总体有两个方向:模型优化 / 框架优化
1. 模型优化
1.1 量化
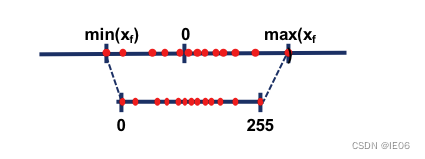
最常见的量化方法为线性量化,权重从float32量化为int8,将输入数据映射在[-128,127]的范围内。在 nvdia gpu,x86、arm 和 部分 AI 芯片平台上,均支持 8bit 的计算。
当然还有简单的二值化。对比从 nvdia gpu 到 x86 平台,1bit 计算分别有 5 到128倍的理论性能提升。
此外还有对数量化,一种比较特殊的量化方法。两个同底的幂指数进行相乘,那么等价于其指数相加。目前 nvdia gpu,x86、arm 三大平台上没有实现对数量化的加速库,但是目前已知海思 351X 系列芯片上使用了对数量化。
根据量化的粒度(共享量化参数的范围)可以分为逐层量化、逐组量化和逐通道量化。TensorRT 框架中就使用了逐层量化的方法,每一层采用同一个阈值来进行量化。
权重量化完后,我们还要对激活层进行量化,这时需要进行calibration,通过校准数据集来确定激活层的比例因子和偏差。
此外,pytorch还可以进行训练后的动态量化(torch.quantization.quantize_dynamic)和训练时的量化(torch.quantization.FakeQuantize)。
1.2 剪枝
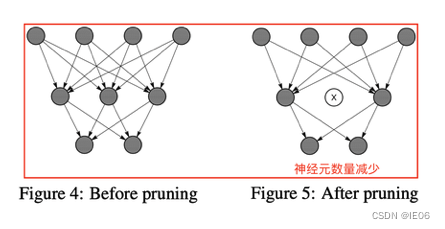
下图是第一种剪枝方法(移除边),非规则的形状对硬件不友好,只能在专用硬件上加速。
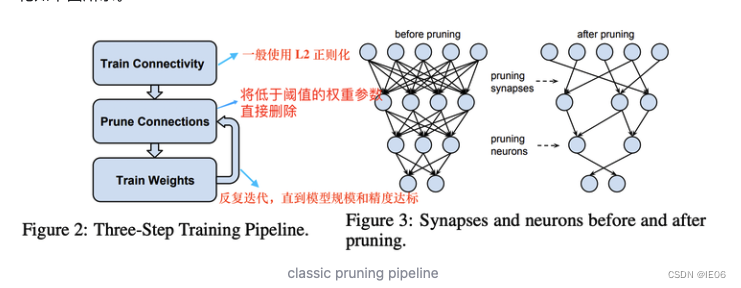
第二种是移除点(找到零神经元)
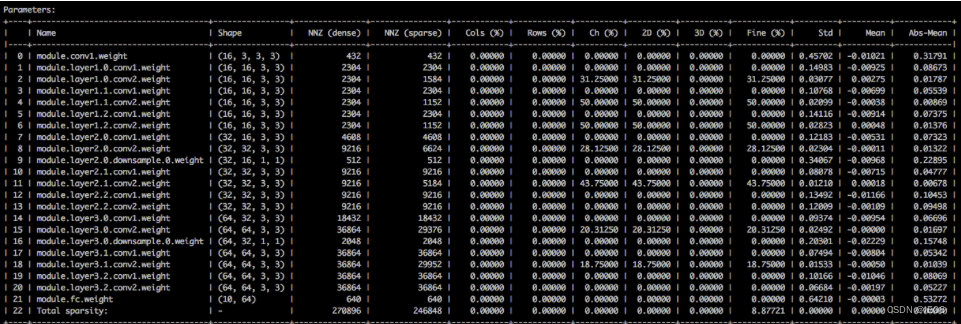
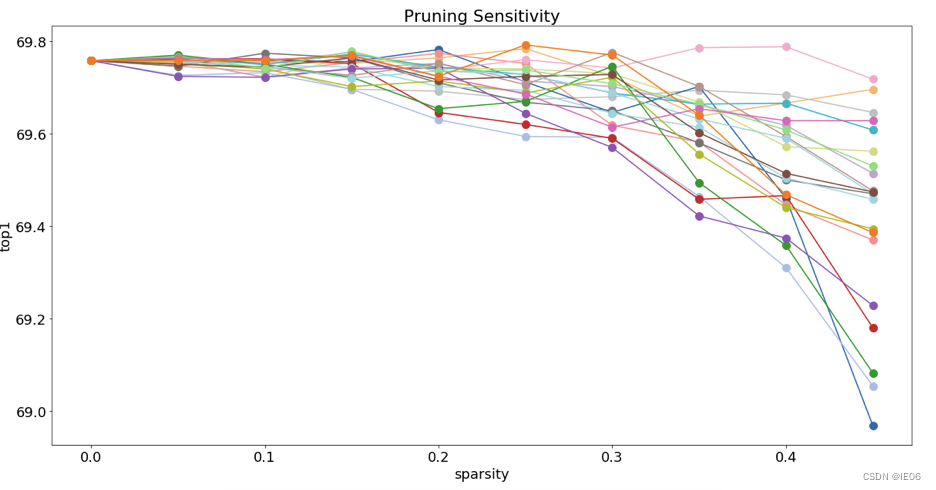
我们可以使用distiller工具来查看模型的稀疏度:
# 显示网络的稀疏度
python3 compress_classifier.py -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
