文章目录
- Django Rest_Framework
- 1. DRF介绍
- 2.DRF特点
- 3.环境安装与配置
- (1)DRF需要以下依赖
- (2)创建django项目
- 4.序列化器的使用
- (1)创建序列化器
- 5. 反序列化器使用
Django Rest_Framework
1. DRF介绍
Django REST framework是一个建立在Django基础之上的Web 应用开发框架,可以快速的开发REST API接口应用,简称DRF。
在REST framework中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,把queryset类型数据自动转化为json等可以传到前端的数据类型
不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。
REST framework还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。
REST framework提供了一个API 的Web可视化界面来方便查看测试接口。
提供了我们写接口便利的方法,把响应的内容,响应的格式,响应状态码都封装好了
不用自己再做这些了,但是能DRF能做的还是有限的,对于复杂的接口还是需要自己来做这些事
restful不是必须的,但是为了后续开发,交接规范,大家约定俗成的使用restful规范

2.DRF特点
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
- 多种身份认证和权限认证方式的支持;[jwt]
- 内置了限流系统;
- 直观的 API web 界面;
- 可扩展性,插件丰富
django restframework(简称drf)本质上其实就是一个别人编写好的app,里面集成了很多编写restful API的功能功能。
其目录中有很多我们以前写django程序见到过的,因为它就是一个别人写好了的app,我们拿来用。
因此 每次新建项目时要记得在settings中注册app。
同时在settings中也要加上如下字典,以后drf相关的全局配置都会在该字典中添加。
3.环境安装与配置
(1)DRF需要以下依赖
- Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6, 3.11)
- Django (1.10, 1.11, 2.0, 4.2.1)
DRF是以Django扩展应用的方式提供的,所以我们可以直接利用已有的Django环境而无需从新创建。(若没有Django环境,需要先创建环境安装Django)
安装DRF,这是linux安装
前提是已经安装了django,建议安装在虚拟环境
#mkvirtualenv drfdemo -p python3
#pip install django
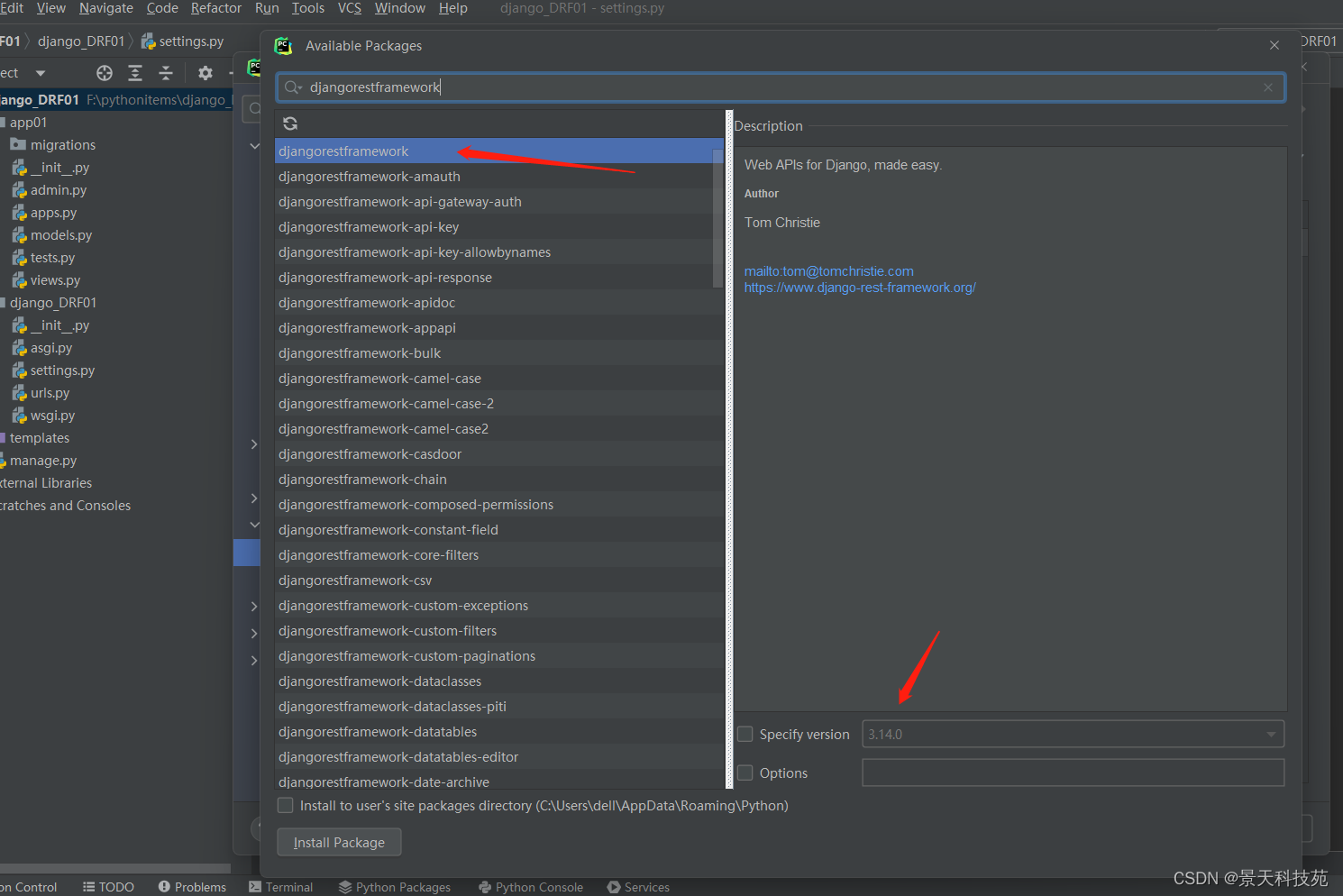
pip install djangorestframework
Windows就在本地环境中安装
(2)创建django项目
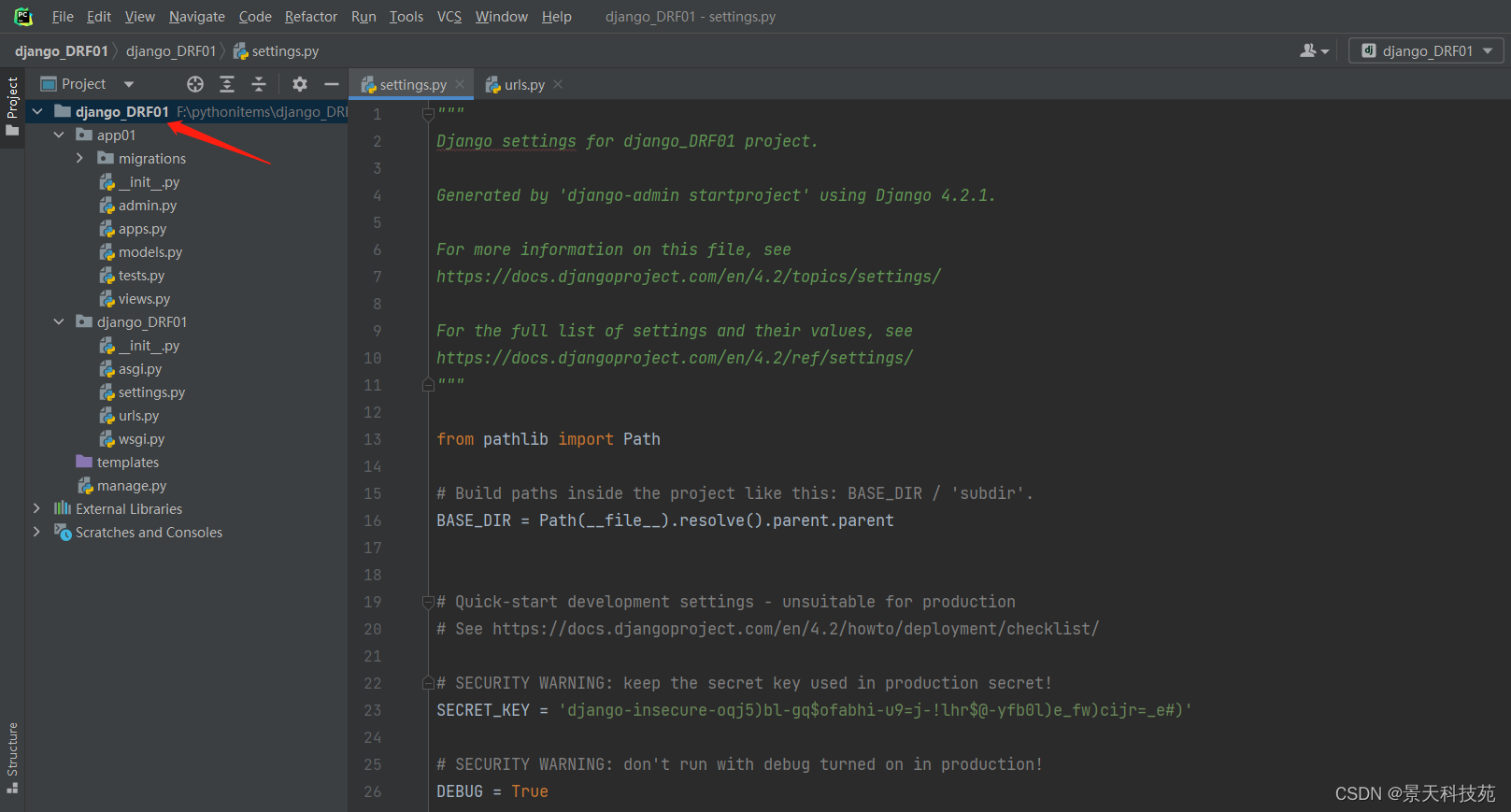
添加rest_framework应用,pycharm创建的项目,默认会把第一个创建的应用添加进去
在settings.py的INSTALLED_APPS中添加’rest_framework’。
需要手动将rest_framework 添加到INSTALLED_APPS 中,这个一定要手动添加,不然用不了drf功能
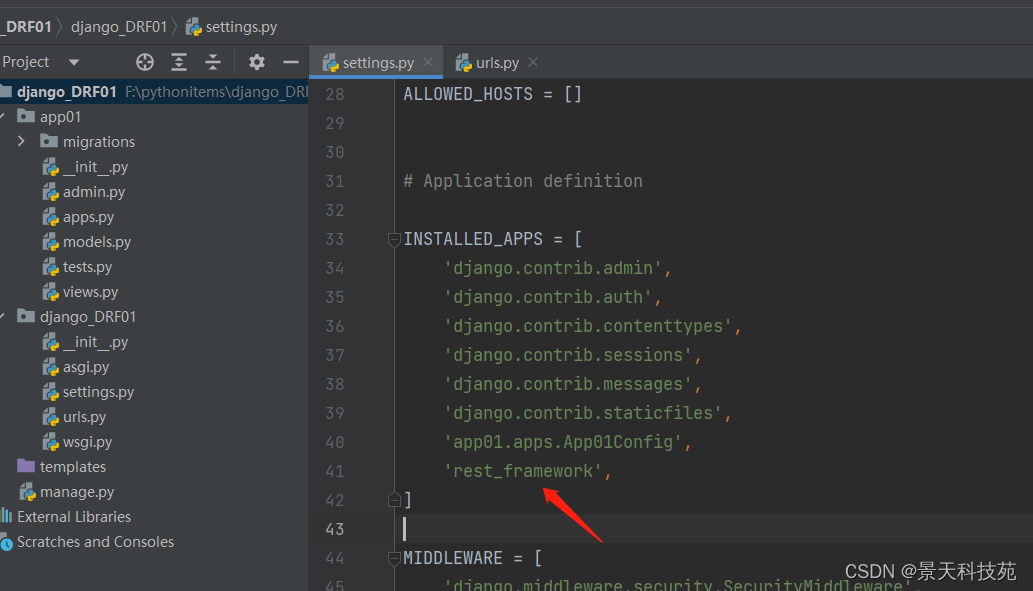
接下来就可以使用DRF提供的功能进行api接口开发了。在项目中如果使用rest_framework框架实现API接口,主要有以下三个步骤:
- 将请求的数据(如JSON格式)转换为模型类对象
- 操作数据库
- 将模型类对象转换为响应的数据(如JSON格式)
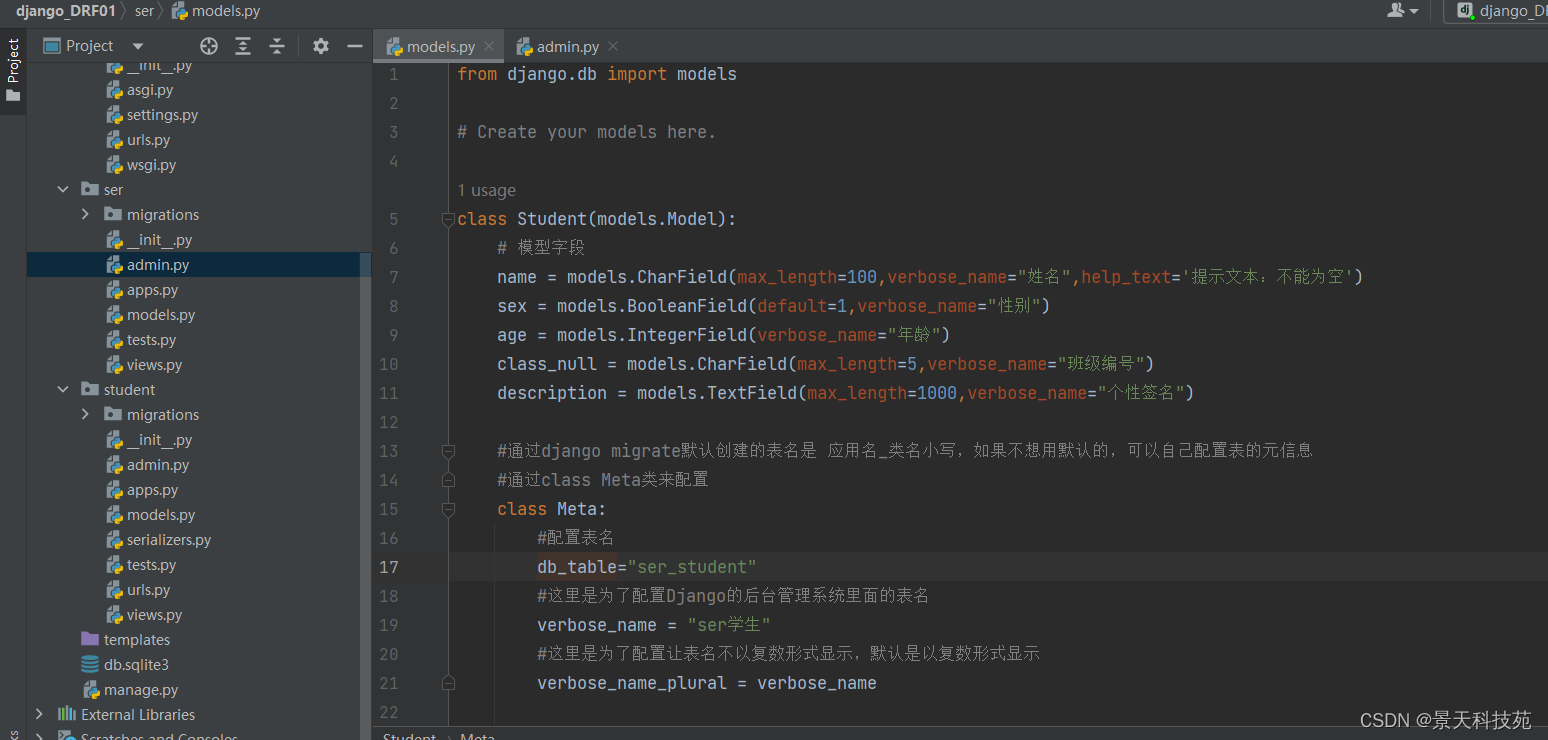
创建模型操作类
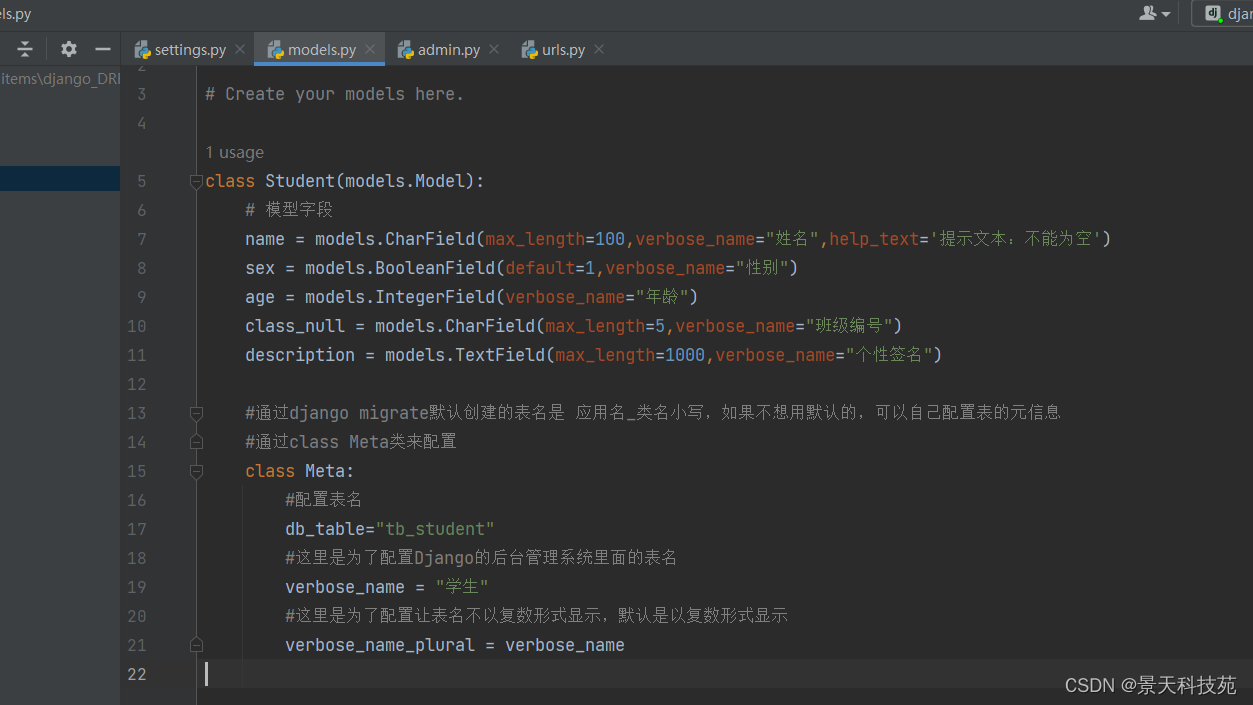
class Student(models.Model):
