参数化的方式:

一、使用用户自定义变量
一种方式:直接在测试计划中添加用户自定义变量

另外一种方式:配置元件——用户自定义变量

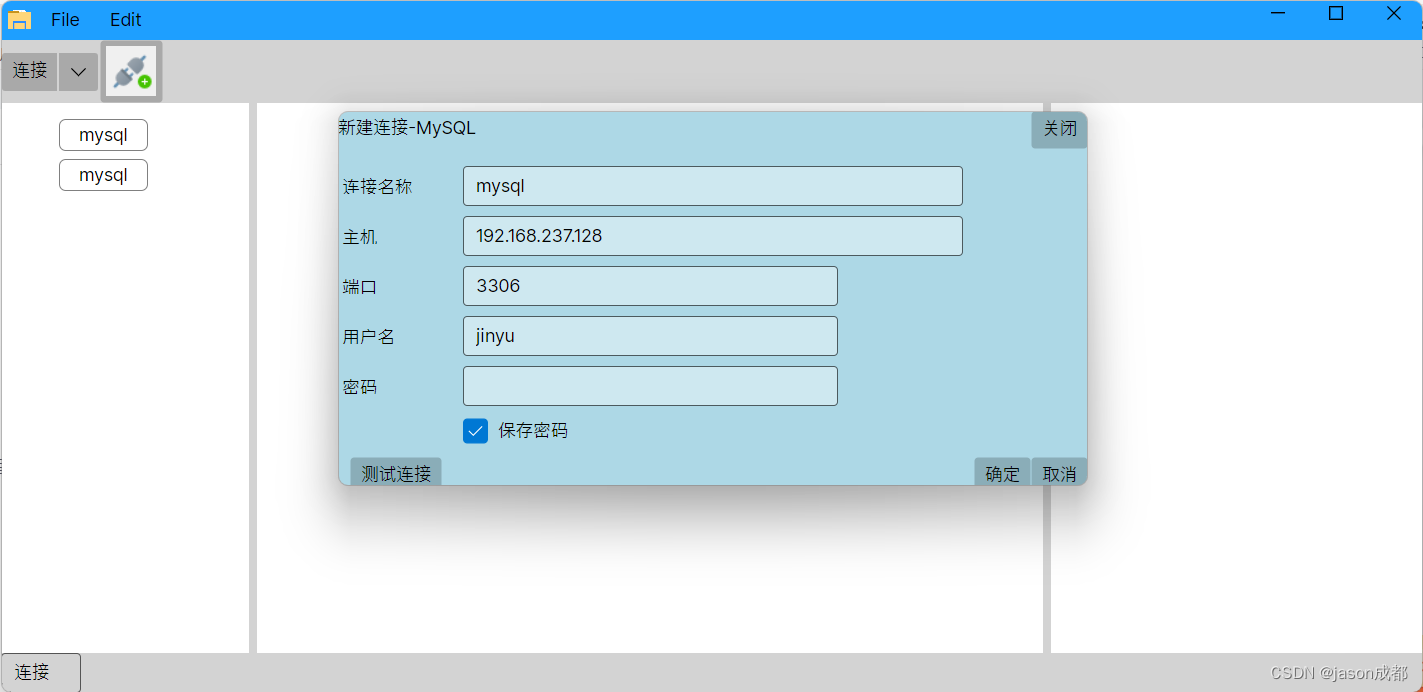
示例:用户自定义变量,登录手机号码

在接口请求的时候,进行引用

请求之后,查看请求参数

二、 使用函数助手里的随机函数进行参数化

选择一个函数(如_Random)
1.设定最小值 1
2.设定最大值 100
3.函数名称设为 num
4.单击生成按钮讲生成一个引用字符串,在需要参数化的地方替换生成的随机函数即可

拷贝该字符串,填入到需要使用的请求参数中

请求接口,查看参数,已经随机变化了

三、使用配置元件中的CSV Data Set Config进行参数化设置
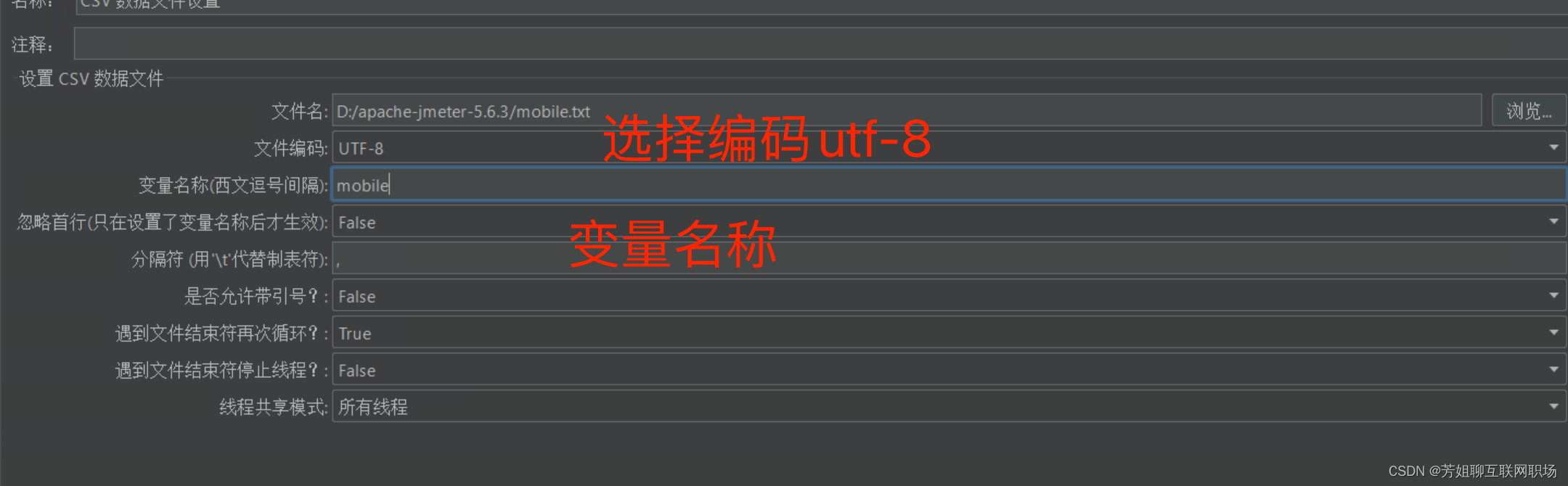
配置元件——CSV数据文件设置

