https://www.cnblogs.com/darcy-yuan/p/17039526.html
1.概述
上文我们讨论了es(elasticsearch,下同)索引流程,本文讨论es查询流程,以下是基本流程图

2.查询流程
为了方便调试代码,笔者在电脑上启动了了两个节点,创建了一个索引如下,该索引有两个分片,没有复制分片

使用postman发送如下请求:
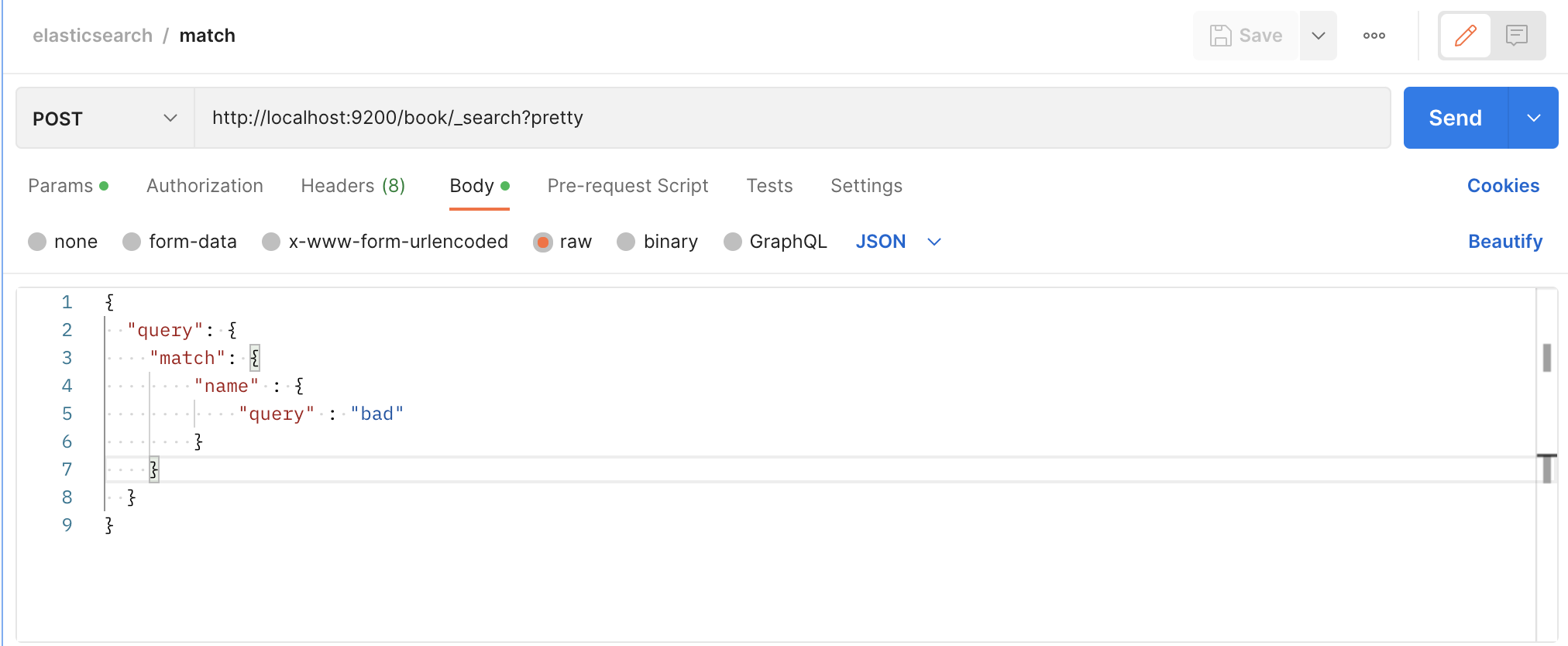
接下来,我们看代码(本系列文章源代码版本为7.4.0),search查询也是rest请求
// org.elasticsearch.action.support.TransportAction
public void proceed(Task task, String actionName, Request request, ActionListener<Response> listener) {
int i = index.getAndIncrement();
try {
if (i < this.action.filters.length) {
this.action.filters[i].apply(task, actionName, request, listener, this); // 先处理过滤器
} else if (i == this.action.filters.length) {
this.action.doExecute(task, request, listener); // 执行action操作
} else {
listener.onFailure(new IllegalStateException("proceed was called too many times"));
}
} catch(Exception e) {
logger.trace("Error during transport action execution.", e);
listener.onFailure(e);
}
}具体执行操作的是 TransportSearchAction,TransportSearchAction 对查询索引的顺序做了一些优化,我们这里用的是 QUERY_THEN_FETCH
// org.elasticsearch.action.search.TransportSearchAction
protected void doExecute(Task task, SearchRequest searchRequest, ActionListener<SearchResponse> listener) {
final long relativeStartNanos = System.nanoTime();
final SearchTimeProvider timeProvider =
new SearchTimeProvider(searchRequest.getOrCreateAbsoluteStartMillis(), relativeStartNanos, System::nanoTime);
ActionListener<SearchSourceBuilder> rewriteListener = ActionListener.wrap(source -> {
if (source != searchRequest.source()) {
// only set it if it changed - we don't allow null values to be set but it might be already null. this way we catch
// situations when source is rewritten to null due to a bug
searchRequest.source(source);
}
final ClusterState clusterState = clusterService.state();
final Map<String, OriginalIndices> remoteClusterIndices = remoteClusterService.groupIndices(searchRequest.indicesOptions(),
searchRequest.indices(), idx -> indexNameExpressionResolver.hasIndexOrAlias(idx, clusterState));
OriginalIndices localIndices = remoteClusterIndices.remove(RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY);
if (remoteClusterIndices.isEmpty()) {
executeLocalSearch(task, timeProvider, searchRequest, localIndices, clusterState, listener); // 查询当前节点
} else {
if (shouldMinimizeRoundtrips(searchRequest)) { // 使用了折叠
ccsRemoteReduce(searchRequest, localIndices, remoteClusterIndices, timeProvider, searchService::createReduceContext,
remoteClusterService, threadPool, listener,
(r, l) -> executeLocalSearch(task, timeProvider, r, localIndices, clusterState, l));
} else {
AtomicInteger skippedClusters = new AtomicInteger(0);
collectSearchShards(searchRequest.indicesOptions(), searchRequest.preference(), searchRequest.routing(),
skippedClusters, remoteClusterIndices, remoteClusterService, threadPool,