# 模型字段
name = models.CharField(max_length=100,verbose_name="姓名",help_text='提示文本:不能为空')
sex = models.BooleanField(default=1,verbose_name="性别")
age = models.IntegerField(verbose_name="年龄")
class_null = models.CharField(max_length=5,verbose_name="班级编号")
description = models.TextField(max_length=1000,verbose_name="个性签名")
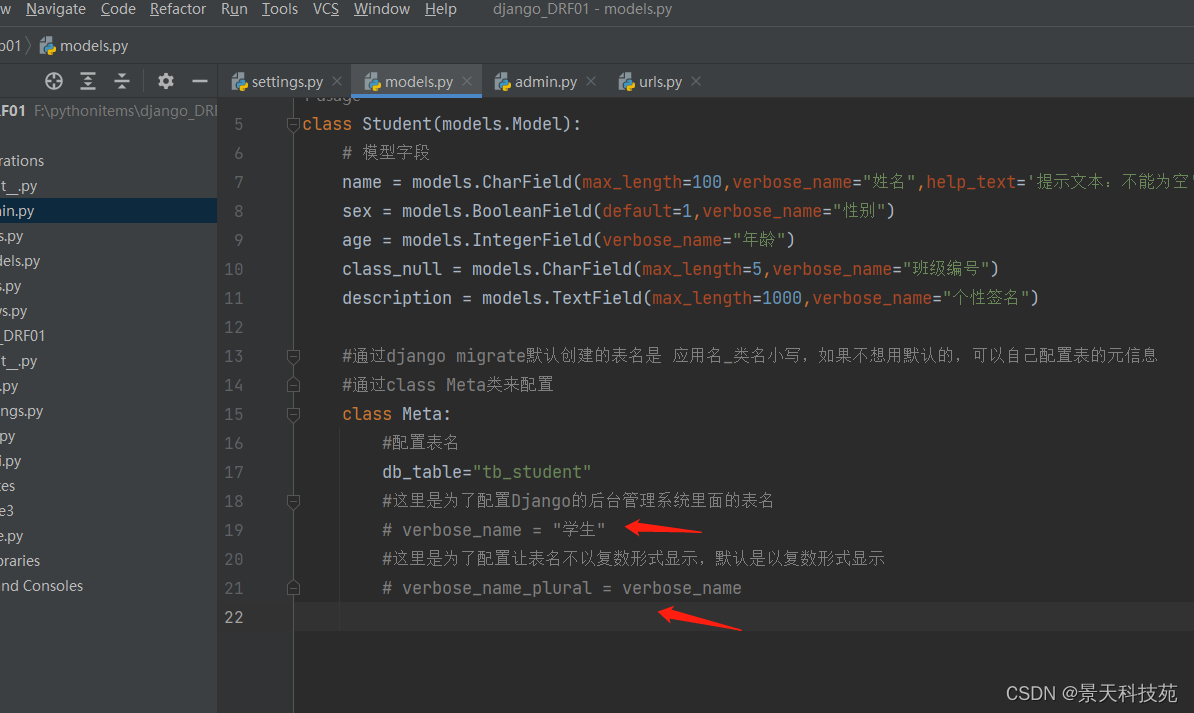
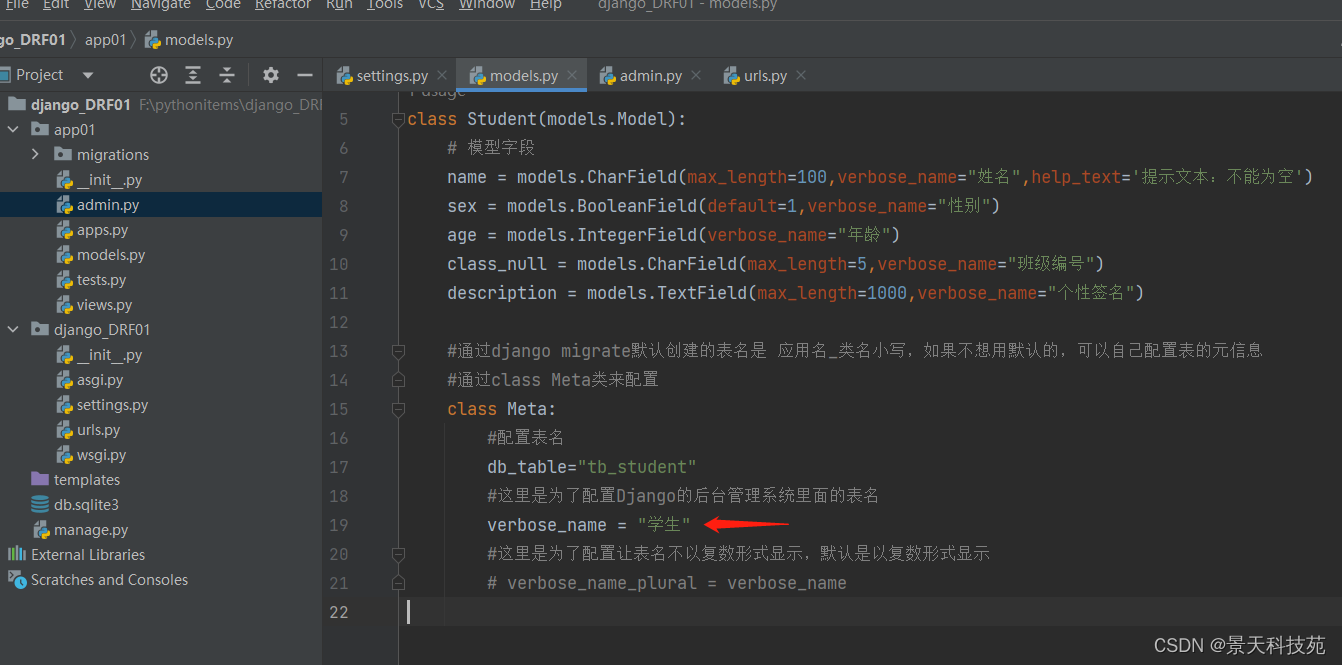
#通过django migrate默认创建的表名是 应用名_类名小写,如果不想用默认的,可以自己配置表的元信息
#通过class Meta类来配置
class Meta:
#配置表名
db_table="tb_student"
#这里是为了配置Django的后台管理系统admin里面的表名
verbose_name = "学生"
#这里是为了配置让表名不以复数形式显示,默认是以复数形式显示
verbose_name_plural = verbose_name
我们看urls.py有个admin路径
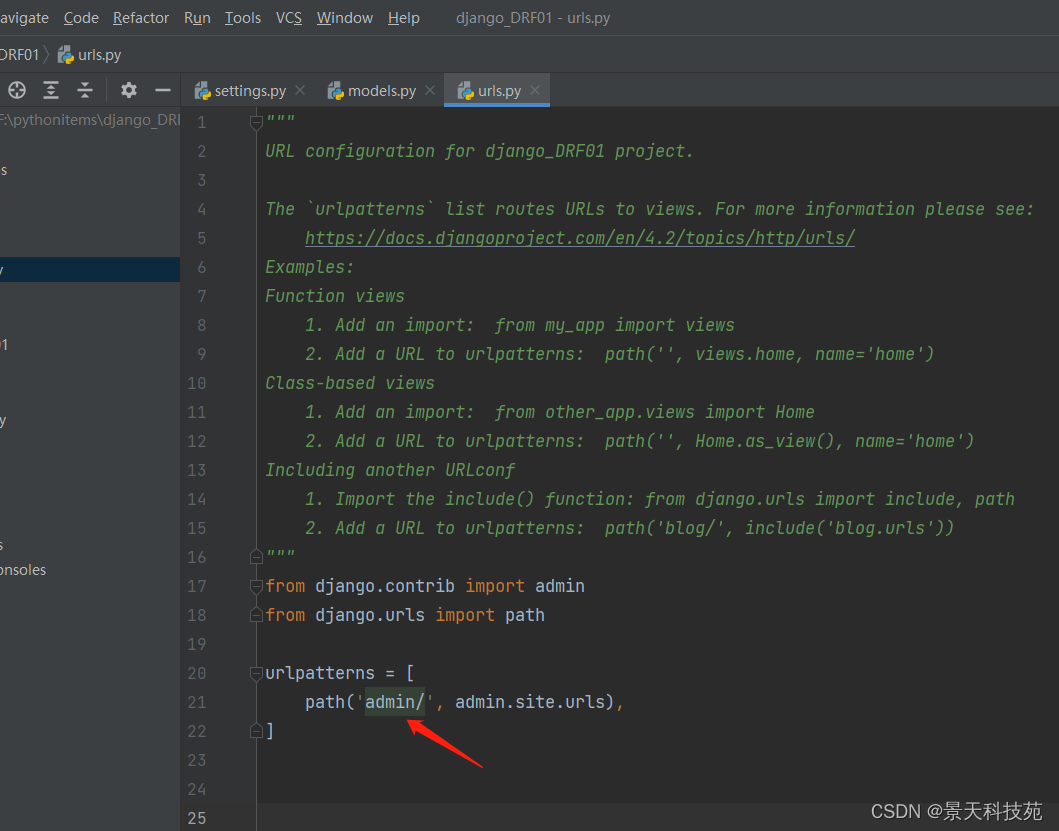
当我们运行项目时,Django默认带个后台管理系统,需要先执行数据库同步指令
运行项目,登录后台管理系统
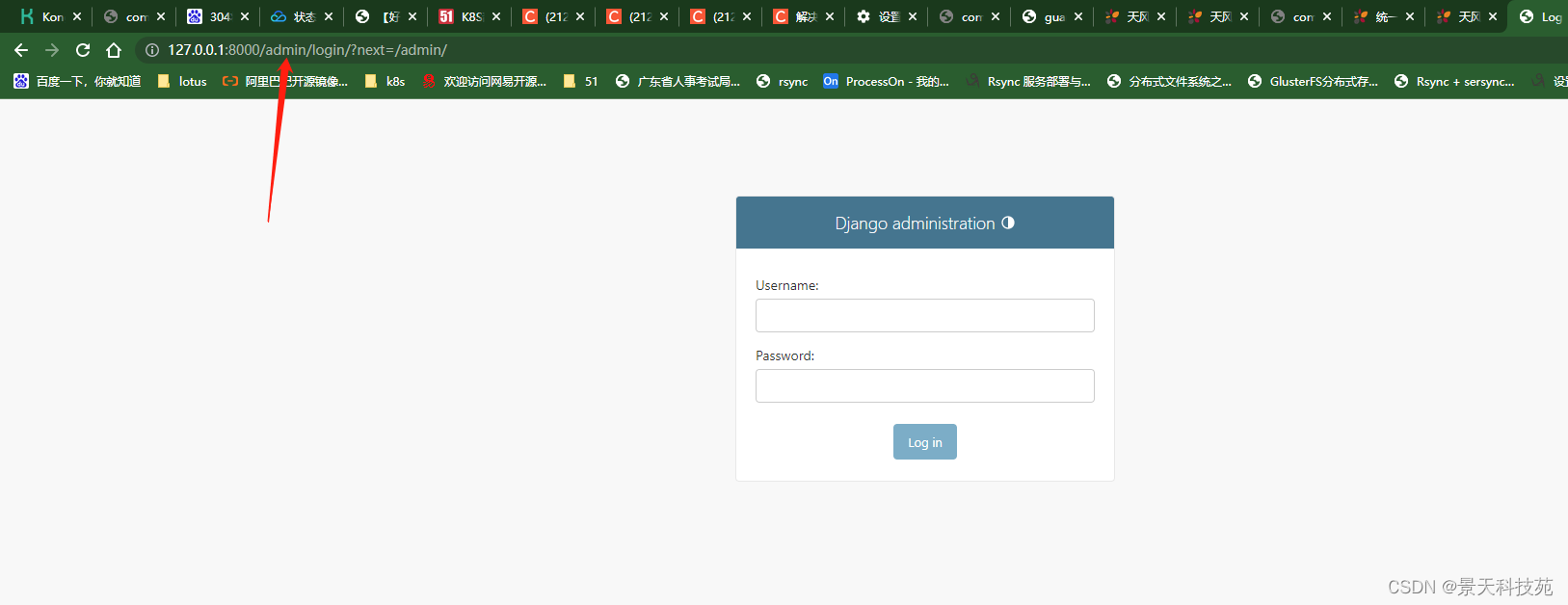
需要用户名,密码,初次登录需要我们创建超级管理员用户
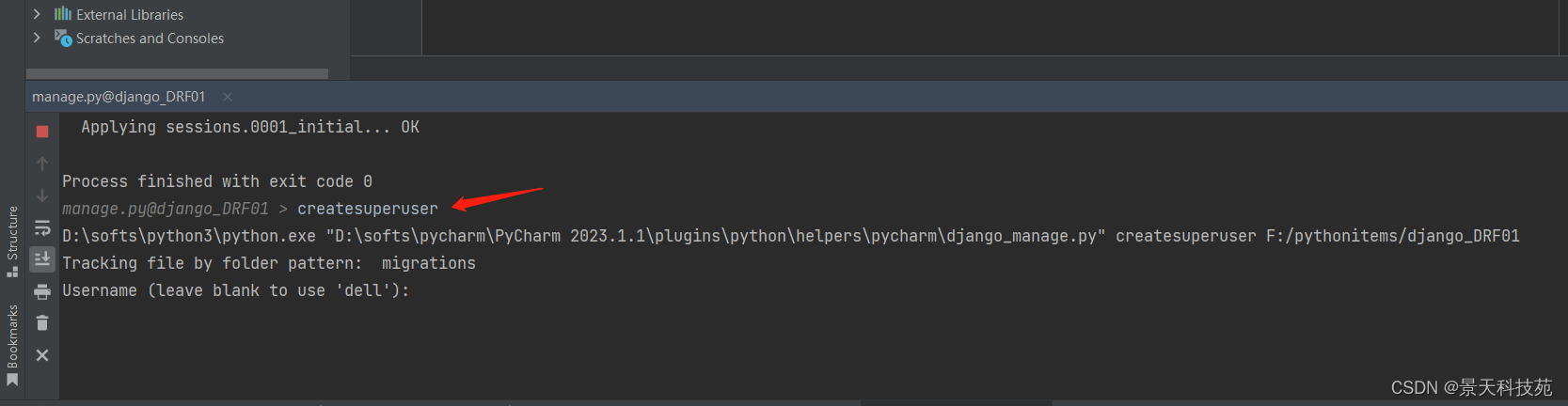
控制台 python manager.py createsuperuser
按照提示输入,邮箱可以不用输入
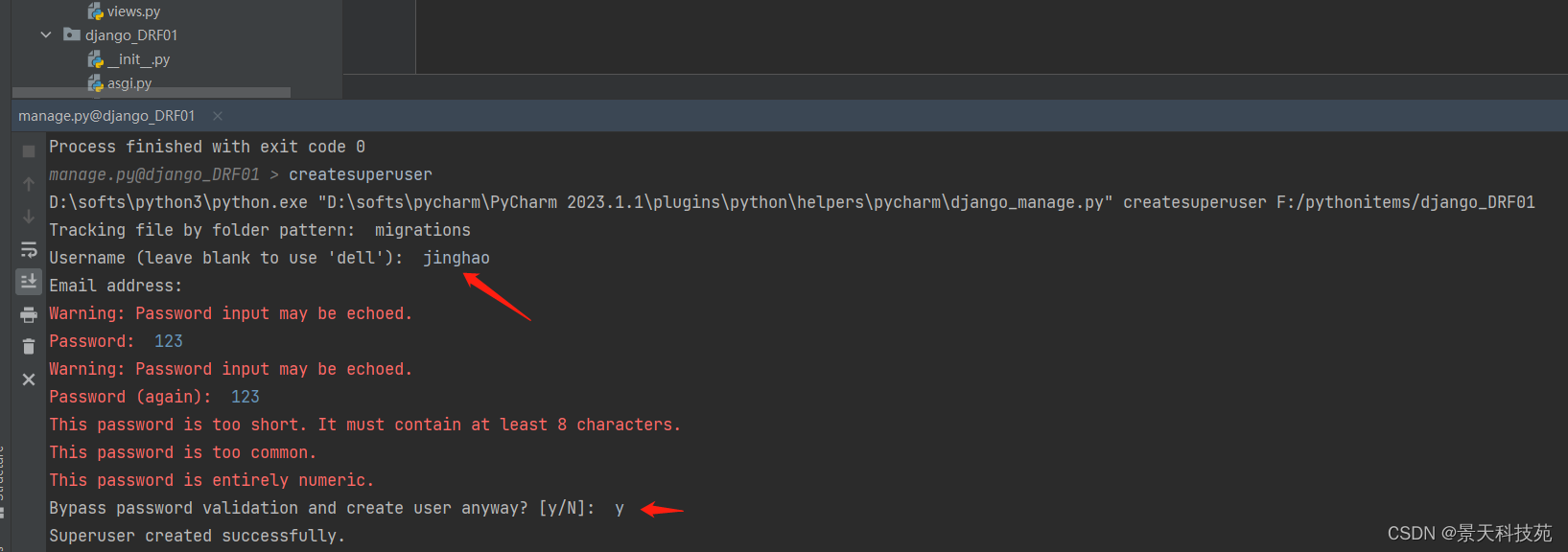
输入用户名,密码登录
这里面有两张系统自带的表,生产中一般不用admin,由于admin功能太过简单,不符合生产要求
如果想用一个不错的后台管理系统,可以用xadmin
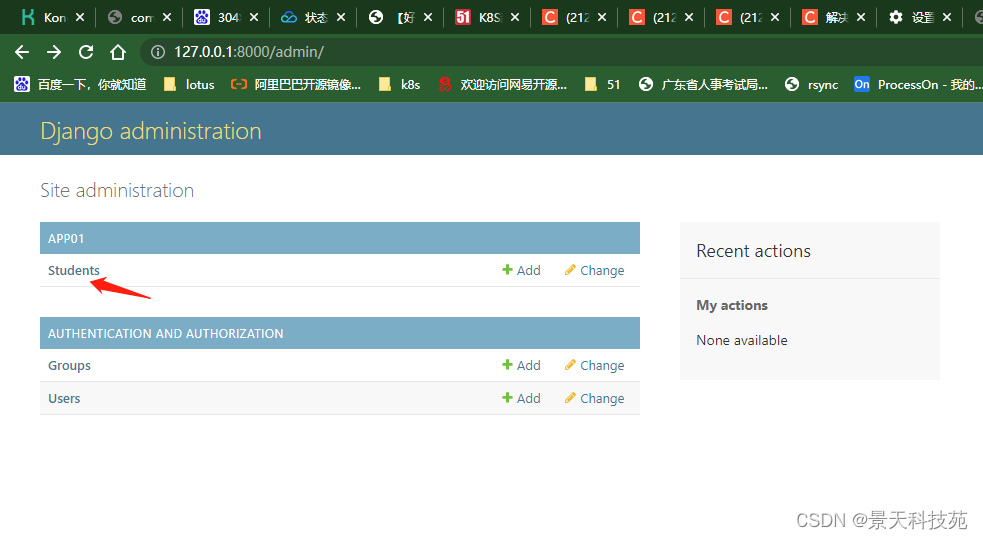
admin和xadmin是用来对数据库中的表进行管理的,项目中可能会写很多表。admin和xadmin就可以展示所有的表,以及表中数据
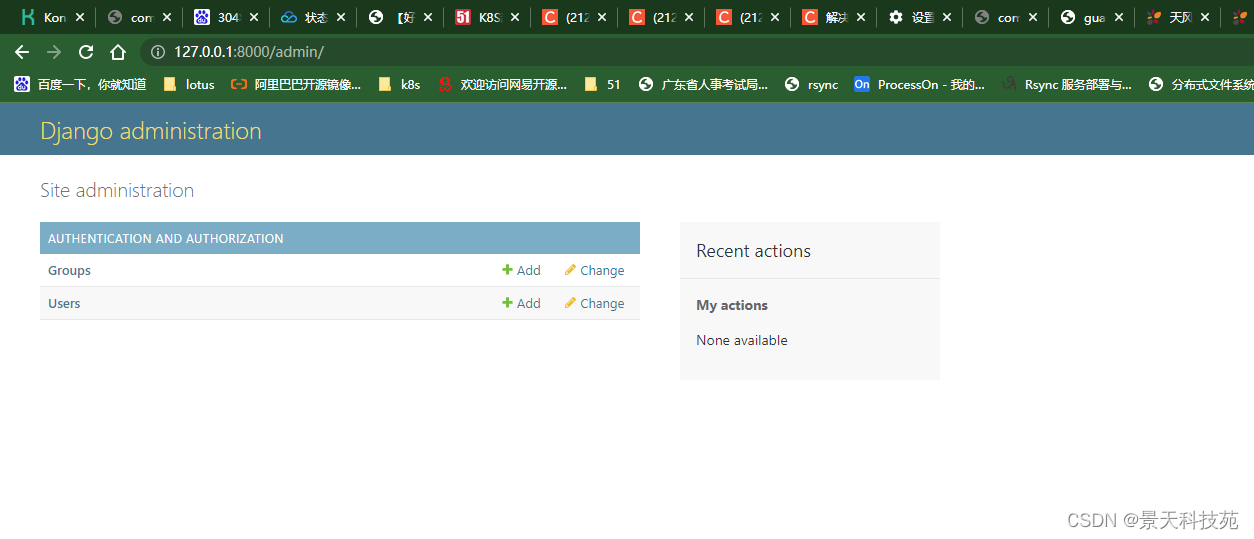
比如我们希望通过admin来管理模型类中的表
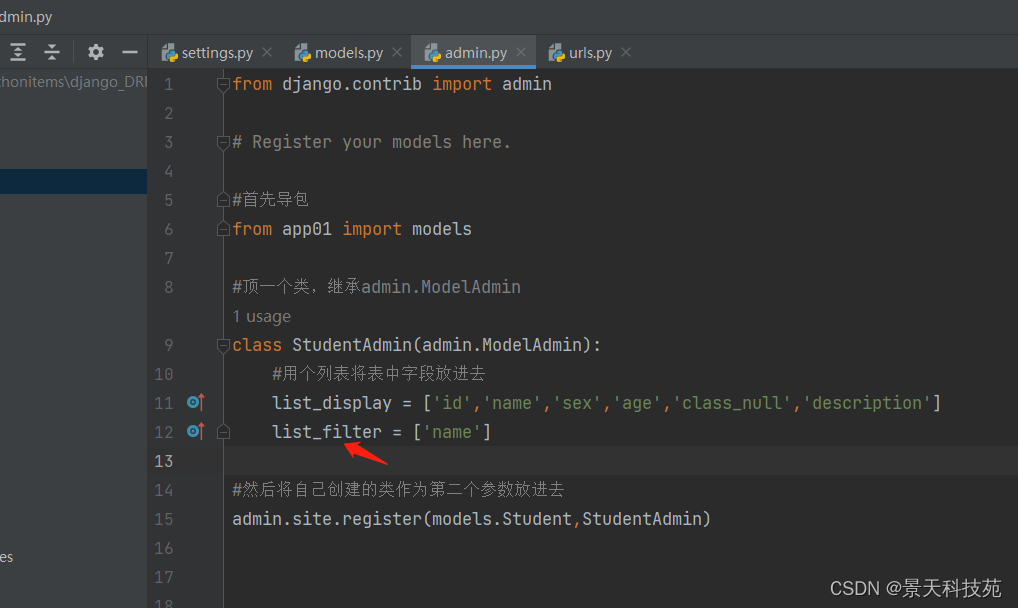
创建完,需要我们将models类里面的表注册到admin里面管理
在我们创建的应用下有个admin.py,专门用于admin后台管理系统的
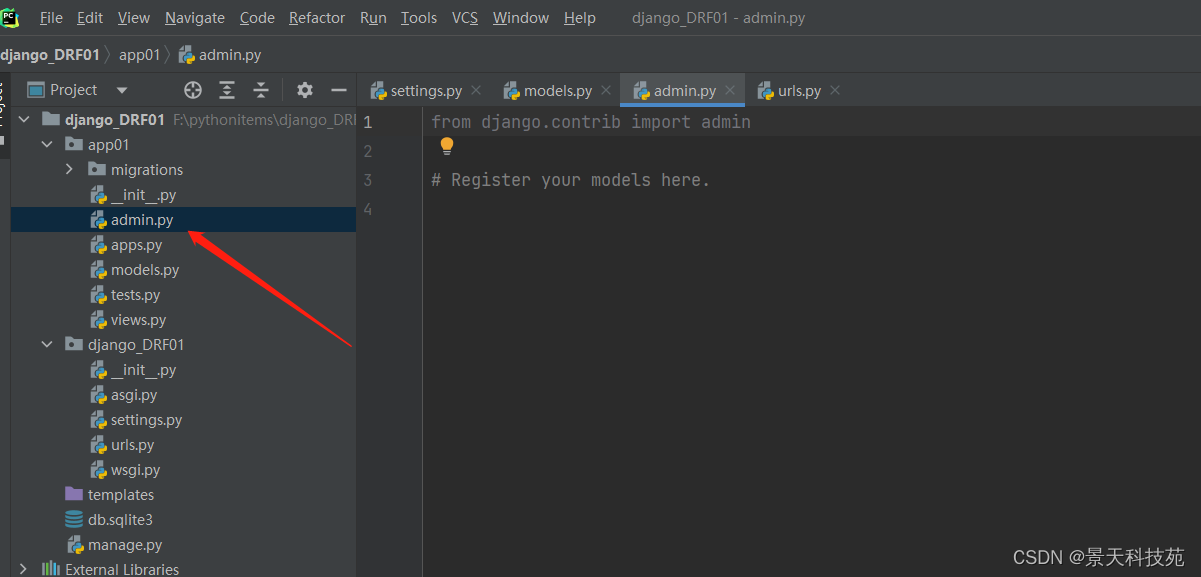
注册模型类
#首先导包
from app01 import models
admin.site.register(models.Student)
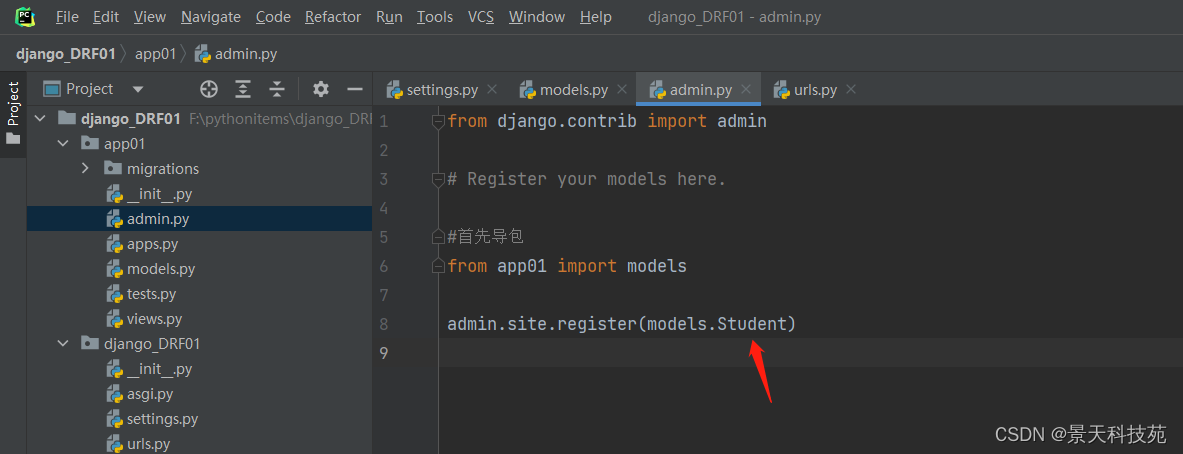
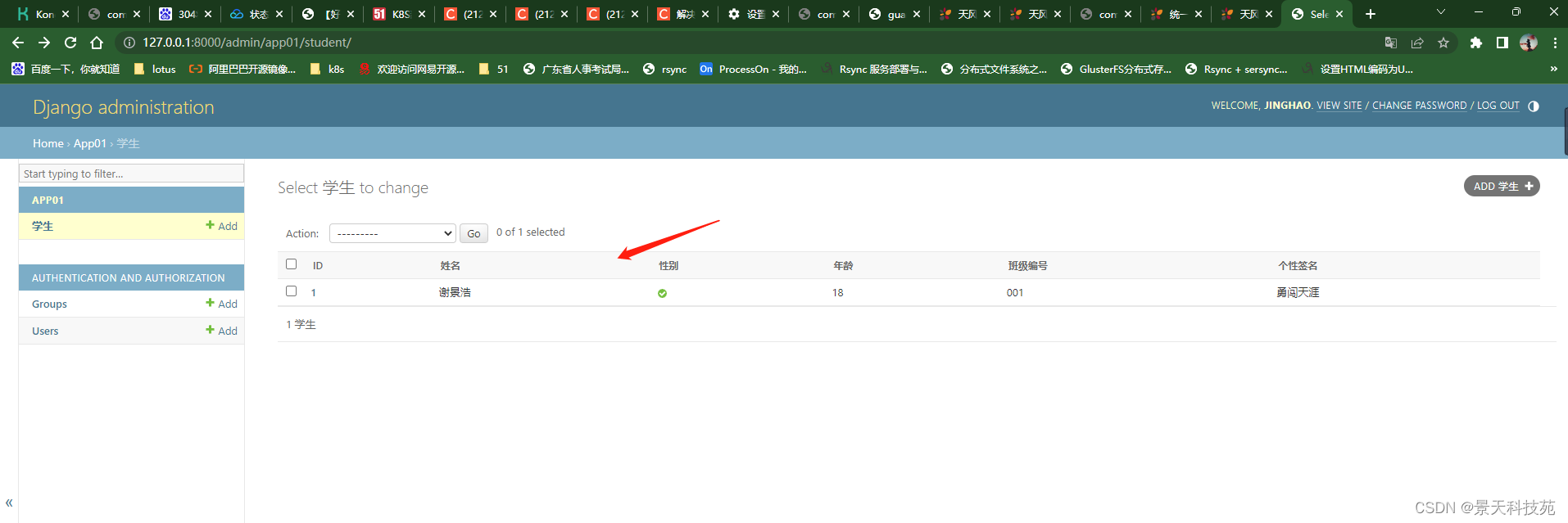
重新运行项目,登录管理系统平台,可以看到我们app01应用下自己创建的表
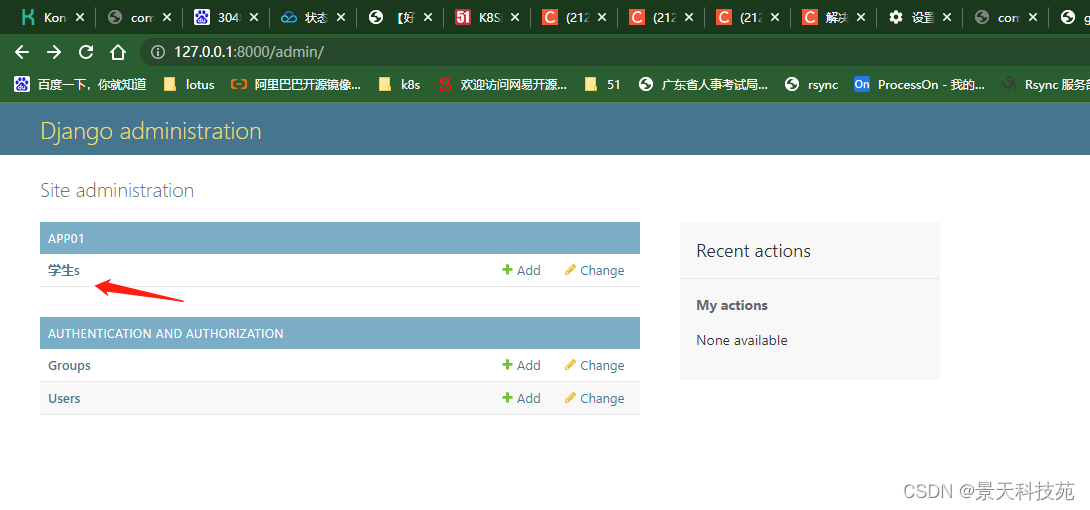
class Meta:下面的verbose_name 就是配置在这里显示的表名
verbose_name_plural 是配置表名复数显示
比如我们注释后再看
表名 显示为我们创建的模型类 类名的复数形式
只配置verbose_name
表名默认以复数形式显示
配置好后,我们进入表中查看
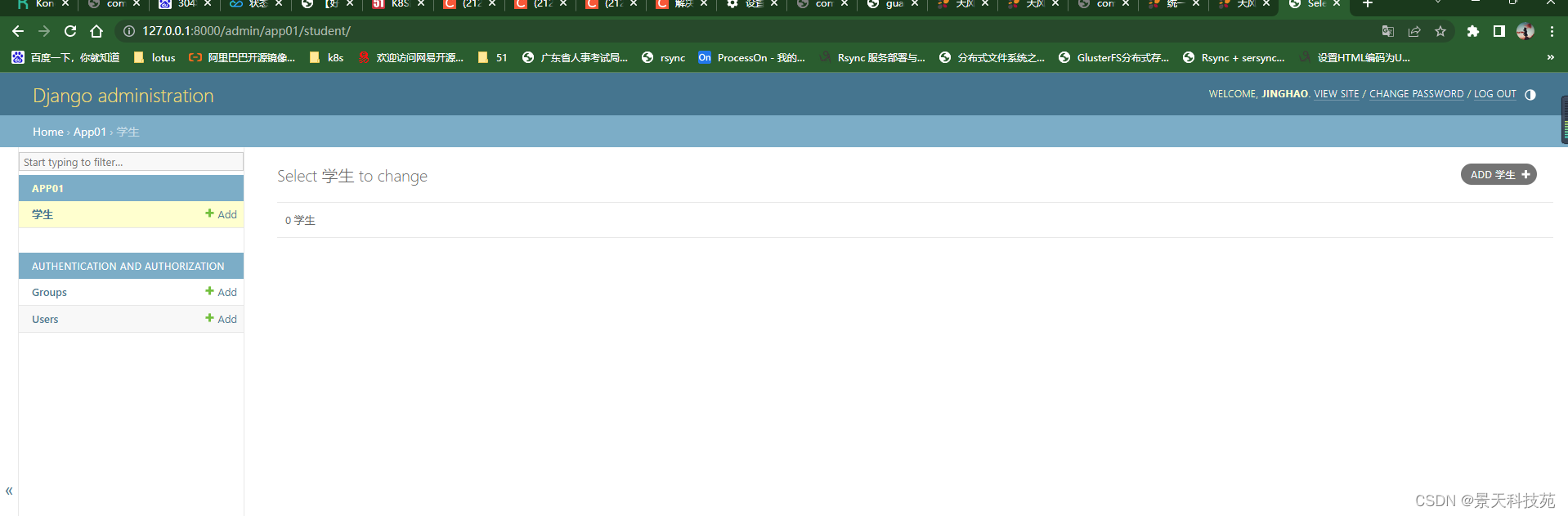
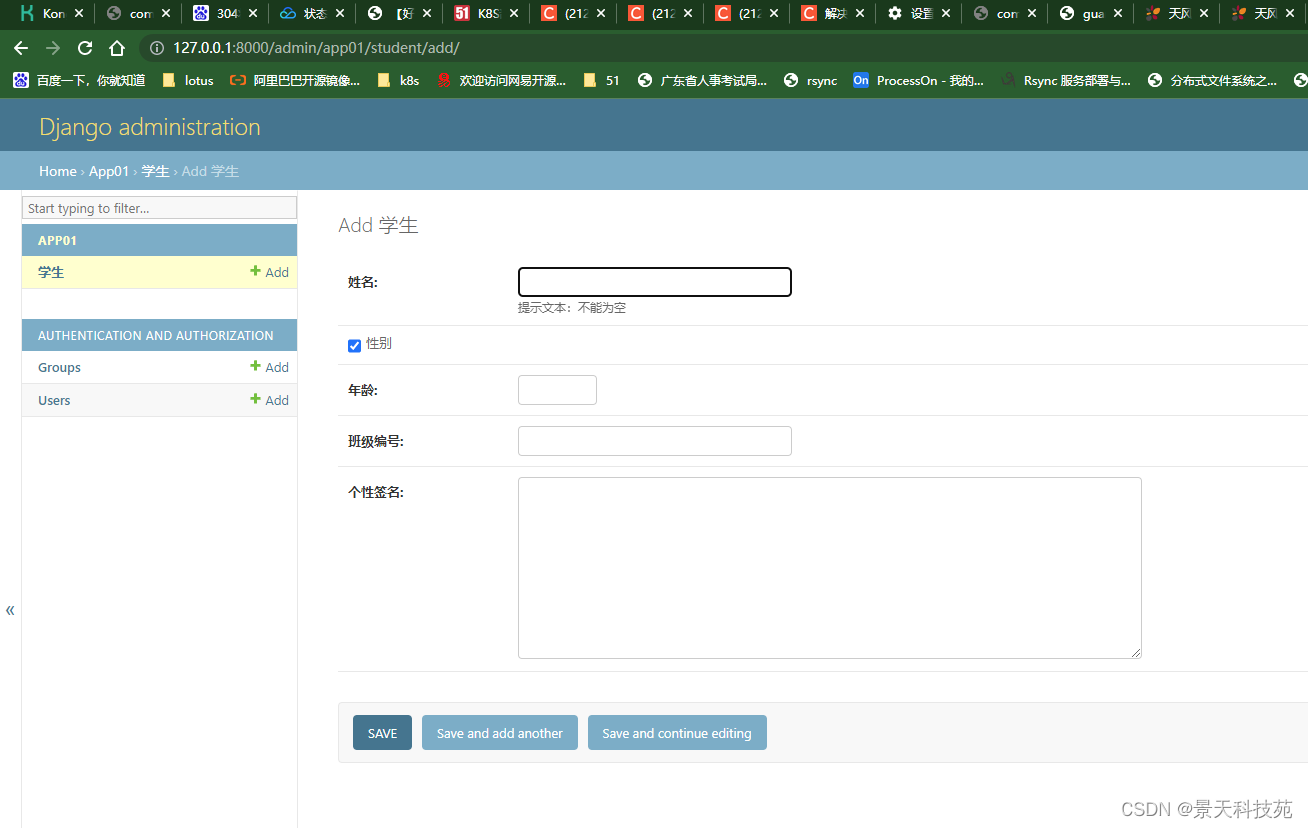
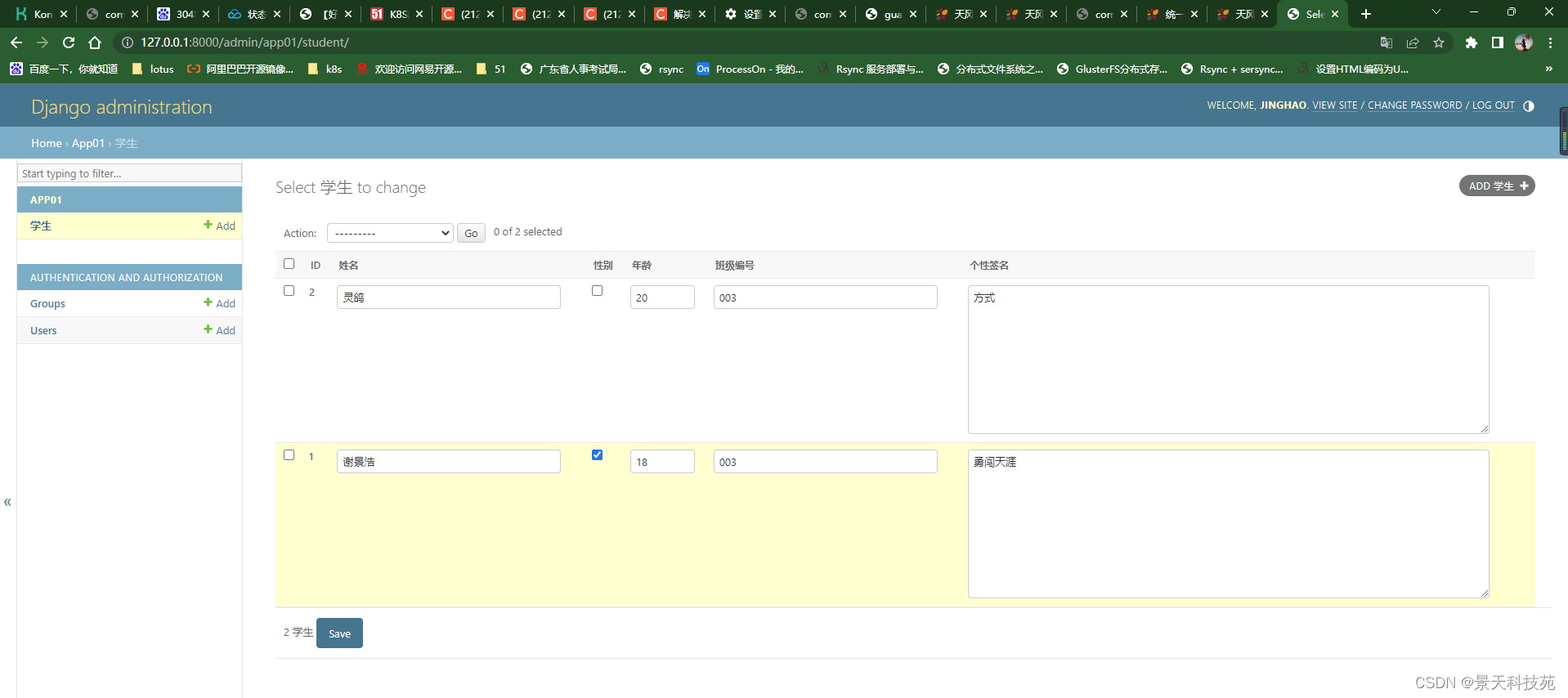
我们可以直接通过这个后台管理系统管理我们的表,做增删改查
