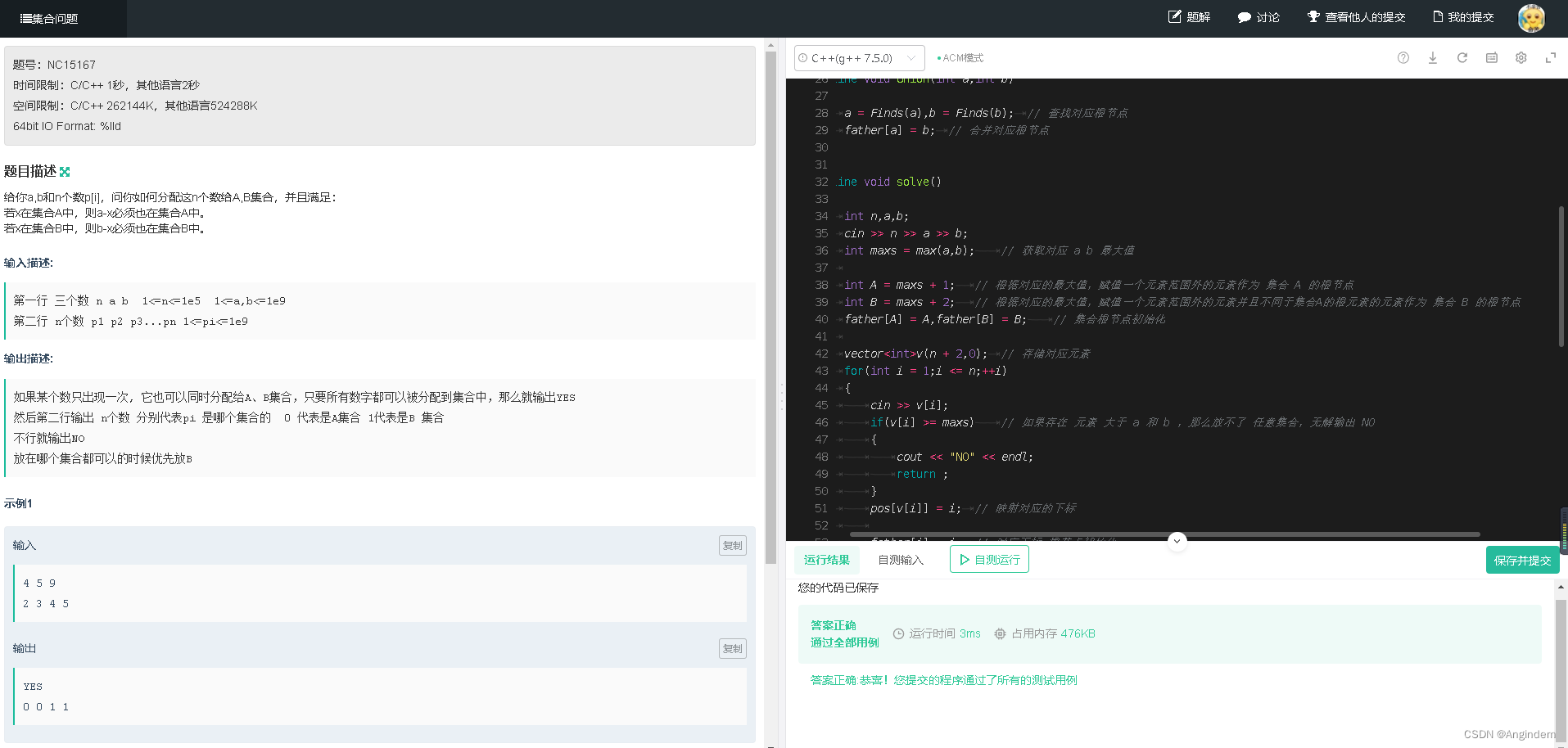
torch.device("cuda" if torch.cuda.is_available() else "cpu")
当使用上面的这个命令时,PyTorch 会检查系统是否有可用的 CUDA 支持的 GPU。如果有,它将选择默认的 GPU(通常是第一块,即 “cuda:0”)。这意味着,即使系统中有多块 GPU,这条命令也只会指向默认的一块。
torch.device(“cuda” if torch.cuda.is_available() else “cpu”) 这个命令在多 GPU 系统中是有效的,但它默认只指向一块 GPU(通常是 “cuda:0”)。要在多 GPU 系统中高效地利用所有 GPU,需要采用更复杂的设置。
下面就列举了几种可能遇到的情况:
调用多个gpu
选择特定的GPU
列出所有可用的GPU:首先,可以使用 torch.cuda.device_count() 来获取系统中可用的GPU数量。
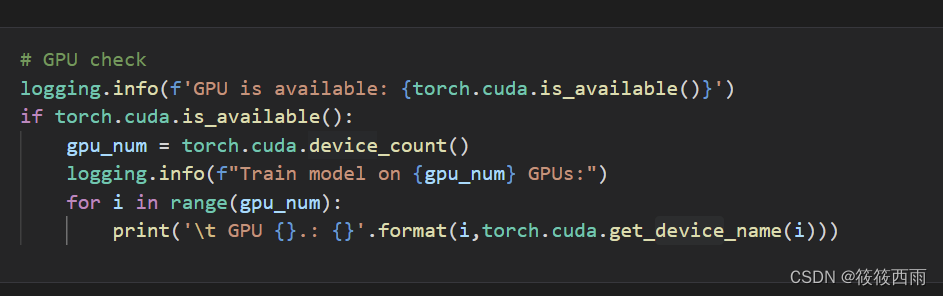
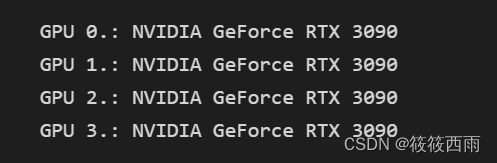
选择特定的GPU:可以通过设置 torch.device(“cuda:X”) 来选择特定的GPU,其中 X 是GPU的索引(从0开始)。例如,使用第一个GPU,可以设置 device = torch.device(“cuda:0”),对于第二个GPU,使用 device = torch.device(“cuda:1”)
使用多个GPU进行并行计算
如果想同时使用多个GPU来加速计算,可以使用PyTorch的 nn.DataParallel 或 nn.parallel.DistributedDataParallel。
使用DataParallel
:这是最简单的方法,可以自动将数据分割并发送到多个GPU上,然后再汇总结果。只需将模型包裹在 nn.DataParallel 中即可。例如:
model = nn.Linear(10, 5)
model = nn.DataParallel(model)
model.to(device)
**
使用DistributedDataParallel
对于更大规模的分布式训练,DistributedDataParallel 提供了更高效的并行计算方式。但它的设置比 DataParallel 复杂一些,通常用于多节点的分布式训练。
import torch
import torch.nn as nn
import torch.distributed as dist
