笔者从 14 年做开源软件以来,接触了众多 Linux 新手用户,这里我为这类用户总结了一些常见的问题排查方法,希望能帮助到大家。如果你已经工作多年,对于下面提到的思路和方法应该非常熟悉,如果对某一条感到陌生,咳咳,真的不太应该,赶紧补补吧。
1. 软件资料获取
第一条是告诉大家去哪里获取软件文档资料,别笑,很多新手就是不知道去哪里找,一上来就 baidu、google,结果搜到很多不靠谱的资料,浪费了很多时间。
- 官网:首先你得知道软件官网在哪里,一切都从这里开始。文档、下载地址,通常都在官网有入口
- Github:如果软件是开源的,那么它的源码通常在 Github 上,你可以在 Github 上找到软件的源码、历史问题、历史版本等资料,以 Nightingale 项目举例,其 Github 截图以及相关信息如下:
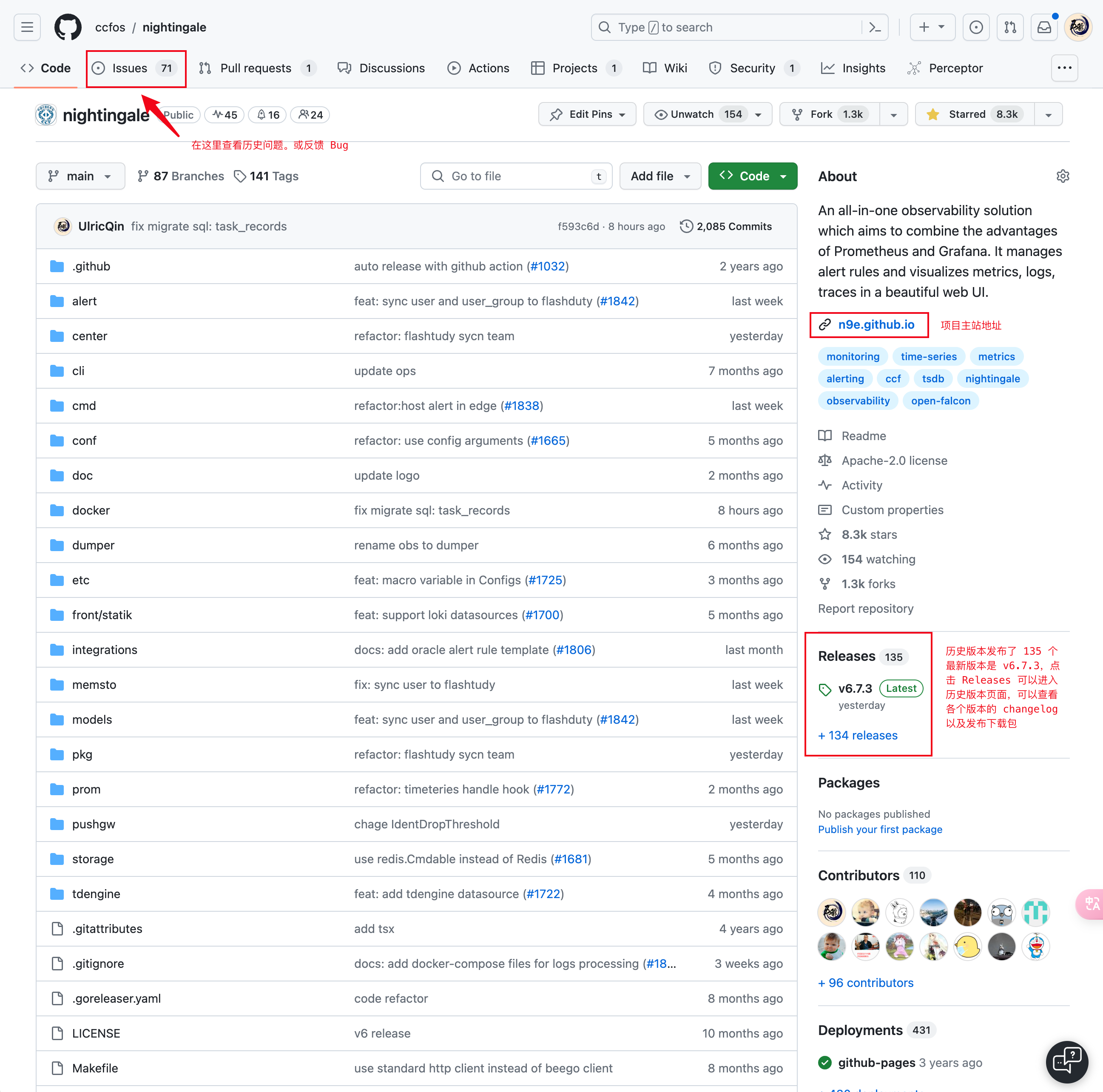
这个页面继续往下滚动,可以看到 README,开源项目的 README 的每一行信息都值得读一下,很多人 README 都不读就敢用也是非常头铁。
2. 软件安装相关
首先,一定要严格按照文档建议去操作,如果遇到问题,下面这些小 tips 或许能够帮到你。
2.1 检查进程
ps -ef | grep prometheus
首先要确认进程是否启动,可以使用 ps 命令查看,grep 后面的 prometheus 表示二进制文件名,这里 prometheus 只是举例,你要换成你自己的二进制文件名。
2.2 检查端口
ss -tlnp | grep 9090
有的时候进程虽然在,但是端口没有在监听,也不正常,比如 Prometheus 默认监听在 9090 端口,通过上面的 ss 命令可以查看 9090 端口是否在正常监听。
2.2 检查 CPU 架构