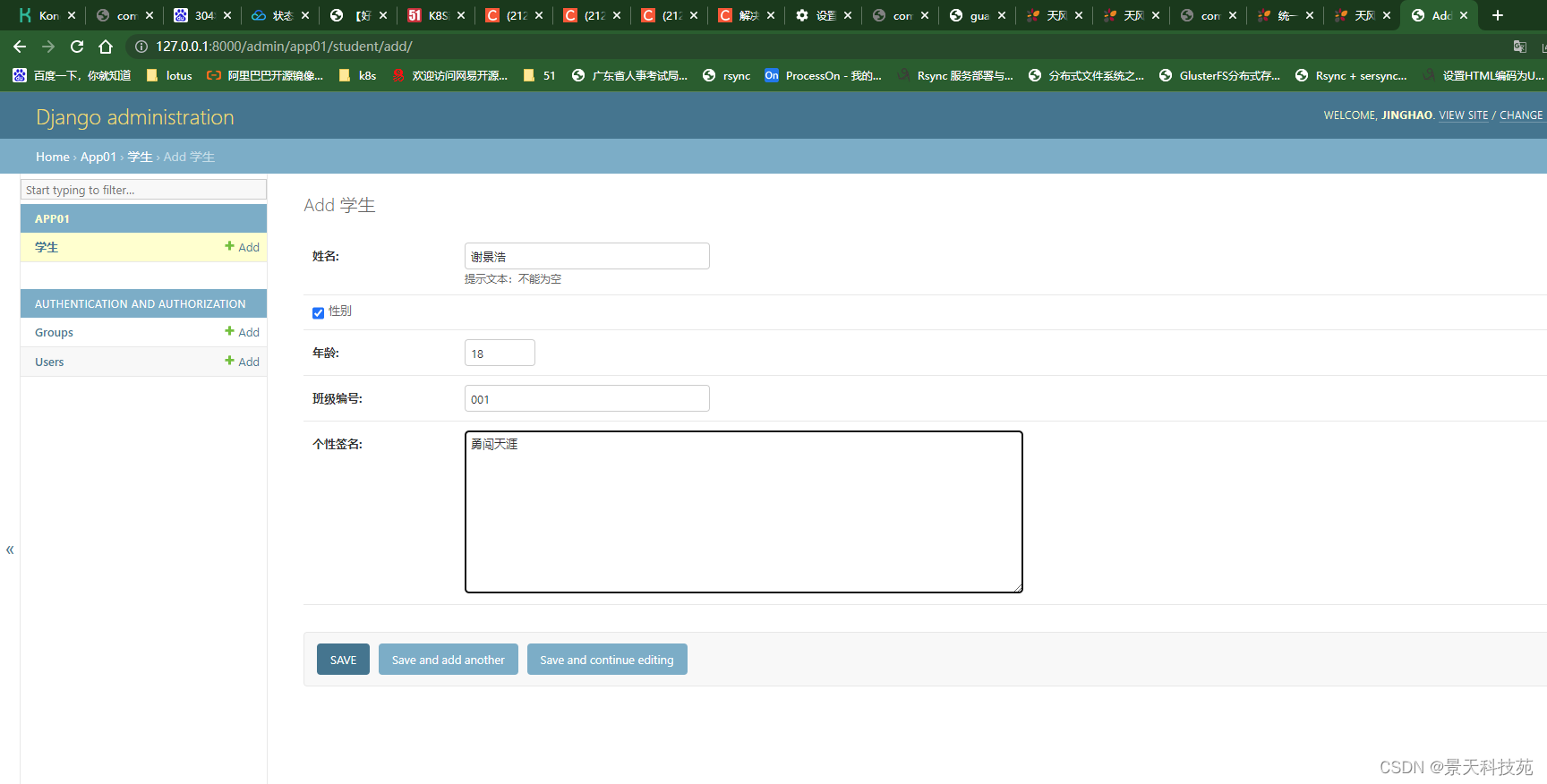
点击ADD学生,可以直接添加学生
页面字段显示中文,就是我们创建模型类时,每个字段指定了verbose_name 才能显示的
admin后台管理系统显示字段名称直接是通过verbose_name配置的名称来显示的
还有提示信息help_text 这些主要是给后台管理系统用的
整个admin后台管理系统是基于 form 和model-form开发的。数据检验用的
布尔值,在后台管理系统显示就是个单选框
添加表记录
点保存

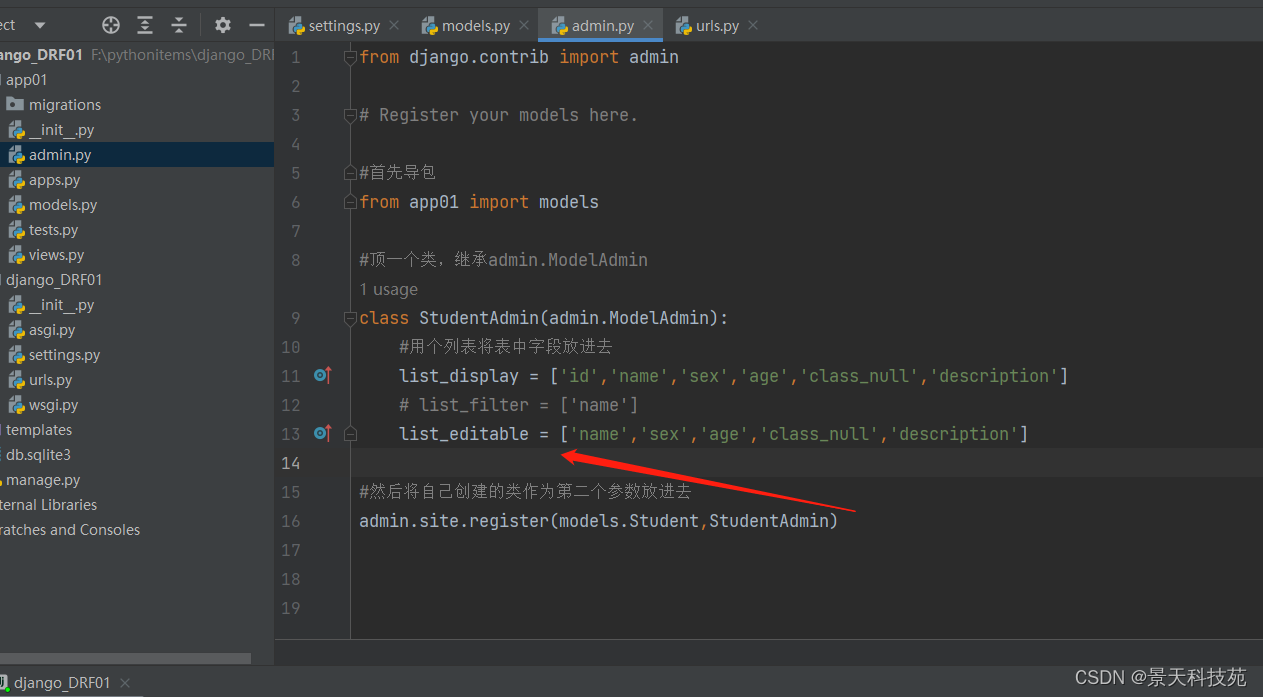
默认展示的是模型类对象,怎么展示出表的字段名称呢,在admin.py中配置
现在看表中数据展示
想要修改字段,点击前面的id进入编辑界面
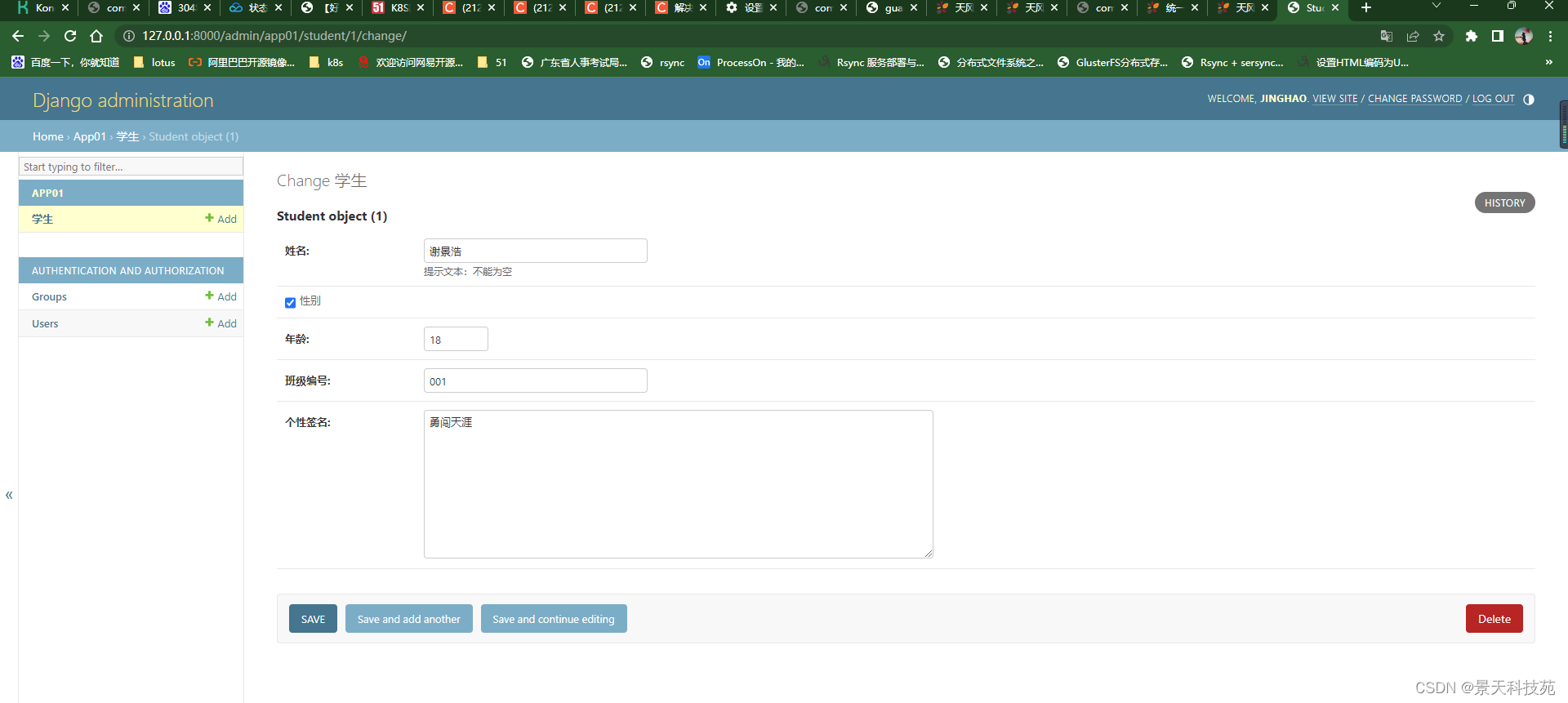
admin就是用来管理数据库表的
也可以查找
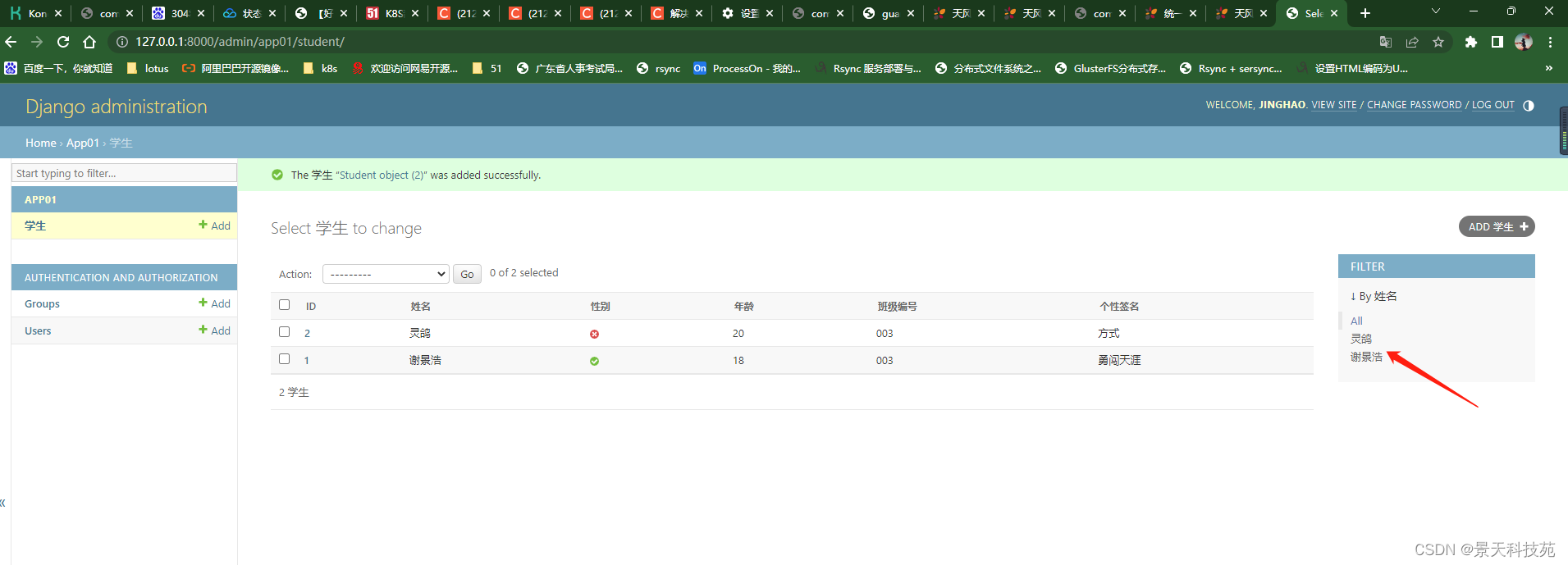
也可以直接在展示页面编辑,不能把id放进去
可以做批量修改
创建管理员以后,访问admin站点,先修改站点的语言配置,设置成显示中文 修改settings.py
LANGUAGE_CODE = ‘zh-hans’
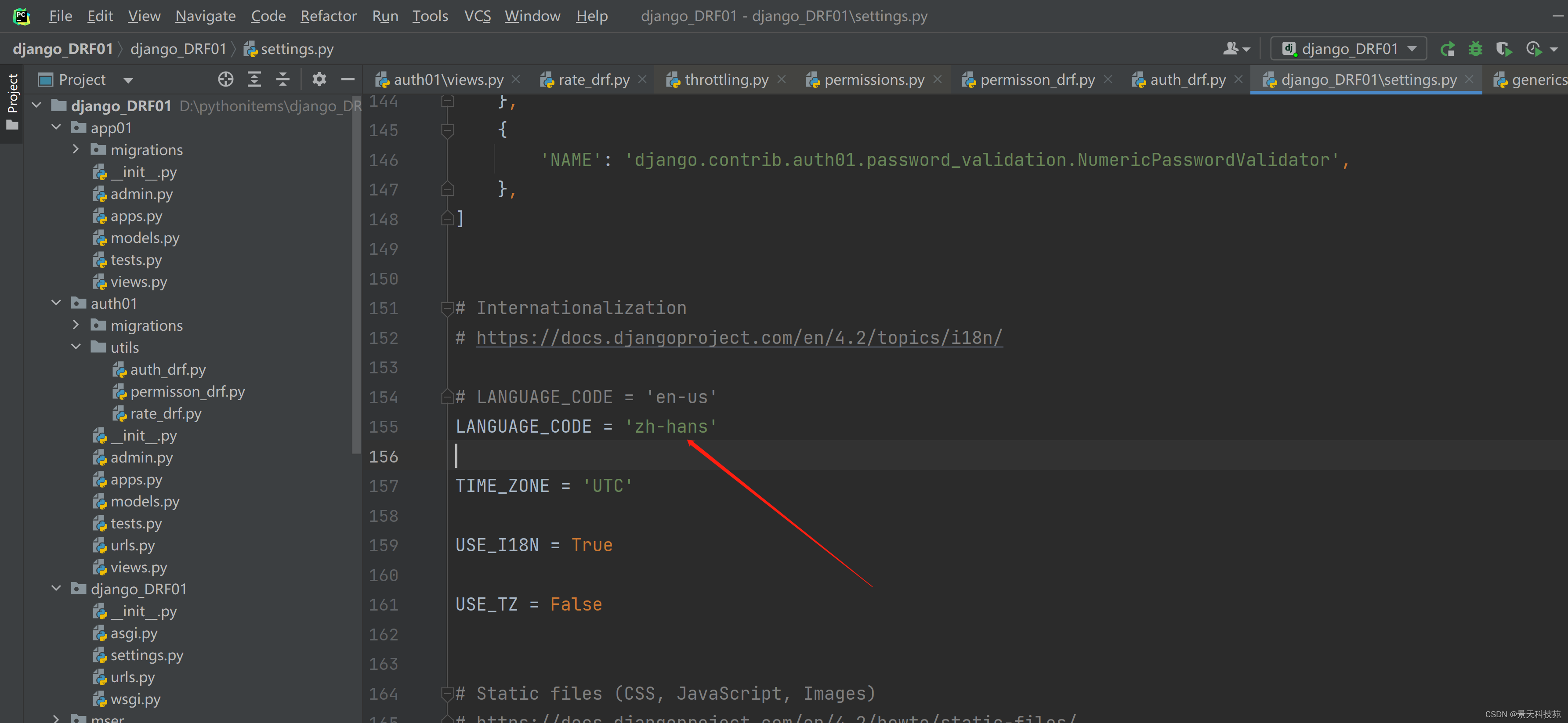
重启服务,这样页面就是中文展示
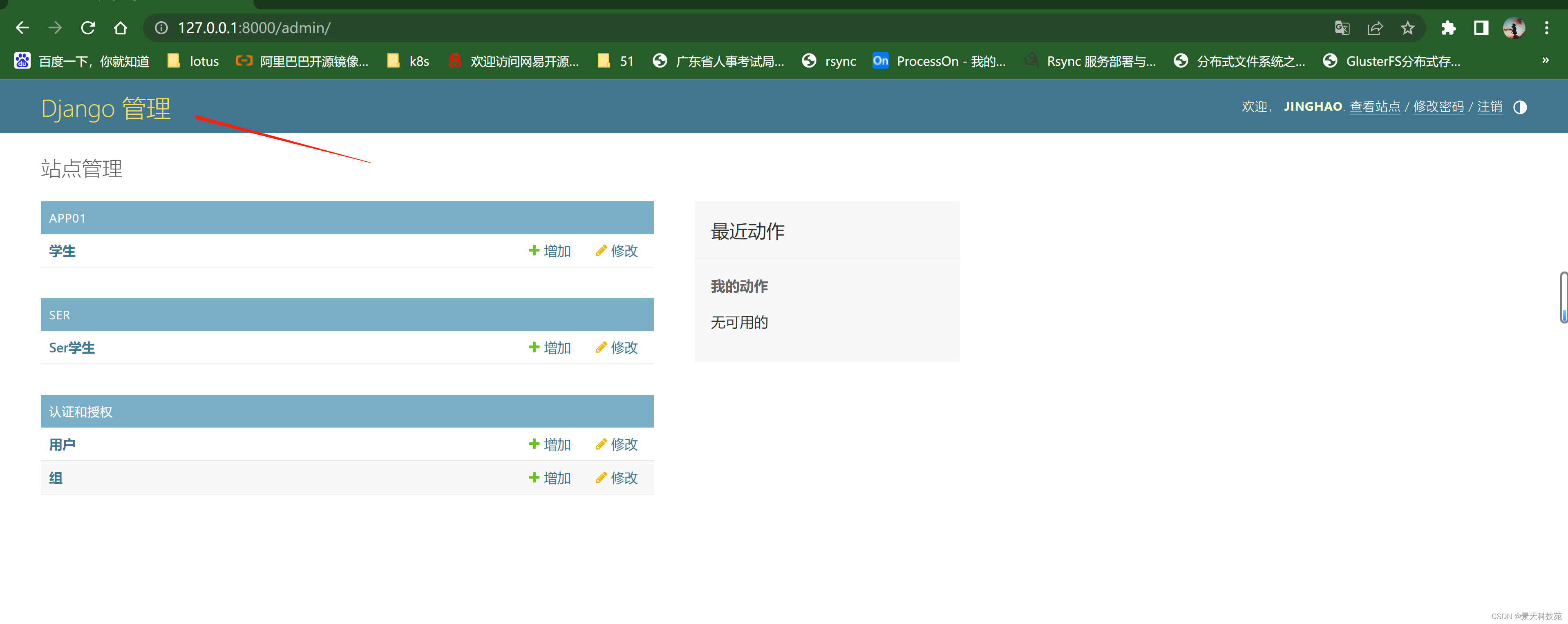
这个admin功能不够全面,后面生产中我们使用xadmin,提供的功能更多
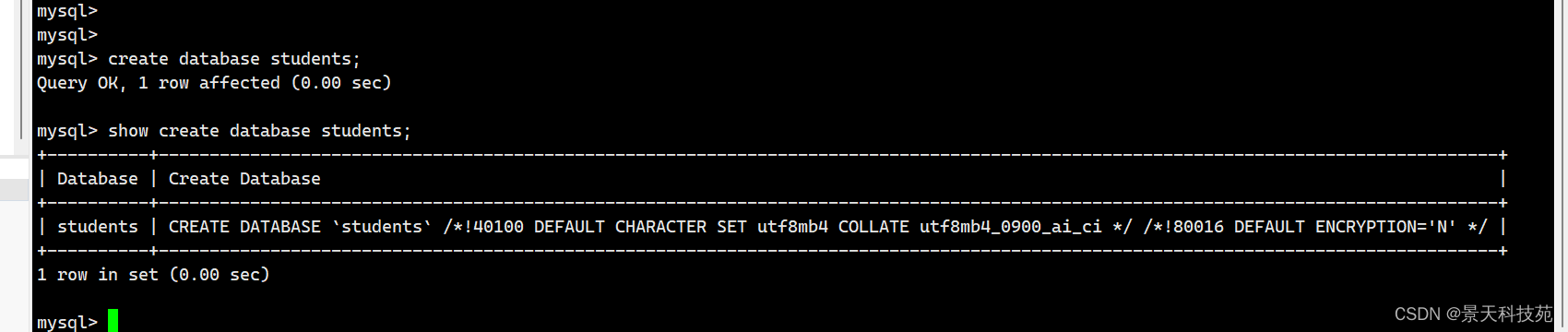
现在我们连接mysql数据库来进行drf操作
create database students;
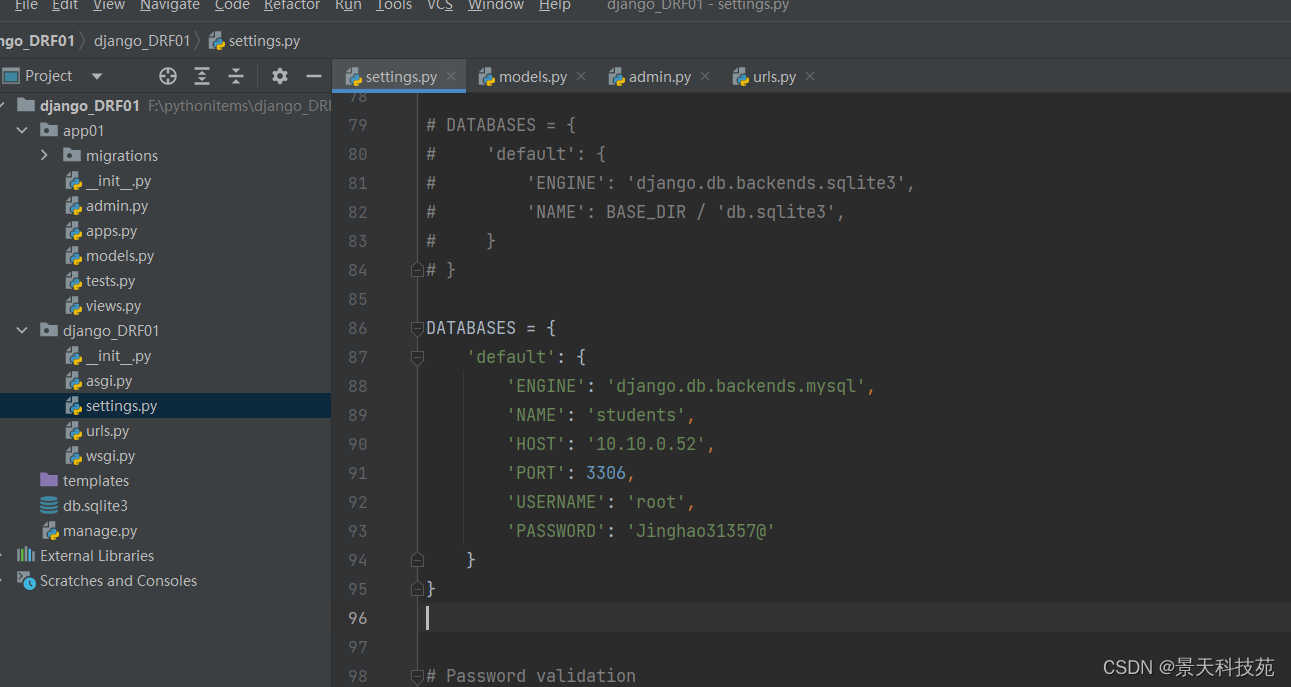
在项目的__init__.py文件中配置pymysql使用mysql数据库,并兼容高版本mysql
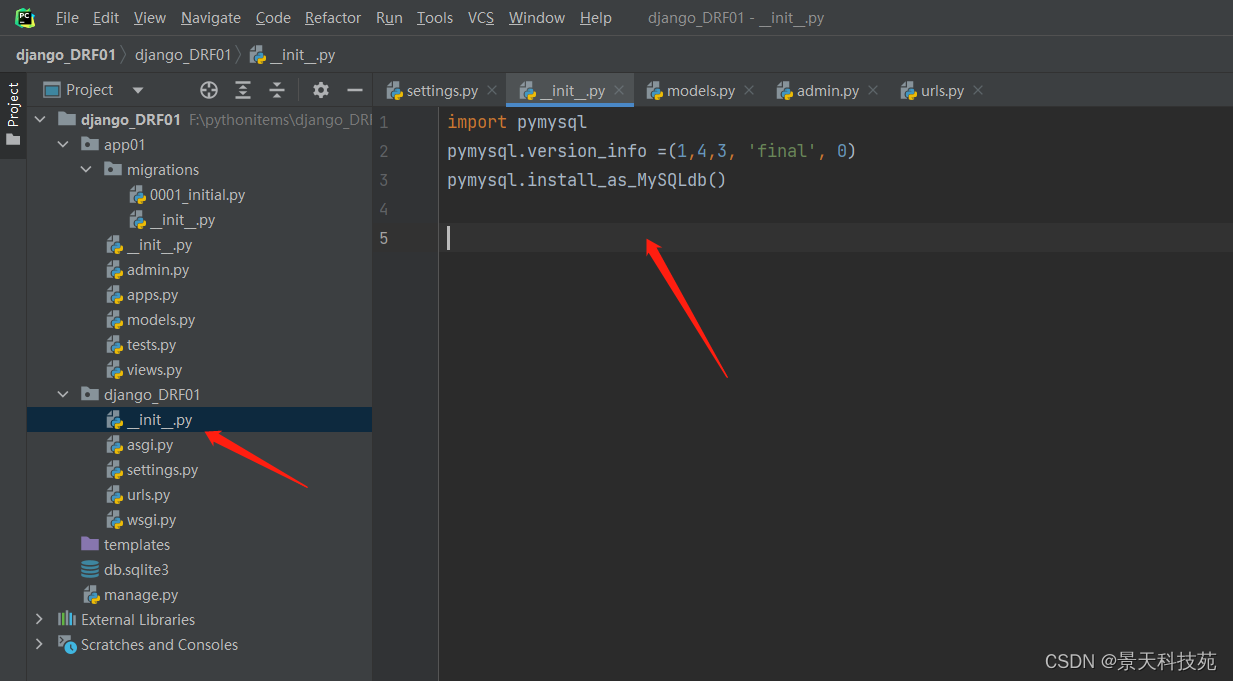
此时,要把原先创建在sqlite3里面的数据迁移到mysql,由于初始化数据库同步语句已经生成了,数据库表没有变化,不要再执行makemigrations
只需要执行migrate
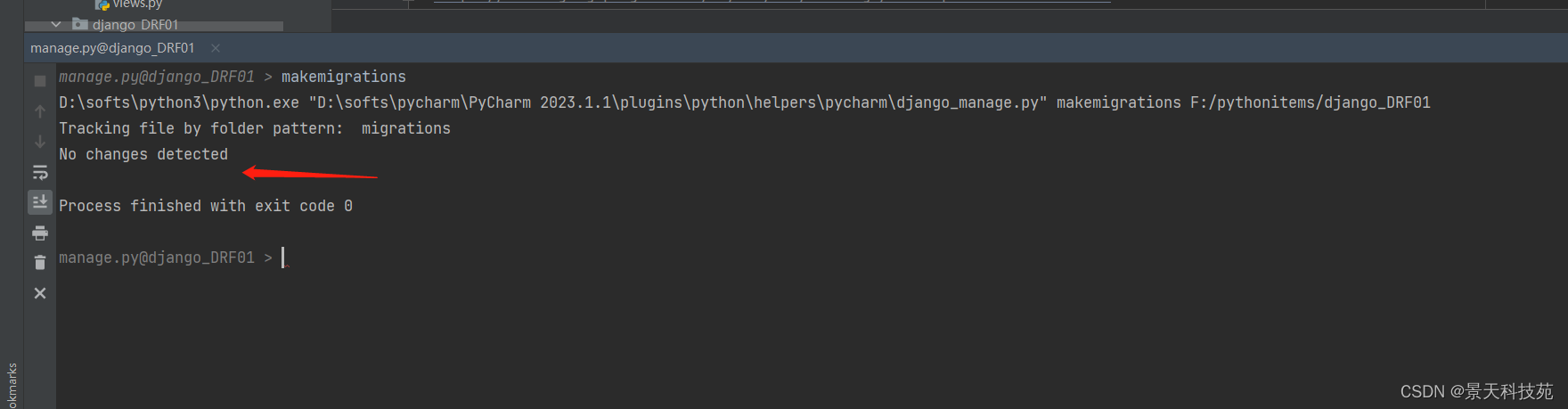
可能的报错处理
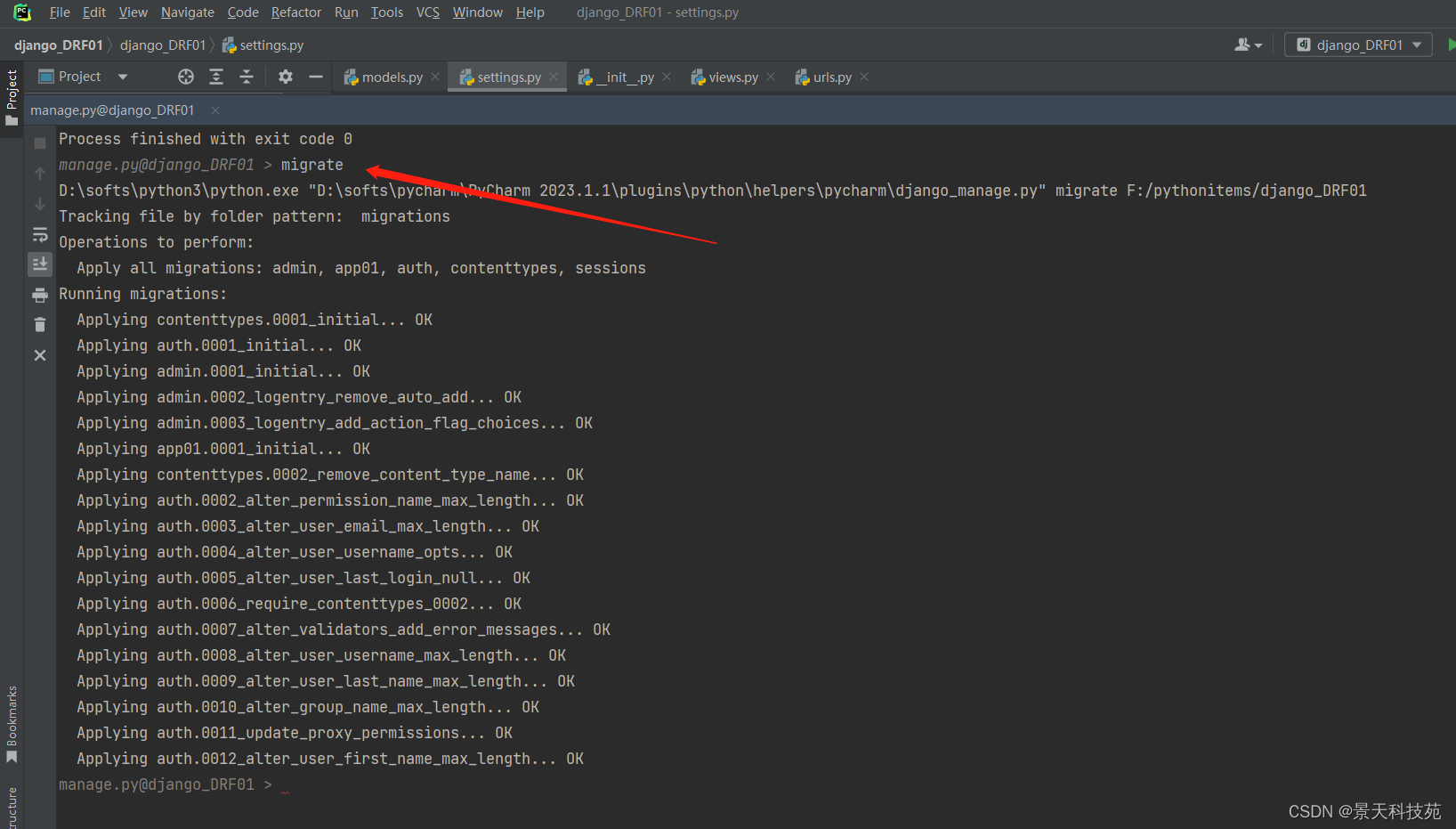
数据库中查看表
创建序列化器
创建个子应用 student
startapp student
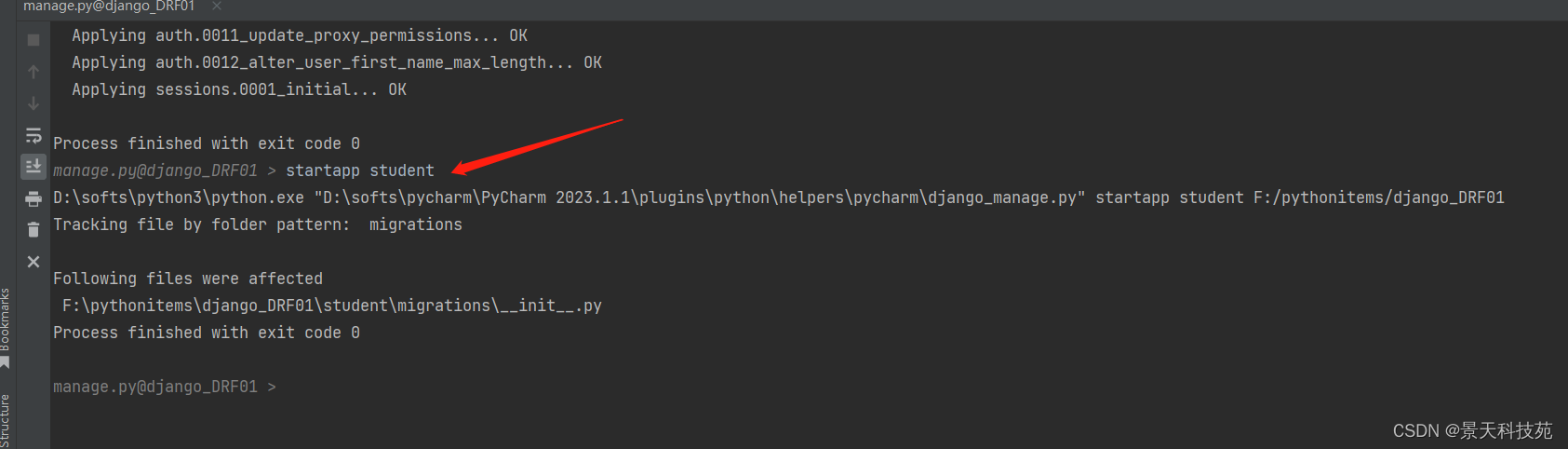
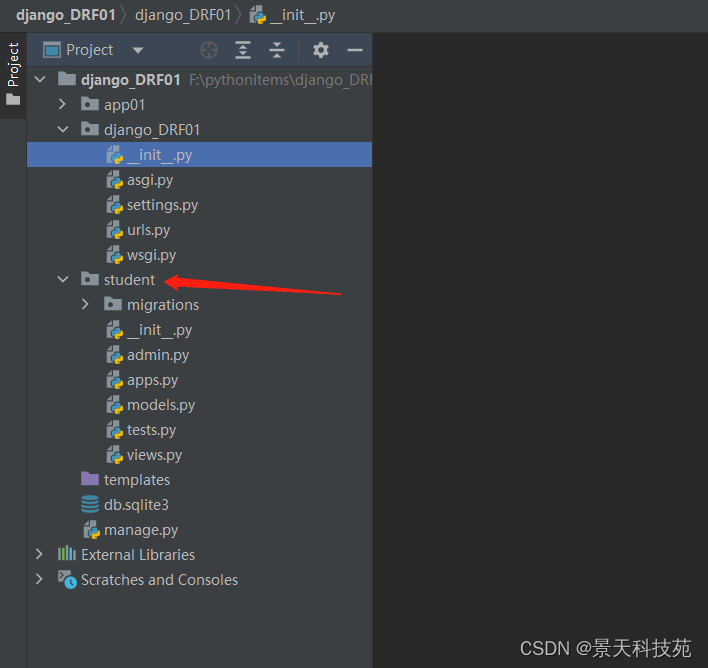
记得将新创建的应用添加到INSTALLED_APPS里面
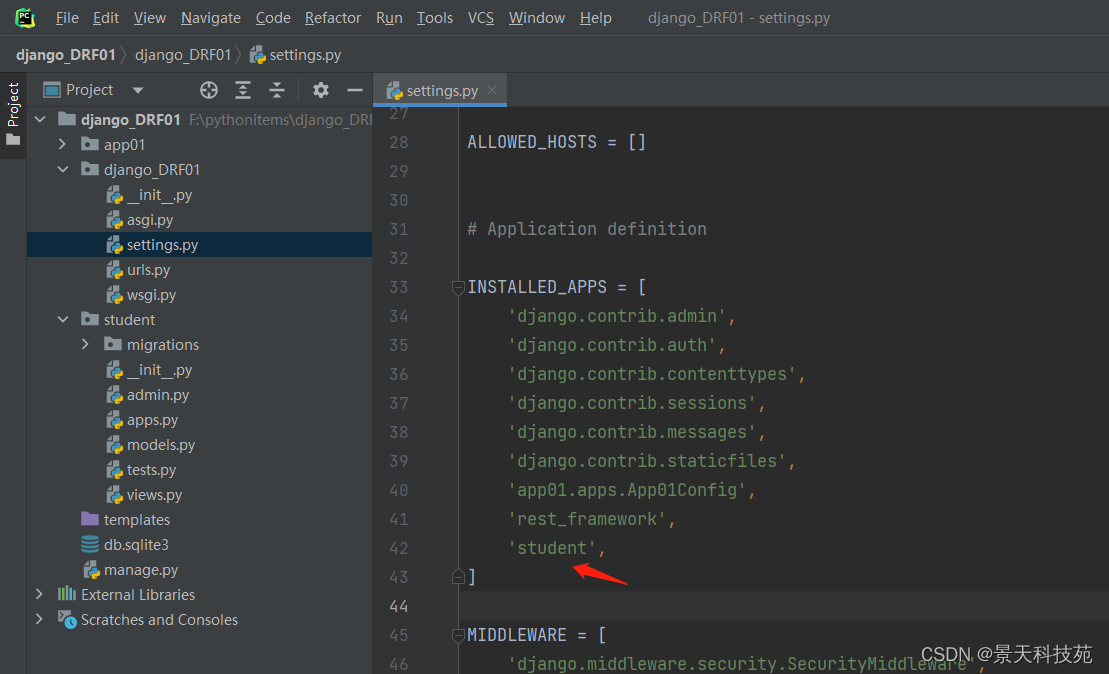
配置路由分发,在新创建的应用下创建urls.py文件
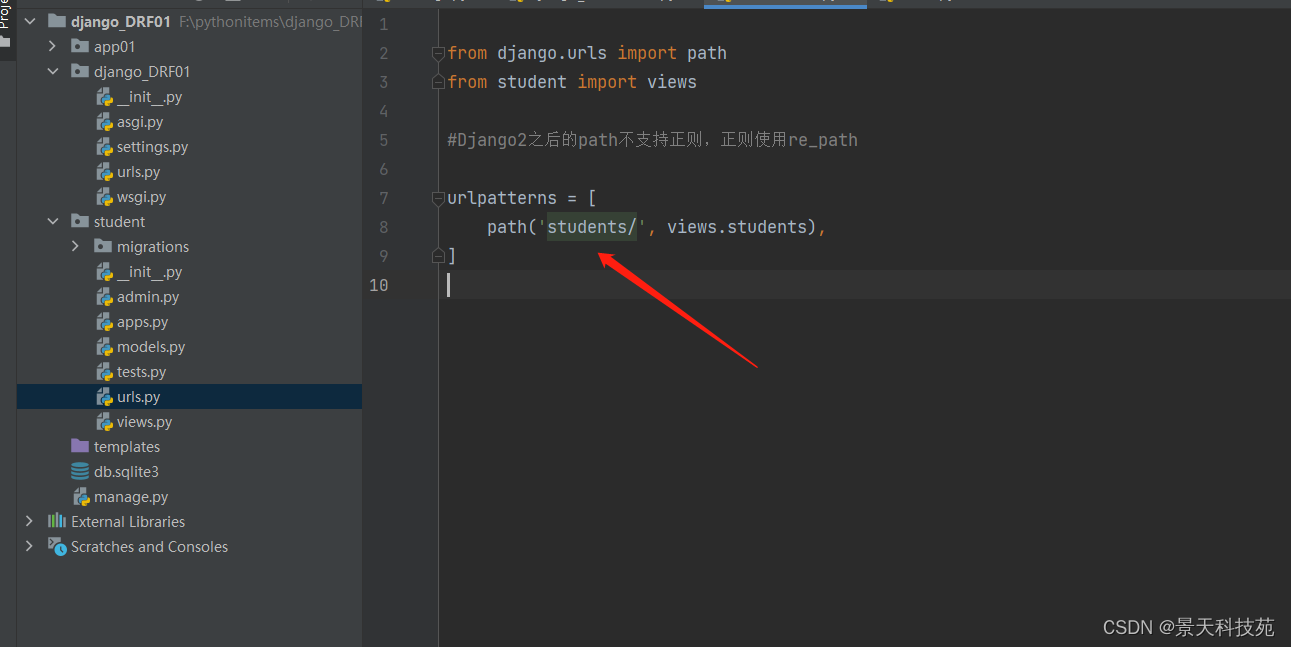
项目下的urls.py 将各个应用的url导入
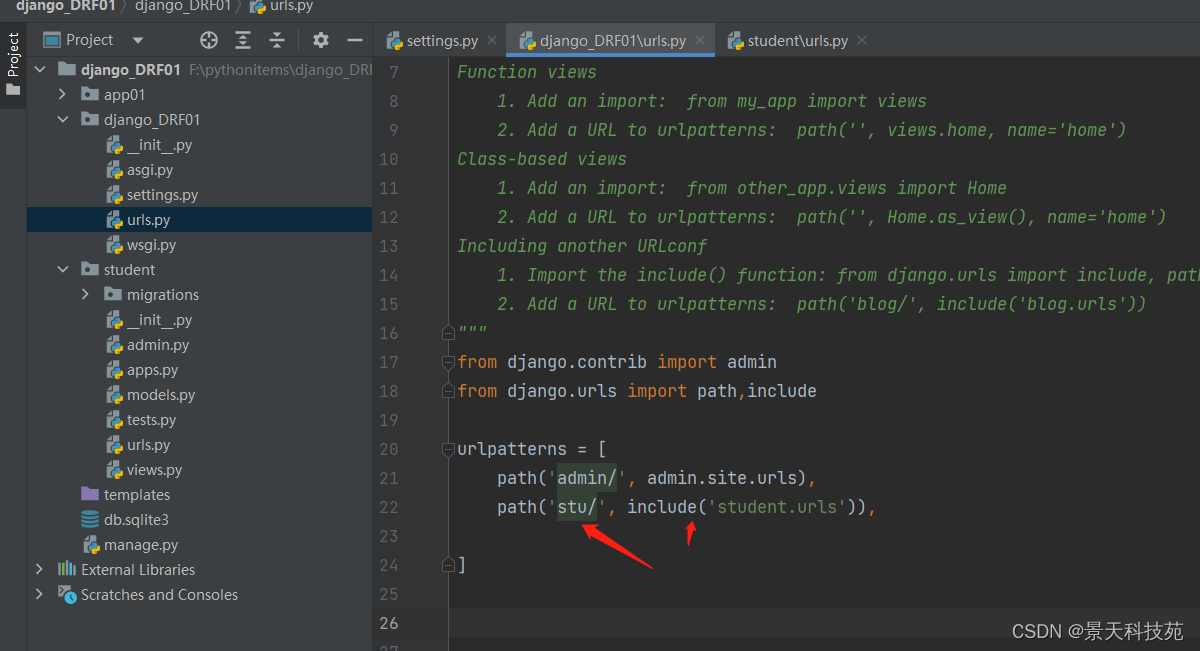
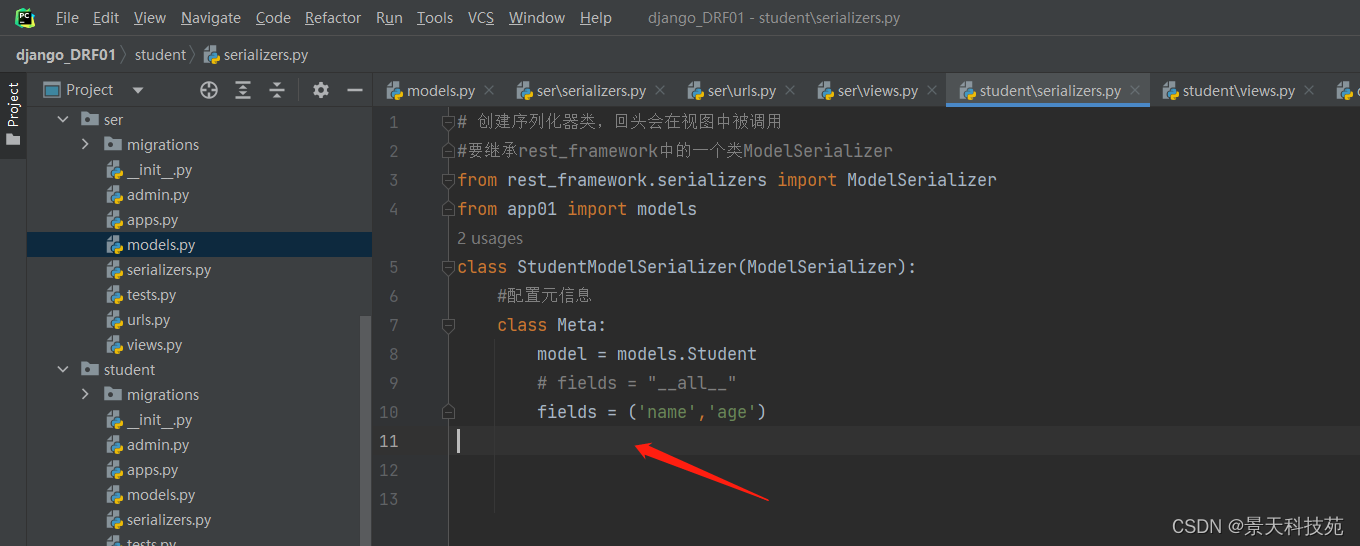
在student应用目录中新建serializers.py用于保存该应用的序列化器。
创建一个StudentModelSerializer类用于序列化与反序列化。
#创建序列化器类,回头会在视图中被调用
#要继承rest_framework中的一个类ModelSerializer
from rest_framework.serializers import ModelSerializer
from app01 import models
class StudentModelSerializer(ModelSerializer):
#配置元信息
class Meta:
model = models.Student
fields = "__all__"
model 指明该序列化器处理的数据字段从模型类Student参考生成
fields 指明该序列化器包含模型类中的哪些字段,'__all__'指明包含所有字段