ActionListener.wrap(
searchShardsResponses -> {
List<SearchShardIterator> remoteShardIterators = new ArrayList<>();
Map<String, AliasFilter> remoteAliasFilters = new HashMap<>();
BiFunction<String, String, DiscoveryNode> clusterNodeLookup = processRemoteShards(
searchShardsResponses, remoteClusterIndices, remoteShardIterators, remoteAliasFilters);
int localClusters = localIndices == null ? 0 : 1;
int totalClusters = remoteClusterIndices.size() + localClusters;
int successfulClusters = searchShardsResponses.size() + localClusters;
executeSearch((SearchTask) task, timeProvider, searchRequest, localIndices,
remoteShardIterators, clusterNodeLookup, clusterState, remoteAliasFilters, listener,
new SearchResponse.Clusters(totalClusters, successfulClusters, skippedClusters.get()));
},
listener::onFailure));
}
}
}, listener::onFailure);
if (searchRequest.source() == null) {
rewriteListener.onResponse(searchRequest.source());
} else {
Rewriteable.rewriteAndFetch(searchRequest.source(), searchService.getRewriteContext(timeProvider::getAbsoluteStartMillis),
rewriteListener); // 重写后回调
}
}
...
private void executeSearch(SearchTask task, SearchTimeProvider timeProvider, SearchRequest searchRequest,
OriginalIndices localIndices, List<SearchShardIterator> remoteShardIterators,
BiFunction<String, String, DiscoveryNode> remoteConnections, ClusterState clusterState,
Map<String, AliasFilter> remoteAliasMap, ActionListener<SearchResponse> listener,
SearchResponse.Clusters clusters) {
clusterState.blocks().globalBlockedRaiseException(ClusterBlockLevel.READ); // 读锁
// TODO: I think startTime() should become part of ActionRequest and that should be used both for index name
// date math expressions and $now in scripts. This way all apis will deal with now in the same way instead
// of just for the _search api
final Index[] indices = resolveLocalIndices(localIndices, searchRequest.indicesOptions(), clusterState, timeProvider);
Map<String, AliasFilter> aliasFilter = buildPerIndexAliasFilter(searchRequest, clusterState, indices, remoteAliasMap);
Map<String, Set<String>> routingMap = indexNameExpressionResolver.resolveSearchRouting(clusterState, searchRequest.routing(),
searchRequest.indices());
routingMap = routingMap == null ? Collections.emptyMap() : Collections.unmodifiableMap(routingMap);
Map<String, Float> concreteIndexBoosts = resolveIndexBoosts(searchRequest, clusterState);
if (shouldSplitIndices(searchRequest)) { // 分开查询只读索引和在写索引,并且优先查在写索引
//Execute two separate searches when we can, so that indices that are being written to are searched as quickly as possible.
//Otherwise their search context would need to stay open for too long between the query and the fetch phase, due to other
//indices (possibly slower) being searched at the same time.