1.3 融合
将一些近邻的层合并成一个层,减少计算量
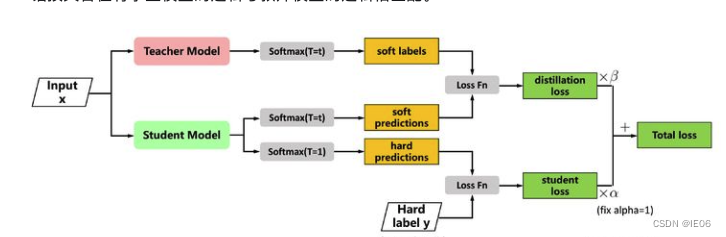
1.4 知识蒸馏
知识蒸馏是一种与模型无关的压缩方法,它从大型、昂贵的教师模型中获取知识,并将其转移到较小的学生模型中。知识蒸馏模型采用软目标来获得比庞大的教师模型更高的准确性和更少的推理时间。
2. 压缩工具
2.1 pocketflow
该工具中所包含的压缩方法主要包括3大类:裁剪、权重稀疏和量化。
# 对网络进行裁剪操作
./scripts/run_seven.sh nets/resnet_at_cifar10_run.py \
--learner channel \
--cp_prune_option uniform \
--cp_uniform_preserve_ratio 0.5
# 对网络进行权重稀疏操作
./scripts/run_local.sh nets/resnet_at_cifar10_run.py \
--learner weight-sparse \
--ws_prune_ratio_prtl uniform \
--data_disk hdfs
# 对网络进行量化操作
./scripts/run_local.sh nets/resnet_at_cifar10_run.py \
--learner uniform \
--uql_use_buckets \
--uql_bucket_type channel \
--data_disk hdfs
2.2 TVM
通过LLCM来支持Intel和ARM CPU等一些设备;通过Opencl来支持ARM的MailGPU;通过CUDA来支持NVIDIA的设备;通过Metal来支持苹果的设备;通过VTA来很好的支持FPGA和ASCI
2.3 openvino/tensorRT
分别是针对intel和nvidia家的硬件,可参考以前的文章。
2.4 手机端加速
MNN/ARMNN/ncnn/TNN等。
2.5 pytorch相关
model-compression以及pytorch自带的压缩工具