有的机器是 x86 的,有的是 arm 的,检查你是否下载错了。通过下面的命令可以查看本机的 CPU 架构:
uname -m
如果输出是 x86_64 就要下载 amd64 的包,如果是 aarch64 就要下载 arm 的包。
2.3 检查版本
大部分软件都会提供查看版本的方式,比如 cprobe:
ulric@ulric-flashcat cprobe % ./cprobe -version
0.0.1-2024-01-25-17-44-37
如果不知道如何查看版本,可以使用 --help 参数,基本所有的软件都会提供 --help 参数来查看帮助信息,比如:
./cprobe --help
这个 help 信息非常非常关键,即便刚开始不能全部阅读,也要大体看一眼软件提供了哪些命令行参数。
2.4 检查配置文件
大部分软件都会提供配置文件,下载包里通常会有一个默认配置,在改动之前一定要先备份一下,改动之后,如何确认改动了哪些部分?可以使用 diff 或 vimdiff 命令来对比一下,比如:
vimdiff config.toml config.toml.bak
假设 config.toml 是改过的配置文件,config.toml.bak 是原始配置文件,通过 vimdiff 查看:

很明显能看到 config.toml 改动了端口,原来是 9090,改成了 19090,非常方便。你要检查配置文件的改动是否符合预期,别多了字符少了字符啥的,以及缩进是否正确,yaml 配置对缩进就非常敏感。通过两次 :q + 回车 可以退出 vimdiff。
2.5 检查日志
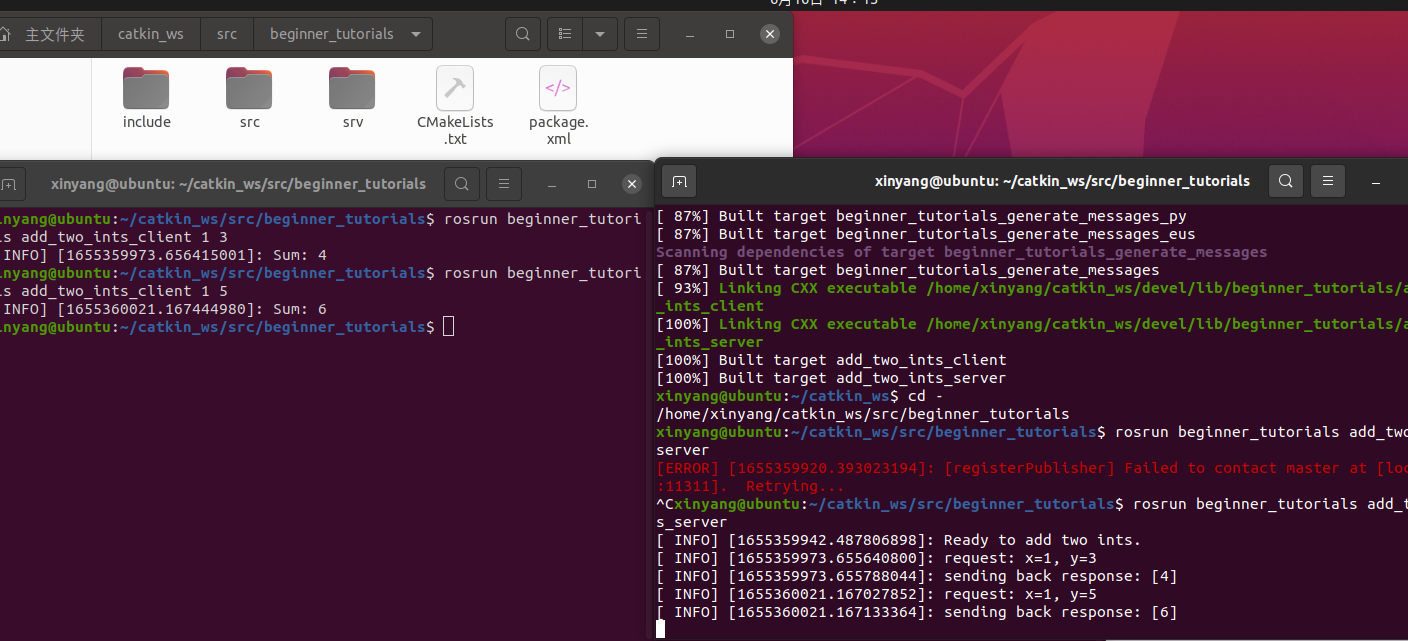
出问题看日志是基本素养。软件如果启动不起来,通常会在控制台直接打印日志。比如 Nightingale,你这么启动的话出错了就会在控制台直接输出错误消息:
ulric@ulric-flashcat nightingale % ./n9e
runner.cwd: /Users/ulric/works/gopath/src/nightingale
runner.hostname: ulric-flashcat.local
runner.fd_limits: (soft=61440, hard=unlimited)
runner.vm_limits: (soft=unlimited, hard=unlimited)
2024-01-25 17:56:07.392349 DEBUG ormx/ormx.go:58 /Users/ulric/works/gopath/src/nightingale/pkg/ormx/ormx.go:93
[error] failed to initialize database, got error dial tcp 127.0.0.1:3306: connect: connection refused
2024-01-25 17:56:07.392477 DEBUG ormx/ormx.go:68 /Users/ulric/works/gopath/src/nightingale/pkg/ormx/ormx.go:93
[error] failed to initialize database, got error dial tcp 127.0.0.1:3306: connect: connection refused
2024/01/25 17:56:07 main.go:39: failed to initialize: dial tcp 127.0.0.1:3306: connect: connection refused
上面的错误也很典型:connection refused 表示连接被拒绝,通常就是目标端口没有在监听,上面的例子的话,就是 127.0.0.1:3306 没有在监听,即本机的 MySQL 没有在监听。
./n9e 这种启动方式是进程前台启动,有错误会输出在控制台,但是 terminal 关掉,进程就退出了,一般生产环境启动会使用 systemd 来托管,此时,使用下面的命令可以查看 n9e 的进程状态:
systemctl status n9e
通过下面的命令可以查看 n9e 的日志:
journalctl -fu n9e
journalctl 的更多用法,请自行 baidu、google。
如果你不是 systemd 来托管的进程,而是采用 nohup 启动的,比如:
nohup ./n9e &> stdout.log &
显然,标准输出和标准错误输出都重定向到 stdout.log 了,启动不了就查看 stdout.log 即可。当然,进程本身可能会把一些日志写到指定的日志目录,日志目录下的日志也要关注。
如果你的进程启动都起不来,此时就不要用 systemd 或者 nohup 启动了,就直接前台启动测试即可,可以更清楚的查看日志。
3. 软件运行相关
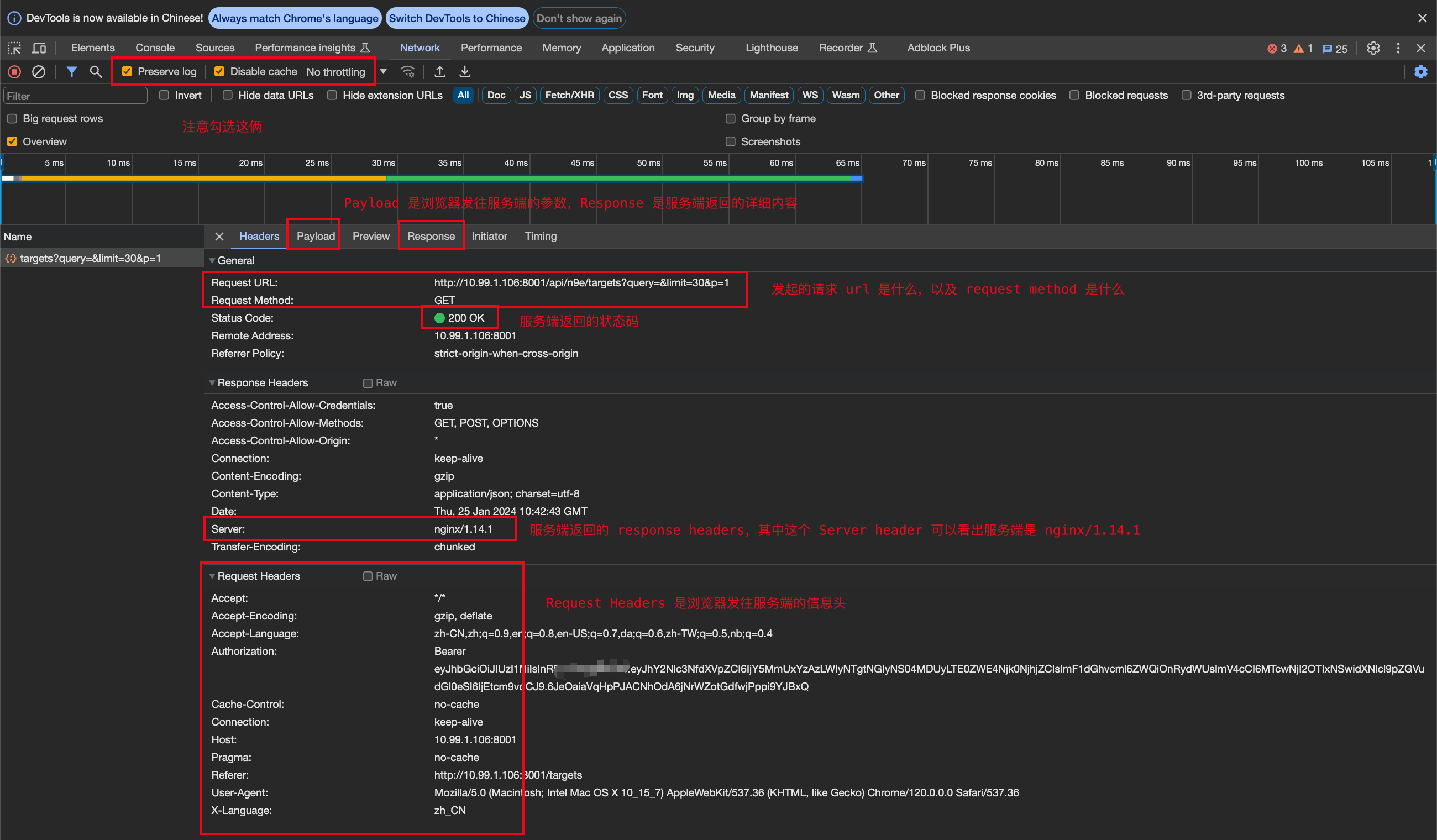
软件正常启动之后,如果又遇到问题,通常就是看页面报错以及运行日志。页面报错是必须要会看的,页面报错之后第一反应应该是打开 Chrome 开发者工具,切到 Network Tab,勾选 Preserve log 和 Disable cache,重新操作一遍页面功能,看看到底是向后端发了啥请求,哪些请求报错了,报错的请求具体发出了什么 request,返回了什么 response。
另外,在请求上右键,可以选择 Copy -> Copy as cURL,这样就可以把请求复制成 curl 命令,可以在命令行里执行。