List<String> writeIndicesList = new ArrayList<>();
List<String> readOnlyIndicesList = new ArrayList<>();
splitIndices(indices, clusterState, writeIndicesList, readOnlyIndicesList);
String[] writeIndices = writeIndicesList.toArray(new String[0]);
String[] readOnlyIndices = readOnlyIndicesList.toArray(new String[0]);
if (readOnlyIndices.length == 0) {
executeSearch(task, timeProvider, searchRequest, localIndices, writeIndices, routingMap,
aliasFilter, concreteIndexBoosts, remoteShardIterators, remoteConnections, clusterState, listener, clusters);
} else if (writeIndices.length == 0 && remoteShardIterators.isEmpty()) {
executeSearch(task, timeProvider, searchRequest, localIndices, readOnlyIndices, routingMap,
aliasFilter, concreteIndexBoosts, remoteShardIterators, remoteConnections, clusterState, listener, clusters);
} else {
//Split the search in two whenever throttled indices are searched together with ordinary indices (local or remote), so
//that we don't keep the search context open for too long between query and fetch for ordinary indices due to slow indices.
CountDown countDown = new CountDown(2);
AtomicReference<Exception> exceptions = new AtomicReference<>();
SearchResponseMerger searchResponseMerger = createSearchResponseMerger(searchRequest.source(), timeProvider,
searchService::createReduceContext);
CountDownActionListener<SearchResponse, SearchResponse> countDownActionListener =
new CountDownActionListener<SearchResponse, SearchResponse>(countDown, exceptions, listener) {
@Override
void innerOnResponse(SearchResponse searchResponse) {
searchResponseMerger.add(searchResponse);
}
@Override
SearchResponse createFinalResponse() {
return searchResponseMerger.getMergedResponse(clusters);
}
};
//Note that the indices set to the new SearchRequest won't be retrieved from it, as they have been already resolved and
//will be provided separately to executeSearch.
SearchRequest writeIndicesRequest = SearchRequest.subSearchRequest(searchRequest, writeIndices,
RemoteClusterService.LOCAL_CLUSTER_GROUP_KEY, timeProvider.getAbsoluteStartMillis(), false);
executeSearch(task, timeProvider, writeIndicesRequest, localIndices, writeIndices, routingMap,
aliasFilter, concreteIndexBoosts, remoteShardIterators, remoteConnections, clusterState, countDownActionListener,
SearchResponse.Clusters.EMPTY);
//Note that the indices set to the new SearchRequest won't be retrieved from it, as they have been already resolved and
//will be provided separately to executeSearch.
SearchRequest readOnlyIndicesRequest = SearchRequest.subSearchRequest(searchRequest, readOnlyIndices,
RemoteClusterService.LOCAL_CLUSTER_GROUP_KEY, timeProvider.getAbsoluteStartMillis(), false);
executeSearch(task, timeProvider, readOnlyIndicesRequest, localIndices, readOnlyIndices, routingMap,
aliasFilter, concreteIndexBoosts, Collections.emptyList(), (alias, id) -> null, clusterState, countDownActionListener,
SearchResponse.Clusters.EMPTY);
}
} else {
String[] concreteIndices = Arrays.stream(indices).map(Index::getName).toArray(String[]::new);
executeSearch(task, timeProvider, searchRequest, localIndices, concreteIndices, routingMap,
aliasFilter, concreteIndexBoosts, remoteShardIterators, remoteConnections, clusterState, listener, clusters);
}
}
...
private void executeSearch(SearchTask task, SearchTimeProvider timeProvider, SearchRequest searchRequest,
OriginalIndices localIndices, String[] concreteIndices, Map<String, Set<String>> routingMap,
Map<String, AliasFilter> aliasFilter, Map<String, Float> concreteIndexBoosts,
List<SearchShardIterator> remoteShardIterators, BiFunction<String, String, DiscoveryNode> remoteConnections,
ClusterState clusterState, ActionListener<SearchResponse> listener, SearchResponse.Clusters clusters) {
Map<String, Long> nodeSearchCounts = searchTransportService.getPendingSearchRequests();
GroupShardsIterator<ShardIterator> localShardsIterator = clusterService.operationRouting().searchShards(clusterState,
concreteIndices, routingMap, searchRequest.preference(), searchService.getResponseCollectorService(), nodeSearchCounts);
GroupShardsIterator<SearchShardIterator> shardIterators = mergeShardsIterators(localShardsIterator, localIndices,
searchRequest.getLocalClusterAlias(), remoteShardIterators);
failIfOverShardCountLimit(clusterService, shardIterators.size());
// optimize search type for cases where there is only one shard group to search on
if (shardIterators.size() == 1) {
// if we only have one group, then we always want Q_T_F, no need for DFS, and no need to do THEN since we hit one shard
searchRequest.searchType(QUERY_THEN_FETCH); // 单个分片,不需要dfs了
}
if (searchRequest.allowPartialSearchResults() == null) {
// No user preference defined in search request - apply cluster service default