在本地新建一个文本文件:
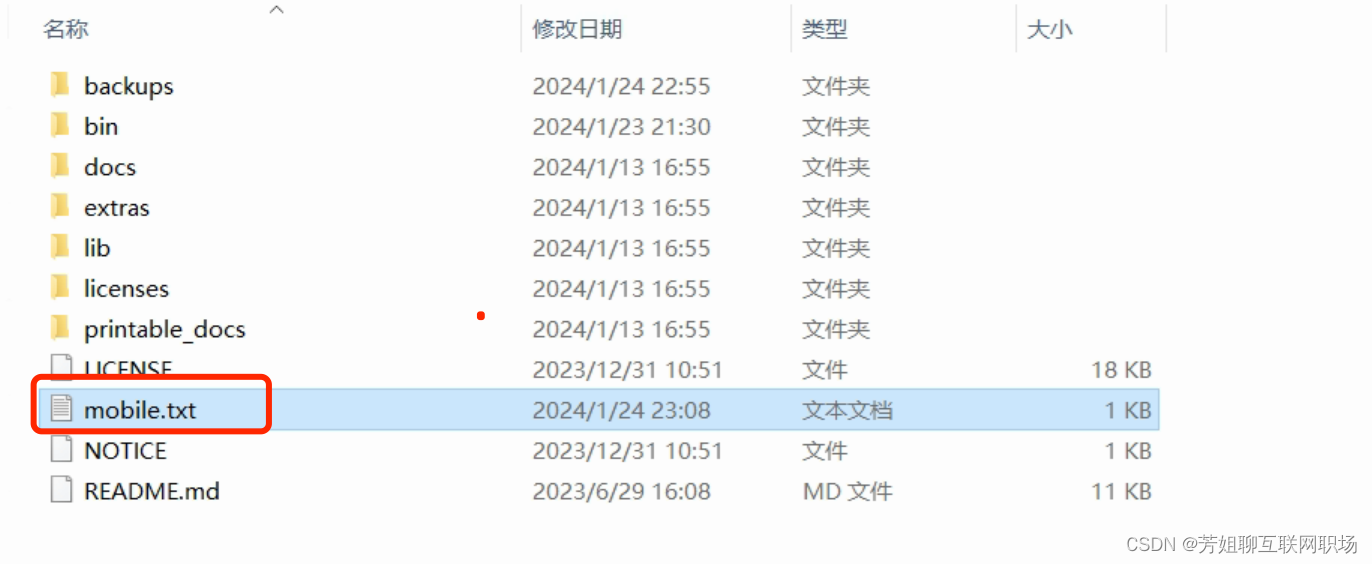
在CSV数据文件设置里面选择该新建的文件

说明:
Filename --- 参数项文件File Encoding --- 文件的编码,设置为UTF-8Vaiable Names --- 文件中各列所表示的参数项;各参数项之间利用逗号分隔;参数项的名称应该与HTTP Request中的参数项一致。Delimiter --- 如文件中使用的是逗号分隔,则填写逗号;如使用的是TAB,则填写\t;(如果此文本文件为CSV格式的,默认用英文逗号分隔)Recycle on EOF? --- True=当读取文件到结尾时,再重头读取文件 False=当读取文件到结尾时,停止读取文件
Stop thread on EOF? --- 当Recycle on EOF为False时,当读取文件到结尾时,停止进程,当Recycle on EOF为True时,此项无意义
备注说明:这里我用通俗的语言大概讲一下Recycle on EOF与Stop thread on EOF结果的关联
Recycle on EOF :到了文件尾处,是否循环读取参数,选项:true和false
Stop thread on EOF:到了文件尾处,是否停止线程,选项:true和false
当Recycle on EOF 选择true时,Stop thread on EOF选择true和false无任何意义,通俗的讲,在前面控制了不停的循环读取,后面再来让stop或run没有任何意义
当Recycle on EOF 选择flase时,Stop thread on EOF选择true,线程4个,参数3个,那么只会请求3次
当Recycle on EOF 选择flase时,Stop thread on EOF选择flase,线程4个,参数3个,那么会请求4次,但第4次没有参数可取,不让循环,所以第4次请求错误
Sharing mode:共享模式, All threads –所有线程, Current thread group—当前线程组, Current thread—当前线程。• 1. All threads:测试计划中所有线程,假如说有线程1到线程n (n>1),线程1取了一次值后,线程2取值时,取到的是csv文件中的下一行,即与线程1取的不是同一行。• 2. Current thread group:当前线程组,假设有线程组1、 线程组2, 1组内有线程1到线程n,线程组2内有线程1到线程n。取之情况是: 线程1-1取到了第1行, 线程1-2取第2行, 现在2-1取第1行, 线程2-2取第2行。• 3.Current thread:当前线程。假设测试计划内有线程1到线程n (n>1),则线程1取了第1行,线程2也取第1行。
运行一下脚本,查看结果


这样就轻松实现了不同的参数化方式,可以根据自己的需求,自由选择了!