文章目录
- scrapy项目部署
- 1.scrapyd部署工具介绍
- (1)环境安装
- 2.scrapy项目部署
- (1)配置需要部署的项目
- (2)管理scrapy项目
- (3)启动项目
- (4)关闭项目
- (5)删除项目
- 3.requests模块控制scrapy项目
scrapy项目部署
1.scrapyd部署工具介绍
- scrapyd是一个用于部署和运行scrapy爬虫的程序,它由 scrapy 官方提供的。它允许你通过JSON API来部署爬虫项目和控制爬虫运行。
所谓json api本质就是post请求的webapi
使用scrapyd部署,可以给更多的人去使用
选择一台主机当做服务器,安装并启动 scrapyd 服务。再这之后,scrapyd 会以守护进程的方式存在系统中,监听爬虫地运行与请求,然后启动进程来执行爬虫程序。
(1)环境安装
- scrapyd服务:
pip install scrapyd
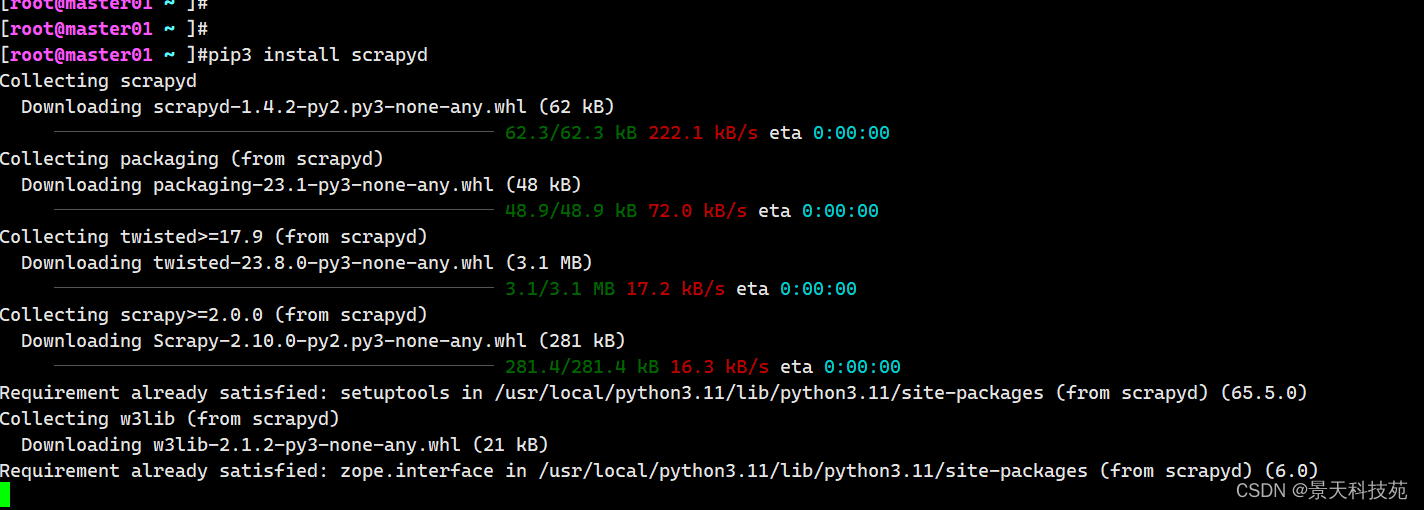
- scrapyd客户端:
pip install scrapyd-client