searchRequest.allowPartialSearchResults(searchService.defaultAllowPartialSearchResults());
}
if (searchRequest.isSuggestOnly()) {
// disable request cache if we have only suggest
searchRequest.requestCache(false);
if (searchRequest.searchType() == DFS_QUERY_THEN_FETCH) {
// convert to Q_T_F if we have only suggest
searchRequest.searchType(QUERY_THEN_FETCH);
}
}
final DiscoveryNodes nodes = clusterState.nodes();
BiFunction<String, String, Transport.Connection> connectionLookup = buildConnectionLookup(searchRequest.getLocalClusterAlias(),
nodes::get, remoteConnections, searchTransportService::getConnection);
boolean preFilterSearchShards = shouldPreFilterSearchShards(searchRequest, shardIterators);
searchAsyncAction(task, searchRequest, shardIterators, timeProvider, connectionLookup, clusterState.version(),
Collections.unmodifiableMap(aliasFilter), concreteIndexBoosts, routingMap, listener, preFilterSearchShards, clusters).start(); // 执行 SearchQueryThenFetchAsyncAction,异步处理
}接下来执行 QUERY_THEN_FETCH的逻辑,从上面的时序图中我们看到 QUERY_THEN_FETCH主要分为四个阶段(phase),init, query, fetch, send response
// org.elasticsearch.action.search.AbstractSearchAsyncAction
private void executePhase(SearchPhase phase) {
try {
phase.run(); // 执行阶段
} catch (Exception e) {
if (logger.isDebugEnabled()) {
logger.debug(new ParameterizedMessage("Failed to execute [{}] while moving to [{}] phase", request, phase.getName()), e);
}
onPhaseFailure(phase, "", e);
}
}首先是init阶段
// org.elasticsearch.action.search.AbstractSearchAsyncAction
public final void run() {
for (final SearchShardIterator iterator : toSkipShardsIts) {
assert iterator.skip();
skipShard(iterator);
}
if (shardsIts.size() > 0) {
assert request.allowPartialSearchResults() != null : "SearchRequest missing setting for allowPartialSearchResults";
if (request.allowPartialSearchResults() == false) {
final StringBuilder missingShards = new StringBuilder();
// Fail-fast verification of all shards being available
for (int index = 0; index < shardsIts.size(); index++) {
final SearchShardIterator shardRoutings = shardsIts.get(index);
if (shardRoutings.size() == 0) {
if(missingShards.length() > 0){
missingShards.append(", ");
}
missingShards.append(shardRoutings.shardId());
}
}
if (missingShards.length() > 0) {
//Status red - shard is missing all copies and would produce partial results for an index search
final String msg = "Search rejected due to missing shards ["+ missingShards +
"]. Consider using `allow_partial_search_results` setting to bypass this error.";
throw new SearchPhaseExecutionException(getName(), msg, null, ShardSearchFailure.EMPTY_ARRAY);
}
}
for (int index = 0; index < shardsIts.size(); index++) { // 轮询分片搜索
final SearchShardIterator shardRoutings = shardsIts.get(index);
assert shardRoutings.skip() == false;
performPhaseOnShard(index, shardRoutings, shardRoutings.nextOrNull());
}
}
}然后是query阶段,query阶段调用transportService去查当前节点,或者其他节点查询符合条件的文档
// org.elasticsearch.action.search.SearchQueryThenFetchAsyncAction
protected void executePhaseOnShard(final SearchShardIterator shardIt, final ShardRouting shard,
final SearchActionListener<SearchPhaseResult> listener) {
getSearchTransport().sendExecuteQuery(getConnection(shardIt.getClusterAlias(), shard.currentNodeId()),
buildShardSearchRequest(shardIt), getTask(), listener);
}节点收到请求后找到对应的处理器处理
// org.elasticsearch.action.search.SearchTransportService
transportService.registerRequestHandler(QUERY_ACTION_NAME, ThreadPool.Names.SAME, ShardSearchTransportRequest::new, // 注册query的请求处理器
(request, channel, task) -> {
searchService.executeQueryPhase(request, (SearchTask) task, new ChannelActionListener<>(
channel, QUERY_ACTION_NAME, request));
});构建queryContext进行查询
// org.elasticsearch.search.SearchService
private SearchPhaseResult executeQueryPhase(ShardSearchRequest request, SearchTask task) throws Exception {
final SearchContext context = createAndPutContext(request);
context.incRef();
try {
context.setTask(task);
final long afterQueryTime;
try (SearchOperationListenerExecutor executor = new SearchOperationListenerExecutor(context)) {
contextProcessing(context);
loadOrExecuteQueryPhase(request, context); // query 主逻辑
if (context.queryResult().hasSearchContext() == false && context.scrollContext() == null) {
freeContext(context.id());
} else {
contextProcessedSuccessfully(context);
}
afterQueryTime = executor.success();
}
if (request.numberOfShards() == 1) {
return executeFetchPhase(context, afterQueryTime); // fetch 逻辑
}
return context.queryResult();
} catch (Exception e) {
// execution exception can happen while loading the cache, strip it
if (e instanceof ExecutionException) {
e = (e.getCause() == null || e.getCause() instanceof Exception) ?