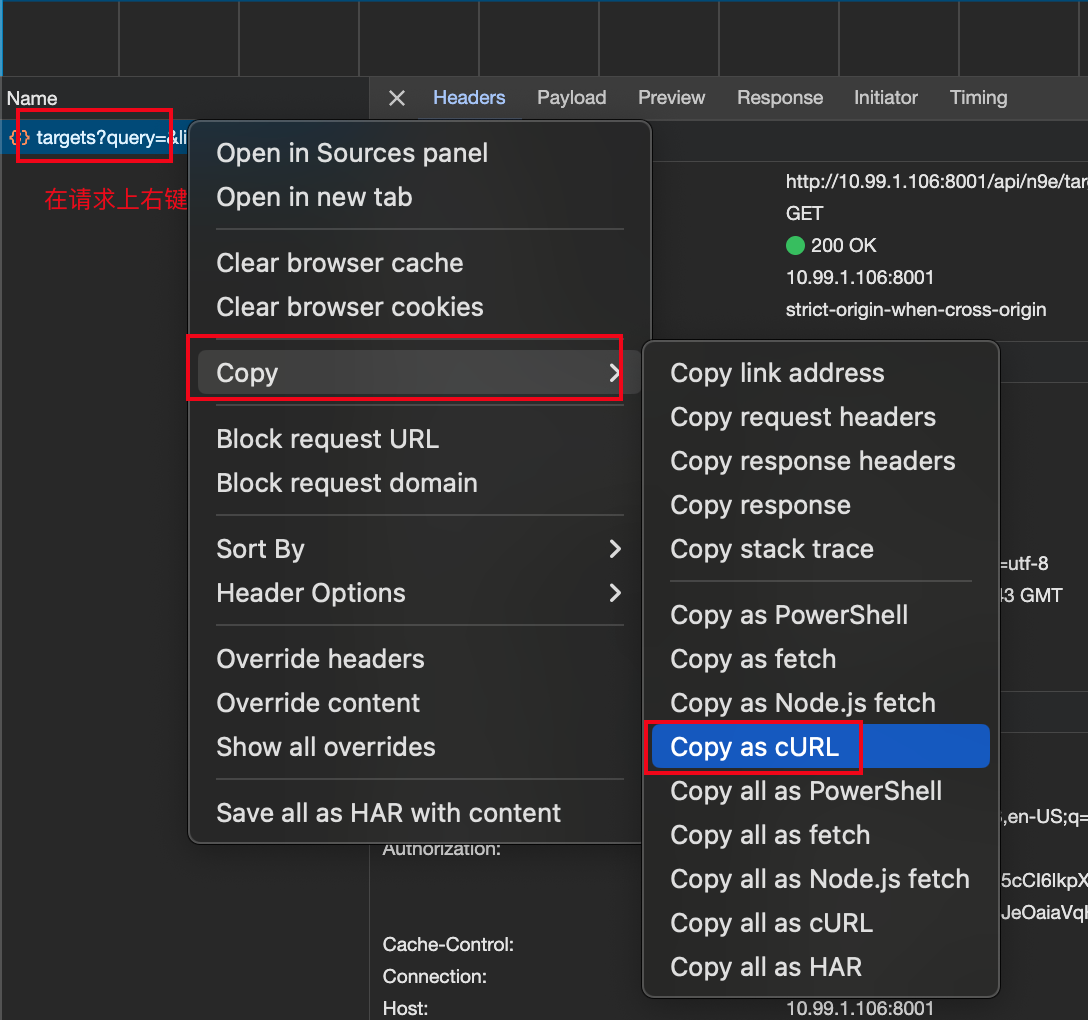
这个功能有何用处呢?有时请求经过了四层负载均衡、七层负载均衡才能最终到达服务端进程,有时我们怀疑是中间某个链路的问题,却没有证据,此时就可以拷贝 curl 这个命令,修改 ip:port 为后端进程的 IP 和端口,然后直接到进程所在机器上执行,看看是否能复现问题,如果能复现,说明是后端进程的问题,如果不能复现,那就是中间某个链路的问题。
如果是后端进程的问题,就要看进程日志了,异常报错通常都会有日志输出。这里就很考验经验了。
比如看到 “Resource temporarily unavailable” 我们就知道是 ulimit 设置不合理。怎么查看进程的 ulimit 呢?找到进程的 pid,查看 /proc/<pid>/limits 文件即可,比如下面的例子,查看 cprobe 进程的 ulimit 限制:
[root@dev-n9e-01 ~]# cat /proc/`pidof cprobe`/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size unlimited unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 30039 30039 processes
Max open files 65536 65536 files
Max locked memory 65536 65536 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 30039 30039 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