可以使用fields来明确字段,__all__表示包含所以字段,具体那些字段->fields = ('title','price')
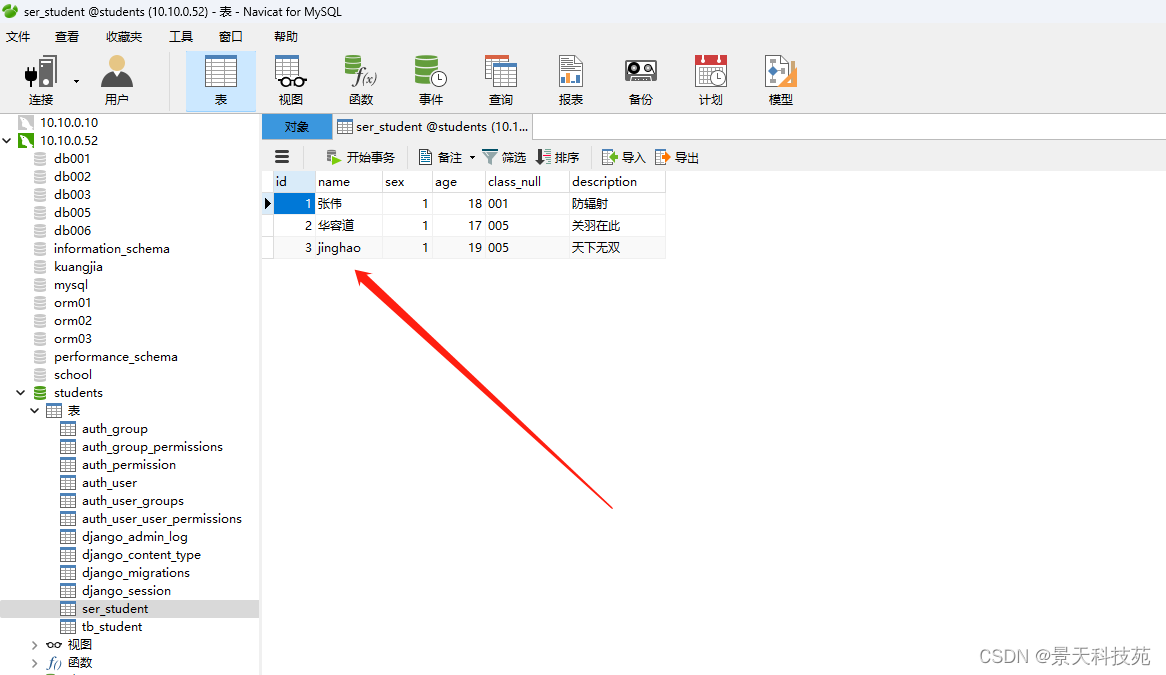
由于之前admin管理后台创建的超级用户存在了sqlite3,现在数据库换成了mysql,需要重新创建一个,存在了django内置的auth-user表中
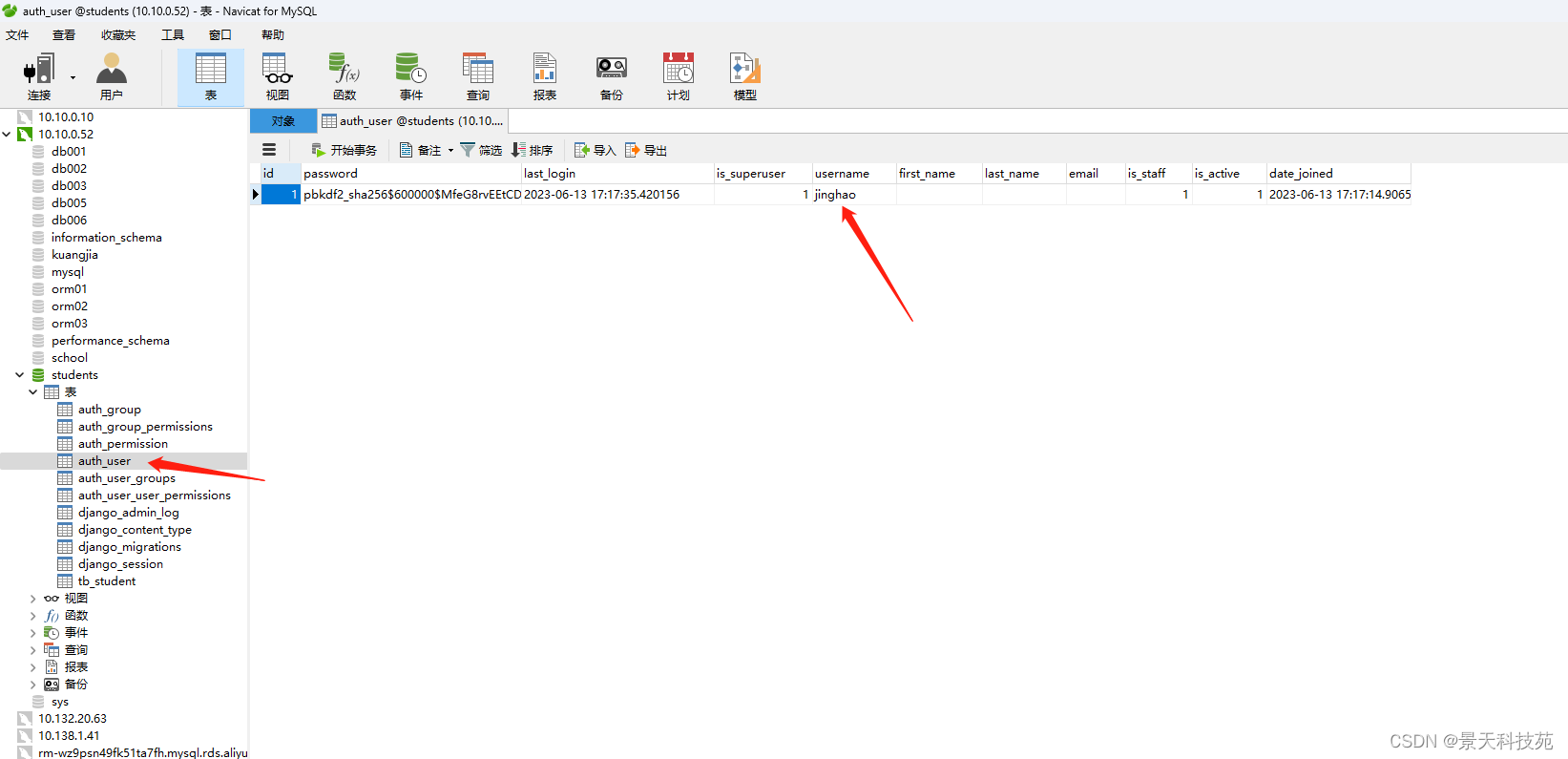
登录上去,添加些数据
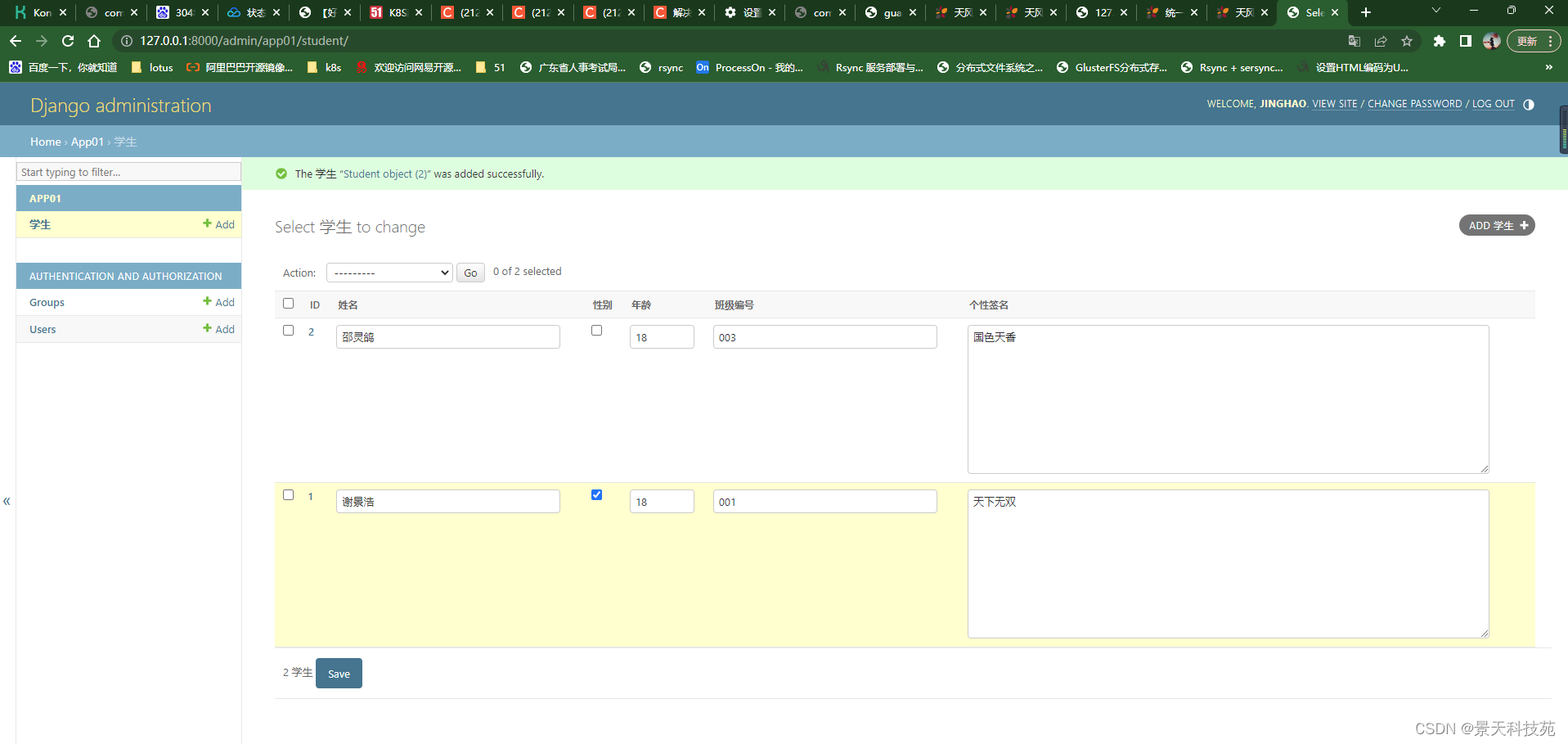
视图类函数
from django.shortcuts import render
# Create your views here.
from app01 import models
from django.http import JsonResponse
#引入我们创建的序列化器类
from student.serializers import StudentModelSerializer
def students(request):
method = request.method
if method == 'GET':
studentdata = models.Student.objects.filter()
#序列化多条数据,需要加上many=True,返回序列化对象
serializer_obj = StudentModelSerializer(instance=studentdata,many=True)
#返回列表类型数据
print(serializer_obj.data,type(serializer_obj.data))
#JsonResponse返回非字典类型数据,需要加上safe=False,返回中文,需要加上, json_dumps_params={'ensure_ascii': False} 不然浏览器查看是Unicode码
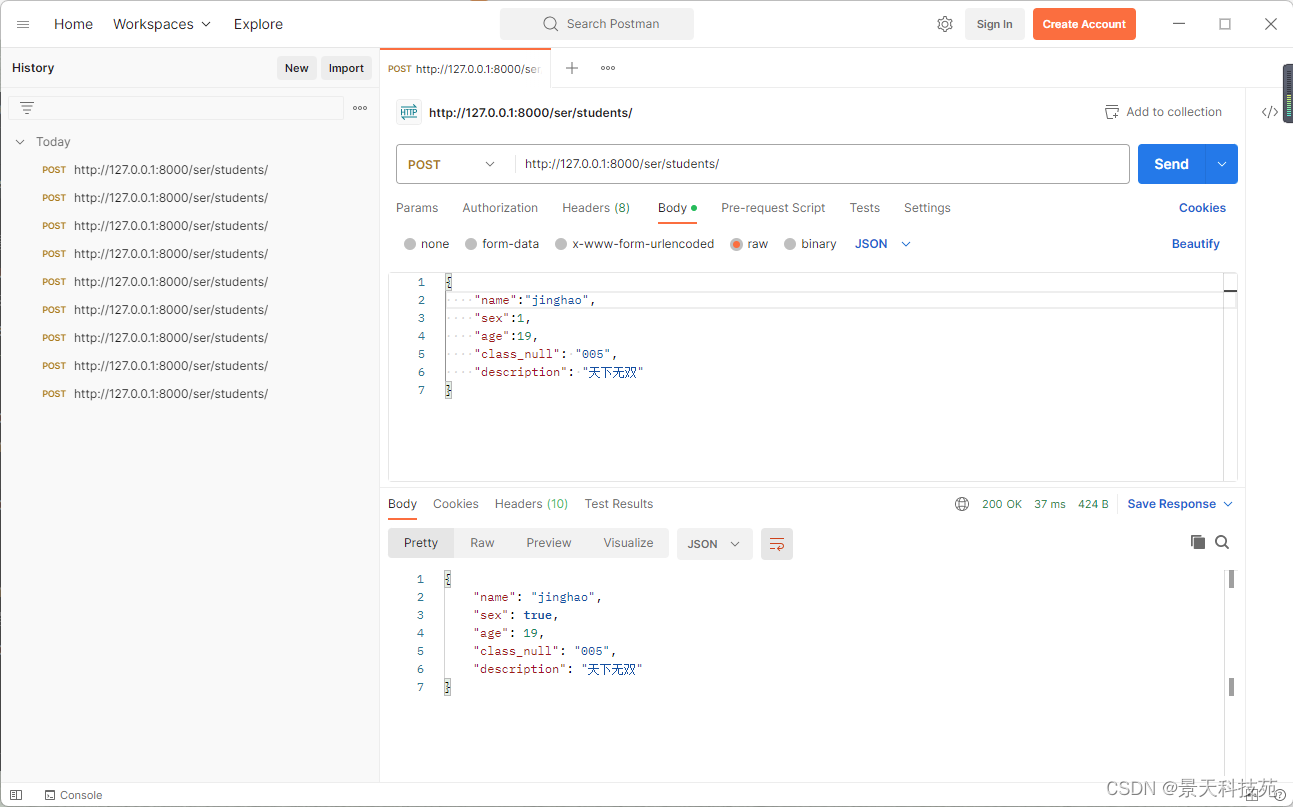
return JsonResponse(serializer_obj.data,safe=False, json_dumps_params={'ensure_ascii': False})
查看数据类型,每个字典由一个元祖包裹
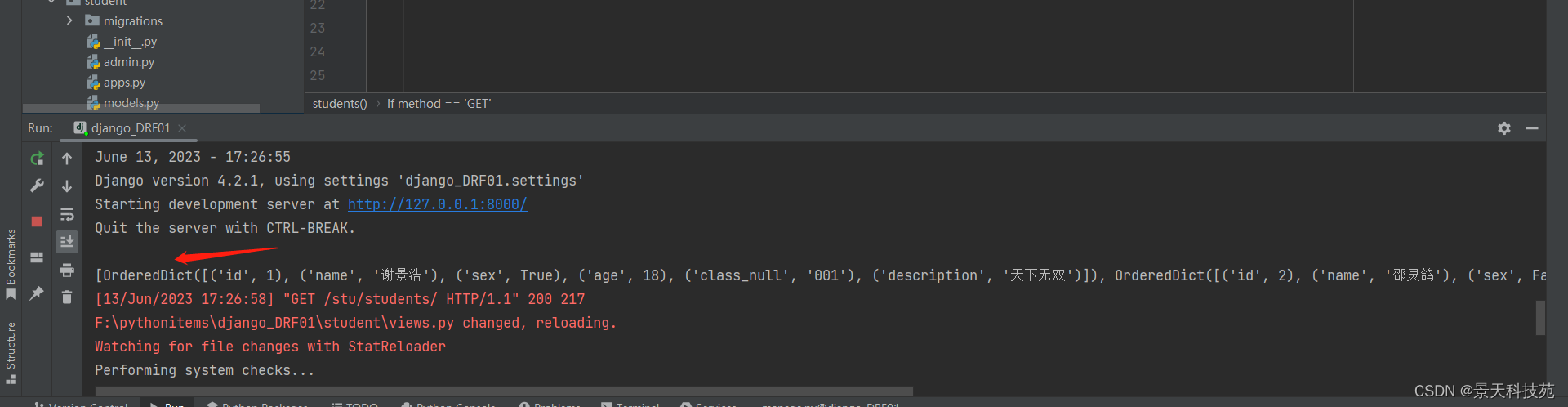
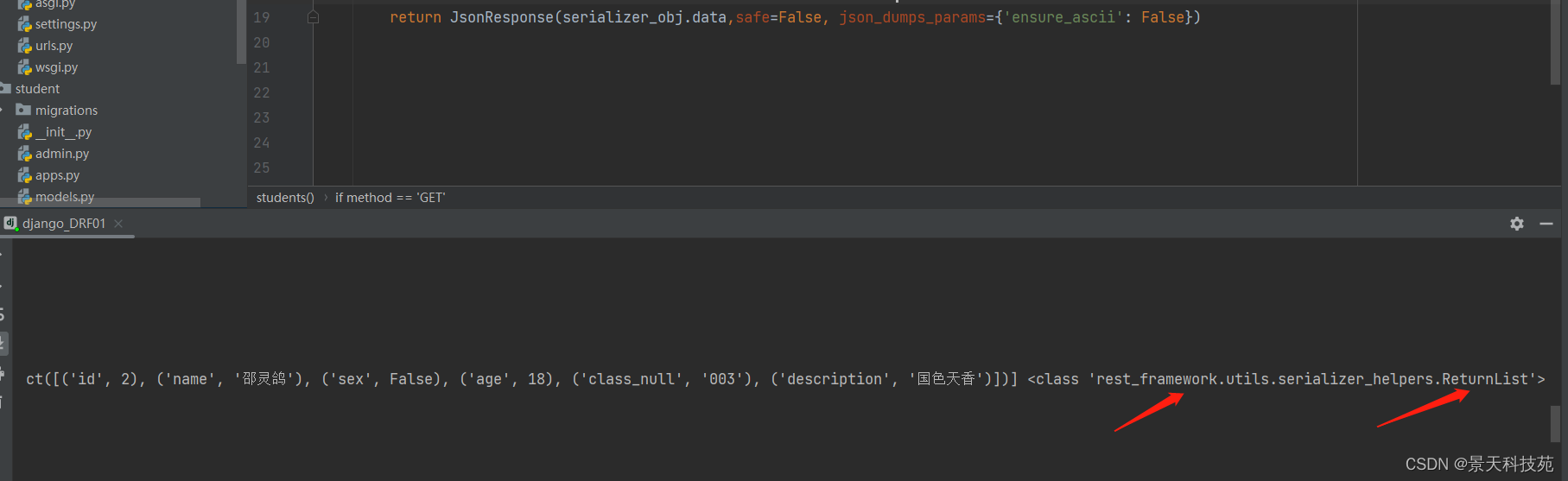
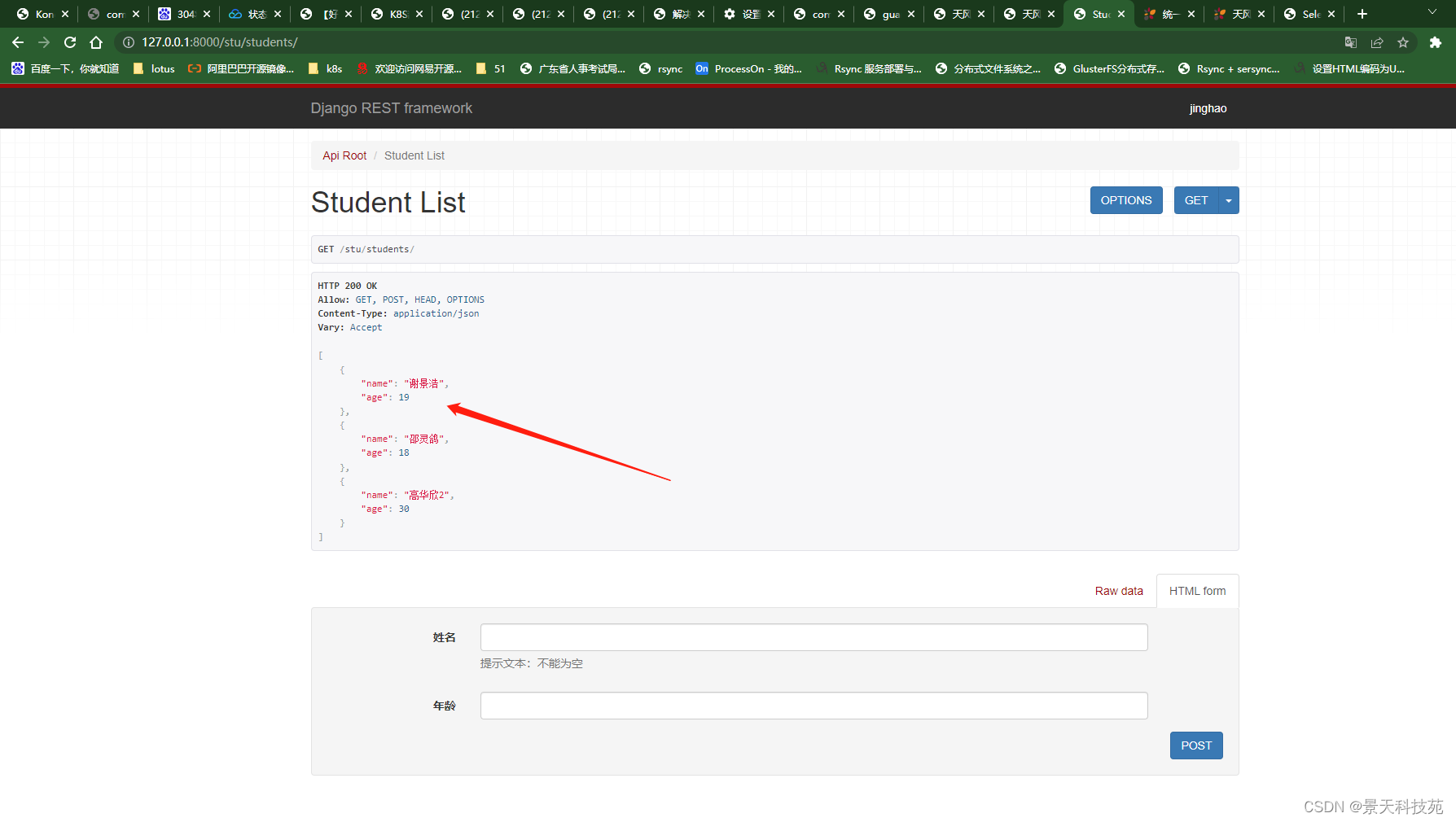
浏览器访问,达到效果,前端拿到数据之后,方便循环来展示
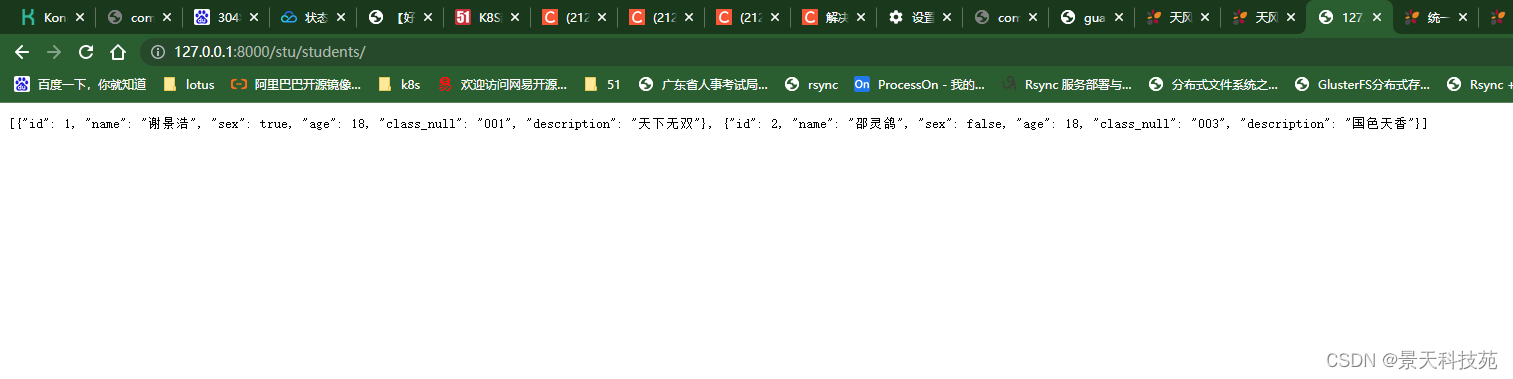
DRF可以用一个方法实现5个接口,增删改查,我们视图使用CBV模式
视图类
from app01 import models
from django.http import JsonResponse
#引入我们创建的序列化器类
from student.serializers import StudentModelSerializer
#导入DRF的ModelViewSet类
from rest_framework.viewsets import ModelViewSet
#定义的视图类要继承ModelViewSet类
class StudentView(ModelViewSet):
#queryset 指明该视图集在查询数据时使用的查询集
#serializer_class 指明该视图在进行序列化或反序列化时使用的序列化器
queryset = models.Student.objects.all()
serializer_class = StudentModelSerializer
路由也由drf来注册生成
from student import views
#Django2之后的path不支持正则,正则使用re_path
urlpatterns = [
# path('students/', views.students),
]
#使用rest_frame创建路由,首先导包
from rest_framework.routers import DefaultRouter