(Exception) e.getCause() : new ElasticsearchException(e.getCause());
}
logger.trace("Query phase failed", e);
processFailure(context, e);
throw e;
} finally {
cleanContext(context);
}
}
...
private void loadOrExecuteQueryPhase(final ShardSearchRequest request, final SearchContext context) throws Exception {
final boolean canCache = indicesService.canCache(request, context);
context.getQueryShardContext().freezeContext();
if (canCache) { // 看下是否有缓存
indicesService.loadIntoContext(request, context, queryPhase);
} else {
queryPhase.execute(context);
}
}
...
public void execute(SearchContext searchContext) throws QueryPhaseExecutionException {
if (searchContext.hasOnlySuggest()) {
suggestPhase.execute(searchContext);
searchContext.queryResult().topDocs(new TopDocsAndMaxScore(
new TopDocs(new TotalHits(0, TotalHits.Relation.EQUAL_TO), Lucene.EMPTY_SCORE_DOCS), Float.NaN),
new DocValueFormat[0]);
return;
}
if (LOGGER.isTraceEnabled()) {
LOGGER.trace("{}", new SearchContextSourcePrinter(searchContext));
}
// Pre-process aggregations as late as possible. In the case of a DFS_Q_T_F
// request, preProcess is called on the DFS phase phase, this is why we pre-process them
// here to make sure it happens during the QUERY phase
aggregationPhase.preProcess(searchContext);
final ContextIndexSearcher searcher = searchContext.searcher();
boolean rescore = execute(searchContext, searchContext.searcher(), searcher::setCheckCancelled); // 查询主逻辑
if (rescore) { // only if we do a regular search
rescorePhase.execute(searchContext); // 重新打分
}
suggestPhase.execute(searchContext); // 处理建议,聚合
aggregationPhase.execute(searchContext);
if (searchContext.getProfilers() != null) {
ProfileShardResult shardResults = SearchProfileShardResults
.buildShardResults(searchContext.getProfilers());
searchContext.queryResult().profileResults(shardResults);
}
}
...
static boolean execute(SearchContext searchContext,
final IndexSearcher searcher,
Consumer<Runnable> checkCancellationSetter) throws QueryPhaseExecutionException {
final IndexReader reader = searcher.getIndexReader();
QuerySearchResult queryResult = searchContext.queryResult();
queryResult.searchTimedOut(false);
try {
queryResult.from(searchContext.from());
queryResult.size(searchContext.size());
Query query = searchContext.query();
assert query == searcher.rewrite(query); // already rewritten
final ScrollContext scrollContext = searchContext.scrollContext();
if (scrollContext != null) {
if (scrollContext.totalHits == null) {
// first round
assert scrollContext.lastEmittedDoc == null;
// there is not much that we can optimize here since we want to collect all
// documents in order to get the total number of hits
} else {
final ScoreDoc after = scrollContext.lastEmittedDoc;
if (returnsDocsInOrder(query, searchContext.sort())) {
// now this gets interesting: since we sort in index-order, we can directly
// skip to the desired doc
if (after != null) {
query = new BooleanQuery.Builder()
.add(query, BooleanClause.Occur.MUST)
.add(new MinDocQuery(after.doc + 1), BooleanClause.Occur.FILTER)
.build();
}
// ... and stop collecting after ${size} matches
searchContext.terminateAfter(searchContext.size());
} else if (canEarlyTerminate(reader, searchContext.sort())) {
// now this gets interesting: since the search sort is a prefix of the index sort, we can directly
// skip to the desired doc
if (after != null) {
query = new BooleanQuery.Builder()
.add(query, BooleanClause.Occur.MUST)
.add(new SearchAfterSortedDocQuery(searchContext.sort().sort, (FieldDoc) after), BooleanClause.Occur.FILTER)
.build();
}
}
}
}
final LinkedList<QueryCollectorContext> collectors = new LinkedList<>();
// whether the chain contains a collector that filters documents
boolean hasFilterCollector = false;
if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER) {
// add terminate_after before the filter collectors
// it will only be applied on documents accepted by these filter collectors
collectors.add(createEarlyTerminationCollectorContext(searchContext.terminateAfter()));
// this collector can filter documents during the collection
hasFilterCollector = true;
}
if (searchContext.parsedPostFilter() != null) {
// add post filters before aggregations
// it will only be applied to top hits
collectors.add(createFilteredCollectorContext(searcher, searchContext.parsedPostFilter().query()));
// this collector can filter documents during the collection
hasFilterCollector = true;
}
if (searchContext.queryCollectors().isEmpty() == false) {