一定要安装较新的版本10以上的版本,如果是现在安装的一般都是新版本
####启动scrapyd服务
- 打开终端在scrapy项目路径下 启动scrapyd的命令:
scrapyd
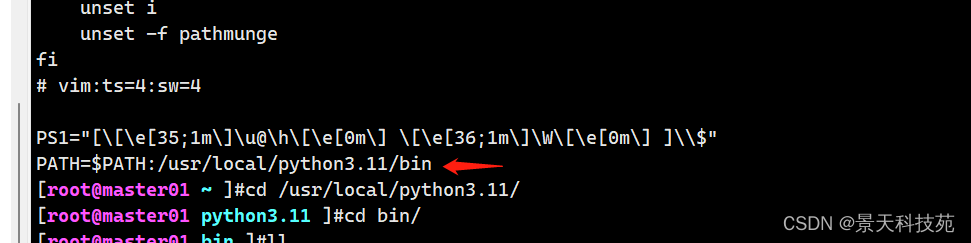
执行scrapyd这个命令,需要将该命令添加到环境变量
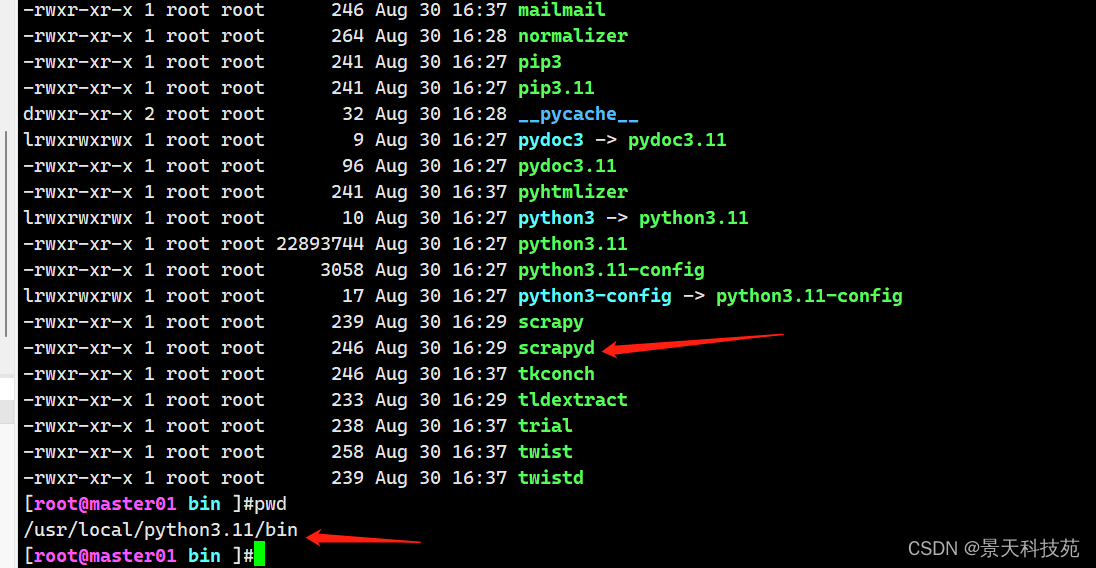
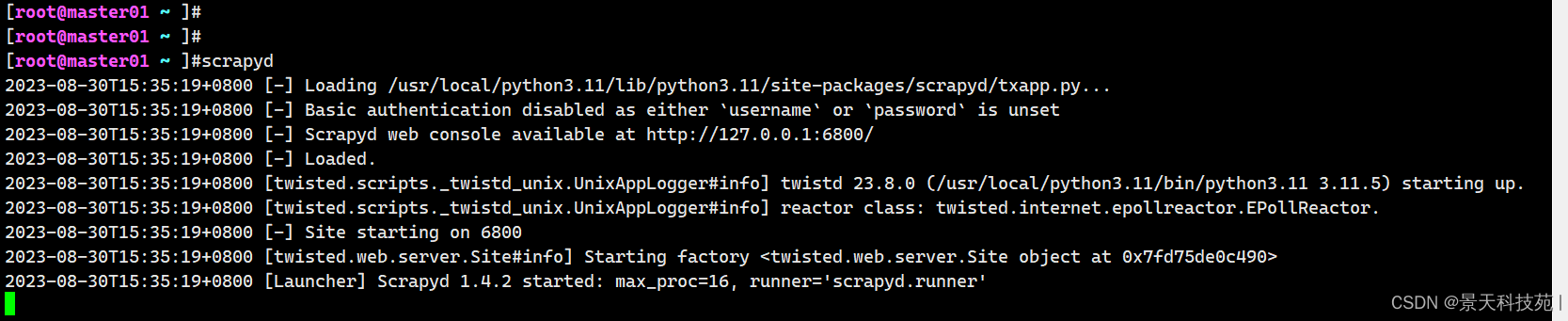
这样启动,只能在本机localhost:6800访问,浏览器访问不了
我们需要修改下配置

官方默认配置:
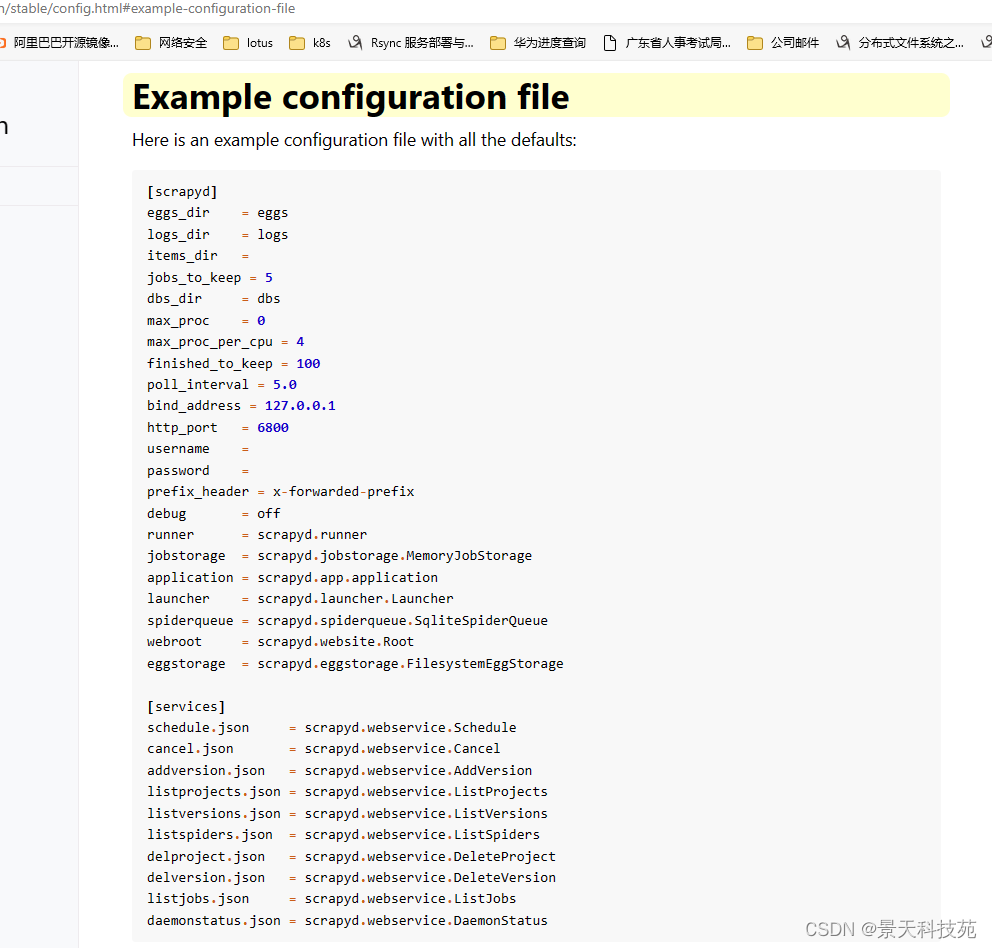
[root@master01 ~ ]#cat /etc/scrapyd/scrapyd.conf
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
prefix_header = x-forwarded-prefix
debug = off
