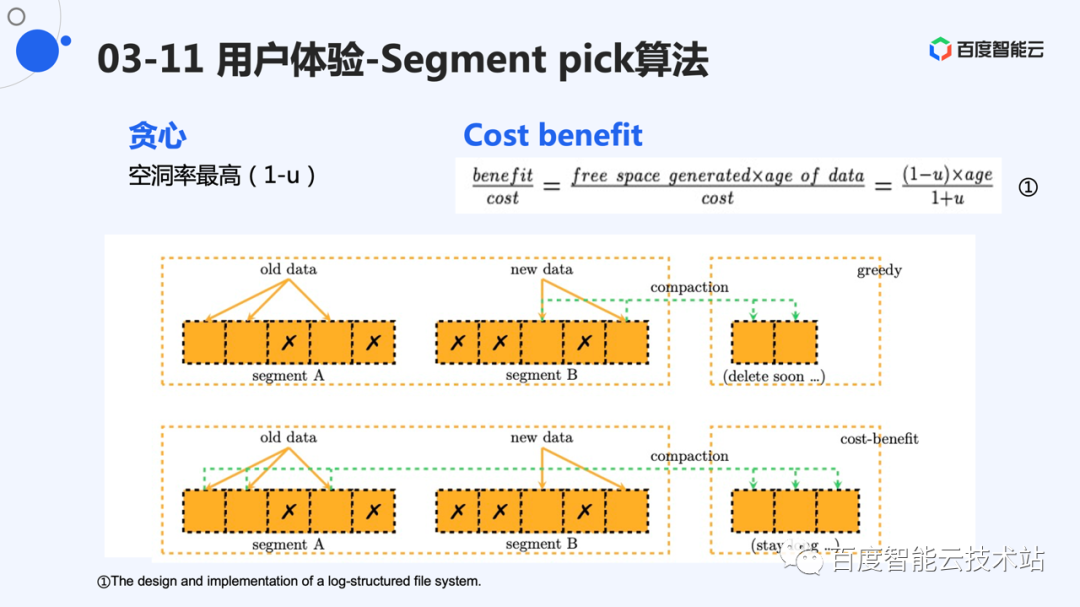
一般的选择方法是贪心算法,即选择最空的 segment 进行 compaction。如图中的例子,在贪心算法的情况下,由于 segment B 的空洞率更高,会选择 segment B 进行 compaction。但是,由于 B 中的数据比较新,很有可能是热数据,则这些数据过很小的一段时间就可能被覆盖写。这次数据搬迁就显得多余。
考虑到 segment A 中数据比较老。按照用户访问特点,更老的数据被更新的可能性更小。Segment A 会被长期占用,空洞空间无法释放。实际上,这些空洞更有价值,因为一旦释放,能够被利用很长时间。所以,cost-benefit 算法兼顾了空洞率和数据年龄。它的 pick 算法如公式所示,其中 u 代表有效数据率,age 表示 segment 中最新数据的年龄。这样,空洞率比较高的的 segment 会被选中,老的 segment 也有大概率被选中,释放出更有价值的空洞。
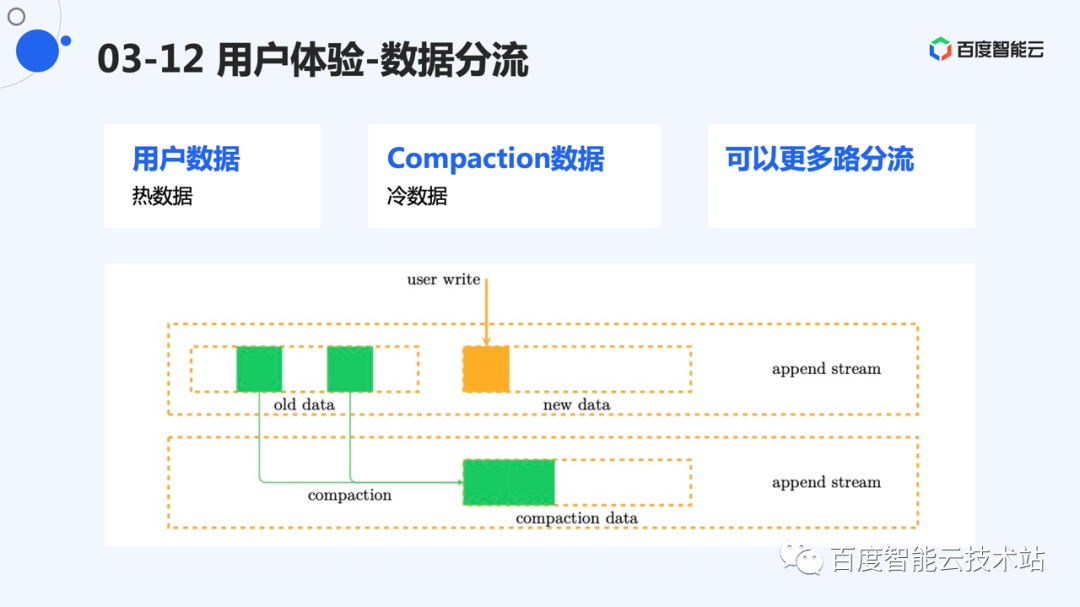
另外,compaction 的数据和用户的写入数据同样有不同的冷热。通常 compaction 的数据为长时间没有写到的数据。将这些数据单独分流,能够形成较为稳定的 segment。而用户的写入的数据短时间内被写的可能性比较大,也单独放置。这样进行分类后,能够形成一些致密的 segment,存放老数据。频繁的写入形成一些稀疏的 segment,这些 segment 可以被反复利用。
如果想要更好的效果,可以将数据流划分更细,更多地减少写放大。