// plug in additional collectors, like aggregations
collectors.add(createMultiCollectorContext(searchContext.queryCollectors().values()));
}
if (searchContext.minimumScore() != null) {
// apply the minimum score after multi collector so we filter aggs as well
collectors.add(createMinScoreCollectorContext(searchContext.minimumScore()));
// this collector can filter documents during the collection
hasFilterCollector = true;
}
boolean timeoutSet = scrollContext == null && searchContext.timeout() != null &&
searchContext.timeout().equals(SearchService.NO_TIMEOUT) == false;
final Runnable timeoutRunnable;
if (timeoutSet) {
final long startTime = searchContext.getRelativeTimeInMillis();
final long timeout = searchContext.timeout().millis();
final long maxTime = startTime + timeout;
timeoutRunnable = () -> {
final long time = searchContext.getRelativeTimeInMillis();
if (time > maxTime) {
throw new TimeExceededException();
}
};
} else {
timeoutRunnable = null;
}
final Runnable cancellationRunnable;
if (searchContext.lowLevelCancellation()) {
SearchTask task = searchContext.getTask();
cancellationRunnable = () -> { if (task.isCancelled()) throw new TaskCancelledException("cancelled"); };
} else {
cancellationRunnable = null;
}
final Runnable checkCancelled;
if (timeoutRunnable != null && cancellationRunnable != null) {
checkCancelled = () -> {
timeoutRunnable.run();
cancellationRunnable.run();
};
} else if (timeoutRunnable != null) {
checkCancelled = timeoutRunnable;
} else if (cancellationRunnable != null) {
checkCancelled = cancellationRunnable;
} else {
checkCancelled = null;
}
checkCancellationSetter.accept(checkCancelled);
// add cancellable
// this only performs segment-level cancellation, which is cheap and checked regardless of
// searchContext.lowLevelCancellation()
collectors.add(createCancellableCollectorContext(searchContext.getTask()::isCancelled));
final boolean doProfile = searchContext.getProfilers() != null;
// create the top docs collector last when the other collectors are known
final TopDocsCollectorContext topDocsFactory = createTopDocsCollectorContext(searchContext, reader, hasFilterCollector);
// add the top docs collector, the first collector context in the chain
collectors.addFirst(topDocsFactory);
final Collector queryCollector;
if (doProfile) {
InternalProfileCollector profileCollector = QueryCollectorContext.createQueryCollectorWithProfiler(collectors);
searchContext.getProfilers().getCurrentQueryProfiler().setCollector(profileCollector);
queryCollector = profileCollector;
} else {
queryCollector = QueryCollectorContext.createQueryCollector(collectors);
}
try {
searcher.search(query, queryCollector); // 调用lucene api
} catch (EarlyTerminatingCollector.EarlyTerminationException e) {
queryResult.terminatedEarly(true);
} catch (TimeExceededException e) {
assert timeoutSet : "TimeExceededException thrown even though timeout wasn't set";
if (searchContext.request().allowPartialSearchResults() == false) {
// Can't rethrow TimeExceededException because not serializable
throw new QueryPhaseExecutionException(searchContext, "Time exceeded");
}
queryResult.searchTimedOut(true);
} finally {
searchContext.clearReleasables(SearchContext.Lifetime.COLLECTION);
}
if (searchContext.terminateAfter() != SearchContext.DEFAULT_TERMINATE_AFTER
&& queryResult.terminatedEarly() == null) {
queryResult.terminatedEarly(false);
}
final QuerySearchResult result = searchContext.queryResult();
for (QueryCollectorContext ctx : collectors) {
ctx.postProcess(result);
}
ExecutorService executor = searchContext.indexShard().getThreadPool().executor(ThreadPool.Names.SEARCH);
if (executor instanceof QueueResizingEsThreadPoolExecutor) {
QueueResizingEsThreadPoolExecutor rExecutor = (QueueResizingEsThreadPoolExecutor) executor;
queryResult.nodeQueueSize(rExecutor.getCurrentQueueSize());
queryResult.serviceTimeEWMA((long) rExecutor.getTaskExecutionEWMA());
}
if (searchContext.getProfilers() != null) {
ProfileShardResult shardResults = SearchProfileShardResults.buildShardResults(searchContext.getProfilers());
result.profileResults(shardResults);
}
return topDocsFactory.shouldRescore();
} catch (Exception e) {
throw new QueryPhaseExecutionException(searchContext, "Failed to execute main query", e);
}
}至此,节点查询逻辑完成。请求查询的节点对查询结果进行保存
// org.elasticsearch.action.search.AbstractSearchAsyncAction
public final void onShardSuccess(Result result) {
successfulOps.incrementAndGet();