url_obj = DefaultRouter() # 可以处理视图的路由器,自动通过视图来生成增删改查的url路径
url_obj.register('students',views.StudentView) #students是生成的url前缀,名称随便写, 向路由器中注册视图集
urlpatterns += url_obj.urls # 将路由器中的所有路由信息追到到django的路由列表中
浏览器访问查看,这些路由都是drf的defaultrouter对象自动生成的
DefaultRouter生成的接口路径太死板,在公司中我们也基本不用它,都是自己手写的
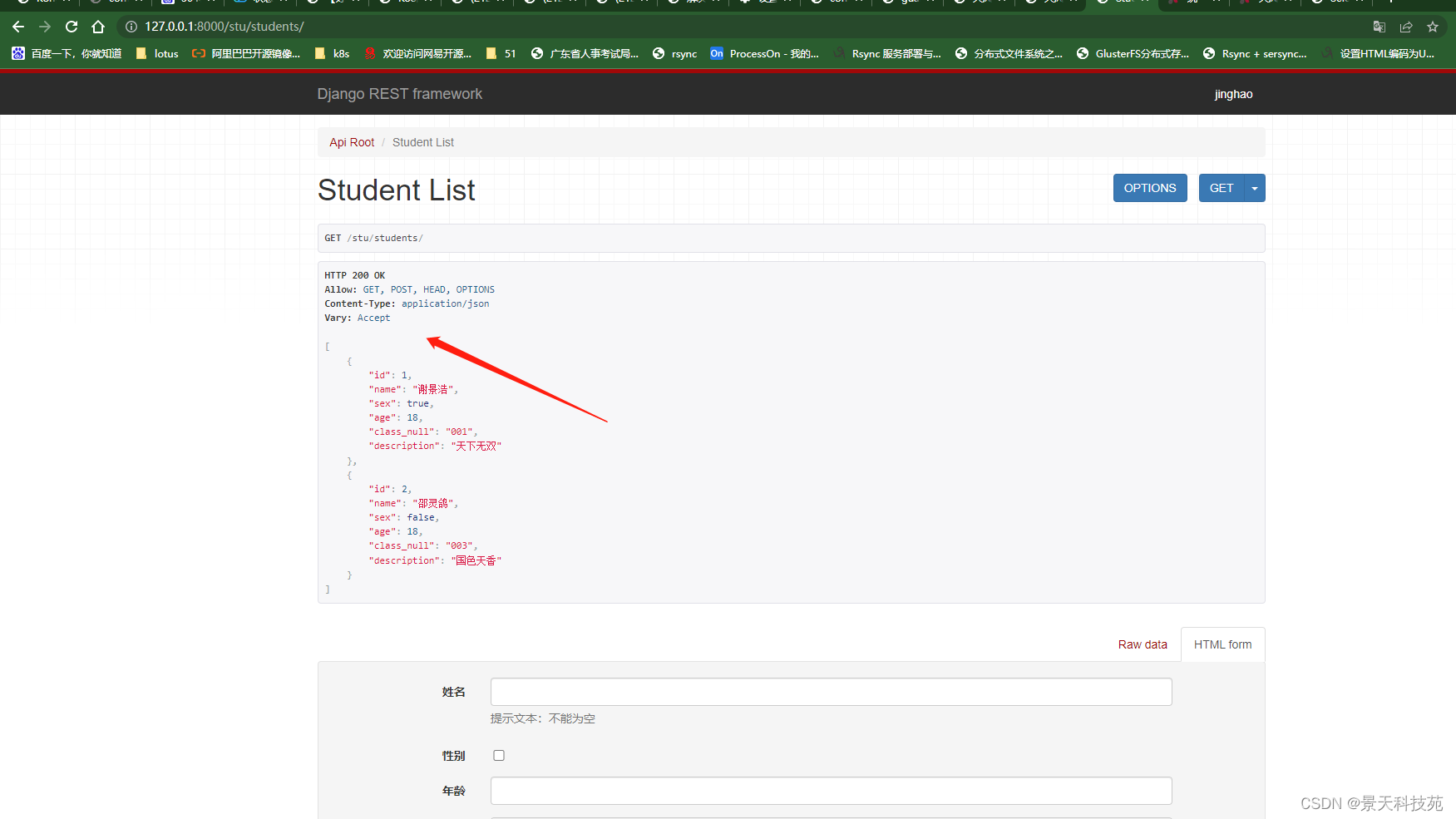
我们查看下students返回的json,页面视图都是drf提供的
视图页面是由ModelViewSet这个视图类提供的
正常的APIView或者View 页面都是返回的json字符串
如果我们不想看页面,也可以只看json数据,在url添加?format=json
这些都是DRF提供的功能

不仅提供了查看数据,也可以直接添加数据,可以直接在页面添加数据
不仅可以以form表单形式提交,还可以以原生json格式提交
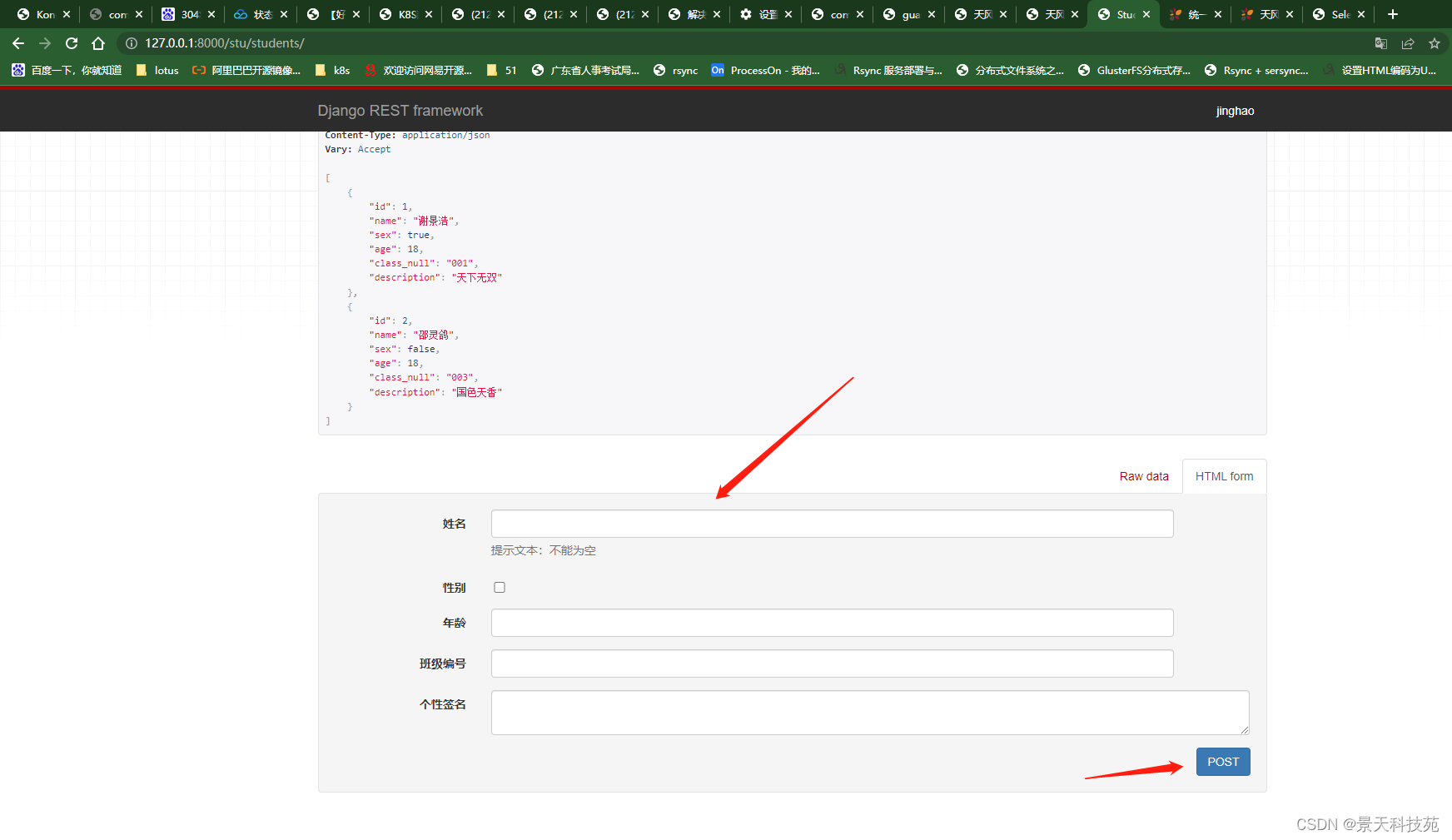
输入数据,点POST直接添加到数据库
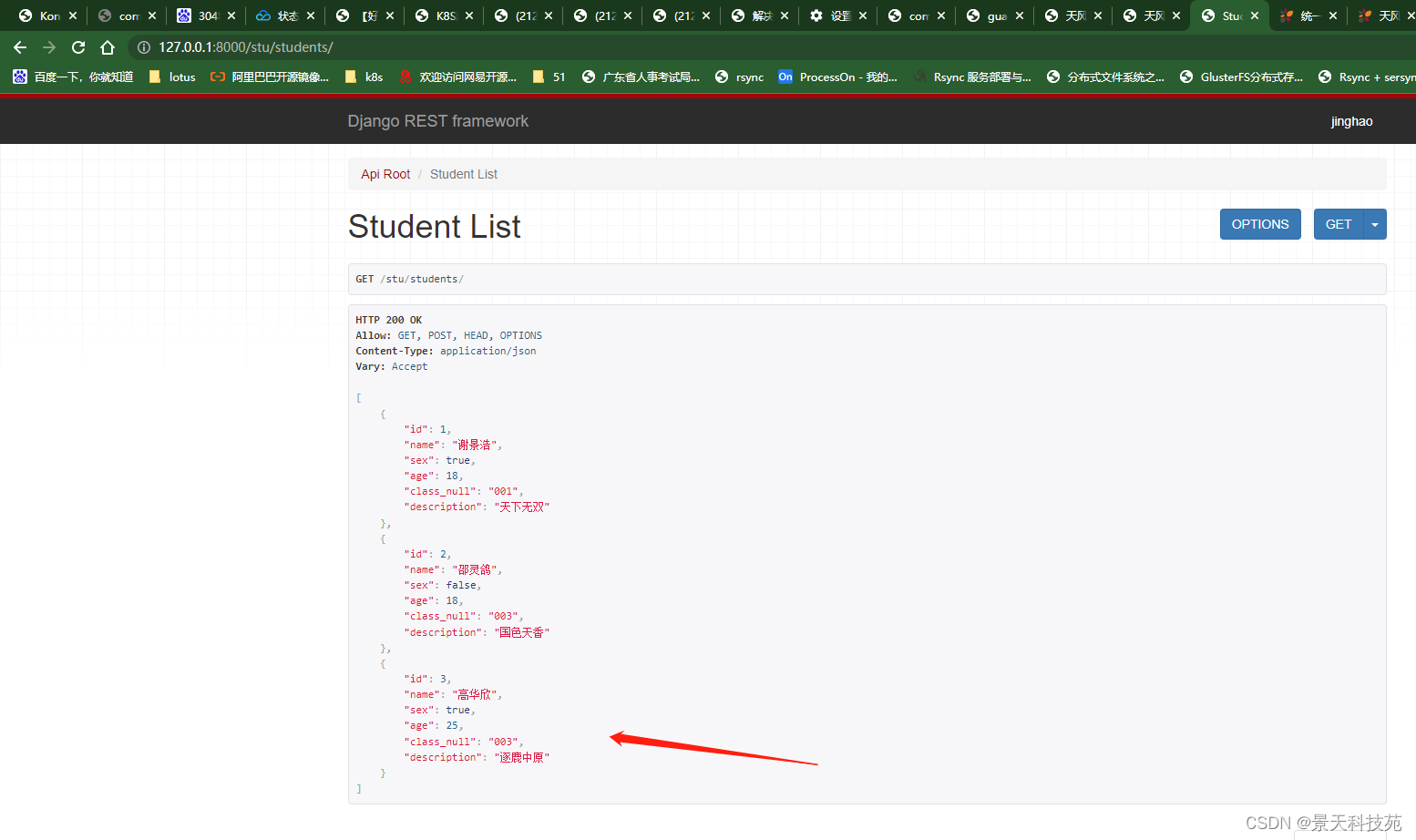
也可以查询指定id的数据
在浏览器中输入网址127.0.0.1:8000/stu/students/3/,可以访问获取单一学生信息的接口(id为3的学生),呈现如下页面:
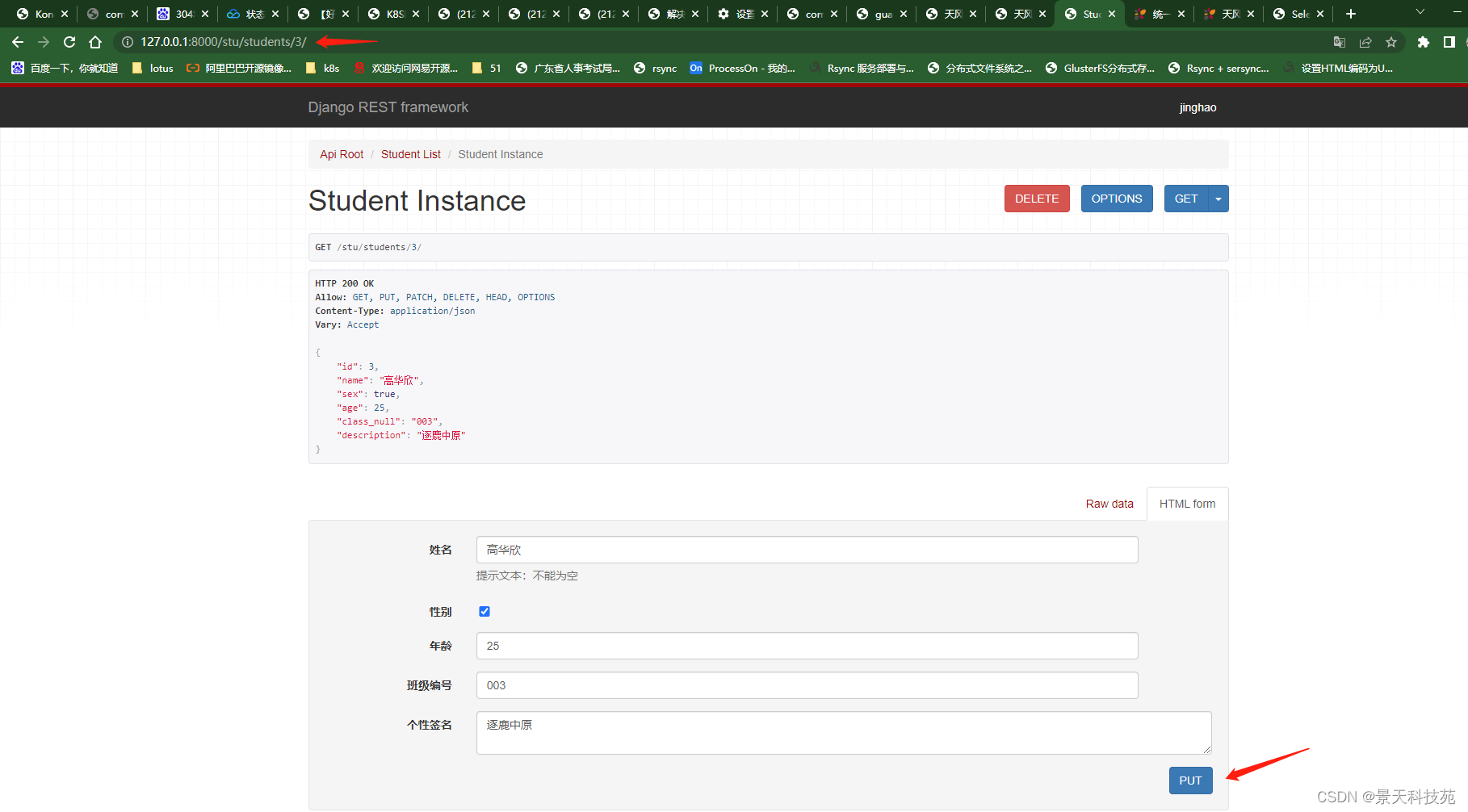
可以直接修改数据,然后点击put提交
点击put后,返回修改后的数据

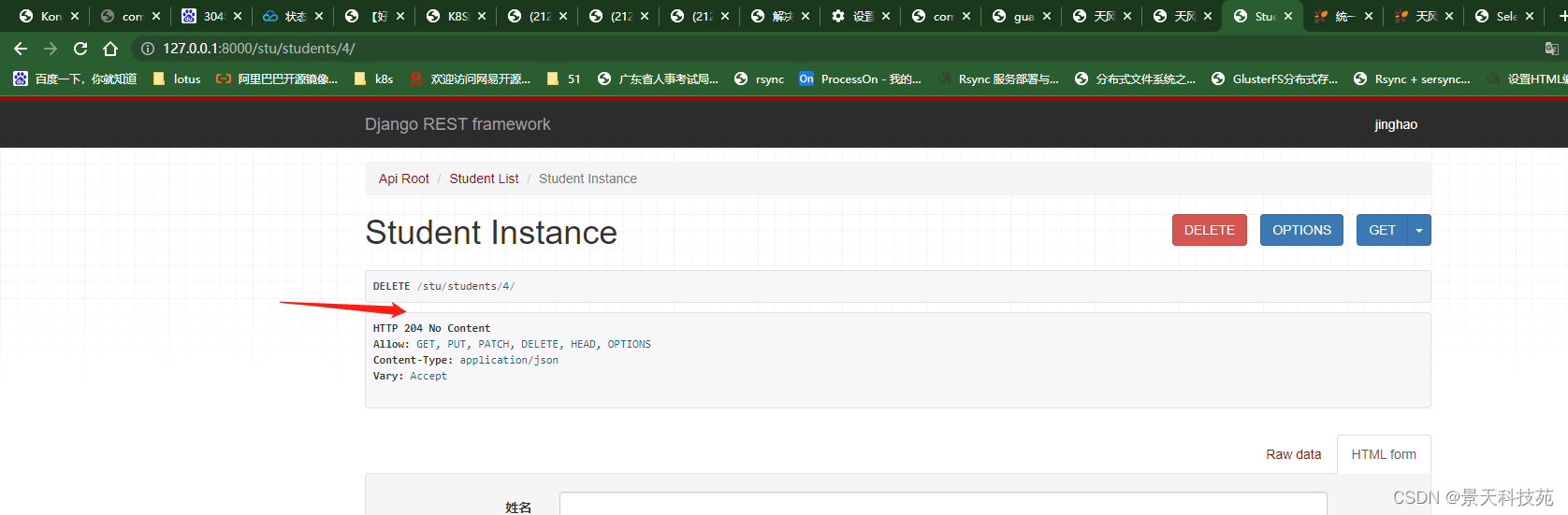
点击delete,可以删除本条记录
删除成功返回状态码204
序列化器类中,可以使用fields来明确字段,__all__表示包含所以字段,具体那些字段->fields = (‘title’,‘price’)
也可以序列化指定字段数据
访问接口查看
4.序列化器的使用
在ser里面创建个新的模型类
添加几条数据
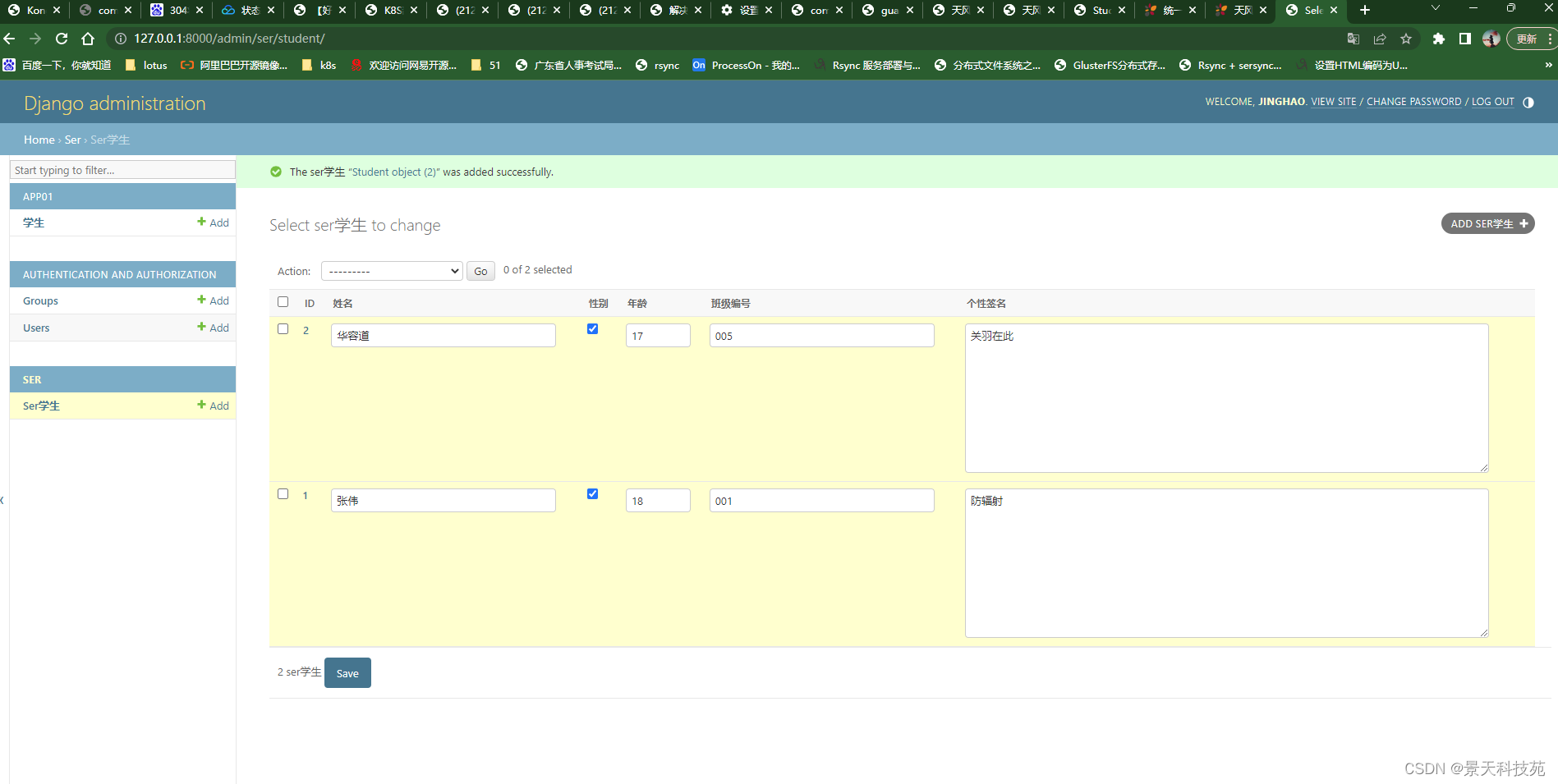
(1)创建序列化器
#先引入基础序列化器类
from rest_framework import serializers
from ser import models
"""
name = models.CharField(max_length=100,verbose_name="姓名",help_text='提示文本:不能为空')
sex = models.BooleanField(default=1,verbose_name="性别")
age = models.IntegerField(verbose_name="年龄")
class_null = models.CharField(max_length=5,verbose_name="班级编号")
description = models.TextField(max_length=1000,verbose_name="个性签名")
"""
#这个基础序列化类,能指定哪个字段序列化什么格式,可以指定序列化哪些数据,加工几条数据,返回几条数据
# 序列化哪些字段,就写与模型类中相同的名称
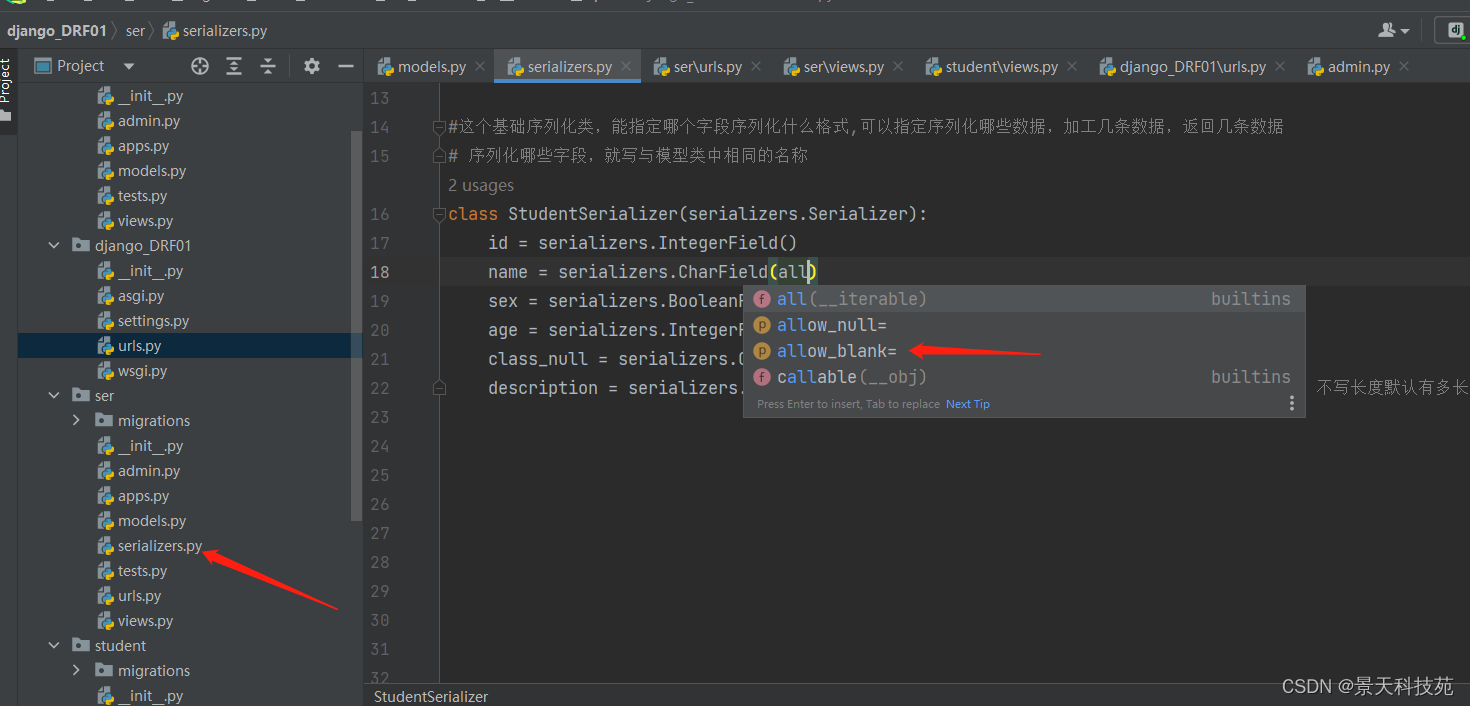
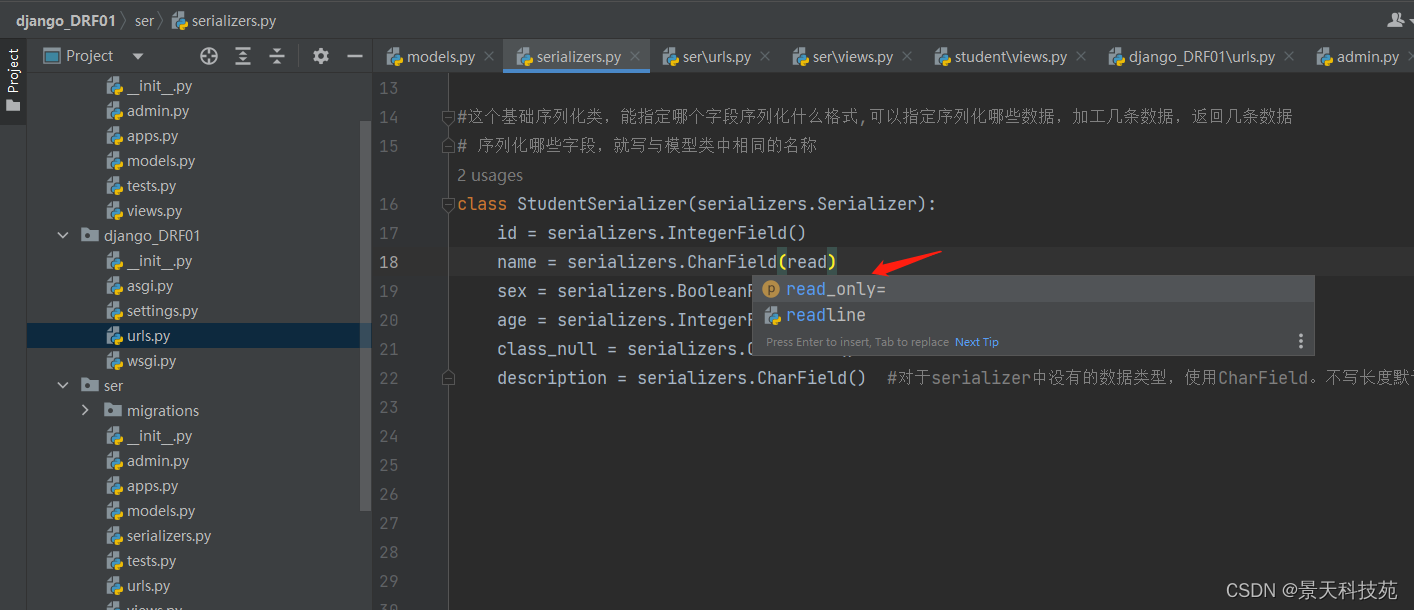
class StudentSerializer(serializers.Serializer):
id = serializers.IntegerField()
name = serializers.CharField()
sex = serializers.BooleanField()
age = serializers.IntegerField()
class_null = serializers.CharField()
description = serializers.CharField() #对于serializer中没有的数据类型,使用CharField。不写长度默认有多长序列化多长
