前段时间, 首届通义千问AI挑战赛成功举办,CodeFuse 为大赛提供技术支持,模型微调框架 MFTCoder 和 CodeFuseEval 评测框架为大赛保驾护航,助力大赛圆满完成。我们基于leetcode 阿里和蚂蚁最新面试题库建设了“模型赛马”在线打榜的评测方案,目前验证集已作为 CodefuseEval 的一项任务在 Github 上开放,欢迎大家下载使用。
赛事背景
2023 年 12 月 28 日,历经 1 个月的首届通义千问 AI 挑战赛圆满结束。Code Qwen 能力算法赛道代表高校有麻省理工学院、新加波国立大学、北京大学、清华大学、中国科学院、浙江大学等,硕博占比 70%。代表企业有中国移动、腾讯、华为、快手等。
本次大赛共吸引来自全国 1216 支队伍报名、其中,20 支队伍在初赛中表现出色,顺利进入决赛。初赛阶段,参赛者围绕 1.8B 规模的开源 Qwen 模型进行微调;决赛阶段,参赛者在阿里云灵积平台上对 72B Qwen 模型进行云端训练,期望大型模型能够像顶尖的编程专家那样在真实 leetcode 上进行编程挑战。

决赛榜单
经过 10 天决赛,上百次的评测,产出了最终的决赛榜单,榜单分为A榜验证集和B榜测试集。复赛A榜第一名成绩:0.62,第二名:0.54。复赛B榜第一名:0.36,第二名:0.30。

决赛榜单
决赛评测
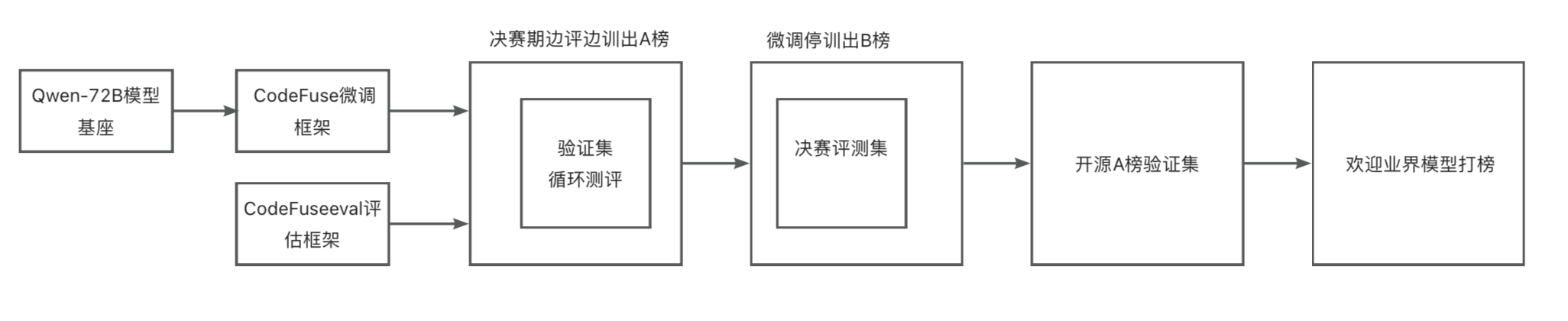
其中 CodeFuse 微调框架 MFTCoder 为 Qwen-72B 模型模型微调提供技术支持,MFTCoder 将多任务学习引入到(代码)大模型微调阶段,通过设计或应用多种均衡损失函数有效缓解多任务学习中数据量不均衡、难易不一、收敛速度不一致的挑战性问题,大量实验结果表明,多任务微调的模型比每个下游任务单独微调的模型和多任务数据混合为一后微调的模型表现更好。
为了贴合编程竞赛场景,评估 72B 大模型的解题能力,我们基于leetcode 阿里和蚂蚁最新面试题库构建了 2995 个评测任务题库,建设了【模型赛马】在线打榜的评测方案。本方案不仅支持模型在不同难度级别的赛题横向对比,同时,给模型预留了足够的提升空间。最终,根据参赛模型在 A 榜的表现,选择难易适度的题目,形成 B 榜测评集。

指标计算(LeetCode在线提交计算Accepted在不同等级上的AC成功率)
{
"prompt": "在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。\n\n当提莫攻击艾希,艾希的中毒状态正好持续 duration 秒。\n\n正式地讲,提莫在 t 发起攻击意味着艾希在时间区间 [t, t + duration - 1](含 t 和 t + duration - 1)处于中毒状态。如果提莫在中毒影响结束 前 再次攻击,中毒状态计时器将会 重置 ,在新的攻击之后,中毒影响将会在 duration 秒后结束。\n\n给你一个 非递减 的整数数组 timeSeries ,其中 timeSeries[i] 表示提莫在 timeSeries[i] 秒时对艾希发起攻击,以及一个表示中毒持续时间的整数 duration 。\n\n返回艾希处于中毒状态的 总 秒数。\n\n示例 1:\n\n输入:timeSeries = [1,4], duration = 2\n输出:4\n解释:提莫攻击对艾希的影响如下:\n- 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。\n- 第 4 秒,提莫再次攻击艾希,艾希中毒状态又持续 2 秒,即第 4 秒和第 5 秒。\n艾希在第 1、2、4、5 秒处于中毒状态,所以总中毒秒数是 4 。\n示例 2:\n\n输入:timeSeries = [1,2], duration = 2\n输出:3\n解释:提莫攻击对艾希的影响如下:\n- 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。\n- 第 2 秒,提莫再次攻击艾希,并重置中毒计时器,艾希中毒状态需要持续 2 秒,即第 2 秒和第 3 秒。\n艾希在第 1、2、3 秒处于中毒状态,所以总中毒秒数是 3 。\n提示:\n\n1 <= timeSeries.length <= 104\n0 <= timeSeries[i], duration <= 107\ntimeSeries 按 非递减 顺序排列\nclass Solution(object):\n def findPoisonedDuration(self, timeSeries, duration):",【问题描述,为了对齐代码补全任务,拼接了目标语言的首行】
"type": "easy",【难易程度如简单/中等/困难】
"title": "teemo-attacking",【题目标题】
"task_id": "Python/43",【任务号】
"question_id": "495" 【题号】
}验证集例子
A榜开源
目前 A 榜验证集,已作为 CodefuseEval 的一项任务,在 Github 上开放,欢迎大家下载使用,本期仅开放样本,指标计算及B榜数据集会在审核后,陆续开放,保持关注。
- GitHub 地址: https://github.com/codefuse-ai/codefuse-evaluation
CodeFuseEval是结合CodeFuse大模型多任务场景,在开源的HumanEval-x、MBPP、DS1000评测基准基础上,开发的面向大模型代码垂类领域的企业级多类型编程任务评估基准。可用于评估大模型在代码补全、自然语言生成代码、测试用例生成、跨语言代码翻译、中文指令生成代码、代码注解释、Bug检测/修复、代码优化等不同任务的能力表现。旨在贴近企业实际应用场景,构建一套能够衡量大模型代码生成相关能力的「多维」、「多样」和「可信」的评测基准。
CodeFuseEval :代码类大模型多任务评估基准