results.consumeResult(result); // 处理查询结果
if (logger.isTraceEnabled()) {
logger.trace("got first-phase result from {}", result != null ? result.getSearchShardTarget() : null);
}
// clean a previous error on this shard group (note, this code will be serialized on the same shardIndex value level
// so its ok concurrency wise to miss potentially the shard failures being created because of another failure
// in the #addShardFailure, because by definition, it will happen on *another* shardIndex
AtomicArray<ShardSearchFailure> shardFailures = this.shardFailures.get();
if (shardFailures != null) {
shardFailures.set(result.getShardIndex(), null);
}
}// org.elasticsearch.action.search.InitialSearchPhase
void consumeResult(Result result) {
assert results.get(result.getShardIndex()) == null : "shardIndex: " + result.getShardIndex() + " is already set";
results.set(result.getShardIndex(), result); // 处理查询结果
}下一步是fetch阶段
// org.elasticsearch.action.search.FetchSearchPhase
private void innerRun() throws IOException {
final int numShards = context.getNumShards();
final boolean isScrollSearch = context.getRequest().scroll() != null;
List<SearchPhaseResult> phaseResults = queryResults.asList();
String scrollId = isScrollSearch ? TransportSearchHelper.buildScrollId(queryResults) : null;
final SearchPhaseController.ReducedQueryPhase reducedQueryPhase = resultConsumer.reduce(); // 解析上一步的查询结果,主要是文档id
final boolean queryAndFetchOptimization = queryResults.length() == 1;
final Runnable finishPhase = ()
-> moveToNextPhase(searchPhaseController, scrollId, reducedQueryPhase, queryAndFetchOptimization ?
queryResults : fetchResults);
if (queryAndFetchOptimization) {
assert phaseResults.isEmpty() || phaseResults.get(0).fetchResult() != null : "phaseResults empty [" + phaseResults.isEmpty()
+ "], single result: " + phaseResults.get(0).fetchResult();
// query AND fetch optimization
finishPhase.run();
} else {
ScoreDoc[] scoreDocs = reducedQueryPhase.sortedTopDocs.scoreDocs;
final IntArrayList[] docIdsToLoad = searchPhaseController.fillDocIdsToLoad(numShards, scoreDocs); // fetch哪些文档
if (scoreDocs.length == 0) { // no docs to fetch -- sidestep everything and return
phaseResults.stream()
.map(SearchPhaseResult::queryResult)
.forEach(this::releaseIrrelevantSearchContext); // we have to release contexts here to free up resources
finishPhase.run();
} else {
final ScoreDoc[] lastEmittedDocPerShard = isScrollSearch ?
searchPhaseController.getLastEmittedDocPerShard(reducedQueryPhase, numShards)
: null;
final CountedCollector<FetchSearchResult> counter = new CountedCollector<>(r -> fetchResults.set(r.getShardIndex(), r),
docIdsToLoad.length, // we count down every shard in the result no matter if we got any results or not
finishPhase, context);
for (int i = 0; i < docIdsToLoad.length; i++) {
IntArrayList entry = docIdsToLoad[i];
SearchPhaseResult queryResult = queryResults.get(i);
if (entry == null) { // no results for this shard ID
if (queryResult != null) {
// if we got some hits from this shard we have to release the context there
// we do this as we go since it will free up resources and passing on the request on the
// transport layer is cheap.
releaseIrrelevantSearchContext(queryResult.queryResult());
}
// in any case we count down this result since we don't talk to this shard anymore
counter.countDown();
} else {
SearchShardTarget searchShardTarget = queryResult.getSearchShardTarget();
Transport.Connection connection = context.getConnection(searchShardTarget.getClusterAlias(),
searchShardTarget.getNodeId());
ShardFetchSearchRequest fetchSearchRequest = createFetchRequest(queryResult.queryResult().getRequestId(), i, entry,
lastEmittedDocPerShard, searchShardTarget.getOriginalIndices());
executeFetch(i, searchShardTarget, counter, fetchSearchRequest, queryResult.queryResult(),
connection); // 去fetch文档内容
}
}
}
}最后收集结果返回:
// org.elasticsearch.action.search.AbstractSearchAsyncAction
protected final SearchResponse buildSearchResponse(InternalSearchResponse internalSearchResponse, String scrollId) {
ShardSearchFailure[] failures = buildShardFailures();
Boolean allowPartialResults = request.allowPartialSearchResults();
assert allowPartialResults != null : "SearchRequest missing setting for allowPartialSearchResults";
if (allowPartialResults == false && failures.length > 0){
raisePhaseFailure(new SearchPhaseExecutionException("", "Shard failures", null, failures));
}
return new SearchResponse(internalSearchResponse, scrollId, getNumShards(), successfulOps.get(),