这样的好处是,不想要哪个字段的数据,就不用序列化
视图类一样
from django.http import JsonResponse
from django.shortcuts import render
# Create your views here.
from django.views import View
from ser import models
from ser.serializers import StudentSerializer
class StudentView(View):
def get(self,request):
studentdata = models.Student.objects.filter()
#序列化多条数据,需要加上many=True,返回序列化对象
serializer_obj = StudentSerializer(instance=studentdata,many=True)
#返回列表类型数据
print(serializer_obj.data,type(serializer_obj.data))
#JsonResponse返回非字典类型数据,需要加上safe=False,中文显示中文
return JsonResponse(serializer_obj.data,safe=False, json_dumps_params={'ensure_ascii': False})
浏览器访问
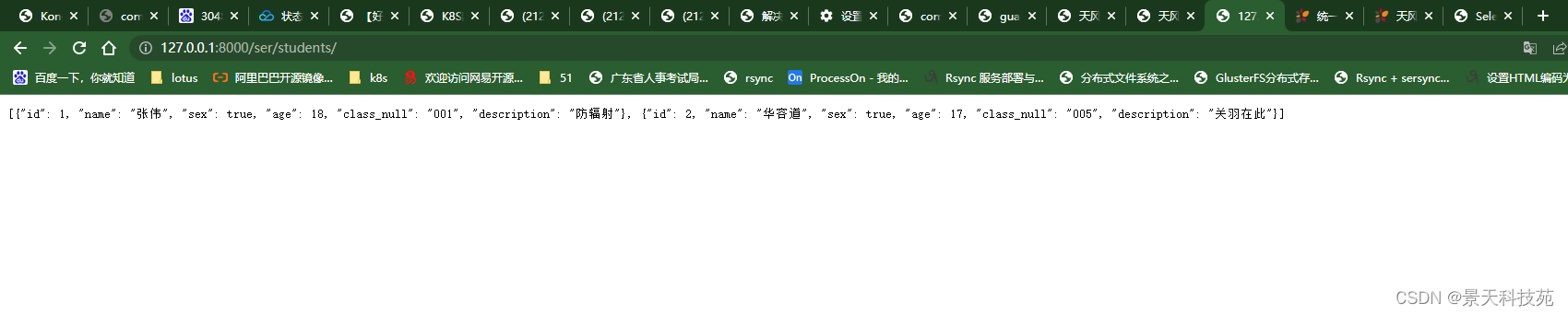
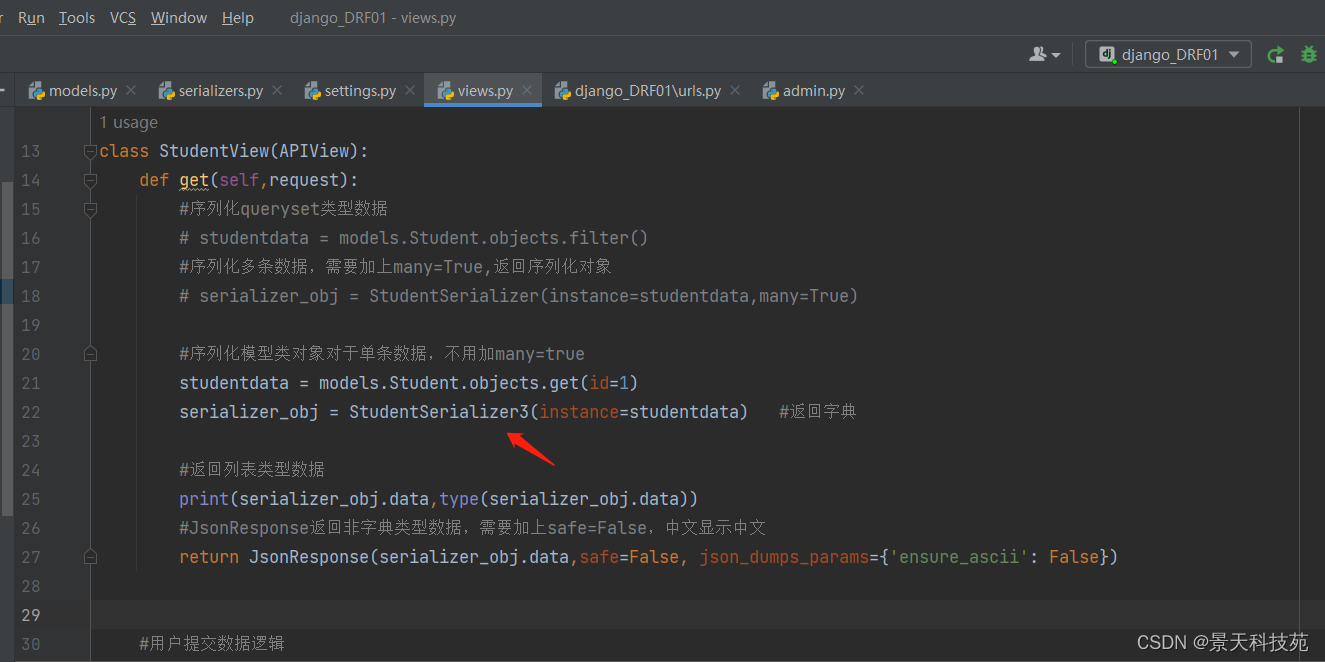
上面我们序列化queryset类型数据,我们也可以序列化模型类对象
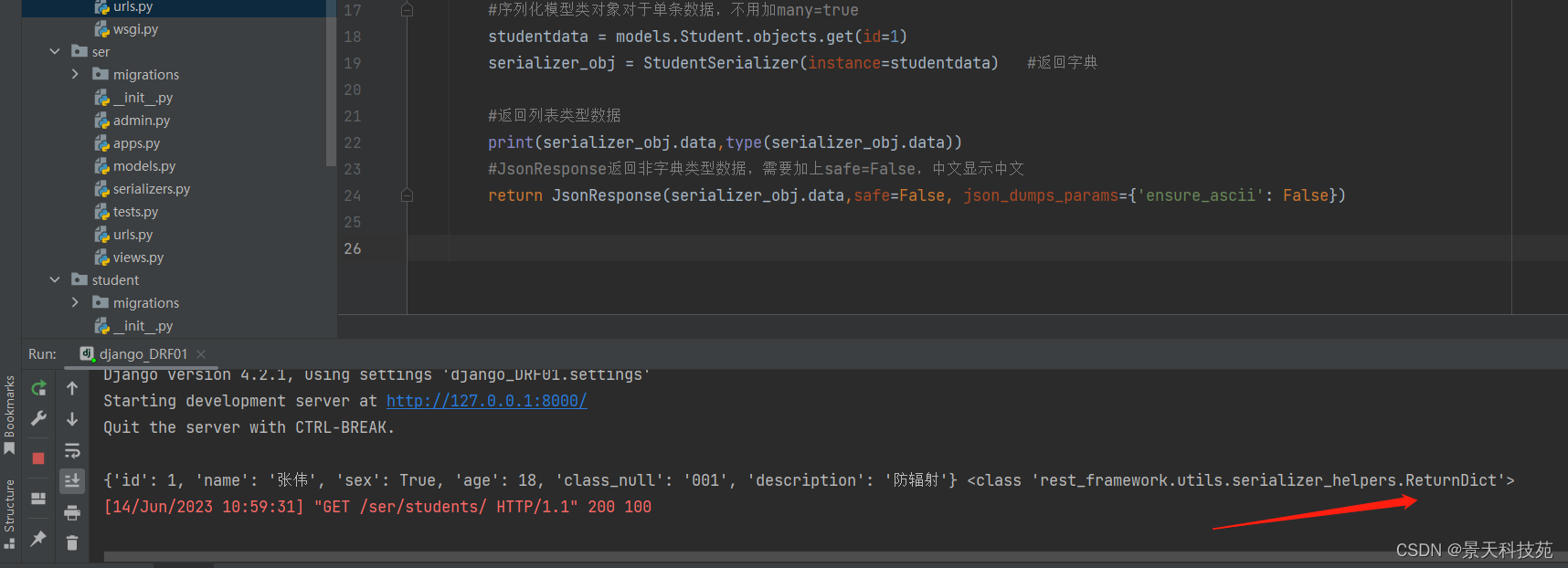
#序列化模型类对象对于单条数据,不用加many=true
studentdata = models.Student.objects.get(id=1)
serializer_obj = StudentSerializer(instance=studentdata) #返回字典
返回的是字典
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
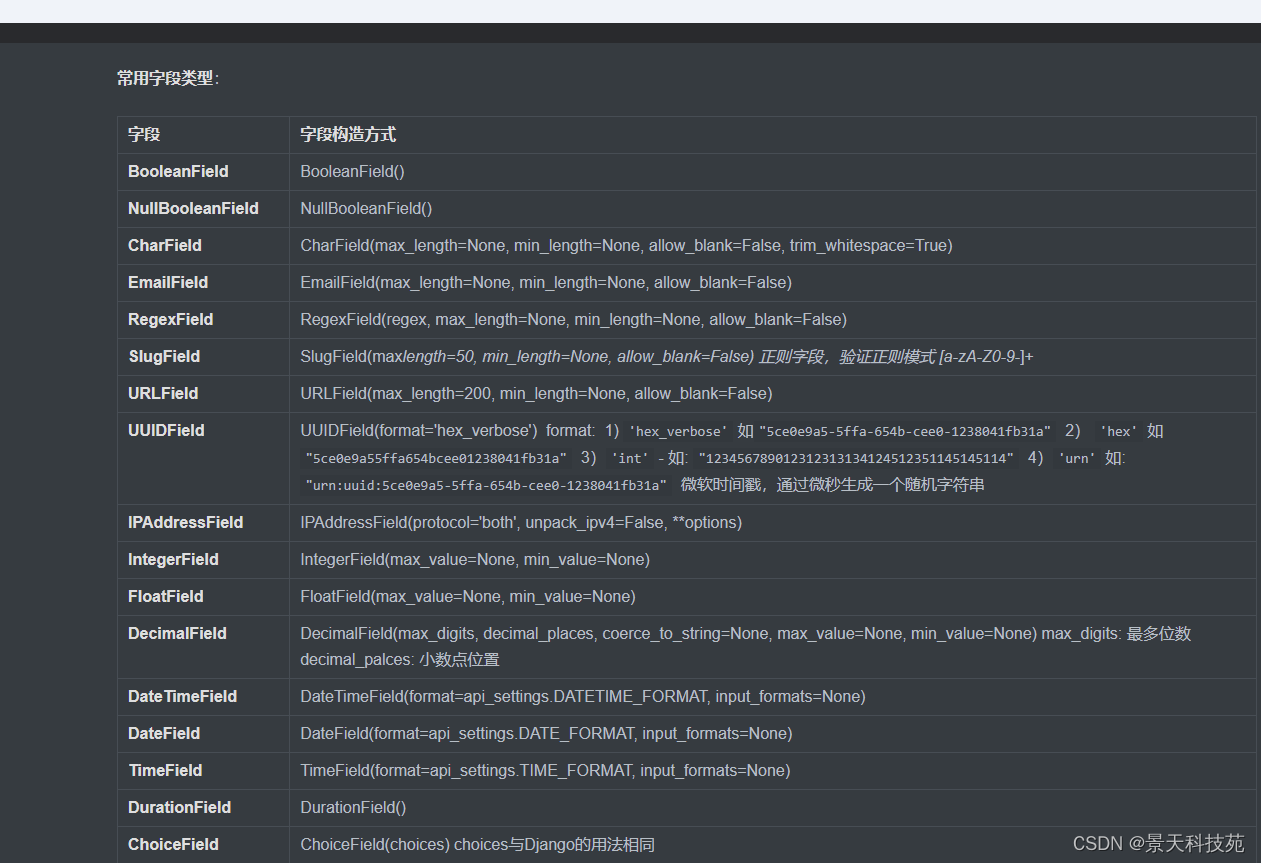
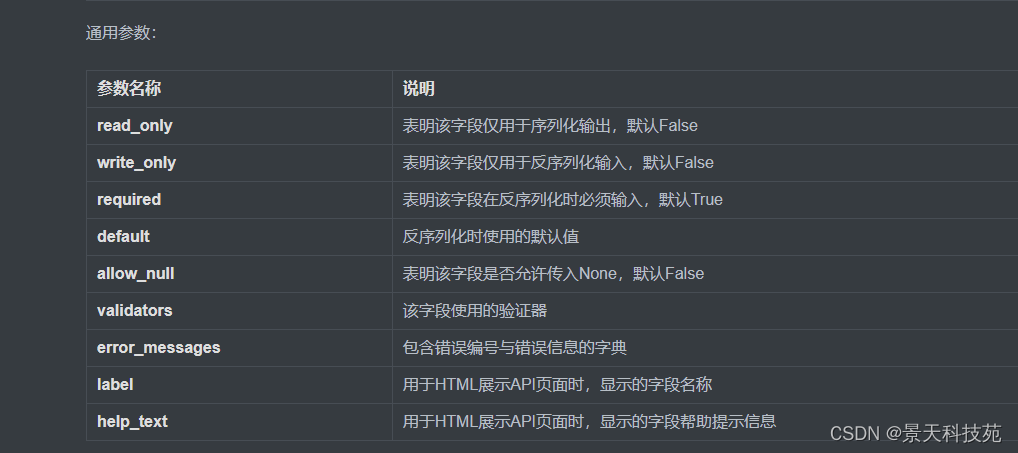
常用字段类型:

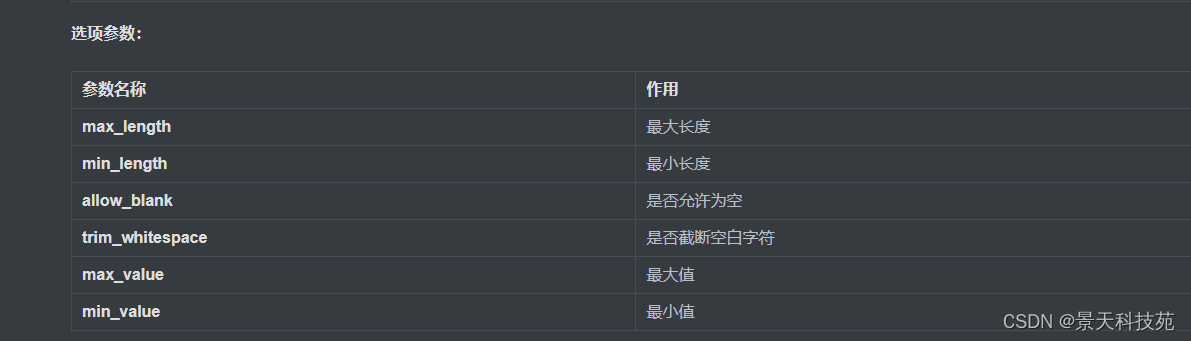
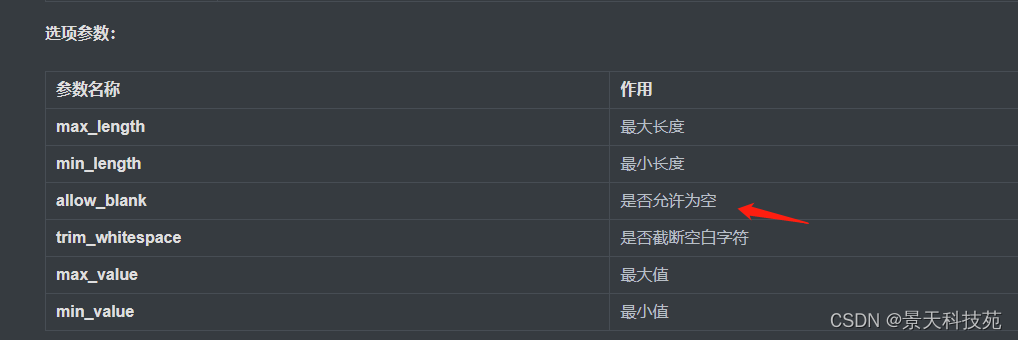
选项参数
这个是在序列化类里面,在序列化相关字段时,可以添加一些参数
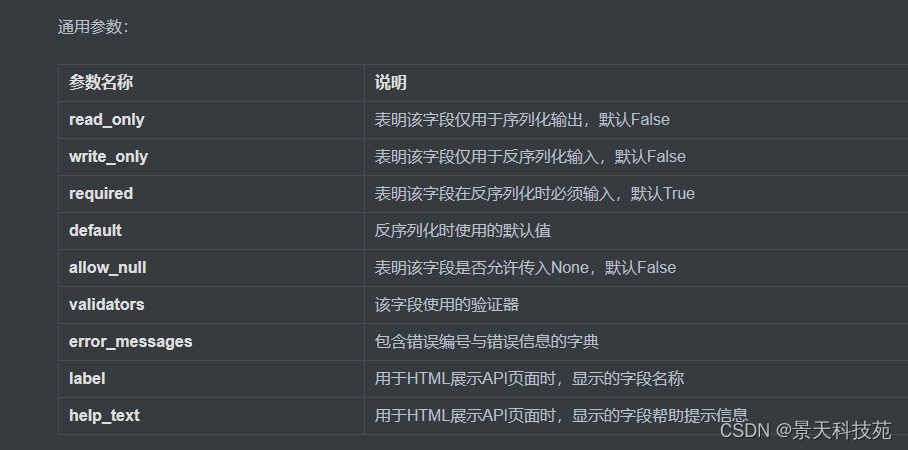
通用参数,默认required 默认是True
5. 反序列化器使用
序列化器的使用分两个阶段:
- 在客户端请求时,使用序列化器可以完成对数据的反序列化。
- 在服务器响应时,使用序列化器可以完成对数据的序列化。
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
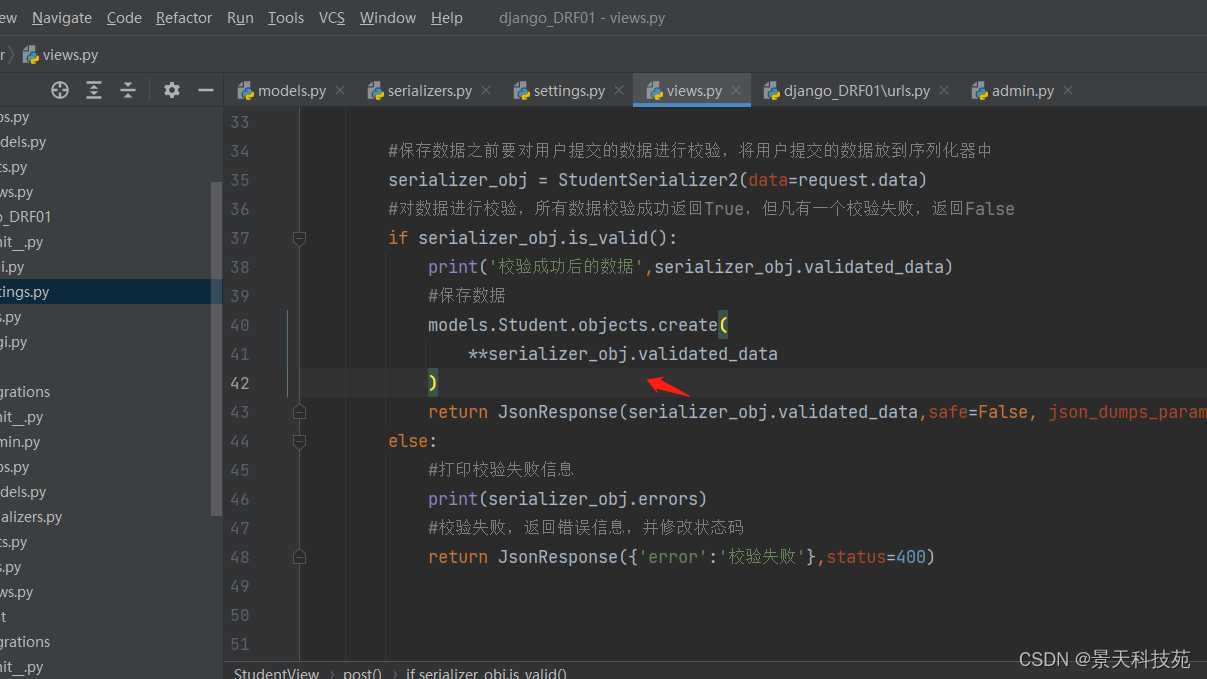
后台收到前端发过来的数据,在保存之前要对数据进行校验,符合要求再往里面存
不符合要求报错
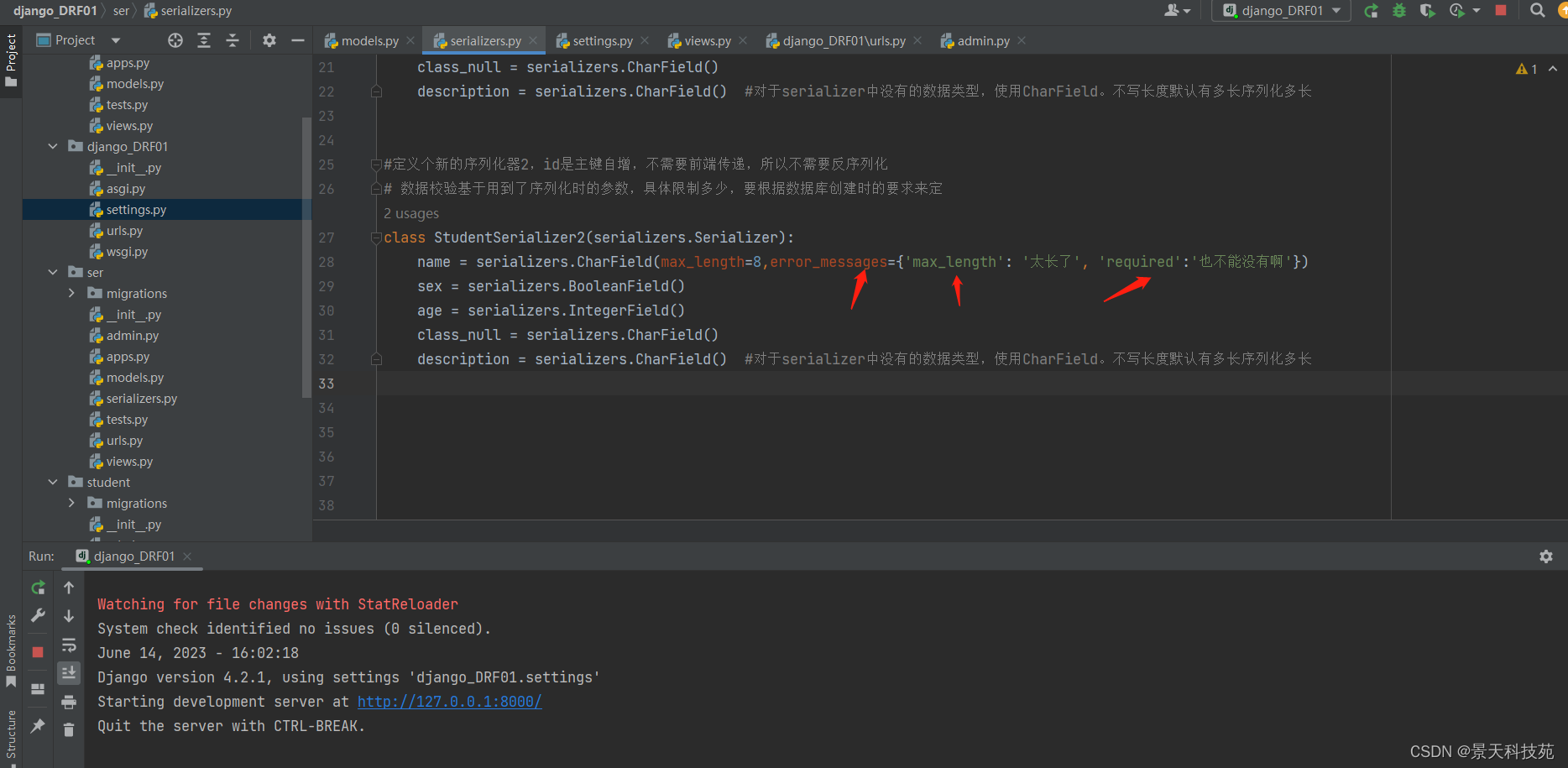
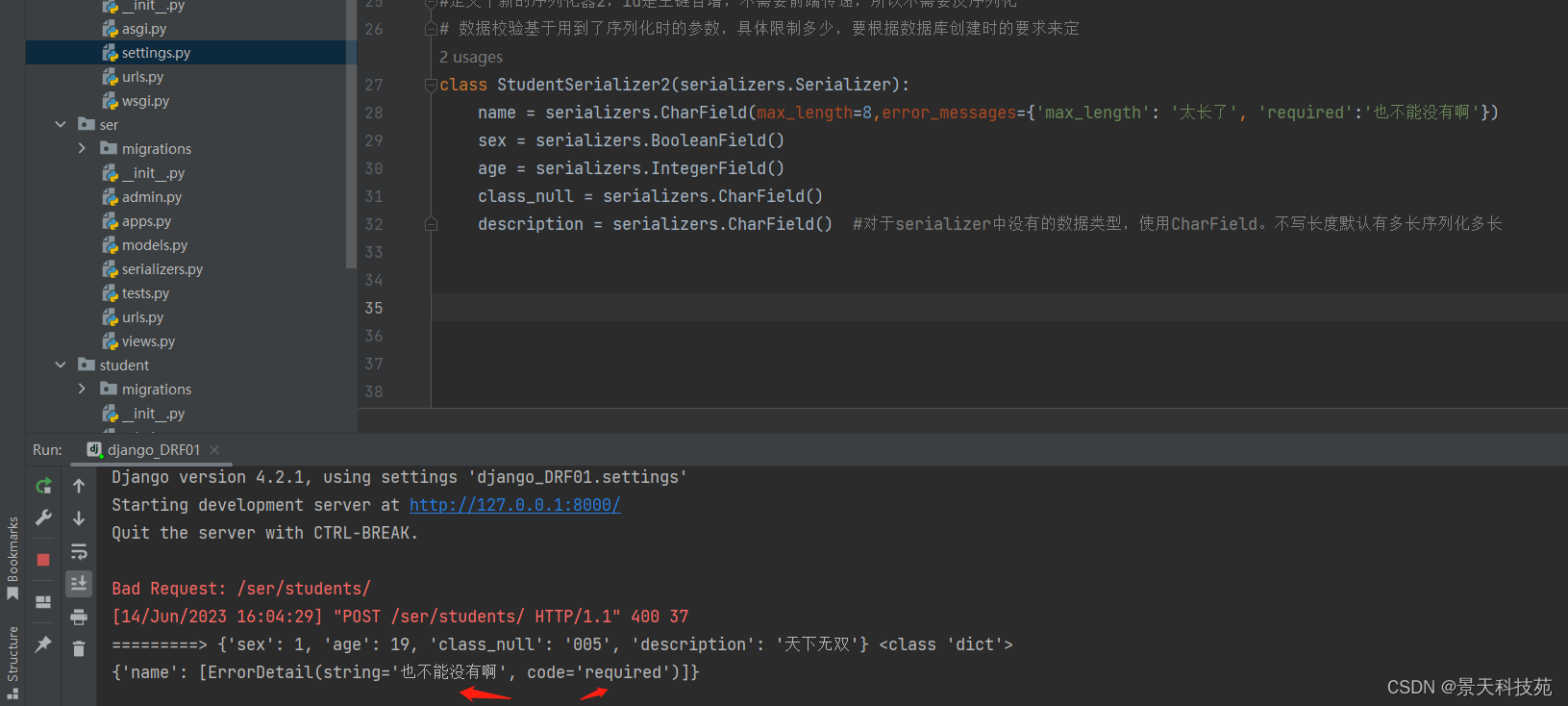
#定义个新的序列化器2,id是主键自增,不需要前端传递,所以不需要反序列化
# 数据校验基于用到了序列化时的参数,具体限制多少,要根据数据库创建时的要求来定
class StudentSerializer2(serializers.Serializer):
name = serializers.CharField(max_length=8)
sex = serializers.BooleanField()
age = serializers.IntegerField()
class_null = serializers.CharField()
description = serializers.CharField() #对于serializer中没有的数据类型,使用CharField。不写长度默认有多长序列化多长