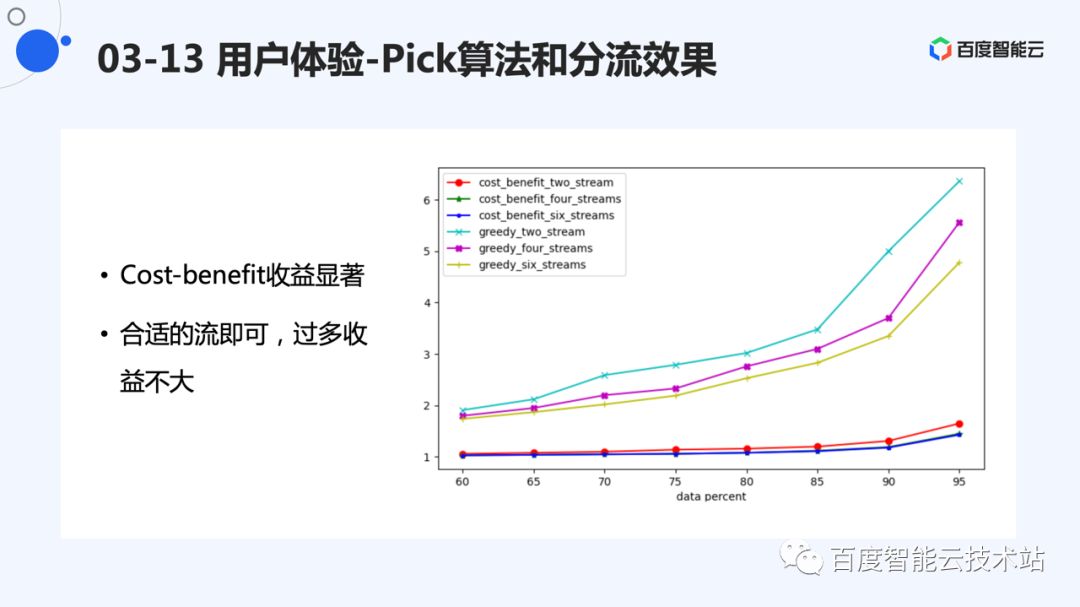
我们统计了线上统计访问,进行回放,控制不同物理空间使用情况下,验证了写放大的优化效果。
从图中可以看出,cost-benefit 与贪心算法相比,能够有效减少写放大。在高空间占用率的情况下(如 95%),cost-benefit 方式,能够达到 1.5 以下的写放大。而贪心算法则要达到 4 倍以上。
另外,更多的分流能够减少写放大。在贪心算法的情况下,能够节省较多的 I/O。cost-benefit 情况下,4 路到 6 路收益不太明显。
另外可以看出,空间使用率对写放大也有影响,即较低的空间使用率的情况下,写放大更好。这也符合直觉,compaction 越晚发生,segment 形成的空洞越多。
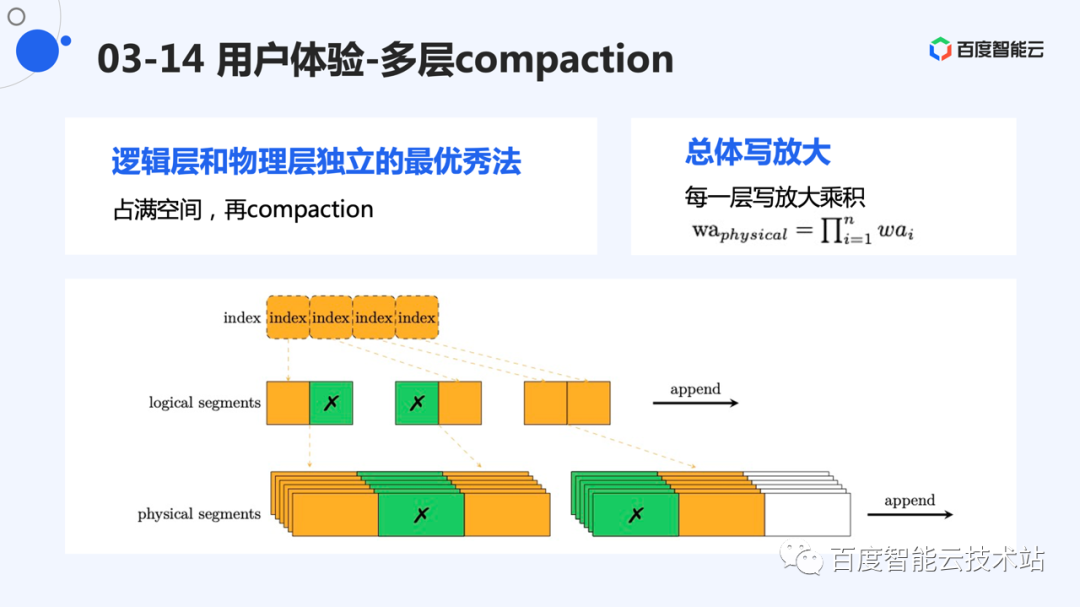
对于多层 append 系统,每一层都期望把本层能用的空间尽量用满,然后再做 compaction。但是这么做会导致下一层的空间持续紧张,导致下层写放大比较严重。例如,如果逻辑层写的比较满,迟迟不做 compaction,那么物理层则需要频繁做 compaction 为逻辑层提供充足写空间。
系统的整体写放大,应该是每一层的写放大的乘积。那么,总体写放大并不是追求单独一层低写放大,而是一个均衡的写放大,使得整体写放大较低。
因此,我们结合自己的系统特征,设计了一个均衡 compaction 的点。最上层是用户数据空间,下层是 EC 系统能够提供的物理空间,中间是写入 EC 层的数据。