skippedOps.get(), buildTookInMillis(), failures, clusters);
}3.elasticsearch中的回调
es中大量使用listener回调,对于习惯了顺序逻辑的同学可能会不太适应,这里举例说明
可以看到doExecute方法定义了一个很长的rewriteListener,然后在Rewriteable中进行回调。
注意到doExecute 方法参数里面也有一个listener,调用 executeLocalSearch 后也会进行回调。有些回调可能有多层,需要层层往上递归。
// org.elasticsearch.action.search.TransportSearchAction
protected void doExecute(Task task, SearchRequest searchRequest, ActionListener<SearchResponse> listener) {
final long relativeStartNanos = System.nanoTime();
final SearchTimeProvider timeProvider =
new SearchTimeProvider(searchRequest.getOrCreateAbsoluteStartMillis(), relativeStartNanos, System::nanoTime);
ActionListener<SearchSourceBuilder> rewriteListener = ActionListener.wrap(source -> { // 1.先定义listener
if (source != searchRequest.source()) {
// only set it if it changed - we don't allow null values to be set but it might be already null. this way we catch
// situations when source is rewritten to null due to a bug
searchRequest.source(source);
}
final ClusterState clusterState = clusterService.state();
final Map<String, OriginalIndices> remoteClusterIndices = remoteClusterService.groupIndices(searchRequest.indicesOptions(),
searchRequest.indices(), idx -> indexNameExpressionResolver.hasIndexOrAlias(idx, clusterState));
OriginalIndices localIndices = remoteClusterIndices.remove(RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY);
if (remoteClusterIndices.isEmpty()) {
executeLocalSearch(task, timeProvider, searchRequest, localIndices, clusterState, listener); // 查询当前节点
} else {
if (shouldMinimizeRoundtrips(searchRequest)) { // 使用了折叠
ccsRemoteReduce(searchRequest, localIndices, remoteClusterIndices, timeProvider, searchService::createReduceContext,
remoteClusterService, threadPool, listener,
(r, l) -> executeLocalSearch(task, timeProvider, r, localIndices, clusterState, l));
} else {
AtomicInteger skippedClusters = new AtomicInteger(0);
collectSearchShards(searchRequest.indicesOptions(), searchRequest.preference(), searchRequest.routing(),
skippedClusters, remoteClusterIndices, remoteClusterService, threadPool,
ActionListener.wrap(
searchShardsResponses -> {
List<SearchShardIterator> remoteShardIterators = new ArrayList<>();
Map<String, AliasFilter> remoteAliasFilters = new HashMap<>();
BiFunction<String, String, DiscoveryNode> clusterNodeLookup = processRemoteShards(
searchShardsResponses, remoteClusterIndices, remoteShardIterators, remoteAliasFilters);
int localClusters = localIndices == null ? 0 : 1;
int totalClusters = remoteClusterIndices.size() + localClusters;
int successfulClusters = searchShardsResponses.size() + localClusters;
executeSearch((SearchTask) task, timeProvider, searchRequest, localIndices,
remoteShardIterators, clusterNodeLookup, clusterState, remoteAliasFilters, listener,
new SearchResponse.Clusters(totalClusters, successfulClusters, skippedClusters.get()));
},
listener::onFailure));
}
}
}, listener::onFailure);
if (searchRequest.source() == null) {
rewriteListener.onResponse(searchRequest.source());
} else {
Rewriteable.rewriteAndFetch(searchRequest.source(), searchService.getRewriteContext(timeProvider::getAbsoluteStartMillis),
rewriteListener); // 2. rewriteAndFetch
}
}// org.elasticsearch.index.query.Rewriteable
static <T extends Rewriteable<T>> void rewriteAndFetch(T original, QueryRewriteContext context, ActionListener<T>
rewriteResponse, int iteration) {
T builder = original;
try {
for (T rewrittenBuilder = builder.rewrite(context); rewrittenBuilder != builder;
rewrittenBuilder = builder.rewrite(context)) {
builder = rewrittenBuilder;
if (iteration++ >= MAX_REWRITE_ROUNDS) {
// this is some protection against user provided queries if they don't obey the contract of rewrite we allow 16 rounds
// and then we fail to prevent infinite loops
throw new IllegalStateException("too many rewrite rounds, rewriteable might return new objects even if they are not " +
"rewritten");
}
if (context.hasAsyncActions()) {
T finalBuilder = builder;
final int currentIterationNumber = iteration;
context.executeAsyncActions(ActionListener.wrap(n -> rewriteAndFetch(finalBuilder, context, rewriteResponse,
currentIterationNumber), rewriteResponse::onFailure));
return;
}
}
rewriteResponse.onResponse(builder); // 3. 回调 rewriteListener
} catch (IOException|IllegalArgumentException|ParsingException ex) {
rewriteResponse.onFailure(ex);
}
}4.总结
本文简单描述了es是如何进行文档查询的,es会先去各个分片上获取符合查询条件的文档id等信息,然后再fetch文档内容。本文没有涉及dfs,后面博客会继续探讨这些课题。