反序列化器校验,基于用户提交的数据,再在视图函数写个post方法
#用户提交数据逻辑
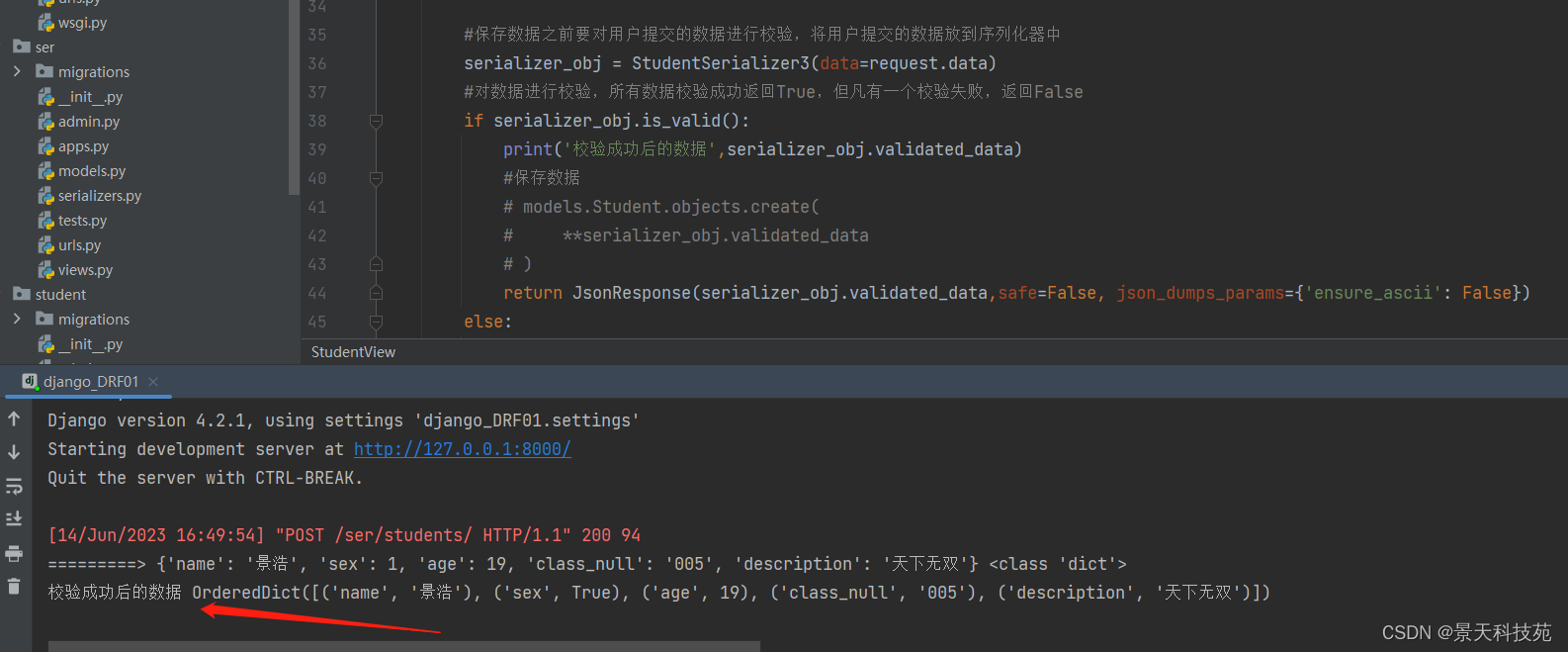
def post(self,request):
#保存数据之前要对用户提交的数据进行校验,将用户提交的数据放到序列化器中
serializer_obj = StudentSerializer2(data=request.POST)
#对数据进行校验,所有数据校验成功返回True,但凡有一个校验失败,返回False
if serializer_obj.is_valid():
print('校验成功后的数据',serializer_obj.validated_data)
return JsonResponse(serializer_obj.validated_data,safe=False, json_dumps_params={'ensure_ascii': False})
else:
#打印校验失败信息
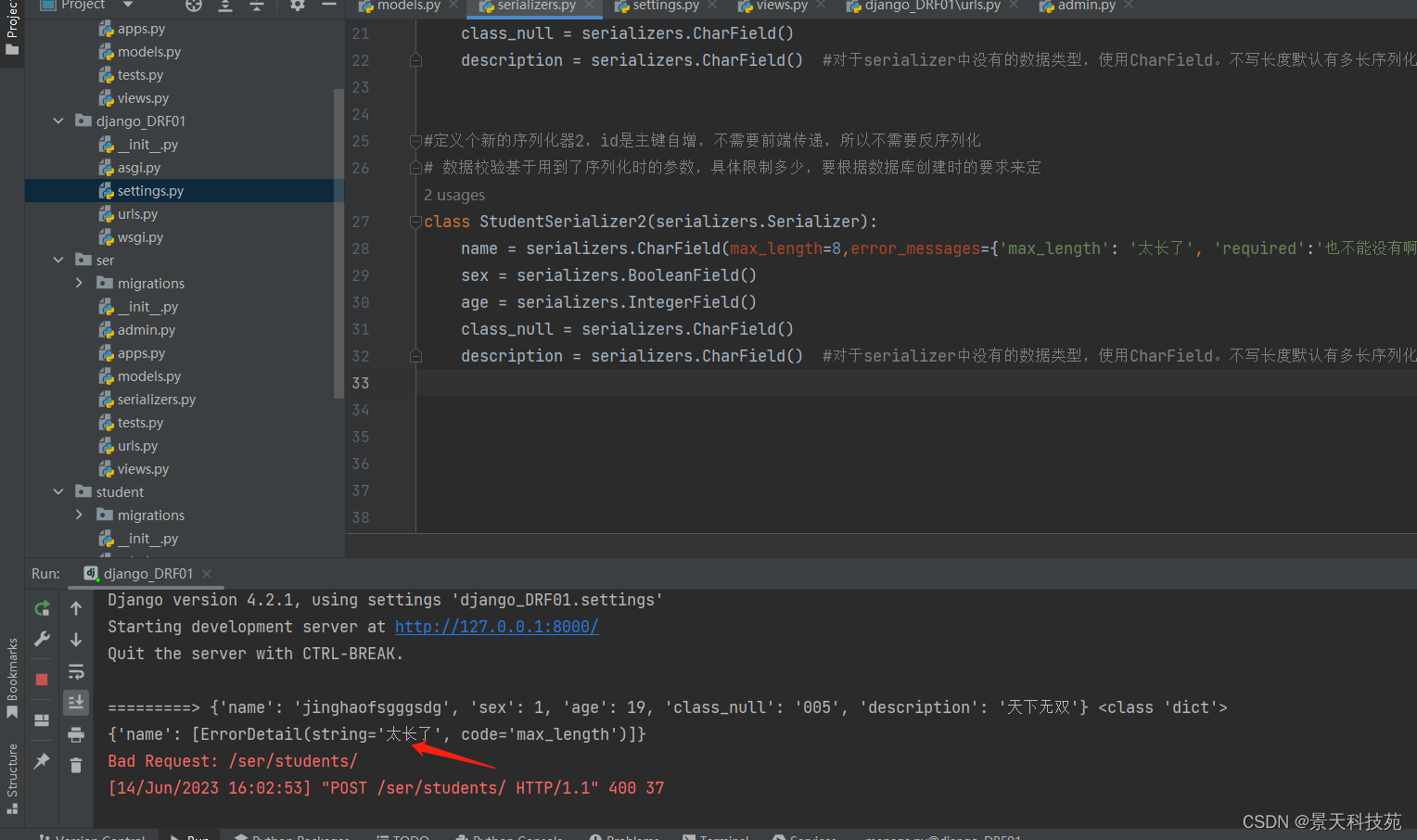
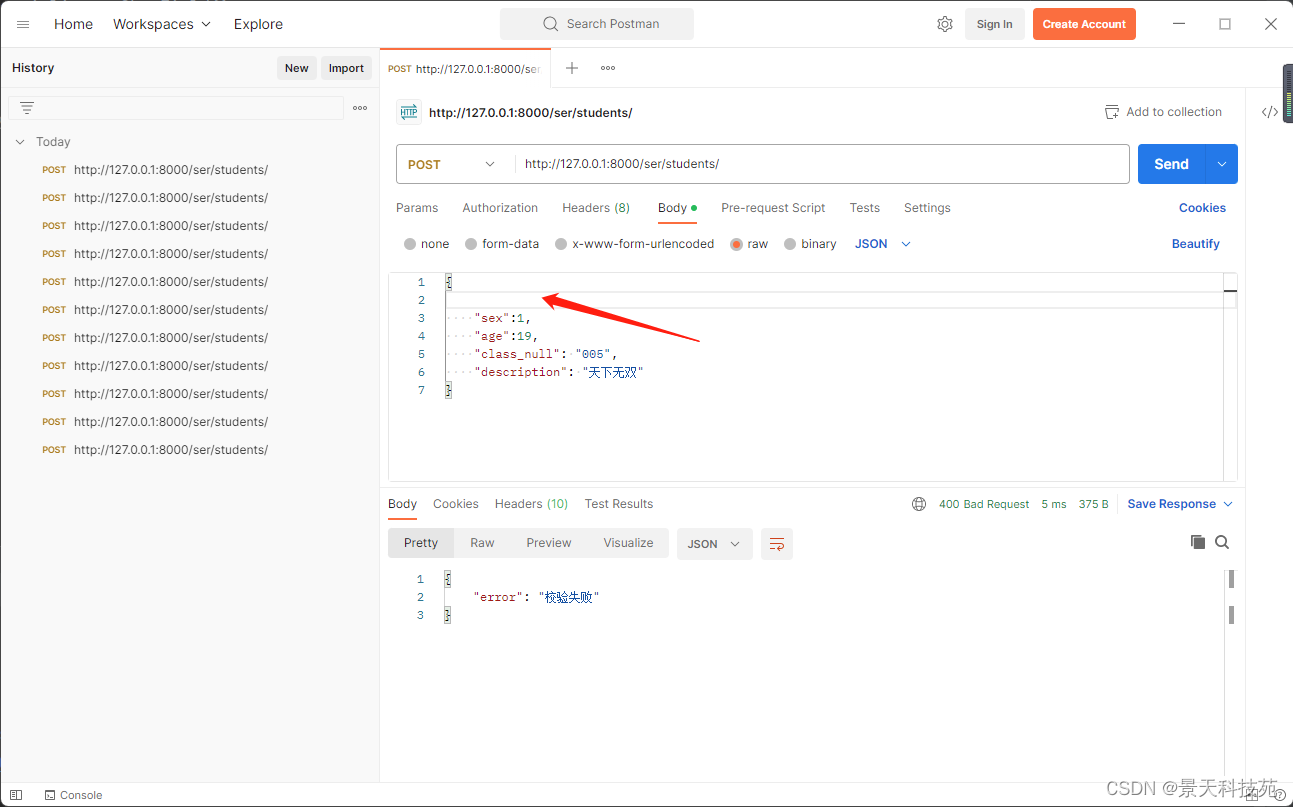
print(serializer_obj.errors)
#校验失败,返回错误信息,并修改状态码
return JsonResponse({'error':'校验失败'},status=400)
我们借助接口调试工具postman或国产的apipost来调试
我们使用国产的apipost,可以设置请求类型,携带的请求参数
可以原生row的json类型提交,也可以form表单的www-form-urlencoded,form-data
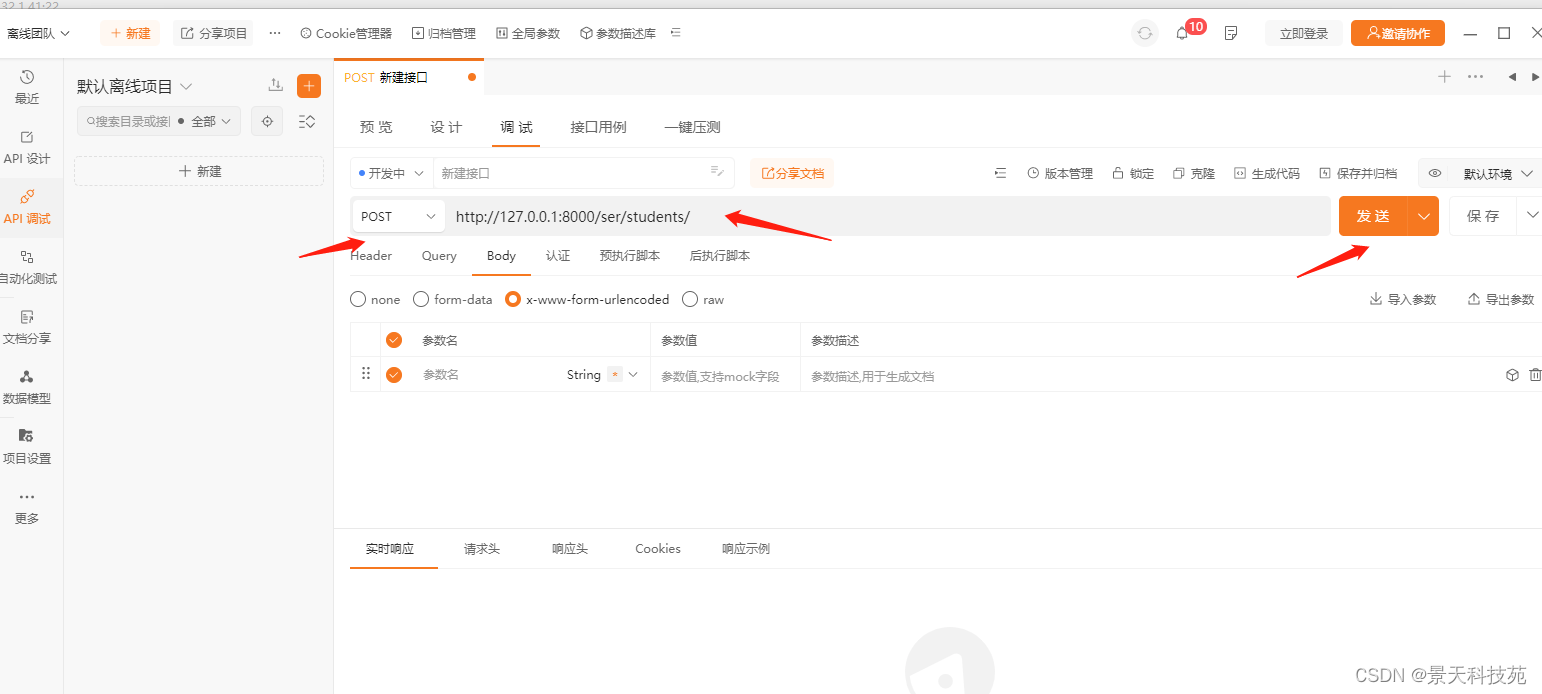
apipost功能还是太少,我们使用postman
向后台传输原生json类型
注意,json 键和值如果是字符串类型,必须用英文双引号
最后一对键值对后面不能有逗号
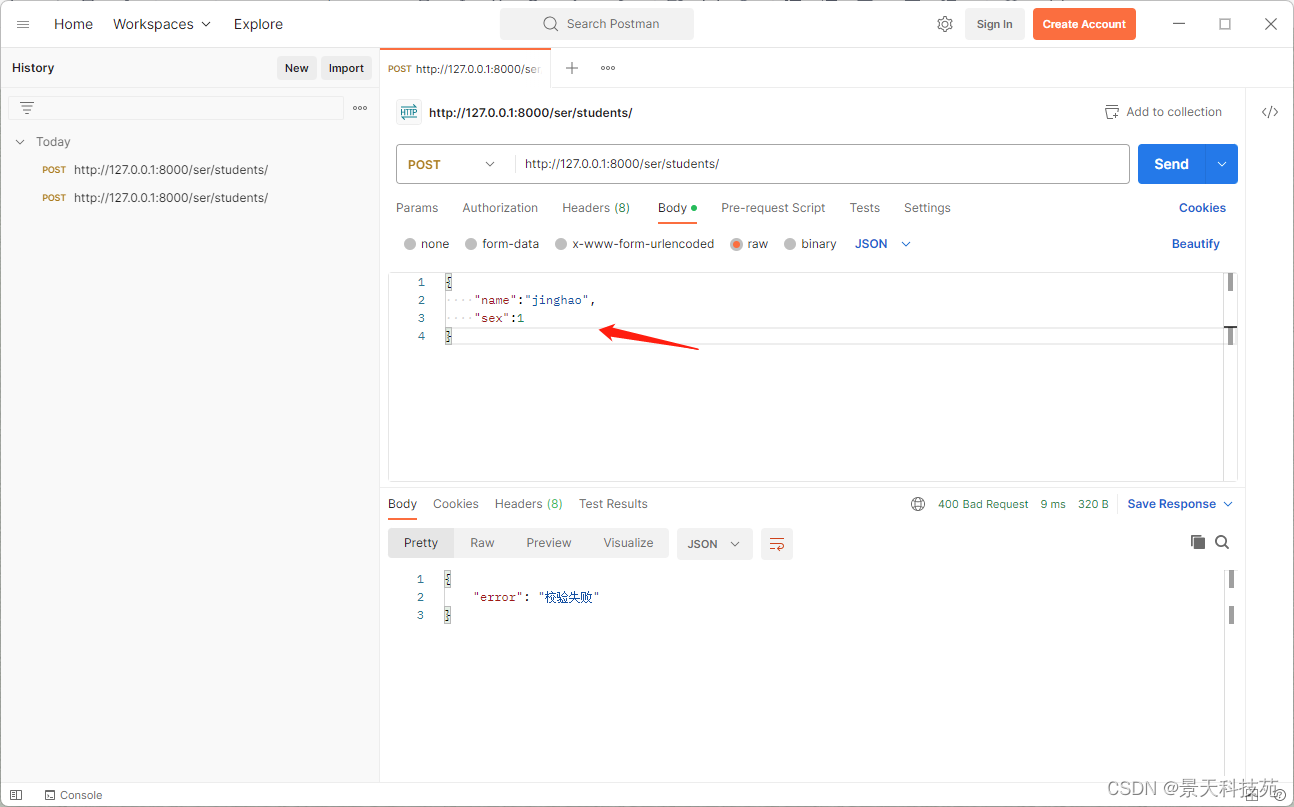
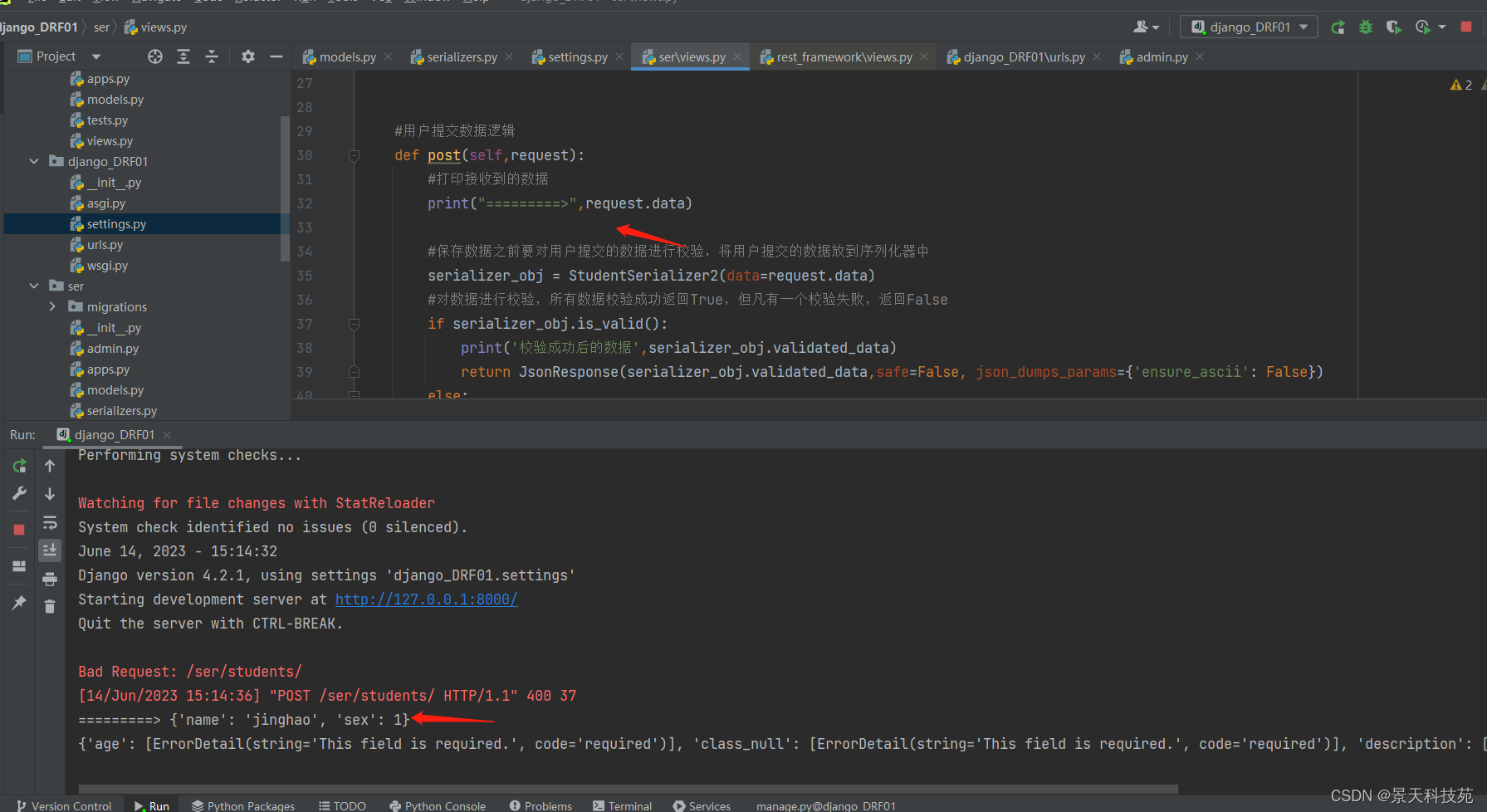
后台打印可知,没接收到数据,因为Django默认解析不了json类型数据
一般情况下,需要我们通过request.body将数据取出来,然后自己手动序列化解析
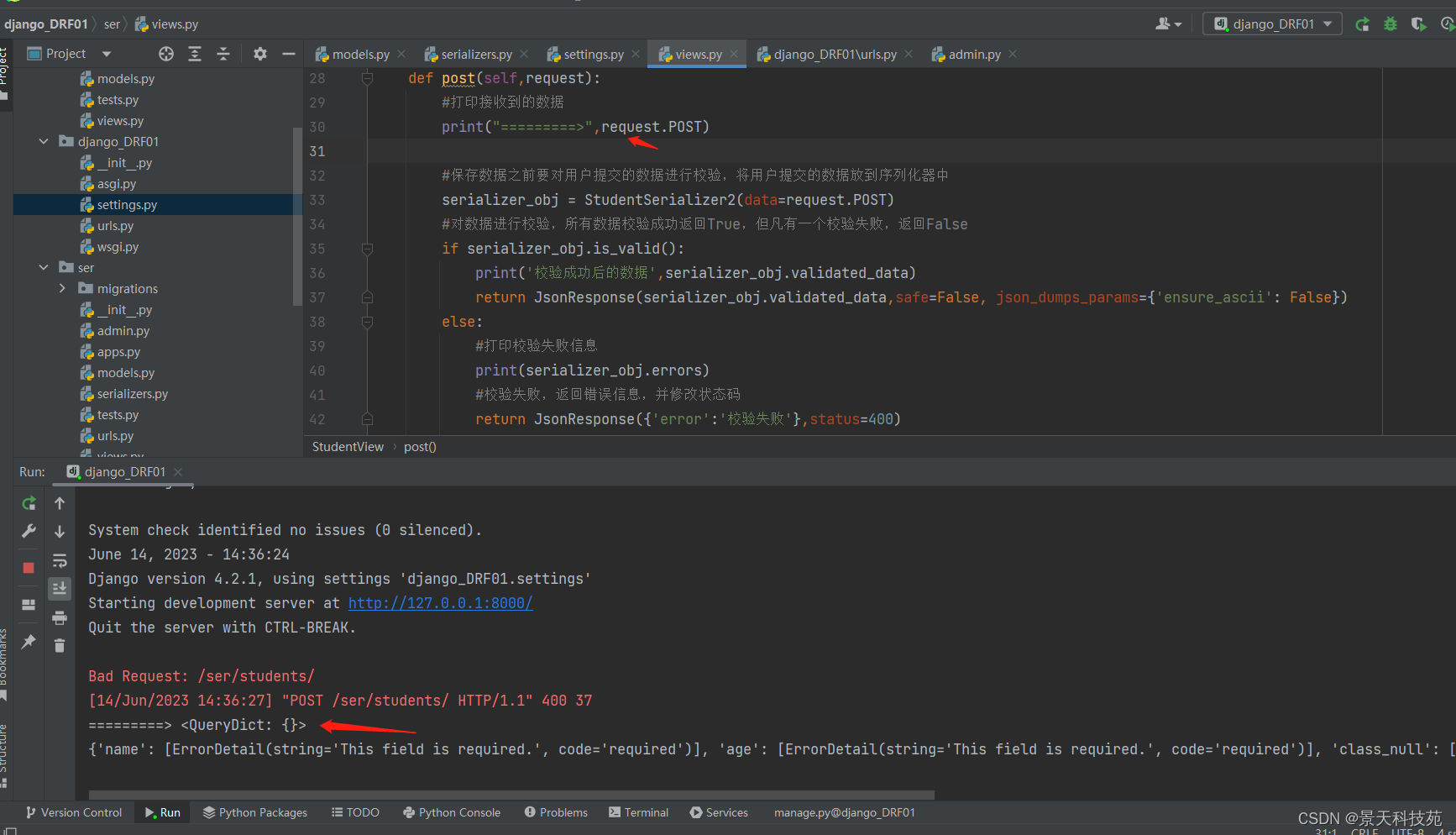
现在我们通过DRF来帮我们自动解析,简化工作量
视图类继承drf的apiview from rest_framework.views import APIView
继承了APIView之后,视图类定义的请求方法中的request 就被重新加工了一遍
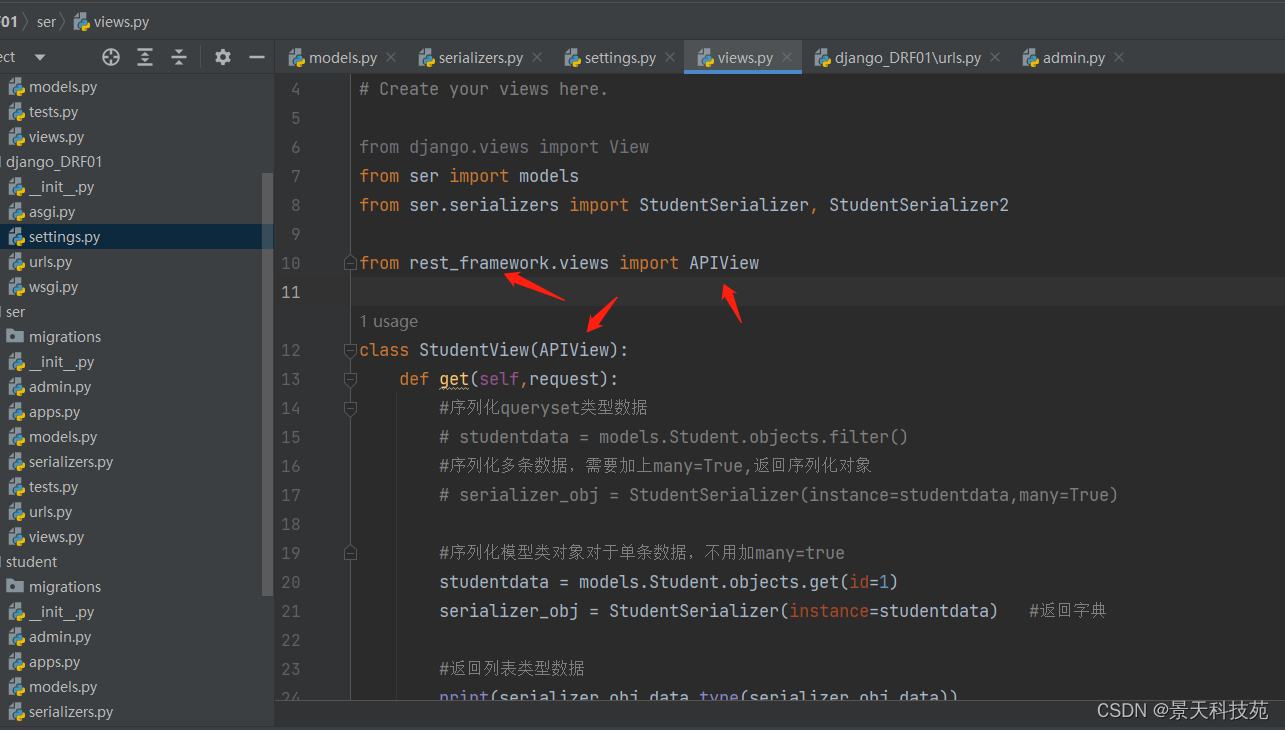
APIView类还是继承的View,对View进行了拓展
对View里面的request进行了扩展
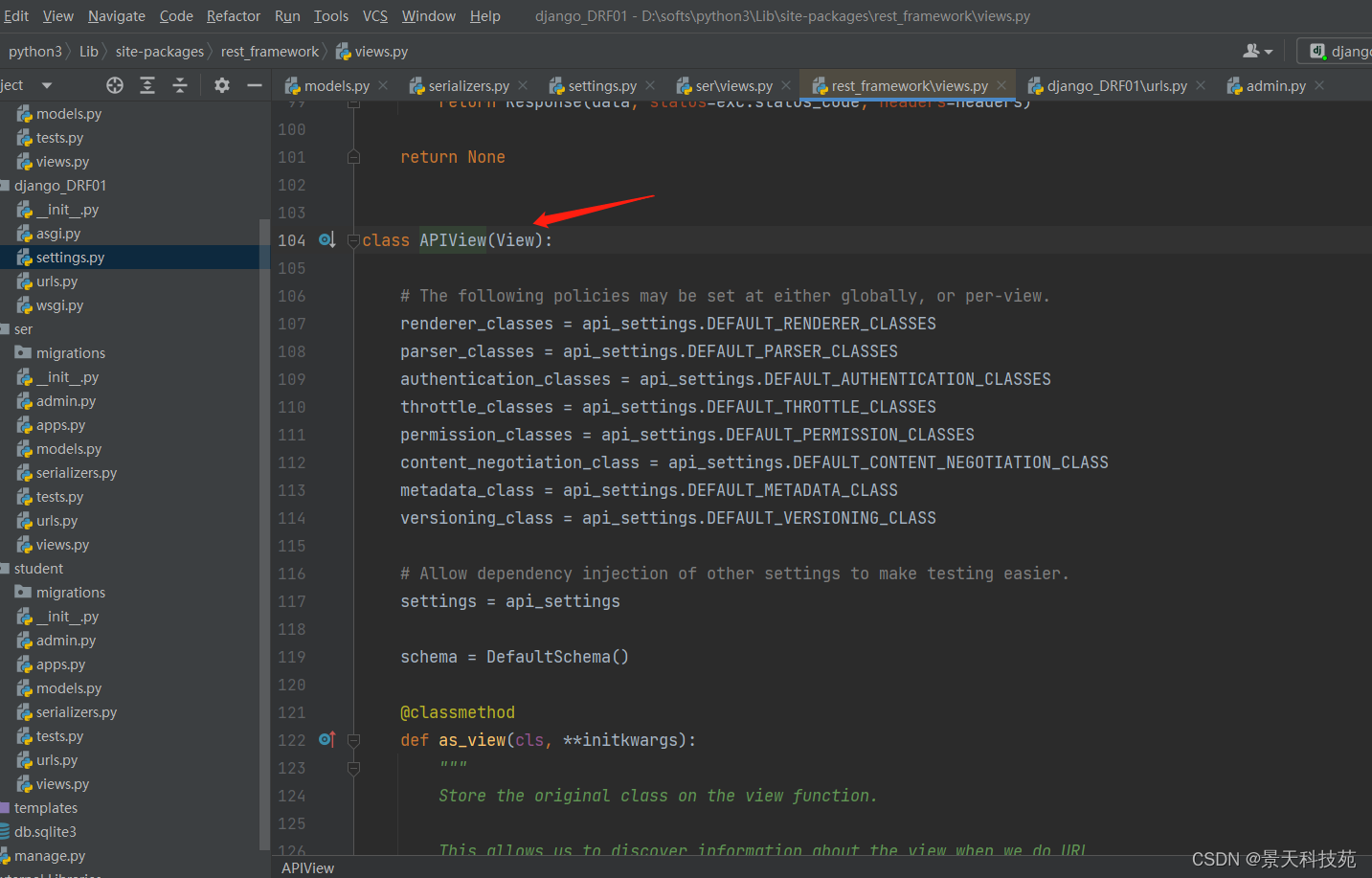
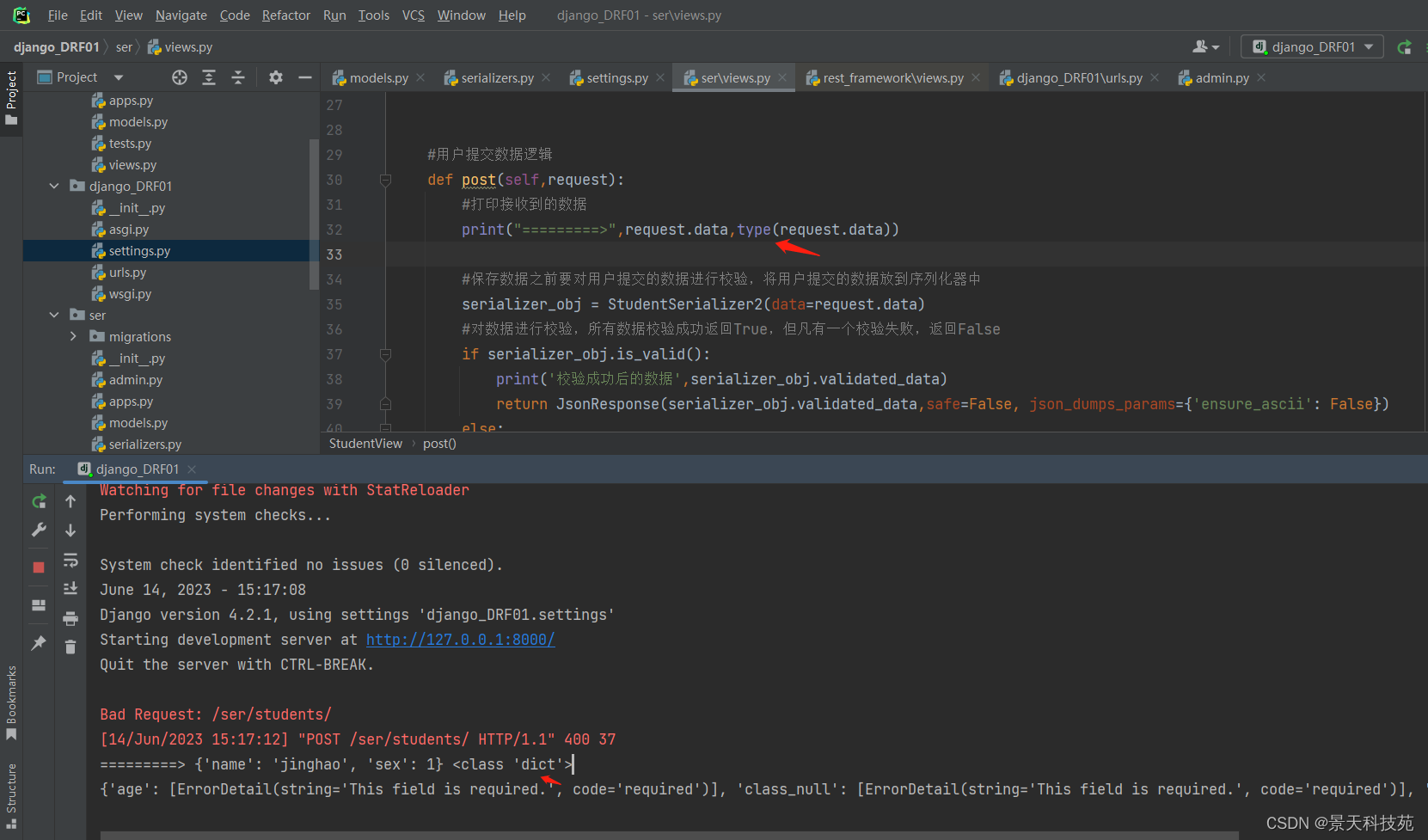
扩展后的request,再从前端拿数据,不用request.POST了 使用request.data
request.data就能获取到前端post请求提交过来的json数据
不管什么格式,都能解析出来
request.data 返回解析后的请求体数据。类似Django中标准的request.POST和request.FILES属性,但是能提供如下属性
包含了解析后的文件和非文件数据
包含了对POST,PUT,PATCH请求方式解析后的数据
利用了REST framework的parsers解析器,不仅支持表单类型数据(unlencoded/data),也支持JSON数据(application/json)
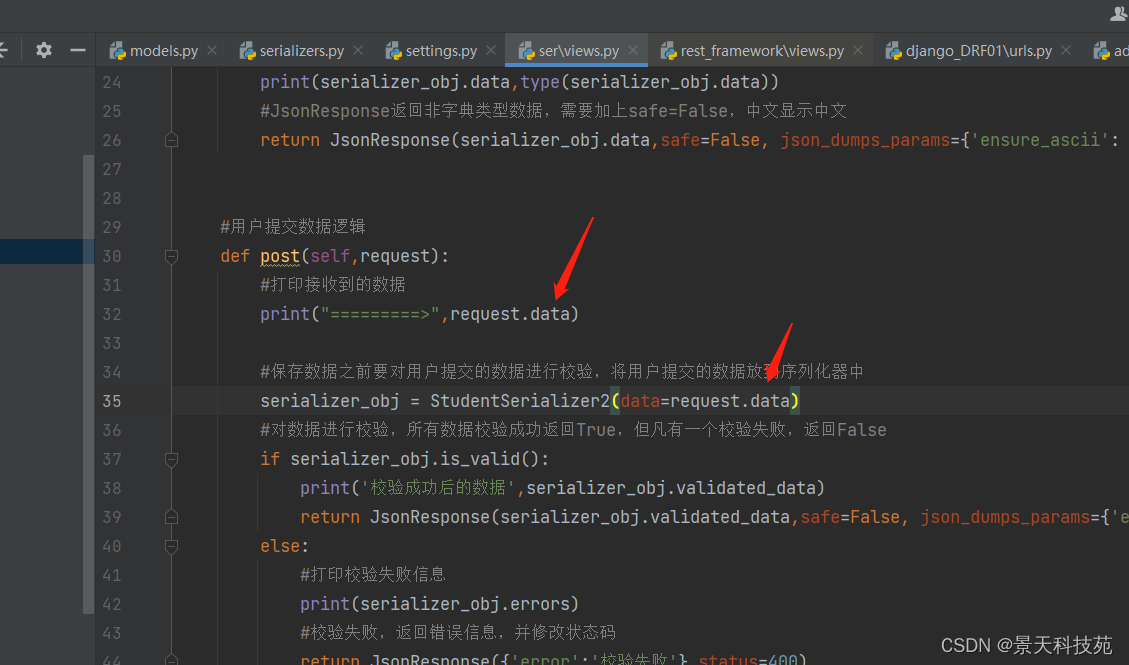
此时,重启服务器,postman发送post请求
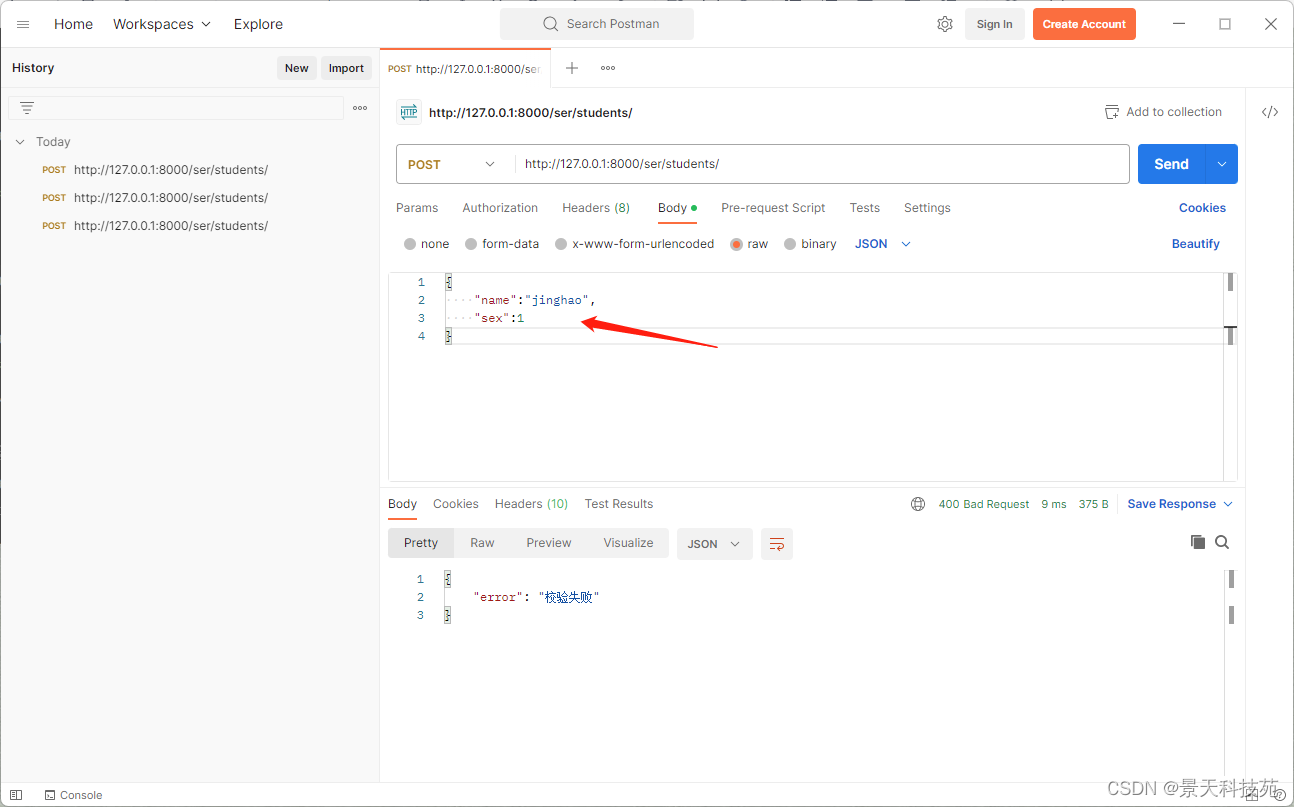
后台已经获取到,获取到的就是字典类型数据
当name字段长度超过限制,则会报错
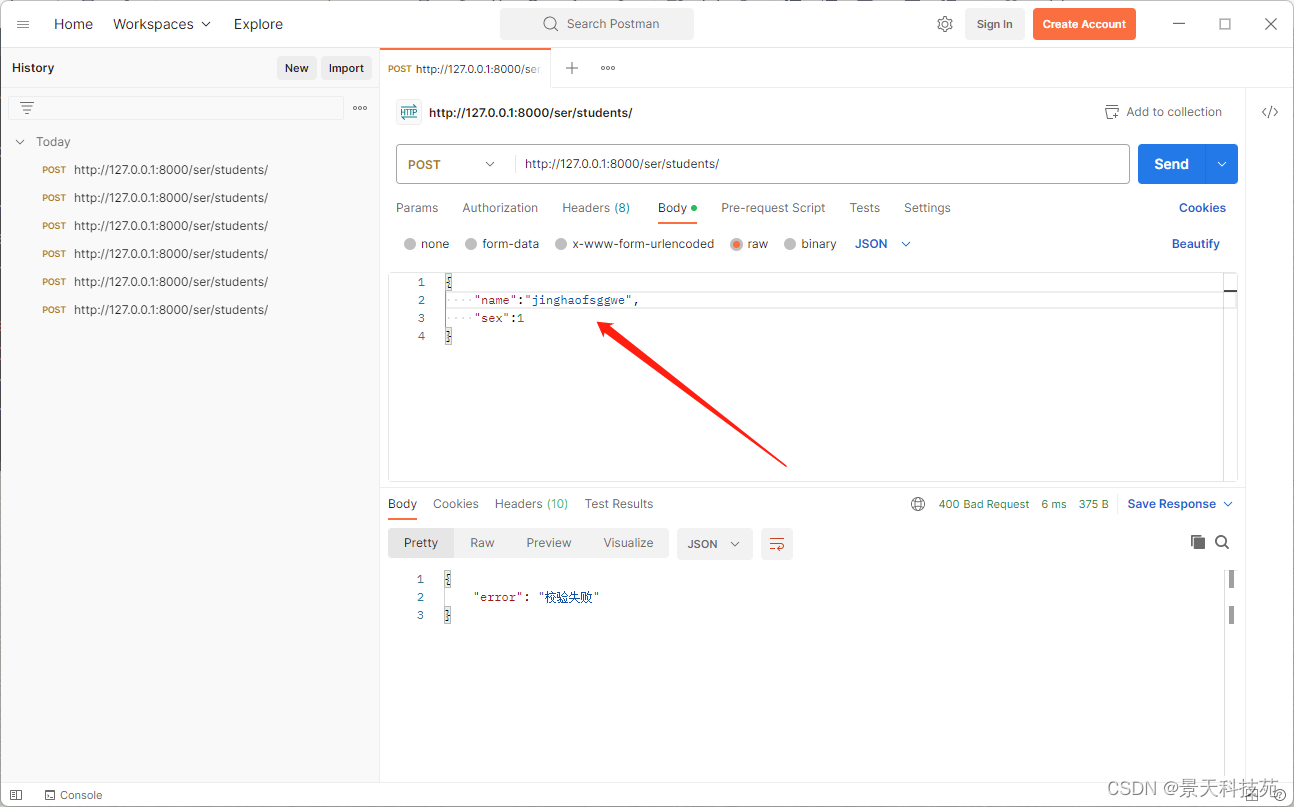
查看打印的错误信息,code指明哪个参数校验报的错