我们选择一个中间点进行 compaction 的选择,如果这个点偏左,说明上层数据比较致密,空洞较少,则下层进行 compaction。如果这个点偏右,则说明下层致密,上层空洞率较多,触发上层的 compaction。
这样,我们就形成了一个动态可调节的 compaction 点,使得上下层的 compaction 都不太大,动态维护一个较低的整体 compaction。

总结下来,系统有低成本的需求,大规模场景下多副本由于成本问题,不能满足需求。因此,我们必要采用纠删码的形式组织数据。
而纠删码本身修改代价比较大,系统设计当中,利用追加写的方式进行修改。并且采用大小写分离的方式存储数据。分离后,大写部分产生的 EC 数据为变长,采用 append 的引擎,为这种变长分片提供更好的空间分配机制,同时能够充分利用硬件追加写的性能优势。
综上,百度沧海的块存储采用了 2 层 append 方案,规避了 EC 的修改代价。通过大小写分离情况,解决了小写不适合 EC 的情况。同时选择了合适 pick 算法、数据分流、合适的 compaction 点的方式,优化了系统的写放大,能够达到低成本下较高的系统性能。
![[当人工智能遇上安全] 11.威胁情报实体识别 (2)基于BiGRU-CRF的中文实体识别万字详解](https://img-blog.csdnimg.cn/53b9f1a2d4014fe68885a3028807286d.jpeg#pic_center)

![[大厂实践] Netflix容器平台内核panic可观察性实践](https://img-blog.csdnimg.cn/img_convert/2a4b58f5c32cbc76b3acfb94b975b9a1.png)