runner = scrapyd.runner
jobstorage = scrapyd.jobstorage.MemoryJobStorage
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
spiderqueue = scrapyd.spiderqueue.SqliteSpiderQueue
webroot = scrapyd.website.Root
eggstorage = scrapyd.eggstorage.FilesystemEggStorage
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
再次启动
浏览器访问
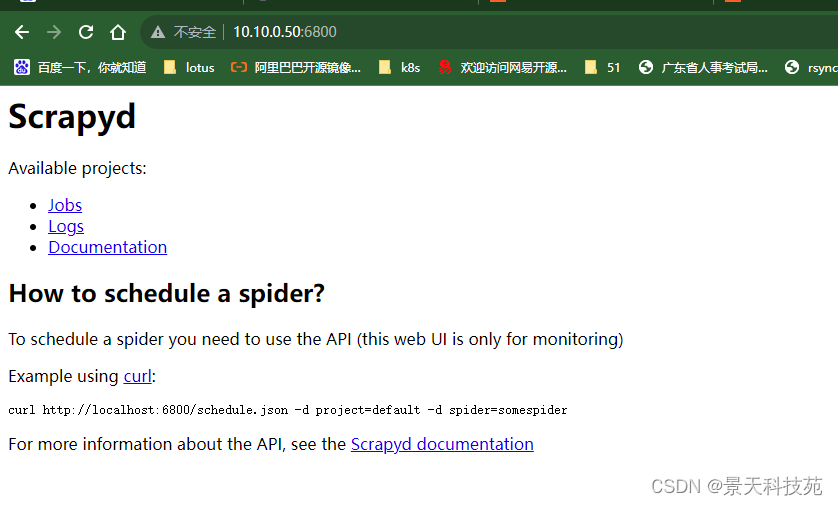
部署过的项目在projects后面会显示 项目名称
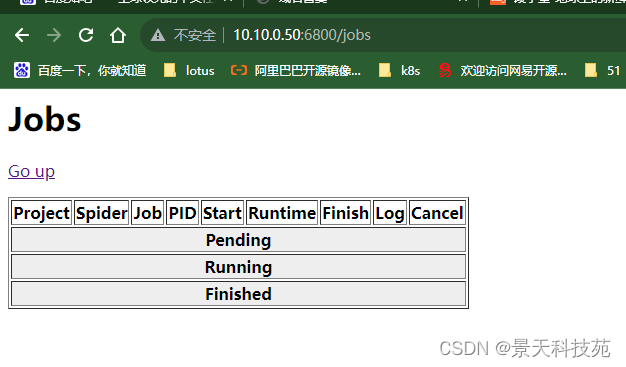
- 点击job可以查看任务监控界面,目前没有任务,都为空
2.scrapy项目部署
(1)配置需要部署的项目