发送符合要求的字段,就不再报错
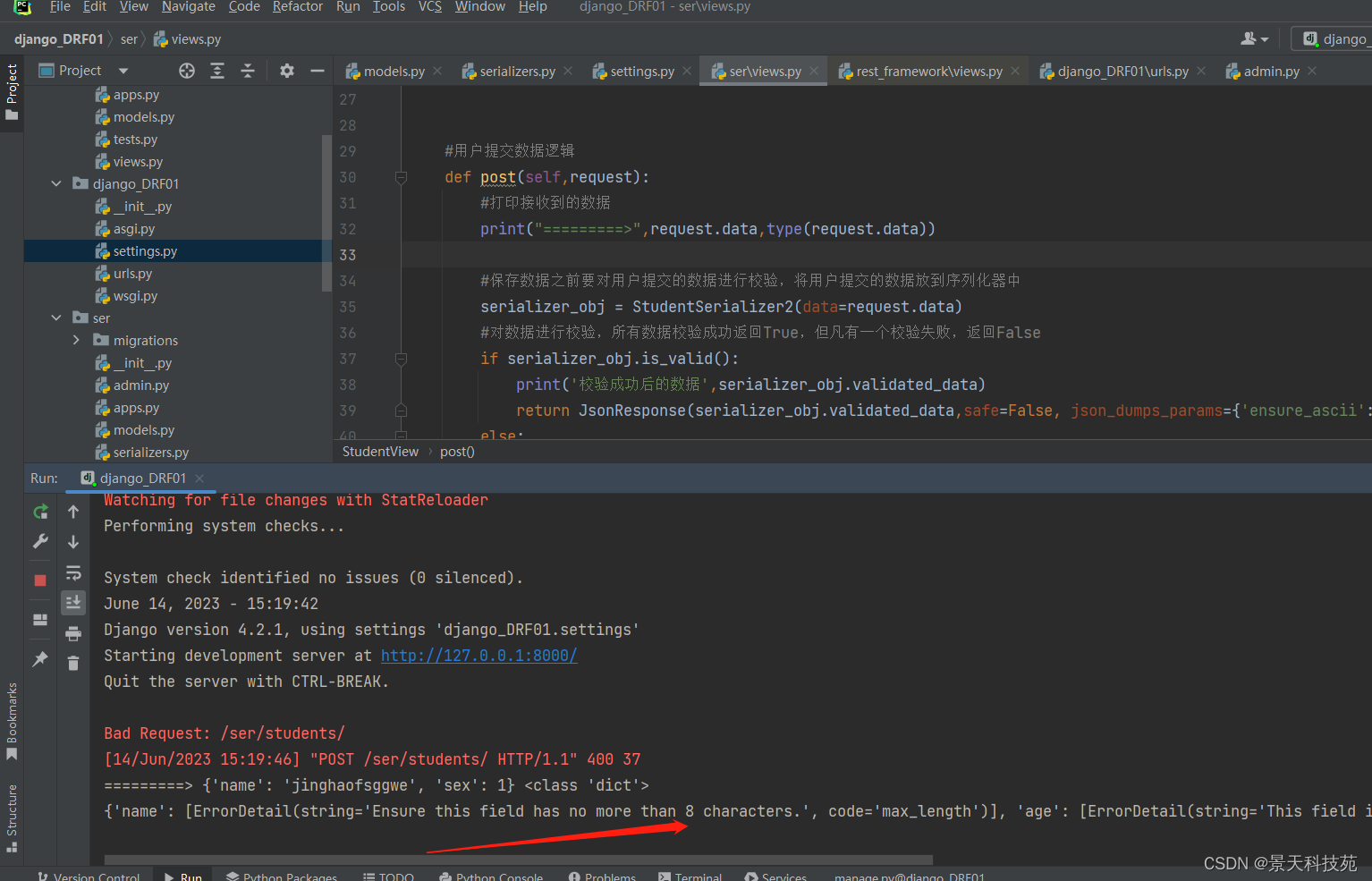
现在我们发送个正确的post请求
返回正常的json类型数据
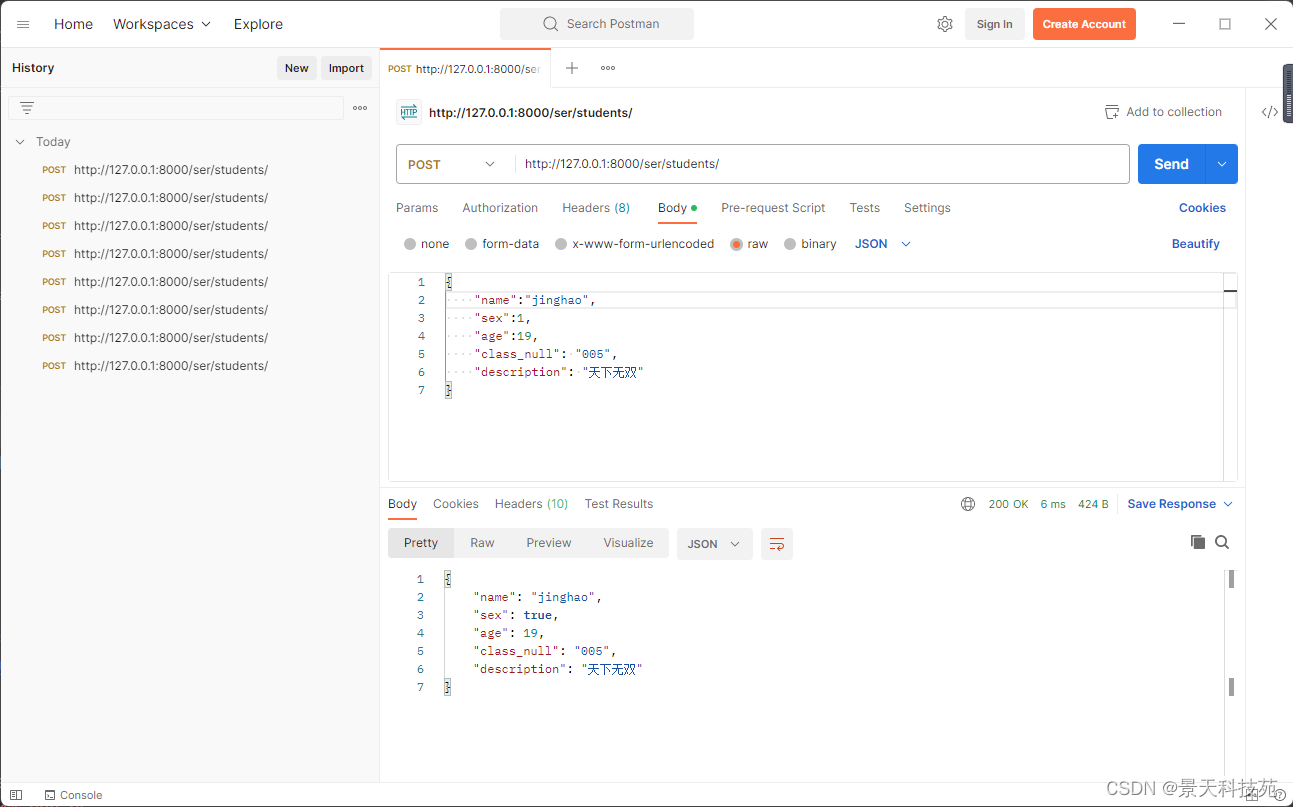
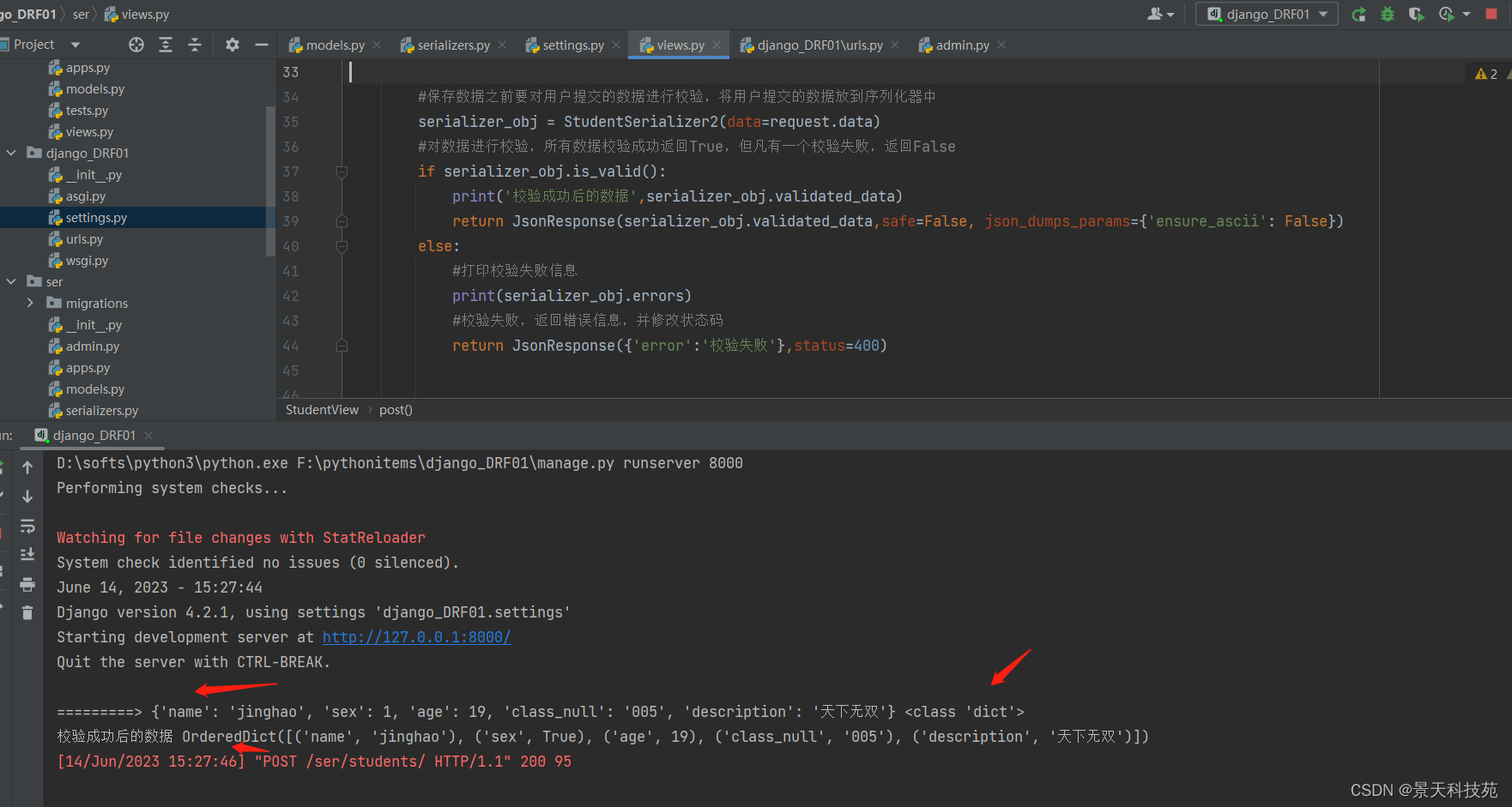
请求正常,就保存数据
allow_blank,默认为False, 空字符串 如果想要实现不传数据,需要结合required =False
validators校验函数
a).可以在序列化器字段上使用validators函数指定自定义的校验规则
b).validators值必须为序列类型(类表),在列表中可以添加多个校验规则
c).DRF框架自带的UniqueValidator校验器,必须指定queryset参数指定查询集对象,用于对该字段的唯一性进行校验,UniqueValidator里面还可以使用message指定自定义报错信息
在序列化器需要反序列化输入校验的字段中,指定validators=[校验规则1,校验规则2...]参数,可以使用drf自带的校验规则UniqueValidator, 也可以使用自定义的的校验规则
error_messages 可以自定义报错信息 自定义错误信息用字典包裹,针对每个参数定义报错信息
发送post请求
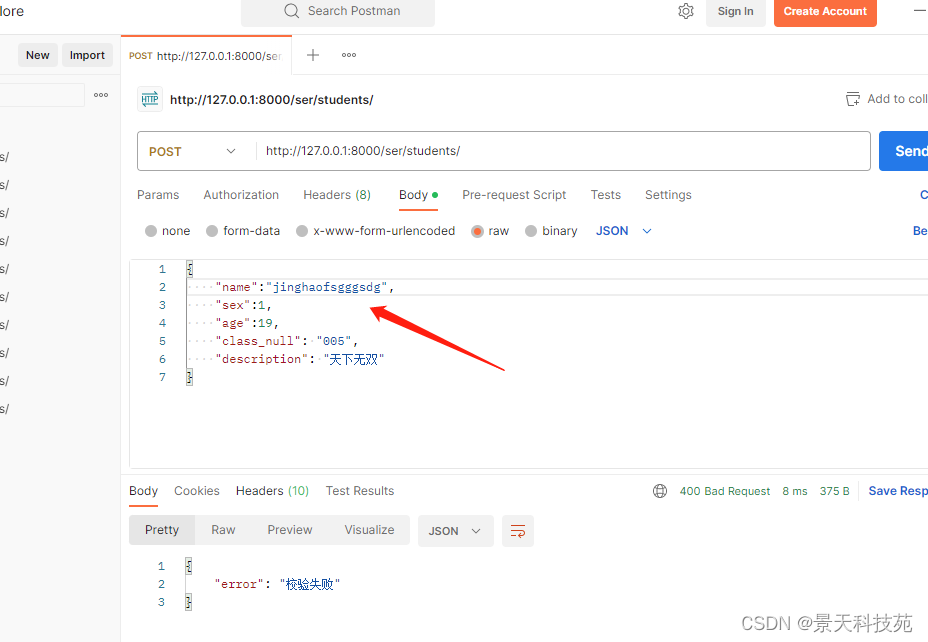
这样,报错信息就是我们自定义的,实现了错误信息定制
不传name
上面序列化器,一个是用于序列化用的,一个是反序列化数据校验的,
序列化和反序列化 能不能合并成一个序列化器来使用呢?
可以的
针对个别字段,有的只用于序列化输出,有的只用于反序列化输入,可以用下面两个参数控制
read_only 表明该字段仅用于序列化输出,默认False 用户提交数据时,不校验该字段
write_only 表明该字段仅用于反序列化输入,默认False 序列化时不会把该字段提取出来,服务端响应数据时,不响应给客户端该字段。反序列化时,客户端必须要传该字段进行校验
序列化器合成一个
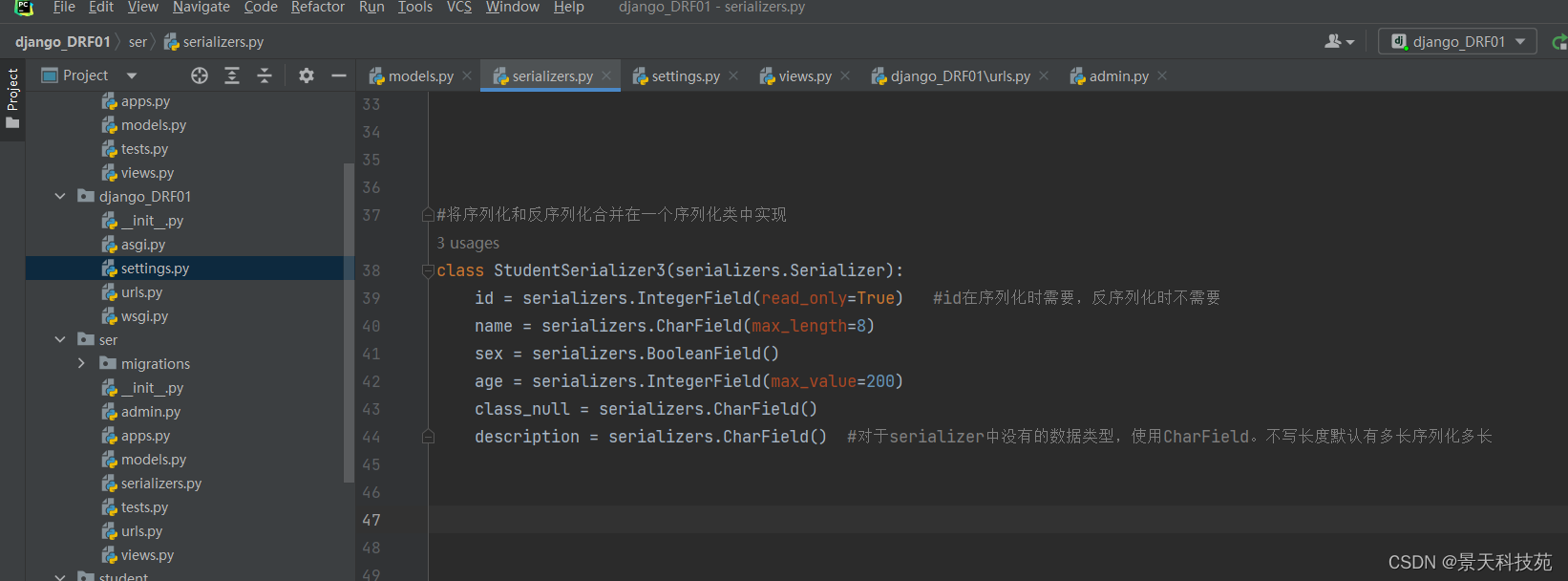
#将序列化和反序列化合并在一个序列化类中实现
class StudentSerializer3(serializers.Serializer):
id = serializers.IntegerField(read_only=True) #id在序列化时需要,反序列化时不需要
name = serializers.CharField(max_length=8)
sex = serializers.BooleanField()
age = serializers.IntegerField(max_value=200)
class_null = serializers.CharField()
description = serializers.CharField() #对于serializer中没有的数据类型,使用CharField。不写长度默认有多长序列化多长
视图类中,get请求和post请求,都用该序列化器
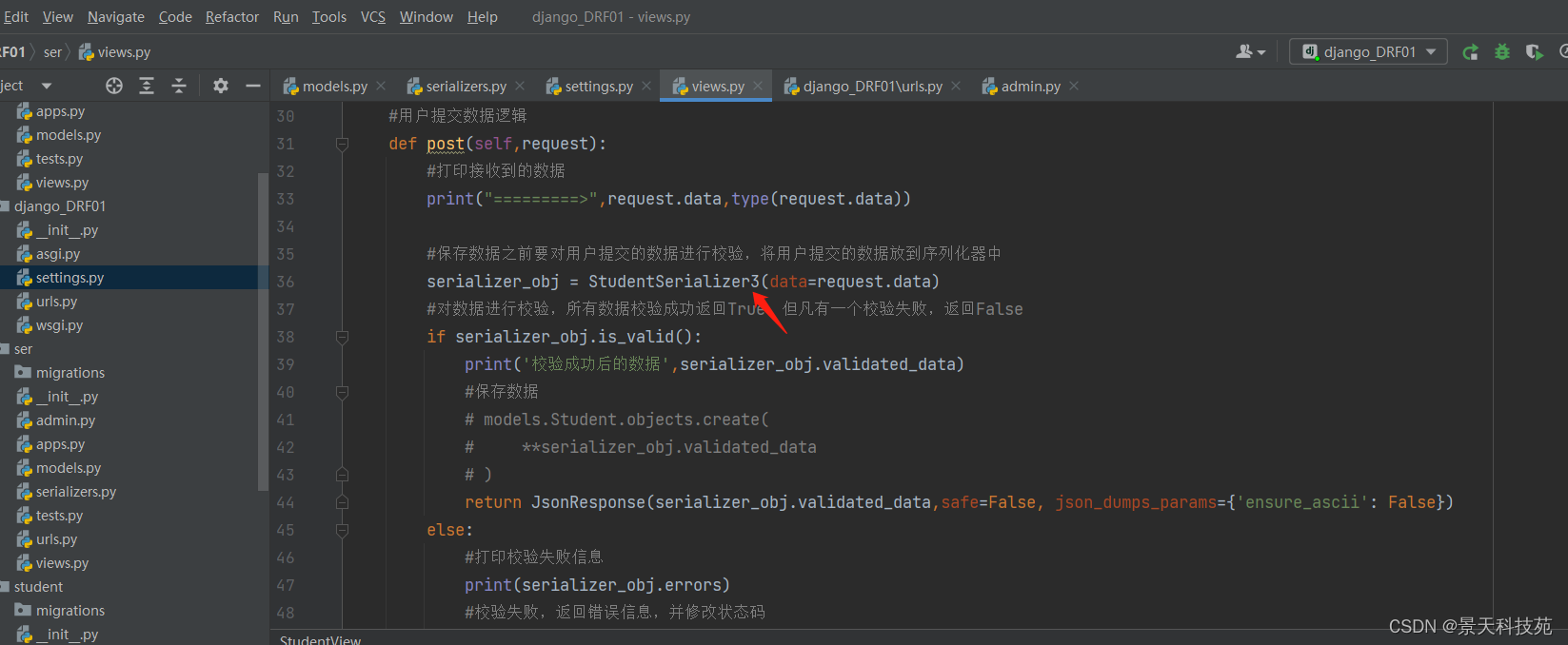
get请求,能收到数据
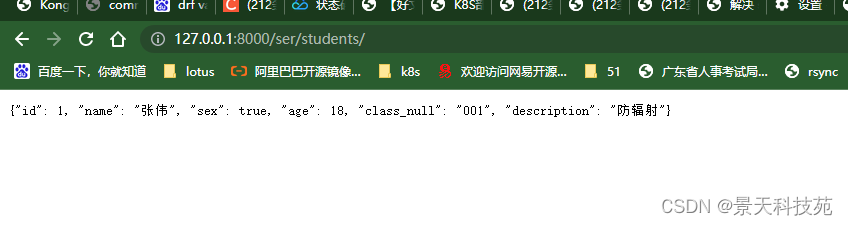
post请求,能提交数据
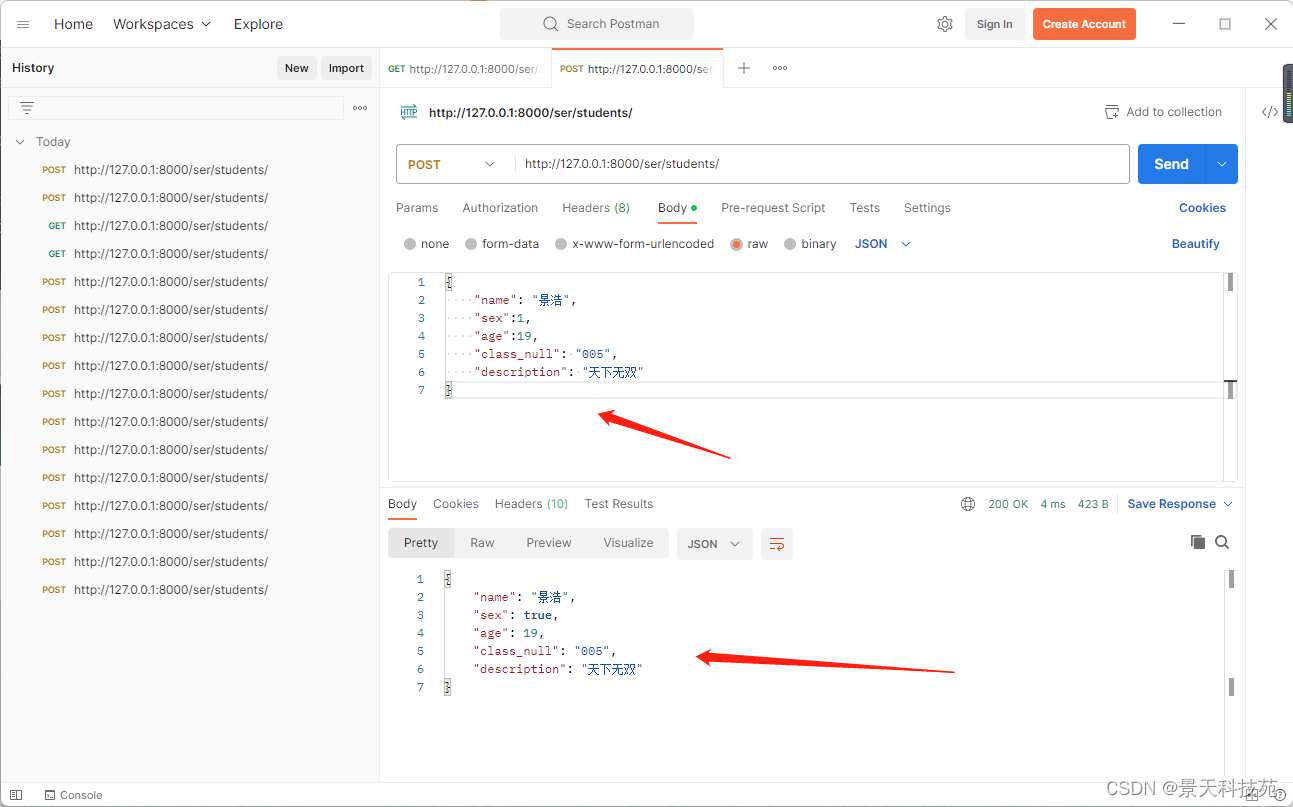
post请求校验成功
read_only使用场景:一般用在id上,序列化时需要,用户提交数据时不需要提交该字段
write_only使用场景:一般用在用户短信验证码,输入手机号,用户收到验证码,需要提交到后台验证,但是不需要服务端响应给客户,也不需要保存到数据库。
好了,今天先到这,明天继续,Carry on !

![[word] word页面视图放大后,影响打印吗? #笔记#学习方法](https://img-blog.csdnimg.cn/img_convert/2c901225278c93deb13e6db4722ee5af.jpeg)




![[AIGC] 21世纪Java与Go的相爱相杀](https://img-blog.csdnimg.cn/direct/6af1378f22b849dab5839a900fd4e1f1.png)