如果是 ulimit 限制,那么就要修改 ulimit 了,修改 ulimit 的方式,可以自行 baidu、google。
比如进程请求 MySQL 的时候报错 “Too many connections”,那么就是 MySQL 的连接数限制了,可以通过 show variables like '%max_connections%'; 来查看 MySQL 的连接数限制,默认是 151,可以通过 set global max_connections=1000; 来修改。当然,只用 set 命令修改重启就不生效了,还需要修改 MySQL 的配置文件使其重启也能生效。
当然,常见的问题很多,这里也没法一一举例,通常看到报错之后,要认认真真的读报错,实在弄不明白就 google、gpt,如果还不行,再问同事等其他有经验的人。问题见的越多,技术成长越快。
另外,如果报错并非 Linux 常规报错,是软件业务逻辑的报错,这就需要你弄懂软件的架构和数据流了,然后根据架构和数据流,来猜想、求证,最终定位问题。如果实在搞不定,可以去 github 上提 issue,提 issue 的时候一定要写清楚复现步骤,并写清楚你做了哪些验证,得到了哪些结果,这样别人才好帮你。提问也是一门艺术,建议 google 一下 “raymond 提问的艺术”。
4. 其他杂项问题
时间校准问题。很多分布式软件,特别是监控系统,对时间校准是有严苛要求的,注意校准机器的时间,除了服务端的时间,还要注意校准你的浏览器所在 pc 的时间。
5. 小结
一时半会儿想到这么多,后续想到了再补充。也欢迎大家在留言里补充,相互学习~







![[开源]GPT Boss – 用图形化的方式部署您的私人GPT镜像网站](https://img-blog.csdnimg.cn/direct/b37ea7bc78a447fbb13f3fd305ac5509.png#pic_center)