- 编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)
看下默认配置
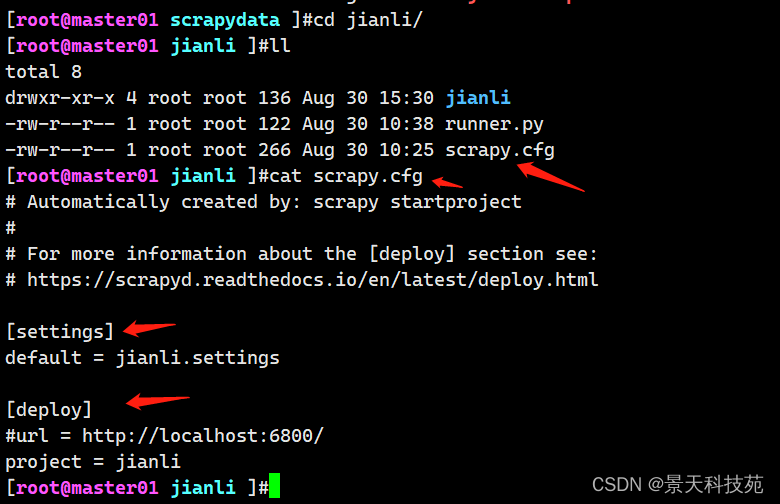
[deploy:部署名(部署名可以自行定义)]
url = http://localhost:6800/ #这里是写scrapyd的服务器地址,scrapyd上面不用运行scrapy项目
project = 项目名(创建爬虫项目时使用的名称)
username = bobo # 如果不需要用户名可以不写
password = 123456 # 如果不需要密码可以不写
比如我们在Windows上的项目
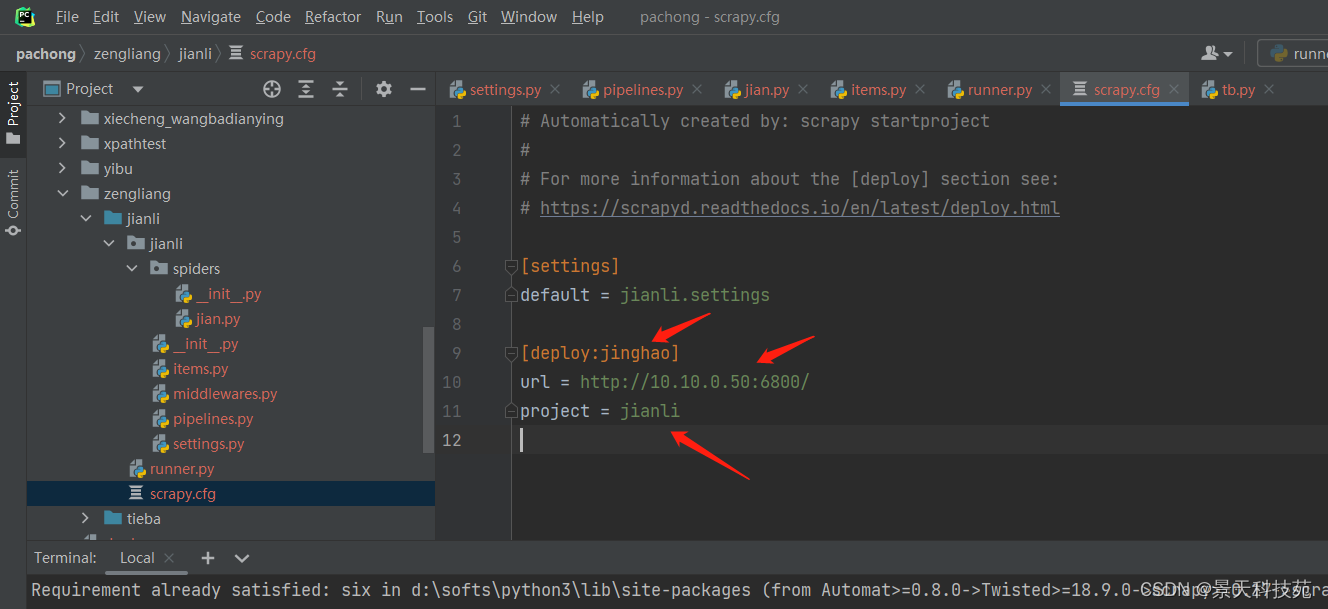
#####部署项目到scrapyd 在windows上执行部署命令
scrapy-deploy 是scrapyd-client的命令 在Windows要安装scrapyd-client
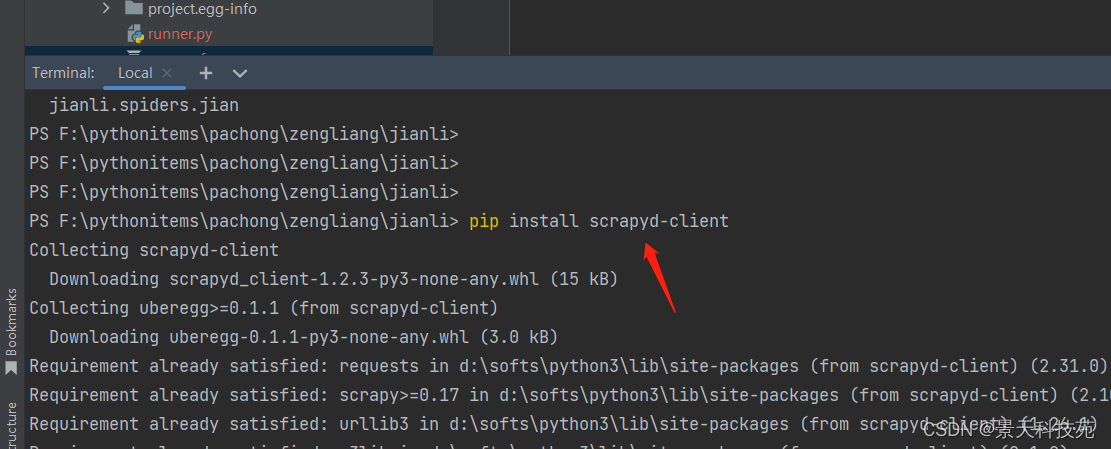
- 同样在scrapy项目路径下执行如下指令:
scrapyd-deploy 部署名(配置文件中设置的名称) -p 项目名称
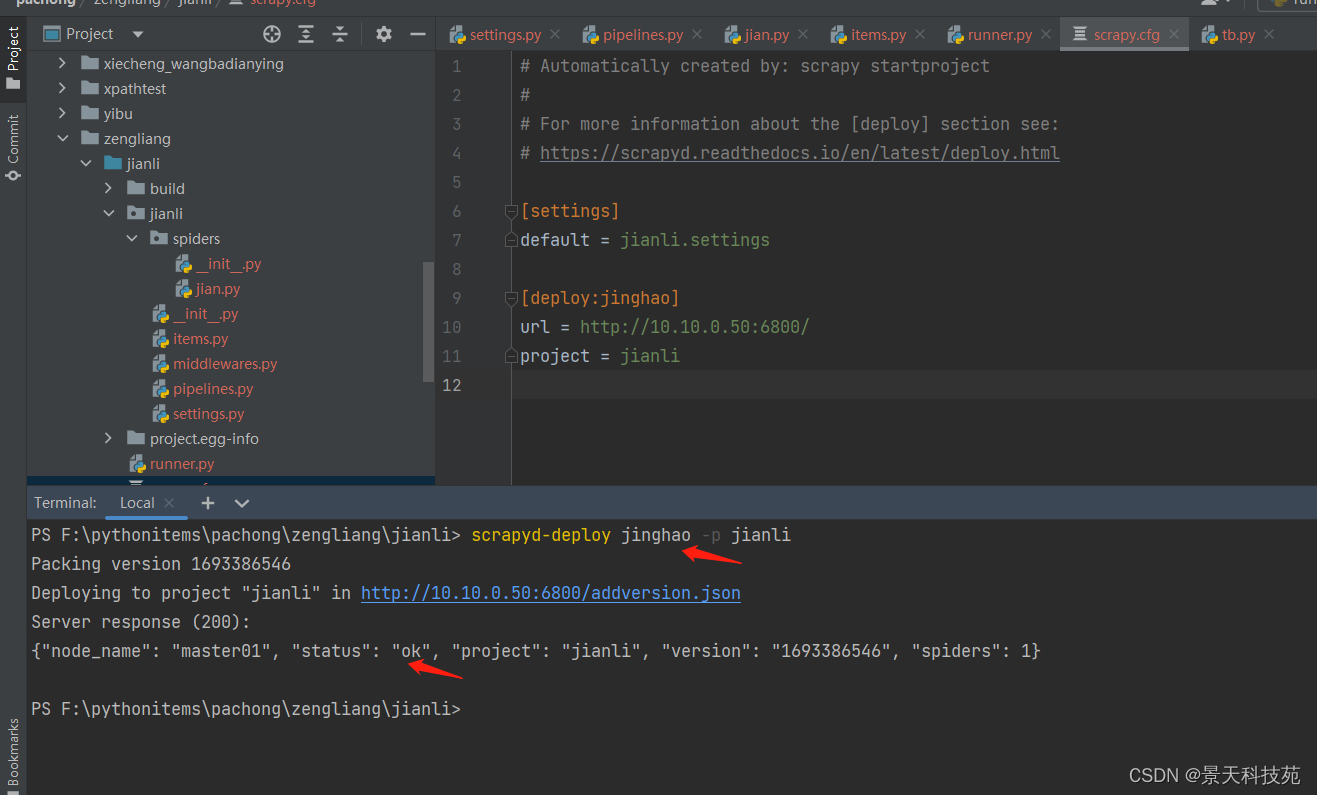
浏览器刷新,可以看到我们部署的项目
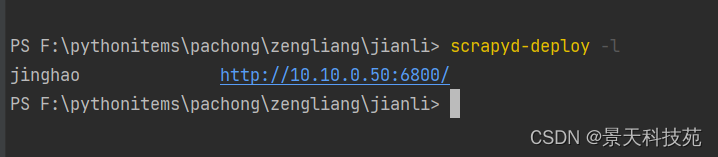
在Windows也能查看部署过的项目
scrapyd-deploy -l
可以通过部署名字,查看项目
scrapyd-deploy -L jinghao

(2)管理scrapy项目
#####指令管理
-
安装curl命令行工具
- window需要安装
- linux和mac无需单独安装
-
window安装步骤:
- 下载curl文件:https://curl.se/download.html,打开网页后向下拖动,找到window系统对应版本下载
向下拉,找到Windows64位
- 下载curl文件:https://curl.se/download.html,打开网页后向下拖动,找到window系统对应版本下载
点这里下载
下载后,放置到一个无中文的文件夹下直接解压缩,解压后将bin文件夹配置环境变量!