# 初始化进程组
dist.init_process_group(backend="nccl", init_method="env://")
#初始化进程组:通过 dist.init_process_group 初始化分布式进程组。这允许进程间通信并同步。
model = YourModel() # 替换为训练模型
model = nn.parallel.DistributedDataParallel(model)
#nn.parallel.DistributedDataParallel 将模型包装为一个分布式训练的模型。
model.to(torch.device("cuda", rank)) # rank 是当前进程的索引
# 训练循环
for data in dataloader:
inputs, labels = data
inputs, labels = inputs.to(torch.device("cuda", rank)), labels.to(torch.device("cuda", rank))
outputs = model(inputs)
# ... 后续操作
在使用DataParallel时,所有GPU的输出将会被汇总到主GPU上,然后再传回CPU。因此,主GPU可能会成为性能瓶颈。
使用DistributedDataParallel要求更复杂的设置,包括环境的配置和更精细的数据处理方式。
在使用多GPU时,确保数据和模型适合进行并行处理。不是所有的模型都能从数据并行中获益。
在多GPU环境下,GPU之间的同步是自动进行的,但需要注意数据的一致性和正确的损失函数处理。
手动分配任务到不同的GPU
在某些情况下,可能希望手动控制不同部分的模型或数据在不同GPU上的运行。这通常在模型非常大或者特别定制化时发生,c此时可以根据模型的不同部分手动指定不同的GPU。
假设有一个大型模型,可以被分解为三个部分,可以将每个部分分配给一个不同的GPU:
device0 = torch.device("cuda:0")
device1 = torch.device("cuda:1")
device2 = torch.device("cuda:2")
model_part1 = ModelPart1().to(device0)
model_part2 = ModelPart2().to(device1)
model_part3 = ModelPart3().to(device2)
# 你需要手动处理数据的传输和模型部分的协调







![[opencvsharp]C#基于Fast算法实现角点检测](https://img-blog.csdnimg.cn/direct/6c1273dc2d514826b2c0623d9a60ca97.jpeg)