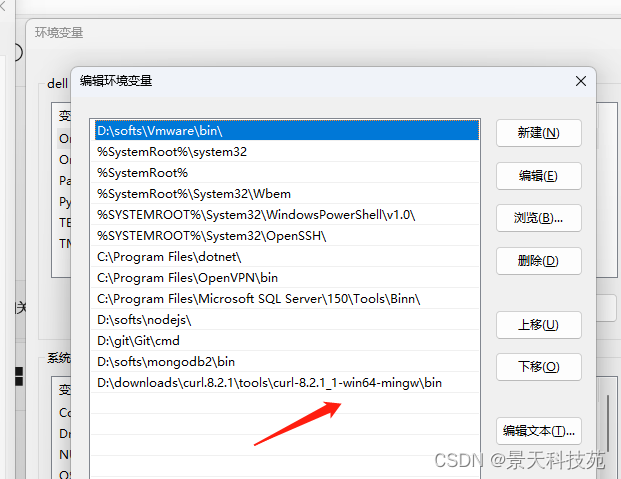
测试curl可用性
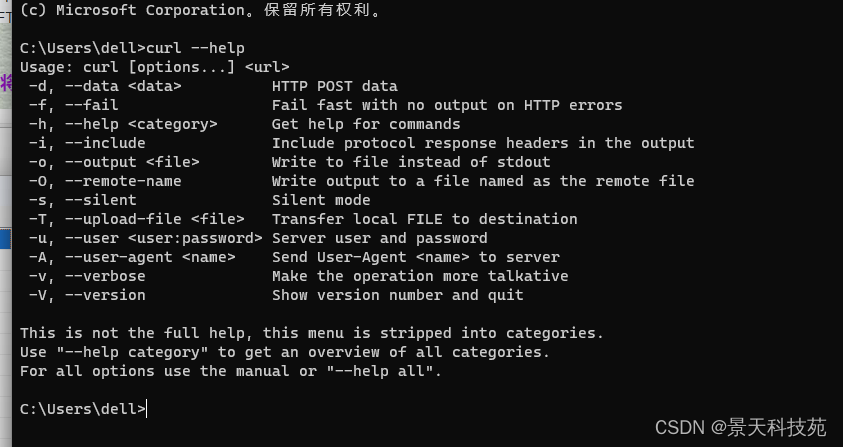
(3)启动项目
curl http://10.10.0.50:6800/schedule.json -d project=项目名 -d spider=爬虫名
curl http://10.10.0.50:6800/schedule.json -d project=jianli -d spider=jian
在pycharm执行报错,要在cmd终端执行
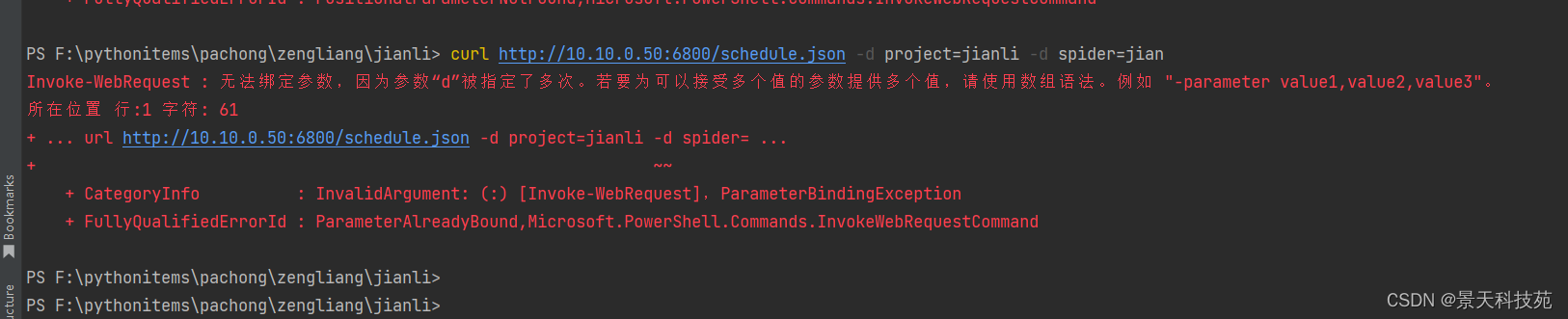
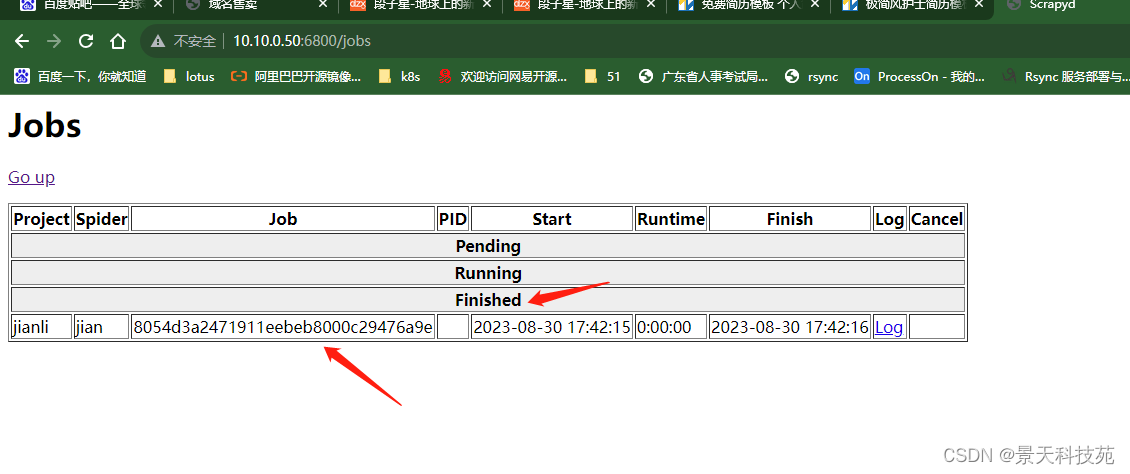
返回结果:注意期中的jobid,在关闭项目时候会用到

浏览器上看我们的job,有执行完成的job
(4)关闭项目
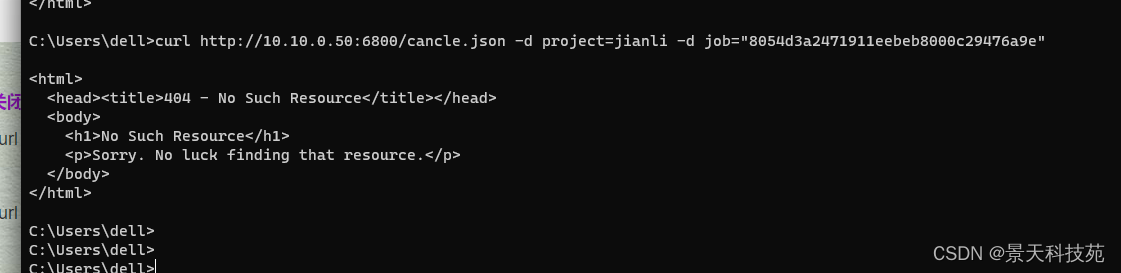
curl http://localhost:6800/cancel.json -d project=项目名 -d job=项目的jobid
curl http://10.10.0.50:6800/cancle.json -d project=jianli -d job=“8054d3a2471911eebeb8000c29476a9e”
(5)删除项目
curl http://localhost:6800/delproject.json -d project=爬虫项目名称

可见项目已被删除
3.requests模块控制scrapy项目
import requests
# 启动爬虫
# url = 'http://10.10.0.50:6800/schedule.json'
# data = {
# 'project': "jianli",
# 'spider': "jian",
# }
# resp = requests.post(url, data=data)
#
# print(resp.json())
# # 停止爬虫
url = 'http://10.10.0.50:6800/cancel.json'
data = {
'project': "jianli",
'job': "ab437994471c11eebeb8000c29476a9e",
}
resp = requests.post(url, data=data)
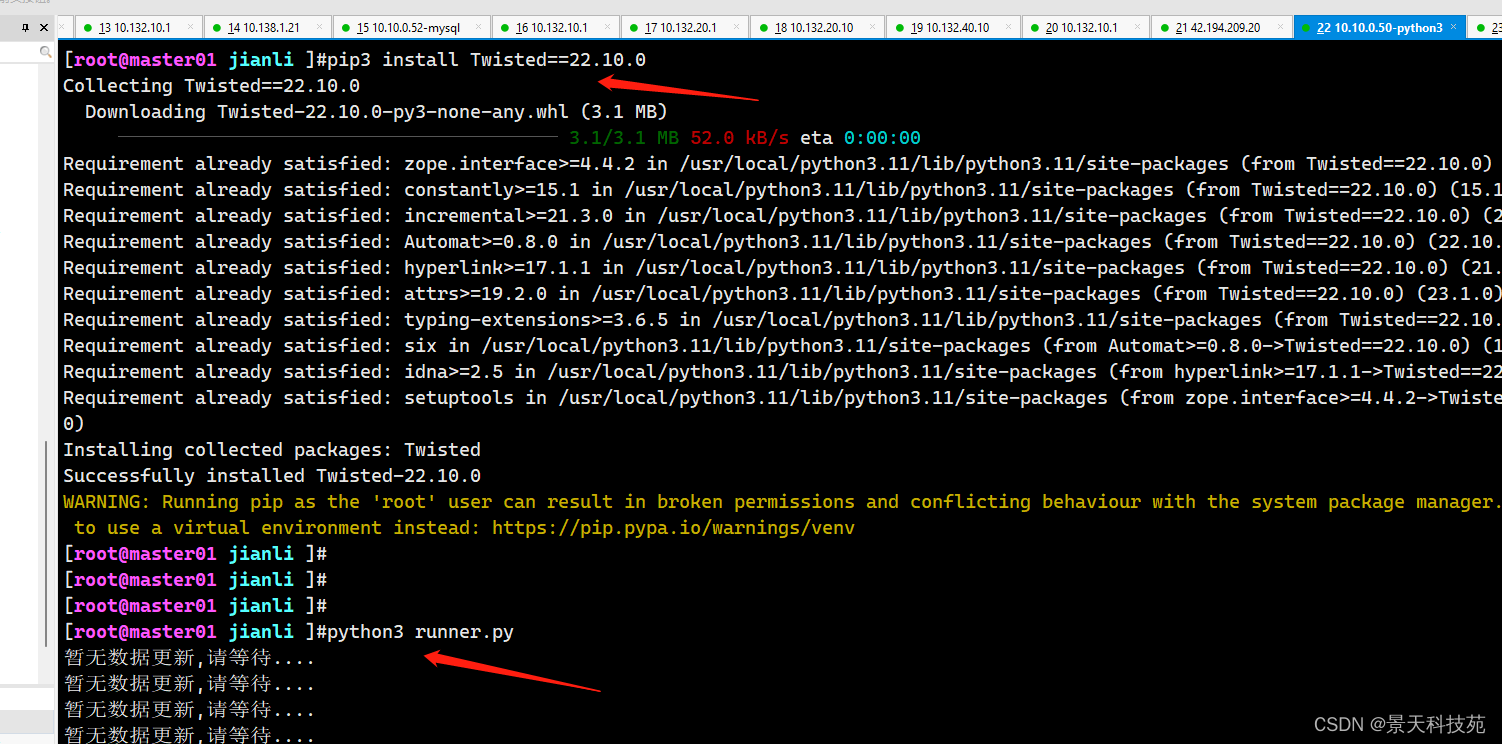
在Windows上创建的项目,到linux运行报这个错误
AttributeError: ‘AsyncioSelectorReactor’ object has no attribute ‘_handleSignals’
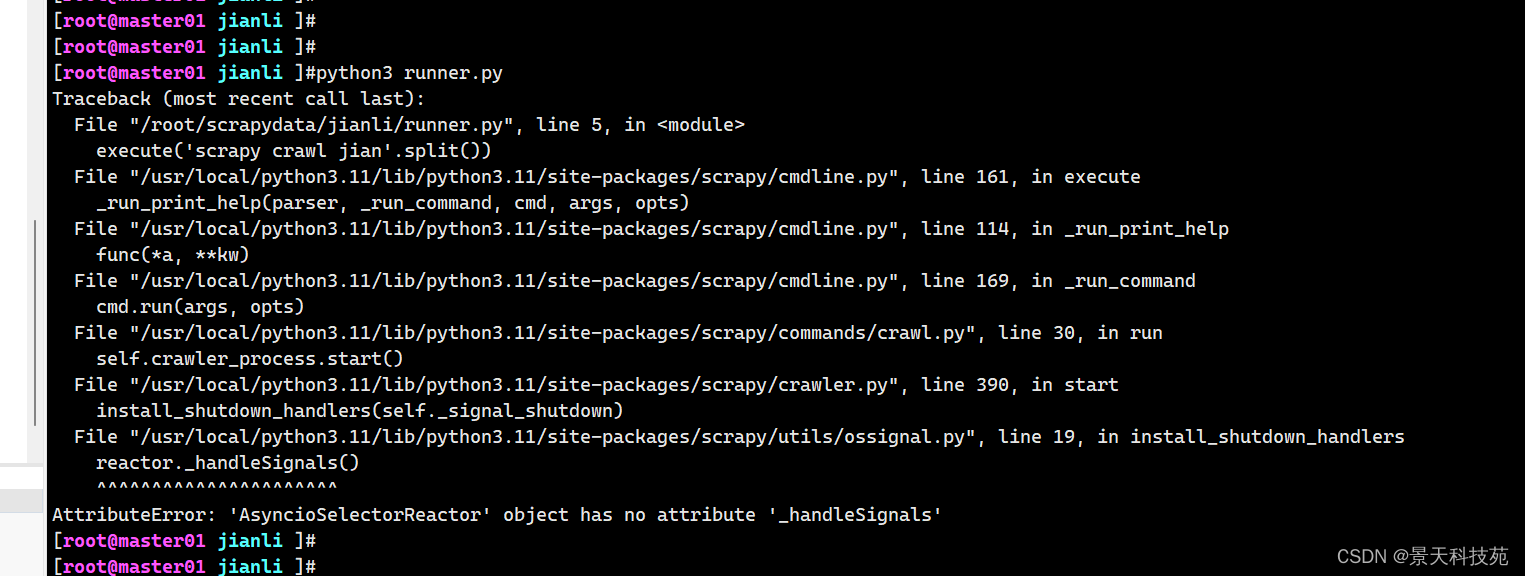
是由于Twisted版本不兼容的问题,把版本降到22.10.0就可以了 目前使用的python版本是3.11.5
更换版本后,可见部署运行成功